RK3588+Deepseek(1):开发环境搭建、模型转换、推理程序编译以及模型运行测试
1 开发环境搭建
1.1 下载安装miniconda
进入miniconda下载页面下载x86版本:Miniconda3-latest-Linux-x86_64.sh。
执行./Miniconda3-latest-Linux-x86_64.sh安装Miniconda3:
1.2 安装rkllm_toolkit
执行conda create -n rkllm python=3.8创建RKLLM虚拟环境:
激活rkllm环境:conda activate rkllm。
安装whl安装rkllm_toolkit及其依赖文件,组成开发环境:
pip install rkllm_toolkit-1.1.4-cp38-cp38-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
2 模型转换
生成量化校准数据模型的过程是由预训练模型根据提供的问题给出标准参考答案;然后在模型量化过程中根据问题和标准版参考答案进行动态范围校准;精度验证;量化感知训练。
模型转换时对模型进行量化优化,并转换为RKNNP适配模型。
2.1 生成量化校准数据
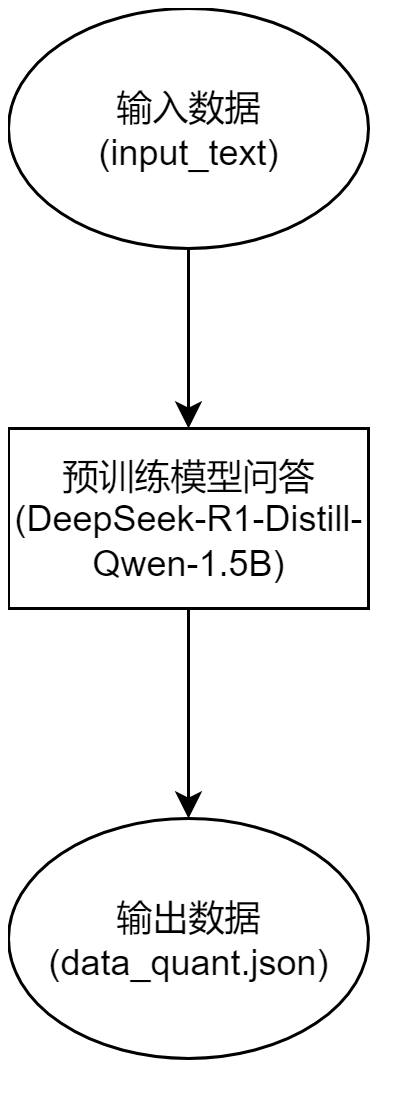
相关Python库如下:
- AutoTokenizer负责将文本转换为模型可以接受的格式。
- AutoModelForCausalLM负责加载支持因果语言建模的预训练模型,用于生成任务。
- PyTorch是一个功能强大的深度学习框架,支持张量操作、自动求导、神经网络构建等功能。
下面功能包括:
- 模型加载与配置:从HuggingFace Hub加载预训练语言模型和分词器,自动选择CPU/GPU设备。
- 校准数据生成:通过预定义的输入样本集(input_text)生成模型输出结果,用于后续的量化校准。
- 对话模板处理:支持将原始输入转换为标准对话格式(当apply_chat_template=True时)。
- 生成控制参数:通过temperature/repetition_penalty等参数控制生成结果的多样性和质量。
- 异常容错机制:在生成失败时记录空结果,保证校准数据收集过程不中断。
- 数据持久化:最终生成包含输入输出对的JSON文件。
from transformers import AutoTokenizer, AutoModelForCausalLM import torch--PyTorch深度学习框架。 import argparse import json ap = argparse.ArgumentParser() ap.add_argument("-m", "--model-dir", help="Path to model directory cloned from HF Hub")--指定HuggingFace模型路径。 ap.add_argument("-o", "--output-file", help="Path to save calibration file", default='./data_quant.json')--量化校准数据保存路径。 ap.add_argument('--apply_chat_template', help="Whether to use the chat template or not.", default=True)--是否应用对话模板。 ap.add_argument('--max_new_tokens', default=128)--控制生成文本最大Token长度。 ap.add_argument('--temperature', default=0.6)--控制生成随机性 (0=确定,1=随机)。 ap.add_argument('--repetition_penalty', default=1.1)--重复惩罚系数 (>1减少重复)。 args = ap.parse_args() if __name__ == '__main__': if not torch.cuda.is_available():--检查CUDA是否可用。 dev = 'cpu' else: dev = 'cuda' tokenizer = AutoTokenizer.from_pretrained(args.model_dir, trust_remote_code=True)--加载model_dir对应的分词器。 model = AutoModelForCausalLM.from_pretrained(args.model_dir, trust_remote_code=True)--加载model_dir对应的预训练语言模型。 model = model.to(dev)--将模型的参数和缓冲区移动到指定设备,GPU或CPU,确保在正确硬件上运行。 model = model.eval()--将模型切换到评估模式,主要用于推理阶段。 ## 请根据模型特点与使用场景准备用于量化的校准样本。 input_text = [--包含多领域样本:选择题/数学题/代码/翻译/诗歌创作等。 '在农业生产中被当作极其重要的劳动对象发挥作用,最主要的不可替代的基本生产资料是\nA. 农业生产工具\nB. 土地\nC. 劳动力\nD. 资金', '下列行为如满足规定条件,应认定为伪造货币罪的是\nA. 将英镑揭层一分为二\nB. 铸造珍稀古钱币\nC. 临摹欧元收藏\nD. 