Spring Cloud
笔记介绍
学习视频,课程思路是基于之前的单体项目【以黑马商城为例】,调整为微服务项目进行学习。高效使用。
微服务是一种软件架构风格,它是以专注于单一职责的很多小型项目为基础,组合出复杂的大型应用。这样更有利于大项目的开发。
项目导入
Docker部署MySQL
Docker - 韩熙隐ario - 博客园。在这篇笔记中已经提到了部署MySQL。这里不多解释。
把准备好的配置文件和初始化脚本放到root目录。
然后创建一个通用网络:
docker network create hm-net
使用下面的命令来安装MySQL:
docker run -d \
--name mysql \
-p 3306:3306 \
-e TZ=Asia/Shanghai \
-e MYSQL_ROOT_PASSWORD=123 \
-v /root/mysql/data:/var/lib/mysql \
-v /root/mysql/conf:/etc/mysql/conf.d \
-v /root/mysql/init:/docker-entrypoint-initdb.d \
--network hm-net\
mysql
然后可以查看进程是否正常运行。
后端
直接打开项目,设置修改配置文件数据库的host。设置运行configuration type中的Active profiles项填成local即可【详见:SpringBoot3大事件 - 韩熙隐ario - 博客园】。启动之后就可以跑通了。
前端
讲前端项目资料放到一个非中文、不包含特殊字符的目录下。打开命令行输入start nginx.exe即可。可以在任务管理器中看到其进程是否运行。

然后就成了。可以输入网址进行测试。
认识微服务
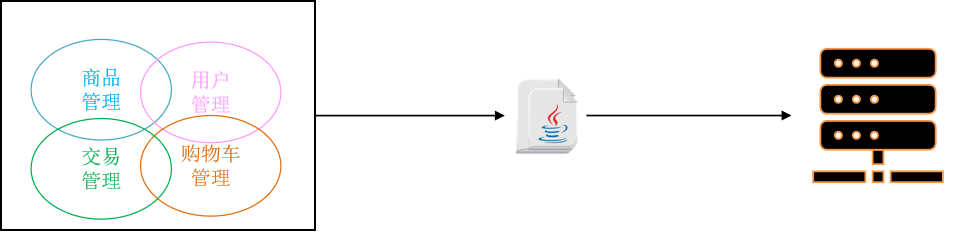
单体架构
将业务功能的所有功能集中在一个项目中开发,达成一个包部署。
优点:
- 架构简单
- 部署成本低
缺点:
- 团队协作成本高【随着功能增加,开发人员变多且代码存在耦合,会很容易导致冲突】
- 系统发布效率低【代码打包的时间越来越长,编译运行可能需要几十分钟】
- 系统可用性差【功能都部署在一起。不协调,没有应对好功能的特点(如是否重点,并发量需求等)。用户体验很差】
所以,单体架构适合开发功能相对简单,规模较小的项目。
微服务
微服务架构,是服务化思想指导下的一套最佳实践架构方案。服务化,就是把单体架构中的功能模块拆分为多个独立项目。
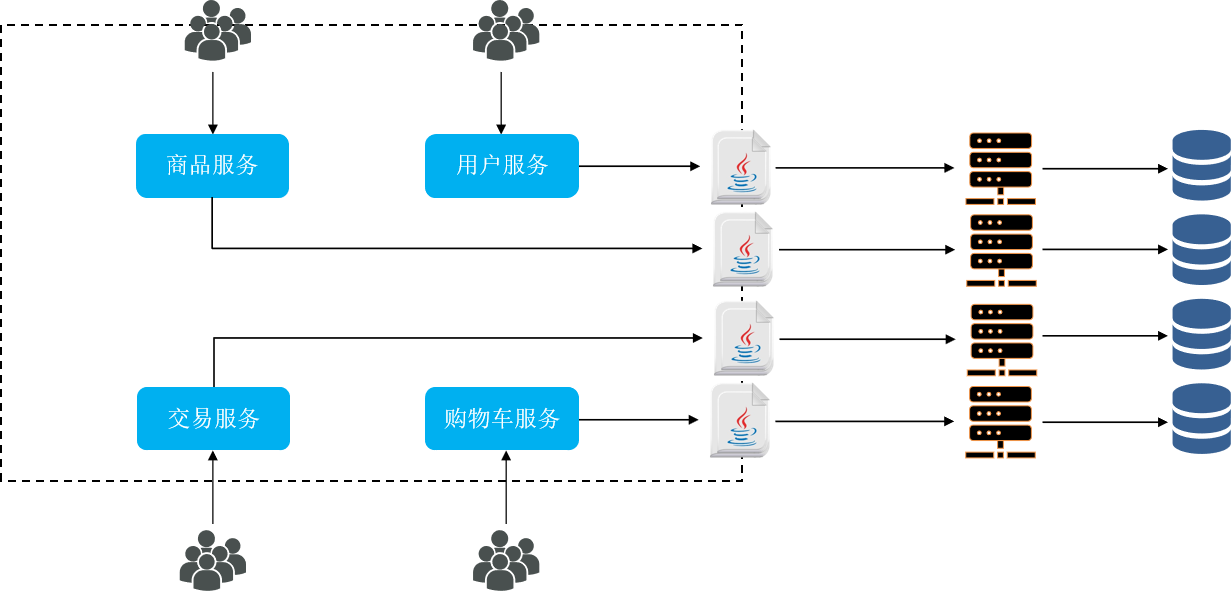
每个功能作为项目
- 粒度小【按业务来看,负责一块完整的功能,做到单一职责】
- 团队自治【每个项目,都有一个完整的团队开发】【相当与拆成了对各项目】
- 服务自治【部署的时候,分别编译打包,分别部署】【也方便了后续的更新了,哪里更新了动哪里】【数据库也可以才开了,功能模块之间相互影响小】
缺点:
- 对应跨模块的复杂业务开发难度大
- 项目结构复杂,不易部署。运维发展的高
如何克服缺点呢?当然是用后面要学的技术栈了。
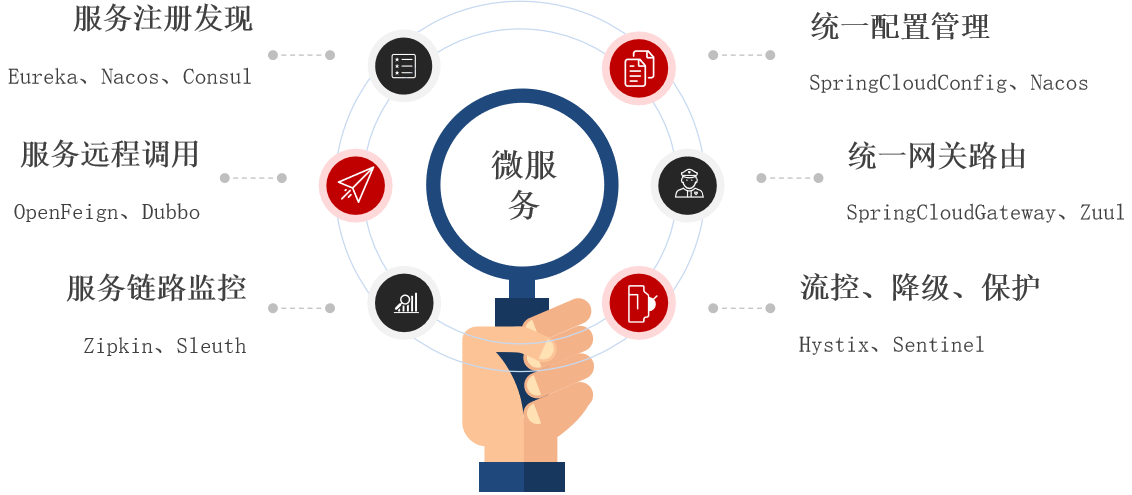
Spring Cloud
Spring Cloud是目前全球使用最广泛的微服务框架。官网地址:https://spring.io/projects/spring-cloud。
Spring Cloud集成了各种微服务功能组件,并基于Spring Boot实现了这些组件的自动装配,从而提供了良好的开箱即用体验:
在官网可以看到有一堆组件。
这是为了解决微服务开发中各种各样的问题。Spring Cloud其实是个集成的,是个完整的技术栈。很多是第三方开发的,被Spring Cloud集成了。其中,有的甚至比Spring Cloud还早,当Spring Cloud有了才火起来的。有了Spring Cloud,使第三方组件的使用组件的难度大大降低了,得到了推广。
Spring Cloud基于Spring Boot实现了微服务组件的自动装配,从而提供了良好的开箱即用体验。但对于Spring Boot的版本也有要求:
| Spring Cloud版本 | Spring Boot版本 |
|---|---|
| 2022.0.x aka Kilburn | 3.0.x |
| 2021.0.x aka Jubilee | 2.6.x, 2.7.x (Starting with 2021.0.3) |
| 2020.0.x aka Ilford | 2.4.x, 2.5.x (Starting with 2020.0.3) |
| Hoxton | 2.2.x, 2.3.x (Starting with SR5) |
| Greenwich | 2.1.x |
| Finchley | 2.0.x |
| Edgware | 1.5.x |
| Dalston | 1.5.x |
因为Spring Boot 3用的是jdk17,但国内基本没人用。所以这里学2021版的Spring Cloud
我们将来对于各组件的版本不需要指定。已经被spring-cloud-dependencies定义了。直接引入即可。
tips:
Spring Cloud是标准的制定者,定义了微服务组件的标准,定义了大量的接口和规范,这些微服务组件都实现了组件并遵守规范。所以各组在使用上差别就不大了,也可能就依赖不同。所以,别看有这么多组件,也是很好掌握的。
微服务拆分
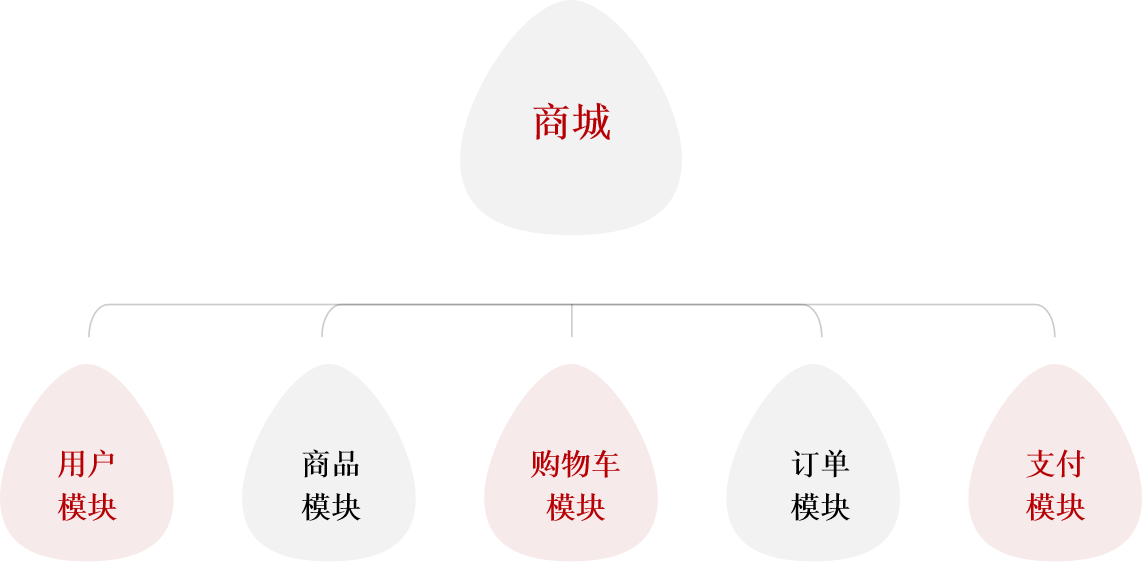
将单体项目拆分为微服务架构,同时学习服务拆分的原则。
项目熟悉
具体细节可在官方文档查看:day03-微服务01 - 飞书云文档
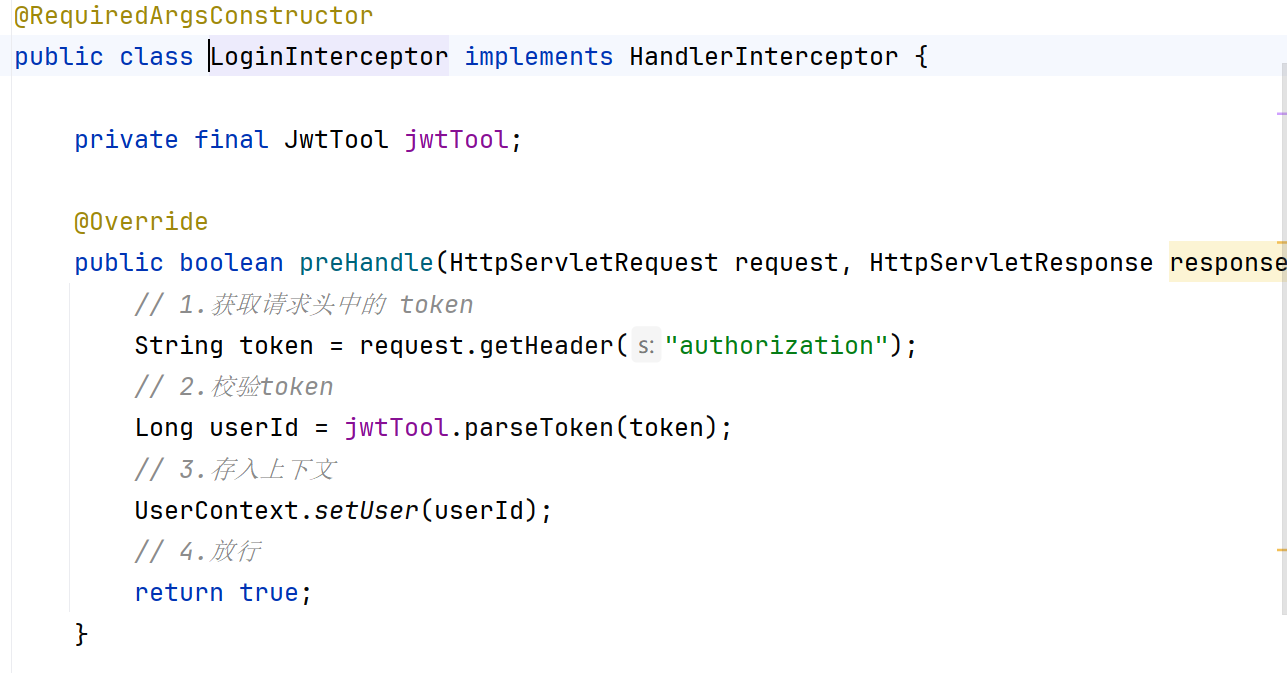
在登录阶段,通过拦截器拿到用户信息。这里加了一个线程区域
基于tomcat,进入tomcat的每个请求,如果不自己创建线程的话。默认是只有一个线程域来处理的。因此,在拦截器中存入当前线程的线程域,后续业务用到用户信息的话,随时都可以基于 usercontext从线程域中取出用户信息。这样会很方便。
服务拆分原则
什么时候拆分
-
创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐渐拆分。【这样可以快速的实现自己的想法,兵贵神速。同时,开发成本低,试错成本低。只不过后面拆的时候麻烦点】
一般情况下,对于一个初创的项目,首先要做的是验证项目的可行性。因此这一阶段的首要任务是敏捷开发,快速产出生产可用的产品,投入市场做验证。为了达成这一目的,该阶段项目架构往往会比较简单,很多情况下会直接采用单体架构,这样开发成本比较低,可以快速产出结果,一旦发现项目不符合市场,损失较小。
如果这一阶段采用复杂的微服务架构,投入大量的人力和时间成本用于架构设计,最终发现产品不符合市场需求,等于全部做了无用功。
所以,对于大多数小型项目来说,一般是先采用单体架构,随着用户规模扩大、业务复杂后再逐渐拆分为微服务架构。这样初期成本会比较低,可以快速试错。但是,这么做的问题就在于后期做服务拆分时,可能会遇到很多代码耦合带来的问题,拆分比较困难(前易后难)
-
明确的大型项目:资金充足,目标明确,可以直接选择微服务架构,避免后续拆分的麻烦。【比如大厂想开发某个业务】
如何拆分
目标有两点:
- 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高【比如某业务的升级,对其他服务基本不会产生什么影响】。【做到高内聚,自然就低耦合了】
- 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖。
从拆分方式来说,一般包含两种方式:【两种方式结合这来用最好。下面主要讲垂直拆分】
-
纵向拆分【垂直】:按照业务模块来拆分【分布式的思想。】
-
横向拆分【水平】:抽取公共服务,提高复用性
