
Django基础知识(1)
Django基础知识
1.url路由系统
URL是web服务的入口,用户通过浏览器发送过来的任何请求,都是发送到一个指定的URL地址,然后服务器会将响应返回给浏览器。路由就是用来处理URL和函数之间关系的调度器。
Django的路由流程如下:
- 查找全局urlpatterns变量,即blog/urls.py文件中定义的urlpatterns变量。
- 按照先后顺序查找,对URL逐一匹配utlpatterns列表中的每个元素。(查找是遵循轮询机制)
- 找到第一个匹配时停止查找,根据匹配结果执行对应的处理函数。
- 如果没有找到匹配或者出现异常,Django进行错误处理。
1.1Django的路由形式
1.精确字符串格式
一个精确URL匹配 一个操作函数;最简单的形式,适合对静态URL的响应;URL字符串不以“/”开头,但是要以“/”结尾
path('admin/', admin.site.urls),
path('index/', views.index),
2.路径转换器格式
通常情况下,在匹配URL同时,通过URL进行参数获取和传递。格式如下:
<类型:变量名>,articles/<int:year/>/
例如:
path('articles/<int:year>/',views.year_archive),
path('articles/<int:year>/<int:month>/',views.mouth_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/',views.articles_detail),
格式转换类型以及说明:
| 类型 | 说明 |
|---|---|
| str | 匹配除分割符(/)以外的非空字符串,默认形式 |
| int | 匹配0和正整数 |
| slug | 匹配字母、数字、横杠、下划线、组成的字符串, str的子集 |
| uuid | 匹配格式化的UUID, 如075194d3-6554-456e-a4d5-6a584a684f00 |
| path | 匹配任何非空字符串,包括路径分隔符,是全集 |
3.正则表达式格式
- 命名分组
如果路径和转换器语法不能很好地定义URL模式,也可以使用正则表达式。使用表达式定义路由时,需要使用re_path()而不是path()。
在python表达式中,命名正则表达式的语法格式如下:
(?P<name>pattern),其中name是组的名称,pattern是要匹配的模式。
from django.urls import path, re_path
from . import views
urlpatterns = [
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),#某年的,(?P<year>[0-9]{4})这是命名参数(正则命名匹配还记得吗?),那么函数year_archive(request,year),形参名称必须是year这个名字。而且注意如果你这个正则后面没有写$符号,即便是输入了月份路径,也会被它拦截下拉,因为它的正则也能匹配上
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),#某年某月的
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail), #某年某月某日的
]
- views配置:
def year_article(request, year=2000):
print(year)
return HttpResponse(f'出版年限:{year}')
def year_mouth_article(request, year, mouth):
print(year, mouth)
return HttpResponse(f'出版年限:{year},出版月份:{mouth}')
def year_mouth_day_article(request, year, mouth, day):
print(year, mouth, day)
return HttpResponse(f'出版年限:{year},出版月份:{mouth},出版天数:{day}')
- 视图函数中指定默认值:
# urls.py中
from django.urls import path,re_path
from . import views
urlpatterns = [
url(r'^blog/$', views.page),
url(r'^blog/page(?P<num>[0-9]+)/$', views.page),
]
# views.py中,可以为num指定默认值
def page(request, num="1"):
pass
在上面的例子中,两个URL模式指向相同的view - views.page - 但是第一个模式并没有从URL中捕获任何东西。
如果第一个模式匹配上了,page()函数将使用其默认参数num=“1”,如果第二个模式匹配,page()将使用正则表达式捕获到的num值。
**注意: ** 命名分组是url设置的组名对应views函数的参数,这是关键字参数,也可以对应views函数的默认值参数。
- 无名分组
from django.urls import re_path
from django.contrib import admin
from app01 import views
urlpatterns = [
# re_path(r'^admin/', admin.site.urls),
re_path(r'^index/', views.login),
# 无名分组 (给应用视图函数传递位置参数)
re_path(r'books/(\d{4})/', views.year_books), # 不完全匹配
re_path(r'^books/(\d{4})/(\d{2})/', views.year_mouth_books),
re_path(r'^books/(\d{4})/(\d{2})/(\d{2})', views.year_mouth_day_books),
]
此时写的还是有问题的,你此时写的url路由匹配是模糊匹配,你如果是这样写的url,当从浏览器输入127.0.0.1:8000/book/2003/12/08它还是映射到year_books这个函数的,因为url遵循轮询机制:
# 伪代码
url 轮训机制:
for url in urlpatterns:
re.match(r'books/(\\d{4})/', 'books/2003/12/08'),这个是非完全匹配,所以直接映射到year_books这个函数中。
所以针对上面的情况,我们应该将这些URL设定为完全匹配
from django.urls import re_path
from django.contrib import admin
from app01 import views
urlpatterns = [
# re_path(r'^admin/', admin.site.urls),
re_path(r'^index/', views.login),
# 无名分组 (给应用视图函数传递位置参数)
re_path(r'books/(\d{4})/$', views.year_books), # 完全匹配
re_path(r'^books/(\d{4})/(\d{2})/', views.year_mouth_books),
re_path(r'^books/(\d{4})/(\d{2})/(\d{2})', views.year_mouth_day_books),
]
- views配置
def year_article(request, year=2000):
print(year)
return HttpResponse(f'出版年限:{year}')
def year_mouth_article(request, year, mouth):
print(year, mouth)
return HttpResponse(f'出版年限:{year},出版月份:{mouth}')
def year_mouth_day_article(request, year, mouth, day):
print(year, mouth, day)
return HttpResponse(f'出版年限:{year},出版月份:{mouth},出版天数:{day}')
注意:****无名分组传递给views函数的为位置参数。
注意事项
- urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续。
- 若要从URL中捕获一个值,只需要在它周围放置一对圆括号(分组匹配)。
- 不需要添加一个前导的反斜杠(也就是写在正则最前面的那个/),因为每个URL 都有。例如,应该是^books而不是 ^/books。
- 每个正则表达式前面的'r' 是可选的但是建议加上。
- ^books& 以什么结尾,以什么开头,严格限制路径。
1.2.include包含路由
1)新建一个项目:然后在项目里新建两个应用,分别命名为app1和app2
python manage.py startapp app01
python manage.py startapp app02
2)然后找到你项目的settings文件,将app01 和 app02应用配置到项目中:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config', # 这个是开启项目时 pycharm自动给你配置的
'app02.apps.App02Config', # 这个是需要我们自己手动配置的
# 'app02', 也可以简单设置与上一行相同
]
找到app02应用按照图示添加上此配置:

整个项目的url是写在项目的目录下了,但是不同应用有不同的views,这样url如何分发给不同的应用呢?

