Hive—学习笔记(一)
主要内容:
1、Hive的基本工能机制和概念
2、hive的安装和基本使用
3、HQL
4、hive的脚本化运行使用方式
5、hive的基本语法--建表语法
6、hive的基本语法--内部表和外部表.
7、hive的基本语法--create建表 like as
8、hive的基本语法--数据导入--从本地--从hdfs
9、查询语法
10、数据类型
11、hive函数
1. 什么是hive
hive本身是一个单机程序。转在哪里都行,相对于hadoop来说就是一个hdfs的客户端和yarn的客户端,放在哪一台linux机器都无所谓,只要能链接上hadoop集群就可以,hive本身没有负载,无非就是接收一个sql然后翻译成mr,提交到yarn中去运行。
hive数据分析系统(数据仓库,像一个仓库一样,存放着很多数据,而且可以做各种查询、统计和分析,将结果放入新生的表中),的正常使用,需要
1、mysql:用来存放hdfs文件到二维表的描述映射信息,也就是元数据
2、hadoop集群
hdfs集群
yarn集群
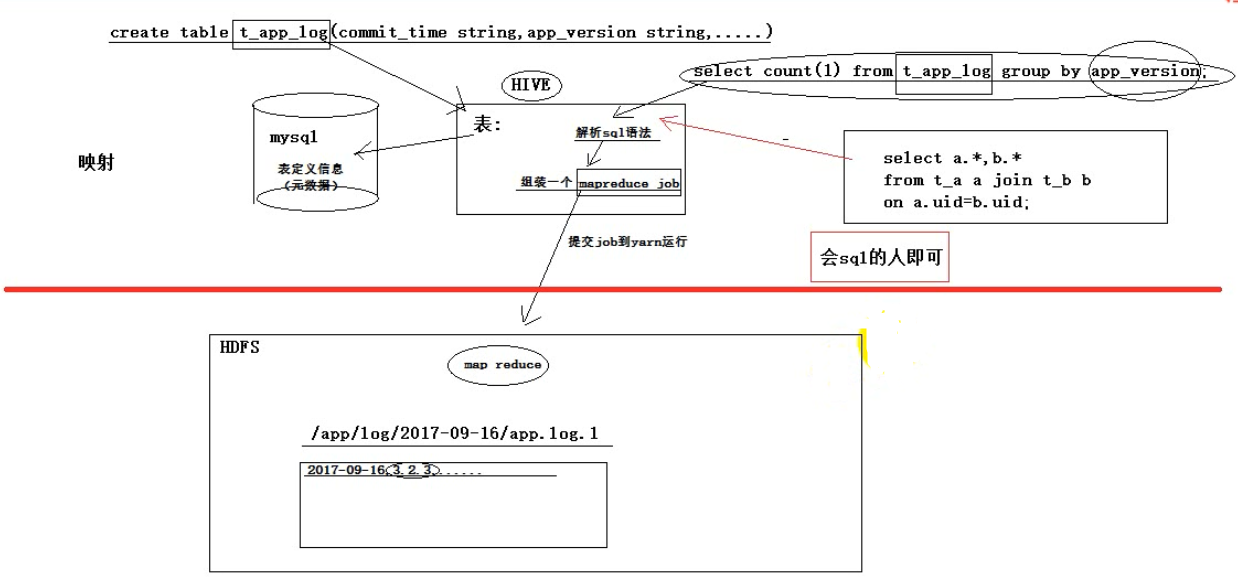
1.1. hive基本思想
Hive是基于Hadoop的一个数据仓库工具(离线),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
1.2. 为什么使用Hive
- 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
- 为什么要使用Hive
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
功能扩展很方便。
1.3. Hive的特点
- 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
- 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 容错
良好的容错性,节点出现问题SQL仍可完成执行。
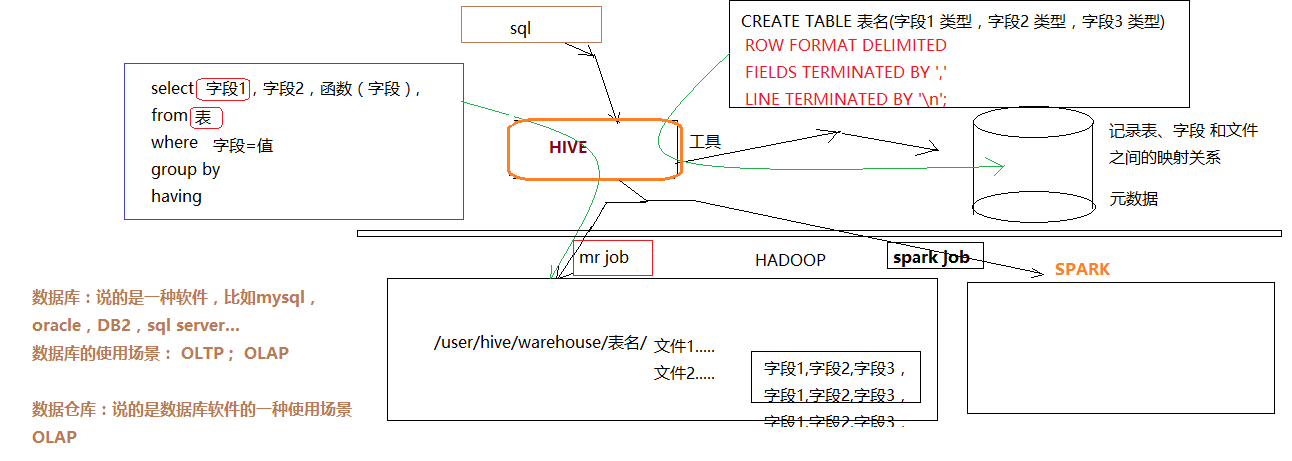
2. hive的基本架构
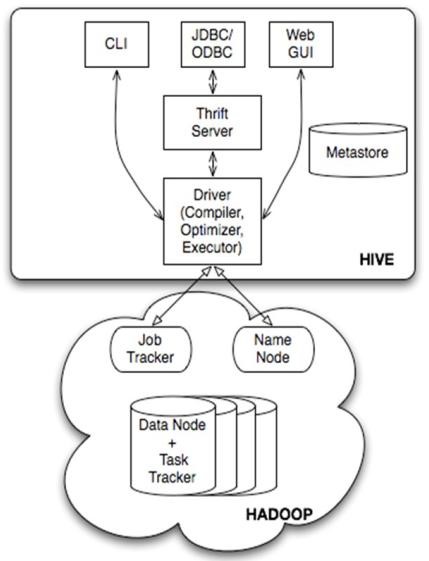
Jobtracker是hadoop1.x中的组件,它的功能相当于:
Resourcemanager+MRAppMaster
TaskTracker 相当于:
Nodemanager + yarnchild
hive 2.0 以后的版本,底层的运算引擎已经不是mr了,而是spark
3. hive安装
3.1. 最简安装:用内嵌derby作为元数据库
准备工作:安装hive的机器上应该有HADOOP环境(安装目录,HADOOP_HOME环境变量)
安装:直接解压一个hive安装包即可
此时,安装的这个hive实例使用其内嵌的derby数据库作为记录元数据的数据库
此模式不便于让团队成员之间共享协作
3.2. 标准安装:将mysql作为元数据库
mysql装在哪里都可以,只要能提供服务,能被hive访问就可以。
下载mysql的rpm安装包

.tar .gz .tar.gz的区别
.tar是讲多个文件打包成一个文件,没有压缩,
.gz是压缩
3.2.1. mysql安装
① 上传mysql安装包
② 解压:
tar -xvf MySQL-5.6.26-1.linux_glibc2.5.x86_64.rpm-bundle.tar
③ 安装mysql的server包
rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
依赖报错:
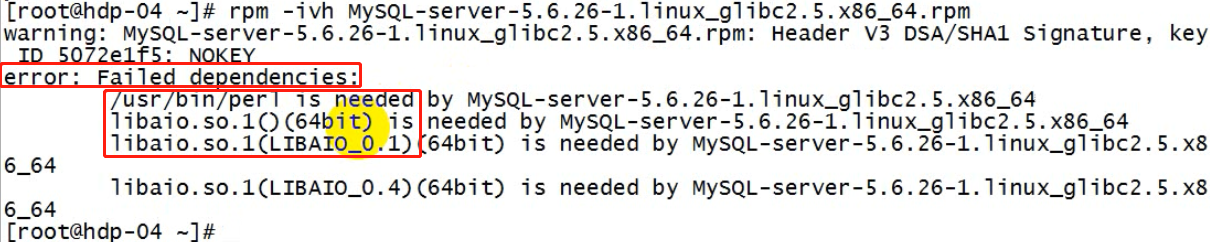
缺perl(是一中编程语言,好比java编程缺少jdk一样)
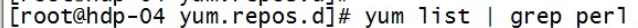
安装perl

yum install perl
安装libaio

安装完perl以及libaio后 ,继续重新安装mysql-server
(可以配置一个本地yum源进行安装:
1、先在vmware中给这台虚拟机连接一个光盘镜像
2、挂载光驱到一个指定目录:mount -t iso9660 -o loop /dev/cdrom /mnt/cdrom
3、修改yum源;将yum的配置文件中baseURL指向/mnt/cdrom
)
1、链接光盘镜像
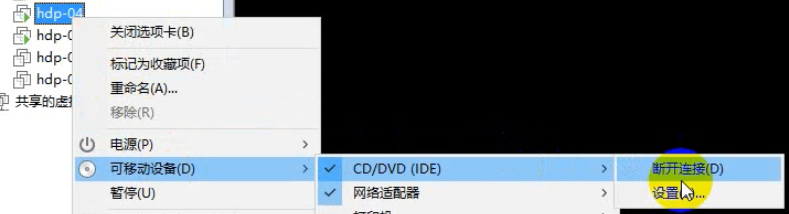
2、挂载光驱
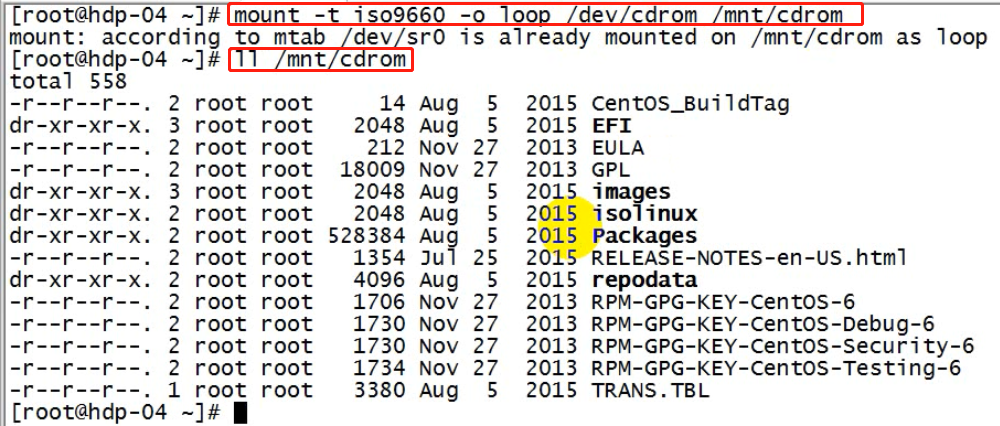
3、修改yum源
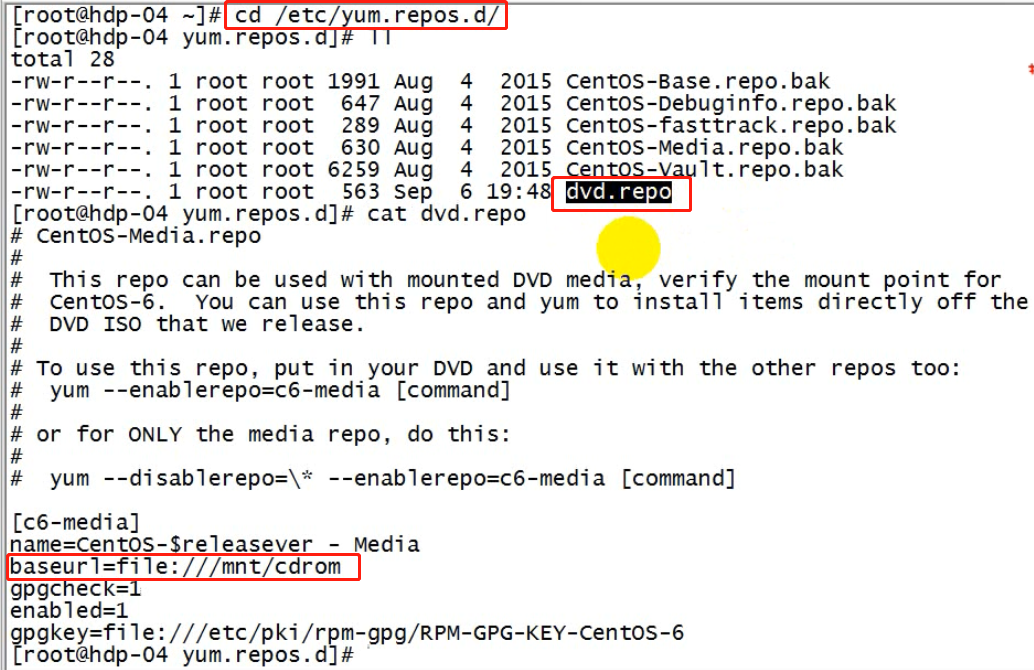
rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
又出错:包冲突conflict with

移除老版本的冲突包:mysql-libs-5.1.73-3.el6_5.x86_64
rpm -e mysql-libs-5.1.73-3.el6_5.x86_64 --nodeps
继续重新安装mysql-server
rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
成功后,注意提示:里面有初始密码及如何改密码的信息
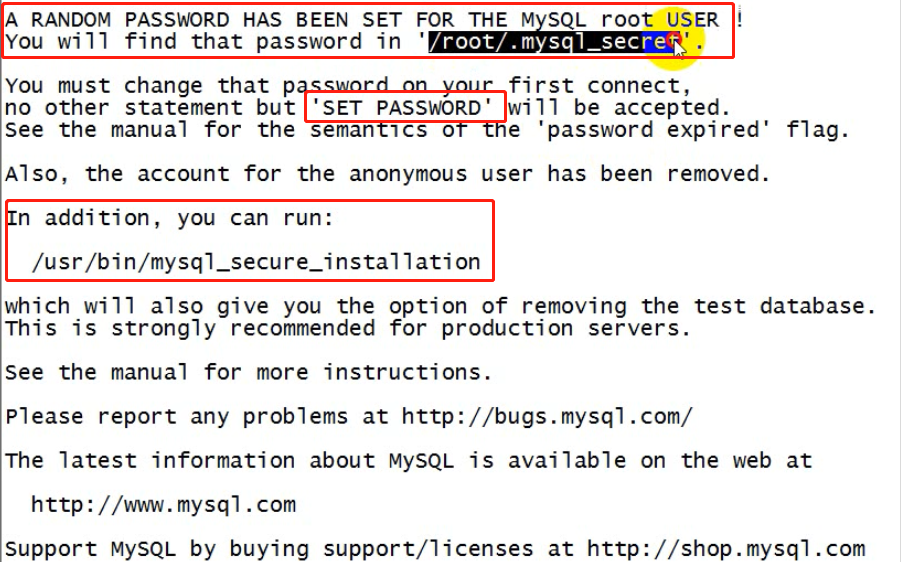
初始密码:
/root/.mysql_secret

改密码脚本:需要mysql客户端
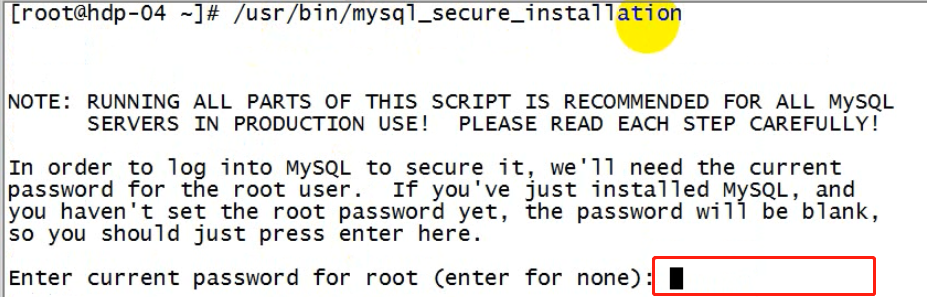
/usr/bin/mysql_secure_installation

④ 安装mysql的客户端包:
rpm -ivh MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm
⑤ 启动mysql的服务端:
service mysql start
Starting MySQL. SUCCESS!