例如用户登录是需要发送消息通知,记录风控数据,下单时也要发送短信,记录风控数据。因此消息发送、风控数据记录就是通用的业务功能,因此可以将他们分别抽取为公共服务:消息中心服务、风控管理服务。这样可以提高业务的复用性,避免重复开发。同时通用业务一般接口稳定性较强,也不会使服务之间过分耦合。
拆分服务
工程结构有两种:
-
独立Project
每个微服务都是一个Project,在idea中是独立的窗口、独立的文件夹。一般我们会创建一个空文件夹。把所有的Project都放进去管理。从项目结构来讲它们是分离的。而且代码仓库git也是分离的。【适合特别大型的项目】
- 优点:完全解耦,没有联系。
- 缺点:但这样结构松散,不易管理。
-
Maven聚合
每个微服务都是一个Module,每个Module都是独立做打包部署的。运行的时候是独立分开的,只不过代码是放到一起的。【适合中小型项目。下面主要讲这个】
- 项目代码集中,管理和运维方便
- 服务之间耦合,编译时间较长
这里可以就在原来的项目父工程基础上拆,优点如下:
- 可以直接使用已经引用的依赖
- 容易拷贝代码
然后可以开始拆分了
-
可以新建module了【以商品管理为例】
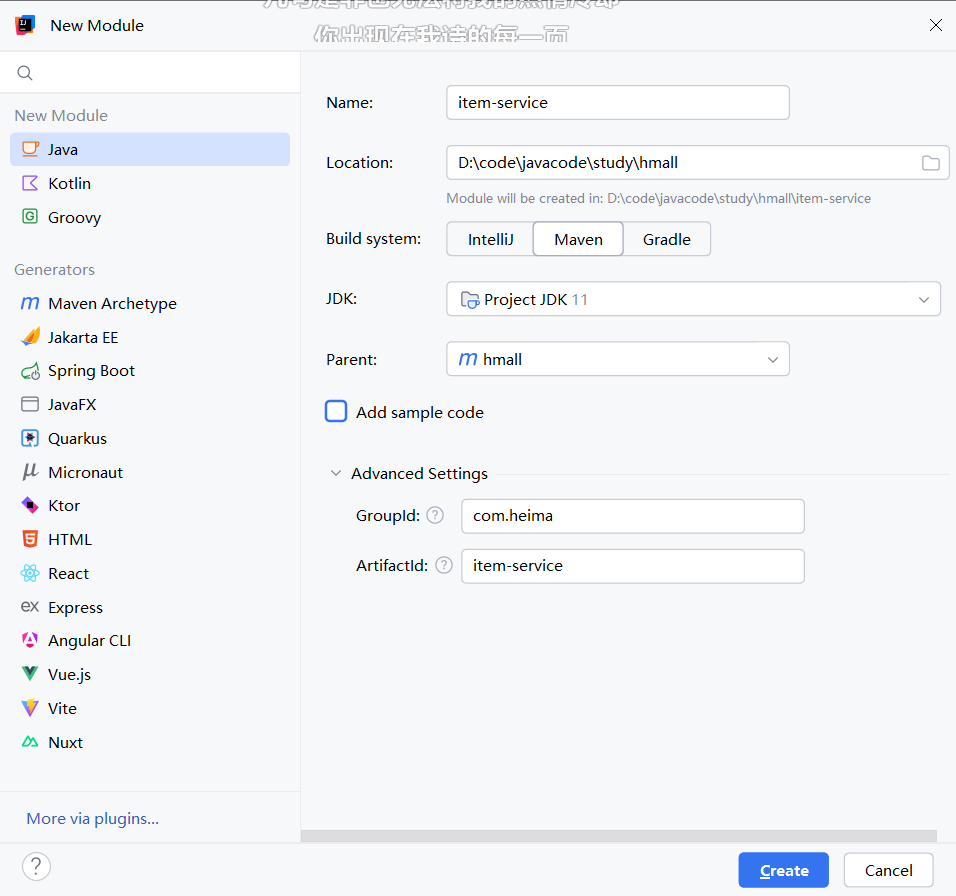
-
把直接去的依赖和build代码复制过去。对于不需要或不确定是否需要的依赖去除。后面用到在加也可以。另外,能继承父工程的也来也要去除。随后导入依赖。
-
创建包和启动类。
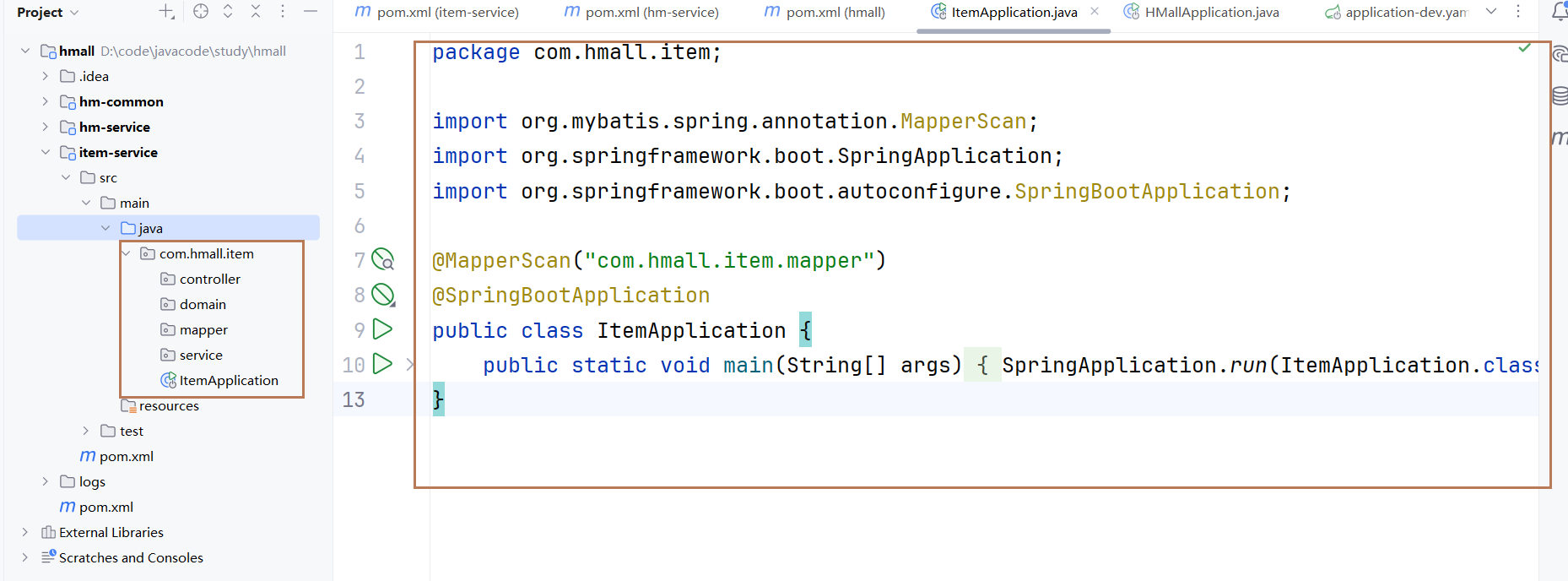
-
配置文件
基本上都是先复制,再修改
-
mapper文件【这里本来是空的,先不管了】
-
yaml文件
server: port: 8081 #这里也要区分,不同微服务端口不能冲突 spring: application: name: item-service #每个服务都要有一个微服务名称 profiles: active: dev #默认就好 datasource: #每个微服务都要独立。在docker中都要对应一个容器,创建不同的mysql示例。所有这里地址会变。【课程为了简单,用不同数据库模拟,所以下面只改数据库名即可】 url: jdbc:mysql://${hm.db.host}:3306/hm-item?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai driver-class-name: com.mysql.cj.jdbc.Driver username: root password: ${hm.db.pw} mybatis-plus: configuration: default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler global-config: db-config: update-strategy: not_null id-type: auto logging: level: com.hmall: debug #com.hmall包下的所有类产生的类都是debug pattern: dateformat: HH:mm:ss:SSS #日期文件 file: path: "logs/${spring.application.name}" #这样每个服务的日志输出会在不同目录下 knife4j: #是swagger接口文档的配置 enable: true openapi: title: 黑马商城商品管理接口文档 description: "黑马商城接口文档" email: zhanghuyi@itcast.cn concat: 虎哥 url: https://www.itcast.cn version: v1.0.0 group: default: group-name: default api-rule: package api-rule-resources: - com.hmall.item.controller #Swagger扫描到Controller,会把Controller接口信息作为接口文档信息
-
-
拷贝有关的domain实体【在整个过程中允许出错。拷漏了,后面用到了再补嘛】
-
拷贝有关的mapper
-
拷贝有关service接口和实现类。要注意代码中的硬编码路径。虽然格式没问题,但需要改
String sqlStatement = "com.hmall.item.mapper.ItemMapper.updateStock"; -
拷贝有关的controller
尝试运行:
因为后面微服务可能很多。我们这里不建议直接找启动类文件去启动。可以在IDEA的services模块中统一管理。然后就可以想启动哪个就启动哪个了,进行配置了。
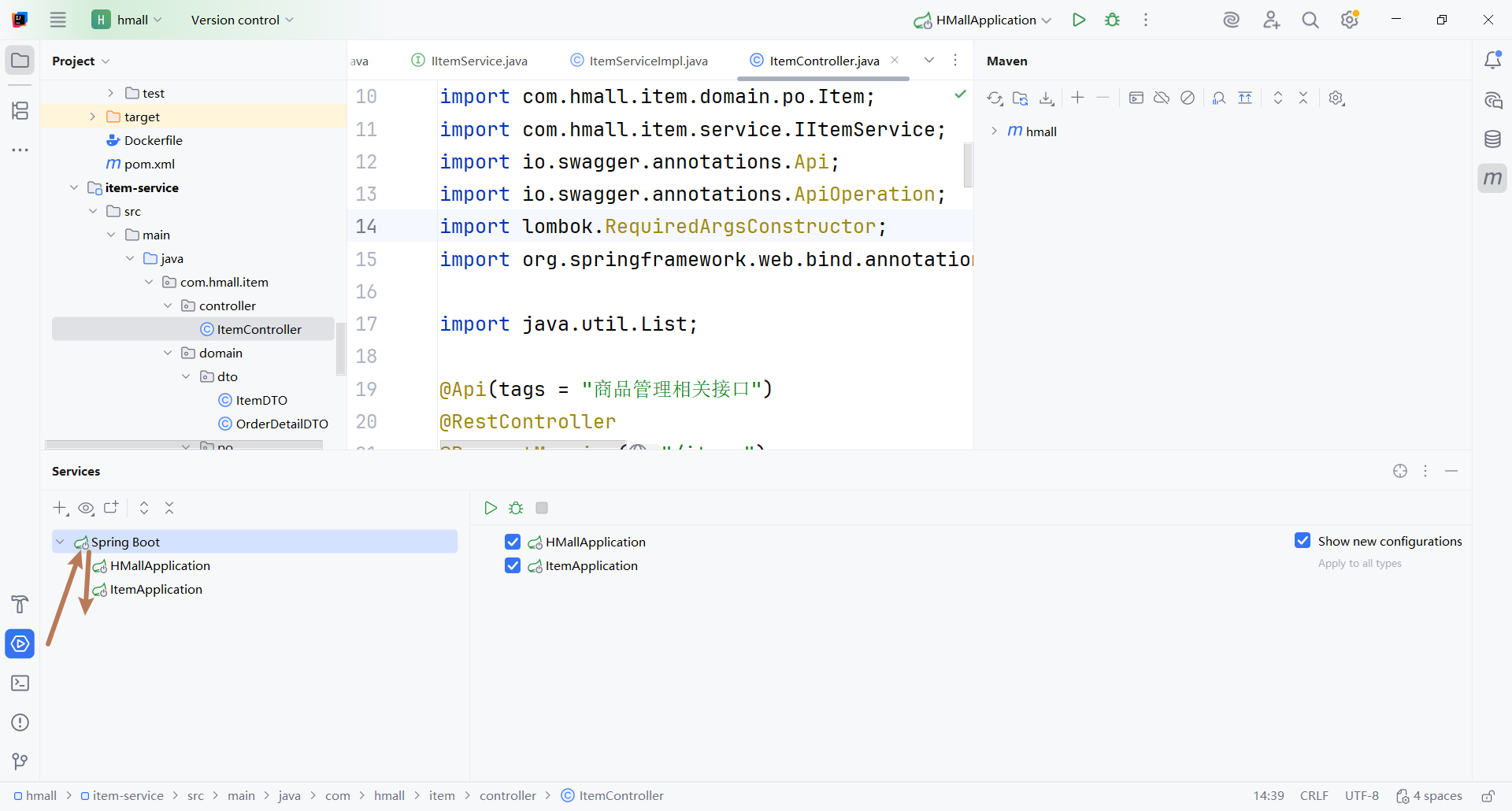
如果发现启动类没被识别到,有两种方式添加
-
reload运行maven,大概率会识别到
-
手动添加
-
先复制已有的启动类配置
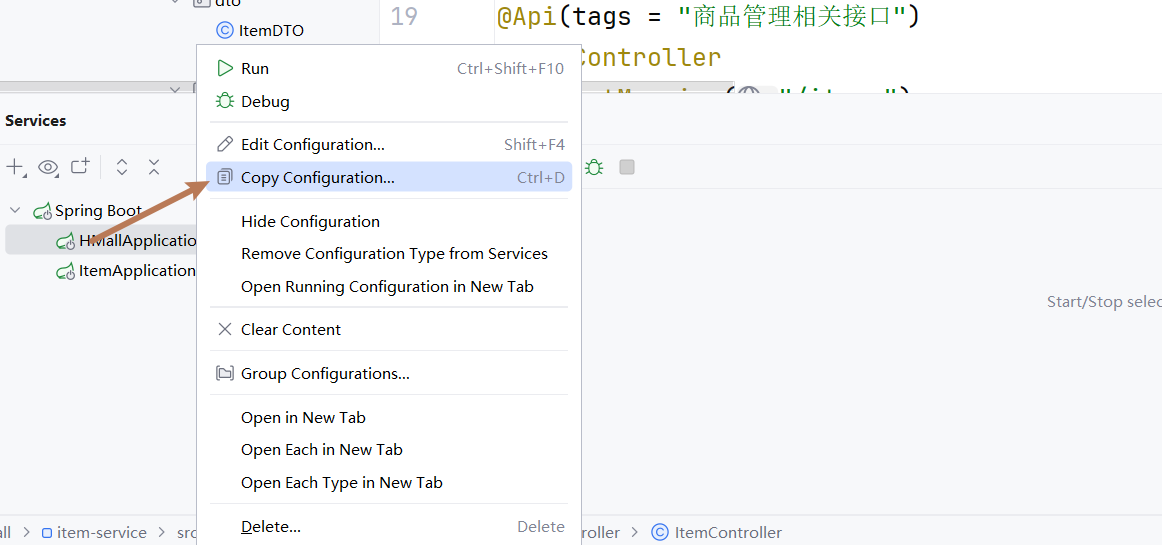
-
进行配置
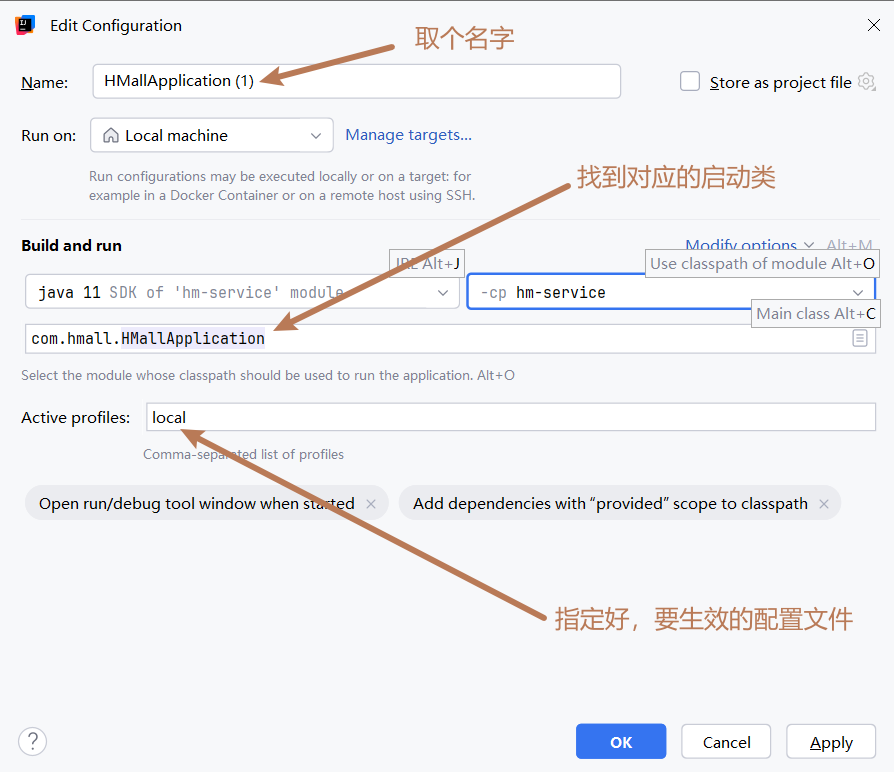
-
拆完商品接着拆购物车管理。步骤基本一致。但是有部分代码耦合,需要知道一下
-
在CartServiceImpl中注入了IItemService【因为查询购物车时,会根据商品信息计算价格波动等信息】。格式上就出错了,因为已经不在一起了【现在先注释。下面远程调用处理这个问题】
private final IItemService itemService; …… private void handleCartItems(List<CartVO> vos) { // TODO 1.获取商品id Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet()); // 2.查询商品 List<ItemDTO> items = itemService.queryItemByIds(itemIds); if (CollUtils.isEmpty(items)) { return; } // 3.转为 id 到 item的map Map<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity())); // 4.写入vo for (CartVO v : vos) { ItemDTO item = itemMap.get(v.getItemId()); if (item == null) { continue; } v.setNewPrice(item.getPrice()); v.setStatus(item.getStatus()); v.setStock(item.getStock()); } …… } -
此外,再queryMyCarts方法中。用到了用户拦截器,这里也是没有的,先写死
List<Cart> carts = lambdaQuery().eq(Cart::getUserId, 1L /* TODO UserContext.getUser()*/).list();
远程调用
再拆分过程中发现,一些服务之间是需要数据传输的【比如查询】,相比之前,现在不同服务之间物理上分开了,不能像之前那样直接注入调用。但网络上可以是相通的。我们去通过网络请求数据。
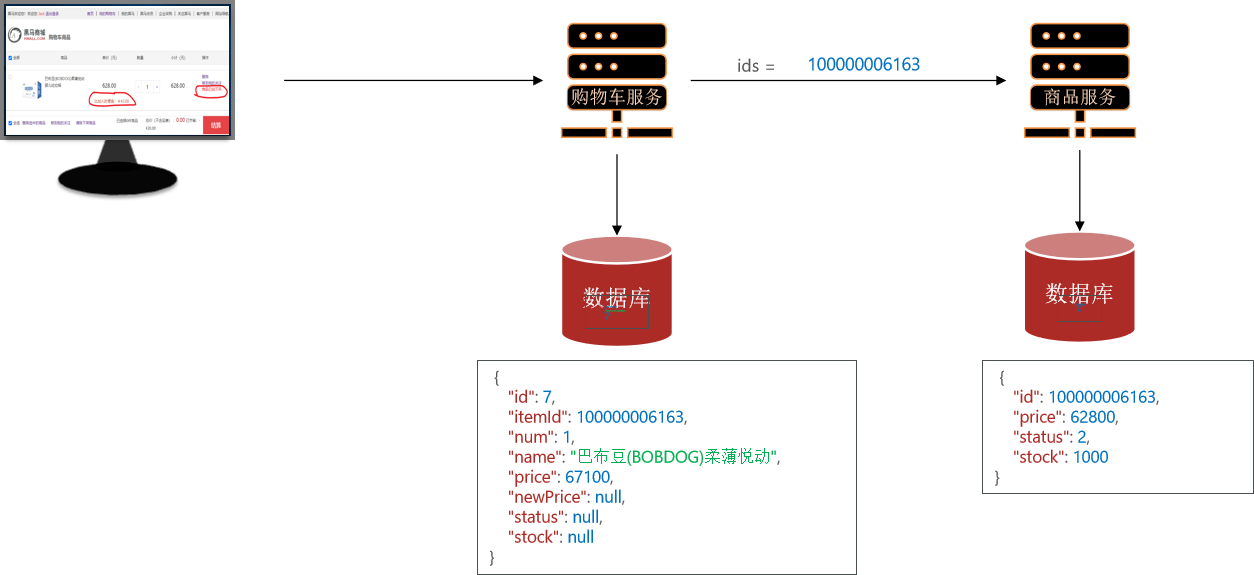
那就需要我通过Java代码从一个服务向另一个服务发送网络请求。Spring给我们提供了一个RestTemplate工具,可以方便的实现Http请求的发送。使用步骤如下:
-
注入RestTemplate到Spring容器

-
发起远程调用

接着我们就可以解决上面的问题了
-
首先我们取消注释发现缺少ItemDTO类。我们这里直接加到服务中【微服务之间重复了,不太好,后面会优化】
-
注入RestTemplate到Spring容器。我们知道Spring Boot的启动类也是一个配置类,可以写一些简单的配置。我们可以直接再启动类中注入。这样再任何地方都可以注入使用了。
