
python基础笔记目录
python基础笔记目录
python学习笔记
cpu:计算机的运算和计算中心,相当于人类大脑
内存:暂时存储数据,临时加载应用程序
速度快,断电消失,造价高
硬盘:长期存储数据,存储视频、音频之类
速度相对慢造价相对低
操作系统:一个软件,连接计算机硬件与所有软件之间的一个媒介
知识点:
hashlib函数 加盐 动态的盐(切片) 写入文件 MD5还可以用于文件的校验(每次读取1024个字节或者一次性读取)

sha系列
随着sha系列数字越高级,加密越复杂,越不容易破解,但耗时长(金融类、安全类)
今日复习:
1.import
2.from ... import ... 容易产生冲突,独立的空间
3.__name__问题
4.模块的搜索路径
内存 内置 sys.path
5.序列化模块:json(四个方法)
6.hashlib
文件的
python笔记2021.11.16格式化输出,运算符,基本数据类型
格式化输出
制作一个格式化模板%占位符
```------------ info of %s ---------------
name :%s
age : %s
job : %s
hobbie : %s
----------- end ----------------
```%(name , naem, age, hobby)
运算符
// --》地板除也是整除
** ---》次幂
% ----》取余
!= ---》不等于
+= ----》n = n + 1 = n+= 1
再没有括号的情况下,优先级:not > and >or
情况1:两边都是比较运算的时候
not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
情况2:两边都是整数
0 or 4 and 3 or 7 or 9 and 6
print(1 or 2)
如果前面为真则输出前面
编码的初识
计算机存储文件,数据以及通过网络发送文件,存储和发送的都是二进制文件
ascall码
基本数据类型
1.int
2.boll
3.str
索引,切片
常用操作方法
列表list(存储大量数据),元组tuple(存储大量数据,不可改变里面元素),字典dict(存储大量关联数据,查询速度非常快)
set集合
str索引和切片
s1 = "python pypy"
s2 = s1[2]
s3 = s1[0:5:]#左闭右开区间,有头没有尾
s4 = s1[6:]#从前往后数六个
s5 = s1[:5:2]#s[起点:终点+1:(正负表示方向)步长]反向是有尾无头
字符串的常用方法
s.upper(转化成大写) s.lower (转化成小写)不会对原来的字符串进行任何操作,都是产生一个新的字符串
s = "sdfsdfsdf"
print(s.startswith('s',3,6)#3-6部分是不是以s开头
s.replace替换
msg = 'aokang taicaile 加强锻炼'
msg1 = msg.replace('加强','增强','次数')#次数不写全部替换写了就替换几个
s.stirp()去除
s1 = 'rre 这里zai'
s2 = s1.strip('reazi')#从前往后,再从后往前搜索去除字符串里有的字母,遇上空格和其他字符不在字符串里的字符就会发生中断,比如s1 = 'rre zai 这里'运行结果为 zai 这里
s.split重要函数 将字符串切割成列表
s1 = '奥康 男生 天字'
l = s1.split()#默认按照空格分割返回一个列表s1.split(’指定分割符‘,分割的次数)
s.join 可拼接任何可迭代对象
s1 = 'alex's2 = '+'.join(s1)#输出结果a+l+e+x
s.count 计数次数
s1 = 'sahfoiwhoiehwoehowssaaasjliaoa'pritn(s1.count('a'))#计算a出现的次数
format:格式化输出
msg = '我叫{}今年{}性别{}'.format('dazhuang','16','nan')msg = '我叫{0}今年{1}性别{2}今年{3},我依然是{0}'.format('dazhuang','16','nan')msg = '我叫{name}今年{age}性别{sex}今年{},我依然是{0}'.format(nan='dazhuang',age='16',sex'nan')
is系列

python笔记2021.11.17列表,增删改查
列表的增删改查,索引切片等
为什么要有列表?