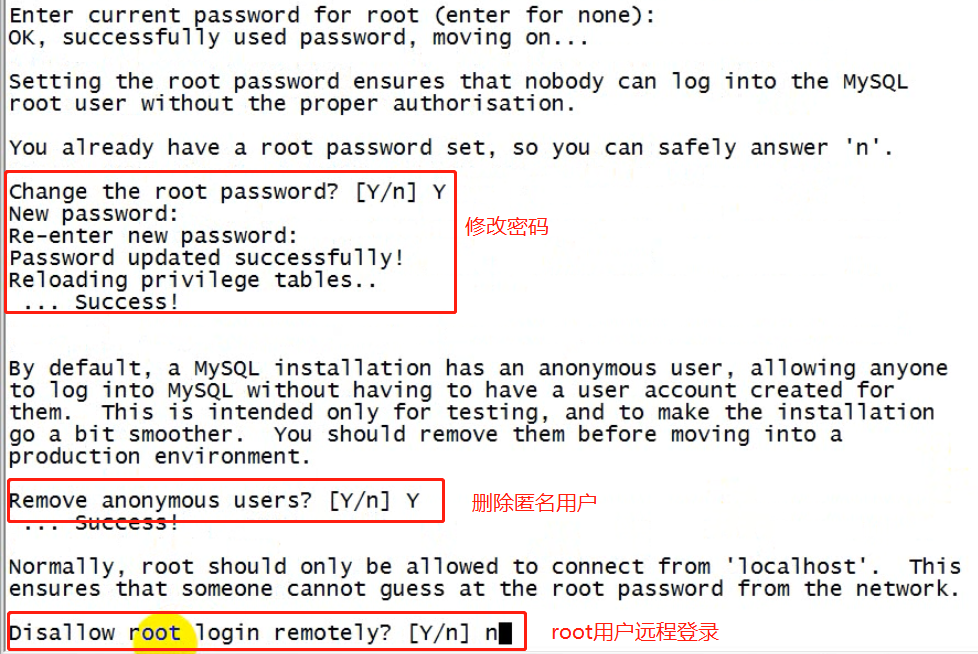
⑥ 修改root的初始密码:
/usr/bin/mysql_secure_installation
按提示,输入生成的随机密码

⑦ 测试:
用mysql命令行客户端登陆mysql服务器看能否成功
[root@mylove ~]# mysql -uroot -proot mysql> show databases;
mysql>exit
⑧ 给root用户授予从任何机器上登陆mysql服务器的权限:
mysql用户权限控制比较严苛,光有用户名,密码还不行,mysql可以限制从哪个机器登录过来的,默认只能从服务器所在的本机登录过来。需要设置某一个用户可以从哪台机器登录过来。
授予root用户,@任何机器,访问任何库的任何表的权限。
mysql> grant all privileges on *.* to 'root'@'%' identified by '你的密码' with grant option; Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
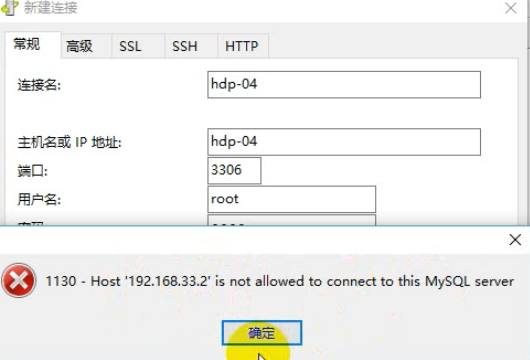
注意点:要让mysql可以远程登录访问
最直接测试方法:从windows上用Navicat去连接,能连,则可以,不能连,则要去mysql的机器上用命令行客户端进行授权:
在mysql的机器上,启动命令行客户端:
mysql -uroot -proot mysql>grant all privileges on *.* to 'root'@'%' identified by 'root的密码' with grant option; mysql>flush privileges;
3.3、开始安装hive
版本说明1.2.1: hive 2.0 以后的版本,底层的运算引擎已经不是mr了,而是spark
3.3.1、上传并解压缩安装包

3.3.2、修改配置文件—元数据库配置
目的:告知mysql在哪里;以及用户名,密码
原因:hive是java程序,需要使用jdbc去连接mysql数据库
hive-site.xml
vi conf/hive-site.xml
<configuration> <property>
<!-- 连接url --> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property>
<!-- 连接的驱动类 --> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property>
<!-- 用户名 -->
<name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property>
<!-- 密码 --> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration>
3.3.3、jdbc驱动包
上传一个mysql的驱动jar包到hive的安装目录的lib中

3.3.4、配置环境变量
因为,hive要访问hdfs,还要提交job到yarn。
1、配置HADOOP_HOME 和HIVE_HOME到系统环境变量中:
/etc/profile

2、刷新配置文件
source /etc/profile
3.3.4、启动hive
然后用命令启动hive交互界面:
[root@hdp20-04 ~]# hive-1.2.1/bin/hive

4、hive使用方式
1、直接在交互界面输入sql进行交互。
2、sql里可以直接使用java类型。
3、hive中建立数据库后,会在hdfs中出现对象的库名.db的文件夹
4、建表的目的是为了和数据文件进行映射;建立表之后(默认建立在default库中),hive会在hdfs上建立对应的文件夹,文件夹的名字就是表名称;
4.1、只要hdfs文件夹中有了数据即文件,对应的表中就会有了记录
4.2、hdfs文件中的数据是按照分隔符进行切分的(value.toString().split("分割符"))(默认分隔符\001:ctrlA--不可见,cat命令下看不见);表的定义是保存在mysql中的。
以下是简单的实例:hive中的数据库,数据表——建库,建表
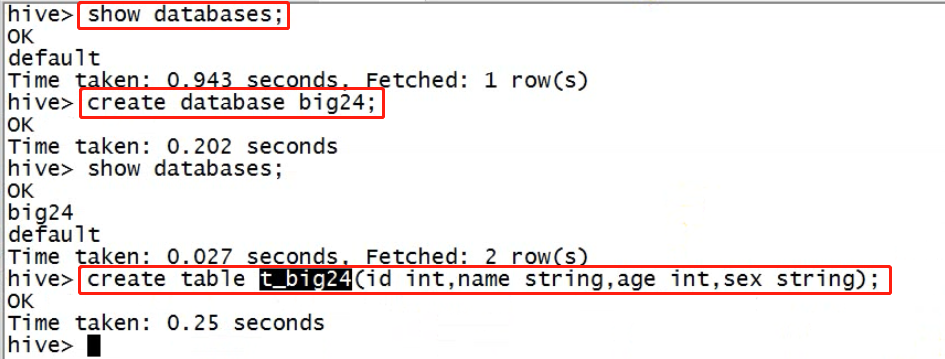
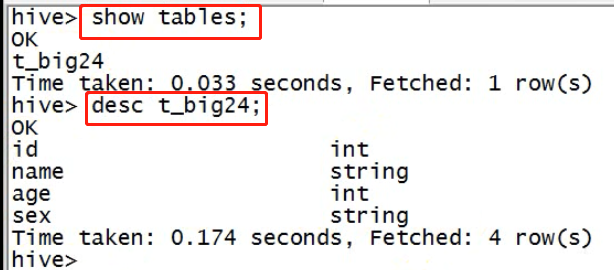
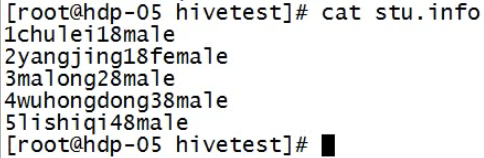
创建数据文件,上传到hdfs对应的目录下;

上传到hdfs
hive查询
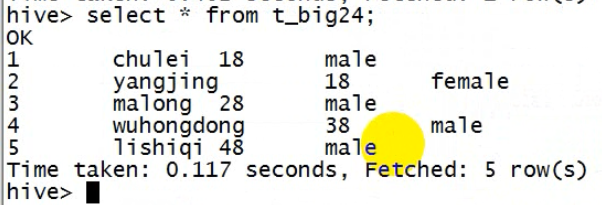
hive有hdfs的对应
hdfs中的user文件夹下有hive,hive下有warehouse(仓库),warehouse下有对应于表名的文件夹




现在看一下mysql中的元数据信息(内部工作机制)

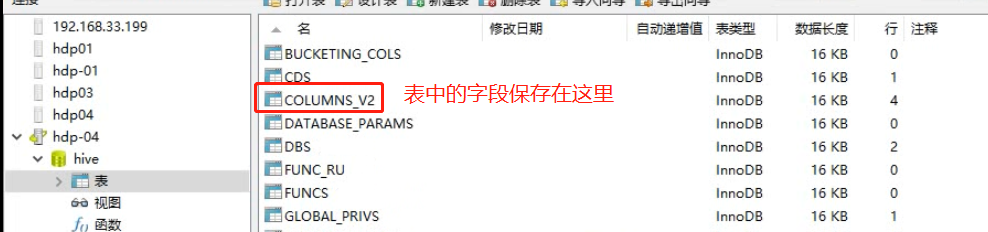
新建数据库的描述信息

新建数据表的描述信息

表中的字段信息

总结:
hive建立一张表的内在机制:
1、在mysql中记录这张表的定义;
2、在hdfs中创建目录;
3、只要把数据文件都到目录下,就可以在hive中进行查询了;
4、因此,不同的hive只要是操作的同一个mysq,同一个hdfs集群,看到的数据是一致的;
4.1、最基本使用方式
启动一个hive交互shell,写sql拿响应,写sql看结果,如上所示。
bin/hive
hive>
以下是一些便捷技巧设置
设置一些基本参数,让hive使用起来更便捷,比如:
1、让提示符显示当前库:
hive>set hive.cli.print.current.db=true;

2、显示查询结果时显示表的字段名称:
hive>set hive.cli.print.header=true;
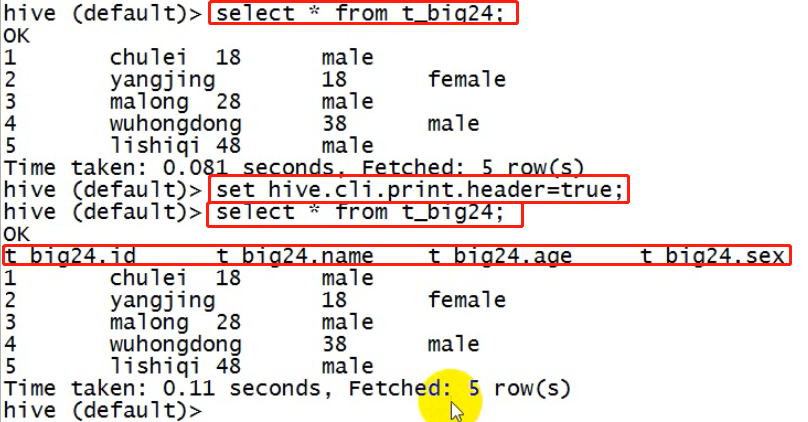
3、但是这样设置只对当前会话有效,重启hive会话后就失效,
解决办法:
在linux的当前用户主目录中,编辑一个.hiverc(隐藏文件)文件,将参数写入其中:
vi .hiverc(hive启动的时候会自动去当前用户目录下加载这个文件)
set hive.cli.print.header=true; set hive.cli.print.current.db=true;
4.2、启动hive服务使用
hive服务程序和hive本身不一样的;hive本身就是一个单机版的交互式程序;而hive服务可以在后台运行,它监听端口1000(默认);
此时有需要另个程序:
1、hive服务程序
2、hive服务的客户端程序

hive服务以及hive服务客户端

4.2.1、启动hive服务
1、前台启动
2、后台启动
# 前台方式 bin/hiveserver2
# 或者
bin/hiveserver2 -hiveconf hive.root.logger=DEBUG,console
上述启动,会将这个服务启动在前台,如果要启动在后台,则命令如下:
& 表示在后台运行,但是标准输出任然是在控制台
1 代表:标准输出
> 代表:重定向
2 代表:错误输出
jobs可以找到在后台运行的程序,然后 fg 1 将其切换到前台,ctrl ^ c 结束进程
若不想要任何的输入,可以将标准输入重定向到linux中的黑洞中。
&1 表示:引用
# nobup表示就算启动该进程的linux用户退出,该进程仍然运行
nohup bin/hiveserver2 1>/dev/null 2>&1 &
# 除了root用户,只要当前linux用户退出,该进程就会被杀死
bin/hiveserver2 1>/dev/null 2>&1 &
4.2.2、启动hive服务客户端beeline
1、连接命令 !connect
2、链接方式2,启动beeline时给出参数链接
3、输入hdfs用户密码认证
4、关闭连接,退出客户端
启动成功后,可以在别的节点上用beeline去连接
方式(1)
[root@hdp20-04 hive-1.2.1]# bin/beeline
回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2//mini1:10000
(hadoop01是hiveserver2所启动的那台主机名,端口默认是10000)
方式(2)
启动时直接连接:
bin/beeline -u jdbc:hive2://mini1:10000 -n root
接下来就可以做正常sql查询了
hive服务客户端连接hive服务用户身份:因为要访问hdfs,填入启动hdfs的用户身份,访问hdfs不需要密码

