一,安装第三方库
$ pip install sentence_transformers
二,创建collection并添加数据
from app import milvus_client
from pymilvus import FieldSchema, DataType, CollectionSchema, Collection, connections
from helpers.utils import success_response
from sentence_transformers import SentenceTransformer
import ast
vector = Blueprint('vector', __name__)
transformer = SentenceTransformer('/data/python/flask/study/all-MiniLM-L6-v2')
@vector.route("/collection/", methods=['GET'])
def collection_list():
milvus_client.using_database("default")
#dim = 1024
dim = 384
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=2048),
# 文本、图片、音频、视频
FieldSchema(name="content_vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
# 可售商品
FieldSchema(name="product_ids", dtype=DataType.ARRAY, max_length=100, element_type=DataType.VARCHAR,
max_capacity=2048),
]
schema = CollectionSchema(fields=fields, description='wkbase data collection')
# 清理并创建 Collection
if milvus_client.has_collection("article"):
milvus_client.drop_collection("article")
# 创建集合
milvus_client.create_collection(collection_name="article", schema=schema)
# 创建索引
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name='content_vector',
metric_type='COSINE',
index_type='IVF_FLAT',
index_name='content_vector_index'
)
milvus_client.create_index(
collection_name="article",
index_params=index_params
)
# 加载集合到内存
# 加载集合到内存
milvus_client.load_collection("article")
print("已成功创建启用 AutoID 的 Collection")
#添加数据:
onec = "我喜欢看某律师直播.他曾经说过一段话.第一次去见涉案当事人的时候.他说的每一句话我都不信."
onecv = embed_content(onec)
one = {
"content":onec,
"content_vector":onecv,
"product_ids":["1","2","3"],
}
# insert to vector db
result = milvus_client.insert(
collection_name="article",
data=one
)
twoc = "强奸犯还在逍遥法外,警察却在阻拦受害者!印度一轮奸受害者冲破警察层层阻碍,来到副警监车前讨公道。"
twocv = embed_content(twoc)
two = {
"content": twoc,
"content_vector":twocv,
"product_ids":["4","5","6"],
}
# insert to vector db
result = milvus_client.insert(
collection_name="article",
data=two
)
threec = "石家庄太和电子城又玩套路?高配变低配?7000多买了一款过时的笔记本电脑,这么多年太和的传统套路一点没变啊!"
threecv = embed_content(threec)
three = {
"content": threec,
"content_vector":threecv,
"product_ids":["7", "8", "9"],
}
# insert to vector db
result = milvus_client.insert(
collection_name="article",
data=three
)
milvus_client.flush(collection_name="article")
return success_response({})
def embed_content(data):
embeddings = transformer.encode(data)
return embeddings
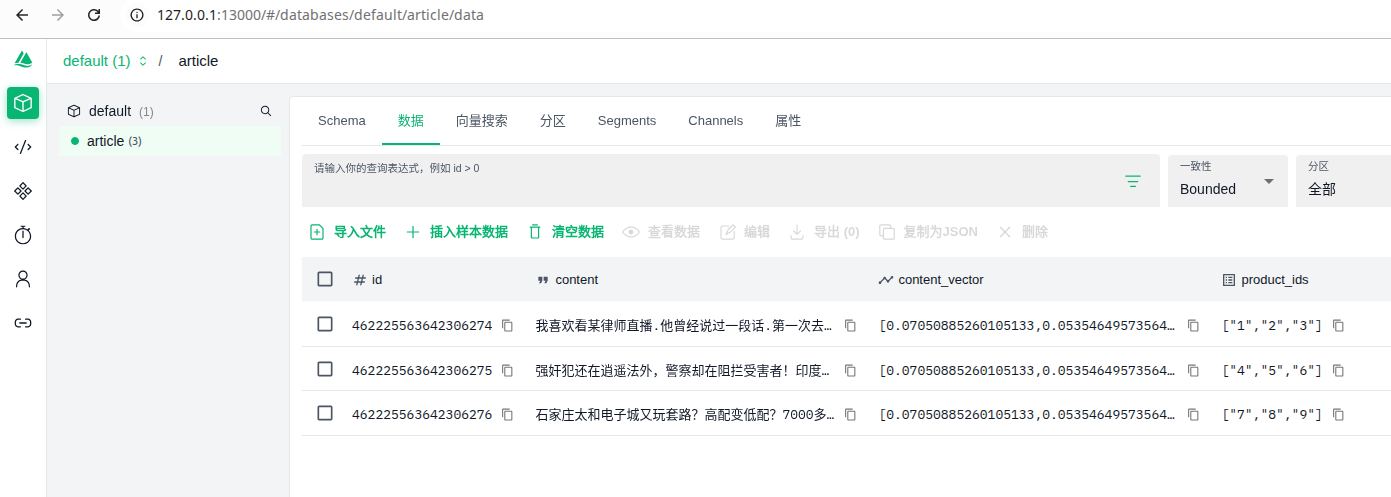
三,测试 效果
![image]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号