
Scrapy 爬取MT论坛 所有主题帖,原因论坛搜索功能很不好使。爬到本地搜索。
在spiders下创建mt.py 写入:
import scrapy class itemSpider(scrapy.Spider): name = 'mt' start_urls = ['https://bbs.binmt.cc/forum.php'] def parse(self, response): urls1 = response.xpath('//*[@class="comiis_fl_g"]/dl/dt/a//text()').extract() urls2 = response.xpath('//*[@class="comiis_fl_g"]/dl/dt/a//@href').extract() for i in urls1: with open('D:\Study\pythonProject\scrapy\paqu_mt_luntan\mt_luntan\mt\{}.txt'.format(i),'a',encoding='utf-8') as f: f.write(i) #print(urls1) #print(urls2) for i in urls2: yield scrapy.Request(i, callback=self.fenlei) def fenlei(self,response): zhuban = response.xpath('//*[@class="comiis_infotit cl"]/h1/a//text()').extract_first() zhuti = response.xpath('//*[@class="comiis_postlist cl"]/h2/span/a[2]//text()').extract() dizhi = response.xpath('//*[@class="comiis_postlist cl"]/h2/span/a[2]//@href').extract() #print(zhuti) with open('D:\Study\pythonProject\scrapy\paqu_mt_luntan\mt_luntan\mt\{}.txt'.format(zhuban),'a',encoding='utf-8') as f: for i in range(len(zhuti)): f.write(zhuti[i]+','+dizhi[i]) f.write('\n') #print(zhuban) for i in range(10,100): next_page1 = response.xpath('//*[@id="fd_page_bottom"]/div/a[{}]//@href'.format(i)).extract_first() next_page1_biaoti = response.xpath('//*[@id="fd_page_bottom"]/div/a[{}]//text()'.format(i)).extract_first() # print(next_page1) #next_page2 = response.xpath('//*[@id="fd_page_bottom"]/div/a[12]//@href').extract_first() #next_page2_biaoti = response.xpath('//*[@id="fd_page_bottom"]/div/a[12]//text()').extract_first() if next_page1_biaoti == '下一页': next_page1 = response.urljoin(next_page1) yield scrapy.Request(next_page1, callback=self.fenlei) break #elif next_page2_biaoti == '下一页': #next_page2 = response.urljoin(next_page2) #yield scrapy.Request(next_page2, callback=self.fenlei) else: print('结束!')
然后在middlewares.py 写入随即请求头:
from fake_useragent import UserAgent class NovelUserAgentMiddleWare(object): #随即user_AGENT def __init__(self): self.t = UserAgent(verify_ssl=False).random def process_request(self, request, spider): ua = self.t print('User-Agent:' + ua) request.headers.setdefault('User-Agent', ua)
然后最后在settings中写入:
ROBOTSTXT_OBEY = False DOWNLOAD_DELAY = 0.25 CONCURRENT_REQUESTS = 100 CONCURRENT_REQUESTS_PER_DOMAIN = 100 CONCURRENT_REQUESTS_PER_IP = 100 COOKIES_ENABLED = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 DOWNLOADER_MIDDLEWARES = { 'mt_luntan.middlewares.NovelUserAgentMiddleWare': 544, #随即user #'ImagesRename.middlewares.NovelProxyMiddleWare': 543,#随即IP ImagesRename 换成自己的 }
加入延迟,太快容易出现抓去到的文字乱码。
最后看下结果:
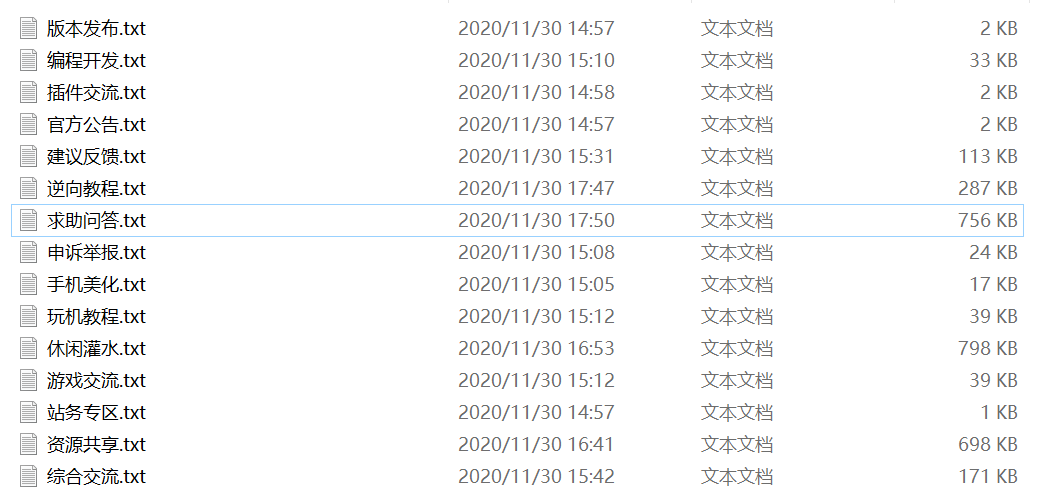
自己搜索想看的帖子,在后面复制地址就可以直达看了。
如果人生还有重来,那就不叫人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号