这样就需要将项目的url分出去,每个应用创建自己的urls。
配置不同应用的url:
app01:urls
from django.urls import re_path
from django.contrib import admin
from app01 import views
urlpatterns = [
# re_path(r'^admin/', admin.site.urls),
re_path(r'^$',views.home), # 完全匹配之后,访问127.0.0.1:8000/app01/就可以映射到app01的views里面的home函数
]
app02:urls
from django.urls import re_path
from django.contrib import admin
from app01 import views
urlpatterns = [
# re_path(r'^admin/', admin.site.urls),
re_path(r'^$',views.home), # 完全匹配之后,访问127.0.0.1:8000/app02/就可以映射到app02的views里面的home函数
]
app01、app02的url都已经配置好了,如何从项目中的urls分别映射到两个appurls中呢?这就得需要在项目重的urls.py引入includs功能了。我们先引入app01应用。
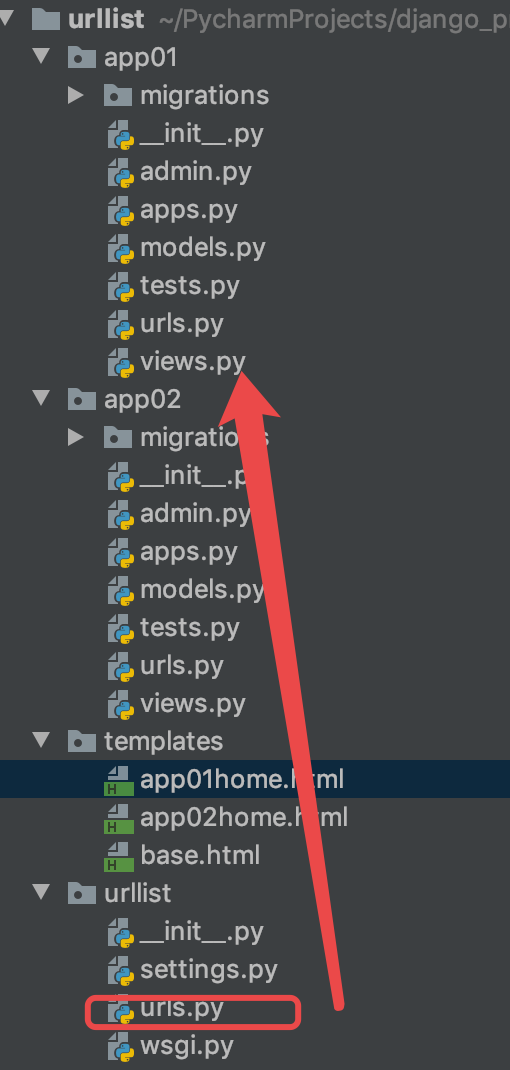
urllist:urls
urlpatterns = [
# re_path(r'^admin/', admin.site.urls),
# 输入不同的url找到不同的app 分发给不同的应用的urls.py
re_path(r'^app01/', include('app01.urls')),
re_path(r'^app02/', include('app02.urls')),
]
这样配置,就相当例如输入:127.0.0.1:8000:app01/index,他会先找到127.0.0.1:8000:app01/ 匹配上app01/之后,进入app01的urls再去匹配对应的index/路径。
配置不同的views函数
app01 app02 views函数基本一致:
# app01
def home(request):
return render(request, 'app01home.html')
# app02
def home(request):
return render(request, 'app02home.html')
配置不同的html
app01 app02 html基本一致:
# app01
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap 101 Template</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<h1>app01 首页</h1>
</body>
</html>
# app02
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap 101 Template</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<h1>app02 首页</h1>
</body>
</html>
1.3额外补充
有的时候我们浏览一些网站,我们会发现直接访问网站就会返回一个首页,这个也称为整个项目的首页,比如你访问京东:
然后通过这个首页可以各种链接到其他的也写分页的主页。那么这个是如何实现的呢?通过我们的目录结构我们可以得知,主项目是没有views文件的,我们应该将整个项目的首页逻辑放置在一个app中,这样就可以实现了。
urllist的urls:
urlpatterns = [
# url(r'^admin/', admin.site.urls),
# 项目首页 放置app01应用中
re_path(r'^$', views.base),
# 输入不同的url找到不同的app 分发给不同的应用的urls.py
re_path(r'^app01/', include('app01.urls')),
re_path(r'^app02/', include('app02.urls')),
]
'''
如果你设置的是
re_path(r'', views.base),
根据不完全匹配原则,你访问的app01或者app02都会先匹配上整个项目的首页,就不会映射到对应的函数中了
'''
app01的views函数:
def base(request):
return render(request, 'base.html')
templates的html:
增加一个base.html页面。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap 101 Template</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<h1>整个项目首页</h1>
<a href="/app01/">跳转app01首页</a>
<a href="/app02/">跳转app02首页</a>
</body>
</html>
2.Django的视图函数views
一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求(request)并且返回Web响应(HttpResponse)。
2.1一个简单的视图
下面是一个以HTML文档的形式返回当前日期和时间的视图:
from django.http import HttpResponse
import datetime
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
让我们来逐行解释下上面的代码:
-
首先,我们从
django.http模块导入了HttpResponse类,以及Python的datetime库。 -
接着,我们定义了
current_datetime函数。它就是视图函数。每个视图函数都使用HttpRequest对象作为第一个参数,并且通常称之为request。注意,视图函数的名称并不重要;不需要用一个统一的命名方式来命名,以便让Django识别它。我们将其命名为
current_datetime,是因为这个名称能够比较准确地反映出它实现的功能。 -
这个视图会返回一个
HttpResponse对象,其中包含生成的响应。每个视图函数都负责返回一个HttpResponse对象。
Django使用请求和响应对象来通过系统传递状态。
当浏览器向服务端请求一个页面时,Django创建一个HttpRequest对象,该对象包含关于请求的元数据。然后,Django加载相应的视图,将这个HttpRequest对象作为第一个参数传递给视图函数。
每个视图负责返回一个HttpResponse对象。

视图层,熟练掌握两个对象即可:请求对象(request)和响应对象(HttpResponse)。
2.2请求对象request
当一个页面被请求时,Django就会创建一个包含本次请求原信息(请求报文中的请求行、首部信息、内容主体等)的HttpRequest对象。Django会将这个对象自动传递给响应的视图函数,一般视图函数约定俗成地使用 request 参数承接这个对象。
请求相关的常用值
-
path_info 返回用户访问url,不包括域名
-
method 请求中使用的HTTP方法的字符串表示,全大写表示。
-
GET 包含所有HTTP GET参数的类字典对象
-
POST 包含所有HTTP POST参数的类字典对象
-
body 请求体,byte类型 request.POST的数据就是从body里面提取到的
from django.shortcuts import render,HttpResponse,redirect
# Create your views here.
def index(request):
print(request.method) #请求方式
print(request.path) #请求路径,不带参数的
print(request.POST) #post请求数据 字典格式
print(request.GET) #get的请求数据 字典格式
print(request.META) #请求头信息
print(request.get_full_path()) #获取请求路径带参数的,/index/?a=1
print(request.is_ajax()) #判断是不是ajax发送的请求,True和False
'''
Django一定最后会响应一个HttpResponse的示例对象
三种形式:
HttpResponse('字符串') 最简单
render(页面) 最重要
2.1 两个功能
-- 读取文件字符串
-- 嵌入变量(模板渲染) html里面:{{ name }} , {'name':'太白'}作为render的第三个参数,想写多个变量{'name':'太白','hobby':['篮球','羽毛球']....}
redirect() 重定向 最难理解,某个网站搬家了,网址变了,访问原来的网址就重定向到一个新网址,就叫做重定向,网站自己做的重定向,你访问还是访问的你之前的,你自己啥也不用做,浏览器发送请求,然后服务端响应,然后服务端告诉浏览器,你直接跳转到另外一个网址上,那么浏览器又自动发送了另外一个请求,发送到服务端,服务端返回一个页面,包含两次请求,登陆成功后跳转到网站的首页,网站首页的网址和你login登陆页面的网址是不用的。
'''
return render(request,'index.html',{'name':'太白'})
# return HttpResponse('ok')
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用:
request.POST.getlist("hobby")
2.3响应对象HttpResponse
与由Django自动创建的HttpRequest对象相比,HttpResponse对象是我们的职责范围了。我们写的每个视图都需要实例化,填充和返回一个HttpResponse。
HttpResponse类位于django.http模块中。
简单使用
传递字符串
from django.http import HttpResponse
response = HttpResponse("Here's the text of the Web page.")
response = HttpResponse("Text only, please.", content_type="text/plain")
设置或删除响应头信息
response = HttpResponse()
response['Content-Type'] = 'text/html; charset=UTF-8'
del response['Content-Type']
属性
HttpResponse.content:响应内容
HttpResponse.charset:响应内容的编码
HttpResponse.status_code:响应的状态码
具体响应方法
响应对象主要有三种形式:
- HttpResponse()
- render()
- redirect()
HttpResponse
HttpResponse()括号内直接跟一个具体的字符串作为响应体,比较直接很简单,所以这里主要介绍后面两种形式。
render

结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数:
request: 用于生成响应的请求对象。
template_name:要使用的模板的完整名称,可选的参数
context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
content_type:生成的文档要使用的MIME类型。默认为 DEFAULT_CONTENT_TYPE 设置的值。默认为'text/html'
status:响应的状态码。默认为200。
useing: 用于加载模板的模板引擎的名称
一个简单的例子:
from django.shortcuts import render #用于渲染html界面
def my_view(request):
# 视图的代码写在这里
return render(request, 'myapp/index.html', {'foo': 'bar'})
redirect
你可以用多种方式使用redirect() 函数。
-
1.传递一个具体的ORM对象(了解即可): 将调用具体ORM对象的
get_absolute_url()方法来获取重定向的URL:from django.shortcuts import redirect def my_view(request): ... object = MyModel.objects.get(...) return redirect(object) -
2.传递一个视图的名称
# views 示例def my_view(request):
...
return redirect('home')
def home(request):
return HttpResponse('跳转成功!')
