ActiveMQ集群整体认识
出自:https://segmentfault.com/a/1190000014592517
前言
最终需要掌握 Replicated LevelDB Store部署方式,这种部署方式是基于ZooKeeper的。
集群分为两种方式:
1.伪集群:集群节点都搭在一台机器上
2.真集群:集群节点分布在多台机器上
更多详细:真集群与伪集群的区别
一、为什么使用集群?
-
实现
高可用,以排除单点故障引起的服务中断。 -
实现
负载均衡,以提升效率为更多的客户提供服务。
二、ActiveMQ集群部署方式
ActiveMQ集群的部署方式主要有下面2种:
-
Broker Clusters 模式:实现负载均衡,多个broker之间同步消息,已达到服务器负载的可能。
-
Master Slave 模式:实现高可用,当主服务器宕机时,备用服务器可以立即补充,以保证服务的继续。
2.1、 失效转移连接
该策略用于控制消费者的访问,这是我们在编写代码的时候要使用的连接方式。一个消费者连接到多个broker集群的中的一个broker,当该broker出问题时,消费者自动连接到其他一个正常的broker。消费者使用 failover 协议来连接broker,通常叫做 失效转移(也叫故障转移,断线重连机制,FailOver)策略,语法如下:failover:(uri1,uri2,...,uriN)?transportOptions
1.uri:消息服务器的地址 2.transportOptions参数说明: randomize:默认为 true ,表示在URI列表中选择URL连接时是否采用随机策略。 initialReconnectDelay:默认为10,单位为毫秒,表示一次尝试重连之间等待的时间。 maxReconnectDelay:默认 30000,单位毫秒,最长重连的时间间隔。
例如:
<!-- 1. client使用failover协议来与有效的master交互 2. master地址在前,slavew 在后,randomize 为 false让 Client优先与master通信 3. 如果 master 失效,failover协议将会尝试与slave建立链接,并依此重试 --> failover:(tcp://localhost:61616,tcp://localhost:61617)?randomize=false
下面考虑一下master slave + broker cluster环境下客户端的失效转移链接。
举例,客户端:
<property name="brokerURL" value="failover:(tcp://uri1:port, tcp://uri2:port, tcp://uri3:port, tcp://uri4:port, tcp://uri5:port, tcp://uri6:port)?startupMaxReconnectAttempts=2" />
uri1~uri3构成一个高可用集群,其中只有一个broker是master ,另外的两个broker是slave,slave不接受客户端的请求,只是对master的数据进行同步(个人觉得不接受客户端的请求太过分了,最起码可以将请求转发给maser也行啊),客户端若没有采用失效转移机制而直接去链接集群中的某一个broker;如下:
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://192.168.8.201:61616");
此时很有可能你链接到的是slave,而不是master,而salve是完全不接受客户端的请求,更不会好心肠的给你转发给master,所以必然的结果就是链接超时。如果运气好直接链接的就是master,那是没有问题的,客户端可以得到响应。
采用failover,会在提供的uri列表中不断尝试链接,在同一次尝试过程中对于无效的联机,只会访问一次。
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("failover:(tcp://192.168.8.201:61616,tcp://192.168.8.202:61616,tcp://192.168.8.203:61616)?startupMaxReconnectAttempts=2");
基于此,uri1~uri3构成一个高可用集群,uri4~uri6构成另外一个高可用集群,组内高可用,组件负载均衡。无论是producer还是consumer一定会在failover的指导下,链接到某一组的master上,若链接到同一组的master,消息的产生和消费就是顺利成章。若producer和consumer了解到不同组的master,则consumer所链接的master会通过network of broker机制去producer所在集群中请求消息,然后返回给consumer。
2.2、 Broker Clusters 部署
Broker-Cluster的部署方式就可以解决负载均衡的问题。Broker-Cluster部署方式中,各个broker通过网络互相连接,并共享queue,保证消息同步。

各个broker进行消息同步使用的是NetworkConnection (网络连接器),主要用于配置各个broker之间的网络通讯方式,用于服务器传递信息。 分为静态连接器和动态连接器。
主要目的是实现负载均衡,提高消息处理能力。
一个client1连接broker1发送消息,另一个client2连接broker2消费消息,这时就需要将broker1上的消息路由到broker2上。而当broker2上的consumer挂了,也需要将消息转发到其它的有consumer的broker上,避免消息大量堆积无法处理,目前的解决方案是Network of Broker。
官方资料:http://activemq.apache.org/networks-of-brokers.html