public class CartApplication { public static void main(String[] args) { SpringApplication.run(CartApplication.class, args); } //注入RestTemplate到Spring容器 @Bean public RestTemplate restTemplate() { return new RestTemplate(); } } -
在service中注入,并调用请求和解析相应
@RequiredArgsConstructor public class CartServiceImpl extends ServiceImpl<CartMapper, Cart> implements ICartService { private final RestTemplate restTemplate; …… private void handleCartItems(List<CartVO> vos) { // TODO 1.获取商品id Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet()); // 2.查询商品 // List<ItemDTO> items = itemService.queryItemByIds(itemIds); //2.1 利用RestTemplate发起http请求,得到http的响应 ResponseEntity<List<ItemDTO>> response = restTemplate.exchange( "http://localhost:8081/items?ids={ids}", HttpMethod.GET, null, new ParameterizedTypeReference<List<ItemDTO>>() { }, Map.of("ids", CollUtils.join(itemIds, ",")) ); //2.2解析相应 if (!response.getStatusCode().is2xxSuccessful()) { //查询失败,直接结束 return; } List<ItemDTO> items = response.getBody(); if (CollUtils.isEmpty(items)) { return; } …… } }其中有几个要注意的点:
-
这里用的是lombok注解的方式注入的RestTemplate。优势之间已经接触过了。Mybatis-Plus - 韩熙隐ario - 博客园
-
RestTemplate不仅有exchange方法。还有其他的简单方法。对于简单的需求是可以使用的。
-
指定返回值类型时有点难。
- 直接写
List<ItemDTO>是不行的,字节码中式没有泛型的。 - 写List也不可以,也要知道泛型。
我们这里使用了参数类型引用,就相当于一个泛型的引用。传一个对象。可以用反射拿到对象上的泛型。
- 直接写
-
这里Map的值,要求是字符串,这里用到了hutool包的集合转字符串功能。
-
然后测试ak。
服务治理
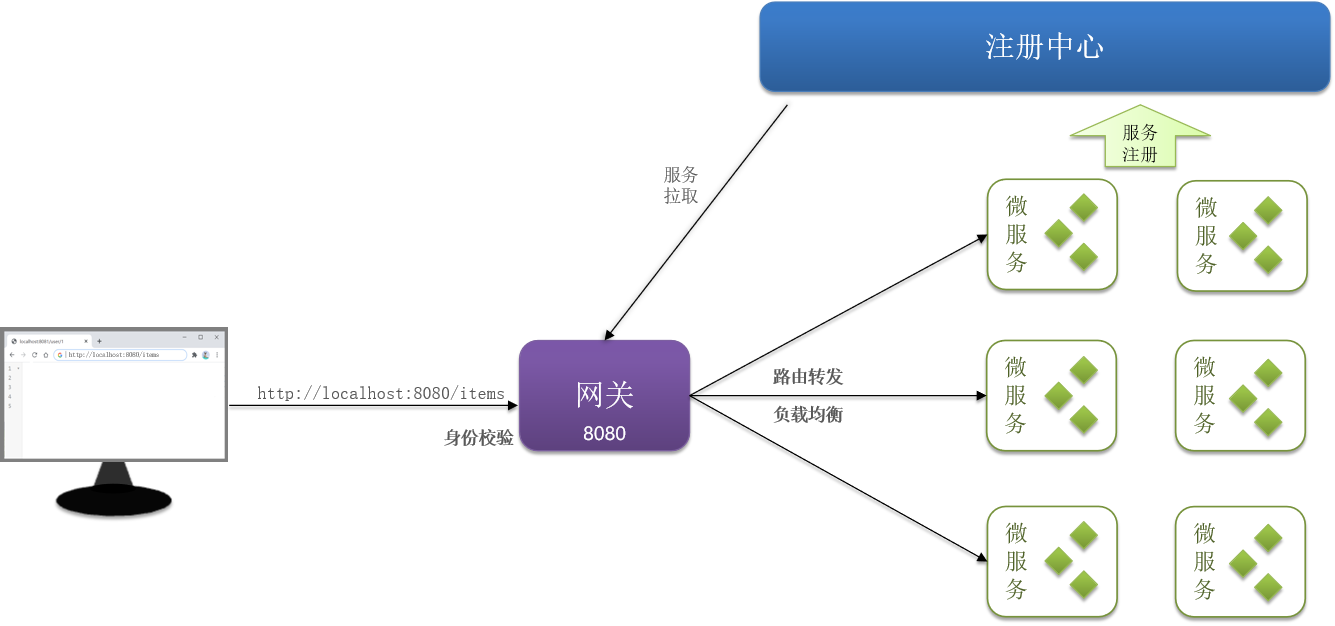
在上一章我们实现了微服务拆分,并且通过Http请求实现了跨微服务的远程调用。不过这种手动发送Http请求的方式存在一些问题。试想一下,假如微服务被调用较多,为了应对更高的并发,我们进行了多实例部署,如图:

但这也遇到了很多问题:
- 写代码的时候不知道后面部署多少实例,并不知道每个实例地址。
- 如何服务消费者,如何确定调用哪个服务。写死也不好,实现不了负载均衡。
- 如果在运行过程中,某一个
item-service实例宕机,cart-service依然在调用该怎么办? - 如果并发太高,
item-service临时多部署了N台实例,cart-service如何知道新实例的地址?
这些问题就是服务治理问题。我们用注册中心解决。
注册中心的原理
任何一个微服务既可以时服务调用者也可以是服务提供者。像极了人生。像是一个中介中心。这里就是注册中心。负载均衡算法,随机和轮询【概率均衡】、加权轮询【这样重点用硬件较好的】或哈希等等很多种。现在由注册中心负责这些工作,所有知道注册中心就好。
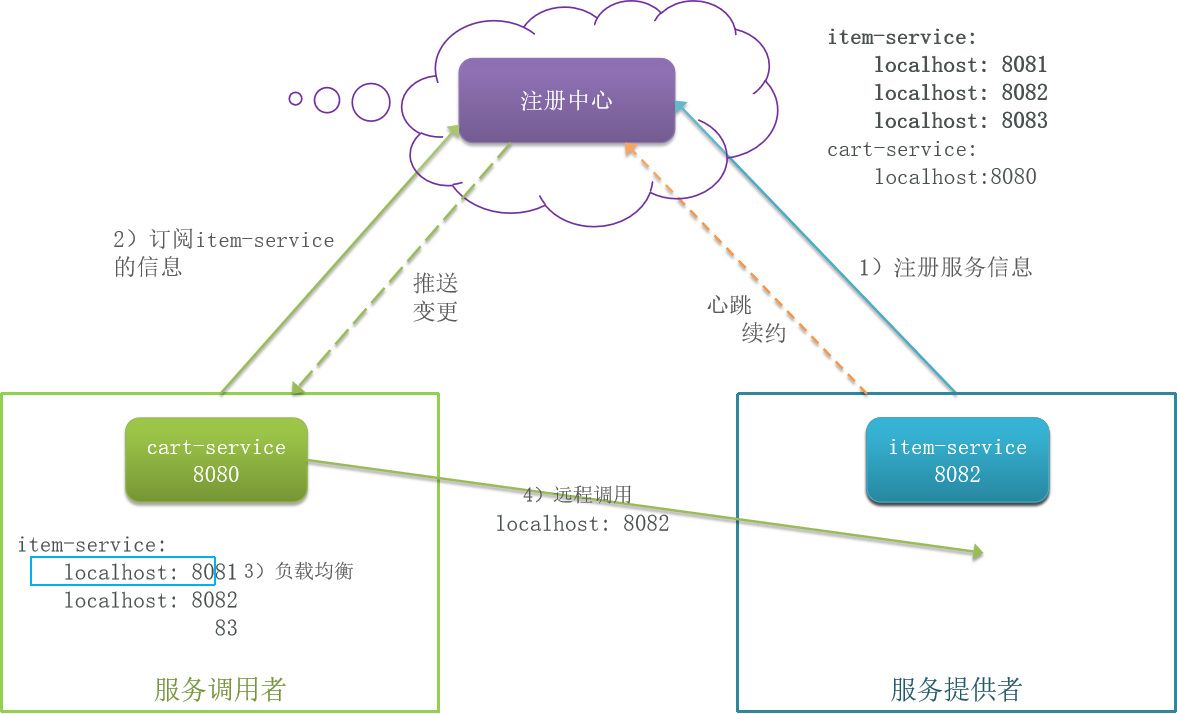
具体流程如下
- 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
- 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
- 调用者自己对实例列表负载均衡,挑选一个实例
- 调用者向该实例发起远程调用
当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢?
- 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求)
- 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除
- 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表
- 当注册中心服务列表变更时,会主动通知微服务(调用者),更新本地服务列表
Nacos注册中心
这是国内主流的注册中心,当然还有其他注册中心,比如Eureka、Consul等。用它的原因是国产的,手册是中文的,好理解。同时功能是很强大的。还是上面说的,这些组件使用上来说差别不大。先学一个就好了。
我们重点看安装和部署。注册中心也是一个独立的服务。将来所有的微服务会跟它关联。
我们基于Docker来部署Nacos的注册中心,首先我们要准备MySQL数据库表【这里用mysql数据源】,用来存储Nacos的数据。由于是Docker部署,所以大家需要将资料中的SQL文件导入到你Docker中的MySQL容器中:
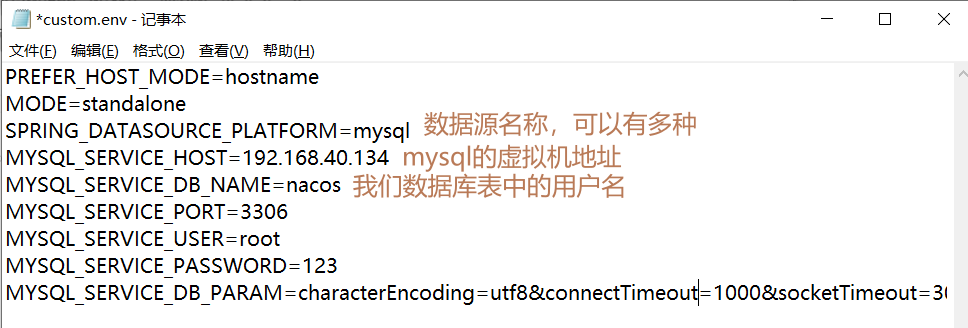
然后,我们这里用docker部署nacos。首先我们写一下配置文件。配置文件主要配置了一些与mysql连接的信息。要在其中的nacos/custom.env文件中配置。
然后上传配置文件【这里也可以nacos镜像】至虚拟机,准备部署。
然后加载上传的镜像
docker load -i nacos.tar
然后创建并运行镜像
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim
然后可以通过如下命令查看运行日志
docker logs -f nacos
注意:这里如果报错没有配置数据源的话,可能是网络的问题,需要把nacos容器加入mysql所在的网络。
然后就可以在浏览器访问nacos可视化界面了http://192.168.40.134:8848/nacos/。账号密码就是数据库中user信息。这里账号密码都是nacos。
服务注册
那么我们可以在代码中进行把服务提供者注册到Nacos中去。
服务注册步骤如下:
-
引入nacos discovery依赖:
<!--nacos 服务注册发现--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> -
配置Nacos地址:
spring: application: name: item-service # 服务名称 cloud: nacos: server-addr: 192.168.40.134:8848 # nacos地址
然后运行代码,刷新nacos就可以看到了。
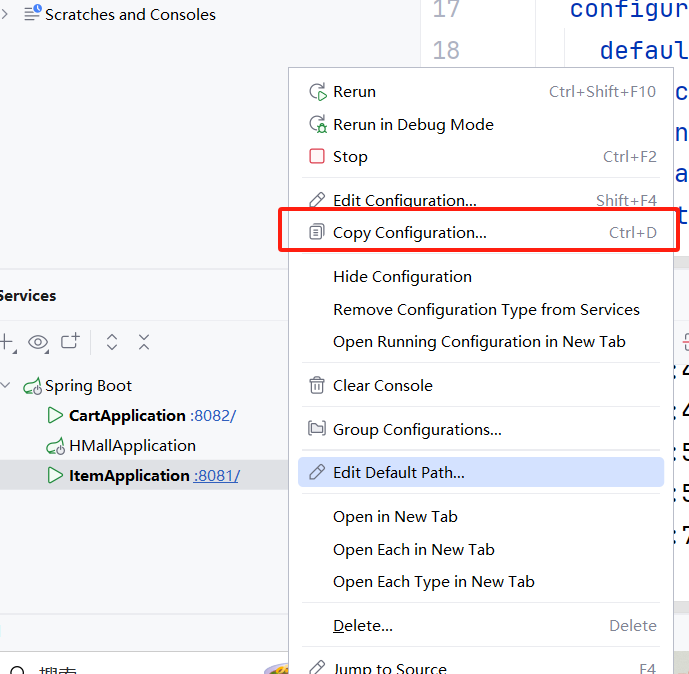
此外,还可以在idea中运行多个服务实例:
-
首先复制启动项配置
-
修改配置项。因为是在同一台机器上运行,所以端口要保持唯一性。
!
