Linux RT补丁/分析/性能测试(@Ubuntu)
关键词:rt-tests,rt等等。
要去了解实时Linux,首先了解其背景,实时Linux的目标是什么?都采取了哪些措施?
然后需要准备测试环境,需要同一版本的两个内核作对比测试。
确定内核版本之后,针对两个版本的差异进行分析,详细了解这些差异是如何保证实时性的。
最后借助rt-tests和ltp的realtime部分进行RT相关测试,确定究竟有哪些提高。
1. Linux RT背景
官网Real-Time Linux介绍了PREEMPT_RT的补丁,这些补丁以patch形式存于https://cdn.kernel.org/pub/linux/kernel/projects/rt/。
之前还存在一个已经不再维护的Real-Time Linux Wiki。
有两个内容需要终点关注:概述PREEMPT_RT补丁的Technical details of PREEMPT_RT patch和实时Linux的基础技术Technical basics: Important aspects for real time。
1.1 PREEMPT_RT补丁概述
PREEMPT_RT补丁的主要最小化内核中不可抢占部分,这些措施修改部分包括高精度定时器、中断线程化、RCU、睡眠spinlock、rt_mutex。
1.2 实时Linux基础技术
Preemption Models有详细介绍,其中常用的有Desktop、Low-Latency Desktop和RT。
Desktop模式在内核总增加了更多的主动抢占,同时还在系统调用返回和中断返回中增加了抢占点。
Low-Latency Desktop模式让内核在所有非critical section可抢占,并且在禁止抢占退出的时候增加了抢占点。
RT模式最大化的缩小了禁止抢占区域,措施包括中断线程化、睡眠spinlock、rt_mutex。并且一些大禁止抢占区域被分开处理了。
Voluntary Kernel Preemption (Desktop): This option reduces the latency of the kernel by adding more “explicit preemption points” to the kernel code [. . . ] at the cost of slightly lower throughput 2). In addition to explicit preemption points, system call returns and interrupt returns are implicit preemption points.
Preemptible Kernel (Low-Latency Desktop): This option reduces the latency of the kernel by making all kernel code (that is not executing in a critical section) preemptible 3). An implicit preemption point is located after each preemption disable section.
Fully Preemptible Kernel (RT): All kernel code is preemptible except for a few selected critical sections. Threaded interrupt handlers are forced. Furthermore several substitution mechanisms like sleeping spinlocks and rt_mutex are implemented to reduce preemption disabled sections. Additionally, large preemption disabled sections are substituted by separate locking constructs. This preemption model has to be selected in order to obtain real-time behavior.
其它的调度相关的技术包括:Scheduling RT throttling(对实时进程配比进行限制)、Scheduling Policy and priority(实时进程调度策略和优先级)、Priority inversion Priority inheritance(解决优先级反转问题的优先级继承)。
2. 测试环境准备
在进行分析之前,确定代码版本和测试环境,为后面的代码分析和验证测试做好准备。
2.1 QEMU or PC
首先考虑的是在虚拟环境QEMU还是PC上进行测试?
由于虚拟环境可能带来不确定因素,决定从PC上开始准备。
一种方法是在qemu上运行RT对比测试,另一种是在Ubuntu PC上运行RT对比测试。
(×)第一种方法感觉受影响较大,对测试的结果是否会有影响不太确定。
