
Storm-wordcount实时统计单词次数
一、本地模式
1、WordCountSpout类
package com.demo.wc; import java.util.Map; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; /** * 需求:单词计数 hello world hello Beijing China * * 实现接口: IRichSpout IRichBolt * 继承抽象类:BaseRichSpout BaseRichBolt 常用*/ public class WordCountSpout extends BaseRichSpout { //定义收集器 private SpoutOutputCollector collector; //发送数据 @Override public void nextTuple() { //1.发送数据 到bolt collector.emit(new Values("I like China very much")); //2.设置延迟 try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } } //创建收集器 @Override public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) { this.collector = collector; } //声明描述 @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { //起别名 declarer.declare(new Fields("wordcount")); } }
2、WordCountSplitBolt类
package com.demo.wc; import java.util.Map; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; public class WordCountSplitBolt extends BaseRichBolt { //数据继续发送到下一个bolt private OutputCollector collector; //业务逻辑 @Override public void execute(Tuple in) { //1.获取数据 String line = in.getStringByField("wordcount"); //2.切分数据 String[] fields = line.split(" "); //3.<单词,1> 发送出去 下一个bolt(累加求和) for (String w : fields) { collector.emit(new Values(w, 1)); } } //初始化 @Override public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) { this.collector = collector; } //声明描述 @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word", "sum")); } }
3、WordCountBolt类
package com.demo.wc; import java.util.HashMap; import java.util.Map; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Tuple; public class WordCountBolt extends BaseRichBolt{ private Map<String, Integer> map = new HashMap<>(); //累加求和 @Override public void execute(Tuple in) { //1.获取数据 String word = in.getStringByField("word"); Integer sum = in.getIntegerByField("sum"); //2.业务处理 if (map.containsKey(word)) { //之前出现几次 Integer count = map.get(word); //已有的 map.put(word, count + sum); } else { map.put(word, sum); } //3.打印控制台 System.out.println(Thread.currentThread().getName() + "\t 单词为:" + word + "\t 当前已出现次数为:" + map.get(word)); } @Override public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) { } @Override public void declareOutputFields(OutputFieldsDeclarer arg0) { } }
4、WordCountDriver类
