sysctl:vm参数设置
1 vm.admin_reserve_kbytes = 8192
参数作用:
- 功能:为系统管理员(root)进程保留 8MB 内存,防止内存耗尽时关键管理进程(如 SSH、systemd)崩溃。
- 默认值:通常为 256(0.25MB)或 8192(8MB,因系统而异)。
影响分析:
| 场景 | 影响 |
| 内存充足时 | 无显著影响,保留内存可被普通进程使用。 |
| 内存不足时 | 确保至少 8MB 内存专供 root 进程,避免系统管理功能失效(如无法登录修复)。 |
| 调整过高(如 64MB) | 浪费可用内存,可能加剧普通进程的 OOM(内存溢出)风险。 |
| 调整过低(如 1MB) | 内存紧张时,关键管理进程可能因内存不足被 OOM Killer 终止,导致系统失控。 |
建议:
- 默认值适用性:若无特殊需求(如极端内存限制环境),保持默认值即可。
- 监控工具:搭配 free -m 或 htop 观察内存使用情况,再决定是否需要调整。
2 vm.dirty_background_bytes = 0
3 vm.dirty_background_ratio = 10
4 vm.dirty_bytes = 0
5 vm.dirty_expire_centisecs = 3000
6 vm.dirty_ratio = 20
7 vm.dirty_writeback_centisecs = 500
8 vm.dirtytime_expire_seconds = 43200
参数说明
1. vm.dirty_background_bytes = 0
- 作用:设置触发后台脏页回写的绝对内存阈值(字节单位)。
- 配置范围:
- 0:禁用绝对值模式,改用 dirty_background_ratio(比例模式)。
- ≥1:指定具体字节数(如 1048576 = 1MB)。
- 影响:
- 设为 0 时,依赖 dirty_background_ratio 触发后台回写。
- 非零时优先级高于 dirty_background_ratio。
2. vm.dirty_background_ratio = 10
- 作用:当系统内存中脏页占比 ≥ 设定比例时,触发 异步后台回写(不阻塞应用)。
- 配置范围:0 ~ 100(百分比)。
- 影响:
- 低值(如 5):频繁小批量回写,减少数据丢失风险,但增加I/O负载。
- 高值(如 20):延迟回写,提升写入吞吐,但内存不足时可能突发高I/O。
3. vm.dirty_bytes = 0
- 作用:设置触发同步脏页回写的绝对内存阈值(字节单位)。
- 配置范围:
- 0:禁用绝对值模式,改用 dirty_ratio(比例模式)。
- ≥1:指定具体字节数。
- 影响:
- 非零时优先级高于 dirty_ratio,适合精确控制内存占用。
- 设为 0 时依赖 dirty_ratio 触发同步回写。
4. vm.dirty_expire_centisecs = 3000
- 作用:脏页在内存中驻留的最长时间(单位:1/100秒),超时后强制回写。
- 配置范围:0 ~ INT_MAX(约 21474836 秒 ≈ 248天)。
- 影响:
- 短时间(如 1000=10秒):频繁回写,减少数据丢失,但增加I/O压力。
- 长时间(如 3000=30秒):适合批量写入场景(如日志服务器),但崩溃时可能丢失更多数据。
5. vm.dirty_ratio = 20
- 作用:当系统内存中脏页占比 ≥ 设定比例时,触发 同步阻塞回写(应用写入被暂停)。
- 配置范围:0 ~ 100(百分比)。
- 影响:
- 低值(如 10):快速回写,减少阻塞,但限制写入吞吐。
- 高值(如 30):允许更多脏页累积,提升突发写入性能,但可能导致应用卡顿。
6. vm.dirty_writeback_centisecs = 500
- 作用:内核周期性唤醒回写线程的时间间隔(单位:1/100秒)。
- 配置范围:0 ~ INT_MAX(设为 0 禁用周期性回写)。
- 影响:
- 短间隔(如 100=1秒):实时回写,减少数据驻留时间,适合低延迟存储(如SSD)。
- 长间隔(如 500=5秒):降低CPU开销,但可能延迟回写。
7. vm.dirtytime_expire_seconds = 43200
- 作用:标记为“脏页”的最长保留时间(秒),超时后可能被优先回收。
- 配置范围:0 ~ INT_MAX(约 68年)。
- 影响:
- 短时间(如 3600=1小时):加速回收长期未访问的脏页,节省内存。
- 长时间(如 43200=12小时):减少频繁回收,适合内存充足且需要缓存持久化的场景。
配置建议与工具
1. 监控命令:
grep "Dirty:" /proc/meminfo # 查看当前脏页大小 vmstat 1 # 观察内存和I/O状态 iostat -x 1 # 监控磁盘I/O负载
2. 调优方向:
- 高吞吐场景:提高 dirty_ratio + 延长 dirty_expire_centisecs。