# urls示例:
urlpatterns = [
url(r'home/', views.home, name='home'), # 起别名,这样以后无论url如何变化,访问home直接可以映射到home函数
]
- 3. 传递要重定向到的一个具体的网址
def my_view(request):
...
return redirect('/index')
- 4.当然也可以是一个完整的网址
def my_view(request):
...
return redirect('http://example.com/')
重定向状态码
接下来我们讨论一下这个重定向的状态码301,302。这个两个状态码面试经常问到。
1)301和302的区别。
301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取
(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。
他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;
302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。 SEO302好于301
2)重定向原因:
(1)网站调整(如改变网页目录结构);
(2)网页被移到一个新地址;
(3)网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的
网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
简单来说就是:
响应状态码:301,为临时重定向,旧地址的资源仍然可以访问。
响应状态码:302,为永久重定向,旧地址的资源已经被永久移除了,这个资源不可访问了。
对普通用户来说是没什么区别的,它主要面向的是搜索引擎的机器人。
A页面临时重定向到B页面,那搜索引擎收录的就是A页面。
A页面永久重定向到B页面,那搜索引擎收录的就是B页面。
2.4 FVB和CVB
FBV(function base views) 就是在视图里使用函数处理请求。
-
定义路由。
from django.urls import path from . import views #导入自定义的views模块 urlpatterns = [ path('',views.article_list), path('<int:year>/',views.year_archive) path('<int:year>/<int:month>/',views.month_archive) path('<int:year>/<int:month>/<slug:slug>/',views.article_detail) path('current',views.get_current_datetime) ] -
创建视图函数
from django.http import HttpResponse from datetime import datetime def get_current_datetime(request): #定义一个视图方法,必须带有请求对象作为参数 today = datetime.today() #请求的时间 formatted_today = today.strftime('%Y-%m-%d') html = f"<html><body>今天是{formatted_today}</body></html>" #生成HTML代码 return HttpResponse(html) #将响应对象返回,数据为生成的HTML代码上面的代码定义了一个函数,返回了一个HttpResponse对象,这就是Django的FVB基于函数的视图。每个视图函数都要有一个HttpResponse对象,用来接收来自客户端的请求,并且必须返回一个HttpResponse对象,作为响应发送给客户端。
CBV(class base views) 就是在视图里使用类处理请求。
Python是一个面向对象的编程语言,如果只用函数来开发,有很多面向对象的优点就错失了(继承、封装、多态)。所以Django在后来加入了Class-Based-View。可以让我们用类写View。这样做的优点主要下面两种:
- 提高了代码的复用性,可以使用面向对象的技术,比如Mixin(多继承)
- 可以用不同的函数针对不同的HTTP方法处理,而不是通过很多if判断,提高代码可读性
CBV与FBV在url、views写法上有一些不同,下面有一些细节一定要注意。
views视图函数
from django.shortcuts import render,HttpResponse
from django.views import View # 从django.views模块中引用View类
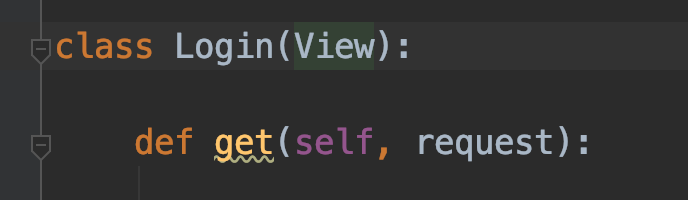
class Login(View):
"""
自己定义get post方法,方法名不能变。这样只要访问此url,get请求自动执行get方法,post请求自动执行post方法,与我们写的FBV
if request.method == 'GET' or 'POST' 一样。
"""
def get(self, request):
return render(request, 'login.html')
def post(self, request):
username = request.POST.get('username')
password = request.POST.get('password')
if username.strip() == 'taibai' and password.strip() == '123':
return HttpResponse('登录成功')
return render(request, 'login.html')
urls路由
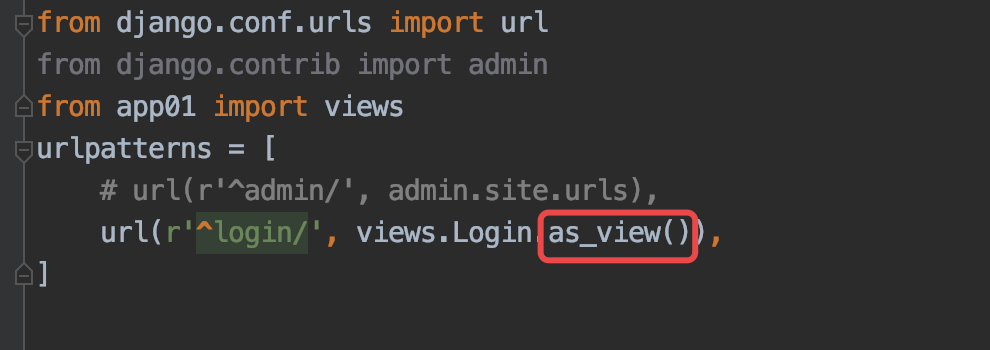
from django.urls import re_path
from django.contrib import admin
from app01 import views
urlpatterns = [
re_path(r'^login/', views.Login.as_view()),
# 引用views函数重的Login类,然后调用父类的as_view()方法
]
CBV传参,和FBV类似,有名分组,无名分组
url写法:无名分组的
re_path(r'^cv/(\d{2})/', views.Myd.as_view(),name='cv'),
re_path(r'^cv/(?P<n>\d{2})/', views.Myd.as_view(name='xxx'),name='cv'),
#如果想给类的name属性赋值,前提你的Myd类里面必须有name属性(类属性,定义init方法来接受属性行不通,但是可以自行研究一下,看看如何行通,意义不大),并且之前类里面的name属性的值会被覆盖掉
templates的html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap 101 Template</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<h1>你好 欢迎来到plus网娱会所,请先登录</h1>
<form action="" method="post">