2.2.1、静态连接器
官网资料:http://activemq.apache.org/static-transport-reference.html
所谓静态发现:就是将所有已知的broker uri连接时手工进行配置,对client端uri地址做相应修改。
关于failover:
当一个client连接到某个broker,而这个broker挂了,客户端就需要自动连接到网络上其它已知的broker上。
AMQ使用failover协议实现该功能,但需要在client连接时将所有broker以硬编码的形式进行配置。
AMQ的failover协议官方资料:http://activemq.apache.org/failover-transport-reference.html
<networkConnectors> <networkConnector uri="static:(tcp://127.0.0.1:61617,tcp://127.0.0.1:61618)"/> </networkConnectors>
2.2.2、动态连接器
官网资料:http://activemq.apache.org/static-transport-reference.html
所谓动态发现,就是部署前不需要知道所有AMQ实例的uri地址,只要进行相关配置,启动后让AMQ自己检测。
需要修改AMQ配置文件,同时client端连接uri地址也要相应修改。
<!-- 网络连接器 --> <networkConnectors> <networkConnector uri="multicast://default"/> </networkConnectors> <!-- 传输连接器 --> <transprotConnectors> <transprotConnector uri="tcp://localhost:0" discoveryUri="multicast://default" /> </transprotConnectors>
静态连接器过于局限,动态连接器可随意扩展服务器连接。
2.3、Master Slave 部署(主从)
只需要掌握 Replicated LevelDB Store。
该
Master Slave主从方案所实现的高可用架构具体内容可参考:ActiveMQ与HA架构(master/slave)
通过部署多个broker实例,选举产生一个master和多个slave,master宕机后由slave接管服务来达到高可用性。Master-Slave的方式虽然能解决多服务热备的高可用问题,但无法解决负载均衡和分布式的问题。Broker Cluster的部署方式刚好可以解决负载均衡的问题。一般两者结合使用。
这里主要介绍2种配置方案(一般只使用):
2.3.1、Share storage master slave(共享存储)
包括:Shared File System Master slave 和 JDBC Store Master Slave 两种模式
此模式中Master和Slave的数据是共享的(相当于共享同一个数据库),当master失效后,slave会自动接管服务,无需手动进行数据的copy与同步,因为master存储数据之后,这些数据在任何时候对slave都是可见的。master与slave之间,通过共享文件的“排他锁”或者分布式排他锁(ZooKeeper)来决定Broker的状态与角色,获取锁权限的Broker作为master,其它的Broker则作为slave。如果master失效,它必将失去锁权限,那么其它的slave将通过锁竞争来选举新master,没有获取锁权限的Broker作为slave,并等待锁的释放(间歇性尝试获取锁)。
- Shared File System Master Slave模式(只适合单台主机部署,不适合多台主机部署)
这种方式是最常用的模式,架构简单,可靠实用。我们只需要一个SAN文件系统即可。使用文件系统来共享数据文件,多个Broker共享同一个文件系统。配置如下: <!-- 假设在本地启动两个broker,配置文件activemq.xml 里面的持久化文件目录都设置成同一个即可。 这里默认使用的kahaDB ,你也可以用levelDB,不推荐AMQDB --> <persistenceAdapter> <kahaDB directory="/opt/activemq/shared_kahadb" /> </persistenceAdapter>
- JDBC Store Master Slave模式(适合多台主机部署)
数据存储用的是数据库(MySQL/Oracle等),相对于日志文件而言,JDBC Store通常认为是低效的。配置如下: ``` <broker brokerName="broker-locahost-0"> <persistenceAdapter> <jdbcPersistenceAdapter dataSource="#mysql-ds"/> </persistenceAdapter> </broker> <!-- 配置jdbc数据库连接 --> <bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"> <property name="driverClassName" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/activemq?relaxAutoCommit=true"/> <property name="username" value="root"/> <property name="password" value="root"/> <property name="poolPreparedStatements" value="true"/> </bean> ```
2.3.2、Replicated LevelDB Store(使用ZooKeeper协调多个Broker)