- 数据安全场景:降低 dirty_ratio + 缩短 dirty_expire_centisecs。
- 低延迟存储:缩短 dirty_writeback_centisecs。
通过合理配置,可平衡 性能、内存占用 和 数据可靠性。
9 vm.laptop_mode = 0
作用
控制系统的磁盘 I/O 和缓存回写策略,针对笔记本电脑等移动设备优化电源管理。
- 启用时(值 >0):延迟磁盘写入操作,合并多次 I/O 请求以减少磁盘唤醒次数,从而降低功耗。
- 禁用时(值 =0):立即处理磁盘写入,优先保证数据安全性和响应速度。
配置范围
- 典型值:
- 0:禁用笔记本电脑模式(默认值,常见于服务器/台式机)。
- 1~5:启用并设置优化强度(值越大,延迟写入越激进,不同内核版本可能范围不同)。
配置影响
| 场景 | laptop_mode=0(禁用) | laptop_mode>0(启用) |
| 数据安全性 | 脏页更快回写磁盘,崩溃时数据丢失风险低。 | 脏页延迟回写,崩溃可能丢失更多未保存数据。 |
| 磁盘 I/O 频率 | 写入操作更频繁,磁盘活动量高。 | 合并写入请求,减少磁盘唤醒次数,延长 SSD/HDD 寿命。 |
| 功耗 | 磁盘频繁唤醒,增加功耗(对笔记本续航不利)。 | 减少磁盘活动,显著降低功耗(适合电池供电场景)。 |
| 性能表现 | 响应更快,适合高吞吐场景(如数据库写入)。 | 轻微延迟可能影响实时性要求高的任务。 |
使用场景建议
1. 禁用(=0)场景:
- 服务器、台式机(无需省电)。
- 高数据安全需求(如金融交易系统)。
- 需要低延迟写入的应用(如实时日志处理)。
2. 启用(>0)场景:
- 笔记本电脑(需延长电池续航)。
- 对磁盘寿命敏感的环境(如 SSD 频繁写入优化)。
- 非关键数据的离线任务(如文档编辑、轻度开发)。
10 vm.legacy_va_layout = 0
作用
控制虚拟内存地址空间布局模式:
- 0:启用 新版布局(默认),将内存映射区域(如堆、栈)放置在更高地址空间,提升 ASLR(地址空间随机化)安全性。
- 1:启用 传统布局(旧版),兼容早期内核版本或特定老旧应用。
配置范围
- 可选值:0(禁用传统布局)或 1(启用传统布局)。
影响
- 设为 0:
- 增强安全性(ASLR 更有效),但对极少数依赖传统地址布局的应用可能导致崩溃(需重新编译)。
- 设为 1:
- 兼容老旧程序,但降低内存随机化防护能力(增加漏洞利用风险)。
11 vm.lowmem_reserve_ratio = 32 0
作用
控制低端内存区域(ZONE_DMA、ZONE_NORMAL)的保留内存比例,防止内核因内存耗尽而崩溃。
- 格式:按内存区域顺序设置比例值(如 32 0 表示 ZONE_DMA 保留比例为 1/32,ZONE_NORMAL 不保留)。
配置范围
- 值范围:每个区域值为 ≥0 的整数(0 表示不保留)。
- 典型配置:32 32 0(三区域:DMA、DMA32、NORMAL)。
影响
- 高比例(如 32):保留更多内存供内核使用,减少用户态进程 OOM(内存溢出)风险,但用户可用内存减少。
- 设为 0:关闭指定区域的内存保留,可能导致内核关键功能(如网络栈)在内存紧张时失效。
12 vm.max_map_count = 65530
作用
限制单个进程可创建的内存映射区域(如文件映射、共享内存)的最大数量。
配置范围
- 最小值:0(禁止映射,系统不可用)。
- 默认值:65530(多数 Linux 发行版)。
- 最大值:内核允许的最大值(通常 1048576)。
影响
- 调高(如 262144):支持需要大量内存映射的应用(如 Oracle 数据库、JVM),避免 ENOMEM 错误。
- 调低(如 32768):减少内核元数据开销,但可能导致应用崩溃(如 Elasticsearch、Redis)。
13 vm.memfd_noexec = 0
作用
控制通过 memfd_create() 创建的内存文件是否允许执行代码(安全防护)。
- 0:允许执行(默认)。
- 1:禁止执行,防范代码注入攻击(如容器环境)。
配置范围
- 可选值:0 或 1。
影响
- 设为 0:
- 允许内存文件执行代码,兼容传统应用(如 JIT 编译器),但存在安全风险。
- 设为 1:
- 增强安全性(阻止恶意代码在内存中运行),但依赖内存执行的程序(如某些语言解释器)可能崩溃。
14 vm.min_free_kbytes = 4008
1. 参数作用
- 定义:指定内核应保留的最小空闲内存(以 KB 为单位),确保系统在内存压力下仍有足够内存处理紧急操作(如中断处理、内核分配等)。
- 目标:防止内存耗尽导致的系统不稳定或进程被 OOM Killer 终止。
2. 默认值计算
- 自动计算:内核根据系统总内存动态计算默认值,通常为:
默认值 ≈ √总物理内存 × 16 (不同内核版本可能有差异)
- 例如:64GB 内存的系统,默认值约为√(64 × 1024) ×16 ≈ 8192 KB(即 8MB)。
- 查看当前值:
cat /proc/sys/vm/min_free_kbytes
3. 配置建议
(1) 合理范围
- 经验值:通常设置为总内存的 1%~3%。
- 例如:64GB(即 65536MB)内存,建议值为 655MB ~ 1966MB(即 65536KB ~ 196608KB)。
- 调整命令:
#临时修改 sysctl -w vm.min_free_kbytes=65536 #永久修改(写入 /etc/sysctl.conf) echo "vm.min_free_kbytes=65536" >> /etc/sysctl.conf sysctl -p
(2) 场景优化
- 内存敏感型应用(如数据库、虚拟机):
- 适当提高值(如 3%),增强内存不足时的稳定性。
- 嵌入式/低内存设备:
- 降低值(如 0.5%),避免过多内存浪费。
4. 影响分析
(1) 设置过低的后果
- 内存碎片增加:内核难以找到连续内存块,可能触发频繁的内存回收(直接回收或 Compaction)。
- OOM 风险:紧急内存需求无法满足,导致进程被终止或系统冻结。
(2) 设置过高的后果
- 内存浪费:用户空间可用内存减少,可能影响应用程序性能。
- 频繁唤醒 kswapd:过早触发内存回收,增加 CPU 开销。
5. 监控与调试
(1) 监控工具
-free 命令:观察free 内存是否接近min_free_kbytes。
free -k 以 KB 为单位显示
-/proc/zoneinfo:查看各内存区域的空闲页和保留页。
grep -A10 "Node 0" /proc/zoneinfo
(2) 关键指标
-pages min:在/proc/zoneinfo 中,表示每个 Zone 的最小保留页数。
-lowmem_reserve_ratio:影响保留内存的分布,需与min_free_kbytes 协调。
6. 与其他参数的关联
-vm.swappiness:控制交换分区使用倾向,高min_free_kbytes 可配合低swappiness 减少交换。
-vm.watermark_scale_factor:调整内存回收阈值,与min_free_kbytes 共同决定何时触发回收。
-vm.extra_free_kbytes:额外保留的内存,用于优化突发内存需求。
7. 注意事项
- 逐步调整:避免一次性大幅修改,建议按 10%~20% 步长调整并观察效果。
- 测试验证:在生产环境调整前,通过压力测试(如stress-ng)模拟内存负载。
- 内核版本差异:不同内核版本的内存管理策略可能不同,需参考对应文档。
示例配置
对于 128GB 内存的服务器(假设默认值为 16384 KB):
1. 计算建议值:1% 为 131072 KB(128GB × 0.01 = 1.28GB)。
2. 临时调整:
sysctl -w vm.min_free_kbytes=131072
3. 监控效果:
watch -n 1 "grep -E 'min|free' /proc/zoneinfo"
总结
- 平衡点:vm.min_free_kbytes 需在内存浪费与系统稳定间找到平衡。
- 动态调整:根据实际负载和业务需求定期评估,避免静态设置。
- 全局视角:结合其他内存参数(如swappiness)和监控工具,全面优化内存管理。
15 vm.mmap_min_addr = 4096
作用
设置用户空间进程进行内存映射(如 mmap)时的 最低允许地址(字节单位),防止恶意程序映射低地址内存(如 0x0),增强系统安全性。
配置范围
- 最小值:0(允许映射到 0x0,极不安全)。
- 典型值:4096(即 0x1000,默认值,与内存页对齐)。
- 最大值:由架构决定(通常不超过 65536)。
影响
- 设为 4096:
- 阻止映射 0x0 地址,防御空指针解引用攻击(如 NULL pointer dereference)。
- 兼容多数现代应用,但极少数老旧程序(依赖低地址映射)可能崩溃。
- 设为 0:
- 允许映射任意低地址,存在安全风险(仅用于调试或兼容性需求)。
- 设为更高值(如 65536):
- 进一步限制内存映射范围,可能误伤合法应用(需谨慎测试)。
16 vm.mmap_rnd_bits = 17
作用
控制 mmap 内存映射的 地址随机化位数(ASLR 的一部分),增加攻击者预测内存地址的难度,提升安全性。
- 值越大:随机化范围越广,地址越难预测。
- 值越小:随机化范围越窄,节省内存但降低安全性。
配置范围
- 32 位系统:8 ~ 16(默认 8)。
- 64 位系统:16 ~ 32(默认 28)。
- 特殊说明:vm.mmap_rnd_bits=17 是针对 64 位系统 的合理值(需确认内核支持)。
影响
- 调高(如 24):
- 增强安全性(如防御 ROP 攻击),但可能略微增加内存碎片化。
- 对性能影响可忽略(现代 CPU 处理随机化开销低)。
- 调低(如 16):
- 减少内存地址分散,但易被攻击者预测内存布局。
- 超出范围:
- 内核可能自动调整为最大/最小值(如 64 位系统设置 33 → 回退到 32)。
