

学习心得2
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzzcxy/2023learning/join?id=CfDJ8GXQNXLgcs5PrnWvMs4xAGN4cHWWqRMNY7CzDMC-49n8j6IT5cvnqlNnraGz8DcrOqn-fXMeSpaDh0WIee4yugqdL61BJHDL1Z-a4vWfuJ_CihGI0X8a5N7Rpt4wdFZulRz3TTPpWObxybVRSx_CKj0 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/2023learning/homework/12899 |
| 这个作业的目标 | 记录下我认为以后可以用的东西,以及此前接触过,但没深入了解过的东西,用自己的语言解释一遍 |
个人GitHub链接:https://github.com/apeiriaDolce
学习心得:
操作系统:手动缩进.jpg
调度:将某一个执行缓慢的程序暂时休眠(如打印机),先执行其他程序,直到程序执行完成被标记为可执行状态,等到某个时刻交给CPU继续处理




TCP如何确保数据不损坏: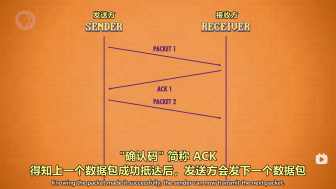
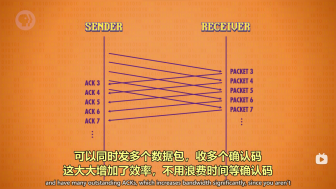
有关域名:网址通过DNS来转换成对应的IP地址。
DNS:采用树状结构储存网址:
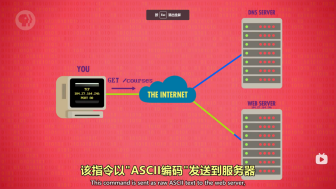
HTTP:状态码400~499代表客户端出错
HTML示例:
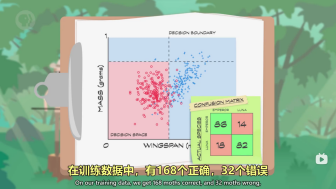
红蓝线为决策边界,
机器学习的目的:最大化正确分类+最小化错误分类。
决策树: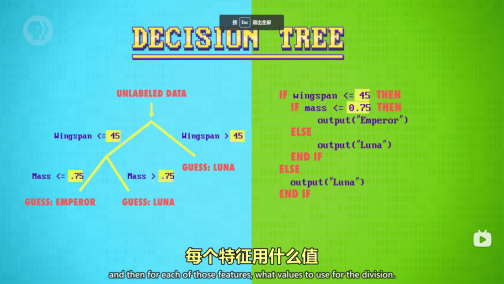
三维决策边界:
人工神经网络: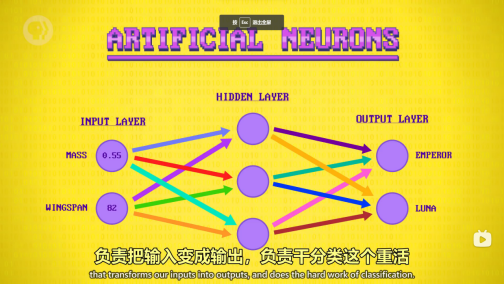
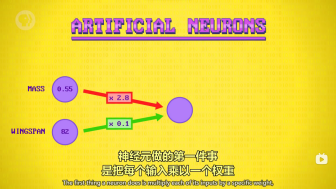
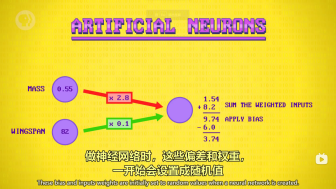
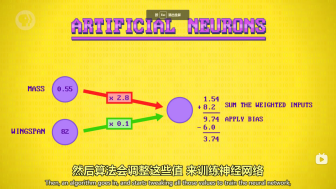 用标记数据来训练测试,逐渐提供准确性。
用标记数据来训练测试,逐渐提供准确性。
激活函数: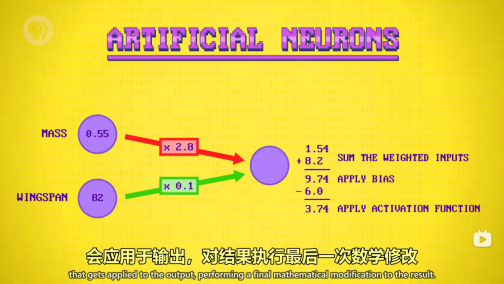
深度学习: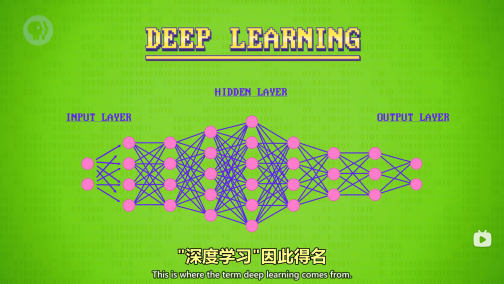
计算机视觉: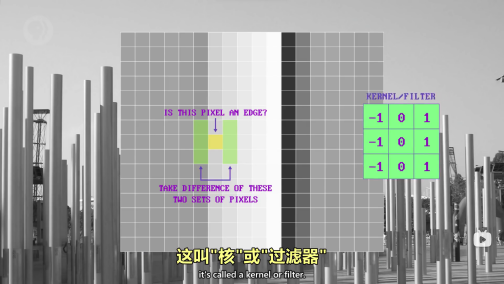


色差很小,不是边缘

卷积神经网络:
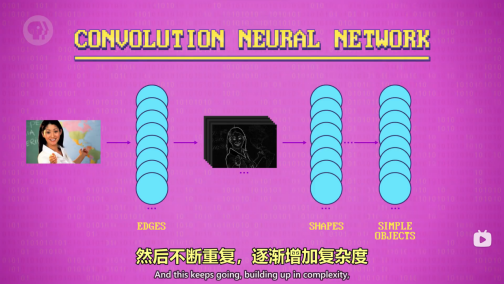