用黄金铸造流通的纪念金币', '设是 $f(x)$ 偶函数, $\varphi(x)$ 是奇函数, 则下列函数(假设都有意义)中是奇函数的是 ( ).\nA. $f[f(x)]$\nB. $\varphi[\varphi(x)]$\nC. $\varphi[f(x)]$\nD. $f[\varphi(x)]$', 'def fizz_buzz(n: int): """Return the number of times the digit 7 appears in integers less than n which are divisible by 11 or 13. >>> fizz_buzz(50) 0 >>> fizz_buzz(78) 2 >>> fizz_buzz(79) 3 """' '已知 ${ }_s p_{10}=0.4$, 且 $\mu_x=0.01+b x, x \geqslant 0$, 则 $b$ 等于 $(\quad$ 。\nA. -0.05\nB. -0.014\nC. -0.005\nD. 0.014', "Imagine you are participating in a race with a group of people. If you have just overtaken the second person, what's your current position? Where is the person you just overtook?", "你是一个手机内负责日程管理的智能助手,你要基于用户给定的目标日程信息,综合考虑日程库的行程,联想一些可以体现人文关怀,实用,并且可以给用户带来惊喜的子日程提醒。", "给定以下Python代码,请改写它,使用列表解析来完成相同的功能。\n\nsquares = []\n\nfor i in range(10): \n\n squares.append(i**2)\n\nprint(squares)", "Some people got on a bus at the terminal. At the first bus stop, half of the people got down and 4 more people got in. Then at the second bus stop, 6 people got down and 8 more got in. If there were a total of 25 people heading to the third stop, how many people got on the bus at the terminal?", "下列句子中存在歧义的一句是()A:上级要求我们按时完成任务B:老师满意地朝他看了一眼C:我看见你那年才十岁D:她的一句话说得大家都笑了", "What is the coefficient of $x^2y^6$ in the expansion of $\left(\frac{3}{5}x-\frac{y}{2}\right)^8$? Express your answer as a common fraction.", "I love Woudenberg Koffiemok Trots op Goedkoop I love Woudenberg Koffiemok Trots op Een te gekke koffiemok die je niet mag missen als je in Woudenberg woont. Productcode: 29979 - bbweb", "Aussie Speedo Guy is a Bisexual Aussie Guy who loves speedos. » Indoor Pool TwinksAussieSpeedoGuy.org: AussieSpeedoGuy.org Members Blog No User Responded in \" Indoor Pool Twinks \"", "在城市夜晚的霓虹灯下,车水马龙,您能为此创作七言绝句吗?关键词:夜晚,霓虹。", "以下是关于经济学的单项选择题,请从A、B、C、D中选择正确答案对应的选项。\n题目:当长期均衡时,完全竞争企业总是\nA. 经济利润大于零\nB. 正常利润为零\nC. 经济利润小于零\nD. 经济利润为零\n答案是: ", '下列句中,“是”充当前置宾语的一句是\nA. 如有不由此者,在執者去,衆以焉殃,是謂小康。\nB. 子曰:敏而好學,不下恥問,是以謂之文也。\nC. 是乃其所以千萬臣而無數者也。\nD. 鑄名器,藏寶財,固民之殄病是待。', 'def is_multiply_prime(a): """Write a function that returns true if the given number is the multiplication of 3 prime numbers and false otherwise. Knowing that (a) is less then 100. Example: is_multiply_prime(30) == True 30 = 2 * 3 * 5 """', "What is the theory of general relativity?