17 vm.oom_dump_tasks = 1
作用
控制在系统触发 OOM(内存耗尽)时,是否在日志中 转储所有进程的内存使用信息,帮助诊断 OOM Killer 选择终止进程的原因。
配置范围
- 0:禁用 OOM 时进程信息转储(默认)。
- 1:启用转储,记录所有进程的 pid、内存占用、oom_score 等详细信息。
影响
- 设为 1:
- 优点:提供详细的调试信息,便于分析内存泄漏或异常进程。
- 缺点:可能生成大体积内核日志(尤其在进程数多时),轻微增加 OOM 处理延迟。
- 设为 0:
- 日志仅记录被终止的进程名,节省存储和计算资源。
18 vm.oom_kill_allocating_task = 0
作用
控制 OOM Killer 是否优先杀死 正在申请内存的进程(触发 OOM 的进程)。
- 0:禁用,根据 oom_score 选择最优进程终止(默认)。
- 1:启用,直接杀死当前申请内存的进程。
配置范围
- 0 或 1。
影响
- 设为 0:
- 优点:公平选择高内存占用或低优先级的进程终止,保护关键服务(如数据库)。
- 缺点:决策延迟稍高(需遍历进程计算评分)。
- 设为 1:
- 优点:快速终止当前请求内存的进程(如内存泄漏的进程),立即缓解内存压力。
- 缺点:可能误杀合法进程(如突发内存需求的正常应用)。
19 vm.overcommit_kbytes = 0
20 vm.overcommit_memory = 0
21 vm.overcommit_ratio = 50
内存的 Overcommit(超量提交) 是 Linux 内核的一种内存管理机制,允许系统分配比物理内存(RAM)和交换空间(Swap)总和更多的内存给进程。这种机制基于一个假设:并非所有进程会同时完全使用其申请的内存。通过 Overcommit,系统可以更灵活地管理内存资源,提高内存利用率,但也可能引入内存耗尽的风险。
Overcommit 的核心逻辑
1. 允许“超额承诺”
进程可以通过 malloc() 等函数申请大量内存,但实际使用时可能仅占用部分内存(例如稀疏数组、预分配但未填充的缓冲区)。
Overcommit 允许内核接受这些请求,即使当前物理内存 + Swap 不足。
2. 内核的策略判断
内核通过 vm.overcommit_memory 参数控制是否允许 Overcommit,并决定如何检查内存请求的合法性。
Linux 的 Overcommit 策略
通过 vm.overcommit_memory 参数配置:
| 参数值 | 策略 | 行为 |
| 0 | 启发式 Overcommit(默认) | 内核根据经验公式判断是否允许分配:若 空闲内存 + 可回收内存 ≥ 请求内存,则允许;否则拒绝(返回 ENOMEM)。 |
| 1 | 总是允许 Overcommit | 无条件接受所有内存申请请求(除非超过进程地址空间限制)。 |
| 2 | 禁止 Overcommit | 严格限制内存分配总量,不得超过 物理内存 × overcommit_ratio% + Swap + overcommit_kbytes。 |
Overcommit 的典型场景
1. 稀疏内存使用
进程申请 1GB 内存,但仅实际写入 100MB(如哈希表的预分配)。
Overcommit 允许此类请求,避免物理内存浪费。
2. 多进程分时占用内存
多个进程申请大量内存,但不同时活跃使用(如批处理任务)。
内核可通过分时调度避免内存耗尽。
3. 内存泄漏容忍
允许短期内存泄漏,依赖进程退出后自动释放(如临时脚本)。
Overcommit 的风险
当进程实际使用的内存总量超过 物理内存 + Swap 时,系统触发 OOM(Out-Of-Memory) Killer,强制终止进程以释放内存。这可能导致:
- 关键服务被终止(如数据库、Web 服务器)。
- 数据丢失或业务中断。
Overcommit 的配置与监控
1. 关键参数
- vm.overcommit_memory:定义 Overcommit 策略(0/1/2)。
- vm.overcommit_ratio(默认 50%):策略 2 下,允许分配的内存比例。
- vm.overcommit_kbytes:策略 2 下,允许分配的绝对内存值(优先级高于 overcommit_ratio)。
2. 监控工具
- free -h:查看内存和 Swap 使用情况。
- dmesg | grep "Out of memory":检查 OOM 事件。
- sar -r:监控内存分配趋势。
3. 配置示例
- 允许所有 Overcommit(高风险):
sysctl vm.overcommit_memory=1
- 严格限制 Overcommit(高稳定):
sysctl vm.overcommit_memory=2 sysctl vm.overcommit_ratio=80 # 允许分配总量 = 物理内存 × 80% + Swap
Overcommit 的优缺点
| 优点 | 缺点 |
| 提高内存利用率,支持更多进程并发。 | 内存耗尽时触发 OOM Killer,可能导致服务中断。 |
