WC 2024 游记
WC2024 游记。
可能是一个听课内容总结与游记的结合体,但是实际上听课内容我也没听懂啥所以基本也不会总结啥东西。
不得不说一个七天的活动的游记还是很难写的,还是得每天写每天的,不要攒到某一天一起写。
不过听课记录并不会记录很多东西,因为大部分课我只听了极小一部分,剩下的要不然我睡觉了要不然没听懂。
Day 0
这里可以承接 THUWC 2024 游记,因为这里是那篇游记的结尾。
额在宾馆颓废了一天,下午打蔚蓝把草莓酱中级大厅的关全打完了,然后开了心门。
好像没啥可写的。
Day 1
报道,好像也没什么可说的。
放张 HE 照片吧。

少一些人,因为有两个人是晚上才来的。
然后感受了一下重庆育才中学的风景,食堂感觉也不错。
我没拍啥照,所以放一个 WC 2024 相册,想看的可以看看。
但是宿舍没有插座。没有插座。没有插座。一层只有一个集中充电点。有点极端了。
得知下午五点之后就不能出校了,于是我们宿舍三个人(有一个没到)决定出去买点东西。我买了个充电宝和一瓶冰红茶。
事实证明买充电宝是很正确的,要不然接下来一周还是会很痛苦的。
下午开幕式,感觉好像属实有点无聊了,有极大量领导念信息熵极低的文本,然后舞蹈和 THUWC 的开幕式舞蹈一模一样,歌唱仍然有点假唱,有点无语。
然后睡觉了。
Day 2
突然想起来当时 yspm 评论我的做题纪要说:“这做题纪要里面不是只有每天前面的日记有意义吗,后面题解太多我都没法看日记了”
所以把听课记录折叠起来了。
信息学竞赛中的持久化数据结构与技巧 - 李欣隆
青蛙。
持久化的分类
- 部分持久化:可以访问历史版本,但是只能在最后一个版本的基础上进行修改。适用于时间复杂度依赖于均摊的做法。称每个版本的数据结构形成的序列为版本序列。
lxl 举例子:假如我们维护一个数列
1 2 3,我们进行一次修改得到1 1 3,再进行一次操作得到1 1 4,再进行一次操作得到5 1 4 - 完全持久化:可以访问历史版本,且可以在任意一个历史版本的基础上进行修改。所有历史版本可以看作是一棵树,称这棵树为版本树。注意完全持久化不能支持需要均摊的操作,因为这样会导致复杂度最坏情况下退化到 \(O(n^2)\)。
- 可合并的持久化:有些数据结构支持合并,可以把版本看作一个 DAG,每个节点由前驱合并得到,把这个图称做版本图。
首先离线可以直接处理掉持久化问题,对于部分持久化来说,直接把询问按照时间排序然后直接做就行了,对于完全持久化来说,我们可以把版本树建出来,把询问挂到点上,然后 DFS 一遍,只需要支持撤销上一次操作即可。那么我们下面讨论的做法都是在强制在线的前提下进行的。
持久化的常见方法
- 路径复制
- 肥节点
- 节点分裂
路径复制
路径复制是最简单也是最常用的一个,具体来讲就是将修改涉及到的所有节点全部复制一遍,我们所熟知的可持久化线段树与可持久化平衡树都是这样实现的。注意这种方法要求数据结构必须是自上而下的,也就是说不能记录父亲,因为这种做法依赖于子树可以重复使用,如果记录父亲则会导致一个子树可能存在多个父亲。因此,对于可持久化边分树来说,一般会建出每个点对应的树,从而自上而下的进行修改与查询。
这种方法支持部分持久化、完全持久化、可合并的持久化,且不改变原数据结构的单次需修改/查询的时间复杂度,但是问题在于其空间复杂度与时间复杂度一致,有时候会导致空间复杂度很劣。
肥节点
首先考虑一个特殊的问题:持久化数组。所有数据结构都可以用持久化数组来实现持久化,所以我们只需要考虑持久化数组。
最暴力的想法当然就是直接上可持久化线段树。我们考虑时空复杂度更优一些的做法。
我们先考虑部分持久化。这样,我们可以考虑用 \(n\) 个 vector 来做这件事情,每个 vector 存储该位置每次修改的时间与修改成的值,这样单点查询时就只需要在数组上二分找到查询时间的前驱即可。这样修改的时间复杂度就降低到了 \(O(1)\),查询时间复杂度 \(O(\log n)\)。如果使用 vEB 树来维护每个位置的 vector,则可以做到插入查询均为 \(O(\log \log V)\),且该做法的空间复杂度是线性的。
那么对于完全持久化呢?我们同样可以考虑和上面所说的类似的方法,仍然对于每一个位置记录其所有修改位置,只不过这时候相当于在查询其在版本树上到根的最近的一次修改,不过直接维护这个显然是不好维护的,因为我们需要动态加点。考虑将树拍成序列来维护,我们考虑版本树的括号序列,左括号表示修改为新值,对应的右括号表示修改为原来的值,这样我们又变成了一个版本序列上的问题,只不过这时候我们可能在序列的某个位置处插入新的版本。不过注意到这只会添加两个元素,不会使之前的修改改变。于是我们直接拿平衡树来维护这个修改序列即可。
看起来很完美,不过实现就会注意到致命的问题:我们很难找到插入的两个版本在平衡树上的位置。我们只能知道这两个括号需要在修改版本的左括号右面插入,但是我们并不知道这两个左括号所在的位置。于是这时候我们要解决一种称为“动态标号问题”,即我们需要解决下面问题:
维护一个双端链表,支持在给定编号的节点前插入一个节点,查询两个编号的节点在链表上的先后关系。有一个简单的想法就是给每一个节点赋一个全新的编号,其大小关系表示其在链表上的先后顺序,一个暴力的做法就是每插入一个点就将其编号设为其前驱与其后继的两个节点的平均值,这样肯定可以保证大小关系是正确的,但是问题在于这样做可能会精度爆炸,如果一直在开头插入元素那么精度就去世了,所以我们需要某种方式防止精度出现问题。注意到如果我们把上述过程在类似于线段树的结构上维护,那么我们只需要保证这棵树的深度不超过 \(O(\log n)\) 即可,而这显然是平衡树可以干的事情。替罪羊树可以很容易的解决这一件事情,其它平衡树理论也可以实现,不过相对来说更麻烦点。
那么我们就在 \(O(n \log n)\) 的时间复杂度,\(O(n)\) 的空间复杂度内实现了持久化数组。
还可以继续使用一些科技优化到 \(O(n \log \log V)\),不过我摆烂了不想写了,大概就是按照 \(O(\log n)\) 进行分块,把编号看作一个二元组,块内可以使用上述所说的取中位数方法,由于节点很少精度不会出问题,所以可以 \(O(1)\) 插入与查询,然后在加上些什么东西就好了,咕了。
结点分裂
没听。
可持久化平衡树相关技巧与应用
终于有一些 OI 有用的内容了。
首先可持久化平衡树是可以标记下传的,pushDown 的时候新建左右儿子即可。
区间复制
FHQ-treap 似了,但是也不完全似。
首先最简单的想法就是直接复制即可,但是这样会出现一个问题就是随机权值也会一起复制过去,导致这样平衡树的高度没有保证了。
有一个乱搞做法就是,合并的时候不再按照随机权值合并,而是直接随机合并,按照子树大小为权重直接随机作为新的根,lxl 都不会卡那么他是对的。
对于其它平衡树来说,WBT / WBLT / AVL / RBT 都是可以严格 \(O(\log n)\) 实现区间复制的。
P8263 [Ynoi Easy Round 2020] TEST_8:维护一个长为 \(n\) 的 01 串,支持将一个区间内的串复制 \(k\) 次,区间按照奇偶性翻转复制 \(k\) 次,删除一段区间,查询第 \(k\) 个 1 的位置。保证 01 串长度始终不超过 \(10^8\)。
首先问题在于怎么复制 \(k\) 次,可以考虑类似于快速幂的方法去合并,这样需要合并 \(O(\log n)\) 次,FHQ-Treap 每次合并 \(O(\log n)\),而 WBLT 和 AVL 可以 \(O(1)\) 合并两棵平衡树,WBLT 是因为只需要新建一个节点将两棵子树直接接上去就行,显然这样仍然是平衡的,AVL 支持 \(O(h)\) 合并两棵深度差为 \(h\) 的子树,所以也是 \(O(1)\) 的。剩下的操作是简单的。
P8524 [Ynoi2078] 《A theory of consciousness from a theoretical computer scienceperspective: Insights from the Conscious Turing Machine》阅读报告(更新中...):维护一个数据结构,支持区间复制(将一段复制然后覆盖到另一段上),区间除以 \(2\) 向下取整,区间求和。要求时间复杂度 \(O(n \log^2 n)\),空间复杂度 \(O(n \log n)\)。
首先如果没有区间复制显然均摊一手就做完了,问题是存在区间复制。
那么我们考虑不使用均摊来考虑这个事情了,我们直接维护出一个元素进行 \(0 \sim \log V\) 次操作后的值分别是多少,然后平衡树维护子树内所有元素操作 \(0 \sim \log V\) 次后的和,这样查询修改都容易在 \(O(n \log n \log V)\) 内实现,现在问题在于空间复杂度也是 \(O(n \log n \log V)\) 的。
注意到多出的 \(\log\) 的空间是持久化导致的,但是我们实际上不需要访问历史版本,我们只关心最后一次操作后的平衡树,于是我们可以考虑优化一下空间使其达到 \(O(n \log V)\)。
