FTRL(Follow The Regularized Leader)学习总结
摘要:
1.算法概述
2.算法要点与推导
3.算法特性及优缺点
4.注意事项
5.实现和具体例子
6.适用场合
内容:
1.算法概述
FTRL是一种适用于处理超大规模数据的,含大量稀疏特征的在线学习的常见优化算法,方便实用,而且效果很好,常用于更新在线的CTR预估模型;
FTRL算法兼顾了FOBOS和RDA两种算法的优势,既能同FOBOS保证比较高的精度,又能在损失一定精度的情况下产生更好的稀疏性。
FTRL在处理带非光滑正则项(如L1正则)的凸优化问题上表现非常出色,不仅可以通过L1正则控制模型的稀疏度,而且收敛速度快;
参考:[笔记]FTRL与Online Optimization
2.算法要点与推导

3.算法特性及优缺点
FTRL-Proximal工程实现上的tricks:
1.saving memory
方案1)Poisson Inclusion:对某一维度特征所来的训练样本,以p的概率接受并更新模型。
方案2)Bloom Filter Inclusion:用bloom filter从概率上做某一特征出现k次才更新。
2.浮点数重新编码
1)特征权重不需要用32bit或64bit的浮点数存储,存储浪费空间
2)16bit encoding,但是要注意处理rounding技术对regret带来的影响(注:python可以尝试用numpy.float16格式)
3.训练若干相似model
1)对同一份训练数据序列,同时训练多个相似的model
2)这些model有各自独享的一些feature,也有一些共享的feature
3)出发点:有的特征维度可以是各个模型独享的,而有的各个模型共享的特征,可以用同样的数据训练。
4.Single Value Structure
1)多个model公用一个feature存储(例如放到cbase或redis中),各个model都更新这个共有的feature结构
2)对于某一个model,对于他所训练的特征向量的某一维,直接计算一个迭代结果并与旧值做一个平均
5.使用正负样本的数目来计算梯度的和(所有的model具有同样的N和P)
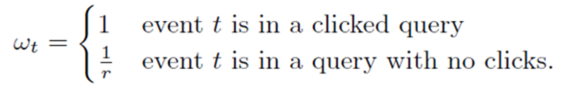
6.subsampling Training Data
1)在实际中,CTR远小于50%,所以正样本更加有价值。通过对训练数据集进行subsampling,可以大大减小训练数据集的大小
2)正样本全部采(至少有一个广告被点击的query数据),负样本使用一个比例r采样(完全没有广告被点击的query数据)。但是直接在这种采样上进行训练,会导致比较大的biased prediction
3)解决办法:训练的时候,对样本再乘一个权重。权重直接乘到loss上面,从而梯度也会乘以这个权重。
算法特点:
在线学习,实时性高;可以处理大规模稀疏数据;有大规模模型参数训练能力;根据不同的特征特征学习率
缺点:
4.注意事项
5.实现和具体例子
FTRL处理“Springleaf Marketing Response”数据
6.适用场合
点击率模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号