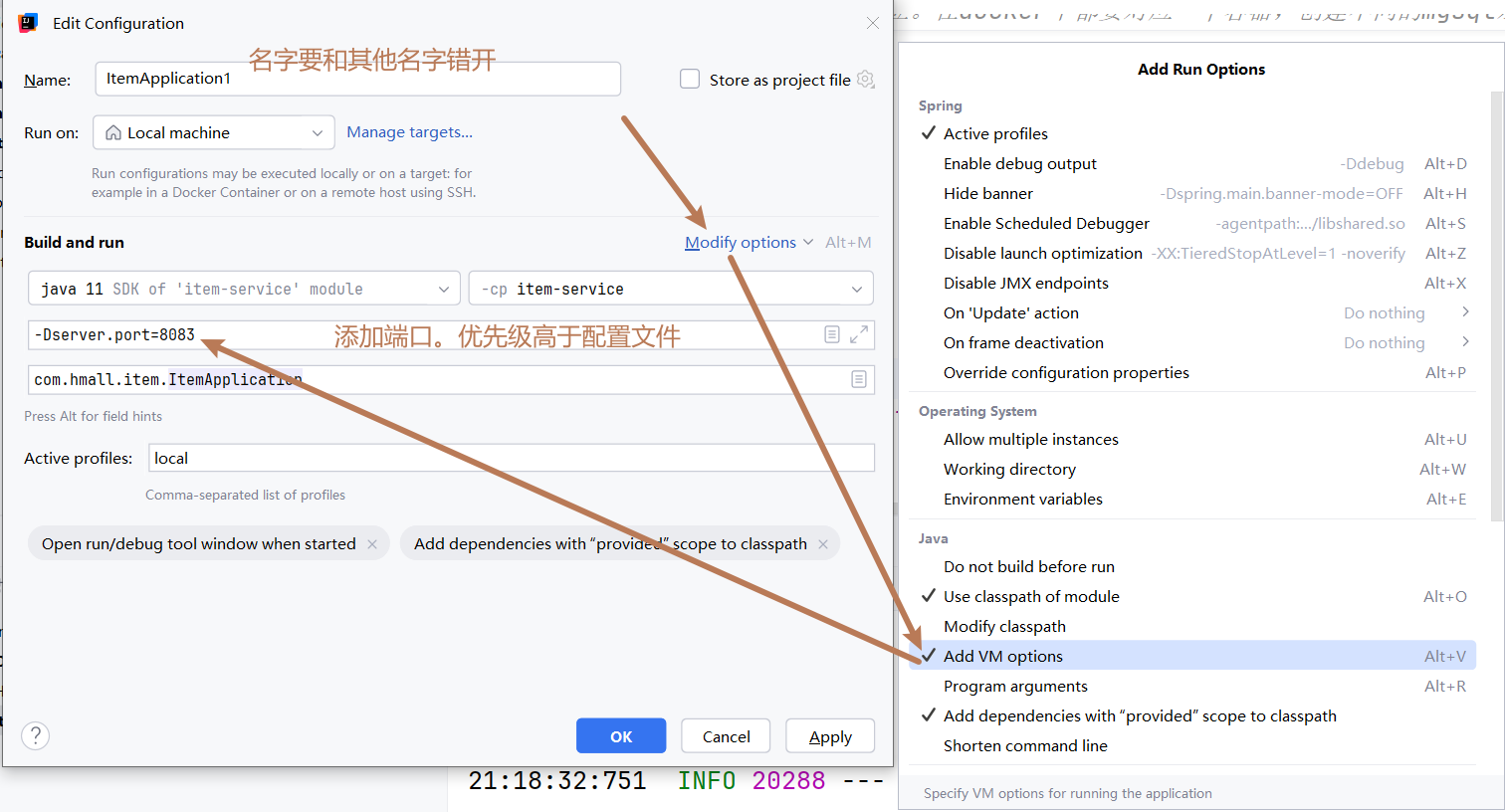
-
然后运行即可。
运行以后,可以在nacos中心看到相关记录
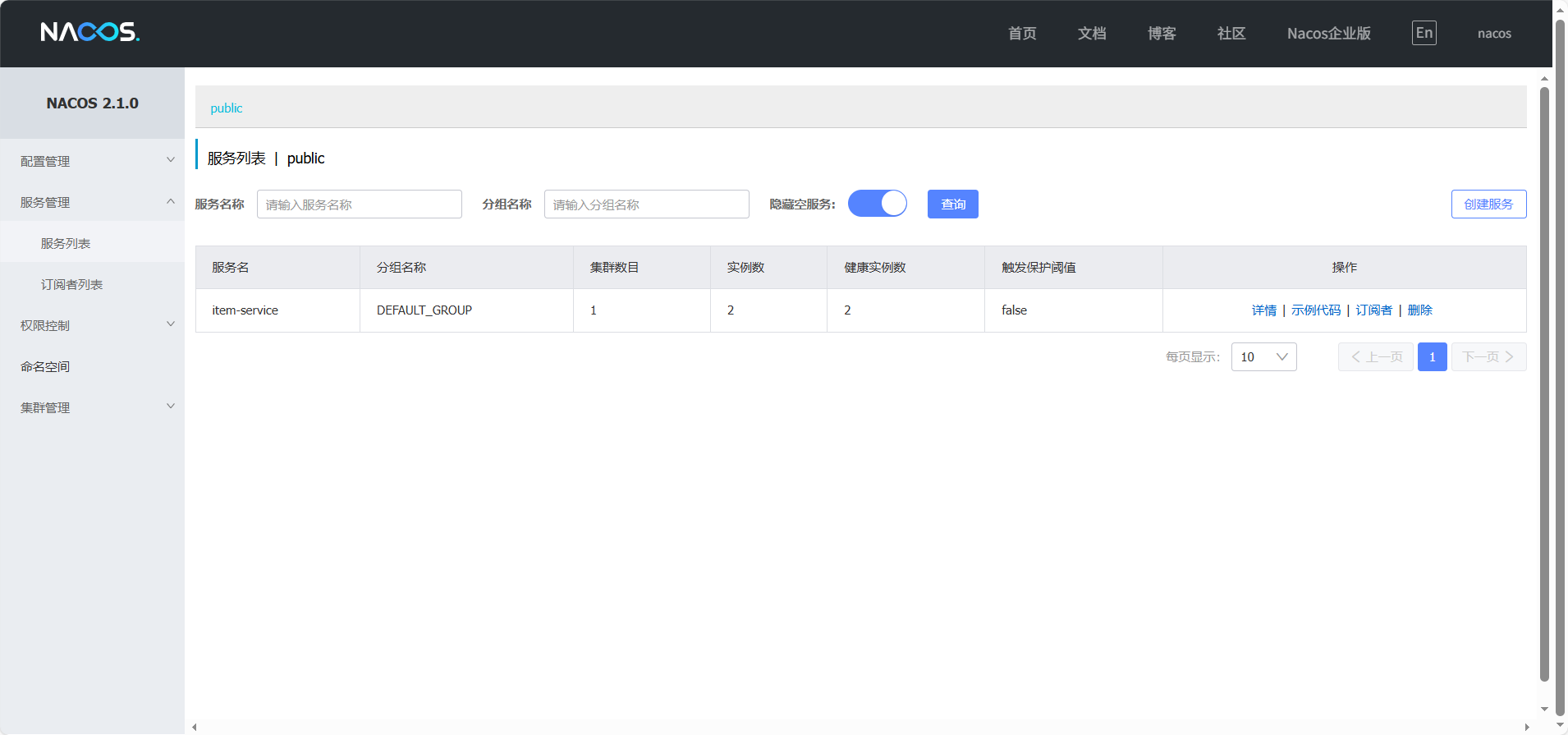
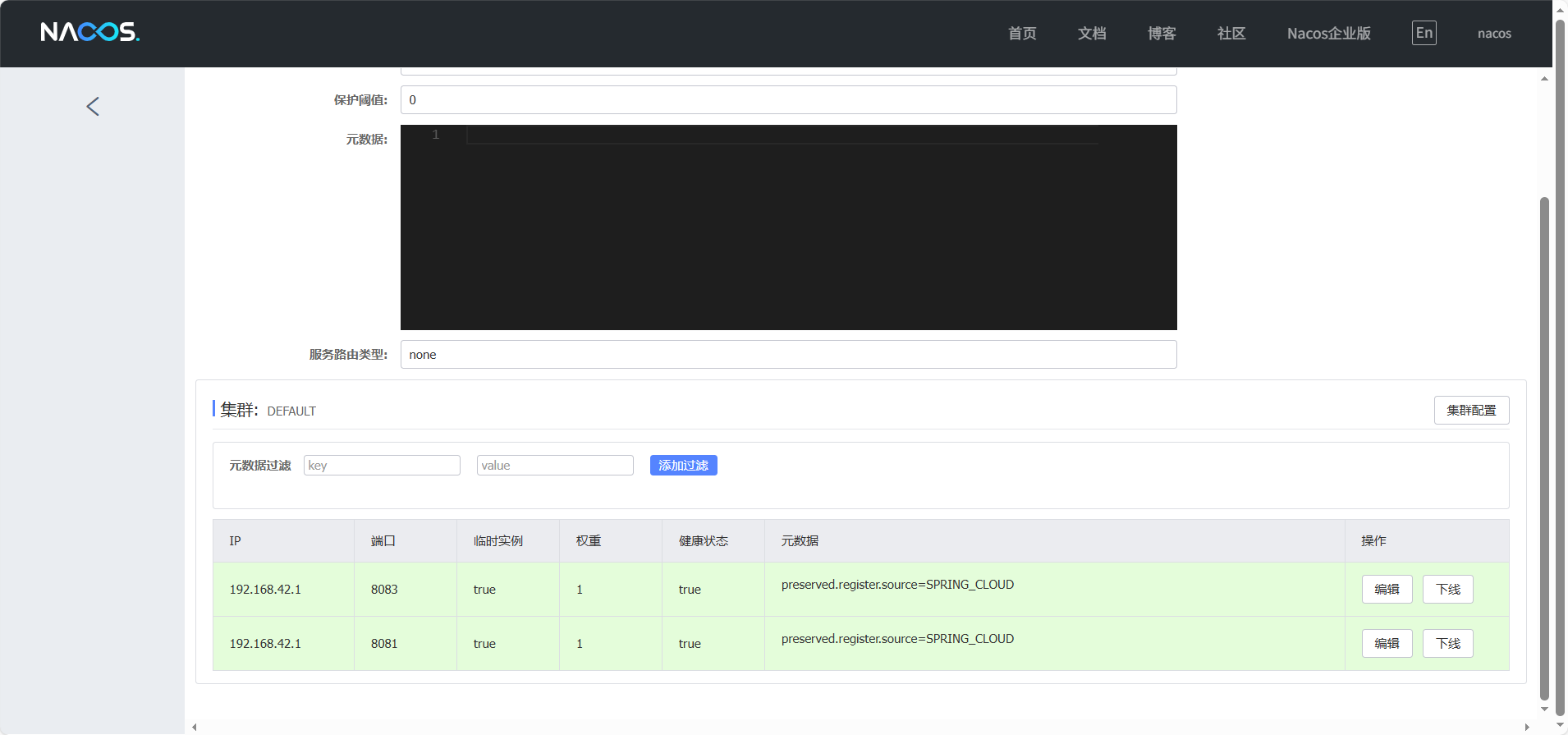
服务发现
服务的消费者要去nacos订阅服务,这个过程就是服务发现,步骤如下:
-
引入依赖【和之前一样】
<!--nacos 服务注册发现--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> -
配置Nacos地址【和之前一样】
spring: application: name: item-service # 服务名称 cloud: nacos: server-addr: 192.168.40.134:8848 # nacos地址 -
发现并调用服务
接下来,服务调用者
cart-service就可以去订阅item-service服务了。不过item-service有多个实例,而真正发起调用时只需要知道一个实例的地址。这里可以常见的负载均衡算法挑选。另外,服务发现需要用到一个工具,DiscoveryClient,Spring Cloud已经帮我们自动装配,我们可以直接注入使用,我们就可以对原来的远程调用做修改了,之前调用时我们需要写死服务提供者的IP和端口。我们通过DiscoveryClient发现服务实例列表,然后通过负载均衡算法,选择一个实例去调用。实例里面有对应服务的信息。我们可以用其中的地址信息【getUri】完成我们的需求。
private final DiscoveryClient discoveryClient; …… //2.1 发现item-service服务的实例列表 List<ServiceInstance> instances = discoveryClient.getInstances("item-service"); //2.2 负载均衡,挑一个实例 ServiceInstance instance = instances.get(RandomUtil.randomInt(instances.size())); //2.3 利用RestTemplate发起http请求,得到http的响应 ResponseEntity<List<ItemDTO>> response = restTemplate.exchange( instance.getUri() + "/items?ids={ids}", HttpMethod.GET, null, new ParameterizedTypeReference<List<ItemDTO>>() { }, -
然后我们可以发请求,看看哪个服务打印日志了,检测正常。
OpneFeign
快速入门
通过上面代码可以看出,跨服服务发送一个请求还是挺麻烦的。OpenFeign可以让我们的代码更加简单优雅。
OpenFeign是一个声明式的http客户端,是SpringCloud在Eureka公司开源的Feign基础上改造而来。官方地址:https://github.com/OpenFeign/feign
其作用就是基于SpringMVC的常见注解,帮我们优雅的实现http请求的发送。
在使用之前,我们先分析一下我们前面发送请求需要的信息,OpneFeign想必也会用到,有助于我们更好理解
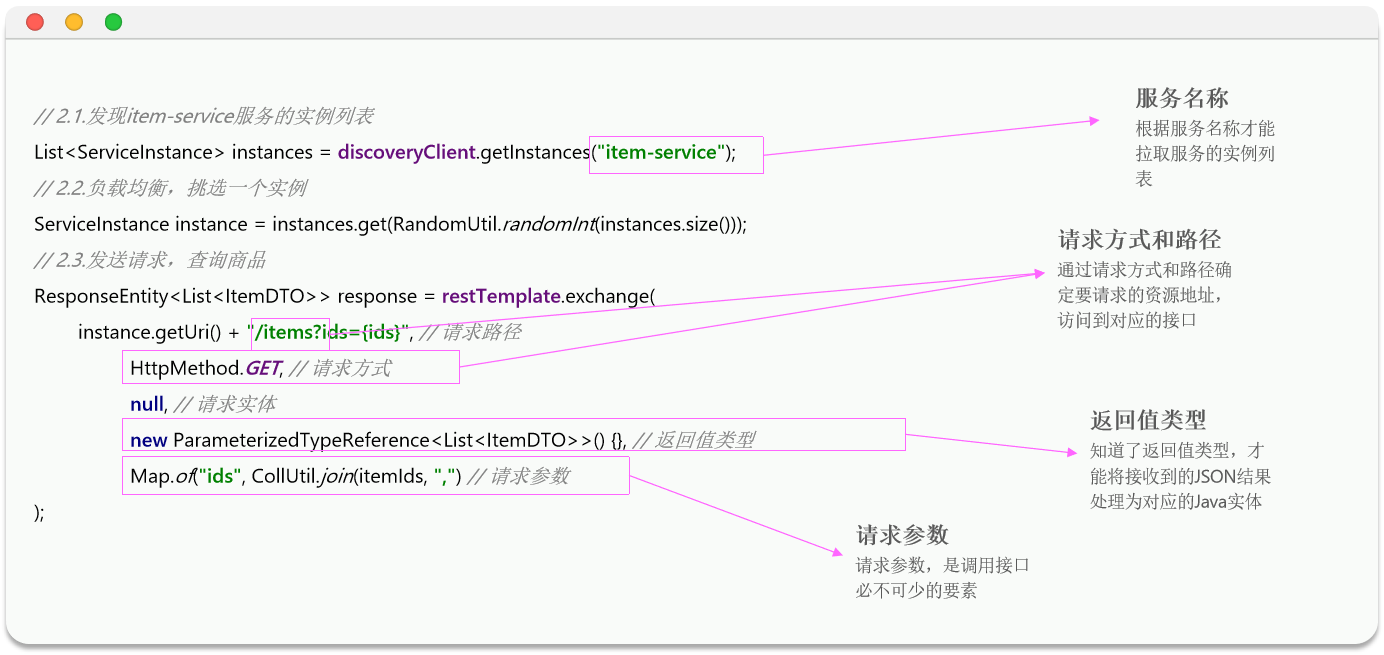
其实远程调用的关键点就在于四个:
- 请求方式
- 请求路径
- 请求参数
- 返回值类型
所以,OpenFeign就利用SpringMVC的相关注解来声明上述4个参数,然后基于动态代理帮我们生成远程调用的代码,而无需我们手动再编写,非常方便。
使用步骤:
以cart-service中的查询我的购物车为例。因此下面的操作都是在cart-service中进行。
-
依赖引入,包括OpenFeign和负载均衡组件SpringCloudLoadBalancer【负载均衡早期用Ribbon,现在用到最新版loadbalancer】
<!--openFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <!--负载均衡器--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> -
通过@EnableFeignClients注解,启用OpenFeign功能
@EnableFeignClients @SpringBootApplication public class CartApplication {略} -
编写FeignClient。其实是个接口,起作用就是代替之前写的主要代码。
package com.hmall.cart.client; import com.hmall.cart.domain.dto.ItemDTO; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestParam; import java.util.Collection; import java.util.List; @FeignClient("item-service") public interface ItemClient { @GetMapping("/items") List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); }- 用注解告诉本接口位OpenFeign客户端,并指定了服务的名称。将来就可以根据服务名称从注册中心中拉去服务列表。
- 负载均衡已经通过依赖引入,接着就可以拿到一个实例了。也就知道uri了
- 然后需要知道请求方式,请求参数,返回值类型。这是通过定义的方法告诉的。方法上的注解指明请求方式和请求路径。【这里用的springMVC的注解是为了降低学习成本】
- 请求参数也是用注解声明@RequestParam,将来就会拼到请求路径后面
- 然后基于方法的返回值指明所需要的返回值类型。
有了上述信息,OpenFeign就可以利用动态代理帮我们实现这个方法,并且向
http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。我们只需要直接调用这个方法,即可实现远程调用了。
-
使用FeignClient,实现远程调用
private final ItemClient itemClient; private void handleCartItems(List<CartVO> vos) { // TODO 1.获取商品id Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet()); List<ItemDTO> items = itemClient.queryItemByIds(itemIds);
连接池
下面我们再深入了解一下实现原理【可以使用断点debug进行分析】,并进行一些优化。
Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括:
- HttpURLConnection:默认实现,不支持连接池
- Apache HttpClient :支持连接池
- OKHttp:支持连接池
因此我们通常会使用带有连接池的客户端来代替默认的HttpURLConnection。比如,我们使用OK Http.