<input type="text" name="username">
<p></p>
<input type="text" name="password">
<p></p>
<input type="submit">
</form>
</body>
</html>
别忘了settings中间件注释掉。这样启动项目之后,我们就完成了一个简单的登录功能。
补充一个类的写法
类写法:
class Myd(View):
name = 'sb'
def get(self,request,n):
print('get方法执行了')
print('>>>',n)
return render(request,'cvpost.html',{'name':self.name})
def post(self,request,n):
print('post方法被执行了')
return HttpResponse('post')
添加类的属性可以通过两种方法设置,第一种是常见的Python的方法,可以被子类覆盖。
from django.http import HttpResponse
from django.views import View
class GreetingView(View):
name = "yuan"
def get(self, request):
return HttpResponse(self.name)
# You can override that in a subclass
class MorningGreetingView(GreetingView):
name= "alex"
第二种方法,你也可以在url中指定类的属性:
在url中设置类的属性Python
urlpatterns = [
url(r'^index/$', GreetingView.as_view(name="egon")), #类里面必须有name属性,并且会被传进来的这个属性值给覆盖掉
]
执行流程的源码解析
1. 请求发送到这里,先要执行as_view()方法。
views.py里面的Login是一个类,类.方法(),那么这个as_view()方法肯定是静态方法或者类方法,但是我们定义Login类时没有定义这个方法,只能从父类查找,也就是查找源码的View。
2. 执行父类View里面的as_view()方法。
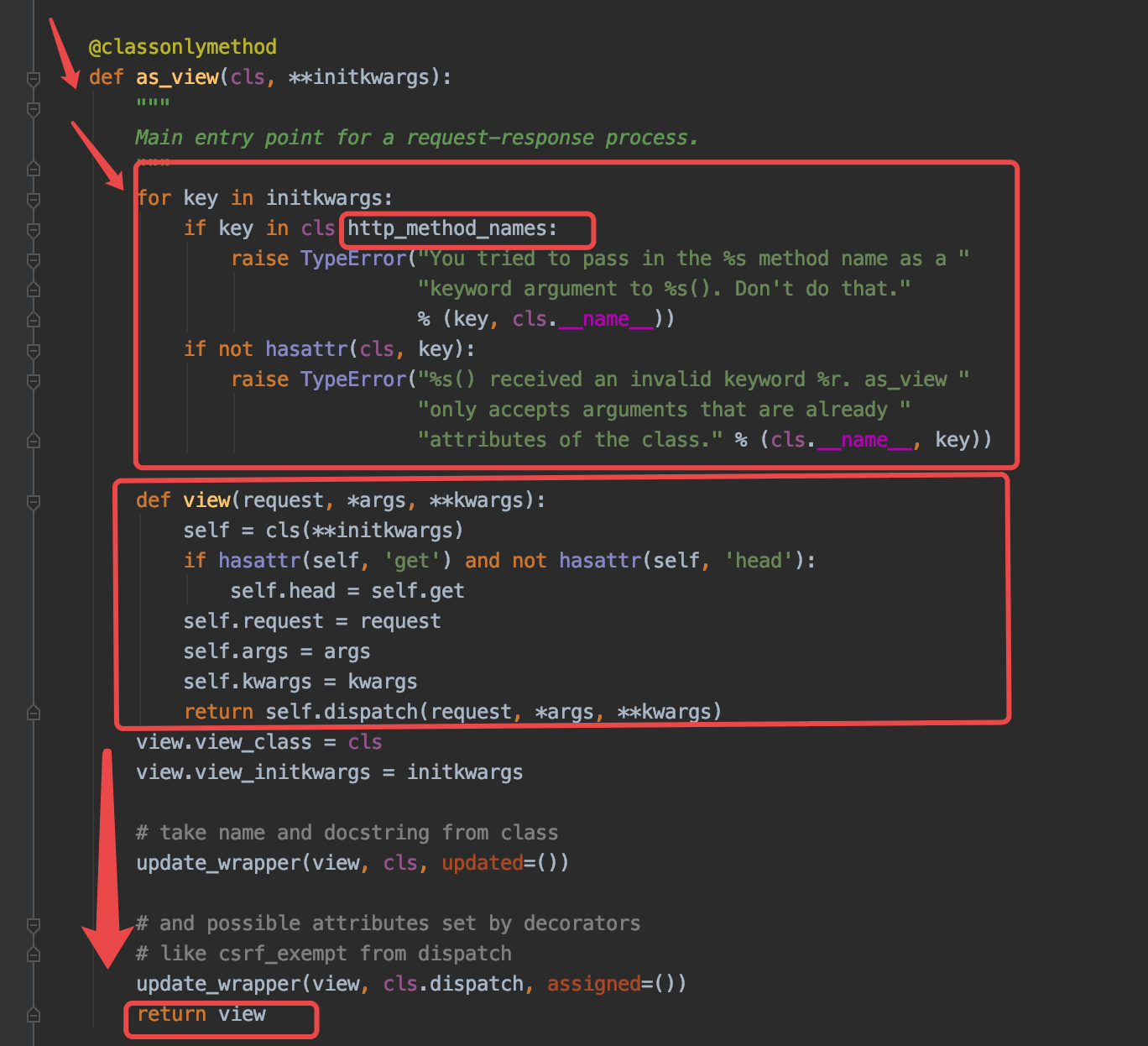
我将部分源码拿来,咱们去分析:
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
第一个框框出来的就是各种主动抛异常,cls肯定就是我们Login类名了,http_method_names从源码中可以获取到是一个列表:
http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
虽然我们现在不知道initkwargs是什么,但是我们可以大概分析出来,如果你的请求方式不是这个列表中的任意一个,我就会给你抛出一个异常。
第二部分是定义了一个view函数,但是现在还没有执行此函数的执行,所以我们直接跳过分析。
第三部分:
view.view_class = cls
view.view_initkwargs = initkwargs
# 上面两行是给函数view封装两个属性:之前我们没有说过函数也可以封装属性,python中一些皆对象,view函数也是一个对象,这个对象是从function类实例化得来的,我通过dir(view)可知,他有'__setattr__'方法,有这个方法,给view封装属性时,就会执行这个方法不报错,那么这个方法就是实现了给一个函数封装一个属性的功能,你可以随意定义一个函数试一试。
view_class = cls cls 也就是Login类
view_initkwargs = initkwargs initkwargs目前我不确定是什么,但是我可以猜到他应该是与请求方式相关的。
# take name and docstring from class
update_wrapper(view, cls, updated=())
# 这里源码给了解释:这个update_wrapper函数就是从类中获取名字和类的描述消息
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
# 这个大概意思就是从装饰器中获取设置的属性,
# 上面这两个函数对我们研究流程来说没有什么影响所以我们可以暂不考虑
这样三部分我们分析完成了,至此源码中的as_view()函数执行完毕,但是千万别忘了,他有个返回值就是此as_view()函数中的view函数地址。其实你自己看一下,as_view函数就是一个闭包。
3. 程序又跳转到url路由
此时url路由就变成了这个样子:
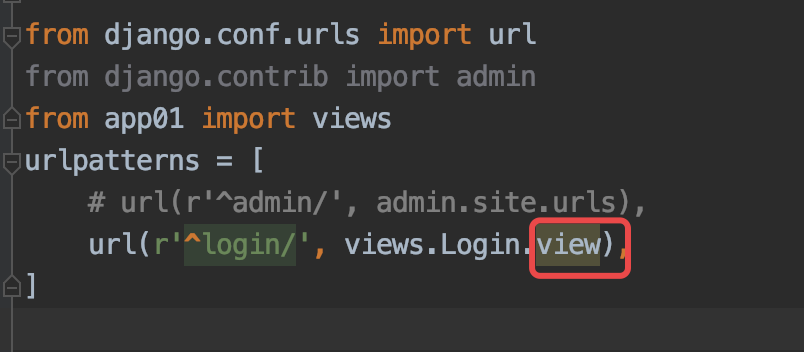
这个我们是不是似曾相识? 我们之前一直写FBV时,你没有过疑问么?当你发送一个请求时,通过url映射到相应的函数,函数是不是就直接执行了???下面是一个FBV模式,对应函数直接就会执行了。
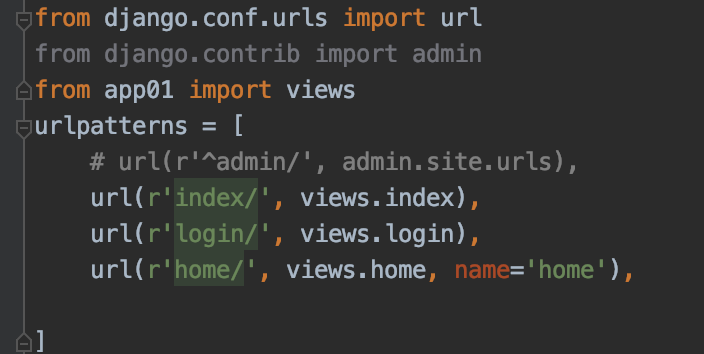
所以!对应的view函数也会自动执行。
4. 执行源码中的view函数
源码中的view函数如下:
def view(request, *args, **kwargs):
self = cls(**initkwargs) # 对Login函数实例化对象为self
if hasattr(self, 'get') and not hasattr(self, 'head'): # 判断self对象是否有get并且没有head方法,条件给self对象设置head属性为self.get
self.head = self.get # 下面给self对象设置三个属性,我们就关注第一个self.request = request,将请求相应相关的内容封装到request属性中
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs) # 最关键的两步:第一步:先执行dispath方法,得到返回值;第二步,在返回给view方法的调用者。
5. 执行源码中dispath方法。
源码中的dispatch函数如下:
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
''' 上面源码给的解释很清楚了,如果请求的方法不存在则执行错误的handler,如果请求的方法正确且存在http_method_names列表中,执行正确的方法。 '''
if request.method.lower() in self.http_method_names:
# self就是自己在views文件中定义的Login类的对象,这里假如是get请求,此请求正确且存在,则执行Login类中的get方法,如果是post请求则执行post方法。
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
# 最后将handler()函数的返回值返回。handler函数是什么?假如我们是get请求,hander()就是我们在Login类中的get(),我们get()是给浏览器返回的html页面,则其实你的页面最终是url这里面返回的。
仔细想想下面的图:
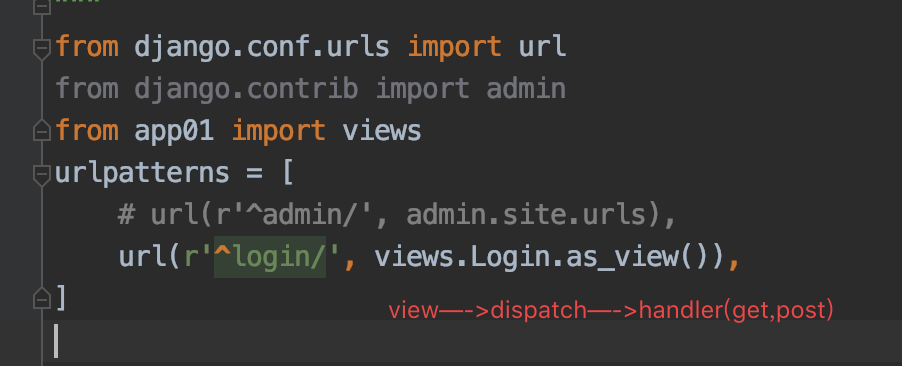