list承载任意数据类型,存储大量的数据
python常用的容器数据类型,Java中叫数组
列表是有序的可以索引和切片
增删改
增:
append:末尾追加
l1.append['xx']
insert:插入
l1.insert[数字,"xx"]#在数字位置插入xx
extend:迭代增加
l1:extend['abcd']#把元素啊,个一个加入a,b,c,d
l1:extend(['aa',])#把元素aa作为一个单位加入
删:
按照索引位置删除
l1.pop["数字"]#返回删除的元素,数字表示删除元素在里面的下标,默认删除最后一个
remove:默认删除第一个,指定删除元素
l1.remove['xx']#指定删除
clear:清空
del:按照索引删除
del l1[n]
按照切片删除
del l1[::2]
改
l1[0] = 'xx'#覆盖原位置
l1[2:] = 'asfsaf' #按照切片改,可以不用一一对应,加步长需要一一对应
列表嵌套
列表嵌套等同于数组的多维数组

元组
只读列表
tu = (100, 'aokang', 1, [1, 2, 3])#应用于账户名,用户密码,个人信息,
#元组的拆包
a,b = (1, 2)#多一个少一个都不行
prit(a, b)
range:类似于列表,自定制数字范围,顾头不顾尾,前闭后开区间
python笔记2021.11.19字典
字典的笔记
字典的初识
为什么要用字典?
缺点:列表可以存储大量数据,但是列表之间的关联性不强
列表查询速度慢,顺序查询
针对这两个缺点就有了字典
数据类型分类(可变与不可变)-->可操作原对象有无影响,比如:你的操作对原对象无影响
可变(不可哈希)的数据类型:list dict set
不可变(可哈希)的数据类型:str bool tuple int
字典:{}括起来,以键值对形式存储的容器型数据类型
键必须是不可变数据类型:int, str(bool tuple几乎不可用)唯一的
值可以是任意数据类型;
缺点:以空间换时间
优点:查询速度快,数据关联性强
字典的创建方式
dict
字典的合法性
键是可哈希的
字典的增删改查
增:
dic = {'name':'aoakang'}
dic['sex'] = '男'#有则改之,无则创建
setdefault('hobby','photo')#设置默认值,有则不变,无则增加
pop:删除
按照键去删除键值对
dic.pop('sex')
dic.pop('hobby','没有此键')#此种方式无论有无此键都不会报错,返回值是第二个内容
clear:清空
dic.clear()
del:删除
del dic['age']#不存在会报错
改:
dic['naem'] = 'wang'
查
按照键查寻
print(dic[naem])#不存在会报错,一般用get
get
dic.get('name')#不存在不会报错,返回None
dic.get('name','无此键')#返回第二个预设返回值
三个特殊
keys(),values(), items()
面试题:
a = 18
b = 12
a,b = b,a#a,b值互换
字典的嵌套:
python笔记2021.11.20代码块、缓存机制、小数据池
代码块,缓存机
id 理解成身份证
#id 每个地址都有一个id
i = 100