使用的只有两个步骤就可以了。
-
引入依赖。在
cart-service的pom.xml中引入依赖:<!--OK http 的依赖 --> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-okhttp</artifactId> </dependency> -
开启连接池。在
cart-service的application.yml配置文件中开启Feign的连接池功能:feign: okhttp: enabled: true # 开启OKHttp功能
重启服务,连接池就生效了。
验证:
我们可以打断点验证连接池是否生效,在org.springframework.cloud.openfeign.loadbalancer.FeignBlockingLoadBalancerClient中的execute方法中打断点:
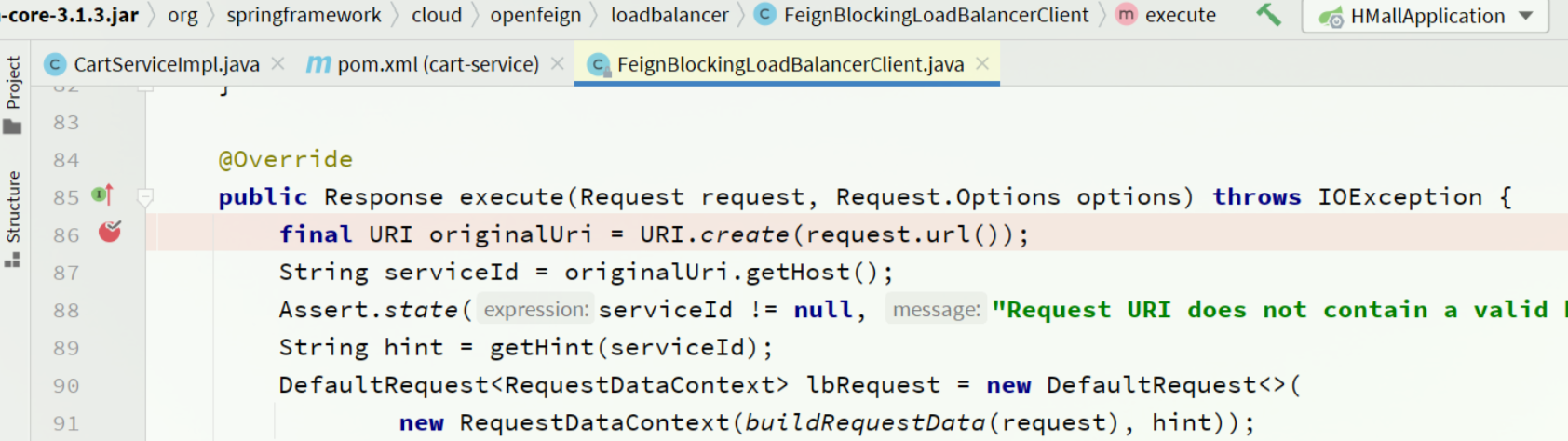
Debug方式启动cart-service,请求一次查询我的购物车方法,进入断点:
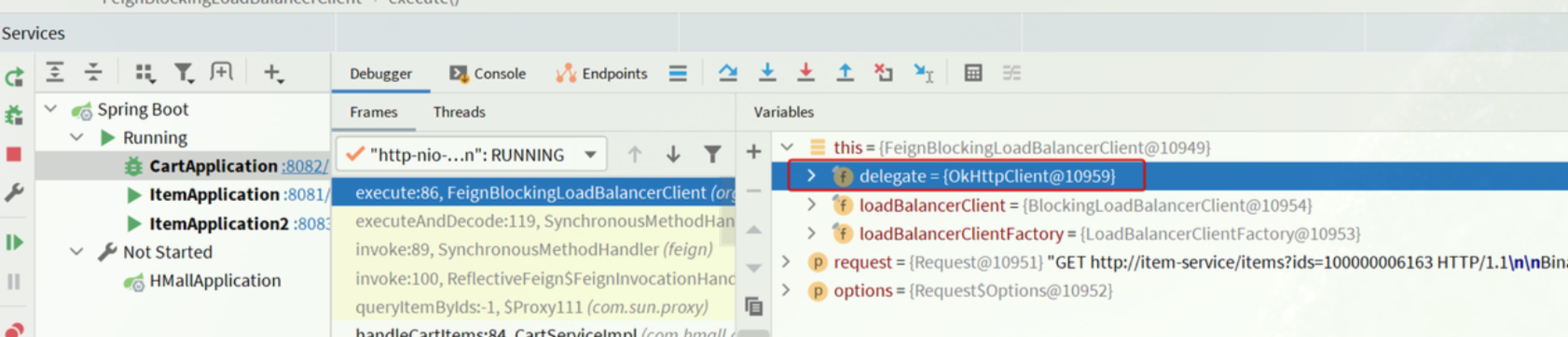
可以发现这里底层的实现已经改为OkHttpClient
最佳实践
有没有实现的最佳方式,所有要请求其他服务的都需要定义clinet接口吗,是不是重复了呢。我们还可以继续优化。
其实实现方式有多种,都还不错。主要方式有如下集中
-
既然重复了,那都别写了。有服务提供者来写【因为提供的服务提供的人最清晰】。再服务下方不直接写java代码了,编程了pom项目,而是写三个模块
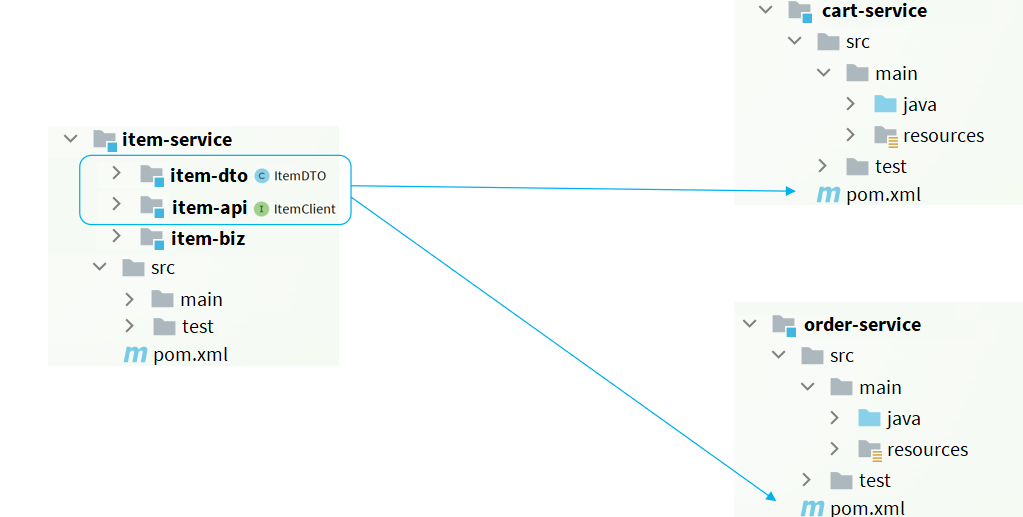
- dto:放实体类。这样服务消费者也不需要重复复制实体类了。
- api:放api接口,可以报feign客户端放进去
- biz:写服务的所有业务代码
接下来直接把前两个的模块坐标,引入到服务消费者项目中即可。
缺点:项目结构太复杂了,微服务又要拆模块了。【这种适合大项目,那种把每个微服务拆成单个项目的拆分方式。加点模块也会很合理】【推荐】
-
不管是提供者还是消费者,都不要写了。我们重新开个项目api。其中定义三个包
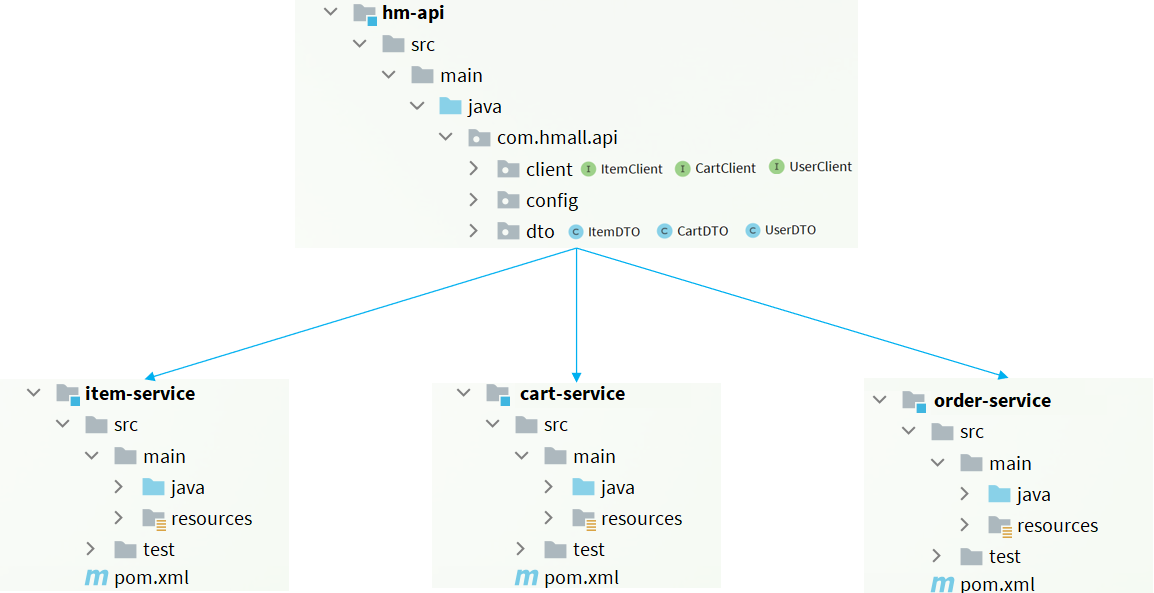
- client:写整个项目每个微服务想要暴露的客户端
- config
- dto:所有需要公共访问的dto。
然后涉及到的模块直接引用依赖即可。
缺点:代码耦合度增加了。【这种适合中型的,那种把每个微服务拆成单个模块的拆分方式。因为已经够多了】
所以根据拆分情况,这里用第二种方式学习
-
新进api模块
-
引入相关依赖。比如openFeign和负载均衡器依赖【这样服务消费者的地方进不用引了。因为最后引api会带着走】。注意:这里没引okhttp依赖,可以让服务请求者自主选择连接方式。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>com.heima</groupId> <artifactId>hmall</artifactId> <version>1.0.0</version> </parent> <artifactId>hm-api</artifactId> <properties> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <!--openFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> <!--负载均衡器--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> <!-- swagger 注解依赖 --> <dependency> <groupId>io.swagger</groupId> <artifactId>swagger-annotations</artifactId> <version>1.6.6</version> <scope>compile</scope> </dependency> </dependencies> </project> -
再
com.hmall.api下创建client和dto包。并把客户端和实体类移过来。之前在服务消费者那就可以删除了 -
可以发现cart模块业务代码报错了,我们把api模块引入,就不报错了。
<!--hm-api--> <dependency> <groupId>com.heima</groupId> <artifactId>hm-api</artifactId> <version>1.0.0</version> </dependency> -
然后我们运行发现报错了。这里因为
ItemClient现在定义到了com.hmall.api.client包下,而cart-service的启动类定义在com.hmall.cart包下,扫描不到ItemClient,所以报错了。解决办法很简单,在cart-service的启动类上添加声明即可,两种方式:-
声明扫描包
@MapperScan("com.hmall.cart.mapper") @EnableFeignClients(basePackages = "com.hmall.api.client") @SpringBootApplication public class CartApplication {略} -
声明要用的FeignClient
@MapperScan("com.hmall.cart.mapper") @EnableFeignClients(clients = ItemClient.class) @SpringBootApplication public class CartApplication {略}
-
日志输出
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
由于Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。只能看到一些sql日志。
调整日志级别的具体方法:
-
要自定义日志级别需要声明一个类型为Logger.Level的Bean,在其中定义日志级别:【可以放到api模块,避免重复定义】
package com.hmall.api.config; import feign.Logger; import org.springframework.context.annotation.Bean; public class DefaultFeignConfig { @Bean public Logger.Level feignLoggerLevel() { return Logger.Level.FULL; } } -
但此时这个Bean并未生效,要想配置某个FeignClient的日志,可以在@FeignClient注解中声明:
@FeignClient(value = "item-service", configuration = DefaultFeignConfig.class) -
如果想要全局配置,让所有FeignClient都按照这个日志配置,则需要在@EnableFeignClients注解中声明:
@EnableFeignClients(clients = {ItemClient.class}, defaultConfiguration = DefaultFeignConfig.class)
平时开发没报错的时候不用开启日志。否则太乱了,影响心情。
合并其他模块,详情见飞书文档:微服务拆分作业参考 - 飞书云文档。主要包含一下三个模块
- 用户服务
- 交易服务
- 支付服务
tips:
-
关于用户登录加密方式不尽相同,知道个大概就行了。不用太懂。
-
实体类和api中引入的实体类重复了就可以不要其他服务的实体类了,直接删掉。
-
写client接口时,可以直接参照对应请求的controller接口。直接复制即可。再稍作修改,比如补全请求地址和去除public,有时参数类型和返回值根据情况改动即可。注意:要理解接口内核。对应的一定要有controller接口。没有的话也要写出来。因为是要通过请求的方式传数据的。
-
如果一个服务消费者中要引入多个服务提供者时。可以通过扫描包的方式声明要用的FeignClient。
@EnableFeignClients(basePackages = "com.hmall.api.client")
需要注意的是,再这个过程中,有很多地方都需要当前登录的用户信息。但目前只有user服务有。其他服务如何获取登录的用户信息是个问题。另外,目前有多个微服务,每个微服务都有自己的端口。我们前端应该如何进行对应访问,也是一个问题。那下面我们将进行解决。
网关
根据上面所说确实存在问题:
- 前端如何请求后端
- 各微服务如何获取登录用户信息。密钥如何管理,避免泄露和重复。
那网关就可以很好的解决上面的问题。相当于小区的保安管理整个小区(整个微服务集群)。这样前端只知道网关地址就行了。
网关就是网络的关口,负责请求的路由、转发、身份校验。
- 路由:判断又哪个服务处理
- 转发:将请求转发到具体服务,【这里的服务可能有多个实例。网关也可以看作一个服务,它会从注册中心管理获取微服务信息,然后负载均衡进行转发】
- 身份校验
以后微服务地址也不用暴露给前端了,对微服务也是一种保护。对于前端和开发单体架构时没区别,小区就相当于黑盒。
在Spring Cloud中网关的实现包括两种:
Spring Cloud Gateway:【响应式编程更加强大。现为主流,这里主要学习这个】
- Spring官方出品
- 基于WebFlux响应式编程
- 无需调优即可获得优异性能
Netfilx Zuul:
- Netflix出品
- 基于Servlet的阻塞式编程
- 需要调优才能获得与SpringCloudGateway类似的性能
网关路由
快速入门
网关转发的动作(服务拉去,负载均衡,转发)是与业务无关的事情,可以由网关自动完成。 但网关的路由,即哪个请求由哪个服务去处理,这就和我们的业务有关了,这就需要开发人员配置路由规则了。
如何创建网关,分为一下四个步骤。
- 创建网关微服务
- 引入SpringCloudGateway、NacosDiscovery依赖
- 编写启动类
- 配置网关路由【可以看出,前三步和创建模块相同,这里重点关注如何配置】
predicatse路由规则,可以配置多个。等号左边是规则的名字,后面是规则。
具体实例如下:
-
创建hm-gateway模块
-
引入依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>com.heima</groupId> <artifactId>hmall</artifactId> <version>1.0.0</version> </parent> <artifactId>hm-gateway</artifactId> <properties> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <!--common--> <dependency> <groupId>com.heima</groupId> <artifactId>hm-common</artifactId> <version>1.0.0</version> </dependency> <!--网关--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--nacos discovery--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--负载均衡--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> </dependencies> <build> <finalName>${project.artifactId}</finalName> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project> -
编写启动类
package com.hmall.gateway; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class GatewayApplication { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class, args); } } -
配置路由规则
server: port: 8080 spring: application: name: gateway cloud: nacos: server-addr: 192.168.150.101:8848 gateway: routes: - id: item # 路由规则id,自定义,唯一 uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表 predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务 - Path=/items/**,/search/** # 这里是以请求路径作为判断规则.等号左边是规则的名字,后面是规则。,如果有多个controller路径,可以用逗号分割。或直接写多行。 - id: cart uri: lb://cart-service predicates: - Path=/carts/** - id: user uri: lb://user-service predicates: - Path=/users/**,/addresses/** - id: trade uri: lb://trade-service predicates: - Path=/orders/** - id: pay uri: lb://pay-service predicates: - Path=/pay-orders/** -
测试,用8080端口访问接口。相应正常,查看控制台,负载均衡正常。
路由属性
上面的内容在官网也是可以找到的,进行详细学习。Spring Cloud Gateway
网关路由对应的Java类型是RouteDefinition,其中常见的属性有:
- id:路由唯一标示
- uri:路由目标地址
- predicates:路由断言,判断请求是否符合当前路由。【提供了有很多种,上节课只用了一种。下面进行详细介绍】
- filters:路由过滤器,对请求或响应做特殊处理。【】
路由断言
Spring提供了12种基本的RoutePredicateFactory实现:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=**.somehost.org,**.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 | - Weight=group1, 2 |
| XForwarded Remote Addr | 基于请求的来源IP做判断 | - XForwardedRemoteAddr=192.168.1.1/24 |
路由过滤器
网关中提供了33种路由过滤器,每种过滤器都有独特的作用。
| 名称 | 说明 | 示例 |
|---|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 | AddrequestHeader=headerName,headerValue |
| RemoveRequestHeader | 移除请求中的一个请求头 | RemoveRequestHeader=headerName |
| AddResponseHeader | 给响应结果中添加一个响应头 | AddResponseHeader=headerName,headerValue |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 | RemoveResponseHeader=headerName |
| RewritePath | 请求路径重写 | RewritePath=/red/?(?<segment>.*), /$\{segment} |
| StripPrefix | 去除请求路径中的N段前缀 | StripPrefix=1,则路径/a/b转发时只保留/b |
| ... |
实例:
- id: pay
uri: lb://pay-service
predicates:
- Path=/pay-orders/**
filters:
- AddResponseHeader=headerName, hello world
如果所有请求都要设置,那么可以进行统一设置【与routes同级】
default-filters: AddResponseHeader=headerName, hello world
网关登录校验
登录授权不用变,路由转发到user服务,给jwt密钥即可。但是验证需要网关了,同时给其他服务当前登录用户信息。
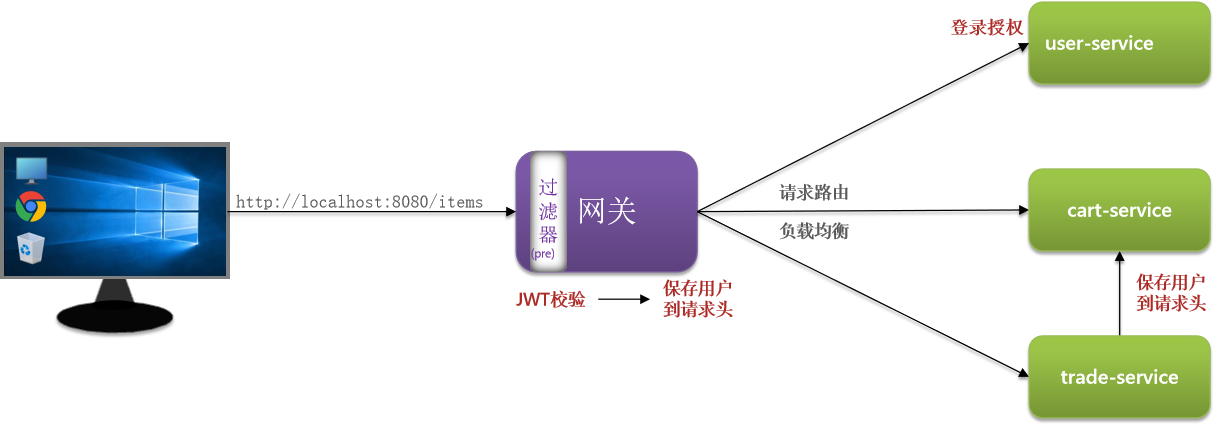
网关也是服务,把信息放到请求头传递给其他微服务再合适不过了。
微服务之间的请求是openfeign的请求。而网关和微服务之间的请求是网关内置的请求。实现方式上有差别。
登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。
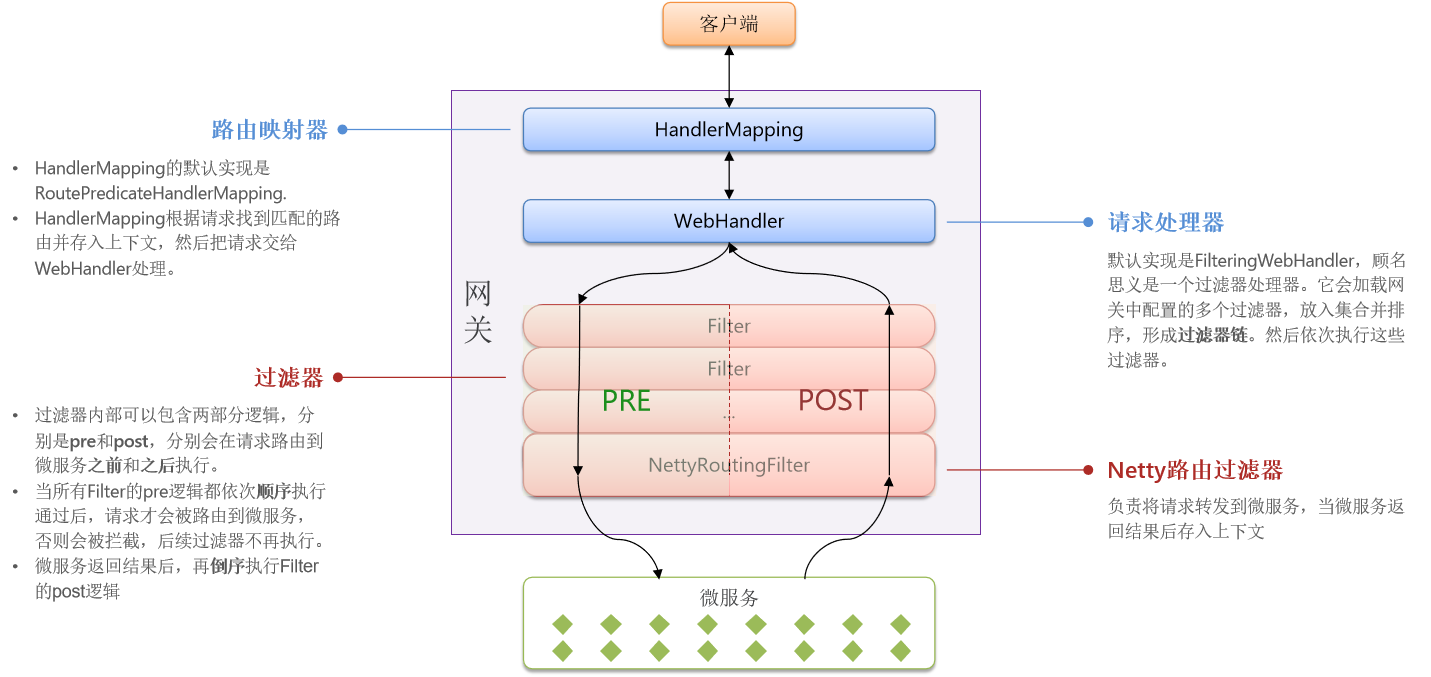
可以看出,我们应该把校验过滤器放在NettyRoutingFilter之前的pre中。
下面我们将关注下面三个问题
- 如何在网关转发之前做登录校验?