首先有一种方法就是直接考虑每个节点是否还被使用,如果不被使用就回收掉,这样需要维护每一个节点被使用了多少次,或者可以使用 STL 中的智能指针实现。另外还有一种更简单的做法是,考虑每进行 \(O(\frac{n}{\log n})\) 次操作后重构一次整个序列。这样每次重构前总共新建的节点有 \(O(\frac{n}{\log n} \times \log n) = O(n)\) 个,而重构的复杂度为 \(O(n)\),且重构次数为 \(O(\log n)\),这样就可以时间复杂度 \(O(n \log n)\),空间复杂度 \(O(n)\) 了。
实际上这题可以直接考虑维护每一种钱数最后会得到的总权值,这个显然是可以递推的,然后这个递推实际上只涉及将上一个序列的两部分拼接起来(两部分有重叠),直接可持久化平衡树维护就行了。
HDU5118 GRE Words Once More(改):给定一个 DAG,边上有字符,问所有从 \(1\) 开始的路径组成的字符串中,字典序第 \(k\) 大的字符串的终止结点。\(n, m \le 10^5, k \le 10^{18}\),强制在线。
同样可以考虑直接递推求解,设 \(f_{u, k}\) 表示从 \(u\) 开始第 \(k\) 大的终止结点时哪个,那么显然有简单的递推,答案就是其后继节点的平衡树的拼接。注意如果子树大小超过 \(10^{18}\) 则将后面的部分截断,否则节点数可能指数级增长导致合并复杂度出现问题(合并复杂度为 \(O(\log siz)\))。
BZOJ3946 无聊的游戏(改):维护长为 \(n\) 的序列,每个位置是长 \(\le 10\) 的字符串,\(m\) 次操作,每次区间在开头拼接上一个输入的字符串 \(S\),或查询区间 LCP 长度。\(n \le 10^6, m \le 3 \times 10^4, \sum |S| \le 10^7\)。
考虑线段树套可持久化平衡树,第一个操作直接在线段树上进行区间操作,比较诡异的可能是如何打标记。注意到平衡树进行拼接操作单次时间复杂度是 \(O(\log n)\) 的,那么实际上我们可以把可持久化平衡树看作一种标记,它是可以 \(O(\log n)\) 进行标记合并的,合并两个区间时,两个区间的 LCP 则可以直接二分哈希找到,就可以做到简单的 \(O(n + m \log^3 n + \sum |S|)\) 的复杂度。
考虑优化一下,求区间 LCP 实际上只需要求相邻两两字符串之间的 LCP 然后取 min 即可,注意到区间前面加字符串只会使得中间的 LCP 直接加上当前这个串的长度,只有两端的 LCP 可能发生改变,于是只对这两个进行二分哈希即可,复杂度 \(O(n + m \log^2 n + \sum |S|)\)。
CF1340F Nastya and CBS:维护一个有多种括号的括号序列,支持单点修改,区间查询括号序列是否合法。
单次询问显然贪心匹配即可。注意到合法区间的某一个子区间,进行贪心匹配后,只会剩下一串右括号和一串左括号,而两个区间是容易合并的,只需要将左区间的右括号与右区间的左括号匹配一下,如果有匹配不上的就是不合法,否则又可以得到剩下的一串右括号和一串左括号。显然可以平衡树维护哈希来判断,然后再上一个线段树套可持久化平衡树即可完成这个问题。
单侧递归模型无用论:lxl 说兔队线段树可以完全被线段树套可持久化平衡树替代,具体啥我没听。
可持久化可并堆
没听,不会堆,听不懂。
OI 在 TCS 中的应用 - 许庭强
对不起我一句也没听懂,最后一个小时手机没电,甚至在座位上睡着了。
要了个 lxl 的签名。

晚上营员交流,下午睡觉睡的有点自闭,所以晚上并不是很想去。听说自习室有大量电源,于是决定去看看,于是和 ztx, haosen, syh 一起去了自习室。
看了眼 USACO Pt 的题,好像确实有点水。然后看了看 [SNOI2024] 拉丁方,想了一段时间大概想到了二分图的模型,注意到了这个图是正则二分图,然后盲猜了一个一定存在完美匹配,每次删一个匹配仍然是正则二分图,搜了一下发现确实,然后感觉只会 \(O(n^{3.5})\) 的算法(每次暴力匹配),搜到的博客里还有个 \(O(n \log n)\) 的正则二分图匹配算法但是感觉有点不像正解,不过确实能做到 \(O(n^2 \log n)\) 之类的东西。然后还没想到第二部分可以补几个点然后同样转化成正则二分图。然后看了眼题解,第一篇确实是这个做法,然后后面的题告诉我这是二分图最小染色问题。我草怎么是卡科技题。算了摆烂了。
然后回去睡觉了。
Day 3
题目选讲 - 戚朗瑞
记不太清讲题顺序是啥了。
CF1753C Wish I Knew How to Sort
是我打的第二场 CF 的过了的题!!!111
我们只关心一个 0/1 有没有移动到正确的位置,也就是考虑有 \(k\) 个 0 \(n-k\) 个 1,那么我们只关心前 \(k\) 个位置中的 1 与后 \(n-k\) 个位置中的 0 进行交换,假设当前前 \(k\) 个位置有 \(m\) 个 1,那么显然期望 \(\frac{n(n-1)}{2 m^2}\) 交换成功,然后求个和就好了。
DMOPC '22 Contest 2 P6 Yogyakarta Elevators
考虑按照电梯建图,把电梯看作点,然后对于一层楼,我们将所有包含这层楼的电梯连一个完全图,边权为楼层,表示对于这个楼层任意电梯可以互达。那么条件可以转化成,对于一个权值区间 \([l. r]\),仅保留这个区间内的点,图是否联通(除去孤立点)。
考虑扫描线,从大到小考虑每一个左端点,对于每一个左端点求最大的右端点。注意到我们只关心连通性,所以只需要维护一棵生成树。我们可以从小到大加入每一条边,注意到这相当于维护出一棵最小生成树,而加边的过程中这棵树只会改变 \(O(m)\) 次,所以我们只需要对这 \(O(m)\) 种情况进行判断即可。这样我们拿并查集简单维护一下,复杂度 \(O(nm \alpha (n))\)。
细节我没有很仔细想,感觉对于如果一个楼层只有一个电梯的情况,好像得特殊处理一下,我的想法是可以把一个电梯拆成两个电梯这样就不存在只有一个电梯的情况了,或者把一个电梯单独看作一个事件,在维护最小生成树的过程中也维护下每个点是否被选。没有电梯的显然是不合法的。
CF1353D The Beach
是我打的第二场 CF 没过的题!!!111
考虑黑白染色一手,发现一次操作之后空白所在的格子颜色不变,而要拼成 1x2 则需要一个白色与黑色空格相邻,那么我们可以看作是移动空格子,可以移动两格或向对角的位置移动一格。只需要建出图来然后跑多源最短路即可,然后枚举最后的 1x2 的位置在哪。这样有可能出现不合法移动,不过可以发现如果有不合法移动(空格旁边并没有可移动障碍,而又是一个空格),那么此时已经有解了,继续往下走肯定也不会影响答案。注意需要连单向边,好像有一些细节。
ARC148D mod M Game
额做过,直接把题解复制过来了。感觉这题还是很牛的。
首先我们考虑当仅剩下两个数字时,Bob 如何会赢。那么假设现在 Alice 取的数的和为 \(x\),Bob 取的数的和为 \(y\),剩下的两个数字为 \(a\) 和 \(b\),那么 Bob 会赢当且仅当 \(x + a \equiv y + b \pmod m\) 且 \(x + b \equiv y + a \pmod m\),那么可以得到一个 Bob 获胜的必要条件 \(2a \equiv 2b \pmod m\)。
那么这样的 \(a,b\) 仅有可能是 \(a=b\) 或者 \(a \equiv b + \frac{m}{2} \pmod m\)(当 \(m\) 为偶数时)。
我们不妨考虑将这样的数看做一对。那么不难想出,如果所有的数都可以匹配成若干 \(a=b\) 与偶数对 \(a \equiv b + \frac{m}{2} \pmod m\),那么 Bob 就一定有必胜策略。Bob 的必胜策略就是每次 Alice 取一个数,Bob 取与之配对的数,这样最后两个和一定相等。
那么是否这个条件为 Bob 获胜的必要条件呢?考虑如果不满足以上的匹配,我们构造一种 Alice 的必胜策略,即可证明该条件为充要条件。
我们先能匹配的匹配,最后应该会剩下一些互不相等的数,且满足 \(a \equiv b + \frac{m}{2} \pmod m\) 的数对只有 \(0\) 或 \(1\) 对。那么我们先让 Alice 随便选满足 \(a \equiv b + \frac{m}{2} \pmod m\) 的其中一个数,如果没有那就随便选一个未匹配的数。
假如 Bob 选择了一个在匹配中的数,那么 Alice 可以直接选择与其向对应的数,如果 Bob 选择了一个不在匹配中的数,那么 Alice 也选不在里面的数。这样当不能匹配的数仅剩下两个时,这两个数一定不满足一开始所述的 \(2a \equiv 2b \pmod m\) 条件,那么此时 Bob 一定不会获胜,也就是 Alice 一定能够获胜。
于是就可以证明上面的条件是充要的,于是只需要判断能否构成这样的匹配即可。
ARC151E Keep Being Substring
这题 SoyTony 很久之前就切了,拜谢 SoyTony!