(√)第二种方法需要编译能在Ubuntu上运行的PREEMPT RT内核。
2.2 内核编译
通过apt-get source获取的内核编译,参考《编译自己的Ubuntu内核》。
但是由于不一定有对应的RT补丁,所以计划从kernel.org下载内核和对应的RT补丁。
在Ubuntu上运行RT对比测试,一种方式是从linux-stable.git下载一个Vanilla Kernel,然后打上对应的RT Patch;另一种是直接从linux-stable-rt.git下载附带RT Patch的内核。
BuildYourOwnKernel介绍从Ubuntu下载并编译内核。
How to Build a Custom Kernel on Ubuntu介绍了如何从kernel.org下载并编译Ubuntu使用内核。
2.2.1 从kernel.org内核开始编译Ubuntu内核
安装编译依赖文件:
sudo apt install git build-essential kernel-package fakeroot libncurses5-dev libssl-dev ccache
从kernel.org下载指定版本内核,然后切换到指定的tag。
git clone https://git.kernel.org/pub/scm/linux/kernel/git/rt/linux-stable-rt.git
git checkout v4.4.138-rt155
使用目前系统当前配置文件作为.config:
cp /boot/config-`uname -r` .config
对当前.config配置默认yes配置内核:
yes '' | make oldconfig
之后如果有需要可以make menuconfig对内核进行手动配置。
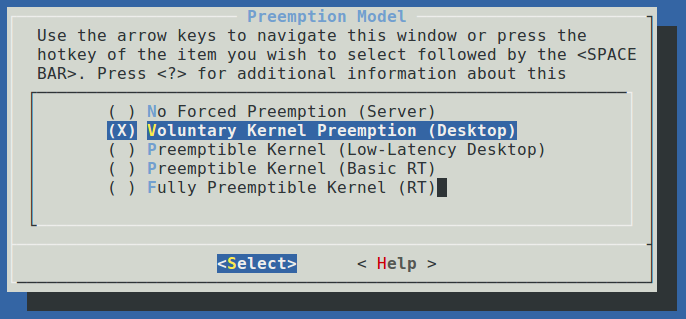
路径是Processor type and features--->Preemption Model,默认是Voluntary Kernel Preemption(Desktop)。
修改成Fully Preemptible Kernel(RT),即可切换到RT模式。
然后清空,在做编译。这里生成是和Ubuntu使用的.deb安装包。
make clean
make -j `getconf _NPROCESSORS_ONLN` deb-pkg LOCALVERSION=-custom
返回到上一级目录,安装生成的*.deb文件。
sudo dpkg -i *.deb
参考文档:《How to Build a Custom Kernel on Ubuntu》
2.2.2 kernel+RT patch编译
下载linux-4.4.138.tar.xz内核和对应的补丁patch-4.4.138-rt155.patch.gz。
tar xvf linux-4.4.138.tar.xz
或者
git clone https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
git checkout v4.4.138
然后打上补丁并修改menuconfig、编译RT内核。
cd linux-4.4.138/
zcat ../patch-4.4.138-rt155.patch.gz | patch -p1
cp /boot/config-4.4.0-116-generic .config
3. RT补丁分析
是使用Desktop和RT比较,还是使用Low Latency Desktop和RT比较呢?
因为大部分Ubuntu都默认使用Desktop模式,所以这里对比Desktop和RT两种模式。
使用linux-stable-rt.git之后,RT和非RT的区别就是Preemption Model的RT和Low Latency Desktop的区别了。
这里主要是一些内核选项的区别,大体分为以下几类。
| 分类 | RT配置 | Low Latency Desktop配置 | Desktop配置 |
| 抢占模式 |
CONFIG_PREEMPT=y CONFIG_PREEMPT_LAZY=y CONFIG_PREEMPT_RT_FULL=y |
CONFIG_PREEMPT=y CONFIG_PREEMPT__LL=y CONFIG_PREEMPT_COUNT=y |
CONFIG_PREEMPT_VOLUNTARY=y |
| RCU设置 | CONFIG_PREEMPT_RCU=y | CONFIG_PREEMPT_RCU=y | CONFIG_TREE_RCU=y |
| IO调度器 |
CONFIG_UNINLINE_SPIN_UNLOCK=y CONFIG_MUTEX_SPIN_ON_OWNER=y |
CONFIG_INLINE_SPIN_UNLOCK_IRQ=y CONFIG_MUTEX_SPIN_ON_OWNER=y |
|
| 辅助调试 |
CONFIG_DEBUG_PREEMPT=y CONFIG_PREEMPT_TRACER=y |
确保实时性的手段是,最小化禁止抢占。那么内核哪些模块禁止抢占呢?