package com.demo.wc; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; public class WordCountDriver { public static void main(String[] args) { //1.hadoop->Job storm->topology 创建拓扑 TopologyBuilder builder = new TopologyBuilder(); //2.指定设置 builder.setSpout("WordCountSpout", new WordCountSpout(), 1); builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(), 4).fieldsGrouping("WordCountSpout", new Fields("wordcount")); builder.setBolt("WordCountBolt", new WordCountBolt(), 2).fieldsGrouping("WordCountSplitBolt", new Fields("word")); //3.创建配置信息 Config conf = new Config(); //4.提交任务 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("wordcounttopology", conf, builder.createTopology()); } }
5、直接运行(4)里面的main方法即可启动本地模式。
二、集群模式
前三个类和上面本地模式一样,第4个类WordCountDriver和本地模式有点区别
package com.demo.wc; import org.apache.storm.Config; import org.apache.storm.StormSubmitter; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; public class WordCountDriver { public static void main(String[] args) { //1.hadoop->Job storm->topology 创建拓扑 TopologyBuilder builder = new TopologyBuilder(); //2.指定设置 builder.setSpout("WordCountSpout", new WordCountSpout(), 1); builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(), 4).fieldsGrouping("WordCountSpout", new Fields("wordcount")); builder.setBolt("WordCountBolt", new WordCountBolt(), 2).fieldsGrouping("WordCountSplitBolt", new Fields("word")); //3.创建配置信息 Config conf = new Config(); //conf.setNumWorkers(10); //集群模式 try { StormSubmitter.submitTopology(args[0], conf, builder.createTopology()); } catch (Exception e) { e.printStackTrace(); } //4.提交任务 //LocalCluster localCluster = new LocalCluster(); //localCluster.submitTopology("wordcounttopology", conf, builder.createTopology()); } }
把程序打成jar包放在启动了Storm集群的机器里,在stormwordcount.jar所在目录下执行
storm jar stormwordcount.jar com.demo.wc.WordCountDriver wordcount01
即可启动程序。
三、并发度和分组策略
1、WordCountDriver_Shuffle类
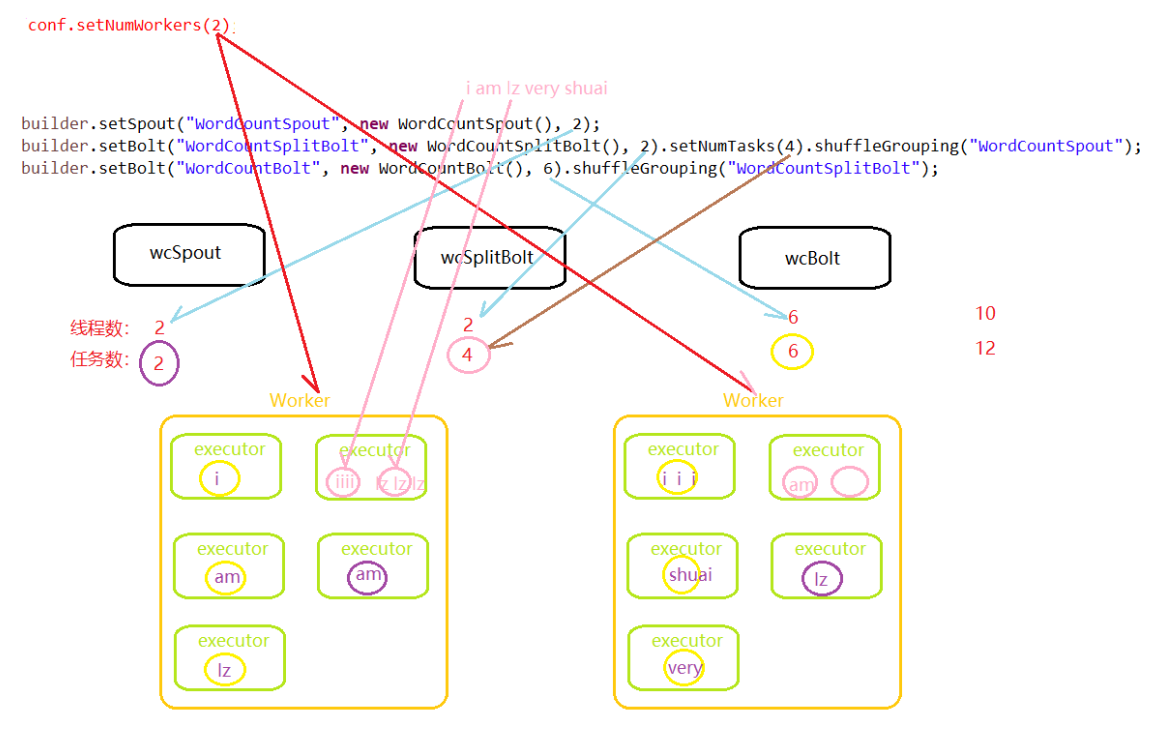
package com.demo.wc; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.topology.TopologyBuilder; public class WordCountDriver_Shuffle { public static void main(String[] args) { //1.hadoop->Job storm->topology 创建拓扑 TopologyBuilder builder = new TopologyBuilder(); //2.指定设置 builder.setSpout("WordCountSpout", new WordCountSpout(), 2); builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(), 2).setNumTasks(4).shuffleGrouping("WordCountSpout"); builder.setBolt("WordCountBolt", new WordCountBolt(), 6).shuffleGrouping("WordCountSplitBolt"); //3.创建配置信息 Config conf = new Config(); //conf.setNumWorkers(2); //集群模式 // try { // StormSubmitter.submitTopology(args[0], conf, builder.createTopology()); // } catch (Exception e) { // e.printStackTrace(); // } //4.提交任务 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("wordcounttopology", conf, builder.createTopology()); } }
2、并发度与分组策略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号