
性能瓶颈分析及调优
分析流程:
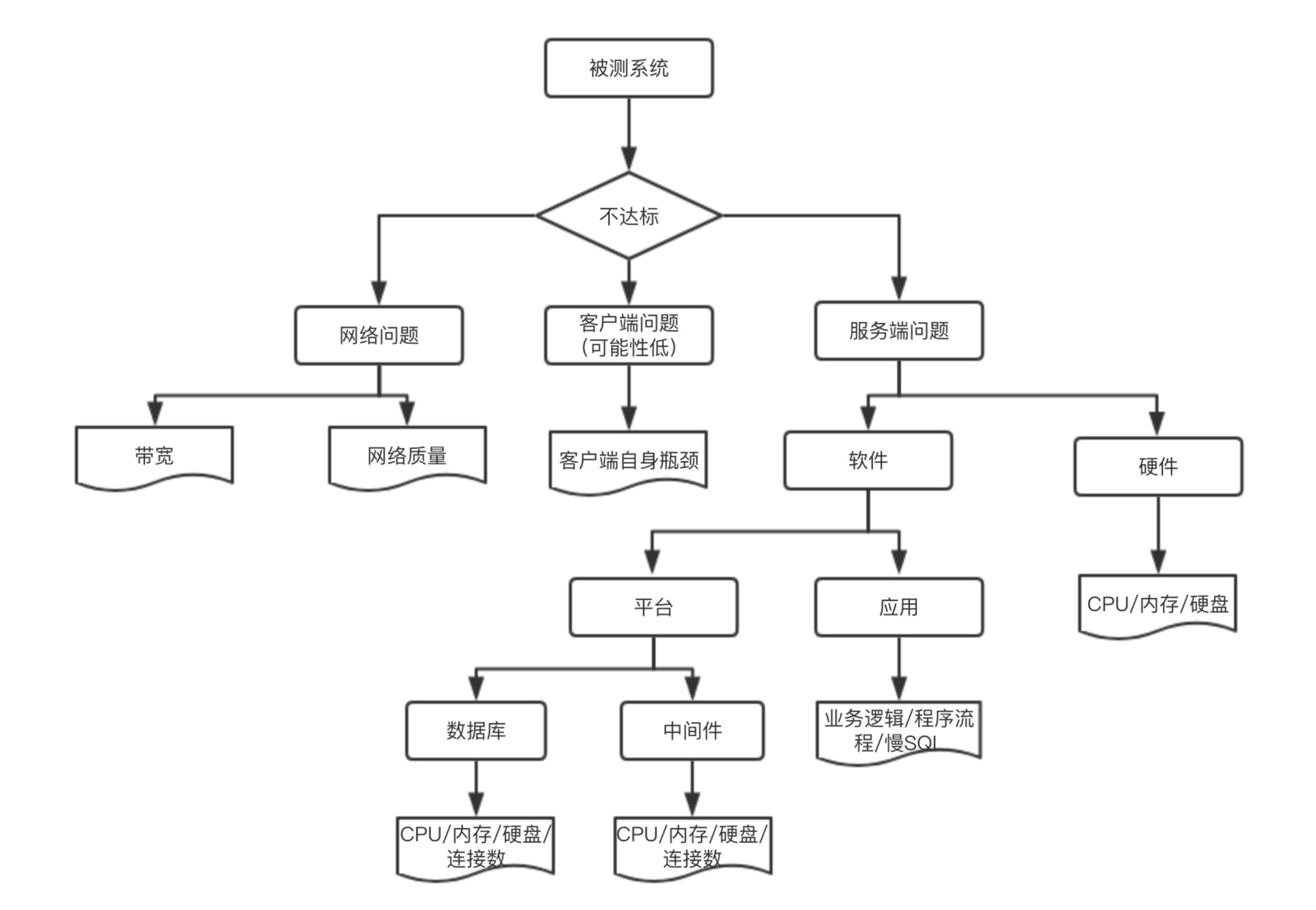
很多情况下压测流量并没有完全进入到后端(服务端),在网络接入层(云化的架构比如:SLB/WAF/高防IP,甚至是CDN/全站加速等)可能就会出现由于各种规格(带宽、最大连接数、新建连接数等)限制或者因为压测的某些特征符合CC和DDoS的行为而触发了防护策略导致压测结果达不到预期。
分析关键指标是否满足要求,如果不满足,需要确定是哪个地方有问题,一般情况下,服务器端问题可能性比较大,也有可能是客户端问题(这种情况非常小)。
对于服务器端问题,需要定位的是硬件相关指标,例如CPU,Memory, Disk I/O, Network I/O, 如果是某个硬件指标有问题,需要深入的进行分析。
如果硬件指标都没有问题,需要查看中间件相关指标,例如:线程池、连接池、GC等,如果是这些指标问题,需要深入的 分析。
如果中间件相关指标没问题,需要查看数据库相关指标,例如:慢查SQL,命中率,锁、参数设置。
如果以上指标都正常,应用程序的算法、缓冲、缓存、同步或异步可能有问题,需要具体深入的分析。

可能存在的瓶颈点及优化思路
硬件瓶颈:
一般指的是CPU、内存、磁盘I/O 方面的问题,分为服务器硬件瓶颈、网络瓶颈
中间件性能瓶颈:
web软件,数据库,缓存等
应用程序瓶颈:
JVM参数不合理,容器配置不合理,慢SQL,慢事务,数据库设计不合理,程序架构规划不合理,程序本身设计有问题(串行处理、请求的处理线程不够、无缓冲、无缓存、生产者和消费者不协调等),造成系统在大量用户方位时性能低下而造成的瓶颈。
操作系统瓶颈:
连接数,虚拟内存,内核参数等
网络设备瓶颈:
包括但不限于SLB/WAF/高防IP/CDN/全站加速等
瓶颈应对手段
CPU:
如果CPU User非常高,需要查看消耗在哪个进程,可以用top(linux)命令看出,接着用top –H –p
如果CPU Sys非常高,可以用strace(linux)看系统调用的资源消耗及时间;
如果CPU Wait非常高,考虑磁盘读写,可以通过减少日志输出、异步或换速度快的硬盘。
内存:
内存的问题主要看某个进程占用的内存是否非常大以及是否有大量的swap(虚拟内存交换)。
磁盘IO:
磁盘I/O一个最显著的指标是繁忙率,可以通过减少日志输出、异步或换速度快的硬盘。
网络IO:
网络I/O主要考虑传输内容大小,不能超过硬件网络传输的最大值70%,可以通过压缩、减少内容大小、在本地设置缓存以及分多次传输等。
内核参数:
注意运行参数不要超过内核参数而导致系统出现问题
JVM:
jvm主要分析GC/FULL GC是否频繁,以及垃圾回收的时间,可以用jstat命令来查看,对于每个代大小以及GC频繁,通过jmap将内存dump,再借助工具HeapAnalyzer来分析哪地方占用的内存较高以及是否有内存泄漏可能。
线程池:
如果线程不够用,可以通过参数调整,增加线程;对于线程池中的线程设置比较大的情况,还是不够用可能的原因是:某个线程被阻塞来不及释放,可能在等锁、方法耗时较长、数据库等待时间很长等原因导致,需要进一步分析才能定位。
JDBC连接池:
连接池不够用的情况下,可以通过参数进行调整增加;但是对于数据库本身处理很慢的情况下,调整没有多大的效果,需要查看数据库方面以及因代码导致连接未释放的原因。
SQL:
慢SQL,可以通过查看执行计划看SQL慢在哪里来进一步优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号