
RabbitMQ
引入
微服务一旦拆分,必然涉及到服务之间的相互调用,目前我们服务之间调用采用的都是基于OpenFeign的调用。这种调用中,调用者发起请求后需要等待服务提供者执行业务返回结果后,才能继续执行后面的业务。也就是说调用者在调用过程中处于阻塞状态,因此我们称这种调用方式为同步调用,也可以叫同步通讯。但在很多场景下,我们可能需要采用异步通讯的方式,为什么呢?
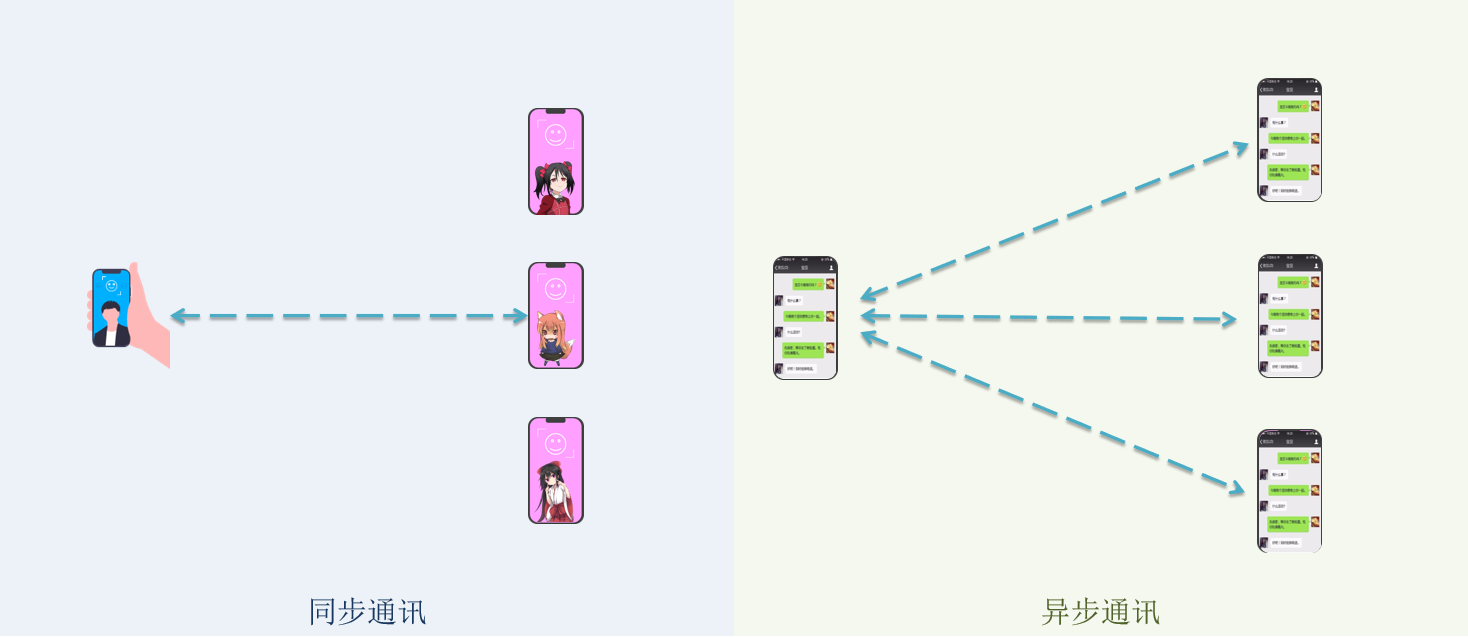
同步通信:如同视频聊天,对方立即能看到,等不到结果会等待阻塞。因此同一时刻你只能跟一个人打视频电话
异步通信:就如同发微信聊天,双方的交互不是实时的,你不需要立刻给对方回应。因此你可以多线操作,同时跟多人聊天
两种方式各有优劣,打电话可以立即得到响应,但是你却不能跟多个人同时通话。发微信可以同时与多个人收发微信,但是往往响应会有延迟。
所以,如果我们的业务需要实时得到服务提供方的响应,则应该选择同步通讯(同步调用)。而如果我们追求更高的效率,并且不需要实时响应,则应该选择异步通讯(异步调用)。
同步调用的方式我们已经学过了,之前的OpenFeign调用就是。但是:
- 异步调用又该如何实现?