至此,整个流程我们就算较为详细的走完了。
3.Django:模板系统
3.1介绍
什么是模版系统?这里做一个简单解释。要想明白什么是模版系统,那么我们得先分清楚静态页面和动态页面。我们之前学过的都是静态页面,所谓的静态页面就是浏览器向后端发送一个请求,后端接收到这个请求,然后返回给浏览器一个html页面,这个过程不涉及从数据库取出数据渲染到html页面上,只是单纯的返回一个页面(数据全部在html页面上)。而动态页面就是在给浏览器返回html页面之前,需要后端与数据库之间进行数据交互,然后将数据渲染到html页面上在返回给浏览器。言外之意静态页面不涉及数据库,动态页面需要涉及从数据库取出数据。那么模版系统是什么呢?如果你只是单纯的写静态页面,也就没必有必要用模版系统了,只用动态页面才需要模版系统。
简单来说,模版系统就是在html页面想要展示的数据库或者后端的数据的标签上做上特殊的占位(类似于格式化输出),通过render方法将这些占位的标签里面的数据替换成你想替换的数据,然后再将替换数据之后的html页面返回给浏览器,这个就是模版系统。
模板渲染的官方文档
关于模板渲染你只需要记两种特殊符号(语法):
{{ }}和 {% %}
变量相关的用{{}},逻辑相关的用{%%}。
3.2变量
接下来,我们先搭一个简单流程:浏览器访问https://127.0.0.1:8000:/index,返回一个index.html页面,我们在views函数中设置一些变量,然后通过模版系统渲染,最终返回给浏览器。
url
"""djangoProject1 URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/4.0/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path, re_path
from . import views
urlpatterns = [
# path('admin/', admin.site.urls),
re_path(r'^index/', views.index),
]
views
render第三个参数接受一个字典的形式,通过字典的键值对index.html页面进行渲染,这也就是模块渲染。
"""
@name : views
@author : wangaokang
@projectname: djangoProject1
"""
from django.http import HttpResponse
from django.shortcuts import render
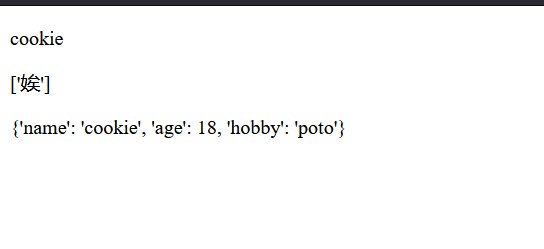
def index(request):
num = 100
name = 'cookie'
namelist = ['娭']
d1 = {'name':'cookie', 'age':18, 'hobby':'poto'}
return render(request, 'index.html',{'nmu':num, 'name':name, 'namelist':namelist, 'd1':d1})

index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{# 通过render进行模版语言渲染然后替换成后端的数据,最终发给浏览器 #}
<p> {{ num }}</p>
<p> {{ name }}</p>
<p> {{ namelist }}</p>
<p> {{ d1 }}</p>
</body>
</html>
效果
3.3 语法
在Django的模板语言中(变量)按此语法使用:{{ 变量名 }}。
当模版引擎遇到一个变量,它将计算这个变量,然后用结果替换掉它本身。 变量的命名包括任何字母数字以及下划线 ("_")的组合。 变量名称中不能有空格或标点符号。
3.4 万能的点 .
通过简单示例我们已经知道模版系统对于变量的渲染是如何做到的,非常简单,接下来我们研究一些深入的渲染,我们不想将整个列表或者字典渲染到html,而是将列表里面的元素、或者字典的某个值渲染到html页面中,那怎么做呢?就是通过万能的点。
views:
"""
@name : views
@author : wangaokang
@projectname: djangoProject1
"""
from django.http import HttpResponse
from django.shortcuts import render
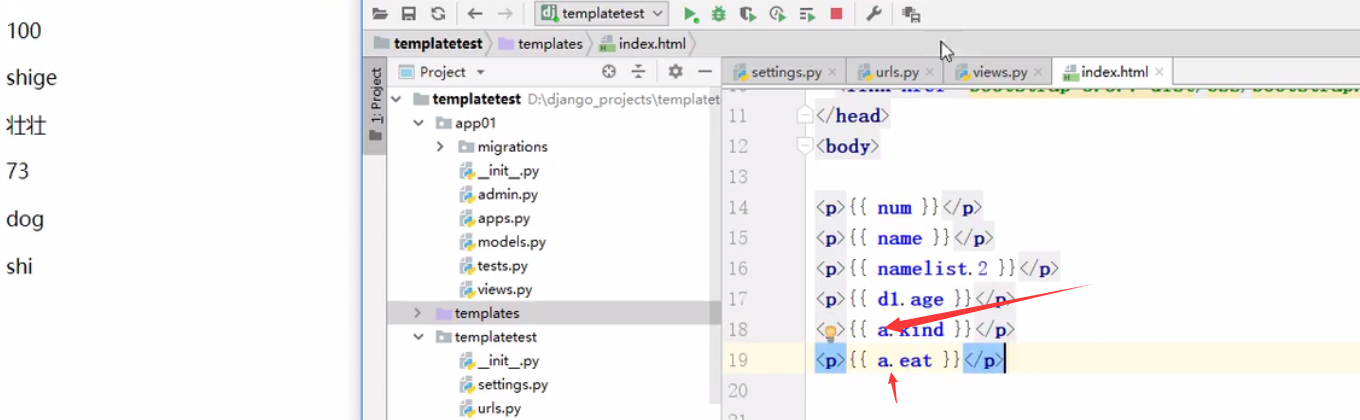
def index(request):
num = 100
name = 'cookie'
namelist = ['娭', '晓丽', '小曹']
d1 = {'name':'cookie', 'age':18, 'hobby':'poto'}
lis = [1, ['冠状病毒', '武汉加油'], 3]
# return render(request, 'index.html ',{'nmu':num, 'name':name, 'namelist':namelist, 'd1':d1})
# 使用locals是用于测试,实际生产环境中是不可以的。
return render(request, 'index.html', locals())
locals():获取函数内部所有变量的值,并加工成{'变量名':'变量值',......}这样的一个字典

html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p> {{ num }}</p>
<p> {{ name }}</p>
<p> {{ namelist.1 }}</p>
<p> {{ d1.age }}</p>
<p> {{ lis.1.1 }}</p>
</body>
</html>
深度查询据点符(.)在模板语言中有特殊的含义。当模版系统遇到点("."),它将以这样的顺序查询:
字典查询(Dictionary lookup)
属性或方法查询(Attribute or method lookup)
数字索引查询(Numeric index lookup)
显示结果

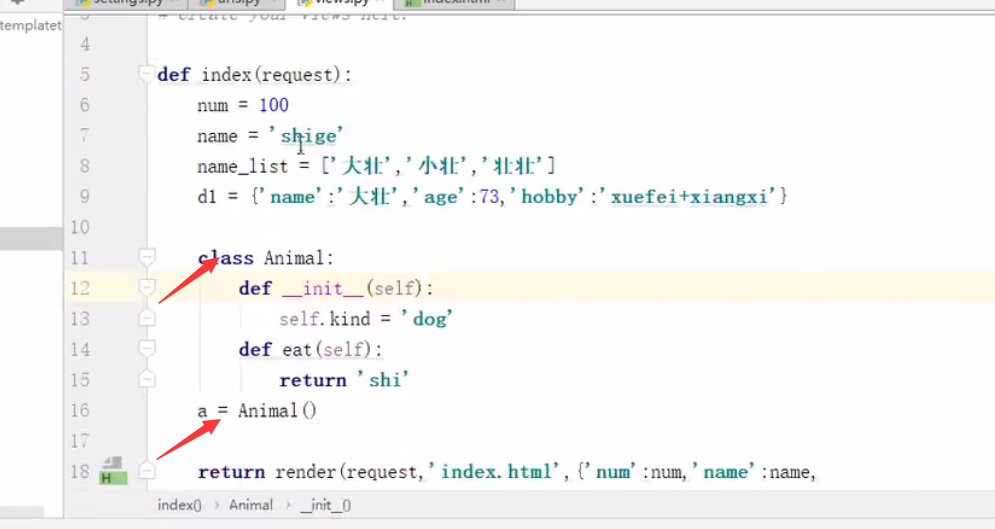
在views界面新建一个类然后在HTML界面调用
但是只能调用类里面的无参函数
3.5过滤器
-
1.什么是过滤器
有的时候我们通过render渲染到html的数据并不是我们最终想要的数据,比如后端向前端传递的数据为hello,但是我们html想要显示为HELLO,当然这个在后端是可以提前处理的,但是诸如此类的需求我们可以通过过滤器解决,过滤器给我们提过了很多便捷的方法,加工你传递到html的数据,便于灵活开发。
-
2.语法
过滤器的语法: {{ value| filter_name:参数 }}
使用管道符"|"来应用过滤器。
例如:{{ name| lower }}会将name变量应用lower过滤器之后再显示它的值。lower在这里的作用是将文本全都变成小写。
注意事项:
- 过滤器支持“链式”操作。即一个过滤器的输出作为另一个过滤器的输入。
- 过滤器可以接受参数,例如:{{ sss|truncatewords:30 }},这将显示sss的前30个词。
- 过滤器参数包含空格的话,必须用引号包裹起来。比如使用逗号和空格去连接一个列表中的元素,如:{{ list|join:', ' }}
- '|'左右没有空格!没有空格!没有空格!