使用实例(界面比上面的单机版hive交互界面好多了)
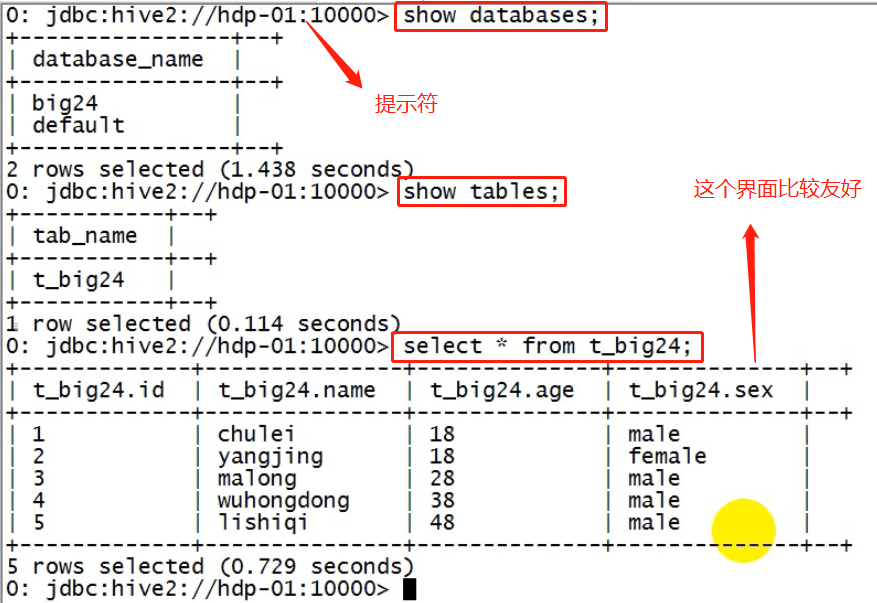
关闭connect,并没有退出客户端

退出hive服务的客户端

4.3、脚本化运行
大量的hive查询任务,如果用交互式shell(hive本身,或者hive服务的客户端都是交互式shell)来进行输入的话,显然效率及其低下,因此,生产中更多的是使用脚本化运行机制:
该机制的核心点是:hive可以用一次性命令的方式来执行给定的hql语句
[root@hdp20-04 ~]# hive -e "insert into table t_dest select * from t_src;"
然后,进一步,可以将上述命令写入shell脚本中,以便于脚本化运行hive任务,并控制、调度众多hive任务,示例如下:
vi t_order_etl.sh
#!/bin/bash hive -e "select * from db_order.t_order" hive -e "select * from default.t_user" hql="create table default.t_bash as select * from db_order.t_order" hive -e "$hql"
4.3.1、hive -e
hive -e:这是linux命令,而不是hive交互式shell,用来执行hive脚本;压根不会进入hive的命令提示符界面,运行结束后回到linux的命令提示符中,这样可以将很多hive操作,写入一个脚本中。
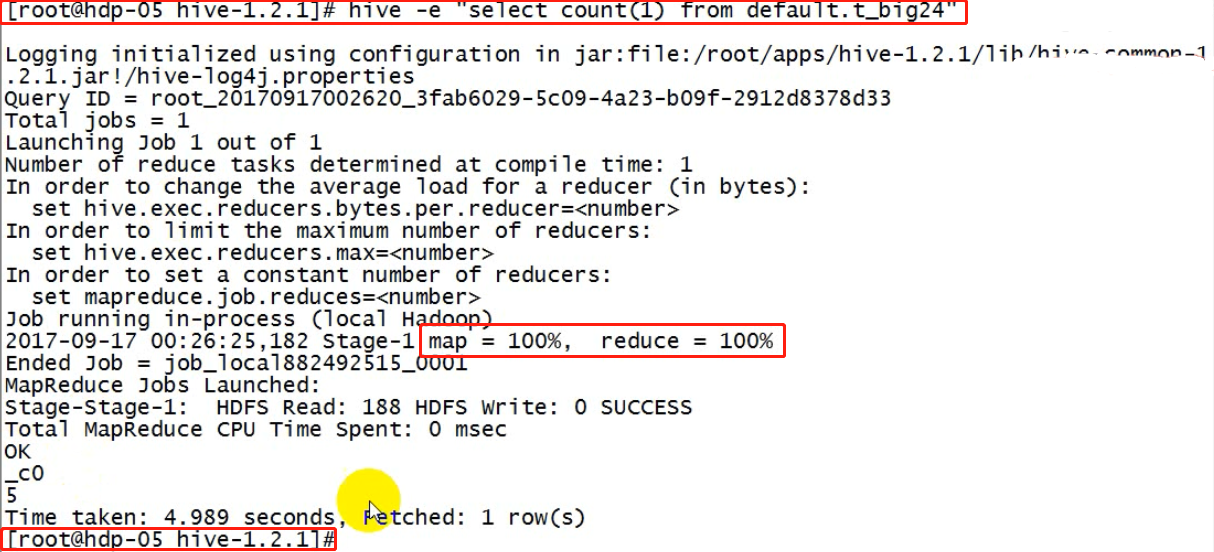
例如:
把一张表中的数据查出来,插入到另外的一张数据表中
sql语法:
create table tt_A(......) insert into tt_A select a,b,c form tt_B ....
新建脚本

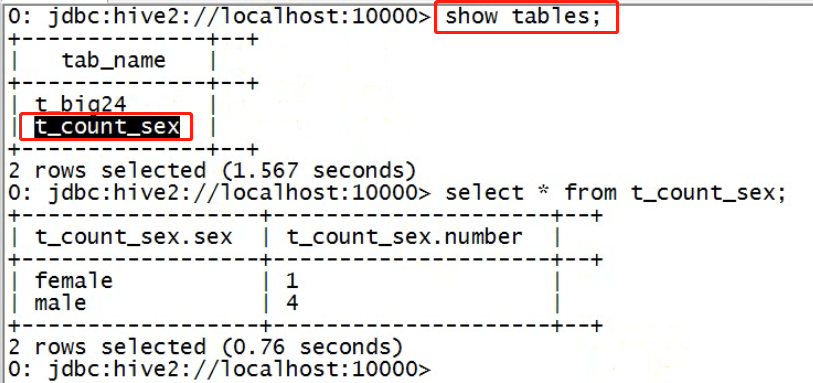
执行脚本

查看hive中的结果
查看hdfs中的结果


4.3.2、hive -f
如果要执行的hql语句特别复杂,那么,可以把hql语句写入一个文件:
vi x.hql
select * from db_order.t_order; select count(1) from db_order.t_user;
然后,用hive -f /root/x.hql 来执行
例子:
vi test.hql


4.3.3、区别
语法不一样
hive -e “sql脚本”
sql太复杂是可以将sql语句写到脚本中,用hive -f来执行。
共同点:
将hive查询语句写到shell脚本。
下面系统学习一下hive的语法(sql的语法极其相似)
5、hive建库建表与数据导入
5.1、建库
hive中有一个默认的库:
库名: default
库目录:hdfs://hdp20-01:9000/user/hive/warehouse
新建库:
create database db_order;
库名:库建好后,在hdfs中会生成一个库目录(库名.db):
库目录:hdfs://hdp20-01:9000/user/hive/warehouse/db_order.db
5.2、建表
5.2.1. 基本建表语句
use db_order; create table t_order(id string,create_time string,amount float,uid string);
表建好后,会在所属的库目录中生成一个表目录
/user/hive/warehouse/db_order.db/t_order
只是,这样建表的话,hive会认为表数据文件中的字段分隔符为 ^A
正确的建表语句为:
create table t_order(id string,create_time string,amount float,uid string) row format delimited fields terminated by ',';
这样就指定了,我们的表数据文件中的字段分隔符为 ","
5.2.2. 删除表
drop table t_order;
删除表的效果是:
hive会从元数据库中清除关于这个表的信息;
hive还会从hdfs中删除这个表的表目录;
细节:
内部表和外部表的删除过程略有不同
内部表:hdfs表目录在warehouse/dbname.db/tableName,数据会放在该目录下(默认:hive中建立的表是映射hdfs的warehouse下的数据)
外部表:外部表可以任意指定表目录的路径,hive里面直接建立一张表去映射该目录下的数据;hive各种操作生成的新表可以是内部表这样就会放到hive默认的数据仓库目录里面,
hdfs表目录不在warehouse;数据不放在该目录下,而是任意目录,因为我们的数据采集程序不一定会把数据直接采集到hdfs下的warehouse中。此时我们也需要在hive找建立一张元数据表和这个hdfs目录进行映射。
外部表的优点:
1、方便
2、避免移走数据从而干扰采集程序的逻辑。
5.2.3. 内部表与外部表
内部表(MANAGED_TABLE):表目录按照hive的规范来部署,位于hive的仓库目录/user/hive/warehouse中
外部表(EXTERNAL_TABLE):表目录由建表用户自己指定
create external table t_access(ip string,url string,access_time string) row format delimited fields terminated by ',' location '/access/log';
外部表和内部表的特性差别:
1、内部表的目录在hive的仓库目录中 VS 外部表的目录由用户指定
2、drop一个内部表时:hive会清除相关元数据,并删除表数据目录
3、drop一个外部表时:hive只会清除相关元数据;
外部表的作用:对接最原始的数据目录,至于后面查询生成的新表,用内部表就好。
一个hive的数据仓库,最底层的表,一定是来自于外部系统,为了不影响外部系统的工作逻辑,在hive中可建external表来映射这些外部系统产生的数据目录;
然后,后续的etl操作,产生的各种表建议用managed_table
演示:
原始数据
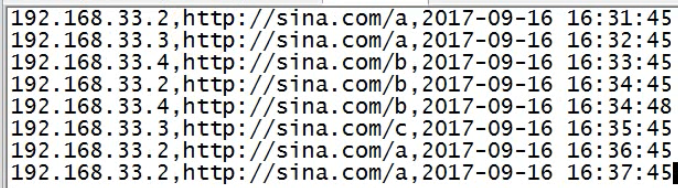
原始数据上传到hdfs非hive数据仓库目录


为了分析数据,需要在hive中建立一张外部表和数据目录进行映射(映射关系:靠元数据来描述)

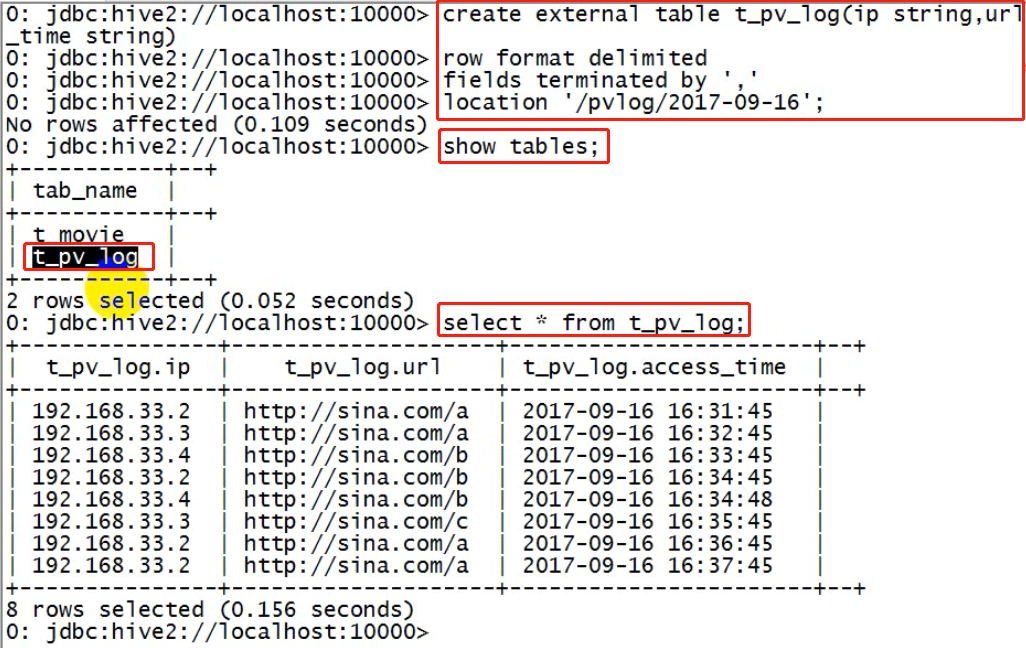
5.2.4. 分区表
分区表的实质是:在表目录中为数据文件创建分区子目录,以便于在查询时,MR程序可以针对分区子目录中的数据进行处理,缩减读取数据的范围。
比如,网站每天产生的浏览记录,浏览记录应该建一个表来存放,但是,有时候,我们可能只需要对某一天的浏览记录进行分析
这时,就可以将这个表建为分区表,每天的数据导入其中的一个分区;
当然,每日的分区目录,应该有一个目录名(分区字段)
5.2.4.1、一个分区字段的实例
示例如下:
1、创建带分区的表
create table t_access(ip string,url string,access_time string) partitioned by(dt string) row format delimited fields terminated by ',';
注意:分区字段不能是表定义中的已存在字段,否组会冲突;以为分区字段也会被当成数组字段值被返回,其实这是一个伪字段;
2、查看分区
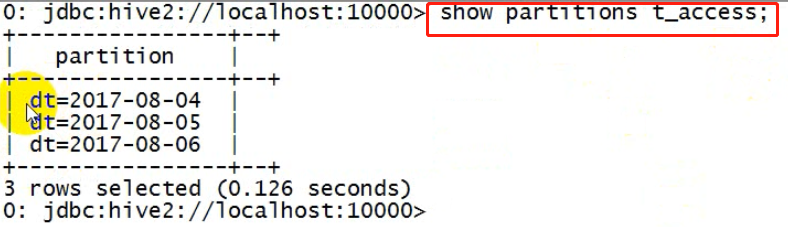
3、向分区中导入数据
hive提供了数据导入命令load,导入的时候需要指定分区,如果不指定直接导入主目录下,本质同hadoop的hdfs上传文件是一样的。
load data local inpath '/root/access.log.2017-08-04.log' into table t_access partition(dt='20170804'); load data local inpath '/root/access.log.2017-08-05.log' into table t_access partition(dt='20170805');
4、针对分区数据进行查询
分区表既可以查询分区数据,也可以查询全部数据。
a、统计8月4号的总PV:
select count(*) from t_access where dt='20170804';
实质:就是将分区字段当成表字段来用,就可以使用where子句指定分区了
b、统计表中所有数据总的PV:
select count(*) from t_access;
例子截图:分区字段也会被当成数组字段值被返回,其实这是一个伪字段。
创建表:

数据文件1

数据文件2
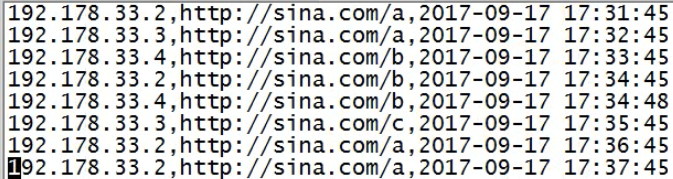
导入数据
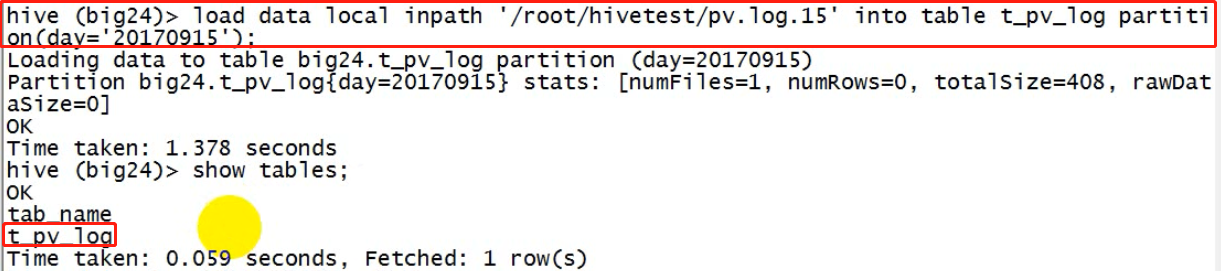
查询数据
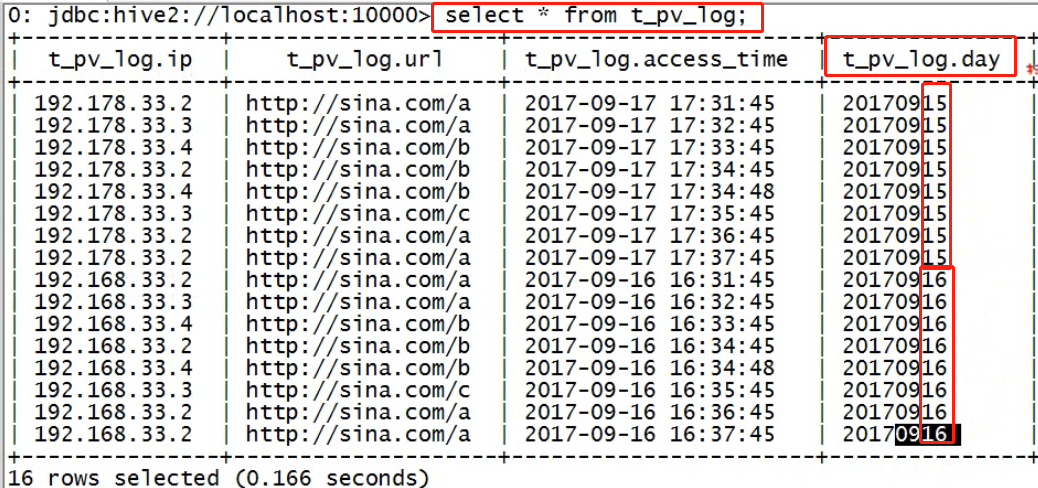
hdfs(主分区与字分区)主目录下的子目录

5.2.4.2、多个分区字段示例
建表:
create table t_partition(id int,name string,age int) partitioned by(department string,sex string,howold int) row format delimited fields terminated by ',';
导数据:
load data local inpath '/root/p1.dat' into table t_partition partition(department='xiangsheng',sex='male',howold=20);
5.2.5. CTAS建表语法
1、like
2、as
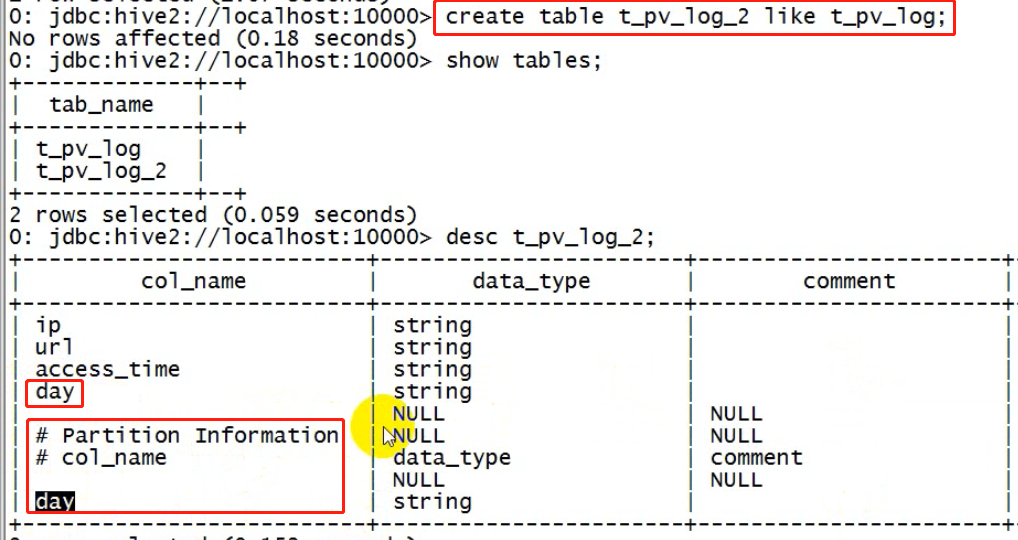
1、可以通过已存在表来建表:
create table t_user_2 like t_user;
新建的t_user_2表结构定义与源表t_user一致,但是没有数据
2、在建表的同时插入数据
创建的表的字段与查询语句的字段是一样的
create table t_access_user as select ip,url from t_access;
t_access_user会根据select查询的字段来建表,同时将查询的结果插入新表中

5.3. 数据导入导出
5.3.1 将数据文件导入hive的表
方式1:导入数据的一种方式:
手动用hdfs命令,将文件放入表目录;
方式2:在hive的交互式shell中用hive命令来导入本地数据到表目录
hive>load data local inpath '/root/order.data.2' into table t_order;
方式3:用hive命令导入hdfs中的数据文件到表目录
hive>load data inpath '/access.log.2017-08-06.log' into table t_access partition(dt='20170806');
注意:导本地文件和导HDFS文件的区别:
本地文件导入表:复制
hdfs文件导入表:移动
5.3.2. 将hive表中的数据导出到指定路径的文件
insert overwrite
1、将hive表中的数据导入HDFS的文件
insert overwrite directory '/root/access-data' row format delimited fields terminated by ',' select * from t_access;
2、将hive表中的数据导入本地磁盘文件
insert overwrite local directory '/root/access-data' row format delimited fields terminated by ',' select * from t_access limit 100000;
5.3.3. hive文件格式
HIVE支持很多种文件格式: SEQUENCE FILE | TEXT FILE | PARQUET FILE | RC FILE
create table t_pq(movie string,rate int) stored as textfile; create table t_pq(movie string,rate int) stored as sequencefile; create table t_pq(movie string,rate int) stored as parquetfile;
5.4. 数据类型
5.4.1. 数字类型
TINYINT (1-byte signed integer, from -128 to 127)
SMALLINT (2-byte signed integer, from -32,768 to 32,767)
INT/INTEGER (4-byte signed integer, from -2,147,483,648 to 2,147,483,647)
BIGINT (8-byte signed integer, from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807)
FLOAT (4-byte single precision floating point number)
DOUBLE (8-byte double precision floating point number)
示例:
create table t_test(a string ,b int,c bigint,d float,e double,f tinyint,g smallint)
5.4.2. 日期时间类型
TIMESTAMP (Note: Only available starting with Hive 0.8.0) 【本质是长整型】
DATE (Note: Only available starting with Hive 0.12.0)
示例,假如有以下数据文件:
1,zhangsan,1985-06-30 2,lisi,1986-07-10 3,wangwu,1985-08-09
那么,就可以建一个表来对数据进行映射
create table t_customer(id int,name string,birthday date) row format delimited fields terminated by ','; --然后导入数据 load data local inpath '/root/customer.dat' into table t_customer; --然后,就可以正确查询
5.4.3. 字符串类型
VARCHAR (Note: Only available starting with Hive 0.12.0)
CHAR (Note: Only available starting with Hive 0.13.0)
5.4.4. 混杂类型
BOOLEAN
BINARY (Note: Only available starting with Hive 0.8.0)
1,zhangsan,true 2,lisi,false create table t_p(id string,name string,marry boolean);
5.5.4. 复合类型(特殊)
数据不是一个值,而是一个集合。
5.4.5.4、array数组类型
arrays: ARRAY<data_type> (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
示例:array类型的应用
假如有如下数据需要用hive的表去映射:
move.dat
战狼2,吴京:吴刚:龙母,2017-08-16 三生三世十里桃花,刘亦菲:痒痒,2017-08-20
设想:如果主演信息用一个数组来映射比较方便
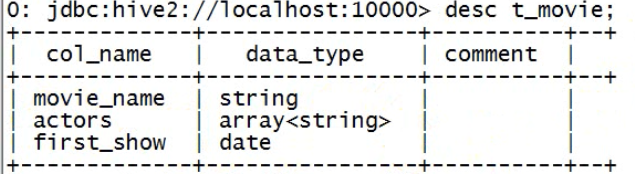
建表:
create table t_movie(moive_name string,actors array<string>,first_show date) row format delimited fields terminated by ',' collection items terminated by ':';
导入数据:
load data local inpath '/root/movie.dat' into table t_movie;
查询:
select * from t_movie;
select moive_name,actors[0] from t_movie;
-- xx演员参演的电影 select moive_name,actors from t_movie where array_contains(actors,'吴刚');
-- 每部电影有几个主演 select moive_name,size(actors) from t_movie;

5.4.5.2、map类型
maps: MAP<primitive_type, data_type> (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
1) 假如有以下数据:
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28 2,lisi,father:mayun#mother:huangyi#brother:guanyu,22 3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29 4,mayun,father:mayongzhen#mother:angelababy,26
可以用一个map类型来对上述数据中的家庭成员进行描述
2) 建表语句:
create table t_person(id int,name string,family_members map<string,string>,age int) row format delimited fields terminated by ',' collection items terminated by '#' map keys terminated by ':';
-- 导入数据 load data local inpath '/root/hivetest/fm.dat' into table t_family;
3) 查询
+--------------+----------------+----------------------------------------------------------------+---------------+--+ | t_family.id | t_family.name | t_family.family_members | t_family.age | +--------------+----------------+----------------------------------------------------------------+---------------+--+ | 1 | zhangsan | {"father":"xiaoming","mother":"xiaohuang","brother":"xiaoxu"} | 28 | | 2 | lisi | {"father":"mayun","mother":"huangyi","brother":"guanyu"} | 22 | | 3 | wangwu | {"father":"wangjianlin","mother":"ruhua","sister":"jingtian"} | 29 | | 4 | mayun | {"father":"mayongzhen","mother":"angelababy"} | 26 | +--------------+----------------+----------------------------------------------------------------+---------------+--+
-- 取map字段的指定key的值 select id,name,family_members['father'] as father from t_person;
-- 取map字段的所有key
-- 得到的是数组
select id,name,map_keys(family_members) as relation from t_person;
-- 取map字段的所有value
-- 得到的是数组 select id,name,map_values(family_members) from t_person;
select id,name,map_values(family_members)[0] from t_person;
-- 综合:查询有brother的用户信息 select id,name,father from (select id,name,family_members['brother'] as father from t_person) tmp where father is not null;
练习
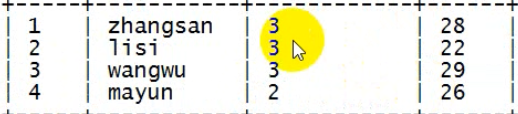
-- 查出每个人的 爸爸、姐妹 select id,name,family_members["father"] as father,family_members["sister"] as sister,age from t_family;

-- 查出每个人有哪些亲属关系 select id,name,map_keys(family_members) as relations,age from t_family;

-- 查出每个人的亲人名字 select id,name,map_values(family_members) as members,age from t_family;

-- 查出每个人的亲人数量 select id,name,size(family_members) as relations,age from t_family;
-- 查出所有拥有兄弟的人及他的兄弟是谁 -- 方案1:一句话写完 select id,name,age,family_members['brother'] from t_family where array_contains(map_keys(family_members),'brother');
-- 方案2:子查询 select id,name,age,family_members['brother'] from (select id,name,age,map_keys(family_members) as relations,family_members from t_family) tmp where array_contains(tmp.relations,'brother');

5.4.5.3、struct类型
带结构的数据,带有涵义,使用对象来描述,这里对象参照了C语言的机构体来表示类似对象的概念。
structs: STRUCT<col_name : data_type, ...>
1)假如有如下数据:
1,zhangsan,18:male:beijing 2,lisi,28:female:shanghai
其中的用户信息包含:年龄:整数,性别:字符串,地址:字符串
设想用一个字段来描述整个用户信息,可以采用struct
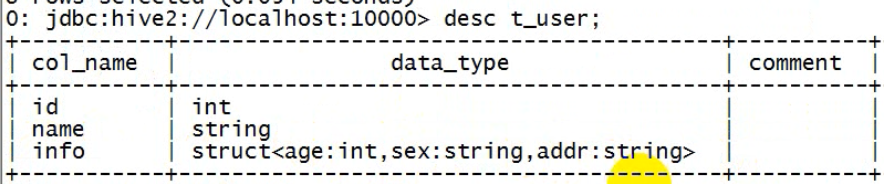
2)建表
drop table if exists t_user;
create table t_person_struct(id int,name string,info struct<age:int,sex:string,addr:string>) row format delimited fields terminated by ',' collection items terminated by ':';
3)查询
对象.属性
select * from t_person_struct;
select id,name,info.age from t_person_struct;
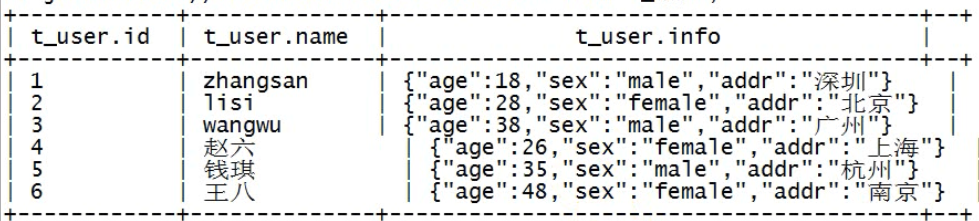
-- 查询每个人的id name和地址 select id,name,info.addr from t_user;
6、查询语法
提示:在做小数据量查询测试时,可以让hive将mrjob提交给本地运行器运行,可以在hive会话中设置如下参数:
hive> set hive.exec.mode.local.auto=true;
6.1. 基本查询示例
select * from t_access;
select count(*) from t_access;
select max(ip) from t_access;
sql中的单行函数与聚合函数
select substr(name,0,2), age from t_user;
select name, sex, max(age) from t_user group by sex;
6.2. 条件查询
select * from t_access where access_time<'2017-08-06 15:30:20'
select * from t_access where access_time<'2017-08-06 16:30:20' and ip>'192.168.33.3';
6.3. join关联查询示例
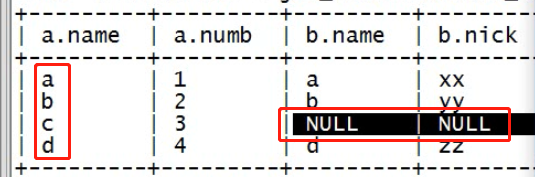
假如有a.txt文件
a,1 b,2 c,3 d,4
假如有b.txt文件
a,xx
b,yy
d,zz
e,pp
创建数据表,并导入数据
create table t_a(name string,numb int) row format delimited fields terminated by ','; create table t_b(name string,nick string) row format delimited fields terminated by ','; load data local inpath '/root/hivetest/a.txt' into table t_a; load data local inpath '/root/hivetest/b.txt' into table t_b;
进行各种join查询:
6.3.1、内连接
不指定连接条件
没有指定连接条件—笛卡尔积
Join连接表的时候没有指定两张表怎么链接,就会出现全连接,就是笛卡尔积
-- 笛卡尔积 select a.*,b.* from t_a a inner join t_b b;