首先就是中断相关的中断上下文,包括硬中断上下文和软中断上下文。
然后就是各种锁,包括spinlock、RCU、mutex等等。
下面就结合代码分析。
3.1 中断线程化
首先明确一点,中断上下文(包括硬中断上下文和软中断上下文)是不允许进程抢占的。
中断处理函数上半部运行于硬中断上下文中,此时硬中断被屏蔽。这也意味着抢占和软中断也被屏蔽。
内核命令行参数”threadirqs“可以将中断处理函数由硬中断上下文变成进程上下文,进程的调度策略是SCHED_FIFO并且优先级为50。
如果需要禁止对中断进行线程化,可以使用IRQF_NO_THREAD作为flag。
同时IRQF_TIMER类型的中断也隐式禁止了对中断进行线程化。
#define IRQF_NO_THREAD 0x00010000
#define IRQF_TIMER (__IRQF_TIMER | IRQF_NO_SUSPEND | IRQF_NO_THREAD)
struct irqaction数据结构是中断操作的描述符,下面分析在中断线程化之后对其影响。
struct irqaction { irq_handler_t handler;-----------------中断处理函数,在被强制线程化之后irq_setup_forced_threading()设置为指向irq_default_primary_handler()。 void *dev_id; void __percpu *percpu_dev_id; struct irqaction *next; irq_handler_t thread_fn;---------------原线程化函数指针在强制线程化环境下,被替换成irqaction->handler。 struct task_struct *thread;----------------中断线程化对应的线程指针。 struct irqaction *secondary;---------------如果原来中断就包含线程化函数,那么就需要设置secondary成员,irqaction->secondary->handler指向irq_forced_secondary_handler(),irqaction->secondary->thread_fn指向原irqaction->thread_fn。 unsigned int irq; unsigned int flags; unsigned long thread_flags; unsigned long thread_mask; const char *name; struct proc_dir_entry *dir; } ____cacheline_internodealigned_in_smp;
3.1.1 RT对force_irqthreads的改动
在没有定义CONFIG_PREEMPT_RT_BASE的情况下,可以通过命令行参数”threadirqs“打开force_irqthreads。
在打开CONFIG_PREEMPT_RT_BASE之后,force_irqthreads已经不是变量了,而是true。
#ifdef CONFIG_IRQ_FORCED_THREADING # ifndef CONFIG_PREEMPT_RT_BASE extern bool force_irqthreads; # else # define force_irqthreads (true)--------------------------------------在CONFIG_PREEMPT_RT_BASE打开情况下,直接为true。 # endif #else #define force_irqthreads (false) #endif #ifdef CONFIG_IRQ_FORCED_THREADING # ifndef CONFIG_PREEMPT_RT_BASE __read_mostly bool force_irqthreads; static int __init setup_forced_irqthreads(char *arg) { force_irqthreads = true; return 0; } early_param("threadirqs", setup_forced_irqthreads);-------------------------通过命令行threadirqs设置是否强制线程化。 # endif #endif
3.1.2 force_irqthreads对中断注册的影响
我们知道在打开CONFIG_PREEMPT_RT_BASE之后,多出了很多中断线程。
但是并没有对相关中断注册进行修改,下面简要分析一下过程。
例如不少中断都是通过request_irq()进行注册,并没有thread_fn。
从request_irq()->request_threaded_irq()->__setup_irq(),在__setup_irq()中对没有thread_fn的注册进行了处理。
static int __setup_irq(unsigned int irq, struct irq_desc *desc, struct irqaction *new) { struct irqaction *old, **old_ptr; unsigned long flags, thread_mask = 0; int ret, nested, shared = 0; cpumask_var_t mask; ... nested = irq_settings_is_nested_thread(desc); if (nested) { ... } else { if (irq_settings_can_thread(desc)) {-----------------------判断当前中断是否可以被线程化 ret = irq_setup_forced_threading(new);-----------------重新设置可以线程化中断的irqaction if (ret) goto out_mput; } } if (new->thread_fn && !nested) { ret = setup_irq_thread(new, irq, false);------------------注册中断线程 if (ret) goto out_mput; if (new->secondary) { ret = setup_irq_thread(new->secondary, irq, true); if (ret) goto out_thread; } } ... } static inline bool irq_settings_can_thread(struct irq_desc *desc) { return !(desc->status_use_accessors & _IRQ_NOTHREAD);---------------只要没有_IRQ_NOTHREAD都可以被线程化 } static int irq_setup_forced_threading(struct irqaction *new) { if (!force_irqthreads)----------------------------------------------这里是一个转折点,如果可以被强制线程化,继续往下走。 return 0; if (new->flags & (IRQF_NO_THREAD | IRQF_PERCPU | IRQF_ONESHOT))-----这3种标志位中断不允许被线程化。 return 0; new->flags |= IRQF_ONESHOT; /* * Handle the case where we have a real primary handler and a * thread handler. We force thread them as well by creating a * secondary action. */ if (new->handler != irq_default_primary_handler && new->thread_fn) {--------------传入了new->handler和new->thread_fn的情况,将new->thread_fn作为secondary->thread_fn。 /* Allocate the secondary action */ new->secondary = kzalloc(sizeof(struct irqaction), GFP_KERNEL); if (!new->secondary) return -ENOMEM; new->secondary->handler = irq_forced_secondary_handler; new->secondary->thread_fn = new->thread_fn; new->secondary->dev_id = new->dev_id; new->secondary->irq = new->irq; new->secondary->name = new->name; } /* Deal with the primary handler */ set_bit(IRQTF_FORCED_THREAD, &new->thread_flags); new->thread_fn = new->handler;----------------------------------------------------将传入的new->handler作为thread_fn new->handler = irq_default_primary_handler; return 0; }