\n General relativity is a theory of gravitation developed by Albert Einstein. It describes gravity not as a force, but as a curvature of spacetime caused by mass and energy.", "Human: 请提取以下句子中的关健词信息,用JSON返回:句子:'我现在想感受一下不同的文化背景,看一部外国喜剧电影。'。", '《坛经》,是历史上除佛经外,唯一被尊称为“经”的佛教典籍。此书作者是\nA. 六祖慧能\nB. 南天竺菩提达摩\nC. 释迦牟尼\nD. 五祖宏忍', "把这句话翻译成英文: RK3588是新一代高端处理器,具有高算力、低功耗、超强多媒体、丰富数据接口等特点", "把这句话翻译成中文: Knowledge can be acquired from many sources. These include books, teachers and practical experience, and each has its own advantages. The knowledge we gain from books and formal education enables us to learn about things that we have no opportunity to experience in daily life. We can also develop our analytical skills and learn how to view and interpret the world around us in different ways." ] gen_kwargs = {"max_new_tokens": args.max_new_tokens, "top_k":1, "temperature": args.temperature, "do_sample": True, "repetition_penalty": args.repetition_penalty}--max_new_tokens限制生成长度避免内存溢出;top_k贪婪搜索(每次选最高概率token);temperature较低温度使输出更确定;do_sample启用采样模式;repetition_penalty抑制重复内容生成。 calidata = [] for idx, inp in enumerate(input_text):--遍历校准标本。 question = inp.strip() if args.apply_chat_template: datas = [{"role":"user","content":question}] messages = tokenizer.apply_chat_template(datas, tokenize=False, add_generation_prompt=True, return_tensors="pt") else: messages = f"{question}" try: inputs = tokenizer(messages, return_tensors='pt').to(dev)--使用分词器将文本转换为模型可以接受的格式,pt表示返回的张亮类型为PyTorch张量。 outputs = model.generate(**inputs, **gen_kwargs)--使用预训练模型(比如DeepSeek-R1-Distill-Qwen-1.5B)生成文本,outputs是一个张量,包含生成的token IDs。 result = tokenizer.decode(outputs[0], skip_special_tokens=True)--将生成的token IDs解码为文本。
print(result, len(result)) calidata.append({"input":messages, "target":result[len(messages):]})--input为原始问题,target为答复内容。 except: calidata.append({"input":messages, "target":''}) with open(args.output_file, 'w') as f: json.dump(calidata, f)
对模型进行量化:
python3 generate_data_quant.py -m deepseek_1.5b
结果如下:
python3 generate_data_quant.py -m deepseek_1.5b Setting `pad_token_id` to `eos_token_id`:None for open-end generation. Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32) <|User|>在农业生产中被当作极其重要的劳动对象发挥作用,最主要的不可替代的基本生产资料是 A. 农业生产工具 B. 土地 C. 劳动力 D. 资金<|Assistant|><think> 嗯,我现在要解决这个问题:在农业生产中被当作极其重要的劳动对象发挥作用,最主要的不可替代的基本生产资料是什么?选项有四个:A. 农业生产工具,B. 土地,C. 劳动力,D. 资金。 首先,我需要理解题目中的问题。题目问的是“主要不可替代的基本生产资料”。这意味着我要找出在农业生产中,哪个因素是最重要的,无法完全替代的资源或要素。 