- 哪些业务适合用异步调用来实现呢?
我们带着问题接着看,后面课程分为了两篇讲解
基础篇
初始MQ
同步调用
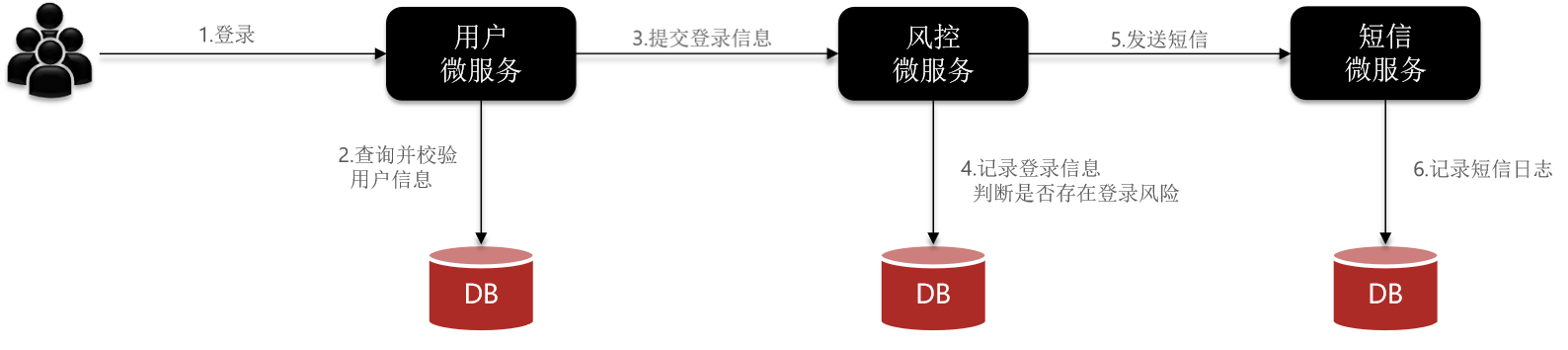
以余额支付功能为例分析同步调用的优缺点:
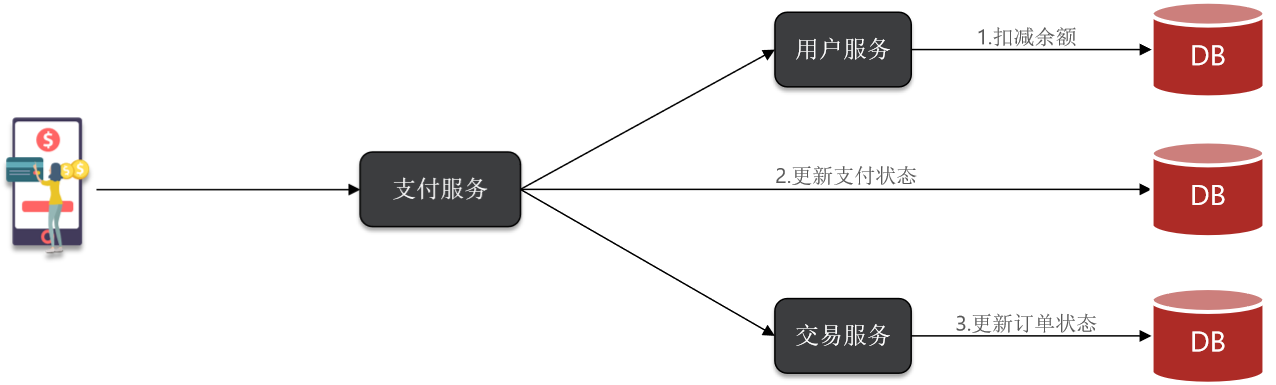
目前我们采用的是基于OpenFeign的同步调用,也就是说业务执行流程是这样的:
- 支付服务需要先调用用户服务完成余额扣减
- 然后支付服务自己要更新支付流水单的状态
- 然后支付服务调用交易服务,更新业务订单状态为已支付
三个步骤依次执行。
优势:
- 时效性强,等待到结果后才返回。【只有知道了扣减余额的结果,才能更新支付状态,应该用同步调用】
劣势:
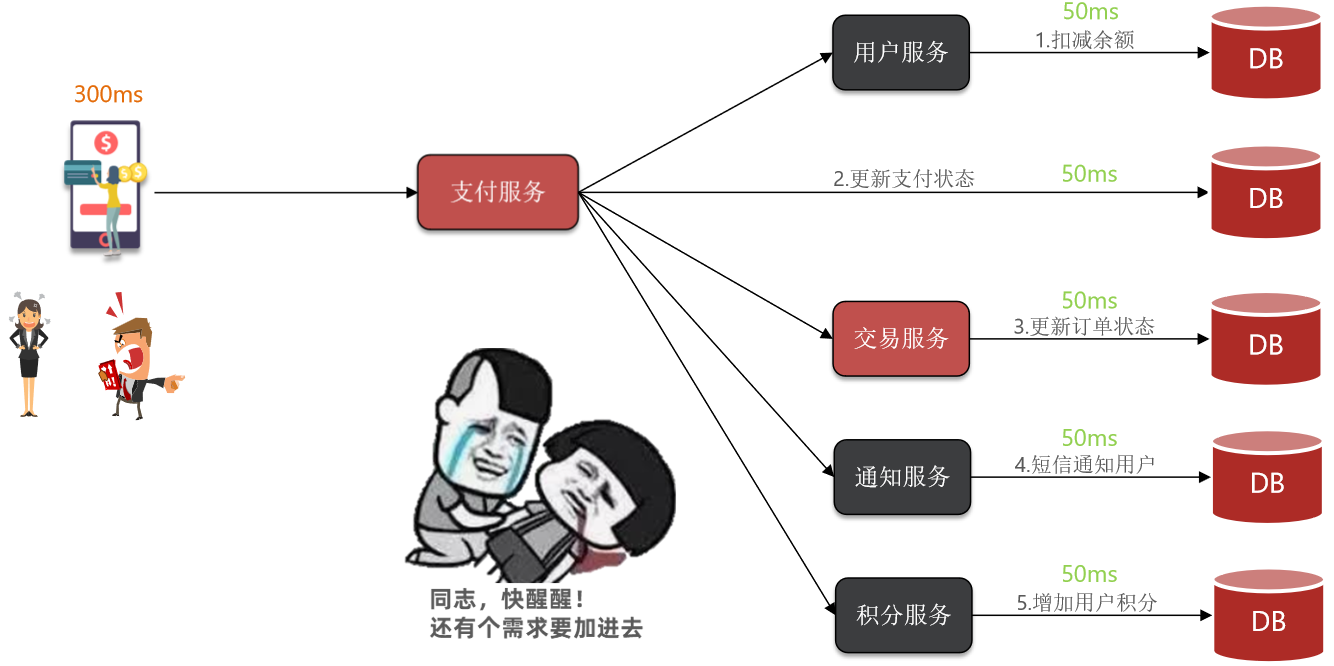
-
拓展性差:但支付完,需要修改交易订单的状态。但这与支付并不是强相关。这不是支付的核心业务,交易服务有需求还得要求我支付服务去干,不仅会增加支付服务中的不必要的代码、还更加耦合了,这可不得了,否者没完没了,后续需求可多了,。【发短信通知、加积分】