从irq_setup_forced_threading()可知,这里强制将new->handler作为变成了中断线程函数thread_fn。
如果也定义了new->thread_fn,那么该中断将创建secondary对应线程。
硬中断上下文中执行的函数是irq_default_primary_handler(),这个函数什么也不做,只是简单的返回IRQ_WAKE_THREAD。
进行唤醒中断对应内核线程的动作。
irqreturn_t handle_irq_event_percpu(struct irq_desc *desc) { struct pt_regs *regs = get_irq_regs(); u64 ip = regs ? instruction_pointer(regs) : 0; irqreturn_t retval = IRQ_NONE; unsigned int flags = 0, irq = desc->irq_data.irq; struct irqaction *action = desc->action; /* action might have become NULL since we dropped the lock */ while (action) { irqreturn_t res; trace_irq_handler_entry(irq, action); res = action->handler(irq, action->dev_id);-------------------------对强制线程化的中断这里对应irq_default_primary_handler(),简单返回IRQ_WAKE_THREAD。 trace_irq_handler_exit(irq, action, res); switch (res) { case IRQ_WAKE_THREAD: if (unlikely(!action->thread_fn)) { warn_no_thread(irq, action); break; } __irq_wake_thread(desc, action);-------------------------------唤醒action->thread线程,即中断对应的内核线程。 /* Fall through to add to randomness */ case IRQ_HANDLED: flags |= action->flags; break; default: break; } retval |= res; action = action->next; } ... }
3.1.3 force_irqthreads对中断处理的影响
内核通过__setup_irq()进行中断注册配置,在打开force_irqthreads之后,中断线程处理函数变成irq_forced_thread_fn()。
static int setup_irq_thread(struct irqaction *new, unsigned int irq, bool secondary) { struct task_struct *t; struct sched_param param = { .sched_priority = MAX_USER_RT_PRIO/2, }; if (!secondary) { t = kthread_create(irq_thread, new, "irq/%d-%s", irq, new->name); } else { t = kthread_create(irq_thread, new, "irq/%d-s-%s", irq, new->name); param.sched_priority -= 1;---------------------------------------如果中断irqaction中secondary不为空,则创建的线程优先级要第一级。 } ... sched_setscheduler_nocheck(t, SCHED_FIFO, ¶m);-------------------中断线程调度策略SCHED_FIFO,优先级为50。 ... return 0; } static int irq_thread(void *data) { struct callback_head on_exit_work; struct irqaction *action = data; struct irq_desc *desc = irq_to_desc(action->irq); irqreturn_t (*handler_fn)(struct irq_desc *desc, struct irqaction *action); if (force_irqthreads && test_bit(IRQTF_FORCED_THREAD, &action->thread_flags))-------------------------------在irq_setup_forced_threading()设置了IRQTF_FORCED_THREAD,如果条件满足中断线程处理函数就为irq_forced_thread_fn()。 handler_fn = irq_forced_thread_fn; else handler_fn = irq_thread_fn; init_task_work(&on_exit_work, irq_thread_dtor); task_work_add(current, &on_exit_work, false); irq_thread_check_affinity(desc, action); while (!irq_wait_for_interrupt(action)) { irqreturn_t action_ret; irq_thread_check_affinity(desc, action); action_ret = handler_fn(desc, action); if (action_ret == IRQ_HANDLED) atomic_inc(&desc->threads_handled); if (action_ret == IRQ_WAKE_THREAD) irq_wake_secondary(desc, action);--------------------------唤醒secondary线程,处理第二级中断处理函数。 #ifdef CONFIG_PREEMPT_RT_FULL migrate_disable(); add_interrupt_randomness(action->irq, 0, desc->random_ip ^ (unsigned long) action); migrate_enable(); #endif wake_threads_waitq(desc); } /* * This is the regular exit path. __free_irq() is stopping the * thread via kthread_stop() after calling * synchronize_irq(). So neither IRQTF_RUNTHREAD nor the * oneshot mask bit can be set. We cannot verify that as we * cannot touch the oneshot mask at this point anymore as * __setup_irq() might have given out currents thread_mask * again. */ task_work_cancel(current, irq_thread_dtor); return 0; }
static irqreturn_t irq_forced_thread_fn(struct irq_desc *desc, struct irqaction *action) { irqreturn_t ret; local_bh_disable(); ret = action->thread_fn(action->irq, action->dev_id); irq_finalize_oneshot(desc, action); /* * Interrupts which have real time requirements can be set up * to avoid softirq processing in the thread handler. This is * safe as these interrupts do not raise soft interrupts. */ if (irq_settings_no_softirq_call(desc)) _local_bh_enable(); else local_bh_enable(); return ret; } static irqreturn_t irq_thread_fn(struct irq_desc *desc, struct irqaction *action) { irqreturn_t ret; ret = action->thread_fn(action->irq, action->dev_id); irq_finalize_oneshot(desc, action); return ret; }
中断处理上下文退出函数irq_exit()中有一个执行软中断的机会invoke_softirq()。
此时刚刚退出硬中断上下文,最大的区别在于invoke_softirq(),下面是进入软中断上下文还是进程上下文?