Django的模板语言中提供了大约六十个内置过滤器。
-
3.常用过滤器
default: 如果一个变量是false或者为空,使用给定的默认值。 否则,使用变量的值。
Django的模板语言中提供了大约六十个内置过滤器。
default
如果一个变量是false或者为空,使用给定的默认值。 否则,使用变量的值。
{{ value|default:"nothing"}}
如果value没有传值或者值为空的话就显示nothing
length
返回值的长度,作用于字符串和列表。
{{ value|length }}
返回value的长度,如 value=['a', 'b', 'c', 'd']的话,就显示4.
filesizeformat
将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如:
{{ value|filesizeformat }}
如果 value 是 123456789,输出将会是 117.7 MB。
slice
切片,如果 value="hello world",还有其他可切片的数据类型
{{value|slice:"2:-1"}}
date
格式化,如果 value=datetime.datetime.now()
{{ value|date:"Y-m-d H:i:s"}}
关于时间日期的可用的参数(除了Y,m,d等等)还有很多,有兴趣的可以去查查看看。
safe
Django的模板中在进行模板渲染的时候会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全,django担心这是用户添加的数据,比如如果有人给你评论的时候写了一段js代码,这个评论一提交,js代码就执行啦,这样你是不是可以搞一些坏事儿了,写个弹窗的死循环,那浏览器还能用吗,是不是会一直弹窗啊,这叫做xss攻击,所以浏览器不让你这么搞,给你转义了。但是有的时候我们可能不希望这些HTML元素被转义,比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。
我们去network那个地方看看,浏览器看到的都是渲染之后的结果,通过network的response的那个部分可以看到,这个a标签全部是特殊符号包裹起来的,并不是一个标签,这都是django搞得事情。

比如:
value = "点我" 和 value=""
{{ value|safe}}
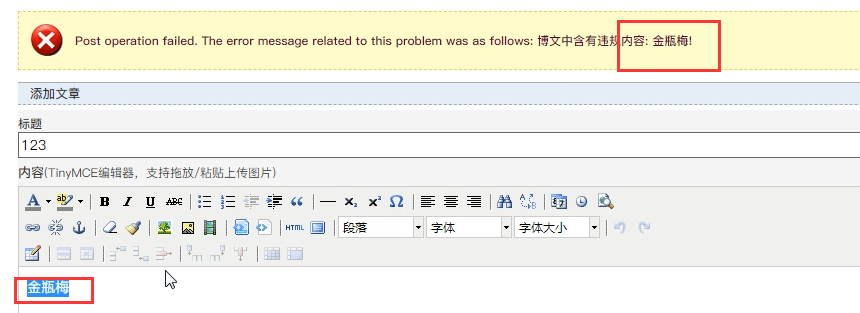
很多网站,都会对你提交的内容进行过滤,一些敏感词汇、特殊字符、标签、黄赌毒词汇等等,你一提交内容,人家就会检测你提交的内容,如果包含这些词汇,就不让你提交,其实这也是解决xss攻击的根本途径,例如博客园:**
**
truncatechars
如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾。
参数:截断的字符数
{{ value|truncatechars:9}} #注意:最后那三个省略号也是9个字符里面的,也就是这个9截断出来的是6个字符+3个省略号,有人会说,怎么展开啊,配合前端的点击事件就行啦
truncatewords
在一定数量的字后截断字符串,是截多少个单词。
例如:‘hello girl hi baby yue ma’,
{{ value|truncatewords:3}} #上面例子得到的结果是 'hello girl h1...'
cut
移除value中所有的与给出的变量相同的字符串
{{ value|cut:' ' }}
如果value为'i love you',那么将输出'iloveyou'.
join
使用字符串连接列表,{{ list|join:', ' }},就像Python的str.join(list)
timesince(了解)
将日期格式设为自该日期起的时间(例如,“4天,6小时”)。
采用一个可选参数,它是一个包含用作比较点的日期的变量(不带参数,比较点为现在)。 例如,如果blog_date是表示2006年6月1日午夜的日期实例,并且comment_date是2006年6月1日08:00的日期实例,则以下将返回“8小时”:
{{ blog_date|timesince:comment_date }}
分钟是所使用的最小单位,对于相对于比较点的未来的任何日期,将返回“0分钟”。
timeuntil(了解)
似于timesince,除了它测量从现在开始直到给定日期或日期时间的时间。 例如,如果今天是2006年6月1日,而conference_date是保留2006年6月29日的日期实例,则{{ conference_date | timeuntil }}将返回“4周”。
使用可选参数,它是一个包含用作比较点的日期(而不是现在)的变量。 如果from_date包含2006年6月22日,则以下内容将返回“1周”:
{{ conference_date|timeuntil:from_date }}
这里简单介绍一些常用的模板的过滤器,更多详见
3.6csrf认证
csrf_token
我们以post方式提交表单的时候,会报错,还记得我们在settings里面的中间件配置里面把一个csrf的防御机制给注销了啊,本身不应该注销的,而是应该学会怎么使用它,并且不让自己的操作被forbiden,通过这个东西就能搞定。
这个标签用于跨站请求伪造保护,
在页面的form表单里面(注意是在form表单里面)任何位置写上{% csrf_token %},这个东西模板渲染的时候替换成了,隐藏的,这个标签的值是个随机字符串,提交的时候,这个东西也被提交了,首先这个东西是我们后端渲染的时候给页面加上的,那么当你通过我给你的form表单提交数据的时候,你带着这个内容我就认识你,不带着,我就禁止你,因为后台我们django也存着这个东西,和你这个值相同的一个值,可以做对应验证是不是我给你的token,存储这个值的东西我们后面再学,你先知道一下就行了,就像一个我们后台给这个用户的一个通行证,如果你用户没有按照我给你的这个正常的页面来post提交表单数据,或者说你没有先去请求我这个登陆页面,而是直接模拟请求来提交数据,那么我就能知道,你这个请求是非法的,反爬虫或者恶意攻击我的网站,以后将中间件的时候我们在细说这个东西,但是现在你要明白怎么回事,明白为什么django会加这一套防御。
爬虫发送post请求简单模拟:
import requests
res = requests.post('http://127.0.0.1:8000/login/',data={
'username':'cookie',
'password':'123'
})
print(res.text)
注释
{# ... #}
注意事项
1. Django的模板语言不支持连续判断,即不支持以下写法:
{% if a > b > c %}
...