-
性能下降:随着业务越加越多,调用链会越来越长,每次调用耗时会增加,而支付业务往往并发是很高的。
-
级联失败:其他非核心业务挂了更不好了,增加耗时,甚至导致雪崩。由于我们是基于OpenFeign调用交易服务、通知服务。当交易服务、通知服务出现故障时,整个事务都会回滚,交易失败。
这其实就是同步调用的级联失败问题。
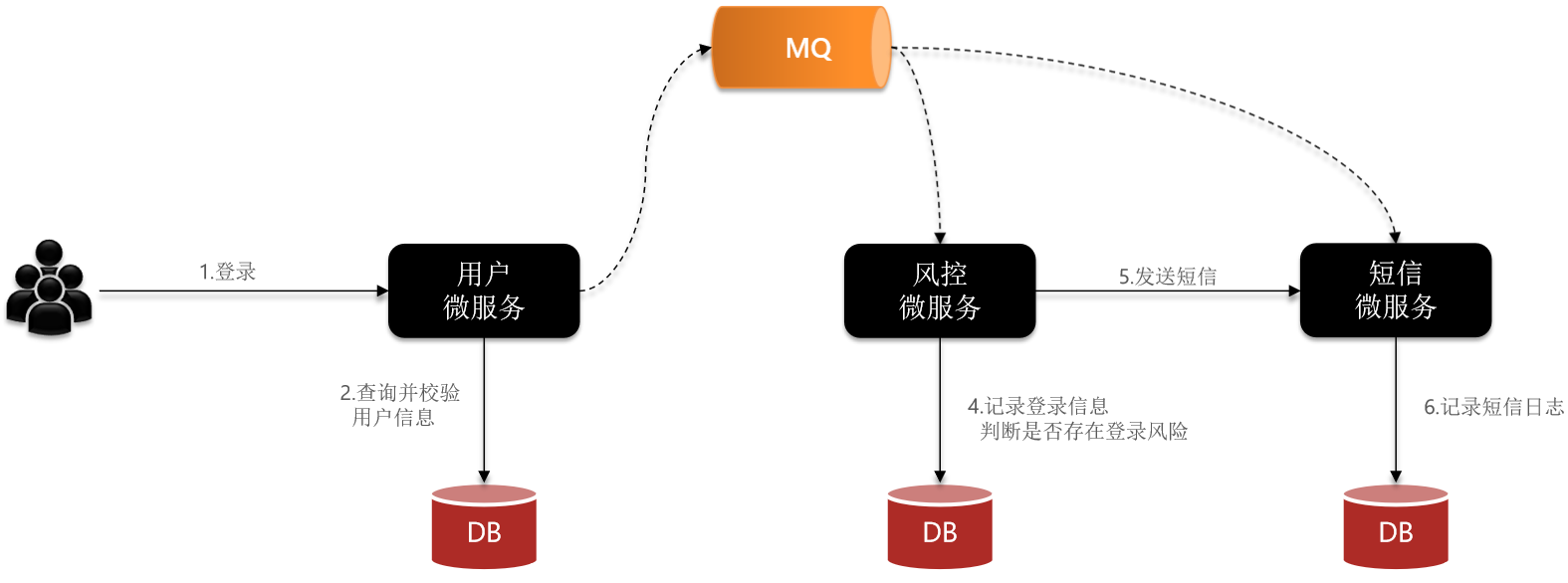
异步调用
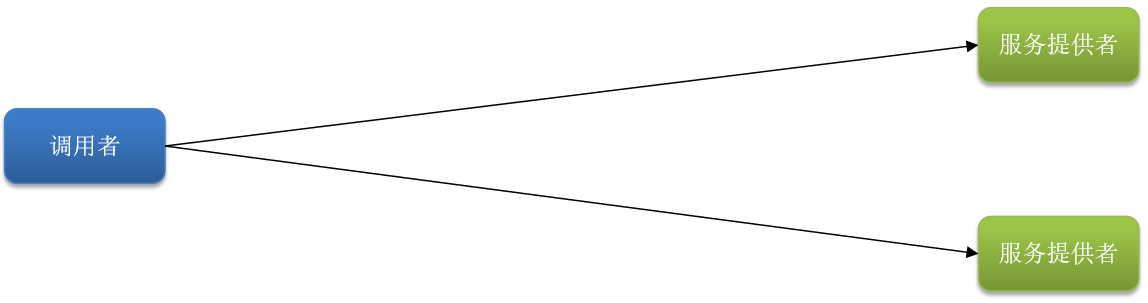
在同步调用中分为两个角色,调用者和提供者
提供者保留接口, 调用者通过http请求调用接口实现远程调用
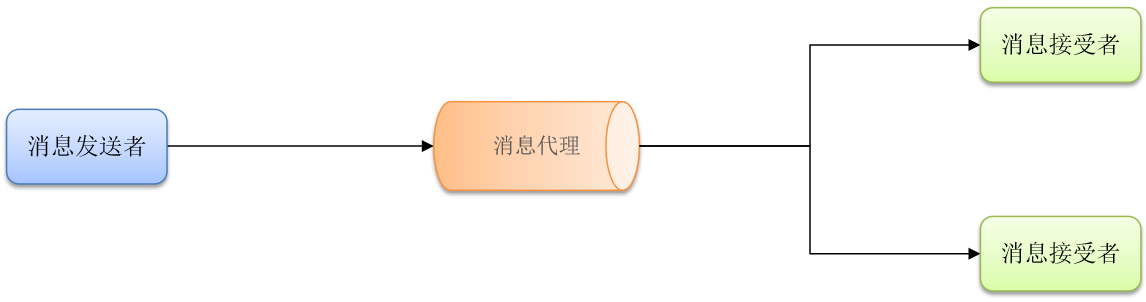
但是异步调用通常是基于消息通知的方式,包含三个角色:
- 消息发送者:投递消息的人,就是原来的调用者
- 消息接收者:接收和处理消息的人,就是原来的服务提供者