我记得农业生产的各个环节都有不同的基本生产资料。比如,土地是基础,因为它是种植作物、蔬菜等的基础。然后是劳动力 320 Setting `pad_token_id` to `eos_token_id`:None for open-end generation. ... <|User|>《坛经》,是历史上除佛经外,唯一被尊称为“经”的佛教典籍。此书作者是 A. 六祖慧能 B. 南天竺菩提达摩 C. 释迦牟尼 D. 五祖宏忍<|Assistant|><think> 嗯,我现在要回答这个问题:“《坛经》,是历史上除佛经外,唯一被尊称为‘经’的佛教典籍。此书作者是谁?”选项有四个:A. 六祖慧能,B. 南天竺菩提达摩,C. 释迦牟尼,D. 五祖宏忍。 首先,我需要明确什么是《坛经》。根据我的了解,《坛经》是中国古代的一部经典,通常被认为是佛教的经典之一。它不是佛经,而是其他一些宗教或文化中的经文。因此,问题中提到它是“唯一 279 Setting `pad_token_id` to `eos_token_id`:None for open-end generation. <|User|>把这句话翻译成英文: RK3588是新一代高端处理器,具有高算力、低功耗、超强多媒体、丰富数据接口等特点<|Assistant|><think> 嗯,用户让我把一句中文句子翻译成英文。原句是:“RK3588是新一代高端处理器,具有高算力、低功耗、超强多媒体、丰富数据接口等特点”。首先,我需要理解每个部分的意思。 “RK3588”看起来像是处理器型号,所以要准确翻译成“RK-3588”比较合适。“新一代高端处理器”可以译为“high-end processor of high generation”,这样既保留了原意,又符合技术术语的表达方式。 接下来,“具有高算力、低功耗、超强多媒体、丰富数据 310 Setting `pad_token_id` to `eos_token_id`:None for open-end generation. <|User|>把这句话翻译成中文: Knowledge can be acquired from many sources. These include books, teachers and practical experience, and each has its own advantages. The knowledge we gain from books and formal education enables us to learn about things that we have no opportunity to experience in daily life. We can also develop our analytical skills and learn how to view and interpret the world around us in different ways.<|Assistant|><think> 嗯,用户给了一个英文句子,让我翻译成中文。首先,我需要仔细阅读原文,理解其意思。原文讲的是知识可以从多种渠道获得,包括书籍、老师和实际经验,每种方式都有自己的优势。然后,通过学习书籍和正式教育,我们可以了解我们日常生活中没有机会体验的东西。同时,还能培养分析能力,学会从不同角度看待世界。 接下来,我要考虑如何准确传达这些信息。第一句“Knowledge can be acquired from many sources.”可以译为“知识可以从多种渠道获取。”这里“sources”对应“来源”,“acquired”是 695
最初输出data_quant.json数据,此文件主要用于以下场景:
- 模型量化校准(Quantization Calibration)
- 动态范围估计:通过输入样本激活模型各层,统计权重和激活值的分布范围,用于后续的 INT8/FP16 量化。
- 精度校准:量化过程中需要校准数据来最小化精度损失(如 GPTQ、AWQ 等量化算法)。
- 生成质量验证
- 对比量化前后的生成结果,验证量化是否导致性能下降。
- 分析模型在不同输入类型(如代码、数学题、翻译)下的响应一致性。
- 对话系统调试
- 检查对话模板(apply_chat_template)是否正确处理用户输入。
- 验证生成参数(temperature, repetition_penalty)的配置效果。
2.2 模型量化优化和转换
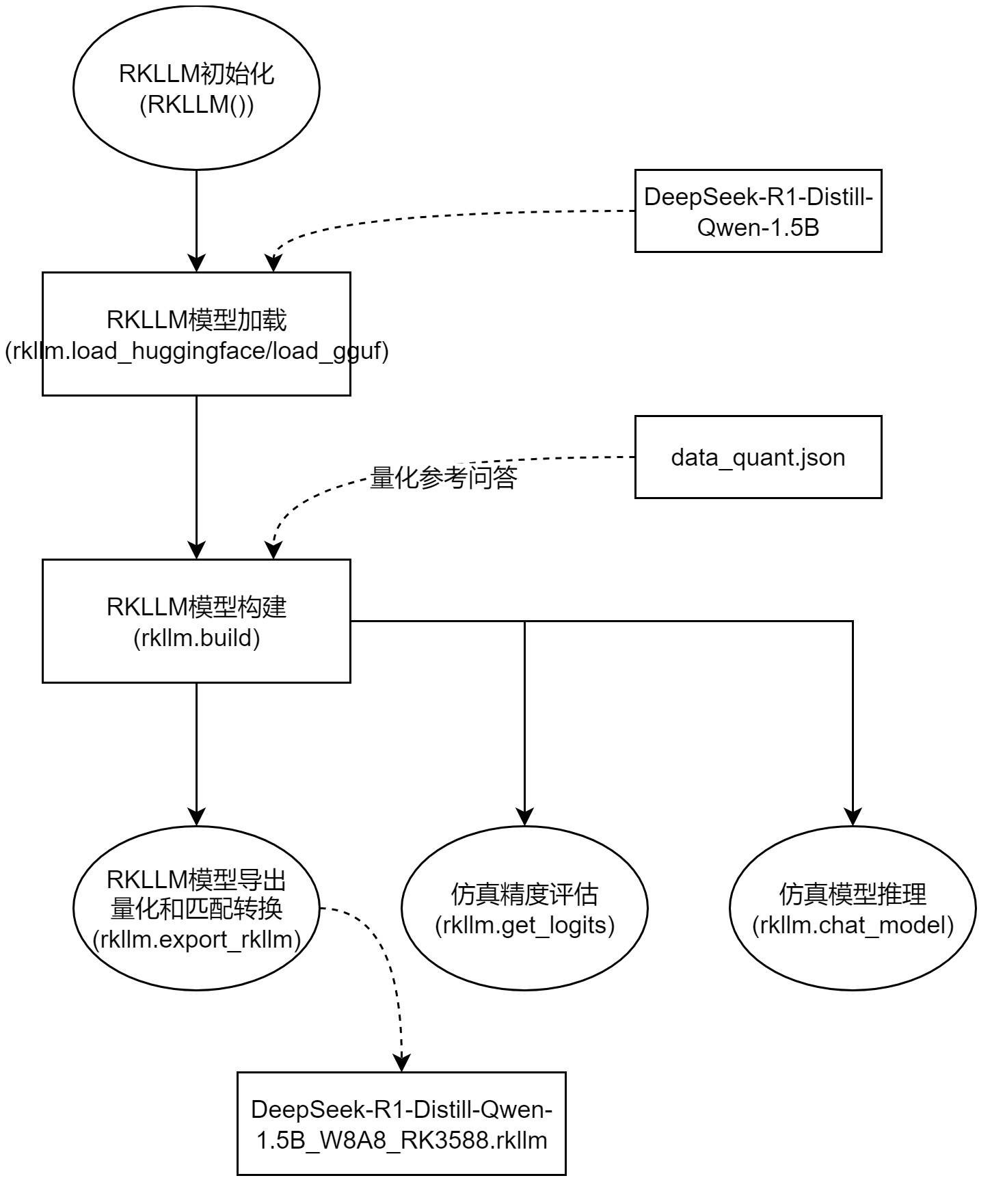
export_rkllm.py进行模型转换:
- 模型加载和初始化。
- 模型量化优化:压缩模型体积、降低计算资源需求、实现边缘设备低功耗高性能推理。
- 模型导出:硬件指令集优化(利用NPU重构计算图)、内存布局调整(减少数据搬运开销)、算子融合。