基于复制的LevelDB Store模式是ActiveMQ 5.9以后新增的特性,这是ActiveMQ全力打造的HA存储引擎。 一般都使用这种方式。由于利用zk 进行配置管理,可以方便监控,同时配置也相对简单。
使用ZooKeeper(集群)注册所有的ActiveMQ Broker。只有其中的一个Broker可以对外提供服务(也就是Master节点),其他的Broker处于待机状态,被视为Slave。如果Master因故障而不能提供服务,则利用ZooKeeper的内部选举机制会从Slave中选举出一个Broker充当Master节点,继续对外提供服务。
Replicated LevelDB Store 主备的方式是用Apache Zookeeper从一组broker中选举一个Master。然后所有的Slave 与Master同步,与Master保持一致。
Replicated LevelDB Store使用Zookeeper来调度集群中的节点变成master。被选举的master broker启动并接受客户端请求连接。其他broker进入到slave模式,并且连接到master上同步他的持久化状态。slave节点不接受客户端的连接。所有的持久化操作被复制到slave节点上。如果master挂掉,最后被更新的节点立刻成为master。挂掉的节点可以重新连接到集群中,成为slave节点
由于基于ZooKeeper(通常ZooKeeper集群至少需要3个实例,才能保证ZooKeeper本身的高可用性),所以Broker最低需要3个。activemq.xml中配置如下:
<!-- 持久化的部分为ZooKeeper集群连接地址--> <persistenceAdapter> <replicatedLevelDB directory="${activemq.data}/leveldb" replicas="3" bind="tcp://0.0.0.0:0" zkAddress="10.10.2.20:2181,10.10.2.21:2181,10.10.2.22:2181" zkPassword="password" zkPath="/opt/activemq/leveldb-stores" hostname="10.10.2.20" /> </persistenceAdapter> <!-- # directory: 存储数据的路径 # replicas:集群中的节点数【(replicas/2)+1公式表示集群中至少要正常运行的服务数量】,3台集群那么允许1台宕机, 另外两台要正常运行 # bind:当该节点成为master后,它将绑定已配置的地址和端口来为复制协议提供服务。还支持使用动态端口。只需使用tcp://0.0.0.0:0进行配置即可,默认端口为61616。 # zkAddress:ZK的ip和port, 如果是集群,则用逗号隔开(这里作为简单示例ZooKeeper配置为单点, 这样已经适用于大多数环境了, 集群也就多几个配置) # zkPassword:当连接到ZooKeeper服务器时用的密码,没有密码则不配置。 # zkPah:ZK选举信息交换的存贮路径,启动服务后actimvemq会到zookeeper上注册生成此路径 # hostname: ActiveMQ所在主机的IP # 更多参考:http://activemq.apache.org/replicated-leveldb-store.html -->
三、未知的名称或服务
不知道为什么机器名没有加入hosts文件中,会造成既无法通过web链接到activemq集群中某一台broker的后台报503错,也无法是的正常代码链接到broker。明明activemq集群均正常启动,却显示无法连接或者链接被拒绝。
javax.jms.JMSException: Could not connect to broker URL: tcp://192.168.8.202:61616. Reason: java.net.ConnectException: Connection refused: connect
503错误解决:
1、查看机器名
[root@itcast168 bin]# cat /etc/sysconfig/network NETWORKING=yes HOSTNAME=centos6.5
2、修改host文件
[root@itcast168 bin]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 centos6.5 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 [root@itcast168 bin]#
四、 Master Slave和Broker Cluster结合使用(常用方式)

Master Slave只能实现高可用性,不能实现负载均衡。Broker Cluster 只能实现负载均衡,不能实现高可用性。Master Slave和Broker Cluster 结合使用可以实现高可用和负载均衡,如下图:
按 A->B->C 顺序启动节点服务。
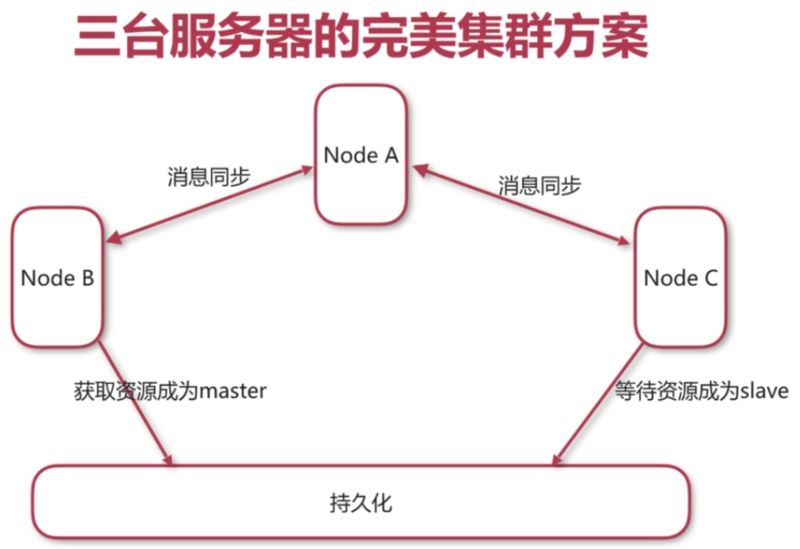
这个集群是综合了Broker Cluster和master/slave两种基本集群方式,其中master/slave(B和C)是基于共享存储实现的。A和B组成消息同步,A和C组成消息同步是为实现均衡负载,B和C组成master/slave是为了实现高可用。
-
如果A宕机,集群退化成标准master/slave集群,只是了失去负载均衡能力。
-
如果B宕机,C会继续提供服务,集群退化成Broker Cluster集群,失去高可用能力。
-
如果C宕机也会失去高可用能力(同B)。
ABC无论哪一台宕机,集群都不会崩溃,但是需要迅速恢复。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号