指定链接条件
内连接:inner join(join)
-- 指定join条件 select a.*,b.* from t_a a join t_b b on a.name=b.name;

6.3.2、左外链接:left outer join(left join)
左外链接不加条件

左外链接加条件—左表中的全部数据都会出现在结果集当中。
-- 左外连接(左连接) select a.*,b.* from t_a a left outer join t_b b on a.name=b.name;
6.3.3、右外链接:right outer join(right join)
右链接不加条件

右外链接加连接条件
-- 3/ 右外连接(右连接) select a.*,b.* from t_a a right outer join t_b b on a.name=b.name;

6.3.4、全外链接—full outer join(full join)
没有连接条件

有链接条件—左右表的数据都有返回
-- 4/ 全外连接 select a.*,b.* from t_a a full outer join t_b b on a.name=b.name;

6.4. left semi join
hive中不支持exist/in子查询,可以用left semi join来实现同样的效果:
返回满足链接条件(有点像inner)的左表的数据,不返回右表的数据。
注意: left semi join的 select子句中,不能有右表的字段
-- 5/ 左半连接 select a.* from t_a a left semi join t_b b on a.name=b.name;


因为:from后面是数据来源,而左半链接压根不包含右表的数据。
6.5. group by分组聚合
select dt,count(*),max(ip) as cnt from t_access group by dt; select dt,count(*),max(ip) as cnt from t_access group by dt having dt>'20170804'; select dt,count(*),max(ip) as cnt from t_access where url='http://www.edu360.cn/job' group by dt having dt>'20170804';
注意: 一旦有group by子句,那么,在select子句中就不能有 (分组字段,聚合函数) 以外的字段
## 为什么where必须写在group by的前面,为什么group by后面的条件只能用having
因为,where是用于在真正执行查询逻辑之前过滤数据用的
having是对group by聚合之后的结果进行再过滤;
上述语句的执行逻辑:
1、where过滤不满足条件的数据
2、用聚合函数和group by进行数据运算聚合,得到聚合结果
3、用having条件过滤掉聚合结果中不满足条件的数据
(核心)
与函数有关
查看有哪些函数
show functions;
可以用select+函数来测试函数
select upper("abc");
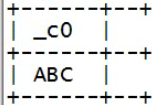
行内函数
表达式针对每一行运算一次
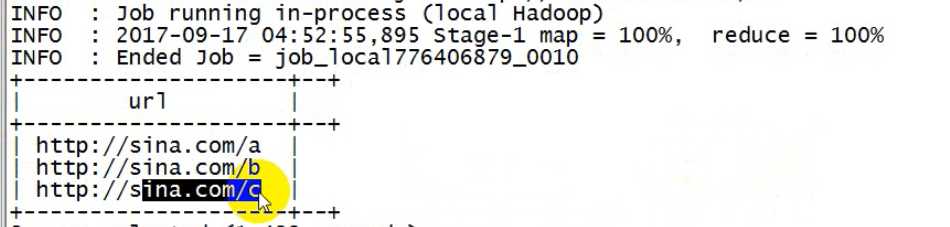
-- 针对每一行进行运算 select ip,upper(url),access_time -- 该表达式是对数据中的每一行进行逐行运算 from t_pv_log;
聚合函数
表达式针对每一组运算一次:一组得到唯一的一行结果,这里查询select ip,是不允许的,因为其结果不唯一。
下图是按照url分组后的数据;分组的目的是为了聚合;聚合结果必须唯一。
也就是:select 要求查询的字段,只能在一组数据中产生一个结果。一组产生一个结果。
或者说:select中出现的字段要么是分组字段,要么是聚合函数(对多条数据产生一个值)。

-- 求每条URL的访问总次数 select url,count(1) as cnts -- 该表达式是对分好组的数据进行逐组运算 from t_pv_log group by url;
max()也是聚合函数,对分组后的数据进行聚合
-- 求每个URL的访问者中ip地址最大的 select url,max(ip) from t_pv_log group by url;

-- 求每个用户访问同一个页面的所有记录中,时间最晚的一条 select ip,url,max(access_time) from t_pv_log group by ip,url;
此时数据分成了多组;
分组聚合综合示例


-- 分组聚合综合示例 -- 有如下数据 /* 192.168.33.3,http://www.edu360.cn/stu,2017-08-04 15:30:20 192.168.33.3,http://www.edu360.cn/teach,2017-08-04 15:35:20 192.168.33.4,http://www.edu360.cn/stu,2017-08-04 15:30:20 192.168.33.4,http://www.edu360.cn/job,2017-08-04 16:30:20 192.168.33.5,http://www.edu360.cn/job,2017-08-04 15:40:20 192.168.33.3,http://www.edu360.cn/stu,2017-08-05 15:30:20 192.168.44.3,http://www.edu360.cn/teach,2017-08-05 15:35:20 192.168.33.44,http://www.edu360.cn/stu,2017-08-05 15:30:20 192.168.33.46,http://www.edu360.cn/job,2017-08-05 16:30:20 192.168.33.55,http://www.edu360.cn/job,2017-08-05 15:40:20 192.168.133.3,http://www.edu360.cn/register,2017-08-06 15:30:20 192.168.111.3,http://www.edu360.cn/register,2017-08-06 15:35:20 192.168.34.44,http://www.edu360.cn/pay,2017-08-06 15:30:20 192.168.33.46,http://www.edu360.cn/excersize,2017-08-06 16:30:20 192.168.33.55,http://www.edu360.cn/job,2017-08-06 15:40:20 192.168.33.46,http://www.edu360.cn/excersize,2017-08-06 16:30:20 192.168.33.25,http://www.edu360.cn/job,2017-08-06 15:40:20 192.168.33.36,http://www.edu360.cn/excersize,2017-08-06 16:30:20 192.168.33.55,http://www.edu360.cn/job,2017-08-06 15:40:20 */ -- 建表映射上述数据 create table t_access(ip string,url string,access_time string) partitioned by (dt string) row format delimited fields terminated by ','; -- 导入数据 load data local inpath '/root/hivetest/access.log.0804' into table t_access partition(dt='2017-08-04'); load data local inpath '/root/hivetest/access.log.0805' into table t_access partition(dt='2017-08-05'); load data local inpath '/root/hivetest/access.log.0806' into table t_access partition(dt='2017-08-06'); -- 查看表的分区 show partitions t_access;
过滤数据用where,过滤分组用having
where直接对from后的数据源进行过滤,group by是对过滤后的数据进行分组,having是过滤分组后的组。
错误示例

正确示例
添加分组字段,或者添加聚合,或者添加常量表达式(一组就一个值)
select dt,max(url),count(1),max(ip) from t_access where url='http://www.edu360.cn/job' group by dt having dt>'2017-08-04';
select dt,url,count(1),max(ip) from t_access where url='http://www.edu360.cn/job' group by dt,url having dt>'2017-08-04';
-- 求8月4号以后,每天http://www.edu360.cn/job的总访问次数,及访问者中ip地址中最大的 select dt,'http://www.edu360.cn/job',count(1),max(ip) from t_access where url='http://www.edu360.cn/job' group by dt having dt>'2017-08-04'; -- 或者 -- 求8月4号以后,每天http://www.edu360.cn/job的总访问次数,及访问者中ip地址中最大的 select dt,'http://www.edu360.cn/job',count(1),max(ip) from t_access where url='http://www.edu360.cn/job' and dt>'2017-08-04' group by dt;

6.6. 子查询
把某一次查询当作一张新的表,在这张表的基础上进行(from,where等操作)再一次的查询。
-- 求8月4号以后,每天每个页面的总访问次数,及访问者中ip地址中最大的 select dt,url,count(1),max(ip) from t_access where dt>'2017-08-04' group by dt,url;
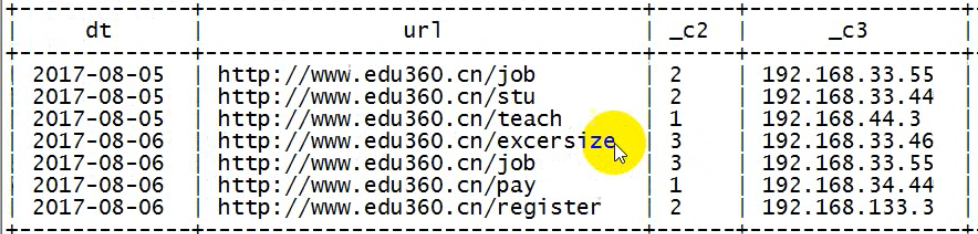
-- 求上述结果中(求8月4号以后,每天每个页面的总访问次数,及访问者中ip地址中最大的),且,只查询出总访问次数>2 的记录
-- 方式1: select dt,url,count(1) as cnts,max(ip) from t_access where dt>'2017-08-04' group by dt,url having cnts>2; -- 方式2:用子查询 select dt,url,cnts,max_ip from (select dt,url,count(1) as cnts,max(ip) as max_ip from t_access where dt>'2017-08-04' group by dt,url) tmp where cnts>2;

7. hive函数使用
-- 查看全部函数
show functions;
小技巧:测试函数的用法,可以专门准备一个专门的dual表
create table dual(x string);
insert into table dual values('');
其实:直接用常量来测试函数即可
select substr("abcdefg",1,3);
hive的所有函数手册:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inTable-GeneratingFunctions(UDTF)
数据库sql中的字符串角标是从1开始的。
7.1. 常用内置函数
7.1.1. 类型转换函数
cast(param1 as type)
cast与java中的类型强转类似(java中一般来讲这两种数据具有继承关系);与scala中的隐式转换类似(不要求继承关系,需要程序员提供转换逻辑,告知如何转换)
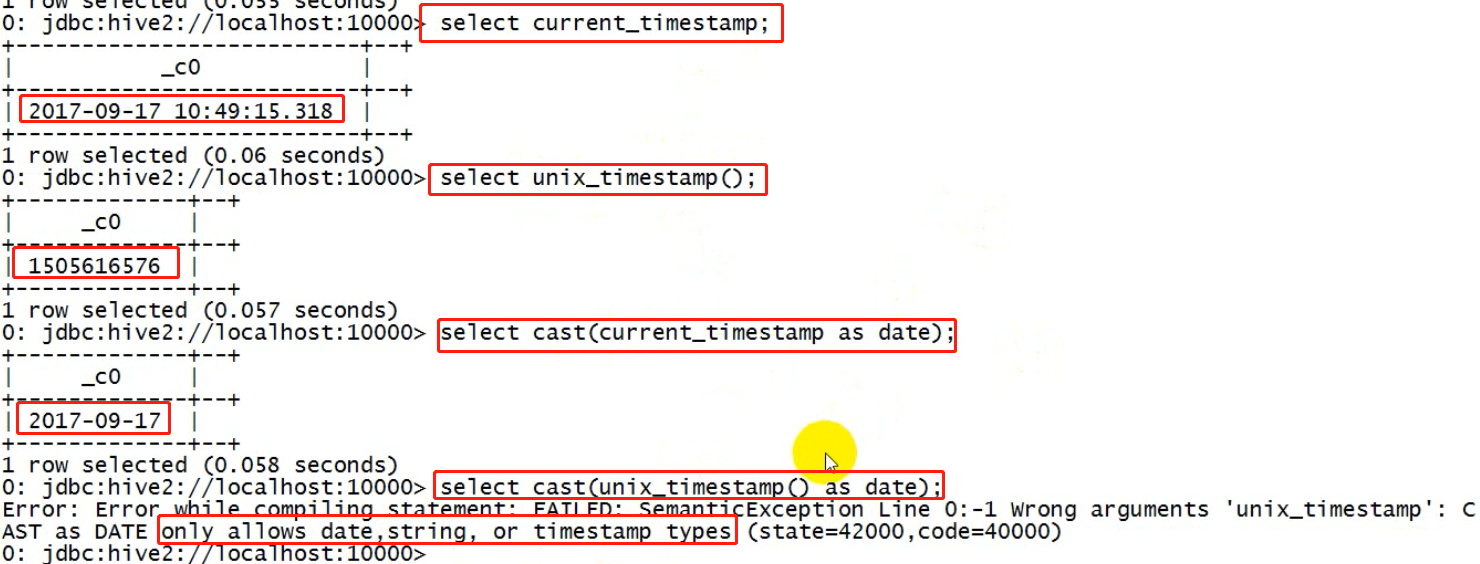
select cast("5" as int) from dual;
select cast("2017-08-03" as date) ;
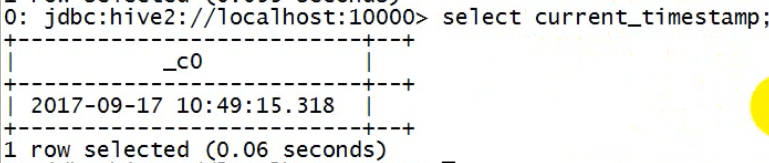
select cast(current_timestamp as date);
current_timestamp 是hive里的时间戳(java里的时间戳是一个长整型),其实就是一个常量
长整型时间戳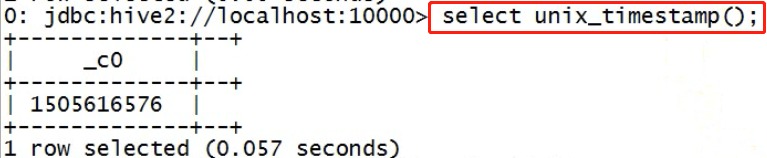
示例
1 1995-05-05 13:30:59 1200.3 2 1994-04-05 13:30:59 2200 3 1996-06-01 12:20:30 80000.5
create table t_fun(id string,birthday string,salary string) row format delimited fields terminated by ','; select id,cast(birthday as date) as bir,cast(salary as float) from t_fun;
例子:
7.1.2. 数学运算函数
select round(5.4); -- 5 select round(5.1345,3); --5.135 select ceil(5.4); // select ceiling(5.4); -- 6 select floor(5.4); -- 5 select abs(-5.4); -- 5.4 select greatest(3,5); -- 5 select greatest(3,5,6); -- 6 select least(3,5,6);