from rkllm.api import RKLLM import os os.environ['CUDA_VISIBLE_DEVICES']='0' ''' https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B Download the DeepSeek R1 model from the above url. ''' modelpath = '/path/to/DeepSeek-R1-Distill-Qwen-1.5B' llm = RKLLM() # Load model # Use 'export CUDA_VISIBLE_DEVICES=0' to specify GPU device # options ['cpu', 'cuda'] ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cuda')--加载Hugging Face模型,指定设备为GPU。 # ret = llm.load_gguf(model = modelpath) if ret != 0: print('Load model failed!') exit(ret) # Build model dataset = "./data_quant.json"--校准数据文件路径,用于量化优化。 # Json file format, please note to add prompt in the input,like this: # [{"input":"Human: 你好!\nAssistant: ", "target": "你好!我是人工智能助手KK!"},...] qparams = None # Use extra_qparams target_platform = "RK3588" optimization_level = 1 quantized_dtype = "W8A8"--量化后的数据类型,W8A8表示8位权重和8位激活。 quantized_algorithm = "normal" num_npu_core = 3 ret = llm.build(do_quantization=True, optimization_level=optimization_level, quantized_dtype=quantized_dtype, quantized_algorithm=quantized_algorithm, target_platform=target_platform, num_npu_core=num_npu_core, extra_qparams=qparams, dataset=dataset)--对模型进行量化优化,并转换为RKNNP适配模型。 if ret != 0: print('Build model failed!') exit(ret) # Export rkllm model ret = llm.export_rkllm(f"./{os.path.basename(modelpath)}_{quantized_dtype}_{target_platform}.rkllm")--将量化后的模型导出为.rkllm格式。 if ret != 0: print('Export model failed!') exit(ret)
进行模型转换:
python3 export_rkllm.py
转换结果如下:
INFO: rkllm-toolkit version: 1.1.4 WARNING: Cuda device not available! switch to cpu device! The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is ignored. Downloading data files: 100%|███████████████████████| 1/1 [00:00<00:00, 78.34it/s] Extracting data files: 100%|████████████████████████| 1/1 [00:00<00:00, 4.18it/s] Generating train split: 21 examples [00:00, 45.06 examples/s] Optimizing model: 18%|█████ | 5/28 [07:12<32:28, 84.72s/it]Optimizing model: 100%|███████████████████████████| 28/28 [39:58<00:00, 85.68s/it] Building model: 100%|███████████████████████████| 399/399 [00:19<00:00, 20.71it/s] WARNING: The bos token has two ids: 151646 and 151643, please ensure that the bos token ids in config.json and tokenizer_config.json are consistent! INFO: The token_id of bos is set to 151646 INFO: The token_id of eos is set to 151643 INFO: The token_id of pad is set to 151643 Converting model: 100%|████████████████████| 339/339 [00:00<00:00, 1267262.97it/s] INFO: Exporting the model, please wait .... [=================================================>] 597/597 (100%) INFO: Model has been saved to ./deepseek_1.5b_W8A8_RK3588.rkllm!
