

激活函数---->反向传播----》更新参数----》初始化
神经元包含了非线性计算,用g()来表示,非线性计算由激活函数来实现,激活函数统一表示成g(z),常见的激活函数:
1、sigmoid函数
如果神经元采用sigmoid函数作为激活函数,那么单个神经元实现的功能就相当于逻辑回归。
2、tanh函数
tanh函数是双曲正切函数
3、relu 函数
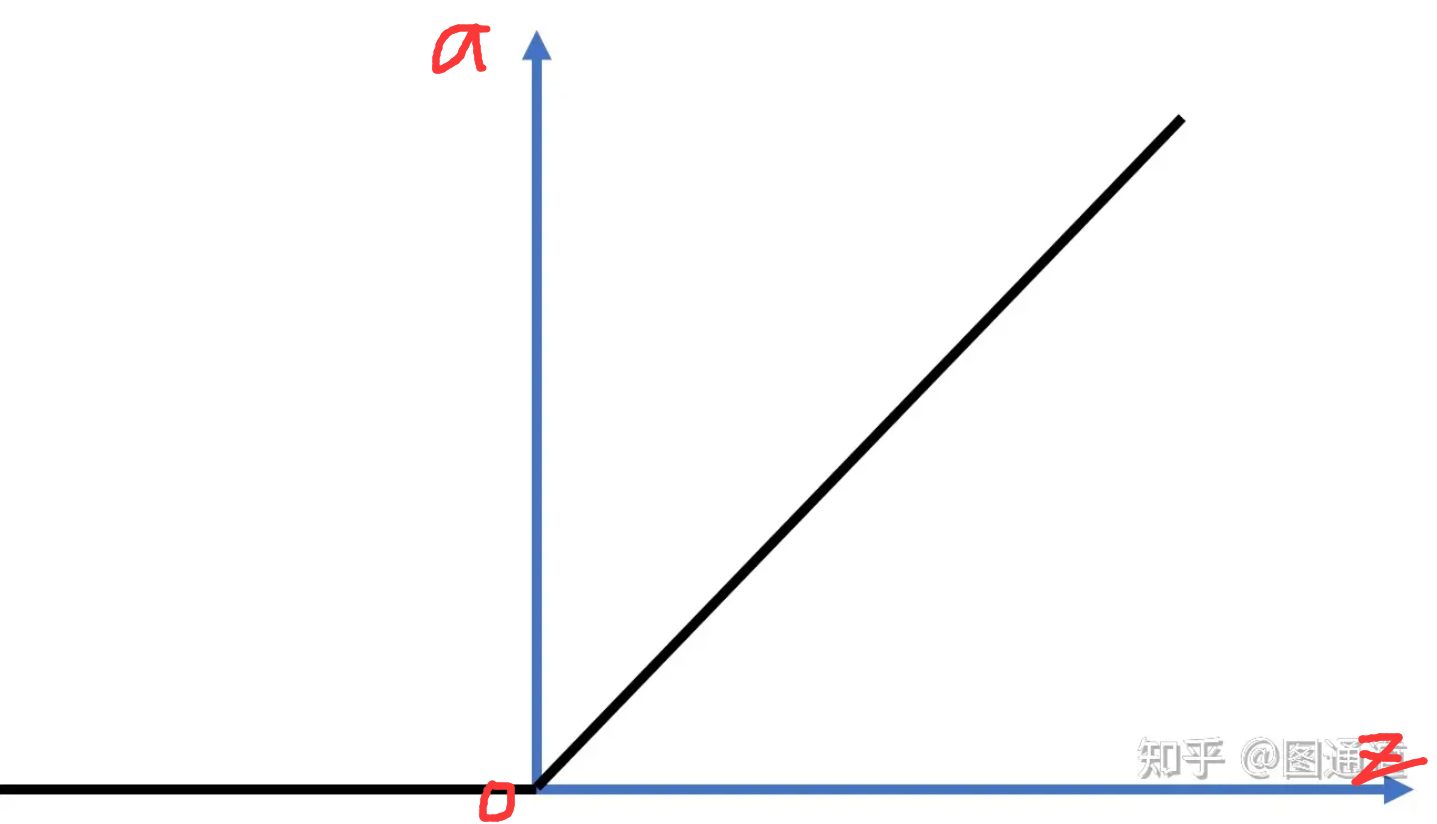 是一种流行的激活函数,它是分段函数,当z>0时,a=z;当z<=0时,a=0;
是一种流行的激活函数,它是分段函数,当z>0时,a=z;当z<=0时,a=0;
relu函数的最大特点就是在z>0时梯度恒为1,保证了网络训练时梯度下降的速度。但是它的缺点是在z<=0时;梯度为0;此时神经元不工作。实际应用中证明这种情况影响不大
4、leaky relu 函数
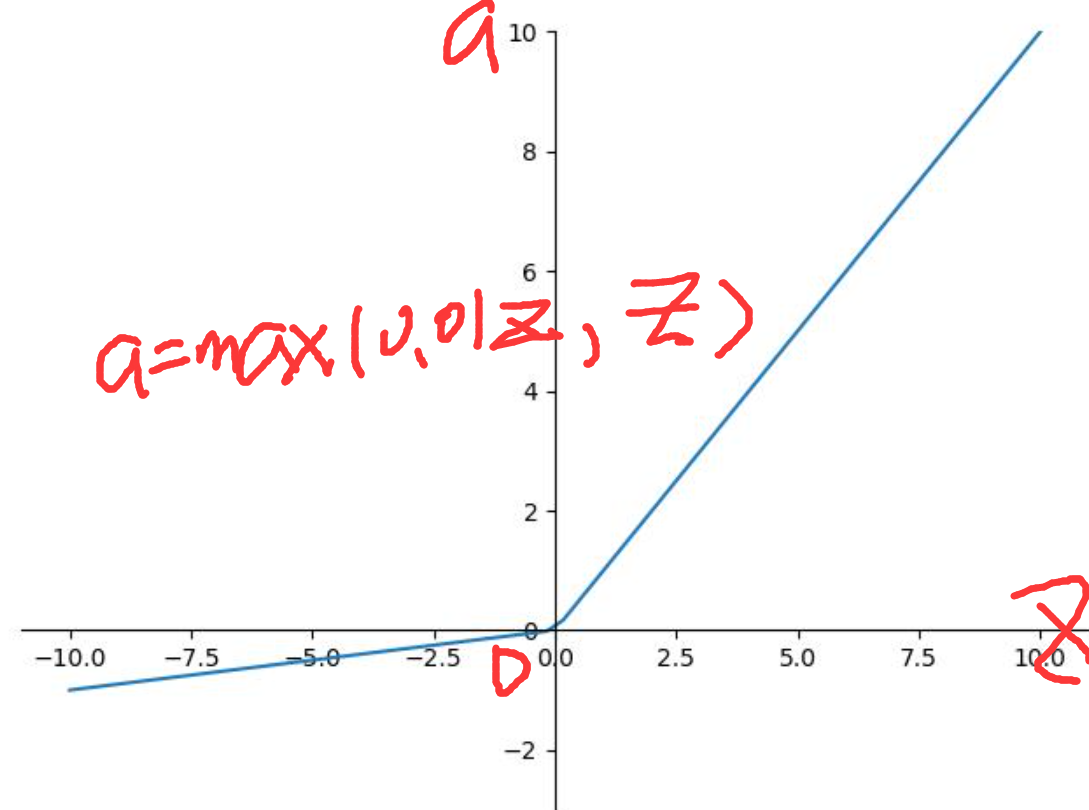 是relu函数的改进,区别仅在于当z<=0时,a不恒为0,而是有一个小梯度,此处为0.01,可以更改,这样做的好处是始终保持梯度不为0;
是relu函数的改进,区别仅在于当z<=0时,a不恒为0,而是有一个小梯度,此处为0.01,可以更改,这样做的好处是始终保持梯度不为0;
5、如何选择合适的激活函数???
首先对于 sigmoid 和 tanh 函数:
对于隐藏层一般是tanh更好一些,因为tanh取值范围在【-1,1】,隐藏层的输出被限定在【-1,1】,可以看成是在0值附近分布,均值为0;这样从隐藏层到输出层,数据达到了归一化(均值为0)的效果。