在没有CONFIG_PREEMPT_RT_FULL情况下,多调用__do_softirq()处理软中断,首先处于软中断上下文,还可能进入进程上下文。
如果定义了CONFIG_PREEMPT_RT_FULL,那么肯定进入了进程上下文。
static inline void invoke_softirq(void) { #ifndef CONFIG_PREEMPT_RT_FULL if (!force_irqthreads) { __do_softirq();--------------------------------------------这里面进行的处理和wakeup_softirqd()的区别就说明了RT是如何保证实时性的。 } else { wakeup_softirqd();-----------------------------------------直接唤醒进程进行处理。 } #else /* PREEMPT_RT_FULL */ unsigned long flags; local_irq_save(flags); if (__this_cpu_read(ksoftirqd) && __this_cpu_read(ksoftirqd)->softirqs_raised) wakeup_softirqd();-----------------------------------------直接唤醒进程进行处理。 if (__this_cpu_read(ktimer_softirqd) && __this_cpu_read(ktimer_softirqd)->softirqs_raised) wakeup_timer_softirqd(); local_irq_restore(flags); #endif }
__do_softirqd()是没有打开RT情况下处理软中断的接口。
首先进入软中断上下文进行处理,然后不停循环,满足下面任一条件则退出软中断上下文,将剩余工作交给线程进行处理。
- 软中断执行时间超过2jiffies
- 软中断循环超过9次
- 当前进程TIF_NEED_RESCHED置位
asmlinkage __visible void __do_softirq(void) { unsigned long end = jiffies + MAX_SOFTIRQ_TIME; unsigned long old_flags = current->flags; int max_restart = MAX_SOFTIRQ_RESTART; bool in_hardirq; __u32 pending; ... pending = local_softirq_pending(); account_irq_enter_time(current); __local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET);--------------------------------表示进入了软中断上下文。 in_hardirq = lockdep_softirq_start(); restart: /* Reset the pending bitmask before enabling irqs */ set_softirq_pending(0); handle_pending_softirqs(pending);-----------------------------------------------在禁止本地中断的情况下,开始执行软中断处理函数。 pending = local_softirq_pending(); if (pending) { if (time_before(jiffies, end) && !need_resched() && --max_restart) goto restart; wakeup_softirqd();----------------------------------------------------------在超时2jiffies、超次数10次、置位TIF_NEED_RESCHED情况下启动对应中断线程进行处理。 } lockdep_softirq_end(in_hardirq); account_irq_exit_time(current); __local_bh_enable(SOFTIRQ_OFFSET);----------------------------------------------退出软中断上下文。 WARN_ON_ONCE(in_interrupt()); tsk_restore_flags(current, old_flags, PF_MEMALLOC); }
可以看出__do_softirq()相对于wakeup_softirqd(),有不少时间处于软中断上下文。这部分时间是不允许进程进行抢占的。
3.1.4 中断线程化增加的内核线程
查看当前进程可以发现,多出了很多”irq/xx-xxxx“的线程。
这些内核线程是中断线程化的结果。
83 ? S 0:00 [irq/9-acpi]
113 ? S 0:00 [irq/123-aerdrv]
114 ? S 0:00 [irq/124-aerdrv]
115 ? S 0:00 [irq/122-PCIe PM]
116 ? S 0:00 [irq/123-PCIe PM]
117 ? S 0:00 [irq/124-PCIe PM]
131 ? S 0:00 [irq/125-xhci_hc]
132 ? S 0:00 [irq/1-i8042]
133 ? S 0:00 [irq/8-rtc0]
198 ? S 0:00 [irq/126-0000:00]
207 ? S 0:02 [irq/129-i915]
421 ? S 0:00 [irq/130-mei_me]
495 ? S 0:04 [irq/16-idma64.0]
529 ? S 0:06 [irq/16-i2c_desi]
530 ? S 0:02 [irq/82-ELAN0501]
...