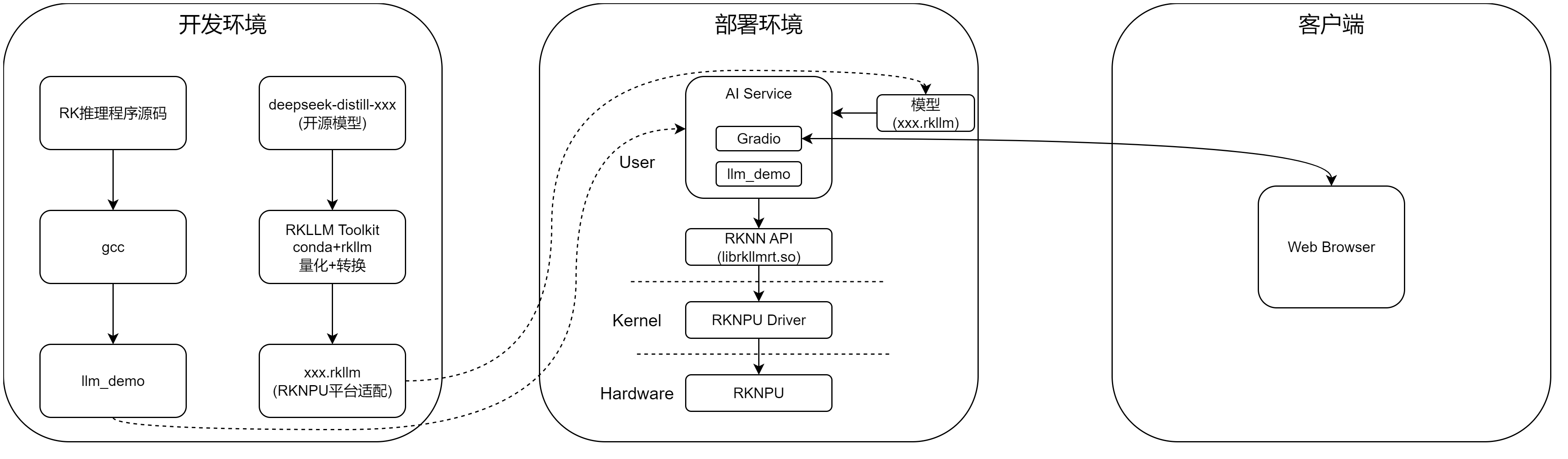
3 推理程序
llm_demo源码如下,核心在封装的librkllmrt.so中:
// Copyright (c) 2024 by Rockchip Electronics Co., Ltd. All Rights Reserved. // // Licensed under the Apache License, Version 2.0 (the "License"); // you may not use this file except in compliance with the License. // You may obtain a copy of the License at // // http://www.apache.org/licenses/LICENSE-2.0 // // Unless required by applicable law or agreed to in writing, software // distributed under the License is distributed on an "AS IS" BASIS, // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. // See the License for the specific language governing permissions and // limitations under the License. #include <string.h> #include <unistd.h> #include <string> #include "rkllm.h" #include <fstream> #include <iostream> #include <csignal> #include <vector> #define PROMPT_TEXT_PREFIX "<|begin▁of▁sentence|><|User|>" #define PROMPT_TEXT_POSTFIX "<|Assistant|>" using namespace std; LLMHandle llmHandle = nullptr; void exit_handler(int signal) { if (llmHandle != nullptr) { { cout << "程序即将退出" << endl; LLMHandle _tmp = llmHandle; llmHandle = nullptr; rkllm_destroy(_tmp); } } exit(signal); } void callback(RKLLMResult *result, void *userdata, LLMCallState state) { if (state == RKLLM_RUN_FINISH) { printf("\n"); } else if (state == RKLLM_RUN_ERROR) { printf("\\run error\n"); } else if (state == RKLLM_RUN_GET_LAST_HIDDEN_LAYER) { /* ================================================================================================================ 若使用GET_LAST_HIDDEN_LAYER功能,callback接口会回传内存指针:last_hidden_layer,token数量:num_tokens与隐藏层大小:embd_size 通过这三个参数可以取得last_hidden_layer中的数据 注:需要在当前callback中获取,若未及时获取,下一次callback会将该指针释放 ===============================================================================================================*/ if (result->last_hidden_layer.embd_size != 0 && result->last_hidden_layer.num_tokens != 0) { int data_size = result->last_hidden_layer.embd_size * result->last_hidden_layer.num_tokens * sizeof(float); printf("\ndata_size:%d",data_size); std::ofstream outFile("last_hidden_layer.bin", std::ios::binary); if (outFile.is_open()) { outFile.write(reinterpret_cast<const char*>(result->last_hidden_layer.hidden_states), data_size); outFile.close(); std::cout << "Data saved to output.bin successfully!" << std::endl; } else { std::cerr << "Failed to open the file for writing!" << std::endl; } } } else if (state == RKLLM_RUN_NORMAL) { printf("%s", result->text); } } int main(int argc, char **argv) { if (argc < 4) { std::cerr << "Usage: " << argv[0] << " model_path max_new_tokens max_context_len\n"; return 1; } signal(SIGINT, exit_handler); printf("rkllm init start\n"); //设置参数及初始化 RKLLMParam param = rkllm_createDefaultParam(); param.model_path = argv[1]; //设置采样参数 param.top_k = 1; param.top_p = 0.95; param.temperature = 0.8; param.repeat_penalty = 1.1; param.frequency_penalty = 0.0; param.presence_penalty = 0.0; param.max_new_tokens = std::atoi(argv[2]); param.max_context_len = std::atoi(argv[3]); param.skip_special_token = true; param.extend_param.base_domain_id = 0; int ret = rkllm_init(&llmHandle, ¶m, callback); if (ret == 0){ printf("rkllm init success\n"); } else { printf("rkllm init failed\n"); exit_handler(-1); } vector<string> pre_input; pre_input.push_back("现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,求鸡和兔子各有多少只?"); pre_input.push_back("有28位小朋友排成一行,从左边开始数第10位是学豆,从右边开始数他是第几位?"); cout << "\n**********************可输入以下问题对应序号获取回答/或自定义输入********************\n" << endl; for (int i = 0; i < (int)pre_input.size(); i++) { cout << "[" << i << "] " << pre_input[i] << endl; } cout << "\n*************************************************************************\n" << endl; string text; RKLLMInput rkllm_input; // 初始化 infer 参数结构体 RKLLMInferParam rkllm_infer_params; memset(&rkllm_infer_params, 0, sizeof(RKLLMInferParam)); // 将所有内容初始化为 0 // 1. 初始化并设置 LoRA 参数(如果需要使用 LoRA) // RKLLMLoraAdapter lora_adapter; // memset(&lora_adapter, 0, sizeof(RKLLMLoraAdapter)); // lora_adapter.lora_adapter_path = "qwen0.5b_fp16_lora.rkllm"; // lora_adapter.lora_adapter_name = "test"; // lora_adapter.scale = 1.0; // ret = rkllm_load_lora(llmHandle, &lora_adapter); // if (ret != 0) { // printf("\nload lora failed\n"); // } // 加载第二个lora // lora_adapter.lora_adapter_path = "Qwen2-0.5B-Instruct-all-rank8-F16-LoRA.gguf"; // lora_adapter.lora_adapter_name = "knowledge_old"; // lora_adapter.scale = 1.0; // ret = rkllm_load_lora(llmHandle, &lora_adapter); // if (ret != 0) { // printf("\nload lora failed\n"); // } // RKLLMLoraParam lora_params; // lora_params.lora_adapter_name = "test"; // 指定用于推理的 lora 名称 // rkllm_infer_params.lora_params = &lora_params; // 2. 初始化并设置 Prompt Cache 参数(如果需要使用 prompt cache) // RKLLMPromptCacheParam prompt_cache_params; // prompt_cache_params.save_prompt_cache = true; // 是否保存 prompt cache // prompt_cache_params.prompt_cache_path = "./prompt_cache.bin"; // 若需要保存prompt cache, 指定 cache 文件路径 // rkllm_infer_params.prompt_cache_params = &prompt_cache_params; // rkllm_load_prompt_cache(llmHandle, "./prompt_cache.bin"); // 加载缓存的cache rkllm_infer_params.mode = RKLLM_INFER_GENERATE; while (true) { std::string input_str; printf("\n"); printf("user: "); std::getline(std::cin, input_str); if (input_str == "exit") { break; } for (int i = 0; i < (int)pre_input.size(); i++) { if (input_str == to_string(i)) { input_str = pre_input[i]; cout << input_str << endl; } } text = PROMPT_TEXT_PREFIX + input_str + PROMPT_TEXT_POSTFIX; // text = input_str; rkllm_input.input_type = RKLLM_INPUT_PROMPT; rkllm_input.prompt_input = (char *)text.c_str(); printf("robot: "); // 若要使用普通推理功能,则配置rkllm_infer_mode为RKLLM_INFER_GENERATE或不配置参数 rkllm_run(llmHandle, &rkllm_input, &rkllm_infer_params, NULL); } rkllm_destroy(llmHandle); return 0; }
llm_demo实例如下:
- 核心实现在librkllmrt.so中。
- 通过打开RKNPU相关的DRM设备进行命令执行和数据搬运。