- 消息代理:管理、暂存、转发消息,你可以把它理解成微信服务器
通常基于消息通知的方式。不是直接发消息,和微信聊天一样,其实是发给了微信服务器
有个代理就相当于外卖柜子。消费者啥时候有空,啥时候用,提供者给到了就干别的事儿就行。
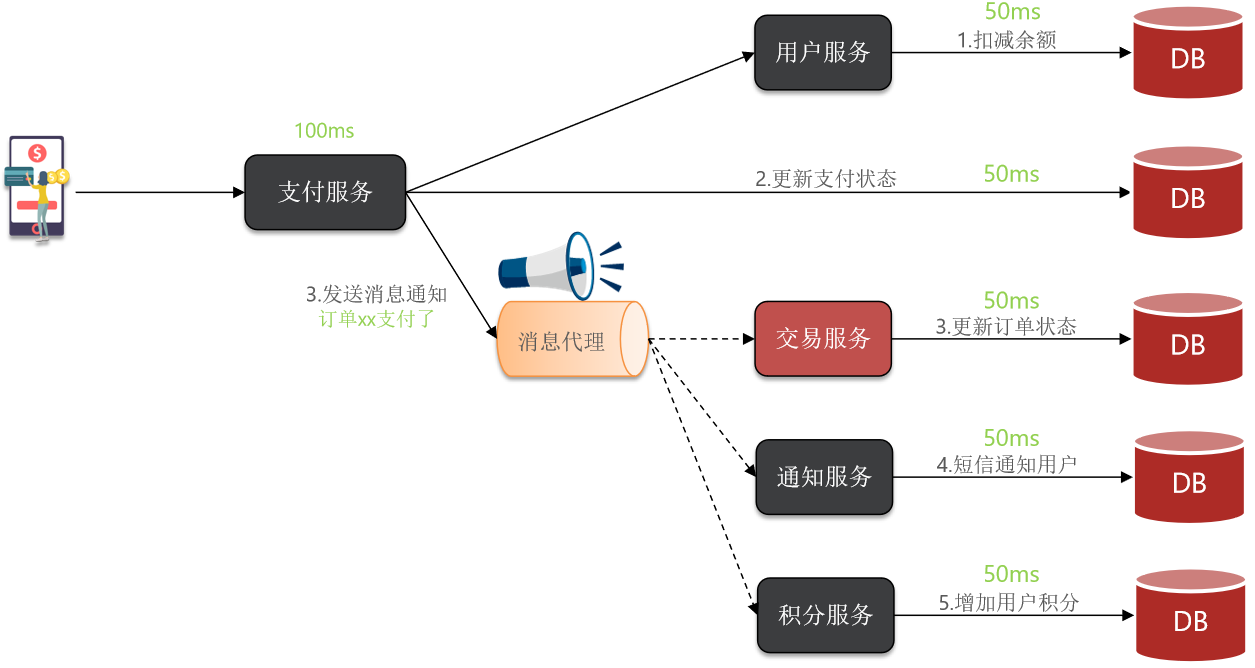
支付服务不再同步调用业务关联度低的服务,而是发送消息通知到Broker【代理】。
具备下列优势:
-
解除耦合,拓展性强【经典加一层】
-
无需等待,性能好【广播+监听】
-
故障隔离,下游服务故障不影响上游业务
-
缓存消息,流量削峰填谷【321上链接。缓存消息,充分利用服务器资源
,减少异常】
具备下列劣势:
-
不能立即得到调用结果,时效性差【或者直接得不到结果
】
-
不确定下游业务执行是否成功
-
业务安全依赖于Broker的可靠性【代理可靠性很重要】
MQ技术选型
MQ (MessageQueue),中文是消息队列【队列就是有个容器,消息对了就是存储消息的容器】,字面来看就是存放消息的队列。也就是异步调用中的Broker。【简单点就是存储和转发消息】