考虑如果初始字符串与终止字符串有公共子串,那么显然缩到最长公共子串然后拓展成终止串最优。
否则肯定是缩小到一个字符,然后不断进行拓展一个字符,删除一个字符,直到得到另一个串中的某个字符,然后再拓展。这个直接建一个 \(26\) 个点的图然后跑最短路即可。
CF1570F Square Filling
没听懂
P4429 [BJOI2018] 染色
超级大分类讨论题,没听,摆了。
P9600 [IOI2023] 封锁时刻
考虑先把 \(a-b\) 的路径从中间切开,两棵树中一棵树距离 \(a\) 最近,一棵树距离 \(b\) 最近,那么有两种情况:一种是两个点能到达的点集不相交,一种是两个点能到达的点集相交。这里选取的 \(c_i\) 显然都是 \(a/b\) 到 \(i\) 的距离。这里看起来像是一个树上背包的状物,但是仔细观察一下就会发现,父亲权值永远比孩子权值小,我们要最小化总花费,那么对于任意选取方案(不考虑树上的限制),最优解一定不会出现某个点选了而父亲没选的情况,那么实际上我们就把树的限制直接去掉就行了,只需要考虑每个点是否选。
对于第一种情况,每个点最多只有 \(1\) 的贡献,显然直接贪心即可。
对于第二种情况,\(a-b\) 的链上所有贡献至少为 \(1\),其它点可能有 \(0/1/2\) 的贡献,我们需要决策这一点。设 \(p_i = \min(\mathrm{dis}(a, i), \mathrm{dis}(b, i)), q_i = \max(\mathrm{dis}(a, i), \mathrm{dis}(b, i))\),显然 \(p_i\) 是贡献为 \(1\) 的代价,\(q_i\) 是贡献为 \(2\) 的代价。这里有一个相关的结论:对于 min-add 卷积,如果所有函数下凸,那么差分之后每次贪心选最小的即可,如果所有函数上凸,那么一定只有一个函数选了一部分,其它的函数要不然全选要不然全不选。这是因为,如果有两个函数均选了一部分,那么我们考虑调整的代价,发现一定有一种调整方案的代价是小于 \(0\) 的,即可以使得权值更小。这题我们可以看作是若干个函数的 min-add 卷积,而所有函数由于只有三个值,所以其要不然上凸要不然下凸,其中只有一个上凸函数选的权值为 \(1\)。那么我们考虑把下凸先全合并起来,上凸按照 \(2\) 的代价排序,枚举选了多少 \(2\),在这些 \(2\) 中挑一个改成 \(1\) 的贡献,显然挑代价减少最大的那个,这样就能找出最小答案了。
P9605 [IOI2023] 机器人比赛
感觉还是很牛的,没有想细节所以大致口胡一下。
我们可以用六种标记来通过本题,六种标记分别为:题目中要求的 0/1 和 上下左右。
首先考虑找出怎么找最短路径,显然不可能考虑 dijkstra 之类的东西,考虑 bfs,并维护出 bfs 树。我们考虑每次拓展一层,每次将整颗 bfs 树遍历一遍,考虑每个点上维护一个指针表示这个点最后一次走的方向,当在左上角时,将当前指针指向下面或右面(如果下面有障碍),然后向相应的位置走,如果走到了一个 \(0\) 的位置那么就将其指针设置为父亲节点并返回(此时周围只有一个指针指向它,所以可以找到父亲节点)。否则,将当前指针逆时针旋转一次,再往相应的方向走。可以发现,这样一直走就能建出 BFS 树了。注意到这个过程中,每一时刻整棵树都是以当前点为根的一棵树,即所有点都指向它(除了没访问的点),不存在出边,我们可以利用这一性质来确定当前所在的阶段。
接下来是第二阶段,需要标记出最短路,我们首先在判断到达右下角后,开始从右下角开始 DFS。此时我们不更改任何箭头,注意到这时候除了右下以外所有点一定存在出边,于是这样就可以判定当前在第二阶段了,每次找到一条出边,然后往里走,如果到左上角或者周围有 1 则把当前点标记为 1,否则如果没有出边了就标记为 0。这样就可以解决这题了。
量子计算简介 - 袁骁
啊这个我应该写听课记录吗?
其实我确实听了,因为我还是对相关的一些东西有些感兴趣的,不过确实相关知识了解的太少所以也不是特别懂。
晚上领取了密码条,马老师让我给大家讲几句。
?
“希望大家不要保龄,谢谢大家。(鞠躬)”
晚上直接摆烂了,然后早点睡准备第二天打比赛了。
然后还是看视频看到了十一点多,没救了。
Day 4
WC 测试,有点恐怖了!
入场了,每个人桌子上放了五个牌子,马桶牌、香蕉牌、电脑牌、水牌、草稿纸牌。分别代表需要上厕所,需要食品,电脑出现故障,需要水,需要草稿纸,有什么事情直接举牌子让工作人员来处理。比较有趣。
然后 8:00 开考了。没有交互?没有交互?没有交互?行吧。
先把配置打了,然后开 T1。是个计数题,看起来好像比较朴素?显然拆一手贡献,然后计算下方案数,枚举它是第一个集合还是第二个集合,第一个集合只需要前面第一个集合内的和加上当前时间小于等于 \(T\) 即可,背包一手。在第二个集合就是前面的所有加上后面的第一个集合,也背包一手就完了..完了?
数据范围给的 \(n \le 200, T \le 300000\),为什么放个 \(O(nT)\) 的算法??还给了测试数据编号??什么鬼??
不太相信,然后开始打了。8:20 的时候就打完了,测了一下发现确实对了。草这个 T1 为什么这么简单??