之前的学习:
AI通过学习之后,将每一个事物变成点存在于空间中的某处,当一个未知的事物加入模型时,AI会通过判断对方的特征和此前事物的特征进行对比,拉动未知的数据移动。
这种学习方式导致了通过足够的学习,相关事物所形成的点一般都是紧密连在一起的,比如苹果就一定会在苹果树旁边。
比如加入模型的东西是鱼,鱼的特点是生活在海里,在空间中它就会被先拉向海洋的位置,接着AI在判断其他特征,最终点的位置和鱼最接近,AI判断:点是鱼。
前段时间大火的绘图AI也是同理,将图片变成一块块极小的色块,再通过画师的作品进行学习,得出这些点,用户在使用的时候,描述出想要的东西,AI就会通过这些东西的特征筛选出对应的点,得出大色块,在一步步细化色块,最后色块组成图片(原理是这样,但实现的过程还有很多难点,比如人物和环境的边缘色块怎么处理)。
由此延伸的弊端:
1.容易混合:假定AI中已经学习1,2,3,4,5这五个数据,用户想要5的话,AI会判断1和2相比2更接近5,2和3相比3更接近5,最终得出5.但如果用户同时想要1和5,由于最终输出结果只能有一个,AI容易混在一起,得出3.所以当前的绘图AI不会画手和面,会和人体的皮肤混在一起来制作色块,导致手部崩坏。
2.短期:AI绘图的方式是拉动点进行移动,有时候鱼的点并不会跑到鱼旁边,有可能因为缺失了什么特征,跑到了螃蟹旁边,导致出来的色块不一样,所以用户即使用同样的描述去生成图片,也会得出不同的结果,假定用户想要用它制作立绘,那么就会出现几张立绘人物长得不一样的问题,当然,可以再次将图片投入AI,通过降低噪声强度的方式去减少差分,但还面临着一个新问题,如果人物的服装不同,生成出来的立绘也会长得不一样,因为服装也是点,点的位置不同可以会让AI将新的点拉入制作中,他们圈内称这种情况为:隐藏tag。
再简化一点:假如AI中有0~9这10个数字,用户想要1,2,3,4,5这五组连续且顺序固定的数字时,AI很难得出用户想要的结果,不仅是因为1,2,3,4,5这组数字在空间中的位置差不多,会相互影响,而且AI是不知道用户想要的1和2这两个数字只差1的,它要学习后才知道,现在把数字上升到图片思考,用户得出了“1”的立绘,接着用户想为这个立绘换服装或者姿势,也就是2,用户并不希望改变脸部和身材,也就是两张图片的区别应该是服装或者姿势(1和2只差1),但AI并不知道,很可能到最后服装和脸一起变了,假设为3吧,如果只有5张图片,那么或许可以用不断的跑图来解决问题,但如果是一万张呢,比如制作动画,AI就很难实现了。
寒假的学习成果:利用Blender建模,然后制作动画,通过降低噪声强度的方式去生成2d动画,我在寒假实验之后发现确实可行,只要批量处理每一帧的图片,就能生成效果极好的舞蹈动画,可惜环境方面有一点点极小的色块区别(只看图片看不出来,但看动画就看得出来),要处理只能接着降低噪声强度,但治标不治本,目前还在探索方法。
(随便说说,不过是一些小打小闹的东西而已,博君一乐.>_>.)