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
-
公司/社区:大厂有大厂的优势,小厂有小厂的强项。一生只干一件事儿,这就叫专业。积极维护,社区活跃
-
开发语言:Erlang语言【99%的任务直接用工具,不用学习语言】,面向并非的语言,而Java这是适配性广泛
-
协议支持:收发信息的格式,就是协议。jms,自定义的协议,要求比较严格,不太适合于微服务,微服务与语言无关,不同微服务可能使用不同语言。
-
可用性:健壮性,不能随便挂,支持分布式集群
-
单机吞吐量:输出存储消息的数量【每秒10万左右(90%的公司已经够了,Q你会解决高并发问题吗,A公司并发量多少……)】【每秒上百万】
-
消息延迟:从发消息到收消息的时间间隔。基于内存处理,速度非常快
-
消息可靠性:消费者至少能消费一次。所以Kafka适合大数据场景。数据丢一两个也没问题,吞吐量高就完事儿了
-
技术使用分布情况
- 中小型企业RabbitMQ,
- 大型企业有一些自研能力的RocketMQ,能解决其中的一些bug
RabbitMQ
安装部署
RabbitMQ是基于Erlang语言开发的开源消息通信中间件,官网地址。
我们同样基于Docker来安装RabbitMQ,使用下面的命令即可:
docker run \
-e RABBITMQ_DEFAULT_USER=itheima \
-e RABBITMQ_DEFAULT_PASS=123321 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
--network hm-net\
-d \
rabbitmq:3.8-management
当然,如果有现成的镜像更好,利用docker load命令加载
可以看到在安装命令中有两个映射的端口:
- 15672:RabbitMQ提供的管理控制台的端口
- 5672:RabbitMQ的消息发送处理接口