| 适应稀疏内存使用场景,减少物理内存浪费。 | 需要合理配置策略,否则可能频繁拒绝合法内存请求。 |
| 简化内存管理(无需精确预判进程内存需求)。 | 调试内存问题时复杂度增加(如隐藏的内存泄漏)。 |
适用场景建议
- 启用 Overcommit(策略 0 或 1):
- 多数通用服务器、桌面环境。
- 内存需求波动大但峰值不同时出现的场景(如云计算虚拟机)。
- 禁用 Overcommit(策略 2):
- 对稳定性要求极高的关键服务(如金融交易系统)。
- 内存需求可精准预测的应用(如嵌入式设备)。
总结
内存的 Overcommit 是一种以弹性换风险的机制,通过“超额承诺”提高资源利用率,但需结合业务场景谨慎配置。理解其原理并合理监控,可在性能与稳定性之间找到最佳平衡。
22 vm.page-cluster = 3
作用
控制文件预读(Read-ahead)的页面数量,优化顺序读取性能。
- 计算公式:预读页数 = 2^page-cluster(例如 3 → 预读 8 页)。
配置范围
- 典型值:0 ~ 5(对应预读 1 ~ 32 页)。
影响
- 高值(如 3~5):提升顺序读性能(如大文件读取),但增加内存占用。
- 低值(如 0~2):减少内存浪费,适合随机读取场景(如数据库)。
23 vm.page_lock_unfairness = 5
作用
调整内存页锁的公平性策略,控制多线程竞争锁时的优先级分配。
- 值越大:允许更多“不公平”锁分配(高优先级线程更快获取锁)。
配置范围
- 典型值:1 ~ 10(默认值因内核版本而异)。
影响
- 高值(如 5~10):提升高优先级线程性能,但可能导致低优先级线程饥饿。
- 低值(如 1~3):更公平的锁竞争,但可能增加调度开销。
24 vm.panic_on_oom = 0
作用
控制系统在内存耗尽(OOM)时是否触发内核崩溃(panic)。
- 0:不触发 panic,由 OOM Killer 终止进程(默认)。
- 1:触发 panic,直接重启系统。
配置范围
- 可选值:0 或 1。
影响
- 设为 0:允许系统继续运行(依赖 OOM Killer),但可能终止关键进程。
- 设为 1:确保系统快速复位,避免数据不一致,但导致服务中断。
25 vm.percpu_pagelist_high_fraction = 0
作用
控制每个 CPU 的页列表(Pagelist)高水位线,影响内存回收策略。
- 0:禁用按 CPU 的高水位限制,使用全局内存管理策略。
配置范围
- 值范围:0 ~ 100(百分比,默认值因内核版本而异)。
影响
- 设为 0:简化内存管理,减少碎片化,但可能降低 NUMA 架构性能。
- 设为非零(如 5):优化多 CPU 内存分配,但增加管理开销。
26 vm.stat_interval = 1
作用
设置内核更新内存统计信息(如缓存、脏页)的时间间隔(秒)。
配置范围
- 最小值:1(1秒,默认)。
- 最大值:600(10分钟)。
影响
- 短间隔(如 1):监控数据更实时,但轻微增加 CPU 开销。
- 长间隔(如 10):减少开销,但监控工具(如 free、top)数据更新延迟。
27 vm.swappiness = 60
vm.swappiness 是 Linux 内核中用于调节内存交换行为的重要参数,以下是其关键信息及使用建议:
作用
- 控制内核在物理内存不足时使用交换空间(Swap)的倾向。值越高,内核越积极使用 Swap;值越低,越倾向于保留在物理内存中。
取值范围
- 0~100,默认值为 60。
- 0:尽可能避免交换匿名内存(应用程序内存),但不禁止交换(极端内存压力下仍会触发)。
- 100:积极使用 Swap,可能增加 I/O 负载。
适用场景
1. 数据库/高性能服务(如 MySQL、Redis):
- 建议设为 1~10,减少交换延迟,确保关键数据驻留物理内存。
2. 桌面环境:
- 默认值 60 或稍低(如 30),平衡响应速度与内存压力。
3. SSD 存储:
- 可适当降低(如 10),因 SSD 虽快但频繁写入可能影响寿命。
4. 内存充足环境:
- 设为 0 或更低值(需内核支持),优先使用物理内存。
检查与配置
- 查看当前值:
sysctl vm.swappiness # 或 cat /proc/sys/vm/swappiness
- 临时修改:
sysctl -w vm.swappiness=10
- 永久生效:
编辑 /etc/sysctl.conf,添加:
vm.swappiness=10
执行 sysctl -p 生效。
与其他参数的关系
- vfs_cache_pressure:控制文件系统缓存回收倾向(默认 100)。若系统依赖文件缓存(如 Web 服务器),可适当降低此值以减少缓存回收,与 swappiness 配合优化内存策略。
- cgroups:某些场景下可为控制组单独设置 memory.swappiness,优先级高于全局参数。
常见误解
- swappiness=0 是否禁用 Swap?