示例:
有表如下:

select greatest(cast(s1 as double),cast(s2 as double),cast(s3 as double)) from t_fun2;
结果:
+---------+--+ | _c0 | +---------+--+ | 2000.0 | | 9800.0 | +---------+--+
select max(age) from t_person; -- 聚合函数 凡是可以比大小的字段都可以用max select min(age) from t_person; -- 聚合函数
7.1.3. 字符串函数
substr
substr(string, int start) -- 截取子串 -- 类似java中的 substring(string, int start) -- 示例:
-- 下标从1开始
select substr("abcdefg",2); substr(string, int start, int len) --类似java中的 substring(string, int start, int len) --示例:
select substr("abcdefg",2,3);
mysql中特殊的函数(hive中没有): 按照给定的分隔符切割后,返回指定个数的结果

concat
concat_ws
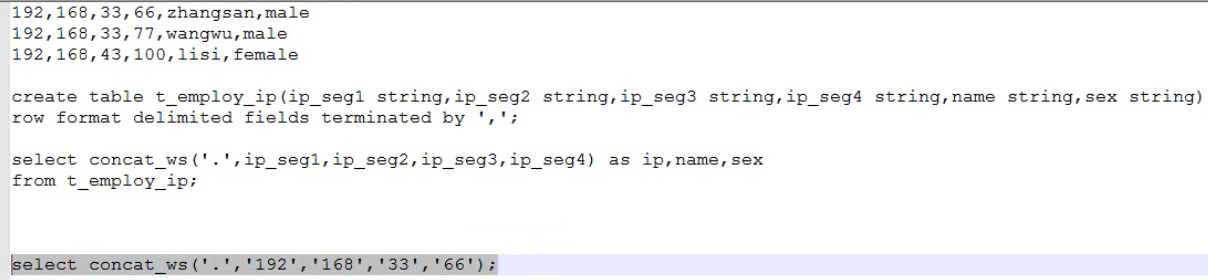
concat(string A, string B...) -- 拼接字符串 -- 中间带分隔符 concat_ws(string SEP, string A, string B...) --示例: select concat("ab","xy") from dual; select concat_ws(".","192","168","33","44") from dual;

length
length(string A) --示例: select length("192.168.33.44") from dual;
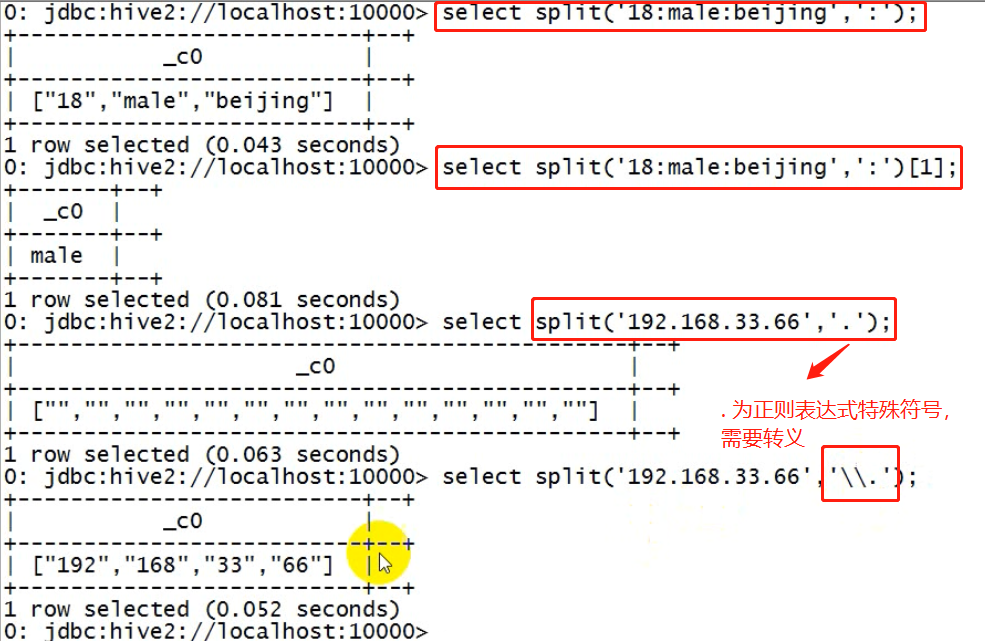
split
split(string str, string pat)
--示例:select split("192.168.33.44",".") ; 错误的,因为.号是正则语法中的特定字符 select split("192.168.33.44","\\.");
upper
upper(string str) --转大写
7.1.4. 时间函数
时间常量
select current_timestamp; -- 常量 select current_date; -- 常量
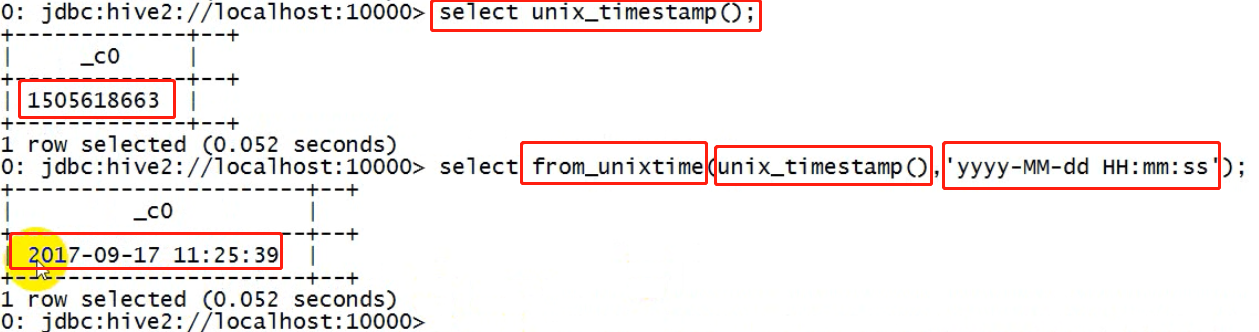
-- 取当前时间的毫秒数时间戳 select unix_timestamp();
转换
unix时间戳转字符串
-- unix时间戳转字符串 from_unixtime(bigint unixtime[, string format]) --示例: select from_unixtime(unix_timestamp()); select from_unixtime(unix_timestamp(),"yyyy/MM/dd HH:mm:ss");
字符串转unix时间戳
-- 字符串转unix时间戳 unix_timestamp(string date, string pattern) --示例: select unix_timestamp("2017-08-10 17:50:30"); select unix_timestamp("2017/08/10 17:50:30","yyyy/MM/dd HH:mm:ss");

将字符串转成日期date(不用给定格式,用标准格式)
-- 将字符串转成日期date select to_date("2017-09-17 16:58:32");
7.1.5. 表生成函数
函数可以生成一张表。
正常select可以生成一张表。
目的:将结构化的数据打散
7.1.5.1、行转列函数:explode()
假如有以下数据:
1,zhangsan,化学:物理:数学:语文 2,lisi,化学:数学:生物:生理:卫生 3,wangwu,化学:语文:英语:体育:生物
映射成一张表
create table t_stu_subject(id int,name string,subjects array<string>) row format delimited fields terminated by ',' collection items terminated by ':';
使用explode()对数组字段“炸裂”
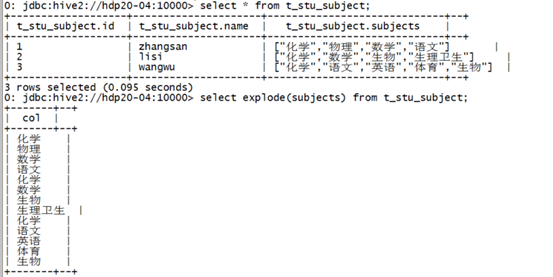
然后,我们利用这个explode的结果,来求去重的课程:
select distinct tmp.sub from (select explode(subjects) as sub from t_stu_subject) tmp;
7.1.5.2、表生成函数:lateral view
横向连接
select id,name,tmp.sub from t_stu_subject lateral view explode(subjects) tmp as sub;

理解: lateral view 相当于两个表在join
左表:是原表
右表:是explode(某个集合字段)之后产生的表
而且:这个join只在同一行的数据间进行
那样,可以方便做更多的查询:
比如,查询选修了生物课的同学
select a.id,a.name,a.sub from (select id,name,tmp.sub as sub from t_stu_subject lateral view explode(subjects) tmp as sub) a where sub='生物';
7.1.6. 集合函数
array_contains(Array<T>, value) 返回boolean值
-- 示例: select moive_name,array_contains(actors,'吴刚') from t_movie;
select array_contains(array('a','b','c'),'c');
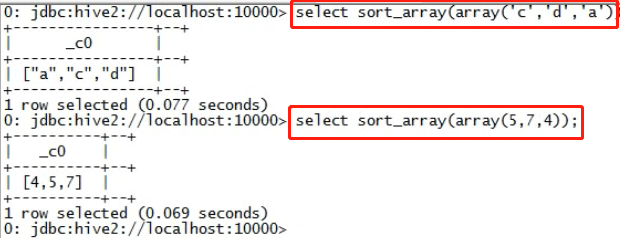
sort_array(Array<T>) 返回排序后的数组
--示例:
-- 直接使用构造函数进行模拟 select sort_array(array('c','b','a'));
-- 前面查询的是常量,与后面查询的表无关 select 'haha',sort_array(array('c','b','a')) as xx from (select 0) tmp;
直接使用构造函数进行模拟
size(Array<T>) 返回一个int值
--示例: select moive_name,size(actors) as actor_number from t_movie;
size(Map<K.V>) 返回一个int值
map_keys(Map<K.V>) 返回一个数组
map_values(Map<K.V>) 返回一个数组
7.1.7. 条件控制函数
7.1.7.1、case when
语法:
语法:
CASE [ expression ]
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
WHEN conditionn THEN resultn
ELSE result
END
示例: select id,name, case when age<28 then 'youngth' when age>27 and age<40 then 'zhongnian' else 'old' end from t_user;
0: jdbc:hive2://localhost:10000> select * from t_user; +------------+--------------+----------------------------------------+--+ | t_user.id | t_user.name | t_user.info | +------------+--------------+----------------------------------------+--+ | 1 | zhangsan | {"age":18,"sex":"male","addr":"深圳"} | | 2 | lisi | {"age":28,"sex":"female","addr":"北京"} | | 3 | wangwu | {"age":38,"sex":"male","addr":"广州"} | | 4 | 赵六 | {"age":26,"sex":"female","addr":"上海"} | | 5 | 钱琪 | {"age":35,"sex":"male","addr":"杭州"} | | 6 | 王二 | {"age":48,"sex":"female","addr":"南京"} | +------------+--------------+----------------------------------------+--+ 需求:查询出用户的id、name、年龄(如果年龄在30岁以下,显示年轻人,30-40之间,显示中年人,40以上老年人) select id,name, case when info.age<30 then '青年' when info.age>=30 and info.age<40 then '中年' else '老年' end from t_user;
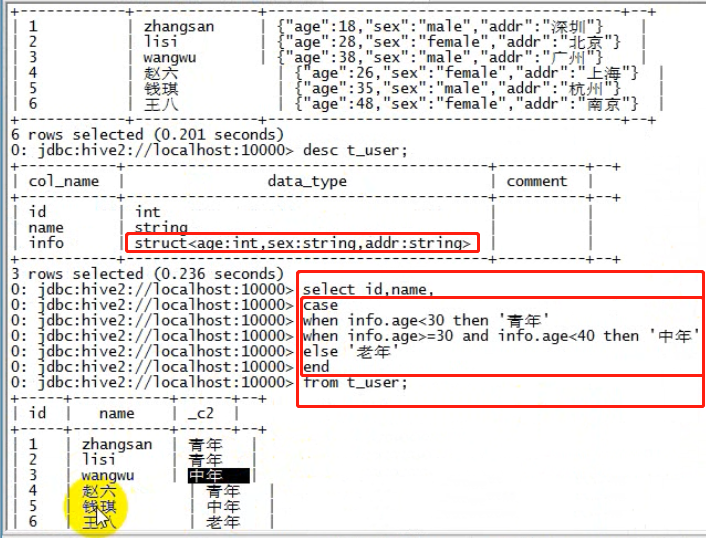
7.1.7.2、 IF
类似java里的三元表达式
select id,if(age>25,'working','worked') from t_user; select moive_name,if(array_contains(actors,'吴刚'),'好电影','rom t_movie;

7.1.8. json解析函数:表生成函数
hive中有很多自带的json解析函数。
json_tuple函数
示例:
select json_tuple(json,'movie','rate','timeStamp','uid') as(movie,rate,ts,uid) from t_rating_json;
产生结果:
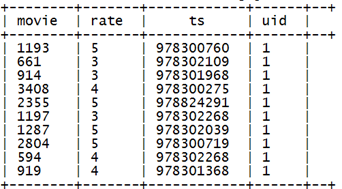
利用json_tuple从原始json数据表中,etl 出一个详细信息表:
create table t_rate2 as select json_tuple(json,'movie','rate','timeStamp','uid') as (movie, rate, ts, uid) from t_tatingjson;
json_tuple不会对嵌套的json进行解析,会将嵌套的json直接当作某一个字段的value返回,可以通过用自定以函数的方式对嵌套的json进行解析。
create table t_rate as select uid, movie, rate, year(from_unixtime(cast(ts as bigint))) as year, month(from_unixtime(cast(ts as bigint))) as month, day(from_unixtime(cast(ts as bigint))) as day, hour(from_unixtime(cast(ts as bigint))) as hour, minute(from_unixtime(cast(ts as bigint))) as minute, from_unixtime(cast(ts as bigint)) as ts from (select json_tuple(rateinfo,'movie','rate','timeStamp','uid') as(movie,rate,ts,uid) from t_json) tmp ;
7.1.9. 分析函数:row_number() over()——分组TOPN
业务场景:业务报表中常见
7.1.9.1、需求
有如下数据:
1,18,a,male 2,19,b,male 3,22,c,female 4,16,d,female 5,30,e,male 6,26,f,female
需要查询出每种性别中年龄最大的2条数据
分析过程
分组,排序,对每一组添加标记序号总段
-- 分组 -- 排序 5,30,e,male 2,19,b,male 1,18,a,male 6,26,f,female 3,22,c,female 4,16,d,female --对每一组添加标记序号字段 5,30,e,male,1 2,19,b,male,2 1,18,a,male,3 6,26,f,female,1 3,22,c,female,2 4,16,d,female,3
7.1.9.2、实现
使用row_number函数,对表中的数据按照性别分组,按照年龄倒序排序并进行标记
hql代码:
select id,age,name,sex, row_number() over(partition by sex order by age desc) as rank from t_rownumber
产生结果