开 T2。感觉要是 T1 这么简单那得争取 T2 过一下或者拿比较高的分了,第一题有点送了。
T2 一眼看上去感觉是个很复杂的题?首先发现这个 \(2L\) 是真的没用,直接换成 \(L\)。一开始想了若干最长脸与最小链覆盖之类的内容,但是确实没啥用。显然只关心两两之间的相对大小关系,所以可以考虑枚举一手 \(L\),由于只有相邻两个数之间的大小关系是有意义的,那么只有 \(O(n)\) 种有用的 \(L\)。先考虑固定一个 \(L\) 怎么计算答案,发现由于选的必须是连续区间,那么感觉是存在很简单的 DP 的,设 \(f_{i, 0/1}\) 表示以 \(i\) 为右端点,选择的是 \(h_i\) 还是 \(h'_i\),最长的长度是多长,那么有很简单的 DP,大概就是 \(f_{i-1, 0/1} + 1 \to f_{i, 0/1}\),转移条件就是两个数之间是否是小于的关系。由于已经固定了 \(L\) 那么所有大小关系是可以确定的。注意到这个转移可以写成 max-add 矩阵,可以考虑拿矩阵维护一下?一开始感觉上是要维护每个位置的历史最值啥的,然后突然意识到好像根本没必要以位置为下标维护答案,可以直接上一个扫描线,以所有可能的 \(L\) 为下标同时维护所有 DP 过程啊!每次只需要找到所有 \(L\) 中的最大值就可以了。把 \(L\) 按顺序排列,那么肯定是每次一个前缀满足 \(h'_{i - 1} < h_i, h_{i-1} > h_i\),后缀反之,于是就很简单了,每次区间乘个矩阵就好了。然后把矩阵大小卡了卡,过了大样例。
此时才 9:40 左右。我挺震惊的,啥意思我怎么不到两个小时已经 200 分了。第三题看着真的不是很能做,感觉极其抽象。感觉能大概想明白若干种确定答案的策略,但是感觉非常复杂,写成 DP 也很抽象。感觉指数级暴力都难写啊!瞪着数据范围看了半天,突然意识到原来特殊性质说的是确定的区间是所有前缀,那不就是说所有值全部都确定了吗?这个我会啊,这个简单 DP 一下就好了,只有选择当前节点,儿子将当前节点确定或者父亲与兄弟将其确定三种情况,直接简单 DP 一下就行了。很快把这个东西写好了,过了特殊性质的大样例,此时 10:20 左右。
然后我趴桌子上睡觉了。感觉真的没有任何可以写的东西了啊??想了很久还是没有任何思路,感觉 \(m=1\) 可以用我想的那种策略去做一下,但是感觉状态与转移多的离谱,怎么想怎么不想写,然后其它的东西也真的想不到,仍然不知道指数级暴力有没有好写的做法,然后就摆烂了。瞪了快半个小时感觉可以尝试写一下 \(m=1\)。然后就开始写了。
极其痛苦的写转移写了快一个小时,写了巨大多转移,感觉把自己快写吐了。
果然大样例过不去。去你妈的。
然后又调了半天,发现了转移的一些错误,改完之后大样例还是不对,手造了一个小样例,但是没有指数级暴力所以没法算答案,手模感觉过于复杂,瞪着 dp 数组想了半天也没想到什么有意义内容。总之又手模了几个小样例发现都是对的。然后摆烂了,实在不知道怎么整。
12:50 多的时候在想指数级暴力判断能不能写个高消判定是否能拼出来啥的,至少不依赖于任何性质所以起码应该能用来验证,不过肯定是没空写了。然后就摆烂了。
非常乐,两个半小时拿完了所有分,剩下两个半小时怒砍 0 分。
出场 fzj 跟我说 T2 自己造的数据比大样例慢快一倍,给我整害怕了。然后发现我做法和他也不一样,他是线段树分治啥的 2log 做法,我 1log 但是有矩阵乘法的十几倍常数,其实可能也差不多。fzj 说感觉有 T3 的 \(O(nm)\) DP,但是样例过不了,我不是很懂,他以为特殊性质只有开头的 5 分,所以根本没想特殊性质,最后冲到最后没冲出来。草了。后来他说又看了看他写的 DP 感觉没啥问题,有可能假了,我不太懂,反正我写的 \(m=1\) 的 DP 也是看不出来问题。
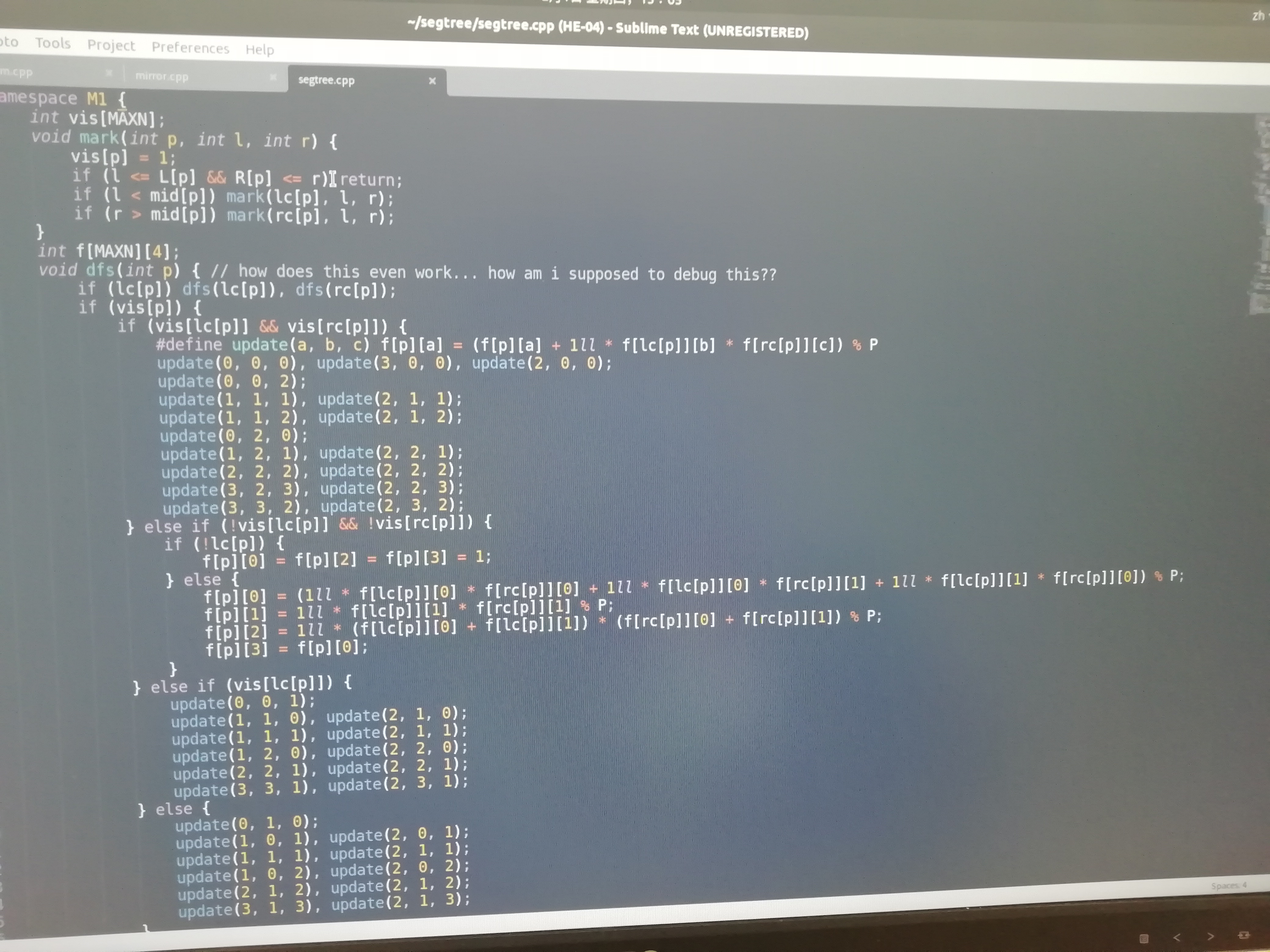
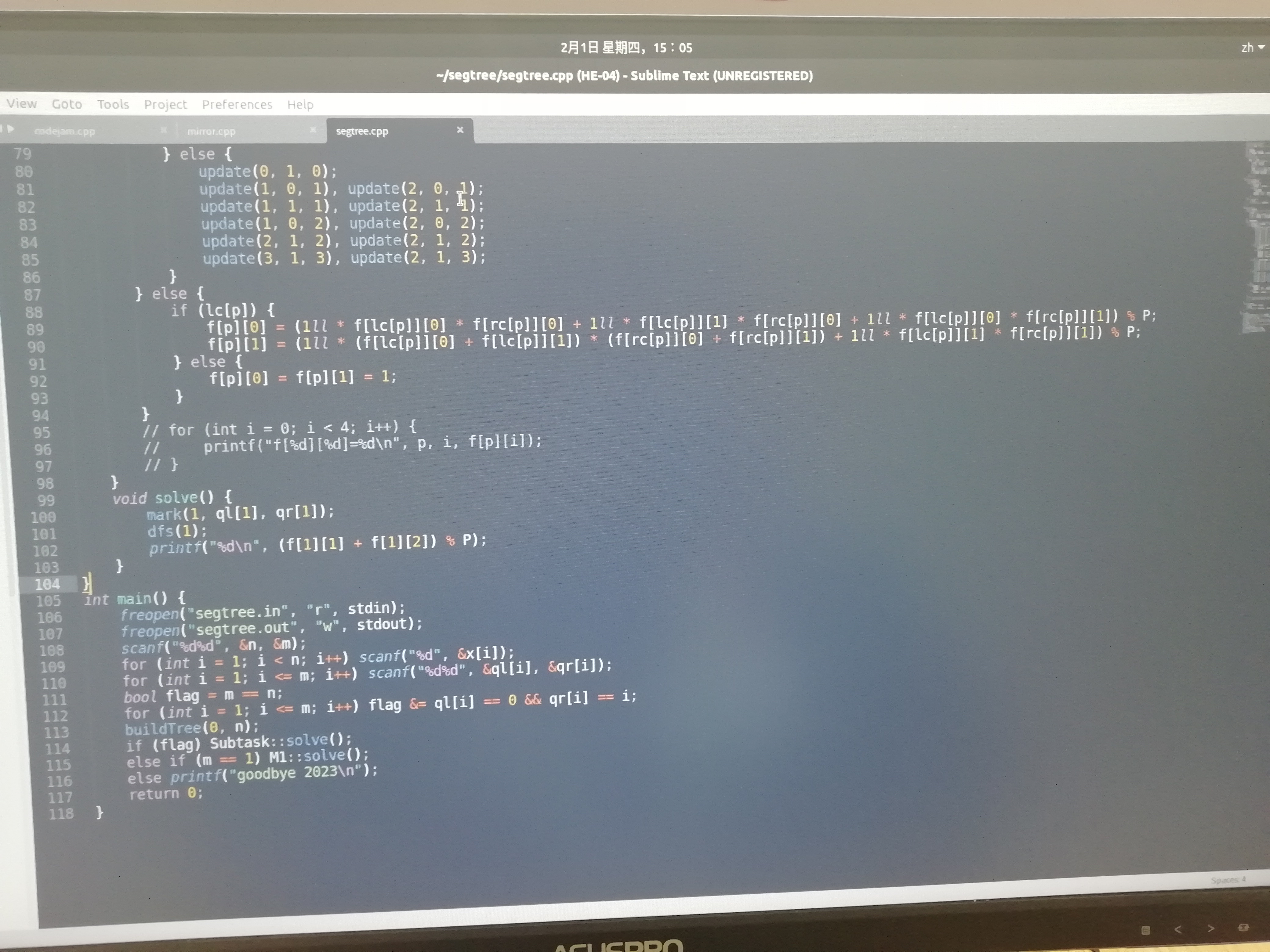
放一个我的抽象 \(m=1\) 的转移代码。写这玩意给我写吐了。
下午查分,没挂。旁边的老哥打了 255 分,恐怖了。看到了若干 220,感觉确实有点大众了。fzj 205。然后就不管了。下午讲题没去听,好像 T2 有线性做法,摆了。然后原来 T1 是 WC 特供的,WC 的 T2 T3 是 CTS day1 的 T1 T2。草,这就解释了诡异的难度了。
晚上有民间文艺汇演!然后晚饭的时候得知好像出现了沟通失误,skc 在跟 ccf 联系的时候,ccf 好像误以为是想让他办一个文艺汇演,所以联系 yc 的人准备了文艺汇演,然后晚上的时候发现 yc 的来彩排了。然后沟通了一下,最后决定先进行 yc 的节目,把 yc 准备的小游戏给去了,后面进行民间文艺汇演的活动。
不过 yc 准备的节目不得不说还是很有水平的。然后接下来若干抽象节目,如出现了三首米哈游歌曲,然后有若干日语歌,还有 dottle 的再一次替身演讲“我的又一个机器人朋友”。中间进行传统谁是卧底,出现了 OI vs 原神 的抽象题目,感觉非常乐。总的来说体验还是很好的。最后又唱了《蜂鸟》,群里:OI 界的难忘今宵( 不过不得不说,半年过去之后再听一次,感触多了很多,半年前的我在极度难受自卑的情况下完全无法嘻嘻听进这首歌,而这次小声跟唱了全首歌。可能也有 WC 考的还行的因素吧,心情本身就不是很差。耳朵龙由于考的不是很好,明显心情就不是很好,可能和半年前我的感受一样吧。
我们到底在追求些什么
为何一直不断往前冲
捏出血的双手
忘了也能够 稍微退后我们总是以为能够自由
回过头那世界却依旧
哎 爱它来的时候
紧握的拳头 别忘了捉 那个梦
Day 5
组合计数中的递推问题 - 李白天
说实话没有东西可以写。
不会符号化啊。
类似于 EGF 下的 exp/ln,欧拉变换也有逆:
证明考虑一些莫反。
一个例子:设 \(A(z) = \frac{1}{1-qz}\),其可以表示字符集为 \(q\) 的字符串,或有限域上的多项式 \(\mathbb{F}_q[x]\),任意一个字符串可以看作是 Lyndon 串的多重集,任意一个多项式可以看作是 \(\mathbb{F}_q[x]\) 上的不可约多项式的多重集,那么 \(A(z)\) 就是 \(B(z)\) 的欧拉变换。那么利用上面的方法,就可以求 \(B(z)\) 了,容易推出 \([x^n] B(z) = \frac{1}{n} \sum_{k | n} \mu(k) q^{n/k}\)。
其实主要是发现这个东西能跟狄利克雷卷积一套东西扯上关系还是比较震撼的,不过可能还是没啥用。
但是剩下的一堆 half-gcd 之类的东西更nm没用啊。我反正不会 bm。
杂题选讲 - 刘一平
P9601 [IOI2023] 最长路径
好像是很有趣的。
只考虑 \(D=1\)。容易猜到,答案应当是很大的,图很有可能存在哈密顿路径。假如这张图不连通,那么容易发现只能有两个连通块,并且两个连通块均为完全图,此时答案就是两个连通块的大小的 \(\max\)。如果联通,猜测一定存在哈密顿路径。
考虑一个很简单的想法:维护一条链,然后每次加入一个点。考虑这个点与两个端点之间的连边,如果这个点与两个点都没连边,那么两个端点之间一定有边,那么这形成了一个环,然后找到这个点与环上任意一个相连的点,从这个点处断开即可得到一条链。但是这样还是存在一些问题,因为可能这个点与环上没有连边,且时间复杂度显然也不忧。
那么考虑把限制放的更宽松,我们维护两条链,这时候考虑一个点与两条链的结尾的连边,如果这个点与任意一个点相连,那么直接接上去,否则两条链的结尾一定存在一条连边,把这两条链接起来并把这个点看作新点,容易发现这样一定能连出两条链。这时候考察四个端点之间的连边,假如之间有连边就直接做完了,否则说明此时得到了两个环,假如图是联通的,我们一定可以找到这两个连通块之间的连边,然后直接把环断开就得到哈密顿路了,否则图不连通,答案就是两条链的长度的 \(\max\)。