{% endif %}
2. Django的模板语言中属性的优先级大于方法(了解)
def xx(request):
d = {"a": 1, "b": 2, "c": 3, "items": "100"}
return render(request, "xx.html", {"data": d})
如上,我们在使用render方法渲染一个页面的时候,传的字典d有一个key是items并且还有默认的 d.items() 方法,此时在模板语言中:
{{ data.items }}
默认会取d的items key的值。
3.7模板继承
Django模版引擎中最强大也是最复杂的部分就是模版继承了。模版继承可以让您创建一个基本的“骨架”模版,它包含您站点中的全部元素,并且可以定义能够被子模版覆盖的 blocks 。
通过从下面这个例子开始,可以容易的理解模版继承:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>小康之家</title>
</head>
<style>
body{
margin: 0;
padding: 0;
}
.nav{
background-color: #4f4f4f;
padding: 0;
}
.nav>a{
color: #1b1b1b;
}
.left-menu{
background-color: #4f4f4f;
color: #4ac1f7;
width: 20%;
height: 400px;
float: left;
}
ul{
margin: 0;
}
.content{
width: 80%;
float: right;
}
.clearfix{
content: '';
display: block;
clear: both;
}
</style>
<body>
<div class="nav">
<a href="/base/">首页</a>
<a href="">个人简历</a>
<a href="">社交旅游</a>
<a href="">摄影作品</a>
<a href="">设备相关</a>
<input type="text"><button>搜索</button>
</div>
<div class="clearfix">
<div class="left-menu">
<ul>
<li><a href="/menu1/">菜单1</a></li>
<li><a href="/menu2/">菜单2</a></li>
<li>菜单3</li>
<li>菜单4</li>
</ul>
</div>
<div class="content">
{% block content %}
base首页
{% endblock %}
</div>
</div>
</body>
</html><!DOCTYPE html>
这个模版,我们把它叫作 base.html, 它定义了一个可以用于两列排版页面的简单HTML骨架。“子模版”的工作是用它们的内容填充空的blocks。
在这个例子中, block 标签定义了三个可以被子模版内容填充的block。 block 告诉模版引擎: 子模版可能会覆盖掉模版中的这些位置。
子模版可能看起来是这样的:
menu1:
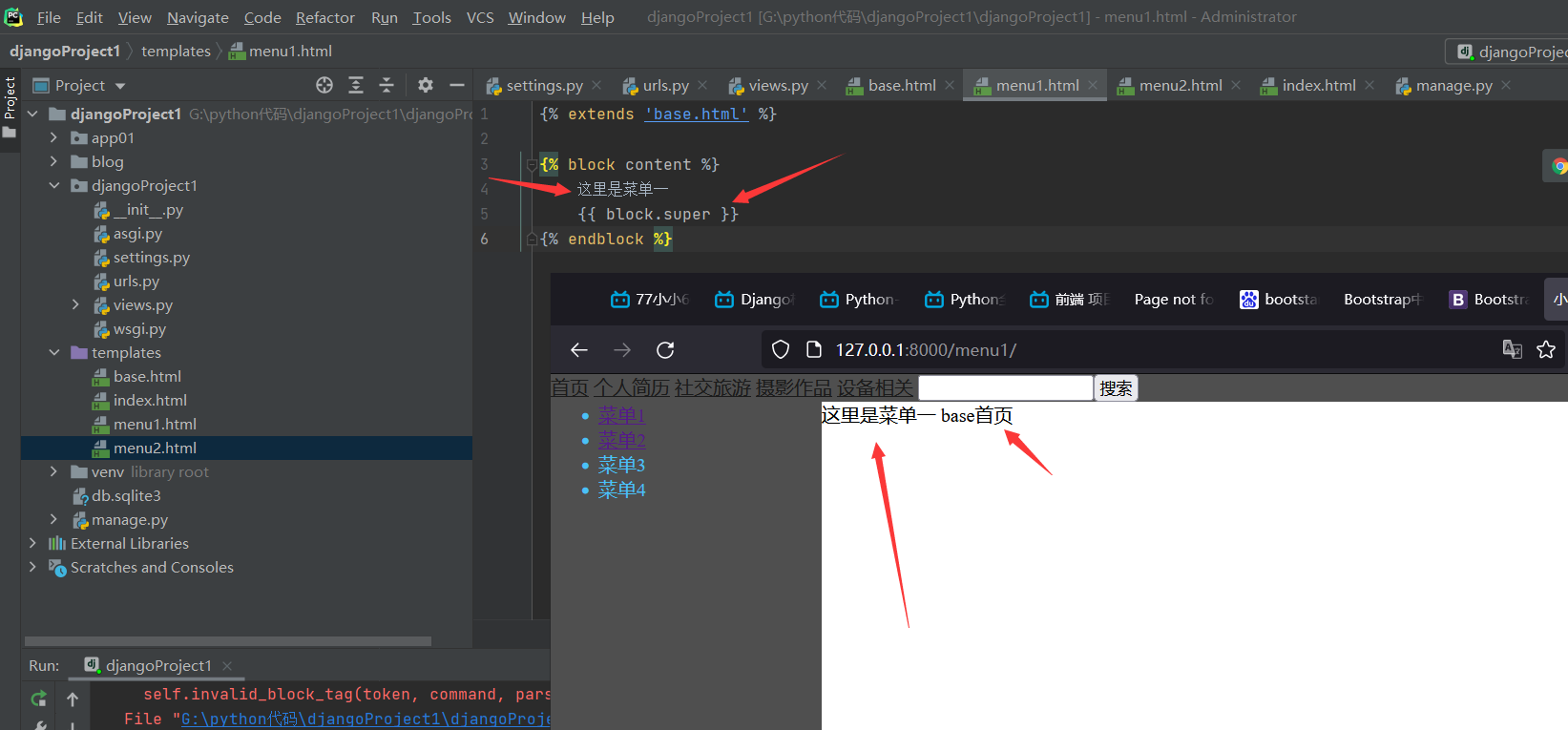
{% extends 'base.html' %}
{% block content %}
这里是菜单一
{{ block.super }}
{% endblock %}
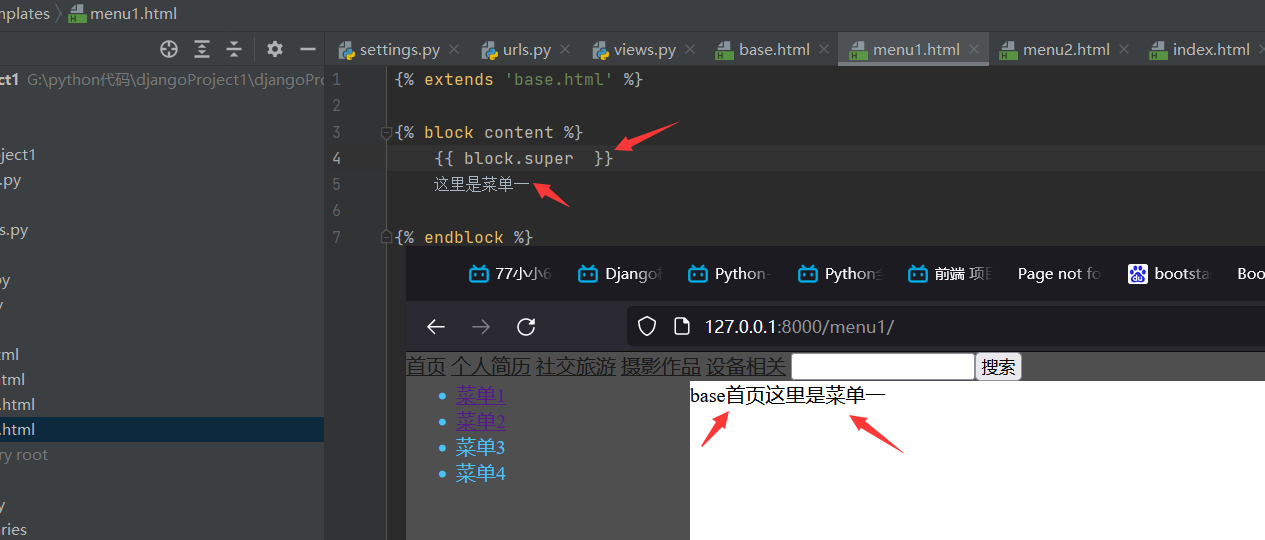
menu2:
{% extends 'base.html' %}
{% block content %}
这里是菜单二
{% endblock %}
子模板关键汇总:
{% extends "base.html" %}
{% block title %}My amazing blog{% endblock %}
{% block content %}
{% for entry in blog_entries %}
<h2>{{ entry.title }}</h2>
<p>{{ entry.body }}</p>
{% endfor %}
{% endblock %}
| 标签 | 说明 |
|---|---|
| 拓展一个父模板,也是继承上一个父模板的内容 | |
| 指定父模板中的一段代码块,此处为title,在父模板中定义title代码块,可以在子模块中重写该代码块。block标签必须是封闭的,要由{%endblock%} 结尾 | |
| {{ entry.title }} | 获取变量的值 |
| {% for entry in blog_entries %} | 和python中的for循环用法相似,但是必须是封闭的 |
这种方式使代码得到最大程度的复用,并且使得添加内容到共享的内容区域更加简单,例如,部分范围内的导航。
这里是使用继承的一些提示:
- 如果你在模版中使用
{% extends %}标签,它必须是模版中的第一个标签。其他的任何情况下,模版继承都将无法工作,模板渲染的时候django都不知道你在干啥。 - 在base模版中设置越多的
{% block %}标签越好。请记住,子模版不必定义全部父模版中的blocks,所以,你可以在大多数blocks中填充合理的默认内容,然后,只定义你需要的那一个。多一点钩子总比少一点好。 - 如果你发现你自己在大量的模版中复制内容,那可能意味着你应该把内容移动到父模版中的一个
{% block %}中。 - If you need to get the content of the block from the parent template, the
{{ block.super }}variable will do the trick. This is useful if you want to add to the contents of a parent block instead of completely overriding it. Data inserted using{{ block.super }}will not be automatically escaped (see the next section), since it was already escaped, if necessary, in the parent template. 将子页面的内容和继承的母版中block里面的内容同时保留
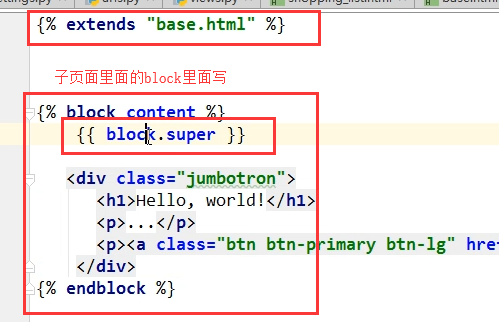
{{block.super}}:的位置和模板关系
3.8组件
可以将常用的页面内容如导航条,页尾信息等组件保存在单独的文件中,然后在需要使用的地方,文件的任意位置按如下语法导入即可。
{% include 'navbar.html' %}
例如:有个如下的导航栏,nav.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
.c1{
background-color: red;
height: 40px;
}
</style>
</head>
<body>
<div class="c1">
<div>
<a href="">xx</a>
<a href="">dd</a>
</div>
</div>
</body>
</html>