对于输出层的激活函数,因为二分类问题的输出取值为{0,1},所以一般会选择sigmoid函数。
但是,两个函数有个缺点:在|z|很大时,激活函数的斜率很小,梯度下降算法会运行得很慢。
为了弥补这个缺点出现了relu 激活函数,在隐藏层,选择relu函数作为激活函数能够保证z>0时梯度总为1,从而提高梯度下降算法运算速度;
leaky relu 是为了弥补当z<0时,relu函数梯度为0的缺点
!!!:如果是预测问题而不是分类问题,在输出是连续值的情况下,输出层的激活函数可以使用线性函数,如果输出值恒为正值,也可以使用relu激活函数
6、非线性激活函数
7、反向传播
神经网络经过前向传播之后,就可以计算损失函数。神经网络二分类与逻辑回归一样采用交叉熵损失
计算完交叉熵损失之后就可以进行反向传播。反向传播是对神经网络输出层,隐藏层的参数W和b计算偏导数的过程。
8、更新参数
神经网络完成反向传播之后,得到各层的参数梯度dW,db。然后根据梯度下降算法对参数W和b进行更新;
~~~~~~~~至此,经过前向传播,反向传播,更新参数之后,神经网络的一次训练就算完成了。经过N次迭代训练,参数W,b会不断更新,并接近全局最优解。
9、初始化
主要是针对神经网络中 W,b 的初始化,在逻辑回归中,W,b一般全部初始化为0即可,但是神经网络中不行。W 一般不会初始化为0,可以进行随机初始化;但是,偏置项b一般可以初始化为0;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号