然后,利用上面的结果,使用子查询,查询出rank<=2的即为最终需求
select id,age,name,sex from
(select id,age,name,sex, row_number() over(partition by sex order by age desc) as rank from t_rownumber) tmp
where rank<=2;
练习:求出电影评分数据中,每个用户评分最高的topn条数据
7.1.10、窗口分析函数 — sum() over()
作用:可以实现在窗口中进行逐行累加。
over() — 就是一个窗口:即 若干条数据
— 窗口如何表示 over (partition by uid order by month)
sum() — 表示在这个窗口中求和
— 窗口怎么求和,哪些行求和 sum (amount) over(partition by uid order by month rows between unbounded preceding and current row)
— 回溯前面所有行,到当前行
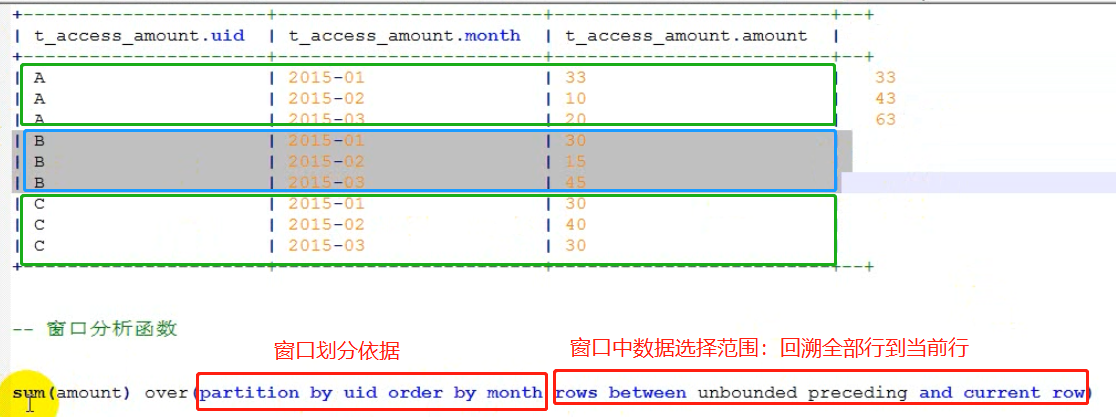
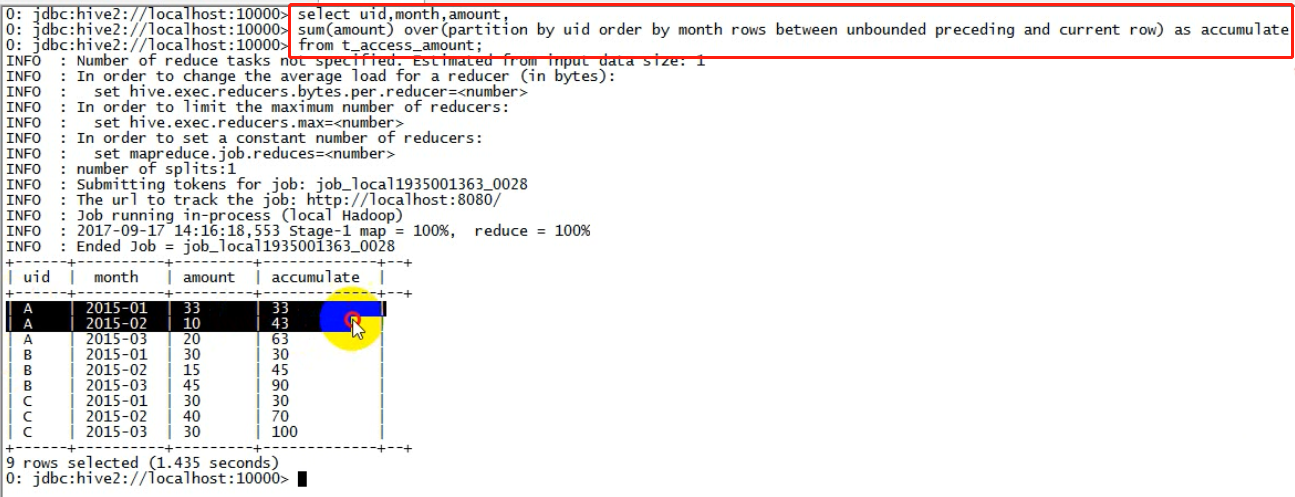
-- 窗口分析函数 sum() over() :可以实现在窗口中进行逐行累加 0: jdbc:hive2://localhost:10000> select * from t_access_amount; +----------------------+------------------------+-------------------------+--+ | t_access_amount.uid | t_access_amount.month | t_access_amount.amount | +----------------------+------------------------+-------------------------+--+ | A | 2015-01 | 33 | | A | 2015-02 | 10 | | A | 2015-03 | 20 | | B | 2015-01 | 30 | | B | 2015-02 | 15 | | B | 2015-03 | 45 | | C | 2015-01 | 30 | | C | 2015-02 | 40 | | C | 2015-03 | 30 | +----------------------+------------------------+-------------------------+--+ -- 需求:求出每个人截止到每个月的总额 select uid,month,amount, sum(amount) over(partition by uid order by month rows between unbounded preceding and current row) as accumulate from t_access_amount;
7.2. 自定义函数
7.2.1. 需求
需要对json数据表中的json数据写一个自定义函数,用于传入一个json,返回一个数据值的数组
json原始数据表:
有如下json数据:rating.json
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"} {"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"} {"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"} {"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
统计每个人的一共评阅了多少部电影。
解决思路:
1、常规方式,用mapreduce先对json数据格式进行解析,生成包含对应的字段hdfs文件如下图所示,利用hive进行映射,形成数据表,之后的便是常规操作。【mapreduce在数据清洗方面,有重要意义】

2、使用自定义函数
在hive中,可以使用自定义函数的方式,实现上述json数据格式到上图说是数据格式的转换。
可以用hive中的字符串函数,对么一条记录进行切割,拆分,这样太过繁琐,若是hive中有如下,对json解析的函数【实际是有的】,将会方便很多。
select myjson(json,1)
-- 自定义函数 /* 有如下json数据:rating.json {"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"} {"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"} {"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"} {"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"} 需要导入hive中进行数据分析 */ -- 建表映射上述数据 create table t_ratingjson(json string); load data local inpath '/root/hivetest/rating.json' into table t_ratingjson; 想把上面的原始数据变成如下形式: 1193,5,978300760,1 661,3,978302109,1 914,3,978301968,1 3408,4,978300275,1 思路:如果能够定义一个json解析函数,则很方便了 create table t_rate as select myjson(json,1) as movie,cast(myjson(json,2) as int) as rate,myjson(json,3) as ts,myjson(json,4) as uid from t_ratingjson; 解决: hive中如何定义自己的函数: 1、先写一个java类(extends UDF,重载方法public C evaluate(A a,B b)),实现你所想要的函数的功能(传入一个json字符串和一个脚标,返回一个值) 2、将java程序打成jar包,上传到hive所在的机器 3、在hive命令行中将jar包添加到classpath : 窗口关闭,函数失效。 hive>add jar /root/hivetest/myjson.jar; 4、在hive命令中用命令创建一个函数叫做myjson,关联你所写的这个java类 hive> create temporary function myjson as 'cn.edu360.hive.udf.MyJsonParser';
7.2.2、 实现步骤
1、开发java的UDF类
public class ParseJson extends UDF{ // 重载 :返回值类型 和参数类型及个数,完全由用户自己决定 // 本处需求是:给一个字符串,返回一个数组 public String[] evaluate(String json,int index) { String[] split = json.split("\""); // split[3],split[7],split[11],split[15] return split[4*index - 1]; } }
2、打jar包
在eclipse中使用export即可
3、上传jar包到运行hive所在的linux机器
4、在hive中创建临时函数:
- hive类环境中添加jar
- 关联自定义函数和java类
在hive的提示符中:
hive> add jar /root/jsonparse.jar;
然后,在hive的提示符中,创建一个临时函数:
hive>CREATE TEMPORARY FUNCTION jsonp AS 'cn.edu360.hdp.hive.ParseJson';
5、开发hql语句,利用自定义函数,从原始表中抽取数据插入新表
create table t_rate as select myjson(json,1) as movie,cast(myjson(json,2) as int) as rate,myjson(json,3) as ts,myjson(json,4) as uid from t_ratingjson;
注:临时函数只在一次hive会话中有效,重启会话后就无效
如果需要经常使用该自定义函数,可以考虑创建永久函数:
拷贝jar包到hive的类路径中:
cp wc.jar apps/hive-1.2.1/lib/
创建function:
create function pfuncx as 'com.doit.hive.udf.UserInfoParser';
删除函数,包括临时函数和永久函数:
DROP TEMPORARY FUNCTION [IF EXISTS] function_name DROP FUNCTION[IF EXISTS] function_name
8. 综合查询案例
8.1. 用hql来做wordcount
有以下文本文件:
hello tom hello jim hello rose hello tom tom love rose rose love jim jim love tom love is what what is love
需要用hive做wordcount
-- 建表映射 create table t_wc(sentence string);
-- 导入数据 load data local inpath '/root/hivetest/xx.txt' into table t_wc;

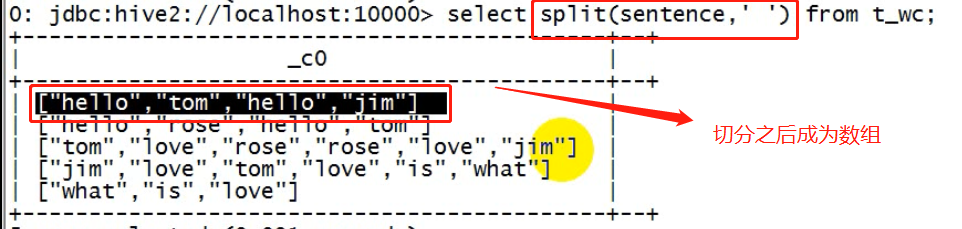
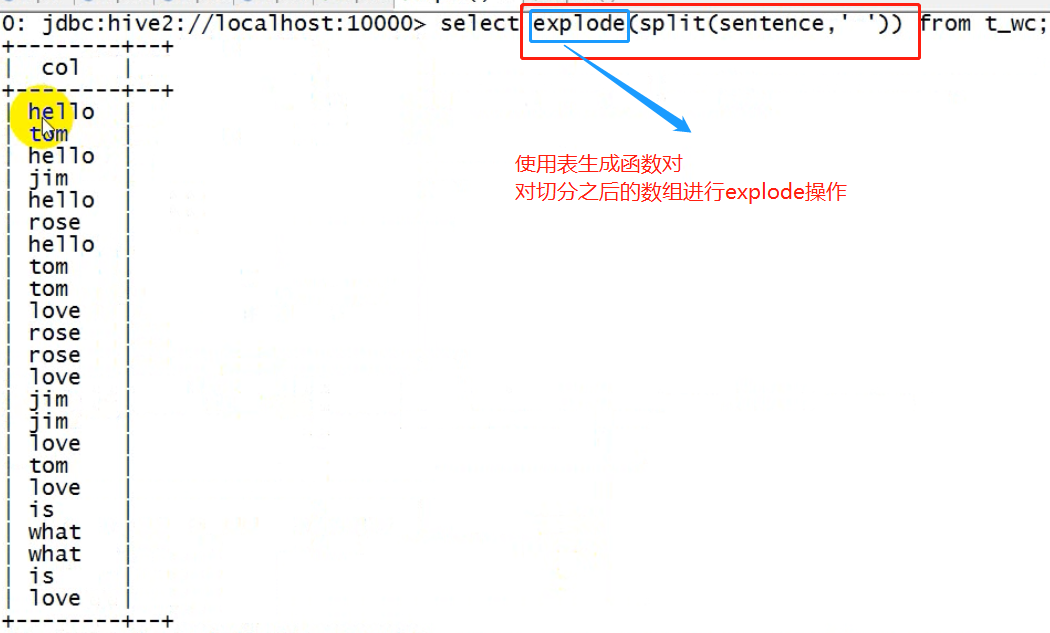
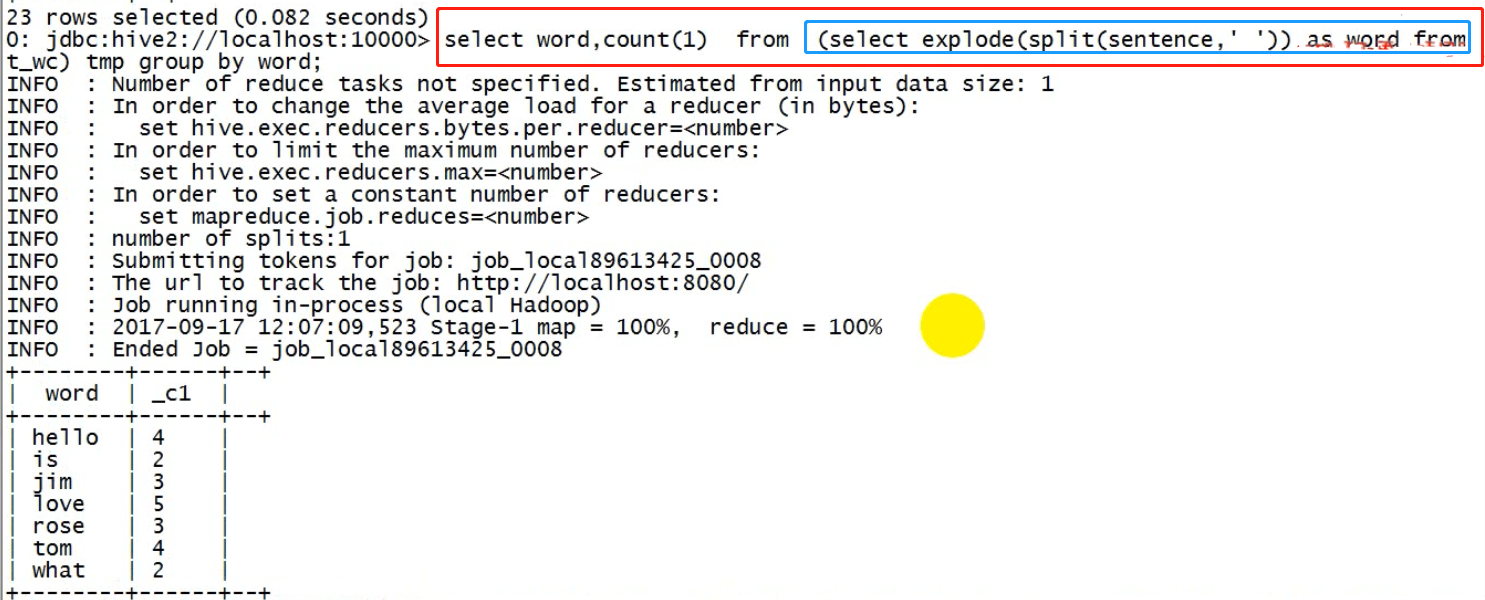