嵌入导航栏的页面,test.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{% include 'nav.html' %}
<h1>xxxxxxxxxx</h1>
</body>
</html>
组件和插件的简单区别:
组件是提供某一完整功能的模块,如:编辑器组件,QQ空间提供的关注组件 等。
而插件更倾向封闭某一功能方法的函数。
这两者的区别在 Javascript 里区别很小,组件这个名词用得不多,一般统称插件。
3.9自定义标签和过滤器
1、在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag.
2、在app中创建templatetags模块(模块名只能是templatetags)
3、创建任意 .py 文件,如:my_tags.py
from django import template
from django.utils.safestring import mark_safe
register = template.Library() #register的名字是固定的,不可改变
@register.filter
def filter_multi(v1,v2): #不带参数的过滤器
s= v1 + '幸福'
return s
@register.filter
def filter_multi(v1,v2): #带参数的过滤器
s= v1 + v2
return s
@register.simple_tag #和自定义filter类似,只不过接收更灵活的参数,没有个数限制。
def simple_tag_multi(v1,v2):
return v1 * v2
@register.simple_tag
def my_input(id,arg):
result = "<input type='text' id='%s' class='%s' />" %(id,arg,)
return mark_safe(result)
4、在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py
{% load 文件名 %} ---- {% load my_tags %}
{{ values|filter_multi}} --- 无参数
{{ values|filter_multi:'222'}} --- 有参数
{% simple_tag_multi 2 5 %} 参数不限,但不能放在if for语句中
{% simple_tag_multi num 5 %}
注意:filter可以用在if、for等语句后,simple_tag不可以
{% if num|filter_multi:30 > 100 %}
{{ num|filter_multi:30 }}
{% endif %}
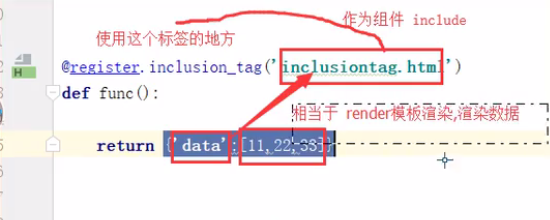
inclusion_tag
多用于返回html代码片段
示例:
templatetags/my_inclusion.py
from django import template
register = template.Library()
@register.inclusion_tag('result.html') #将result.html里面的内容用下面函数的返回值渲染,然后作为一个组件一样,加载到使用这个函数的html文件里面
def show_results(n): #参数可以传多个进来
n = 1 if n < 1 else int(n)
data = ["第{}项".format(i) for i in range(1, n+1)]
return {"data": data}#这里可以穿多个值,和render的感觉是一样的{'data1':data1,'data2':data2....}
templates/snippets/result.html
<ul>
{% for choice in data %}
<li>{{ choice }}</li>
{% endfor %}
</ul>
templates/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>inclusion_tag test</title>
</head>
<body>
{% load inclusion_tag_test %}
{% show_results 10 %}
</body>
</html>
3.10静态文件配置
js、css、img等都叫做静态文件,那么关于django中静态文件的配置,我们就需要在settings配置文件里面写上这写内容:
# STATIC_URL = '/xxx/' #别名,随便写名字,但是如果你改名字,别忘了前面页面里面如果你是通过/xxx/bootstrap.css的时候,如果这里的别名你改成了/static/的话,你前端页面的路径要改成/static/bootstrap.css。所以我们都是用下面的load static的方式来使用静态文件路径
STATIC_URL = '/static/' #别名
STATICFILES_DIRS = [
os.path.join(BASE_DIR,'jingtaiwenjian'), #注意别忘了写逗号,第二个参数就是项目中你存放静态文件的文件夹名称
]
目录:别名也是一种安全机制,浏览器上通过调试台你能够看到的是别名的名字,这样别人就不能知道你静态文件夹的名字了,不然别人就能通过这个文件夹路径进行攻击。

前端页面引入静态文件的写法,因为别名也可能会修改,所以使用路径的时候通过load static来找到别名,通过别名映射路径的方式来获取静态文件
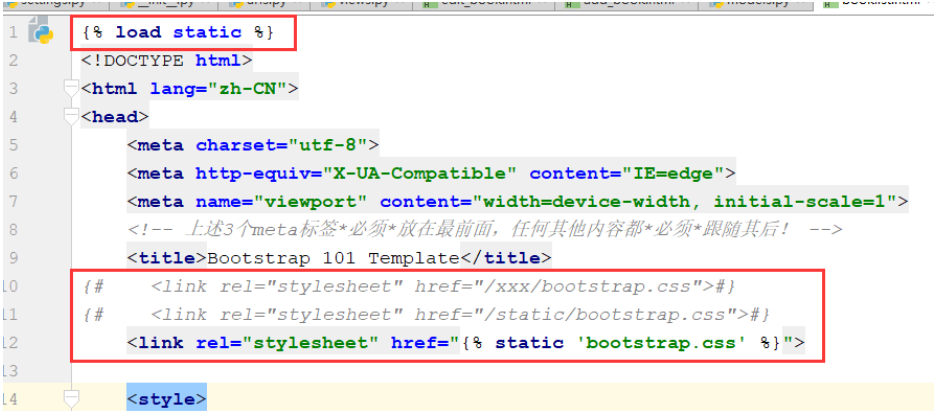
1.
{% load static %}
<img src="{% static "images/hi.jpg" %}" alt="Hi!" />
引用JS文件时使用:
{% load static %}
<script src="{% static "mytest.js" %}"></script>
某个文件多处被用到可以存为一个变量
{% load static %}
{% static "images/hi.jpg" as myphoto %}
<img src="{{ myphoto }}"></img>
2.
{% load static %}
<img src="{% get_static_prefix %}images/hi.jpg" alt="Hi!" />
或者
{% load static %}
{% get_static_prefix as STATIC_PREFIX %}
<img src="{{ STATIC_PREFIX }}images/hi.jpg" alt="Hi!" />
<img src="{{ STATIC_PREFIX }}images/hi2.jpg" alt="Hello!" />
注意一个html文件中写相对路径时需要注意的一个问题:
例子:
<form action="/login/"></form>
<img src="/static/1.jpg" alt="">
等标签需要写路径的地方,如果写的是相对路径,那么前置的/这个斜杠必须写上,不然这个请求会拼接当前网页的路径来发送请求,就不能匹配我们的后端路径了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号