卷积神经网络学习总结
摘要:
1.算法概述
2.算法要点与推导
3.算法特性及优缺点
4.注意事项
5.实现和具体例子
6.适用场合
内容:
1.算法概述:
卷积神经网络(Convolutional Neural Network,CNN)最开始是为了解决图像识别问题被设计而来的,CNN使用图像的原始像素作为输入,训练时可以自动提取图像特征;卷积神经网络的三个基本要点是:局部连接,权值共享和降采样。其中局部连接和权值共享降低了参数量,减少了模型复杂度;而降采样则进一步降低了输出参数量,并赋予模型对轻度畸变的容忍性,提高了模型的泛化能力。
1.1局部连接(感受野):
每一次卷积操作,输入神经元只有一小片区域会被连接到下一层的一个神经元,这个区域被称为局部感受野;如果局部感受野是5x5的,一次移动一格(stride),输入图像是28x28的,那么隐层有24x24(28-5+1)个神经元。
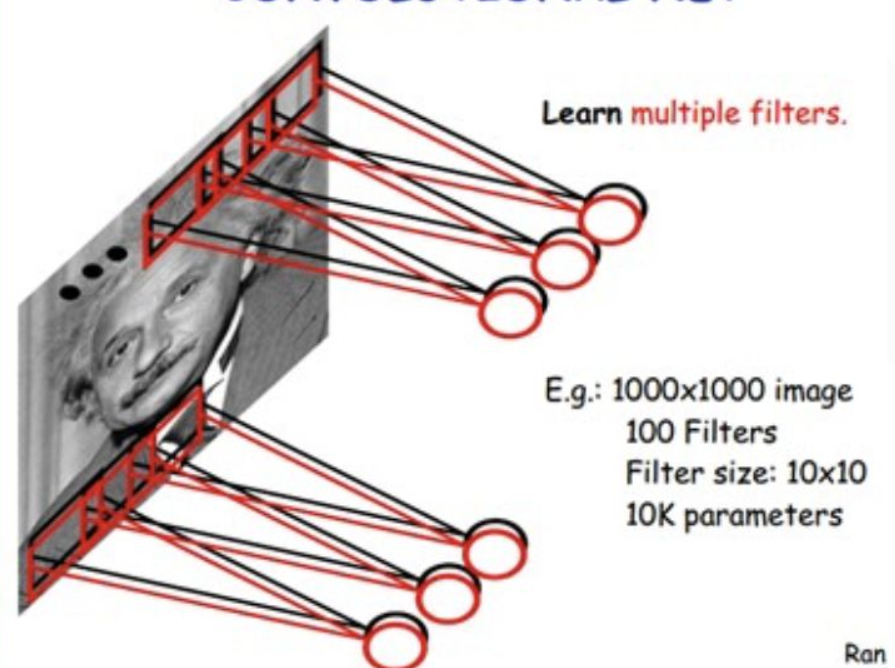
1.2权值共享:
卷积网络中某一个层的所有神经元使用相同的权重和偏置。也就是说,对于隐藏层的第j行第k列的神经元,它的输出为:
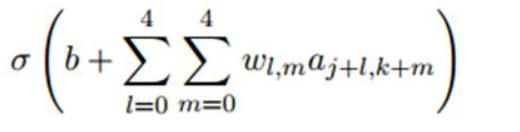
其中σ是激活函数,b是共享偏置,Wl,m是共享权重的5x5数组,用ax,y表示输入层的第x行第y列的神经元的输出值,即隐层的第j行第k列的神经元的若干个输入。
共享,意味着这一个隐层的所有神经元检测完全相同的特征,在输入图像的不同位置。这说明卷积网络可以很好地适应图片的平移不变性。
图像分类中我们会卷积多次(卷积核不同),也称为特征映射,下图卷积了3次,识别了3种特征: 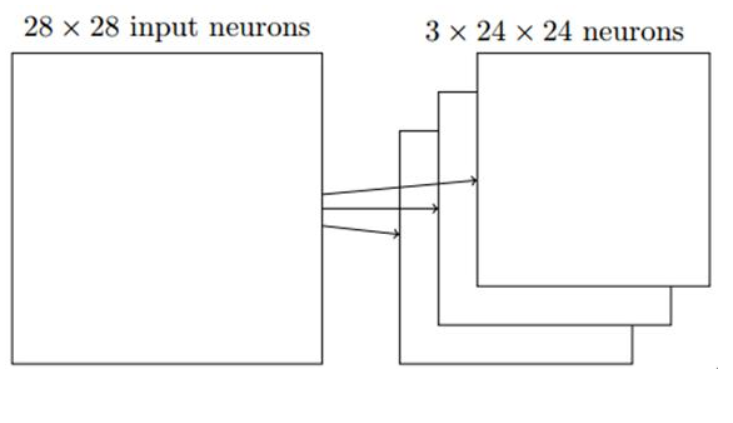
一次卷积我们需要5x5=25个共享权重,加上一个共享偏置共26个参数。如果我们卷积了20次,那么共有20x26=520个参数。与全连接对比,输入神经元有28x28=784个,隐层神经元设为30个,共有784x30个权重,加上30个偏置,共有23550个参数。