否!内核仍可能在内存严重不足时触发交换。完全禁用需结合 swapoff -a。
- 高内存占用是否需调高 swappiness?
不一定,物理内存未耗尽时,Swap 使用可能无必要。建议监控后再调整(如使用 free 或 vmstat)。
内核版本差异
- 3.5+ 版本:引入更积极的内存回收策略,swappiness=0 可能仍比旧内核更频繁交换。
- 调整前建议测试:不同工作负载下,参数效果可能差异显著。
总结建议
- 优先物理内存:对延迟敏感的服务,降低 swappiness。
- 监控再调整:通过 sar、vmstat 观察 Swap 使用率及 SI/SO(交换入/出)频率。
- 结合存储类型:机械硬盘慎用高 swappiness,SSD 可适度放宽但避免极端值。
通过合理配置 vm.swappiness,可显著优化系统性能与稳定性,尤其在内存密集型场景中效果显著。
28 vm.user_reserve_kbytes = 31169
作用
为用户态(非 root)进程保留 31,169 KB(约 31MB)内存,防止内存耗尽时关键用户进程(如 Web 服务、数据库客户端)被 OOM Killer 强制终止。
配置范围
- 最小值:0(不保留,默认值通常为 0 或基于系统内存动态计算)。
- 合理范围:根据系统总内存调整,通常为总内存的 0.1%~1%(例如 32GB 内存可设为 32768 KB)。
- 最大值:理论上无上限,但需避免过度占用可用内存。
影响分析
| 场景 | 影响 |
||--|
| 内存充足时 | 保留内存仍可被用户进程使用,无实际限制。 |
| 内存不足时 | 用户进程最多只能使用 总内存 - 保留内存,降低关键服务被 OOM Killer 终止的概率。 |
| 配置过高(如 128MB) | 浪费可用内存,可能加剧普通进程的 OOM 风险。 |
| 配置过低(如 8MB) | 内存紧张时,用户进程可能因保留内存不足被终止,影响服务可用性。 |
29 vm.vfs_cache_pressure = 100
vm.vfs_cache_pressure 是 Linux 内核中用于调节虚拟文件系统(VFS)缓存回收行为的参数,主要影响 dentry(目录项) 和 inode(索引节点) 缓存的回收策略。以下是对其作用、配置及影响的详细说明:
作用与原理
1. 缓存类型:
- dentry 缓存:加速文件路径查找,缓存目录结构信息。
- inode 缓存:存储文件元数据(如权限、大小、时间戳等),减少磁盘读取。
2. 参数功能:
- 控制内核回收 VFS 缓存的倾向性。值越大,内核越积极回收缓存;值越小,越保留缓存。
配置方式
1. 临时调整(重启失效):
sysctl -w vm.vfs_cache_pressure=200 # 设置为 200
2. 永久生效:
- 编辑 /etc/sysctl.conf,添加:
vm.vfs_cache_pressure=50
- 应用配置:
sysctl -p
参数影响
| 值范围 | 行为表现 | 适用场景 |
| < 100 | 内核减缓回收 VFS 缓存,提升重复文件访问速度,但可能占用更多内存。 | 文件密集型服务(如 Web 服务器、数据库)。 |
| 100(默认) | 按默认比例回收 VFS 缓存与其他内存。 | 通用场景。 |
| > 100 | 内核加速回收 VFS 缓存,释放内存供应用使用,但可能增加磁盘 I/O。 | 内存紧张或需优先保障应用内存的场景。 |
调优建议
1. 监控工具:
- free -h:观察 Slab 内存占用(包含 dentry/inode 缓存)。
- slabtop:实时查看 dentry 和 inode_cache 的缓存大小。
- vmstat 或 iostat:检查 I/O 压力变化。
2. 场景示例:
- 提升文件性能:降低值(如 50),适用于频繁访问相同文件的场景。
- 缓解内存压力:提高值(如 150),适用于内存不足且文件缓存可牺牲的情况。
3. 注意事项:
- 与 swappiness 参数协同调整(后者控制匿名内存与文件缓存的回收优先级)。
- 极端值可能导致性能波动,需结合监控逐步调整。
示例配置
# 优化文件服务器缓存保留 sysctl -w vm.vfs_cache_pressure=50 # 内存紧张环境,优先释放缓存 sysctl -w vm.vfs_cache_pressure=150
通过合理配置 vm.vfs_cache_pressure,可在文件访问速度和内存利用率之间实现平衡,适应不同工作负载需求。
30 vm.watermark_boost_factor = 15000
vm.watermark_boost_factor 是 Linux 内核中用于动态调整内存水印(watermark)的参数,影响内存回收的触发策略。以下是对其作用、配置和影响的详细说明:
作用