- 网关如何将用户信息传递给微服务?
- 如何在微服务之间传递用户信息?
自定义过滤器
网关过滤器有两种,分别是:
- GatewayFilter:路由过滤器,作用于任意指定的路由;默认不生效,要配置到路由后生效。【就是上面在配置中学到的Filter】
- GlobalFilter:全局过滤器,作用范围是所有路由;声明后自动生效。
两种过滤器的过滤方法签名完全一致:

GlobalFilter
其中有两个参数:
-
ServerWebExchange exchange
请求上下文,包含整个过滤器链内共享数据,例如request、response等
-
GatewayFilterChain chain
过滤器链。当前过滤器执行完后,要调用过滤器链中的下一个过滤器
方法中编写的都是pre逻辑
Mono,网关采用非阻塞式的编程,通过利用Mono定义回调函数。这样就不用等待了,将来返回结果有了,在调用回调函数,执行post逻辑。其实在实际开发中,大多数情况下基本不用post,用到了再到官网学习即可。
放行记得传递上下文,实现上下文信息
实例代码:
package com.hmall.gateway.filters;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpHeaders;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
public class MyGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//TODO 模拟登录校验逻辑
//1.获取请求
ServerHttpRequest request = exchange.getRequest();
// 2.过滤器业务处理
HttpHeaders headers = request.getHeaders();
System.out.println("headers:" + headers);
//3.放行,并传递上下文,实现上下文共享
return chain.filter(exchange);
}
@Override
public int getOrder() {
// 过滤器执行顺序,值越小,优先级越高。比NettyRoutingFilter这个int范围中最大的即可。可通过源码看出(通过搜索定位)
return 0;
}
}
GatewayFilter
GatewayFilter在使用的过程中可以自由的去指定作用的范围,配置自定义参数,使用更加的灵活,但是要自定义一个GatewayFilter的话就比较麻烦了,我们日常开发中,要自定义过滤器,大部分都是选择GlobalFilter。所以不常用。
需要继承一个工厂。过滤器随参数变化而变化,每次变化都会有一个新的过滤器对象,因此就需要这个工厂类,来读取配置,创建一个定制化的过滤器对象(apply方法)。
自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory。最简单的方式是这样的:

@Component
public class PrintAnyGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {
@Override
public GatewayFilter apply(Object config) {
return new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 获取请求
ServerHttpRequest request = exchange.getRequest();
// 编写过滤器逻辑
System.out.println("过滤器执行了");
// 放行
return chain.filter(exchange);
}
};
}
}
注意:该类的名称一定要以GatewayFilterFactory为后缀!前缀就是过滤器名字。过滤器可以无参。
然后在yaml配置中这样使用:
spring:
cloud:
gateway:
default-filters:
- PrintAny # 此处直接以自定义的GatewayFilterFactory类名称前缀类声明过滤器
可以装饰类(OrderedGatewayFilter)结合匿名类来控制生效顺序,当然也可以不用匿名类,没通过实现getOrder方法控制生效顺序。另外,这种过滤器还可以支持动态配置参数,不过实现起来比较复杂,示例:
@Component
public class PrintAnyGatewayFilterFactory // 父类泛型是内部类的Config类型
extends AbstractGatewayFilterFactory<PrintAnyGatewayFilterFactory.Config> {
@Override
public GatewayFilter apply(Config config) {
// OrderedGatewayFilter是GatewayFilter的子类,包含两个参数:
// - GatewayFilter:过滤器
// - int order值:值越小,过滤器执行优先级越高
return new OrderedGatewayFilter(new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 获取config值
String a = config.getA();
String b = config.getB();
String c = config.getC();
// 编写过滤器逻辑
System.out.println("a = " + a);
System.out.println("b = " + b);
System.out.println("c = " + c);
// 放行
return chain.filter(exchange);
}
}, 100);
}
// 自定义配置属性,成员变量名称很重要,下面会用到
@Data
static class Config{
private String a;
private String b;
private String c;
}
// 将变量名称依次返回,顺序很重要,将来读取参数时需要按顺序获取
@Override
public List<String> shortcutFieldOrder() {
return List.of("a", "b", "c");
}
// 返回当前配置类的类型,也就是内部的Config
@Override
public Class<Config> getConfigClass() {
return Config.class;
}
}
然后在yaml文件中使用:
spring:
cloud:
gateway:
default-filters:
- PrintAny=1,2,3 # 注意,这里多个参数以","隔开,将来会按照shortcutFieldOrder()方法返回的参数顺序依次复制
上面这种配置方式参数必须严格按照shortcutFieldOrder()方法的返回参数名顺序来赋值。
还有一种用法,无需按照这个顺序,就是手动指定参数名:
spring:
cloud:
gateway:
default-filters:
- name: PrintAny
args: # 手动指定参数名,无需按照参数顺序
a: 1
b: 2
c: 3
实现登录校验
我们日常开发中,一般是通过GlobalFilter的方式自定义过滤器。
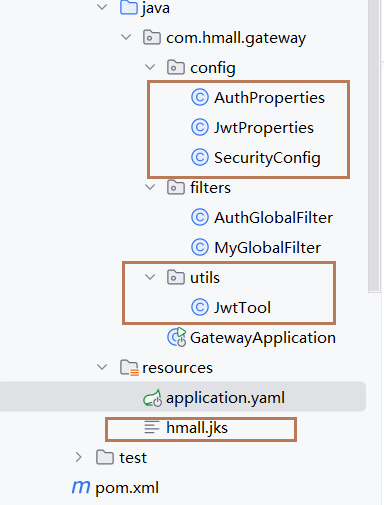
在这个项目中,是通过jwt实现登录的,无论是jwt的token生成和校验,都是需要用到密钥和工具类的。保存密钥本事的jks文件也是加密的,需要密码。
配置信息示例如下:
hm:
jwt:
location: classpath:hmall.jks
alias: hmall
password: hmall123 #解析密钥文件的密码
tokenTTL: 30m
auth:
excludePaths: #相当于白名单
- /search/**
- /users/login
- /items/**
- /hi
配置文件的信息,通过属性类去读取。
其中JwtProperties和AuthProperties的类就是分别负责读取jwt和auth的属性值【用注释指定前缀区分】,代码如下:
JwtProperties
@Data
@ConfigurationProperties(prefix = "hm.jwt")
public class JwtProperties {
private Resource location;
private String password;
private String alias;
private Duration tokenTTL = Duration.ofMinutes(10);
}
AuthProperties
@Data
@Component
@ConfigurationProperties(prefix = "hm.auth")
public class AuthProperties {
private List<String> includePaths;
private List<String> excludePaths;
}
SecurityConfig
@Configuration
@EnableConfigurationProperties(JwtProperties.class)
public class SecurityConfig {
@Bean
public PasswordEncoder passwordEncoder(){
return new BCryptPasswordEncoder();
}
@Bean
public KeyPair keyPair(JwtProperties properties){
// 获取秘钥工厂
KeyStoreKeyFactory keyStoreKeyFactory =
new KeyStoreKeyFactory(
properties.getLocation(),
properties.getPassword().toCharArray());
//读取钥匙对
return keyStoreKeyFactory.getKeyPair(
properties.getAlias(),
properties.getPassword().toCharArray());
}
}
JwtTool工具
package com.hmall.gateway.utils;
import cn.hutool.core.exceptions.ValidateException;
import cn.hutool.jwt.JWT;
import cn.hutool.jwt.JWTValidator;
import cn.hutool.jwt.signers.JWTSigner;
import cn.hutool.jwt.signers.JWTSignerUtil;
import com.hmall.common.exception.UnauthorizedException;
import org.springframework.stereotype.Component;
import java.security.KeyPair;
import java.time.Duration;
import java.util.Date;
@Component
public class JwtTool {
private final JWTSigner jwtSigner;
public JwtTool(KeyPair keyPair) {
this.jwtSigner = JWTSignerUtil.createSigner("rs256", keyPair);
}
/**
* 创建 access-token
*
* @param userId 用户信息
* @return access-token
*/
public String createToken(Long userId, Duration ttl) {
// 1.生成jws
return JWT.create()
.setPayload("user", userId)
.setExpiresAt(new Date(System.currentTimeMillis() + ttl.toMillis()))
.setSigner(jwtSigner)
.sign();
}
/**
* 解析token
*
* @param token token
* @return 解析刷新token得到的用户信息
*/
public Long parseToken(String token) {
// 1.校验token是否为空
if (token == null) {
throw new UnauthorizedException("未登录");
}
// 2.校验并解析jwt
JWT jwt;
try {
jwt = JWT.of(token).setSigner(jwtSigner);
} catch (Exception e) {
throw new UnauthorizedException("无效的token", e);
}
// 2.校验jwt是否有效
if (!jwt.verify()) {
// 验证失败
throw new UnauthorizedException("无效的token");
}
// 3.校验是否过期
try {
JWTValidator.of(jwt).validateDate();
} catch (ValidateException e) {
throw new UnauthorizedException("token已经过期");
}
// 4.数据格式校验
Object userPayload = jwt.getPayload("user");
if (userPayload == null) {
// 数据为空
throw new UnauthorizedException("无效的token");
}
// 5.数据解析
try {
return Long.valueOf(userPayload.toString());
} catch (RuntimeException e) {
// 数据格式有误
throw new UnauthorizedException("无效的token");
}
}
}
最后我们就可以写AuthGlobalFilter了
示例代码如下【传递用户信息省略了,后面补齐】
package com.hmall.gateway.filters;
import cn.hutool.core.text.AntPathMatcher;
import com.hmall.common.exception.UnauthorizedException;
import com.hmall.gateway.config.AuthProperties;
import com.hmall.gateway.utils.JwtTool;
import lombok.RequiredArgsConstructor;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.util.List;
@Component
@RequiredArgsConstructor
public class AuthGlobalFilter implements GlobalFilter, Ordered {
private final AuthProperties authProperties;
private final JwtTool jwtTool;
private final AntPathMatcher antPathMatcher = new AntPathMatcher();
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取request
ServerHttpRequest request = exchange.getRequest();
// 2.判断是否需要左登录拦截
if (isExclude(request.getPath().toString())) {
//放行
return chain.filter(exchange);
}
// 3.获取token
String token = null;
List<String> headers = request.getHeaders().get("authorization");//返回列表,一个键可能对应多个值
if (headers != null || !headers.isEmpty()) {
token = headers.get(0);
}
// 4.校验并解析token
Long userId = null;
try {
userId = jwtTool.parseToken(token);
} catch (UnauthorizedException e) {
//终止请求,可以抛异常,但页面状态码为500,可以更具体一点,通过设置http状态码终止请求
//拦截,设置相应状态码
ServerHttpResponse response = exchange.getResponse();
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete(); //complete,终止了
}
// TODO 5.传递用户信息
System.out.println("userId" + userId);
// 6.放行
return chain.filter(exchange);
}
private boolean isExclude(String path) {
for (String pathPattern : authProperties.getExcludePaths()) {
//由于路径匹配比较特殊,这里用spring提供的AntPathMatcher
if (antPathMatcher.match(pathPattern, path)) {
return true;
}
}
return false;
}
@Override
public int getOrder() {
return 0;
}
}
网关传递用户
光验证还不够,还需要向下传递用户信息。
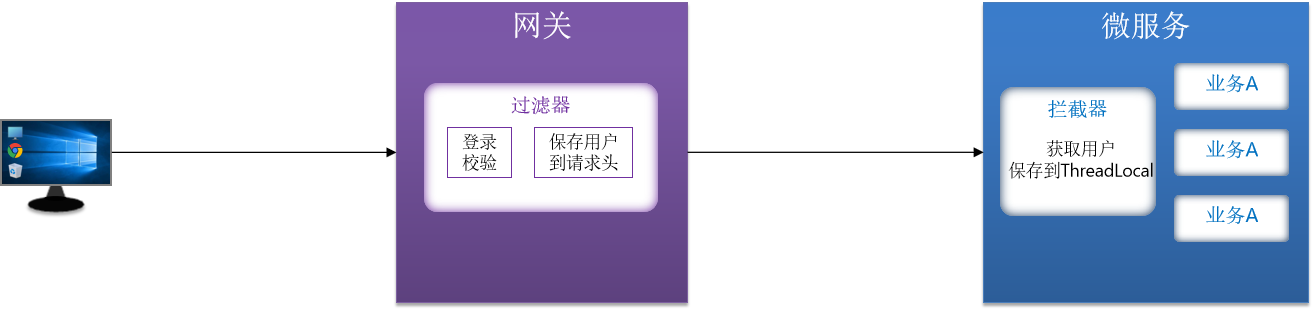
微服务中的业务有很多,需要用户信息的业务有很多,不可能每个业务都写一遍,所以在微服务中,在业务之前获取用户信息,可以通过spring MVC的拦截器。放到TreadLocal中
要实现这个工程有一下步骤:
-
在网关的登录校验过滤器中,把获取到的用户写入请求头
在上面的过滤器中修改一下5、6步骤即可
// 5.传递用户信息 String userInfo = userId.toString(); ServerWebExchange swe = exchange.mutate() .request(builder -> builder.header("user-info", userInfo)) .build(); // 6.放行 return chain.filter(swe);其中,mutate突变,对请求做处理,用builder对请求中的各种信息做修改。请求头的名字可以随便写,跟微服务开发中约定好就行。两边对上就行,可以写个常量。返回一个新的exchange。放行新的exchange。
-
在hm-common中编写SpringMVC拦截器,获取登录用户
由于每个微服务都可能有获取登录用户的需求,因此我们直接在hm-common模块定义拦截器,这样微服务只需要引入依赖即可生效,无需重复编写。
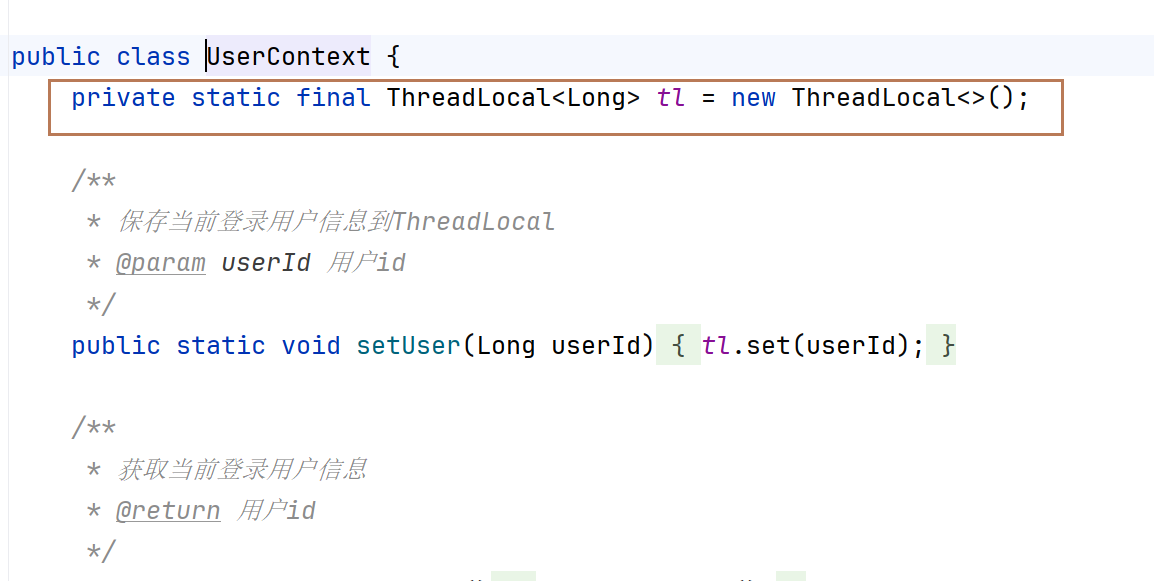
在hm-common中已经有一个用于保存登录用户的ThreadLocal工具UserContext.其中已经提供了保存和获取用户的方法.只需要编写拦截器,获取用户信息并保存到
UserContext,然后放行即可。这里的api略有不同。我们这里的拦截器不做拦截,只做信息获取就行了。public class UserInfoInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //存用户 // 1.获取用户信息 String userInfo = request.getHeader("user-info"); // 2.判断请求是否获取了用户,如果有,存入ThreadLocal if (StrUtil.isNotBlank(userInfo)) { UserContext.setUser(Long.valueOf(userInfo)); } // 3.放行 return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { //清理用户 UserContext.removeUser(); } }拦截器要配置才能生效。默认拦截所有的路径。这里创建配置类
package com.hmall.common.config; import com.hmall.common.interceptor.UserInfoInterceptor; import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.InterceptorRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; @Configuration public class MvcConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { //这里默认对所有路径都生效,所以不用加.addPathPatterns("/**")了 registry.addInterceptor(new UserInfoInterceptor()); } }最后还要让微服务扫描到这个报下才能生效。学过springboot自动装配的原理可以知道,这里在resources/META-INF下的factories配置文件(这是老版本的配置文件)中加入扫描路径才行
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.hmall.common.config.MyBatisConfig,\ com.hmall.common.config.MvcConfig,\ com.hmall.common.config.JsonConfig运行了一些发现报错了。这里网关也引入common,但网关中没有不是springmvc,而是非阻塞式响应式,基于webflix编程。没有mvcConfig就报错了。跟springboot自动装配的原理,可以给配置了加条件,进行有选择的装配。网关相比其他微服务,没有springmvc。我们根据这一点做有条件的装配
@Configuration @ConditionalOnClass({DispatcherServlet.class}) //有条件的进行装配 public class MvcConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { //这里默认对所有路径都生效,所以不用加.addPathPatterns("/**")了 registry.addInterceptor(new UserInfoInterceptor()); } }
思考:为什么不能直接把用户信息存到网关中?