COMMAND PID PGID USER FD TYPE DEVICE SIZE/OFF NODE NAME llm_demo 16806 16806 root cwd DIR 179,6 4096 389409 /root/localbuild-llm_demo llm_demo 16806 16806 root rtd DIR 179,6 4096 2 / llm_demo 16806 16806 root txt REG 179,6 53976 389548 /root/localbuild-llm_demo/llm_demo llm_demo 16806 16806 root mem CHR 226,1 218 /dev/dri/card1 llm_demo 16806 16806 root mem REG 179,6 6152 4510 /usr/lib/aarch64-linux-gnu/libdl.so.2 llm_demo 16806 16806 root mem REG 179,6 13752 4530 /usr/lib/aarch64-linux-gnu/libpthread.so.0 llm_demo 16806 16806 root mem REG 179,6 278024 25555 /usr/lib/aarch64-linux-gnu/libgomp.so.1.0.0 llm_demo 16806 16806 root mem REG 179,6 1637400 4508 /usr/lib/aarch64-linux-gnu/libc.so.6 llm_demo 16806 16806 root mem REG 179,6 84296 25471 /usr/lib/aarch64-linux-gnu/libgcc_s.so.1 llm_demo 16806 16806 root mem REG 179,6 551064 4511 /usr/lib/aarch64-linux-gnu/libm.so.6 llm_demo 16806 16806 root mem REG 179,6 2190752 26423 /usr/lib/aarch64-linux-gnu/libstdc++.so.6.0.30 llm_demo 16806 16806 root mem REG 179,6 6239192 648989 /usr/lib/librkllmrt.so llm_demo 16806 16806 root mem REG 179,6 187776 4504 /usr/lib/aarch64-linux-gnu/ld-linux-aarch64.so.1 llm_demo 16806 16806 root 0u CHR 136,0 0t0 3 /dev/pts/0 llm_demo 16806 16806 root 1u CHR 136,0 0t0 3 /dev/pts/0 llm_demo 16806 16806 root 2u CHR 136,0 0t0 3 /dev/pts/0 llm_demo 16806 16806 root 3u CHR 226,1 0t0 218 /dev/dri/card1 llm_demo 16806 16806 root 5u 0000 0,8 581632 379 /dmabuf:16806-llm_demo llm_demo 16806 16806 root 6u 0000 0,8 9920512 380 /dmabuf:16806-llm_demo llm_demo 16806 16806 root 7u 0000 0,8 1543569408 381 /dmabuf:16806-llm_demo llm_demo 16806 16806 root 8u 0000 0,8 88326144 382 /dmabuf:16806-llm_demo
4 部署环境下Deepseek使用
4.1 本地命令行
本地运行环境目录如下:
├── deepseek_1.5b_W8A8_RK3588.rkllm
├── lib
│ └── librkllmrt.so
└── llm_demo
然后执行:
export LD_LIBRARY_PATH=./lib ./llm_demo deepseek_1.5b_W8A8_RK3588.rkllm 10000 10000
问答如下,质量一般般:
rkllm init start I rkllm: rkllm-runtime version: 1.1.4, rknpu driver version: 0.9.8, platform: RK3588 rkllm init success **********************可输入以下问题对应序号获取回答/或自定义输入******************** [0] 现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,求鸡和兔子各有多少只? [1] 有28位小朋友排成一行,从左边开始数第10位是学豆,从右边开始数他是第几位? ************************************************************************* user: 描述一下基于arm的Linux启动过程,包括uboot、kernel、rootfs。 robot: 在arm-based Linux系统中,启动过程通常涉及三个主要阶段:uboot、kernel和rootfs。下面是一个简要的描述: 1. **uboot( bootloader )**: - uboot是arm-based Linux系统的引导程序,它负责从磁盘读取并执行必要的代码来启动系统。 - 当系统启动时,uboot首先读取引导磁盘中的引导信息,并根据这些信息选择合适的引导项。 - 在arm-based Linux中,uboot通常位于一个名为`uboot.bin`的文件中。 2. **kernel(内核)**: - kernel是arm-based Linux系统的核心部分,它负责管理整个系统的资源和操作。 - 当uboot完成引导后,kernel开始运行,并通过一系列的步骤来准备并运行其他进程。 - kernel首先装载内核代码到内存中,然后执行一些初始化工作,如分配内存、设置设备驱动程序等。 3. **rootfs(根文件系统)**: - rootfs是arm-based Linux系统中的主文件系统,它存储了所有用户和内核需要的文件。 - 当kernel完成初始化后,它会开始加载rootfs,并将内核代码和用户空间代码分开。 - rootfs通常位于一个名为`/boot/vol0`的分区中。 在arm-based Linux系统中,这些步骤可能略有不同,具体取决于具体的arm内核和uboot实现。不过,这个基本的启动过程是 arm-based Linux 系统中最常见的。
4.2 基于Gradio提供Web服务
联系方式:arnoldlu@qq.com


 浙公网安备 33010602011771号
浙公网安备 33010602011771号