然后我们可以通过浏览器输入ip地址和端口地址信息信息去访问控制台。账号密码就是上面命令中的密码。
其中我们发现涉及到了RabbitMQ的整体架构及核心概念:
- virtual-host:虚拟主机,起到数据隔离的作用
- publisher:消息发送者
- consumer:消息的消费者
- queue:队列,存储消息
- exchange:交换机,负责路由消息
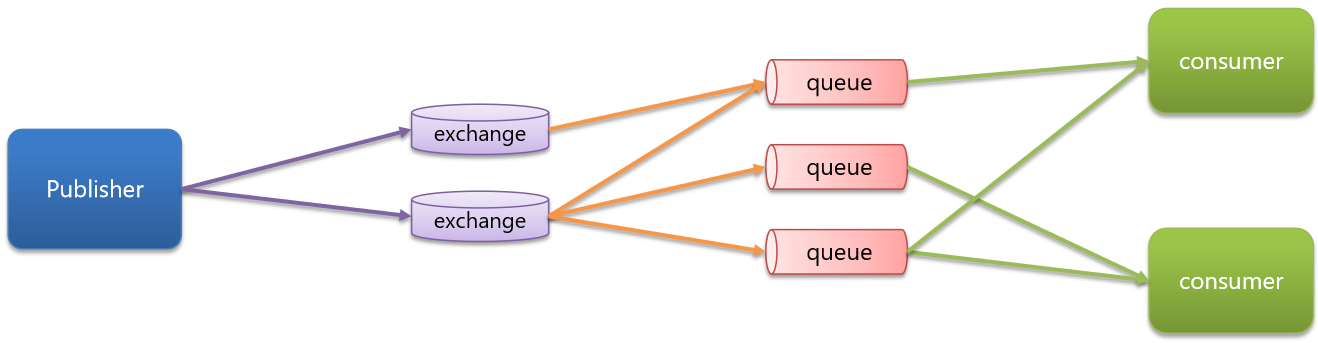
队列进行存储,发送者发给交换机而不是直接给到队列。交换机会根据配置好的队列路由给队列【可以是多个队列】,在由队列发给消费者【可以是多个消费者】
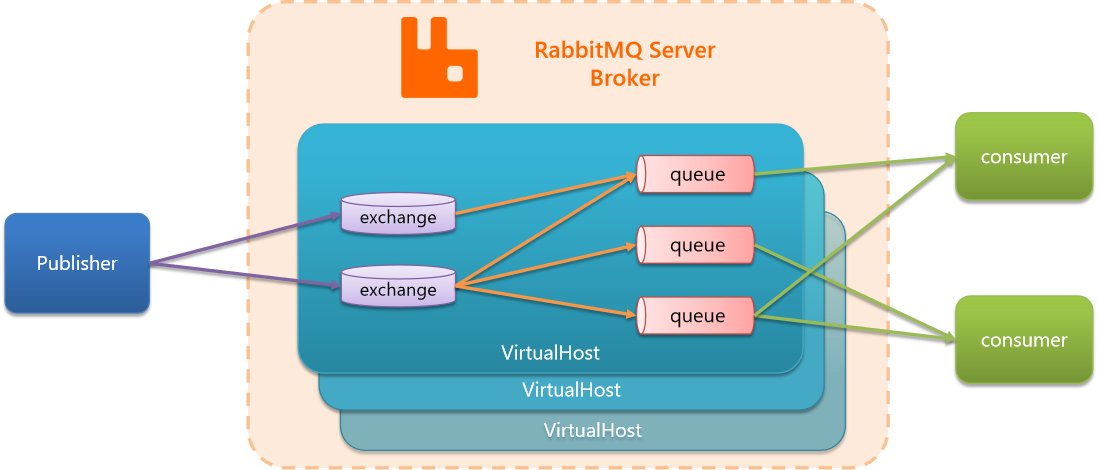
因为吞吐量很高,所以一个项目往往打不满,在企业中可能同时把多个项目部署在一套RabbitMQ中,不同项目的交换机和队列可能会产生冲突,这里就可以引入VirtualHost来隔离项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号