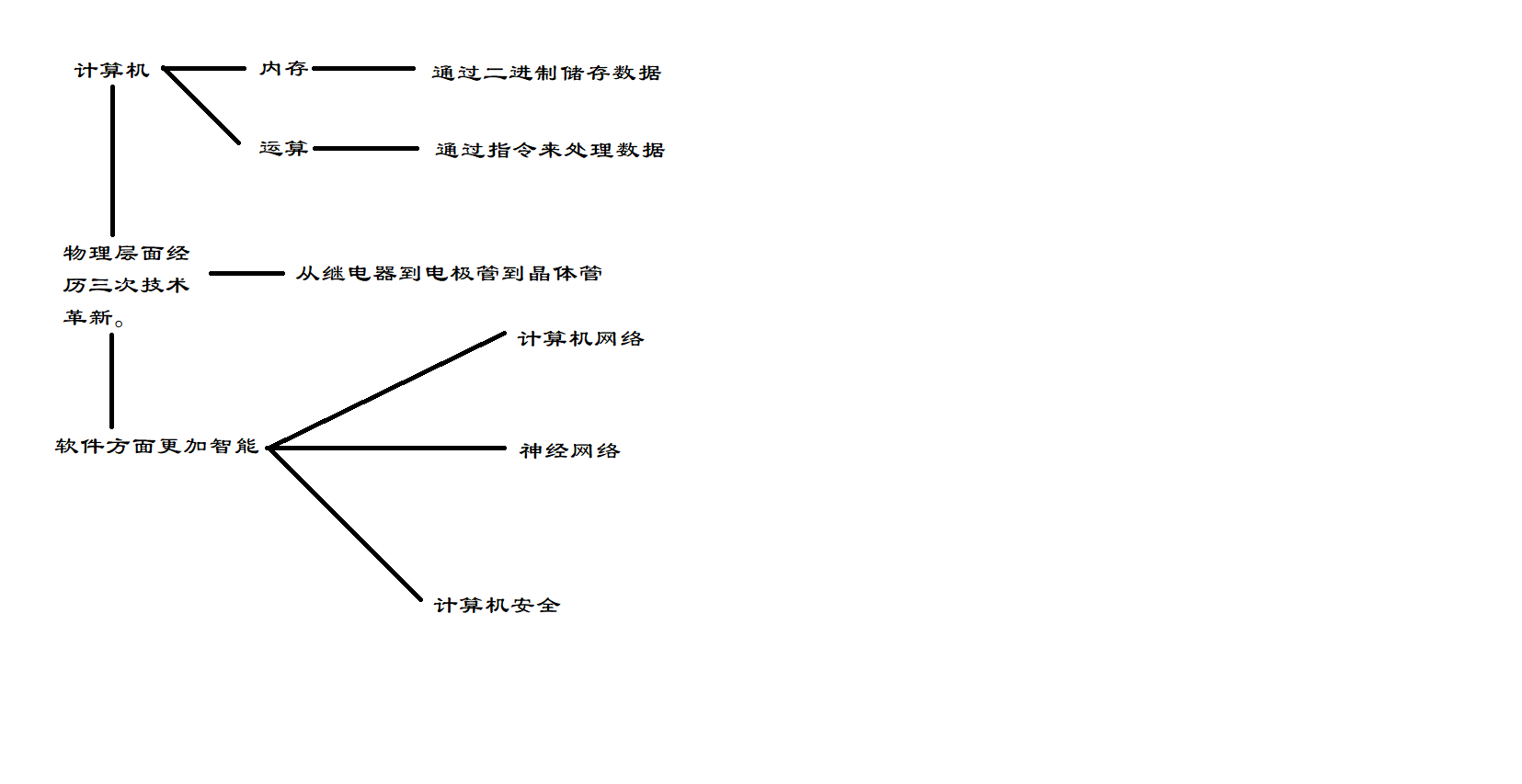
思维导图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号