那么发现这样就构造出了答案,不过询问次数为 \(2n + 2 \log n + 2\),这还是超出了限制。
注意问题在于每加一个点需要询问两次太差了,考虑一个比 \(2\) 小的方法,观察到 \(1.5n + 2 \log n + 2\) 正好等于 \(500\),于是我们考虑构造这样的方法。考虑每次同时加两个点,先询问这两个点之间是否有连边,如果没有连边,说明 \(u, v\) 与两个链尾之间一定存在连边,直接询问即可,否则考虑 \(u\) 与两个链尾是否有连边,如果有就直接连了,否则说明两个链尾之间有边。这样,我们就在 \(1.5n + 2 \log n + 2\) 次询问内做完了。注意 \(2\log n\) 指的是两条链的长度的 \(\log\) 的和,所以上界是 \(14\) 而不是 \(16\)。
P9602 [IOI2023] 足球场
首先肯定不能包含任何障碍,否则绕过这个障碍至少 3 步。然后考虑到形状大致形如从上到下均为一个连续区间,且左端点与右端点是单峰的。注意到如果存在两个区间不交,那么从一个区间到另一个区间就至少需要 3 步,所以所有区间一定都交于一点,那么限制条件就是,区间长度先变大再变小,且按长度排序后小区间一定包含于大区间内。
考虑一个超级暴力 DP:设 \(f_{l,r,u,d}\) 表示当前选取的最短的区间为 \([l, r]\),且选取的区间所在行为 \([u, d]\),时间复杂度可以优化到 \(O(n^4)\)。
实际上对于一个 \([l, r]\) 来说,只有极大的 \([u, d]\) 是有用的,并且又可以发现,有用的 \([u, d]\) 的总数是 \(O(n^2)\) 的,考虑固定左端点,右端点从左往右扫,每次只可能是一个区间分裂成两个区间,这形成了一个树形结构,于是只有 \(O(n)\) 种不同的区间,于是总数就是 \(O(n^2)\) 的,于是本题就可以在 \(O(n^2)\) 内解决了。
CF1175G Yet Another Partiton Problem
上一个无脑 DP,\(f_{i, k}\) 表示到 \(i\) 分了 \(k\) 段,有转移:
考虑维护单调栈,得到若干个区间 \([L, R]\) 与其对应的最大值 \(P\),上式改写为 \(f_{i, k} = \min_{j \in [L, R]} \{f_{j, k - 1} - jP\} + iP\)。发现前面是一个关于 \(P\) 的一次函数,可以维护凸包,且横坐标是单调的。单调栈插入一个元素会使得最后几个区间合并成一个新区间,由于凸包的横坐标是单调的,我们可以直接把其中一个凸包的点依次加入另一个凸包内,可以直接启发式合并。于是这样我们就得到了 \(O(n)\) 个凸包,对应的找到每个凸包中的最小值后,我们记为 \(g_P\),那么现在问题就是在若干个 \(g_P + iP\) 中找到最大值。注意到这又是一个关于 \(i\) 的一次函数,且每次修改只会删除最后若干函数并插入一个新函数,这相当于插入与回溯的操作,用李超树进行维护即可。
TopCoder 14379 RPSRobots
首先考虑刻画结果,一轮石头剪刀布显然可以看作模 \(3\) 加法,而多轮总和我们可以用单位根来刻画,一轮的结果就是 \(\sum \omega_3^{a_i} \cdot \omega_3^{-b_i}\),循环位移的结果就是 \(\sum_{i - j \equiv d} \omega_3^{a_i} \cdot \omega_3^{-b_j}\)。发现这其实是循环卷积的形式,令 \(p_i = \omega_3^{a_i}, q_i = \omega_3^{-a_{-i}}\),那么合法条件就是 \(p, q\) 的卷积的每一位值相等。
循环卷积肯定不太好考虑,我们 FFT 一手,也就是说将两个序列 DFT 后,点乘起来,再 IDFT,如果每一位都相等则合法。考虑什么序列 IDFT 后会每一位都相等,注意到 IDFT 也是求值的过程,而所有函数值都相等的函数一定是常函数,所以条件是 IDFT 前的序列只有 \(0\) 处有值,其它位置都没值。那么这个条件就好刻画了,我们考虑将 \(p, q\) DFT 后,令集合 \(S\) 为 \(p\) 中非 \(0\) 的位置集合(除了 \(0\)),\(T\) 同理,那么合法条件就是 \(S \cap T = \varnothing\)。
但是注意到此时 \(p, q\) 的定义仍然不同,不过我们可以证明,两者最后得到的集合是相等的。具体考虑 DFT 后得到的东西:
也就是说,\(q\) 的定义下 DFT 后的序列实际上是 \(p\) 的定义下 DFT 后的序列的共轭,显然共轭后非零值仍然非零,零仍然是零,所以这时候两个定义是等价的,于是我们就可以看作有 \(n\) 个集合,问有多少种选择一些集合的方案使得任意两个集合无交的方案数,这就是子集卷积问题,可以 \(O(3^k)\) 或 \(O(2^k k^2)\) 解决。
LOJ2462 「2018 集训队互测 Day 1」完美的集合
缝合怪题其实是。
首先求出最大重量和,直接枚举一个 \(x\),树上连通块 DP 有经典的 dfn 序上做法,单次可以 \(O(nm)\),这部分总复杂度 \(O(n^2 m)\)。
先考虑枚举一个 \(x\),然后计算答案。考虑求出包含 \(x\) 的完美连通块的方案数,这显然是可以 long long 存下的。记这个方案数为 \(ans\),那么答案就是 \(\binom{ans}{K} \bmod 5^23\)。由于固定了 \(x\),我们可以直接知道哪些点能选哪些点不能选,求这个完美连通块的方法是简单的,这还是个树上连通块 DP,直接 \(O(nm)\) 做就行了,这样也能 \(O(n^2 m)\) 求出所有答案。
但是容易发现这显然是不对的,会大量算重复。注意到合法的 \(x\) 一定还是树上的一个连通块,那么我们可以用点减边容斥,因为点减边等于 \(1\),我们对于每个点计算一次答案,减去对于每条边计算的答案,就可以去重了。边计算答案也是类似的,就是要求同时包含两个点的完美连通块数。
现在问题在于怎么求 \(\binom{ans}{K} \bmod 5^23\)。显然不能直接算,用 exLucas 的思路,我们先计算出 \(5\) 的次数,这部分是经典的。接下来问题是怎么计算除去所有 \(5\) 的 \(n! \bmod 5^23\)。还是可以用 exLucas 的做法,忽略掉模 \(5\) 剩下的部分,有 \(n! = \prod_{i=1}^{n / 5} (5i) \cdot \prod_{i=0}^{n/5-1} \prod_{j=1}^4 (5i+j) = 5^{n / 5} (n/5)! \cdot \prod_{i=0}^{n/5-1} \prod_{j=1}^4 (5i+j)\),前面可以递归计算,重点在于后一项。正常 exLucas 是 \(O(P)\) 预处理这一部分,但是显然 \(P\) 太大,这里不可以这么做。
考虑折半,\(\prod_{i=0}^{n/5-1} \prod_{j=1}^4 (5i+j) = \prod_{i=0}^{(n/5)/2-1} \prod_{j=1}^4 (5i+j) \prod_{i=0}^{(n/5)/2-1} \prod_{j=1}^4 (n/2+5i+j)\),设 \(f_L(x) = \prod_{i=0}^{L-1} \prod_{j=1}^4 (x + 5i + j)\),那么我们求的就是 \(f_{n/5}(0)\)。
类似的可以合并:\(f_{A+B}(x) = f_A(x) f_B(x+5A)\)。比较重要的事情是我们需要的 \(x\) 都是 \(5\) 的倍数,也就是说多项式只需要维护前 \(23\) 项即可,这样就可以暴力卷积了,\(f_{n/5}(x)\) 快速幂一下即可,于是这样就可以 \(O(23^2 \log_5 n \log_2 n)\) 计算出一个组合数了。