- 动态提升水印值:当系统经历高内存压力(如直接内存回收)后,内核会临时提高内存区域(zone)的 min、low、high 水印值。vm.watermark_boost_factor 决定了提升的幅度。
- 预防内存压力:通过更早触发内存回收(kswapd),避免频繁进入直接回收或 OOM(Out-Of-Memory)状态,提高系统稳定性。
配置
- 路径:
/proc/sys/vm/watermark_boost_factor
- 默认值:
通常为 0(不启用动态提升)或较小整数(如 15000,具体取决于内核版本)。
- 修改方式:
# 临时修改 echo <value> | sudo tee /proc/sys/vm/watermark_boost_factor # 永久修改(在 /etc/sysctl.conf 中添加) vm.watermark_boost_factor = <value>
- 取值范围:
非负整数。典型值为 0(禁用)到 100000,表示水印提升的百分比或倍数(具体公式因内核版本而异)。
影响
1. 调高参数值:
- 优点:更积极的内存回收,减少直接回收和 OOM 风险,适合需要高稳定性的场景(如数据库、实时系统)。
- 缺点:增加后台回收频率,可能导致 CPU 开销上升,空闲内存减少,影响应用性能。
2. 调低参数值:
- 优点:减少内存回收频率,最大化应用可用内存,适合内存密集型负载(如缓存服务)。
- 缺点:可能频繁触发直接回收,增加应用延迟,甚至引发 OOM。
工作机制
- 触发条件:当发生直接内存回收时,内核根据 watermark_boost_factor 动态提升水印值。
- 计算公式(示例):
提升后的水印值 = 原始水印值 × (1 + watermark_boost_factor / 10000)
(具体实现可能因内核版本不同而有所调整)
- 恢复机制:水印值会随时间逐步恢复至原始值,避免长期过度回收。
与其他参数的关系
- vm.min_free_kbytes:设置静态的最小空闲内存。若两者均配置较高,可能导致过度内存保留。
- vm.swappiness:控制回收匿名页与文件页的倾向性,与水印策略协同影响回收行为。
应用建议
- 监控工具:使用 vmstat、sar -B、/proc/vmstat(关注 pgscan_kswapd、pgsteal_kswapd、oom_kill)评估内存压力。
- 优化步骤:
1. 观察默认配置下的内存回收频率和 OOM 事件。
2. 逐步调整 watermark_boost_factor,平衡性能与稳定性。
3. 结合 vm.min_free_kbytes 和 vm.swappiness 进行综合调优。
示例场景
- Web 服务器:适度调高(如 10000),确保快速响应请求时内存充足。
- 大数据处理:调低(如 0 或 5000),优先保障应用内存使用,容忍短暂延迟。
通过合理配置 vm.watermark_boost_factor,可在内存利用率和系统稳定性间取得平衡,适应多样化的工作负载需求。
31 vm.watermark_scale_factor = 10
vm.watermark_scale_factor 是 Linux 内核中与内存管理相关的一个参数,用于动态调整内存水印(watermarks)的缩放比例。内存水印决定了系统何时触发内存回收机制(如 kswapd 或直接内存回收),其作用、配置方式及影响如下:
作用说明
1. 内存水印的作用
内存水印是内核定义的三个关键阈值(min、low、high),用于管理物理内存的回收:
- min: 系统保留的最低空闲内存,用于紧急情况(如原子内存分配)。
- low: 当空闲内存低于此值时,内核启动后台回收(kswapd)。
- high: 当空闲内存达到此值时,停止后台回收。
vm.watermark_scale_factor 通过缩放因子动态调整 low 和 high 水印的位置,影响内存回收的触发时机。
2. 动态调整机制
- 默认情况下,low = min * 1.5,high = min * 3。
- 通过 vm.watermark_scale_factor,内核会基于总内存的百分比重新计算 low 和 high 水印。
- 该参数允许内核根据系统内存压力动态调整水印,更灵活地平衡内存使用与回收效率。
配置方法
1. 查看当前值
cat /proc/sys/vm/watermark_scale_factor
- 默认值:通常为 10(即 0.1% 的总内存比例)。
2. 临时修改
echo <value> > /proc/sys/vm/watermark_scale_factor
- 例如:echo 200 > /proc/sys/vm/watermark_scale_factor 设置为 2% 的总内存比例。
3. 永久生效
在 /etc/sysctl.conf 中添加:
vm.watermark_scale_factor = <value>