539 ? S 0:00 [irq/131-ath10k_]
540 ? S 0:00 [irq/132-ath10k_]
541 ? S 0:05 [irq/133-ath10k_]
542 ? S 0:00 [irq/134-ath10k_]
543 ? S 0:00 [irq/135-ath10k_]
544 ? S 0:00 [irq/136-ath10k_]
545 ? S 0:00 [irq/137-ath10k_]
546 ? S 0:00 [irq/138-ath10k_]
579 ? S 0:00 [irq/139-snd_hda]
3.1.5 小结
可以看出中断线程化之后,原来上半部变成一个空函数,其任务被线程化;下半部软中断/tasklet也被强制线程化。最大限度的降低了禁止抢占的区域。
下面是中断线程化后相关线程流程:
- 中断线程创建点在setup_irq_thread(),对应的irqaction->thread和irqaction->secondary->thread都会被唤醒。
- 创建的线程名称为irq/xxx-xxx之类,不同的线程处理函数都是irq_thread(),不同之处在于入参void *data指向的struct irqaction->thread_fn(),这里对应的是irqaction->handler。
- 中断线程被唤醒后,会在睡眠点irq_wait_for_interrupt()等待中断去唤醒。
- 在中断到来进行处理时,__irq_wake_thread()唤醒睡眠的进程进行处理。
- 如果存在secondary,那么调用irq_wake_secondary()唤醒对应的线程。
3.2 RT对HR Timer的修改
HRTIMER_SOFTIRQ
posix_cpu_thread_init
timer_wait_for_callback
wait_for_running_timer
posix_cpu_thread_call
run_posix_cpu_timers
posix_cpu_timers_thread
run_hrtimer_softirq
hrtimer_rt_run_pending
hrtimer_rt_reprogram
3.3 RT对RCU的修改
RCU有三种
CONFIG_PREEMPT_RCU和CONFIG_TREE_RCU两者区别?
3.4 RT Mutex
RT Mutex的来历?Documentation/locking/rt-mutex.txt
如何设计?Documentation/locking/rt-mutex-design.txt
3.5 RT对spinlock的修改
spinlock是内核使用广泛的自旋锁,接口都在include/linux/spinlock.h中定义。
在打开了CONFIG_PREEMPT_RT_FULL之后,spinlock的大部分API都被替换了。
原来spin_xxx()调用raw_spin_xxx()变成了调用rt_spin_xxx()。rt_spin_xxx()函数又依赖于rt_mutex。
相应的读写锁,也进行了同样的替换
diff --git a/include/linux/spinlock.h b/include/linux/spinlock.h index 47dd0ce..02928fa 100644 --- a/include/linux/spinlock.h +++ b/include/linux/spinlock.h @@ -271,7 +271,11 @@ static inline void do_raw_spin_unlock(raw_spinlock_t *lock) __releases(lock) #define raw_spin_can_lock(lock) (!raw_spin_is_locked(lock)) /* Include rwlock functions */ -#include <linux/rwlock.h> +#ifdef CONFIG_PREEMPT_RT_FULL +# include <linux/rwlock_rt.h> +#else +# include <linux/rwlock.h> +#endif /* * Pull the _spin_*()/_read_*()/_write_*() functions/declarations: @@ -282,6 +286,10 @@ static inline void do_raw_spin_unlock(raw_spinlock_t *lock) __releases(lock) # include <linux/spinlock_api_up.h> #endif +#ifdef CONFIG_PREEMPT_RT_FULL +# include <linux/spinlock_rt.h> +#else /* PREEMPT_RT_FULL */ + /* * Map the spin_lock functions to the raw variants for PREEMPT_RT=n */ @@ -347,6 +355,12 @@ static __always_inline void spin_unlock(spinlock_t *lock) raw_spin_unlock(&lock->rlock); } +static __always_inline int spin_unlock_no_deboost(spinlock_t *lock) +{ + raw_spin_unlock(&lock->rlock); + return 