参考:网关是存到请求头里了啊,跨服务没法使用threadlocal的,这个是因为所有服务都引用common所以在这里写一个拦截器存相当于全局的了。要理解common与网关的不同。common模块可以说是一个依赖包,引入就可以了
UserContext原理介绍
-
ThreadLocal 核心原理
ThreadLocal 为每个线程创建独立的变量副本,不同线程之间互不干扰。
-
为什么能准确存储"当前用户"
- Web服务器(如Tomcat)为每个请求分配独立的线程
- 同一个请求在整个处理过程中都在同一个线程中执行
- ThreadLocal 将用户ID与当前线程绑定
-
线程安全
- 每个线程独立存储,天然线程安全
- 不需要同步锁,性能好
总之,ThreadLocal + 拦截器的组合实现了:
- 请求级别的数据隔离
- 优雅的上下文传递
- 代码的简洁性
- 良好的性能
可以这样理解:
- 每个请求都会触发拦截器
- 拦截器负责解析并设置用户信息到当前线程
- 整个请求链路中都可以直接获取用户信息
- 请求结束后必须清理,避免内存泄漏和用户信息混乱
OpenFeign传递用户
上面我们讲的是网关传递用户,但是对于复杂的业务,调用了比较长可以出现微服务直接的调用。
微服务项目中的很多业务要多个微服务共同合作完成,而这个过程中也需要传递登录用户信息,例如:
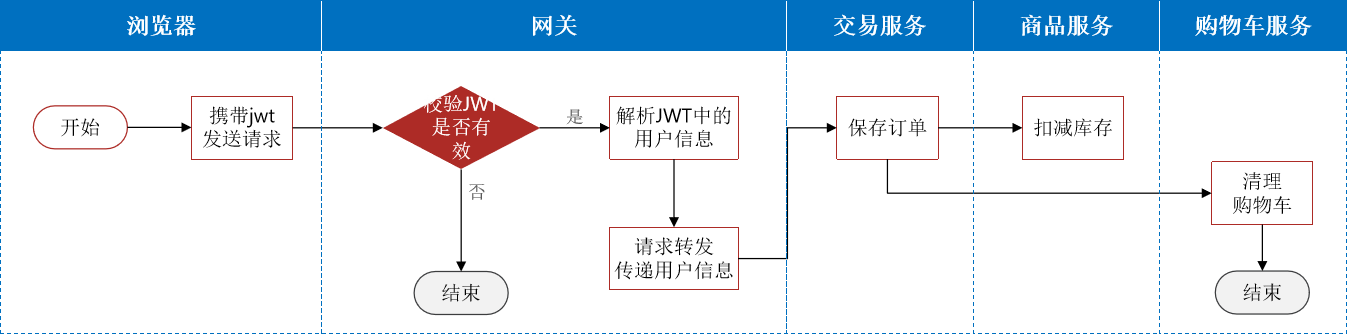
这就与网关和微服务之间的传递不同了。
如果直接请求的话,第三方微服务是没有用户信息的,因为这是微服务之间的请求,没有通过网关,在现有的代码中,没有对请求头中加入用户信息,所以第三方微服务拿不到用户信息。
我们之前是通过OpenFeign实现微服务之间的请求的。OpenFeign中提供了一个拦截器接口,所有由OpenFeign发起的请求都会先调用拦截器处理请求,其中的RequestTemplate类中提供了一些方法可以让我们修改请求头。
拦截器放在api模块就行,只要用到了请求的逻辑,引入api模块,也就用了这个拦截器了。因为操作简单,没有必要重新定义一个拦截器了。可以用匿名内部类实现【这里放到了DefaultFeignConfig,当然也可以定义一个新的配置类实现】。
public class DefaultFeignConfig {
@Bean
public Logger.Level feignLoggerLevel() {
return Logger.Level.NONE;
}
@Bean
public RequestInterceptor userInfoRequestInterceptor() {
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate template) {
Long userId = UserContext.getUser();
if (userId != null) {
template.header("user-info", userId.toString());
}
}
};
}
}
其中用到了UserContext。可以导一下common包。最后别忘了加注解,让配置类生效。
配置管理
有了上面的知识,其实已经具备了微服务开发的能力了。其他的小问题,不解决也能开发,解决了会更加便捷,是一个锦上添花的过程。配置管理就是这个过程。
我们还存在一下问题
-
微服务重复配置过多,维护成本高
我们在整个过着中,我们微服务的配置比较多,而且很多都是重复的。比如mysql数据库的配置、日志和swagger接口文档的配置等等。如果微服务数量成千上万的话,修改起来很繁琐。可以引入配置管理组件。对于通用的配置可以交给它配置。共享效果。
-
业务配置经常变动,每次修改都要重启服务
登录超时时间,次数上限。数量上限等等。即便写道配置文件中,服务也要重启,用户体验不好。
-
网关路由配置写死,如果变更要重启网关
网关请求路由变更的话,重启的话,也很不好。
以上都可以交给配置管理,监听配置变动,推送变更消息到对应服务。这样无需重启,立刻生效。
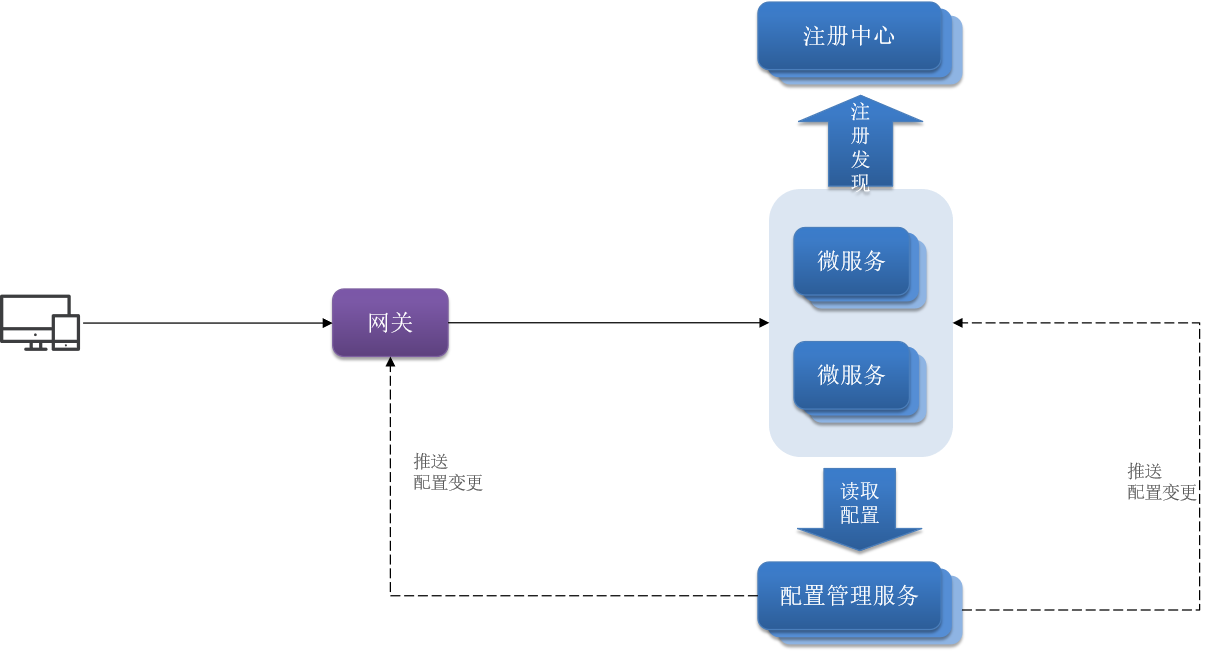
综上,配置管理主要有两个亮点
- 共享效果
- 无需重启,立即生效。实现配置热更新。
惊喜的是我们nacos还可以配置管理服务。降低了学习成本

配置共享
对于重复度比较高度配置,可以放到nacos中,实现配置共享。如何实现配置共享呢,有如下两步:
添加共享配置
添加一些共享配置到Nacos中,包括:Jdbc、MybatisPlus、日志、Swagger、OpenFeign等配置。
在nacos中添加这些配置很方便,不用编写代码,用图形化操作即可。
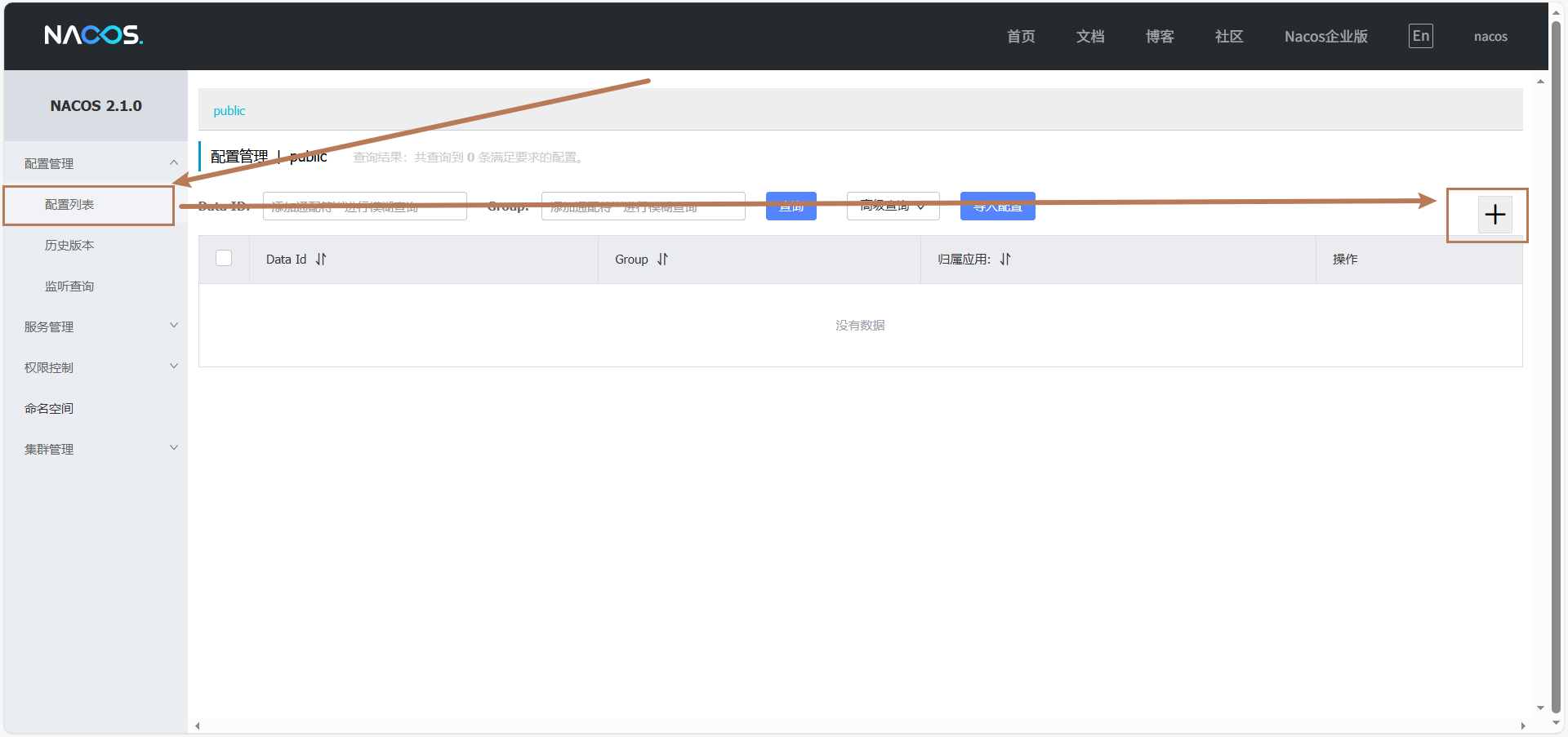
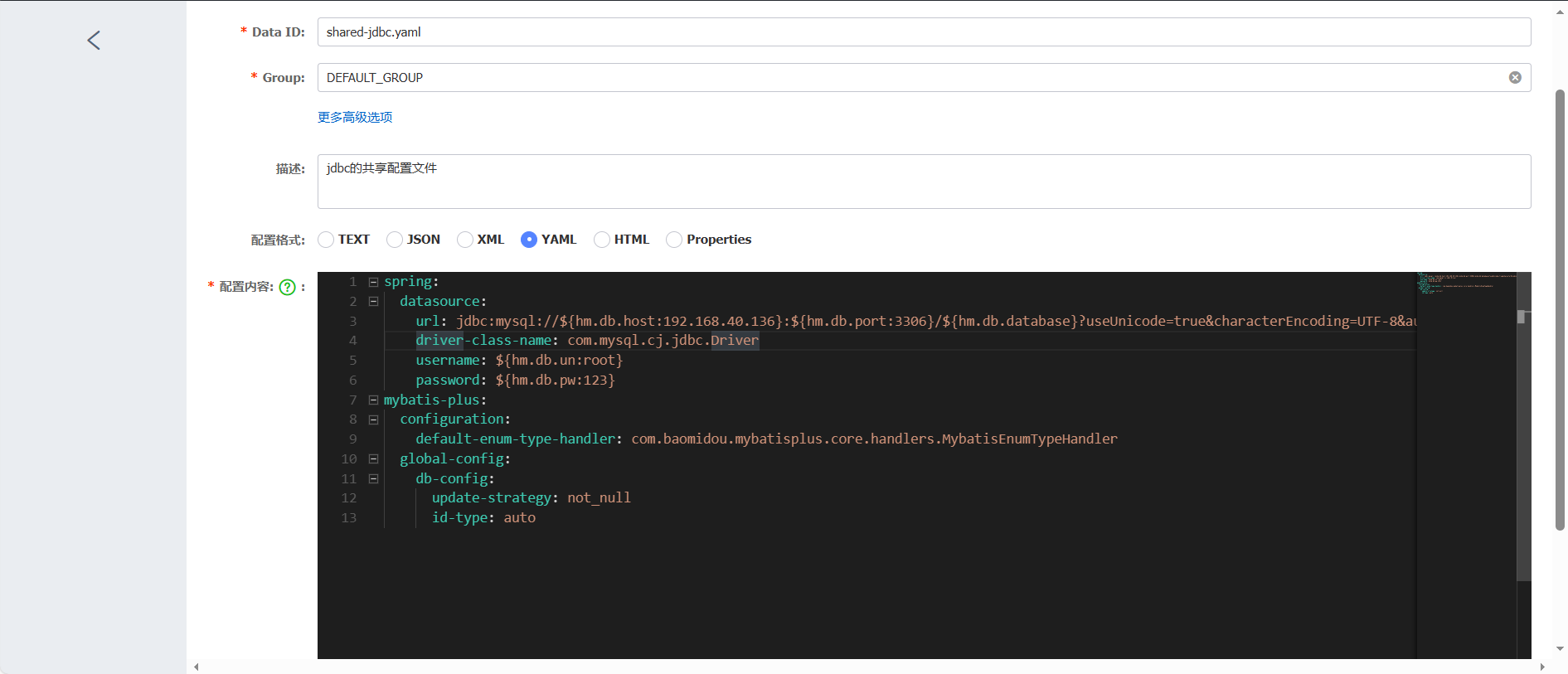
DataID可以理解为配置文件的名称。Group就是一个分组。这么默认就可以。对于一些字段,比如数据库名,尽可能不要写死,比如数据库名字。可以::设置默认值
示例代码如下:【可以建多个文件】
jdbc相关配置shared-jdbc.yaml
spring:
datasource:
url: jdbc:mysql://${hm.db.host:192.168.150.101}:${hm.db.port:3306}/${hm.db.database}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: ${hm.db.un:root}
password: ${hm.db.pw:123}
mybatis-plus:
configuration:
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
global-config:
db-config:
update-strategy: not_null
id-type: auto
统一的日志配置shared-log.yaml
logging:
level:
com.hmall: debug
pattern:
dateformat: HH:mm:ss:SSS
file:
path: "logs/${spring.application.name}"
统一的swagger配置shared-swagger.yaml
knife4j:
enable: true
openapi:
title: ${hm.swagger.title:黑马商城接口文档}
description: ${hm.swagger.description:黑马商城接口文档}
email: ${hm.swagger.email:zhanghuyi@itcast.cn}
concat: ${hm.swagger.concat:虎哥}
url: https://www.itcast.cn
version: v1.0.0
group:
default:
group-name: default
api-rule: package
api-rule-resources:
- ${hm.swagger.package}
拉取共享配置
基于NacosConfig拉取共享配置代替微服务的本地配置。
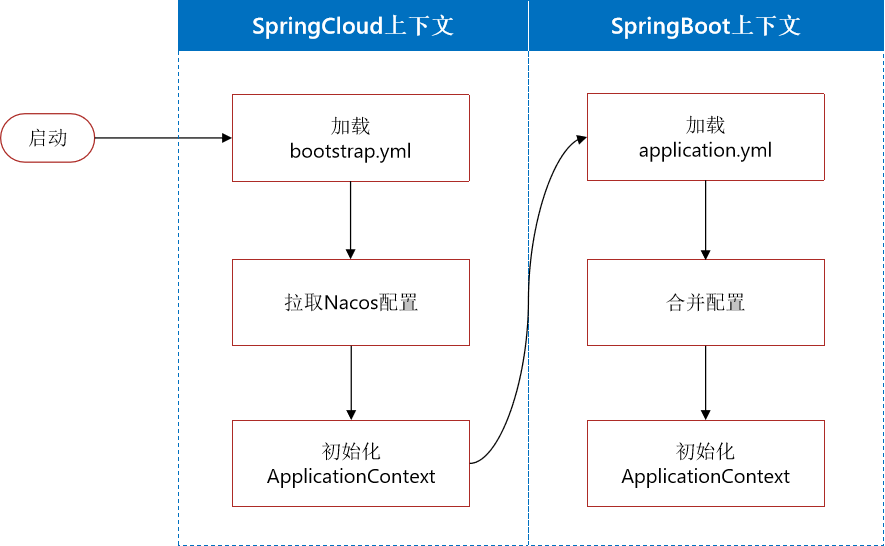
相比传统的Spring Boot项目的加载【启动->加载->初始化】。这里又加了一些步骤,不过,需要注意的是,读取Nacos配置是SpringCloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段。然后才会初始化SpringBoot上下文,去读取application.yaml。
也就是说引导阶段,application.yaml文件尚未读取,根本不知道nacos 地址,该如何去加载nacos中的配置文件呢?
