

算法常识——冒泡排序
前言
冒泡排序是一种通用的算法,凡是通用的,可以理解为效率不高,但是通用。
code
从小到大的排序:
static void Main(string[] args)
{
int[] intarr = new int[] {1,6,8,2,3,5,10,48,9 };
sort(intarr);
foreach(var i in intarr)
{
Console.Write(i+"\n");
}
Console.ReadKey();
}
public static void sort(int[] arr)
{
var temp = 0;
var hasSore = true;
for(var i=0;i<arr.Length-1;i++)
{
for (var j=0;j<arr.Length-1-i;j++)
{
if (arr[j] > arr[j + 1])
{
temp = arr[j+1];
arr[j + 1] = arr[j];
arr[j] = temp;
hasSore = false;
}
}
if (hasSore)
{
break;
}
}
}
这里面稍微有点难以理解的地方是如何一开始就确认:
i<arr.Length-1
j<arr.Length-1-i
先来看下冒泡排序的过程。
首先要确认i,j的意思是什么?
在这里我把i变量认为是已经排好的个数,在这里需要确定排序arr.length-1个数,最后一个不需要确认。所以i的范围为0-arr.length-2
j 是该次需要多少元素排好一个元素。
1.第一步需要确认最后一个元素是最大值。
也就是说需要比较的是全部。因为j,所以比较范围是0到arr.length-1,那么j的范围是0到 arr.length-2
2.第二步需要确定倒数第二大元素是多少。
j的比较范围是0到arr.length-2,那么j的范围是0到arr.length-3,也就是确认一个后j的一个范围就不需要确认(可以解释数组缩短了),也就是 arr.length-1-i
为什么hasSore为true的时候可以break呢?因为如果顺序没有变化,那么其实已经排好了。
其实几乎达不到i=arr.length-2的情况,为何这么说呢?每循环一次,其实已经在排序了,把冒泡排序的时间排序归纳为o(n^2),也是不正确的。
继续优化
class Program
{
static void Main(string[] args)
{
int[] intarr = new int[] {1,6,8,2,3,5,10,48,9 };
sort(intarr);
foreach(var i in intarr)
{
Console.Write(i+"\n");
}
Console.ReadKey();
}
public static void sort(int[] arr)
{
var temp = 0;
var hasSore = true;
var sortEnd = arr.Length - 1;
for (var i=0;i<arr.Length-1;i++)
{
for (var j=0;j< sortEnd; j++)
{
if (arr[j] > arr[j + 1])
{
temp = arr[j+1];
arr[j + 1] = arr[j];
arr[j] = temp;
sortEnd = j;
hasSore = false;
}
}
if (hasSore)
{
break;
}
}
}
}
原理:
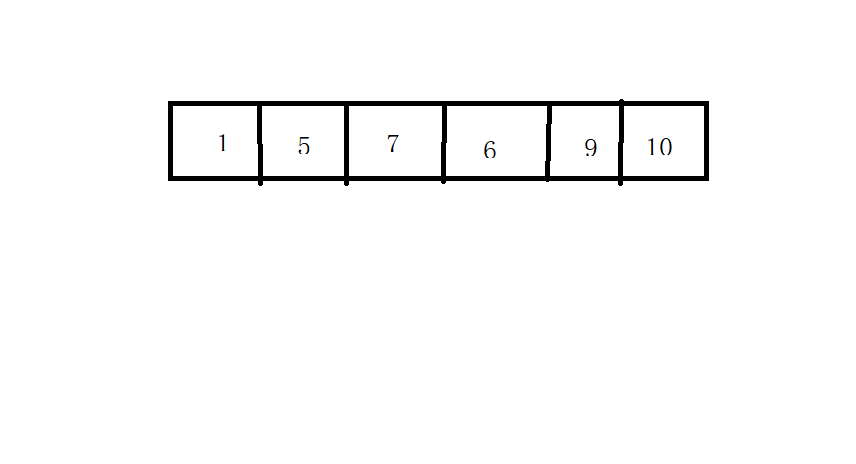
上面我们只要7和6换了位子就可以了,但是计算机可不会这么做。
但是我们知道其实9和10是排好了顺序的。
如何判断到最后一个交换位置的位置,那么就可以肯定后面的位置包括了后面交换的位置是已经判断了的。
就比如说这里:
加入7和6交换了位置,然后7没有和9交换位置,9也没有和10交换位置,那么是不是可以判断6到7到9到10是排序好的?
这里难以理解的是6,为什么6也被排序好了?因为6和7比较排序的时候6肯定是前面的最大值,也就是仅次于7的值。
我们比较的是6,也就是j,那么第二次判断的时候只需要去判断0-(j-1),所以可以向上面那么做。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号