
kafka 第一次小整理(草稿篇)————演变[二]
前言
简单整理一些kafka的设计。
正文
前文提及到log 的重要性,以及kafka在其中的作用,起着一个日志管理分发的作用,对于其他服务来说相当于新闻报社,订阅某种主题就会收到某类信息。
当人们意识到事件状态的重要性的时候,当时还没有日志管理系统,可能像下面这样:

他们各自传递着各自的事件状态给需要的服务,有点乱且难以维护。
于是为了给他们解耦,就出现了下面这样的:
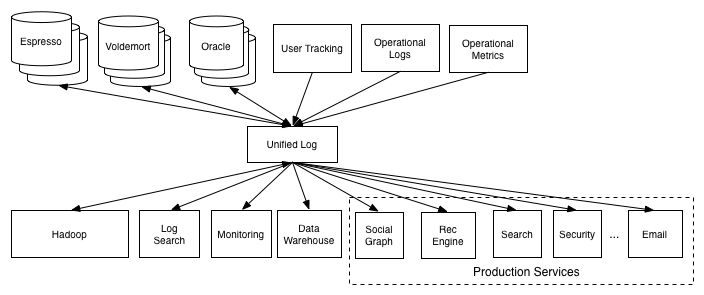
这种模式解决了日志分发问题。
这种模式的出现是否解决了各种服务之间日志的共享。
现在日志和数据库似乎没有什么关联了,也就是事件状态的出现满足了新的需求,并没有和事物的状态有什么影响,似乎这两者在并行的发展。
在事物状态历史发展中,出现了一种东西叫做也就是数据仓库。
通过清洗业务仓库里面的东西来进行对聚合整理,这个清洗过程叫做etl,也就是extract-transform-load.
顾明思议哈,收集、转换、加载。
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个环节。
这东西有什么作用呢,比如说,要查询进一个月每天的订单,如果直接这样查的话,一个是数据库语句难写,有人可能会问怎么就难写哈,不就是group by 聚合吗,但是还有一个问题那就可能有一天没有订单哈。
第二个问题就是性能消耗大,假如订单多的话,做group by 也是很损耗的。 elk 可以做一些简单的工作,比如说每天统计一次订单数量,然后查询的时候复杂度就很低了,现在的数据库设计更偏向于设计更加简单的数据表,而不是写复杂的语句,语句写的复杂更多的可能是数据库设计问题。
数据仓库对于分析很有作用。但是传统的数据仓库有一个问题,那就是一般清洗过程是定时去业务数据库里面取数据哈。
且不从技术层面上考虑性能问题, 有一个问题就是时效性,也就是说无法对现有的数据进行监控。
然后还有另外一个问题,似乎数据仓库是一个独立的服务了,和其他服务脱钩了,取数据也是直接面向数据库,处理的结果也无法反馈到其他服务中去。
数据仓库服务,似乎成了业务孤岛。那么怎么协调他们呢,日志系统去协调他们。
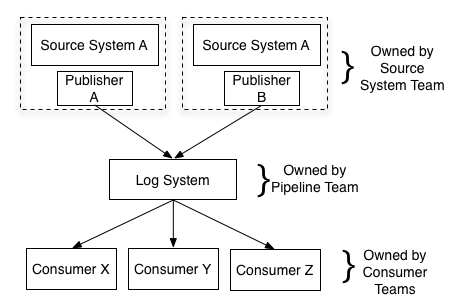
各自的服务发送各自的事件进入日志系统,elk 订阅这些进入到数据仓库中,数据仓库又反馈给自动化营销服务中。
这也对服务提出了新的需求了,也就是数据的发布者。 比如说用户的退款,那么产生的事件里面有: 订单id 用户id 退款时间,这样似乎就能对这件事情的状态有了描述了。
但是更多的是在发布的时候就进行了清洗,里面的事件里面有: 订单id 用户id 订单金额 退款金额 退款商品 退款数量 退款时间等(什么人在什么地点干了一件什么事) 这些清洗好的数据,这样elk 的负担相对小很多,如果需要查询商品的退款情况,就很明白了。
而对于市场服务的性能上也没有很大的问题,因为在退款上本来就要查询订单,顺便清洗。对于扩展性,如果有新的服务,那么可以定义新的数据模型发布即可。
这些也就是事件驱动了,事件驱动是指在持续事务管理过程中,进行决策的一种策略,即跟随当前时间点上出现的事件,调动可用资源,执行相关任务,使不断出现的问题得以解决,防止事务堆积。在计算机编程、公共关系、经济活动等领域均有应用。
事件驱动达到了很好的解耦的目的,比如说商家订单支付完,然后要进行骑手送餐,市场服务只需要完成自己的事情即可,然后发送事件到kafka即可。
那么对于日志业务的可扩展性,kafka 是能满足的。
需求基本满足了,通过这种日志的订阅发布是可以达到需求的。
那么就开始考虑到实际情况,各个服务的日志是很庞大的,那么是否kafka能满足呢?
最简单的一个问题,就是生产和消费的速度很有可能不一致。很有可能就是生产要大于消费,可能远大于。
毕竟生产没啥业务逻辑,消费的时候可能就要复杂的业务逻辑了。
故而kafka 一个主题可以有多个分区:
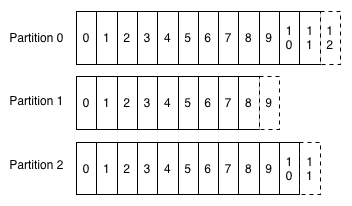
且每个分区的消费都是顺序的。
后来又出现了流处理,那么什么是流处理呢?
上面介绍了,有了日志系统后将数仓业务和线上业务打通了,业务服务有也承担着一部分清洗功能。
但是面对着大量的数据,可能就处理不过来,有hadoop 这种这种是批处理程序,但是无法到达实时。
比如说可能能达到这个用户几天没有续费,然后发个问卷调查,但是无法达到下面这种。
达不到用户如果连输输了15把,给一张优惠券的目的,用户赢了10把,匹配更强对手的战略营销。
尤其是赢了10把,下一把匹配更强了,这就需要计算实效非常高。
为啥有专门的流处理呢? 自己写个服务进行处理不是也挺好吗。其实自己写服务达到流处理,也是可以的呀,但是可能面对数据太大,撑不住啊,但是只能说人家更专业,在低延迟、高吞吐、结果和准确性和良好的容错性上。
然而最关键的不是处理能力问题,而是流式处理是一门学问。
那么为什么hadoop 一开始不做成这种流式的呢? 是不是当时就没有这个需求呢。 肯定是有需求的,不然后面也不会出现流处理。那到底是什么问题呢?仅仅是处理能力的问题吗? 这就是流式的学问了。
结
下一节正式kafka 整理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号