SpringCloud在初始化上下文的时候会先读取一个名为bootstrap.yaml(或者bootstrap.properties)的文件,如果我们将nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取nacos中的配置了。
这个过程其实不用我们写,引入依赖就行了。
-
引入依赖:
在cart-service模块引入依赖:
<!--nacos配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> -
新建
bootstrap.yaml在cart-service中的resources目录新建一个
bootstrap.yaml文件:
spring: application: name: cart-service # 服务名称 profiles: active: dev #环境 cloud: nacos: server-addr: 192.168.150.101 # nacos地址 config: file-extension: yaml # 文件后缀名 shared-configs: # 共享配置 - dataId: shared-jdbc.yaml # 共享mybatis配置 - dataId: shared-log.yaml # 共享日志配置 - dataId: shared-swagger.yaml # 共享日志配置 -
修改
application.yaml由于一些配置挪到了
bootstrap.yaml,因此application.yaml需要修改为:【把已经配置好的信息去除,写一些给字段赋值的信息】server: port: 8082 feign: okhttp: enabled: true # 开启OKHttp连接池支持 hm: swagger: title: 购物车服务接口文档 package: com.hmall.cart.controller db: database: hm-cart -
启动项目,发现正常启动,日志中显示正常拉去配置文件
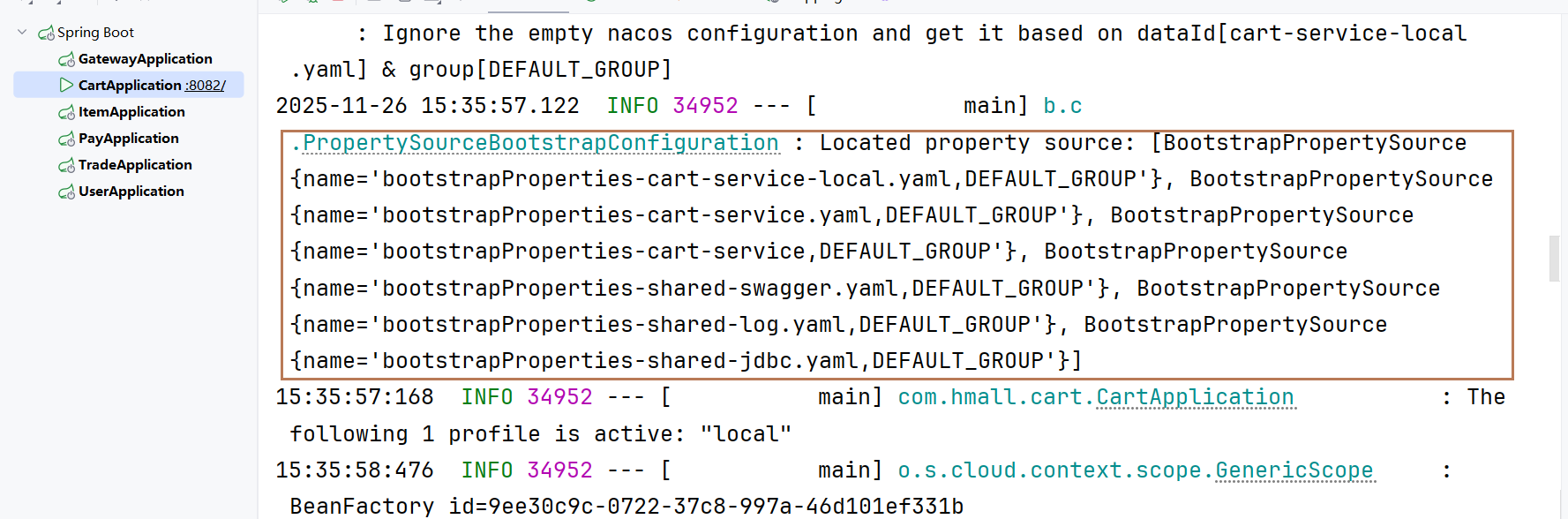
远程大于本地,nacos中的配置优先级高
配置热更新
当修改配置文件中的配置时,微服务无需重启即可使配置生效。这就是配置热更新。
我们要实现配置热更新,需要满足一定的前提条件。
前提条件:
-
nacos中要有一个与微服务名有关的配置文件。

例如:user-service-dev.yaml。这就是为什么bootstap.yaml为什么要配置这些内容了。自动就拼起来了。可以在日志中看到。所以将来nacos中有这个文件的话,不用指定,自动就能读到
-
微服务中要以特定方式读取需要热更新的配置属性。有两种方式。第二种太传统了。还要用到一个新的注解——RefreshScope注解。所以推荐使用第一种。来获取配置文件中的属性值

案例:购物车商品数量不能超过20个
我们可以从已有的代码中发现。我们之前是写死的
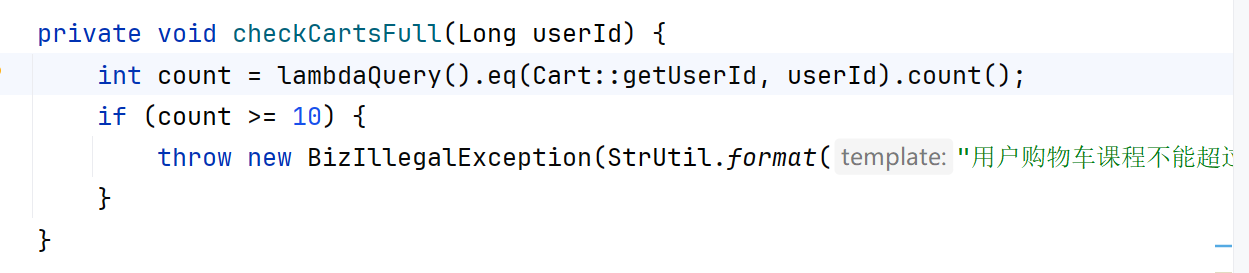
我们下面使用配置热更新。
首先写一个配置类
package com.hmall.cart.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component
@ConfigurationProperties(prefix = "hm.cart")
public class CartProperties {
private Integer maxAmount;
}
然后在进行注入使用。这里实在CartServiceImpl文件中的
private final CartProperties cartProperties;
private void checkCartsFull(Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= cartProperties.getMaxAmount()) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", cartProperties.getMaxAmount()));
}
}
最后别忘了,在nacos中进行配置:【这里我们直接使用cart-service.yaml这个名称,环境名可以省略,则不管是dev还是local环境都可以共享该配置。】
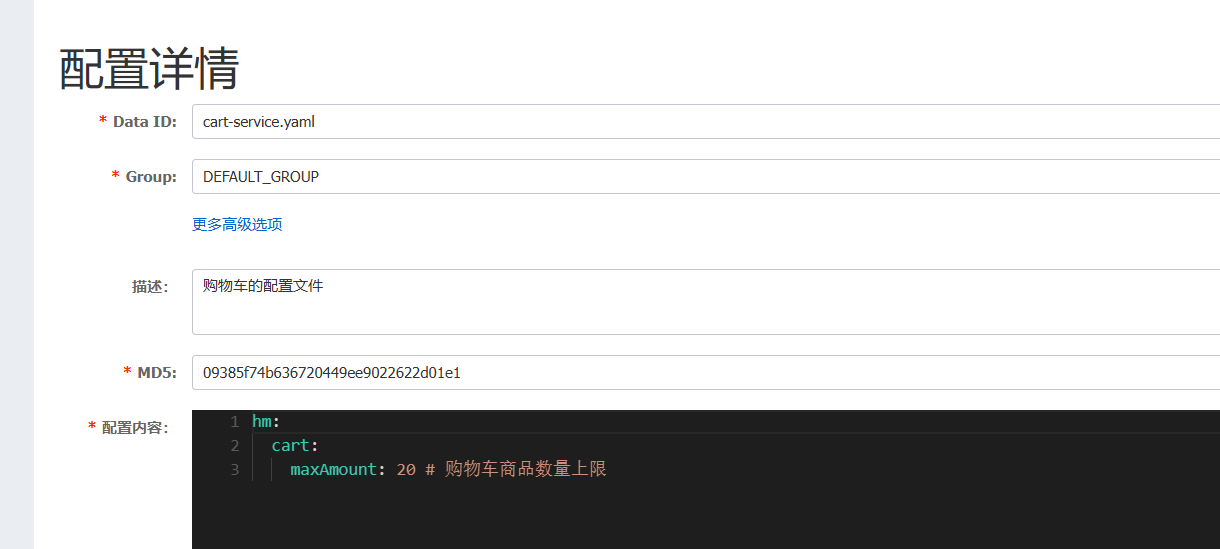
hm:
cart:
maxAmount: 20 # 购物车商品数量上限
然后可以实地测试。体验热更新的魅力。无需重启,立刻生效
动态路由
该路由时,不用重启项目。直接生效。
但是,nacos只负责保存配置并推送配置。后续动作,如监听配置和更新路由配置信息等操作需要自己实现
因此,我们需要完成两件事情:
- 监听Nacos配置变更的消息
- 当配置变更时,将最新的路由信息更新到网关路由表
具体如何实现。我们可以参考官方文档Java SDK
Data Id和 Group就能确定一个配置文件。一般我们还会加上超时时间。
对于我们这里要做的,要用到的就是监听配置的功能。可以参照具体示例。
String serverAddr = "{serverAddr}";
String dataId = "{dataId}";
String group = "{group}";
Properties properties = new Properties(); //properties就可以理解为一个map,是key——value结构
properties.put("serverAddr", serverAddr);
ConfigService configService = NacosFactory.createConfigService(properties); //利用服务器地址跟nacos建立来连接。
String content = configService.getConfig(dataId, group, 5000); //先读取配置,在添加监听器
System.out.println(content);
configService.addListener(dataId, group, new Listener() {
//处理变更逻辑
@Override
public void receiveConfigInfo(String configInfo) {
System.out.println("recieve1:" + configInfo);
}
@Override
public Executor getExecutor() { //返回一个Executor线程池,将来回调函数的执行,可以由线程池执行,可以异步执行
return null;
}
});
// 测试让主线程不退出,因为订阅配置是守护线程,主线程退出守护线程就会退出。 正式代码中无需下面代码
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
比上面简单的是,我们可以直接拿到configService。因为从jar包中的源码可以看出已经注入了【NacosConfigAutoConfiguration类中往下找】。
还提供了获取配置和添加监听器的方法。
示例如下:【在网关中写】
-
引入依赖
<!--nacos配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> -
创建对应的bootstrap.yaml文件。
spring: application: name: gateway # 微服务名称 profiles: active: dev #环境 cloud: nacos: server-addr: 192.168.40.136:8848 # nacos地址 config: file-extension: yaml #文件后缀名 shared-configs: #共享配置 - dataId: shared-log.yaml # 共享日志配置 -
application.yaml中的信息就可以简化掉了。我们用nacos的路由
server: port: 8080 hm: jwt: location: classpath:hmall.jks alias: hmall password: hmall123 #解析密钥文件的密码 tokenTTL: 30m auth: excludePaths: #相当于白名单 - /search/** - /users/login - /items/** - /hi -
最后写一下我们的动态配置加载器
package com.hmall.gateway.routers; import cn.hutool.json.JSONUtil; import com.alibaba.cloud.nacos.NacosConfigManager; import com.alibaba.nacos.api.config.listener.Listener; import com.alibaba.nacos.api.exception.NacosException; import lombok.RequiredArgsConstructor; import lombok.extern.slf4j.Slf4j; import org.springframework.cloud.gateway.route.RouteDefinition; import org.springframework.cloud.gateway.route.RouteDefinitionWriter; import org.springframework.stereotype.Component; import reactor.core.publisher.Mono; import javax.annotation.PostConstruct; import java.util.HashSet; import java.util.List; import java.util.Set; import java.util.concurrent.Executor; @Slf4j @Component @RequiredArgsConstructor public class DynamicRouteLoader { private final NacosConfigManager nacosConfigManager; private final RouteDefinitionWriter writer; private final String dataId = "gateway-routers.json"; private final String group = "DEFAULT_GROUP"; private final Set<String> routeIds = new HashSet<>(); //保存配置id @PostConstruct public void initRouteConfigListener() throws NacosException { //1.项目启动时,先拉取一次配置,并且添加配置监听器 String configInfo = nacosConfigManager.getConfigService() .getConfigAndSignListener(dataId, group, 5000, new Listener() { @Override public Executor getExecutor() { return null; } @Override public void receiveConfigInfo(String configInfo) { //2.监听配置变更,需要去变更路由表 updateConfigInfo(configInfo); } }); //3.第一次读取配置,也需要更新到路由表 updateConfigInfo(configInfo); } public void updateConfigInfo(String configInfo) { //1.解析配置信息,转为RouteDefinition List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class); //2.删除旧的路由表 for (String routeId : routeIds) { writer.delete(Mono.just(routeId)).subscribe(); } routeIds.clear(); //3.更新路由表 for (RouteDefinition routeDefinition : routeDefinitions) { //3.1 更新路由表 writer.save(Mono.just(routeDefinition)).subscribe(); //3.2 记录路由id,便于下一次更新是删除 routeIds.add(routeDefinition.getId()); } } }其中,我们监听到路由信息后,可以利用RouteDefinitionWriter【也是一个注入好的api,很方便】来更新路由表。其中有两个方法。
-
save:更新路由到路由表,如果路由id重复,则会覆盖旧的路由
-
delete:根据路由id删除某个路由
我们巧妙利用了这两个方法实现来我们的配置更新。
-
-
为了方便解析从Nacos读取到的路由配置,推荐使用json格式的路由配置【因为JSON格式更好解析,所以我们上面也是按JSON格式写的解析代码】,我们在nacos中新建配置,和我们的代码对应上名字就叫
gateway-routers.json,格式为JSON,内容如下:[ { "id": "item", "predicates": [{ "name": "Path", "args": {"_genkey_0":"/items/**", "_genkey_1":"/search/**"} }], "filters": [], "uri": "lb://item-service" }, { "id": "cart", "predicates": [{ "name": "Path", "args": {"_genkey_0":"/carts/**"} }], "filters": [], "uri": "lb://cart-service" }, { "id": "user", "predicates": [{ "name": "Path", "args": {"_genkey_0":"/users/**", "_genkey_1":"/addresses/**"} }], "filters": [], "uri": "lb://user-service" }, { "id": "trade", "predicates": [{ "name": "Path", "args": {"_genkey_0":"/orders/**"} }], "filters": [], "uri": "lb://trade-service" }, { "id": "pay", "predicates": [{ "name": "Path", "args": {"_genkey_0":"/pay-orders/**"} }], "filters": [], "uri": "lb://pay-service" } ]
发布以后就生效了。可以对比一些发布前后的不同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号