LOJ2461 「2018 集训队互测 Day 1」完美的队列
注意到我们如果能知道每一次插入的所有元素最后一个弹出的时间,我们就能知道每种颜色出现的时间区间,然后就很容易知道哪些颜色出现过哪些颜色没有出现过了。
考虑分块,这样把插入拆成了 \(O(mn/B)\) 次整块插入与 \(O(mB)\) 次单点插入,我们可以分开考虑每一个整块插入或单点插入的弹出时间。
先考虑整块插入,依次对每一个块考虑其中的所有修改。注意到先进行的操作一定先弹出完,这是具有单调性的,于是我们可以考虑双指针来求所有操作的弹出时间。那么考虑某一次操作,维护每个位置上这个操作插入的元素还需要在这个位置插入多少数才会弹出,我们维护出最大值,如果最大值小于等于 \(0\) 则说明在这一时刻所有元素全部被弹出。考虑维护这个操作,一次整块插入会使得所有值全部减 \(1\),一次单点修改给某一位置进行减 \(1\),左端点向右移动时进行全局加 \(1\) 或单点加 \(1\)。全局操作维护一个全局 tag 即可,单点 \(\pm 1\) 全局找最值可以使用桶加链表解决,这样即可 \(O(1)\) 实现所有操作,这部分的复杂度即可做到 \(O(m \sqrt{n})\)。
考虑单点插入,思路类似,仍然双指针,这时候只需要维护这个点被加了多少次,不过并不能遍历所有修改到这个位置的操作,因为这样一个整块操作会被遍历 \(\sqrt{n}\) 次,复杂度爆炸。所以需要将整块特殊处理,维护出每两个单点修改之间有多少次整块操作,只遍历所有单点修改,复杂度就是正确的了。需要比较精细的实现。复杂度 \(O(m \sqrt{n})\)。
注意到这两种修改实际上差不多,可以尝试在线段树上来做。对于线段树某个区间,覆盖它的区间有三种:
- 完全覆盖它的父亲节点上的区间;
- 在当前节点上的区间;
- 不完全覆盖它的子树内的区间。
注意到第二种第三种的总和是 \(O(n \log n)\) 的,我们仍然可以考虑双指针,维护出每两个这样的区间之间有多少种一类型的区间,需要区间加减全局查询最大值,这可以直接线段树维护,复杂度可以做到 \(O(n \log^2 n)\)。
P4220 [WC2018] 通道
?
边分治加虚树加直径,没了,不想写。
CF506E Mr. Kitayuta's Gift
题目等价于问有多少长为 \(n+|s|\) 的回文串存在子序列 \(s\)。但是回文串从前往后 DP 肯定不方便,考虑找出前缀的最长匹配子序列与后缀的最长匹配子序列,这样只要前缀后缀的匹配长度和 \(\ge |s|\) 就是可以匹配。
然后考虑 DP,\(f_{n, i, j}\) 表示已经填了长度为 \(n\) 的前缀与后缀,前缀匹配长度为 \(i\),后缀匹配长度为 \(j\) 的方案数。用 \((i, j)\) 来简记一个状态。考虑 \(s_{i + 1}\) 与 \(s_{n - j}\) 的关系,如果两者相等,那么下一位转移 \(\times 25 \to (i + 1, j + 1)\) 或 \(\times 1 \to (i, j)\),否则 \(\times 1 \to (i, j + 1) / (i + 1, j)\) 或 \(\times 24 \to (i, j)\)。若 \(i + j \ge |s|\),那么这时候已经满足了条件,直接让它 \(\times 26\) 转移到自己。
朴素想法是直接跑矩阵快速幂,但是矩阵大小 \(O(|s|^2)\),复杂度 \(O(|s|^6 \log n)\),不是很能接受。
考虑简化匹配过程。有一种生成函数的做法,考虑记录 \(F_{i, j}(x) = \sum_{k \ge 0} f_{k, i, j} x^k\),那么有转移:
其中 \(A,B,C,D,E\) 都是只与 \(i, j\) 有关的系数,且 \(A\) 的取值为 \(24/25/26\),\(B,C,D,E\) 的取值均为 \(0/1\)。
容易得到 \(F_{i, j}(x) = \frac{1}{1-Ax} (B x F_{i - 1, j}(x) + C x F_{i, j - 1}(x) + D x F_{i - 1, j - 1}(x) + E)\)。又因为 \(A = 24/25/26\),那么 \(F_{i, j}(x)\) 一定是 \(\frac{x^t}{(1-24x)^p (1-25x)^q (1-26x)^r}\) 的线性组合,我们记这个系数为 \(f_{i, j, p, q, r, t}\)。似乎并没有什么改进,但是注意到这些下标之间存在一些潜在的关系。
首先 \(r\) 仅在终止状态会出现一次,也就是 \(r = 0/1\)。其余部分可以看作在矩阵上行走,注意转移 \(\times 25 \to (i + 1, j + 1)\) 与 \(\times 1 \to (i, j + 1) / (i + 1, j)\),如果我们确定了 \(i, j\),那么知道 \(q\) 就能立即知道 \(p\),同时 \(t = p + q + r\),我们也能够知道 \(t\),也就是说,我们只需要记录 \(i, j, q, r\) 四个下标,总状态数是 \(O(|s|^3)\) 的。系数的转移是容易的。
答案可以写成 \([x^n] \frac{A(x)}{B(x)}\) 的形式,直接 Bostan-Mori 求,总复杂度 \(O(|s|^3 + |s|^2 \log n)\)。
还可以从自动机的角度来看,咕了。实际上这个过程大致就是简化自动机的过程。
晚上仍然没去听员交。不过 zky 晚上讲了他的 \(O(\sqrt{n} \log^3n)\) 块筛,不过摆了,我也听不懂啊。
然后又去了自习室,有若干人在打 mc。我把草莓酱中级大厅的心门打通了,然后尝试了下高级大厅,开了个传送门谜题,感觉有点困难了。然后开始写这篇游记了。
不过我右前方的那个老哥在玩啥整合包啊?感觉看着还挺有趣的。太久不玩整合包了都不知道最近有啥有趣的整合包了。
耳朵龙在自习室卷,望周知。
Day 6
随机化和近似算法选讲 - 程思元
P9604 [IOI2023] 超车
首先变一下坐标系,将所有的 \(w_i\) 减去 \(x\),让 \(x=0\)。
考虑如果知道上一个调度站时每个车的到达时刻,计算下一个调度站的到达时刻,每一辆车的到达时刻是它的到达时刻与前面的人的到达时刻的 \(\max\)。容易 \(O(nm \log n)\) 计算出所有车到达调度站的时间。
然后是查询,注意到一件事情,就是如果某辆车被查询的车影响到了,那么这辆车一定是比它快的,那么之后它就在这辆车前面了,一定不会影响这辆车的运行。所以我们只需要管原来的车对查询车的影响就行了。考虑依次在每个调度站二分找到到达下一个调度站的时间,单次 \(O(n \log n)\)。
显然太差了,然后有若干种方法优化。一种方法是注意到这实际上就是 \(O(m)\) 个 \(O(n)\) 段的分段函数的复合,分治复合可以做到 \(O(nm \log n)\),然后再做就行了。还可以数据结构维护复合。或者注意到实际上如果某一时刻查询的车被影响到了,那么下一个时刻就一定是某辆车在某个调度站的时刻了,可以二分找到被影响的调度站然后记忆化一下。
P9603 [IOI2023] 山毛榉树
这题的限制怎么都这么抽象,不是很想读题,摆了。。
P7450 [THUSCH2017] 巧克力
先假设总颜色数等于 \(k\)。不考虑中位数,那么所求的实际上就是最小斯坦纳树。中位数也是容易处理的,经典套路是二分一个值,然后把小于等于这个值的点权加上些东西,然后再跑同样的算法看最少有多少点小于这个值就可以了。