执行 sysctl -p 生效。
4. 取值范围
- 有效范围:0 到 1000(对应 0% 到 10% 的总内存比例)。
- 推荐值:默认 10(0.1%),可根据内存压力和性能需求调整。
影响分析
1. 调大该参数(例如设为 200)
- 效果:提高 high 和 low 水印,使内核更早触发内存回收(kswapd 更积极)。
- 优点:减少内存耗尽风险,降低直接内存回收(可能阻塞进程)的概率。
- 缺点:可能增加 CPU 开销(频繁内存回收),降低缓存利用率。
2. 调小该参数(例如设为 5)
- 效果:降低 high 和 low 水印,延迟内存回收。
- 优点:减少 CPU 开销,提高缓存命中率。
- 缺点:可能因内存不足触发直接回收,导致进程延迟(卡顿)。
3. 与 min_free_kbytes 的关系
- min_free_kbytes 设置静态的 min 水印(单位为 KB),而 watermark_scale_factor 动态调整 low 和 high。
- 两者需配合使用:若 min_free_kbytes 设置过大,可能浪费内存;若过小,watermark_scale_factor 的调整范围受限。
适用场景
1. 内存敏感型应用(如数据库、虚拟机)
- 适当增大 watermark_scale_factor,避免内存不足导致性能骤降。
2. CPU 敏感型场景
- 调小参数以减少内存回收的 CPU 开销,但需监控内存压力。
3. 默认配置
- 多数场景下,默认值 10 已足够平衡性能与稳定性。
注意事项
- 修改前需监控内存压力(如 vmstat、sar -B)及直接回收事件(grep "pgsteal" /proc/vmstat)。
- 避免极端值(如 0 或 1000),可能导致系统不稳定。
- 结合 vm.swappiness 和 vm.vfs_cache_pressure 综合优化内存行为。
通过合理配置 vm.watermark_scale_factor,可以在内存利用率与系统响应速度之间找到最佳平衡点。
内核中min、low、high的计算
setup_per_zone_wmarks
pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
tmp = pages_min * zone_managed_pages()
do_div(tmp, lowmem_pages)--当lowmem_pages等于zone_managed_pages()时,tmp等于pages_min。
tmp = max_t(u64, tmp >> 2, mult_frac(zone_managed_pages(zone), watermark_scale_factor, 10000))--取tmp的1/4,zone管理内存的water_scale_factor千分比的最大值。
zone->watermark_boost = 0
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;--当water_scale_factor比较小时,tmp最终即为pages_min的1/4。增大watermark_scale_factor的值,即增大low和high的值,更早进行内存回收,回收更多内存。
zone->_watermark[WMARK_HIGH] = low_wmark_pages(zone) + tmp;--从上面计算的结果tmp,然后MIN->LOW->HIGH->PROMO递增。
zone->_watermark[WMARK_PROMO] = high_wmark_pages(zone) + tmp;
在/proc/zoneinfo中有上述项的对应值:
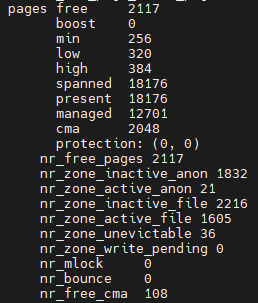
比如我需要保证free最小值为4096KB,则watermark_scale_factor=(4096/4 - 256(min))*10000(万分比)/12701(managed)=605。
设置完后结果如下:
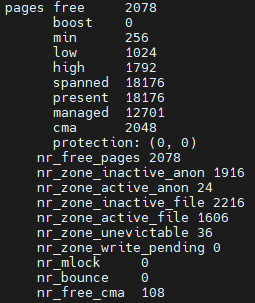
/proc/zoneinfo相关字段说明如下:
- free:当前空闲内存页数。
- boost:临时提高的 `min` 水印。
- min:触发直接回收的最低阈值。
- low:触发后台回收的阈值。
- high:停止回收的阈值。
- spanned:内存区域总地址跨度页数(含空洞)。
- present:实际存在的物理页数。
- managed:伙伴系统管理的可用页数。
- cma:连续内存分配器保留的页数。
- protection:内存区域保护机制(如 NUMA 节点间内存隔离限制)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号