0; +} + static __always_inline void spin_unlock_bh(spinlock_t *lock) { raw_spin_unlock_bh(&lock->rlock); @@ -416,4 +430,6 @@ extern int _atomic_dec_and_lock(atomic_t *atomic, spinlock_t *lock); #define atomic_dec_and_lock(atomic, lock) \ __cond_lock(lock, _atomic_dec_and_lock(atomic, lock)) +#endif /* !PREEMPT_RT_FULL */ + #endif /* __LINUX_SPINLOCK_H */
spinlock区分主要在include/linux/spinlock.h和include/linux/spinlock_rt.h中。
spin_lock()/spin_trylock()/spin_unlock()
spin_lock_irq()/spin_trylock_irq()/spin_unlock_irq()
spin_lock_bh()/spin_trylock_bh()/spin_unlock_bh()
读写锁区分主要在include/linux/rqlock.h和include/linux/rqlock_rt.h中。
read_lock()/read_trylock()/read_unlock()
write_lock()/write_trylock()/write_unlock()
read_lock_irqsave()/read_unlock_irqrestore()
write_lock_irqsave()/write_unlock_irqrestore()
3.6 RT throttling
由于RT进程使用实时调度策略并且优先级高于普通进程,如果RT应用出现问题可能导致整个系统挂死。
就像在一个进程中执行了"while(true){}"死循环,将其它所有进程阻塞,并且CPU占用率得到100%。
RT throttling就是解决这种现象的一种措施,通过限制RT进程执行的时间段,来保证留有一部分给普通进程使用。
对RT throttling的配置通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us两个节点配置。
RT进程占比 = sched_rt_runtime_us/sched_rt_period_us,,如果sched_rt_runtime_us置为-1,则禁止了RT throttling。
详细设置及解释参照:2.4.2 sysctl调节RT进程带宽及占比和4.3.1 sched_rt_period_us和sched_rt_runtime_us。
3.7 Priority Inheritance
优先级继承是解决优先级反转问题的一种方案。
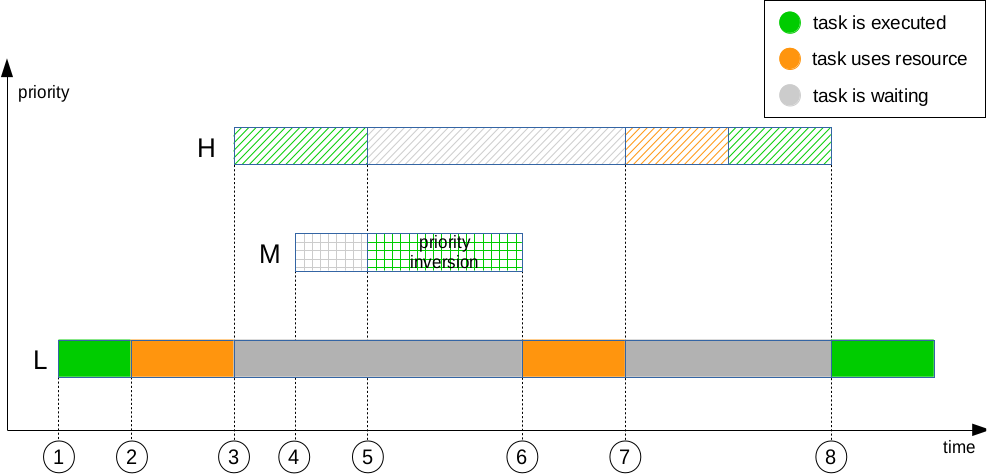
下面首先了解一下什么是优先级反转问题。
-
A task with low priority L becomes runnable and starts executing (1).
-
It acquires a mutually exclusive resource (2).
-
Now a task with a higher priority H becomes runnable and preempts L while L is holding the resource (3).
-
A third task M with priority between Hs and Ls priority (and with no need for the resource) becomes runnable, but it has to wait because H with higher priority is running (4).
-
H needs the resource still held by L (5), and so H stops running to wait until the resource is released.
-
The runnable task M prevents L from executing because of its higher priority. This leads to the priority inversion because H has to wait until M has finished (6) so that L can release the resource (7).
再来看看优先级继承是如何解决优先级反转问题的。
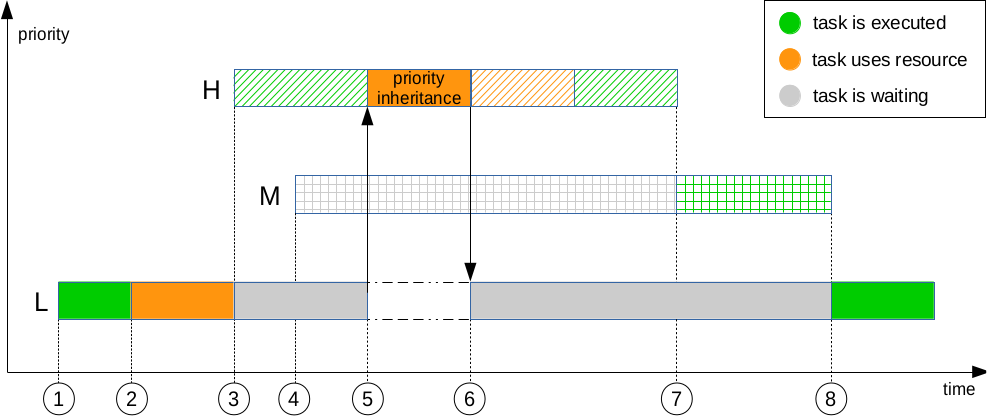
This means than when H needs the resource held by L, L inherits H's priority (5) in order to release the resource sooner (6). When M gets ready to run, M has to wait until the currently higher prioritized task L releases the resource and H finishes running (7).