比较困难的是这个颜色数,有一个比较神奇的随机化做法:我们可以给每个颜色重新随机一个 \([1, k]\) 的颜色,然后做上面的算法。对于某一种合法解来说,其所包含的 \(k\) 种颜色被染成互不相同的颜色的概率是 \(\frac{k!}{k^k} = 3.84 \%\),随机 \(200\) 次错误率已经低于千分之一。复杂度 \(O(T nm 3^k \log nm)\),\(T\) 为随机次数。
LOJ3400 「2020-2021 集训队作业」Storm
我们肯定是尽可能少选边。那么首先选择出来的一定是森林,有环显然不优,其次不可能存在长度为 \(4\) 的链,否则拆成两条链一定更优。也就是说最后的边集一定是若干个菊花构成的集合。
考察这样一种选择方法:选择一些点被覆盖,每个点选择出边边权最小的边。这样度数为 \(1\) 的点都可以选择到,但是对于度数大的点就选择不到或者会使边算重。那么加一种选择方案,选择某条边与两段的端点。发现,最优解一定可以通过以上两种选择方法得到。
那么问题转换成,可以选择一些点,权值为点权减最小出边,或者选择一些边,权值为两端端点减边权。要求选择的点不重复,即是一组匹配。
但是这东西是在一般图上的,一般图最大权匹配有点炸裂。考虑随机化,假如我们给每个点随机染黑白色,这样一个匹配就有 \(2^{-k}\) 的概率满足匹配的两个点颜色不同,我们只保留黑白点之间的边,那么答案的匹配就是这张二分图上的匹配。于是就好说了,直接建模跑费用流即可。期望 \(2^k\) 次找到最优解。
随机重排
随机重排有一些优秀的性质:
- 随机排列的前缀最值数量是 \(O(\log n)\) 的;
- 随机 01 序列前缀 01 数量之差的绝对值最大值期望是 \(O(\sqrt{n})\) 的。
因此一些问题将序列进行随机重排后可以优化复杂度。
一道模拟赛题

首先对于一行来说,我们可以 \(O(n)\) 双指针求出这一行中 \(mex\) 小于某值的区间数,套上一个二分即可 \(O(n \log n)\) 计算这一行的答案。
但是直接计算所有答案是 \(O(n^2 \log n)\),比较寄。
这里用到随即重排的做法:随机重排后,由于只有 \(O(\log n)\) 种前缀最大值,我们可以先 \(O(n)\) check 一遍看这一行的答案是否比当前前缀最大值要大。如果 check 成功再 \(O(n \log n)\) 计算新的最大值,否则直接不计算。这样的复杂度变成了 \(O(n \log^2 n + n^2)\),成功去掉了一个 \(\log\),可以通过。
零和背包

正常做背包大小需要开 \(O(nm)\),复杂度 \(O(n^2m)\)。
考虑随机重排一下,这样对于最优解的序列来说,前缀和绝对值不会超过 \(O(m\sqrt{n})\),于是我们只做这么大的背包,复杂度就是 \(O(nm \sqrt{n})\) 的了。
CF1198F GCD Groups 2
考虑一个贪心,设两个集合的 GCD 为 \(g_1, g_2\)。对于每一个数,如果它放在第一个集合不能使得 \(g_1\) 减去一个质因子,那么就放到第二个集合中,因为此时放第一个集合一定不优。同理如果第二个集合不能就放第一个,如果都不能就随便放一个,不重要。如果两个集合都能减质因子,这时候就需要进行决策了,没法直接贪心了。似乎没有好做法,但是注意到质因子个数最多只有 \(w=9\) 种,这样的决策最多只有 \(2w\) 次,我们假如每次随机一个决策,也有 \(2^{-2w}\) 的概率能够找到最优解,我们可以直接随机,期望 \(O(4^w)\) 次随机到正确解,时间复杂度 \(O(4^w n \log a)\)。卡个时就已经可以通过了。
但是这样并不优美,注意到不同的决策一共也就只有 \(O(4^w)\) 种,我们尝试直接遍历所有的不同决策。每次 st 表跳到下一个决策点,据说根据一些好结论单次二分复杂度是 \(O(\log a)\) 的,预处理复杂度 \(O(n \log a)\),这样复杂度 \(O(4^w w \log a + n \log a)\)。
P9074 [WC/CTS2023] 比赛
首先有一个无解的显然的充分条件是同一个社团大小超过 \(\frac 23 n\),因为根据鸽巢原理一定有连续的三个同一社团。猜测这是无解的充分必要条件。
那么构造基本上只需要满足任意时刻最大社团大小不超过 \(\frac 23 n\) 且符合条件就大概是合法的了。那么考虑一个随机化做法:每次随机一个人数最多的社团,然后在里面随机选一个人放到末尾。如果末尾两个人都是这一社团的,就改成随机选一个人放到末尾。如果没有合法的人就重新放。这样最后能得到一个序列,如果这个序列首位相接不合法就重新来。成功概率大致是 \(O(1)\) 的。
[CTSC 2009] N2 数码游戏
这啥抽象玩意,摆了。
神秘科技:格内最短向量问题
说实话感觉这个东西还是很牛逼的。
首先介绍格的概念:对于实数域上,我们有线性空间的概念,即一个由一组基线性组合得到的向量的集合。类似的概念,我们可以在整数域上定义类似的概念,称之为格。具体的,对于 \(k\) 个线性无关的 \(n\) 维列向量 \(\mathbf{b}_1, \mathbf{b}_2, \cdots, \mathbf{b}_k \in \mathbb{R}^n\),定义它们生成的格为:
我们考虑这样一个问题:对于给定的一个格,其中最短的非零向量是什么?不过遗憾的是,这是一个 NPC 问题,但是存在一些近似算法找到近似短的向量。
这个算法叫做 Lenstra Lenstra Lovasz 算法,简称 LLL 算法。具体的,LLL 算法可以找到不超过最短向量的长度 \(\left(\frac{2}{\sqrt 3}\right)^n\) 倍的短向量。我们先来看看需要用到该算法的例子。
0/1 背包问题:有 \(n\) 个正整数,选出一个子集使得它们的和等于 \(m\),或判断无解。如果 \(m\) 远大于 \(n\)(\(m = 2^{n^2}\))且数据随机时,可以使用 LLL 求解问题。
我们用矩阵表示格,那么我们可以构造格:
对于这个格中,系数为 \((b_1, b_2, b_3, \cdots, b_n, -1)\) 所表示的向量如果最后一维为 \(0\),那么就是我们要求的解。这个向量的长度不超过 \(\sqrt{n}\),于是我们可以通过找到这个格内的短向量来解决这个问题。
那么下面介绍 LLL 算法:
首先我们定义 Gram-Schmidt 正交化:
对于一组向量 \((\mathbf{b}_1, \mathbf{b}_2, \cdots, \mathbf{b}_n)\),其 Gram-Schmidt 正交化为:
其中 \(\mu_{i, j}\) 为向量 \(\mathbf{b}_i\) 到 \(\mathbf{b}_j\) 上的投影长度占 \(\mathbf{b}_j^*\) 长度的比例,即 \(\frac{\mathbf{b}_i \cdot \mathbf{b}_j^*}{\mathbf{b}_j^* \cdot \mathbf{b}_j^*}\)。这相当于把当前向量减掉前 \(i-1\) 个正交基的投影向量,得到的新的向量就与前面的基正交。
显然有:
定义 \(\pi_i(\mathbf{x})\) 为 \(\mathbb{R}^n\) 到 \(\mathrm{span}(\mathbf{b}_i^*, \mathbf{b}_{i+1}^*, \cdots, \mathbf{b}_n^*)\) 的正交投影,即:
现在回到一开始的问题。注意到,如果给出的这组向量是正交的,那么最短向量就一定是其中的一个基。那么如果我们能够找到给定格的一组正交基,那么就能找到最短的向量了。当然一个格并不一定存在正交基,所以我们可以找一组“接近正交”的基,我们把它定义为 LLL-简化基。对于一个参数 \(\delta\),称一组基 \((\mathbf{b}_1, \mathbf{b}_2, \cdots, \mathbf{b}_n)\) 是 LLL-简化的,当且仅当同时满足两个条件:
- \(\forall 1 \le j < i \le n, |\mu_{i, j}| \le \frac 12\);
- \(\forall 1 \le i < n, \delta |\pi_i(\mathbf{b}_i)|^2 \le |\pi_i(\mathbf{b}_{i+1})|^2\)。
第一个条件相当于限制两两向量之间的夹角比较接近直角,第二个条件等价于 \(\forall 1 \le i < n, \delta |\mathbf{b}_i^*|^2 \le |\mathbf{b}_{i+1}^* + \mu_{i + 1, i} \mathbf{b}_i^*|^2\)。
引理:若一组基是 LLL-简化的,则 \(|\mathbf{b}_1| \le (\delta - \frac 14) ^ {\frac{1-n}{2}} \lambda\),其中 \(\lambda\) 是格中最短向量的长度。
证明:由第一、二个条件可以得到:
于是对于任意 \(1 \le j \le i \le n\),有:
又因为 \(|\mathbf{b}_1| = |\mathbf{b}_1^*|\) 且 \(\lambda \ge \min |\mathbf{b}_i^*|\),所以有:
根据引理,我们可以令 \(\delta = \frac{1}{4} + \left(\frac 34\right)^\frac{n}{n-1}\),那么 \(|\mathbf{b}_1| \le \left(\frac{2}{\sqrt{3}}\right)^n \lambda\),即一开始所说的结论。
考虑如何进行 LLL-简化。首先我们需要让它满足第一个条件,我们依次处理每一个 \(\mathbf{b}_i\),对于 \(j = i-1 \cdots 1\),令 \(\mathbf{b}_i \gets \mathbf{b}_i - \lfloor\mu_{i, j}\rceil \mathbf{b}_j\),由于较小的 \(j\) 不会影响到较大的 \(j\),执行完这次操作之后一定满足第一个条件,称这个过程为一次 reduction。
然后是第二个条件,如果当前存在一个 \(i\) 不满足第二个条件,那么就直接交换 \(\mathbf{b}_i,\mathbf{b}_{i+1}\),我们称这样一次操作为 swap。但是这样之后第一个条件可能不满足了,这时候再进行一次 reduction。不断重复 reduction 和 swap 这两个操作直到满足条件为止。


一些应用:
低密度背包
就是开头举的那个例子。
卡字符串哈希
我们考虑一般的字符串哈希算法:\(h(s) = \sum_{i=0}^{n-1} \mathrm{ord}(s_i) e^i \bmod p\),其中 \(\mathrm{ord}(s_i)\) 为 \(s_i\) 的 ASCII 码。注意到我们只关心 \(\mathrm{ord}(s_i) - \mathrm{ord}(t_i)\),这个值在 \([-25, 25]\) 之间。
构造格:
那么我们可以找出较短的一个向量,使得前若 \(n\) 维都在 \([-25, 25]\) 之间,且 \(n+1\) 维等于 \(0\),那么就意味着找到了两个哈希值相等的字符串。
注意到第 \(n+1\) 维的限制比较紧,必须等于 \(0\),那么我们可以考虑将第 \(n+1\) 维整体乘一个常数 \(M\),这样如果第 \(n+1\) 维不等于 \(0\) 则会导致距离偏大,这样短向量就更有可能符合条件。\(M\) 可以取字符集的二倍。也就是说新的构造:
对于多模也是一样的做法,对上述格拓展下,假如有 \(k\) 组模数与底数 \((e_i, p_i)\),那么:
据 csy 说双模哈希 \(n=6\) 可以卡掉,十模哈希 \(n=100\) 可以卡掉。还是很恐怖的。
P6634 [ZJOI2020] 密码
考虑这题相当于要求 \(|((c_1 - a_1 x) \bmod p, (c_2 - a_2 x) \bmod p, \cdots, (c_m - a_m x) \bmod p)|\) 尽可能小,那么相当于向量 \(x \mathbf{a} - \sum k_i \mathbf{p}_i\) 尽可能接近 \(\mathbf{c}\)。首先先构造前者的格,由于我们最后需要知道 \(x\) 的值,所以需要新加一维表示 \(x\) 的值,但是这样可能会导致距离过大,所以我们把这一维的值写为 \(\frac{err}{p}\),这样这一维大小也是 \(O(err)\) 的,实际实现可以直接把所有值全乘 \(p\) 就行了。构造为:
考虑把 \(\mathbf{c}\) 也加入格,然后限制 \(\mathbf{c}\) 的系数为 \(\pm 1\)。
但是这样有可能出现最后一维系数大于 \(1\) 的情况,和上一个问题类似的思路,用一个常数来控制这一维的系数。不过这时候是列向量的系数而不是最后的向量的某一维大小,我们可以加一维来控制这个大小:
但是这时候又要注意,如果 \(M\) 很大那么最后一维的系数会变成 \(0\),如果 \(M\) 很小则系数绝对值会大于 \(1\),所以需要选一个适中的 \(M\)。
\(m\) 太大会 TLE,可以只用前十条信息来跑,再把得到的所有可能向量全验证一遍即可。
GYM104857A SQRT Problem
首先第二个限制显然是 \(x \in [l, r]\),记 \(B = r - l + 1\),然后问题转换成求 \((x-l)^2 - a \equiv 0 \pmod n\) 在 \([0, B)\) 内的零点问题。设 \(f(x) = (x-l)^2 - a = f_0 + f_1 x + f_2 x^2\),考虑构造多项式 \(g(x) = g_0 + g_1 x + g_2 x^2\) 满足 \(f(x) \bmod n\) 的零点都是 \(g(x) \bmod n\) 的零点,且满足任意 \(x \in [0, B)\) 都满足 \(g(x) < n\),那么我们就不用考虑 \(\mod n\) 的限制,可以直接二次函数求根。问题在于求 \(g(x)\)。
我们把 \(g(x)\) 看作几个多项式的线性组合,这里给出一种构造是 \(g_1(x) = n, g_2(x) = nx, g_3(x) = f(x)\),可以发现这三个多项式的系数是线性无关的,于是用这三个来做。如果能让 \(g_0, g_1 B, g_2 B^2\) 都很小,就能满足 \(g(x) < n\),于是构造格:
找到这样的多项式后直接二次函数求根即可。
计算机教育漫谈——算法与教育 - 刘润达
额这个真的没啥可写的,总不能写一个刘润达老师对原神的看法吧。
upd. 若干人问我看法是什么:“我认为原神是中国近几年最好的游戏之一”
终于听完了 WC 的所有课了!!
晚上打了会 phi,突然感觉手感不错,GOODRAGE 莫名打到了 2 good(之前没全连),然后尝试去推了一下之前一直 1 good 的 DNA,在两次 1 good 之后终于 phi 了,感动,感觉是拖了有两年了。
然后晚上又开始尝试写听课记录了,但是还是写的内容巨少。没意识到讲课内容原来这么多。
Day 7
上午听答辩。zak 的还是有点牛逼,听 dzd 的各种提问还是很有趣的。不过最后还是选了 1234。恭喜他们!
下午闭幕式,129 / 169 / 220,压线 Au,有点蚌埠了。220 和 225 的一共有 52 个人,这波区分度有点乐。
反正算是个 Au 吧也!
但是只有证书,没有实体牌子。瞬间难过了很多,算了证书也是奖吧。
颓一晚上,没啥可写的了。
好久没出门过这么久了,感觉很神奇。而且好久没有长假了!!!!11
😄
Day 8
但是走的时候发现我的五个牌子丢了啊啊啊啊啊啊啊啊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号