1.3降采样:池化层一般在卷积层之后使用,池化层的每个单元概括了前一层的一个小区域,常见的方法有mean-pooling,max-pooling和stochastic pooling。
2.算法要点与推导
2.1前向推断过程:
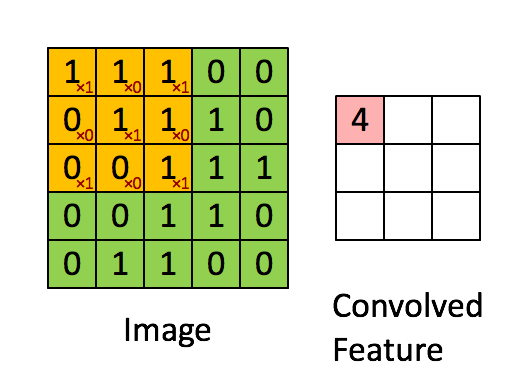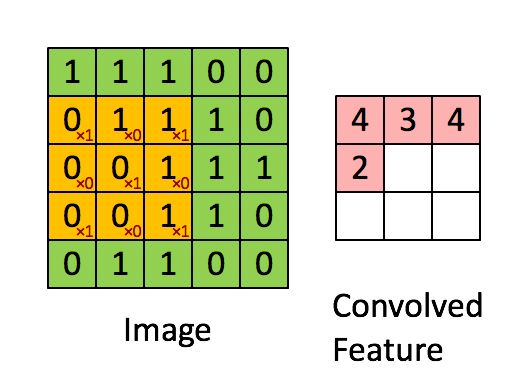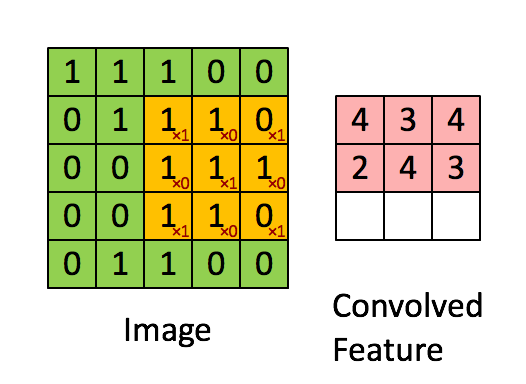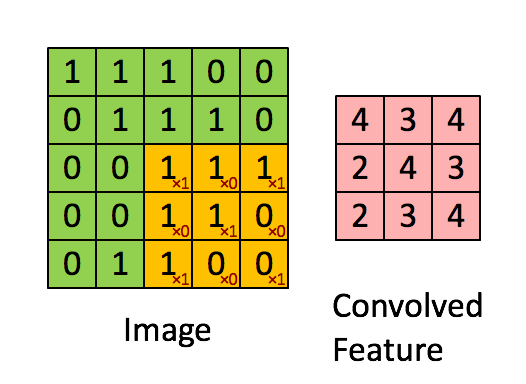
第一步:卷积操作:
其中卷积核为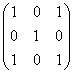 ,
,
2.2激活函数ReLU
2.3池化操作:
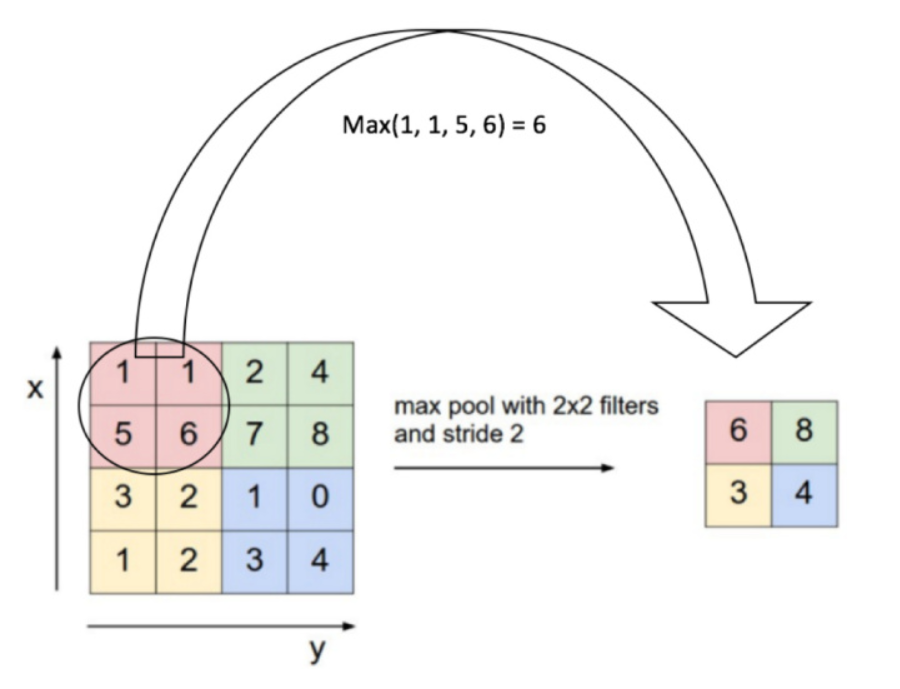
2.1后向求导过程:
http://note.youdao.com/noteshare?id=1babdc0a6670d94a3b90f7e65949874d
参考:Deep Learning模型之:CNN卷积神经网络推导和实现 ;CNN卷积神经网络和反向传播
3.算法特性及优缺点
局部连接,权值共享和降采样。其中局部连接和权值共享降低了参数量,减少了模型复杂度;而降采样则进一步降低了输出参数量,并赋予模型对轻度畸变的容忍性,提高了模型的泛化能力。
优点:具有空间不变性,自动提取特征;
缺点:相比传统模型,卷积复杂度高。训练时间长,只能提取局部特征,不能提取全局特征;
4.注意事项:
5.实现和具体例子
《Tensorflow实战》实现简单CNN处理mnist数据
《TensorFlow实战》实现增加了L2正则化与LRN层的CNN处理CIFAR-10数据
《TensorFlow实战》实现InceptionNet V3网络
Implementing a CNN for Text Classification in TensorFlow
Character-level Convolutional Networks for Text Classification

 浙公网安备 33010602011771号
浙公网安备 33010602011771号