优先级继承的一般方法是如果一个进程持有锁,那么他应该运行在所有持有锁进程的最高优先级,直到锁的释放。
也就是说,在锁的存活期间,所有低于最高优先级的持锁进程短暂的提高优先级。
参考文档:《Priority inheritance in the kernel》
3.8 实际进程的调度策略和优先级
实时调度策略有三种:SCHED_FIFO/SCHED_RR和SCHED_DEADLINE。
《Linux进程管理 (9)实时调度类分析,以及FIFO和RR对比实验》和《Linux进程管理 (10) Deadline调度策略分析》分别介绍了FIFO/RR和DEADLINE三种调度策略。
4. RT性能评估
RT:Benchmarks介绍了一系列适用于RT测试的工具集。
4.1 rt-tests
sudo apt-get install build-essential libnuma-dev
RT-Tests包含了一系列用于测试Linux实时功能的工具包,源代码可以从这里下载。
git clone https://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git
在ARM平台上使用这些工具需要交叉编译,对Makefile进行修改。
diff --git a/Makefile b/Makefile
index 569adc1..08e7508 100644
--- a/Makefile
+++ b/Makefile
@@ -1,6 +1,6 @@
VERSION = 1.0
-CC?=$(CROSS_COMPILE)gcc
-AR?=$(CROSS_COMPILE)ar
+CC = arm-linux-gnueabi-gcc
+AR = arm-linux-gnueabi-ar
OBJDIR = bld
cyclictest
sudo cyclictest -p 80 -t 8 -q -l 40000
RT结果如下:
# /dev/cpu_dma_latency set to 0us
T: 0 ( 4519) P:80 I:1000 C: 40000 Min: 1 Act: 1 Avg: 1 Max: 87
T: 1 ( 4520) P:80 I:1500 C: 26680 Min: 1 Act: 1 Avg: 1 Max: 55
T: 2 ( 4521) P:80 I:2000 C: 20010 Min: 1 Act: 1 Avg: 1 Max: 69
T: 3 ( 4522) P:80 I:2500 C: 16008 Min: 1 Act: 2 Avg: 1 Max: 81
T: 4 ( 4523) P:80 I:3000 C: 13340 Min: 1 Act: 2 Avg: 1 Max: 37
T: 5 ( 4524) P:80 I:3500 C: 11435 Min: 1 Act: 2 Avg: 1 Max: 52
T: 6 ( 4525) P:80 I:4000 C: 10005 Min: 1 Act: 1 Avg: 1 Max: 21
T: 7 ( 4526) P:80 I:4500 C: 8894 Min: 1 Act: 2 Avg: 1 Max: 90
Desktop结果如下:
T: 0 ( 2701) P:80 I:1000 C: 40000 Min: 1 Act: 1 Avg: 1 Max: 129
T: 1 ( 2702) P:80 I:1500 C: 26679 Min: 1 Act: 1 Avg: 1 Max: 161
T: 2 ( 2703) P:80 I:2000 C: 20010 Min: 1 Act: 1 Avg: 1 Max: 130
T: 3 ( 2704) P:80 I:2500 C: 16008 Min: 1 Act: 1 Avg: 1 Max: 218
T: 4 ( 2705) P:80 I:3000 C: 13340 Min: 1 Act: 1 Avg: 1 Max: 116
T: 5 ( 2706) P:80 I:3500 C: 11434 Min: 1 Act: 1 Avg: 1 Max: 93
T: 6 ( 2707) P:80 I:4000 C: 10005 Min: 1 Act: 1 Avg: 1 Max: 121
T: 7 ( 2708) P:80 I:4500 C: 8893 Min: 1 Act: 1 Avg: 1 Max: 125
hackbench
hwlatdetect
pip_stress
pi_stress
pmqtest
需要打开CONFIG_POSIX_MQUEUE。
ptsematest
rt-migrate-test
sendme
signaltest
sigwaittest
svsematest
cyclicdeadline
deadline_test
queuelat
4.2 LTP
LTP(Linux Test Project)是一套验证Linux可靠性、鲁棒性、稳定性的测试集。
LTP包含一系列测试,和realtime相关的测试位于realtime,其使用方法参考这里。
git clone https://github.com/linux-test-project/ltp.git
5. 参考资料
《Linux RT(1)-硬实时Linux(RT-Preempt Patch)在PC上的编译、使用和测试》


 浙公网安备 33010602011771号
浙公网安备 33010602011771号