hql答案:
SELECT word ,count(1) as cnts FROM ( SELECT explode(split(sentence, ' ')) AS word FROM t_wc ) tmp GROUP BY word order by cnts desc ;
8.2. 级联报表查询
思路:
1、传统sql方法:分组聚合自连接
2、窗口分析函数
有如下数据:
A,2015-01,5 A,2015-01,15 B,2015-01,5 A,2015-01,8 B,2015-01,25 A,2015-01,5 C,2015-01,10 C,2015-01,20 A,2015-02,4 A,2015-02,6 C,2015-02,30 C,2015-02,10 B,2015-02,10 B,2015-02,5 A,2015-03,14 A,2015-03,6 B,2015-03,20 B,2015-03,25 C,2015-03,10 C,2015-03,20
建表映射
create table t_access_times(username string,month string,counts int) row format delimited fields terminated by ',';
需要要开发hql脚本,来统计出如下累计报表:
|
用户 |
月份 |
月总额 |
累计到当月的总额 |
|
A |
2015-01 |
33 |
33 |
|
A |
2015-02 |
10 |
43 |
|
A |
2015-03 |
30 |
73 |
|
B |
2015-01 |
30 |
30 |
|
B |
2015-02 |
15 |
45 |
|
|
|
|
|
分析1:
sql中的最长常见函数无非是
1、行级别函数:对每一行都执行同样的操作
2、聚合函数:对别一组(大于等于1行)的数据进行通向的操作
到目前为止没有接触到,下一行的结果需要使用上一行的数据的函数,比如上述的逐月累加求和,其实这可以用窗口分析函数来做
**、窗口分析函数
解决方案1:
1、先按照用户、月份分组聚合求出每个用户的月总金额;
2、将上述数据表自身join
3、筛选出 合适的结果
4、求和
第2步结果
A 2015-01 33 A 2015-01 33 A 2015-01 33 A 2015-02 10 A 2015-01 33 A 2015-03 30 A 2015-02 10 A 2015-01 33 A 2015-02 10 A 2015-02 10 A 2015-02 10 A 2015-03 30 A 2015-03 30 A 2015-01 33 A 2015-03 30 A 2015-02 10 A 2015-03 30 A 2015-03 30 B 2015-01 30 B 2015-01 30 B 2015-01 30 B 2015-02 15 B 2015-02 15 B 2015-01 30 B 2015-02 15 B 2015-02 15
第3步结果,筛掉右侧日期大于左侧的数据
A 2015-01 33 A 2015-01 33 A 2015-02 10 A 2015-01 33 A 2015-02 10 A 2015-02 10 A 2015-03 30 A 2015-01 33 A 2015-03 30 A 2015-02 10 A 2015-03 30 A 2015-03 30 B 2015-01 30 B 2015-01 30 B 2015-02 15 B 2015-01 30 B 2015-02 15 B 2015-02 15
求解过程:
准备数据,导入数据
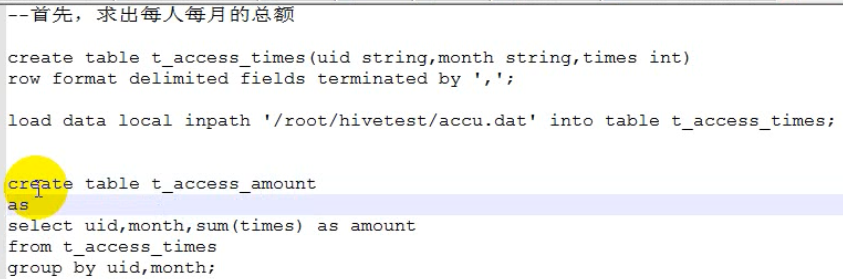
求出没人每月的总额
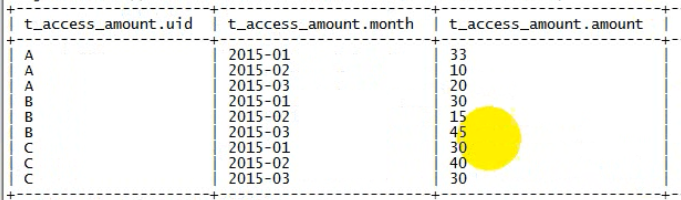
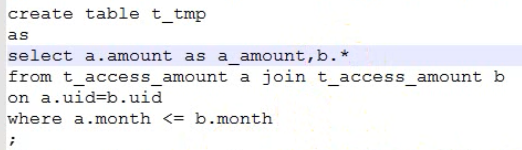
将总额表自链接

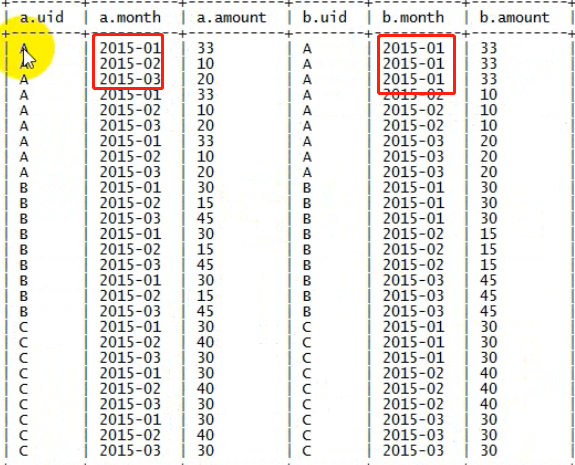
筛选数据
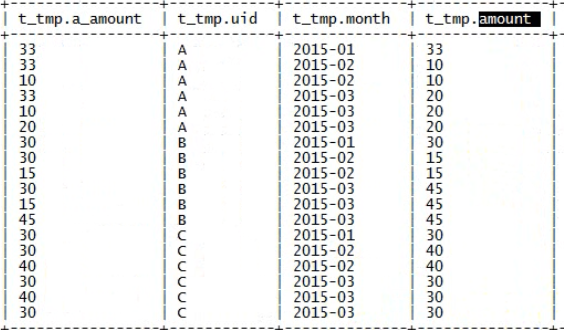
按照右侧表的id和month进行分组聚合


方案2:窗口分析函数
思想:把若干条数据作为一个窗口进行分析。
over()— 表示一个窗口
现在已经有了按用户、月份分组聚合的结果。

-- 窗口分析函数 -- 窗口的定义: -- 针对窗口中数据的操作 -- 哪些数据 select uid, month, amount, sum (amount) over(partition by uid order by month rows between unbounded preceding and current row) as accumulate from t_access_amount;
8.3、日新,日活统计
需求描述
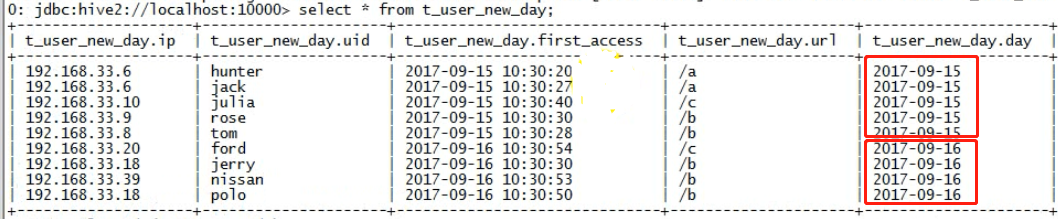
假如有一个web系统,每天生成以下日志文件: 2017-09-15号的数据: 192.168.33.6,hunter,2017-09-15 10:30:20,/a 192.168.33.7,hunter,2017-09-15 10:30:26,/b 192.168.33.6,jack,2017-09-15 10:30:27,/a 192.168.33.8,tom,2017-09-15 10:30:28,/b 192.168.33.9,rose,2017-09-15 10:30:30,/b 192.168.33.10,julia,2017-09-15 10:30:40,/c 2017-09-16号的数据: 192.168.33.16,hunter,2017-09-16 10:30:20,/a 192.168.33.18,jerry,2017-09-16 10:30:30,/b 192.168.33.26,jack,2017-09-16 10:30:40,/a 192.168.33.18,polo,2017-09-16 10:30:50,/b 192.168.33.39,nissan,2017-09-16 10:30:53,/b 192.168.33.39,nissan,2017-09-16 10:30:55,/a 192.168.33.39,nissan,2017-09-16 10:30:58,/c 192.168.33.20,ford,2017-09-16 10:30:54,/c 2017-09-17号的数据: 192.168.33.46,hunter,2017-09-17 10:30:21,/a 192.168.43.18,jerry,2017-09-17 10:30:22,/b 192.168.43.26,tom,2017-09-17 10:30:23,/a 192.168.53.18,bmw,2017-09-17 10:30:24,/b 192.168.63.39,benz,2017-09-17 10:30:25,/b 192.168.33.25,haval,2017-09-17 10:30:30,/c 192.168.33.10,julia,2017-09-17 10:30:40,/c -- 需求: 建立一个表,来存储每天新增的数据(分区表) 统计每天的活跃用户(日活)(需要用户的ip,用户的账号,用户访问时间最早的一条url和时间) 统计每天的新增用户(日新)
8.3.1、sql开发
1、建表映射日志数据
create table t_web_log ( ip string, uid string, access_time string, url string ) partitioned by (day string) row format delimited fields terminated by ',' ;
2、建表保存日活数据
没有指定行分隔符,默认是\001不可见字符
create table t_user_active_day ( ip string, uid string, first_access string, url stirng partitioned by(day string);
3、导入数据
load data local inpath '/root/hivetest/log.15' into table t_web_log partition ( day='2017-09-15' ); load data local inpath '/root/hivetest/log.16' into table t_web_log partition ( day='2017-09-16' ); load data local inpath '/root/hivetest/log.17' into table t_web_log partition ( day='2017-09-17' );
4、指标统计
4.1、日活:
每日的活跃用户:在该天内,用户的第一次访问记录
192.168.33.6,hunter,2017-09-15 10:30:20,/a,1 192.168.33.7,hunter,2017-09-15 10:30:26,/b,2
insert into table t_user_active_day partition(day='2017-09-15') select ip, uid ,access_time, url from (select ip, uid, access_time, url row_number() over(partition by uid order by access_time) as rn from t_web_log where day = '2017-09-15') tmp where rn=1;
默认分隔符为\001[不可见]


4.2、日新:
统计每天的新增用户:
思路如下:利用当日活跃用户(日活是一个去重结果)
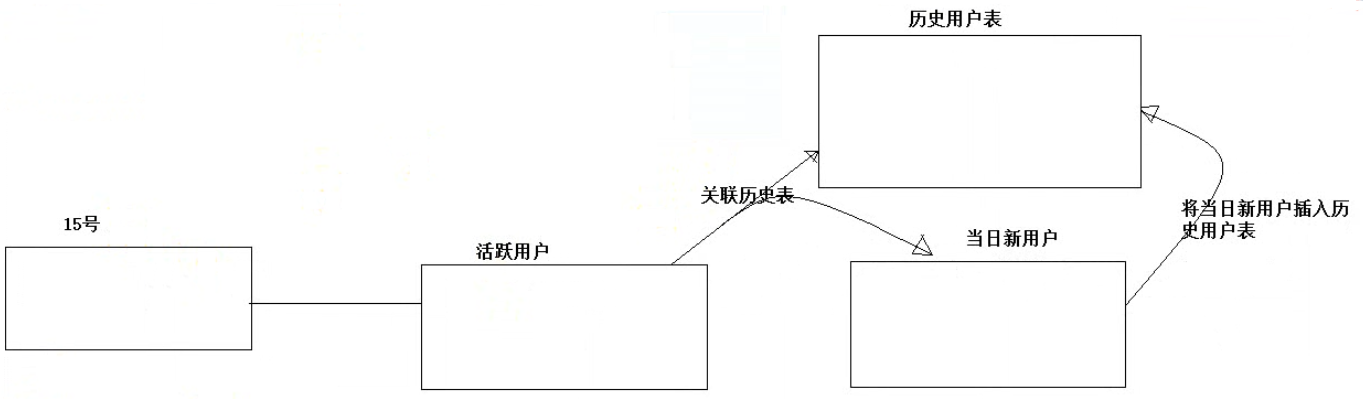
一、建表
1、历史用户表
每个用户的uid是唯一的,只保存uid就可以。
create table t_user_history(uid string);
2、新增用户表
新怎用户表里保存的数据可以和日活表一样(活跃用户表里存的数据,可能一部分是新用户,一部分是老用户)—表结构一致,存的数据不一样而已。
create table t_user_new_day like t_user_active_day;
二、操作
1、将当日活跃用户跟历史用户表关联,找出那些在历史用户表中尚未不存在的用户—当日新增用户
-- 关联日活表和历史用户表 select a.ip, a.uid, a.access_time, a.url, b.uid from t_user_active_day a left join t_user_history b on a.uid = b.uid where a.day = '2017-09-15';
2、求出15号的新用户,并插入到新用户表中
-- 求出15号的新用户,并插入到新用户表中 insert into table t_user_new_day partition(day='2017-09-15') select ip, uid, access_time, url from (select a.ip, a.uid, a.access_time, a.url, b.uid as b_uid from t_user_active_day a left join t_user_history b on a.uid = b.uid where a.day = '2017-09-15';) tmp where tmp.b_uid is null;
3、将15号的新用户插入到历史表中
-- 将15号的新用户,插入到历史用户表中 insert into table t_user_history select uid from t_user_new_day where day='2017-09-15';
下图是维护的历史用户表

下图是每日新用户表
设计脚本,自动获取日期,执行

设置date日期。

#!/bin/bash day_str=`date -d '-1 day' +'%Y-%m-%d'` # 若是没有配置过hive环境变量 echo "准备处理 $day_str 的数据..." hive_exec=/root/apps/hive-1.2.1/bin/hive # 求日活 HQL_user_active_day=" insert into table big24.t_user_active_day partition(day=\"$day_str\") select ip, uid ,access_time, url from (select ip, uid, access_time, url row_number() over(partition by uid order by access_time) as rn from big24.t_web_log where day = \"$day_str\") tmp where rn=1 " # 执行 echo "executing sql:" echo $HQL_user_active_day $hive_exec -e "$HQL_user_active_day" # 求日新 HQL_user_new_day=" insert into table big24.t_user_new_day partition(day=\"$day_str\") select ip, uid, access_time, url from (select a.ip, a.uid, a.access_time, a.url, b.uid as b_uid from big24.t_user_active_day a left join big24.t_user_history b on a.uid = b.uid where a.day = \"$day_str\") tmp where tmp.b_uid is null " # 执行 $hive_exec -e "$HQL_user_new_day" # 插入历史数据表 HQL_user_new_to_history=" insert into big24.table t_user_history select uid from big24.t_user_new_day where day=\"$day_str\" " # 执行 $hive_exec -e "$HQL_user_new_to_history"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号