print(id(i))
l1 = [1, 2, 3]
l2 = [1, 2, 3]
# == 判断的是等号两边的数据是否相等
print(l1 == l2)
print(id(l1) == id(l2))
#is 判断的是内存地址是否相同
print(l1 is l2)#fales
s1 = 'alex'
s2 = 'alex'
print(s1 is s2)#返回结果是Ture
1.代码块
代码块:我们所有的代码都需要依赖代码块执行
一个文件就是一个代码块
交互之命令下,一个命令就是一个代码块
2.两个机制:同一个代码下 ,有一个机制。不同代码块下,遵循另一个机制
3.同一个代码块下的缓存机制
前提条件:在同一个代码块内
机制内容:pass
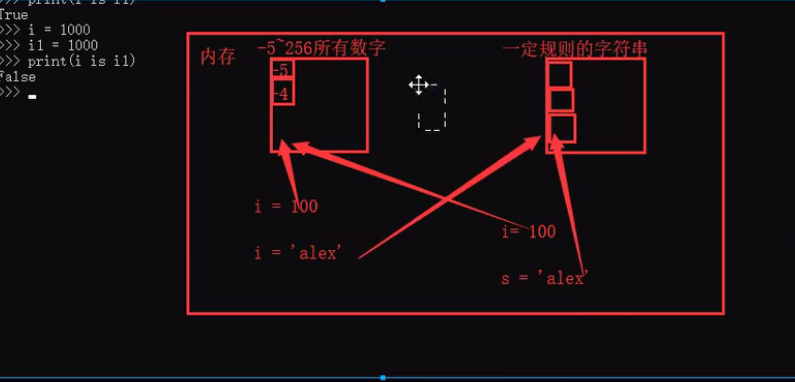
适用对象:int bool str三个不可变数据类型
具体细则:所有数字,bool,和大部分str(几乎所有)
优点:节省内存,提升性能
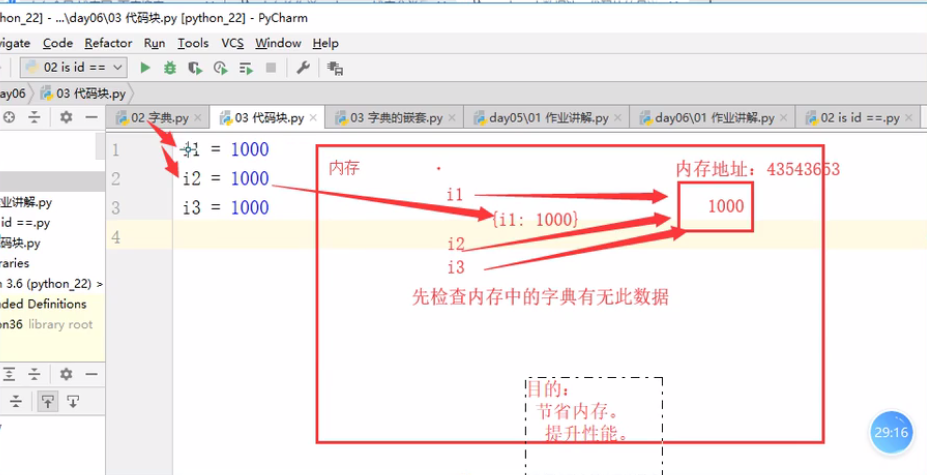
4.不同代码块的缓存机制:小数据池(交互式环境)
前提条件:在不同一个代码块内
机制内容:pass
适用对象:int bool str三个不可变数据类型
具体细则:-5~256,bool,和满足规则的字符串
优点:节省内存,提升性能
集合
python笔记2021.11.21浅、深copy
python基础类型之:集合set.容器型数据类型
要求里面的数据类型是不可变的数据类型,但是它本身时可变数据类型。集合是无序的。{}
集合的作用:1.列表的去重 2.关系测试:交集,并集,补集
#集合的创建
set1 = set{1, 2, 3, 4}
set1 = set({1, 2, 3, 'xx'})
#空集合
set1 = set()
#集合的有效性
set1 = {[1, 2, 3], 3, {'naem': 'alex'}}#需要不可变数据类型
#增
add
set1.add('xxx')
#update迭代增加
set1.update('asdf')#可迭代对象
#删
remove:按元素删除
set1.remove('alex')
pop:随机删除
set1.pop()
#交集 &
set1 = set{1, 2, 3, 4, 5}
set2 = set{3, 4, 5, 6, 7, 8}
print(set1 & set2)
#并集 |
print(set1 | set2)
#差集 -
print(set1 - set2)
#反交集 ^
print(set1 ^ set2)
#子集
print(set1 > set2)#返回boll
#超集
print(set2 > set1)#返回boll
#列表去重
l1 = [1, 1, 1, 1, 2, 3, 4, 4, 5, 3, 3, 5]
set1 = set(l1)#不能保证原来顺序
l1 = list(set1)
print(l1)
#集合用处:数据之间的关系列表去重(了解就行)
深浅copy
l1 = [1, 2, 3, 4, [2,2,4]]
l2 = l1
l1.append(666)
l2 = l1.copy()
l1.append(666)
print(l1,id(l1))
print(l2,id(l2))#结果不一样
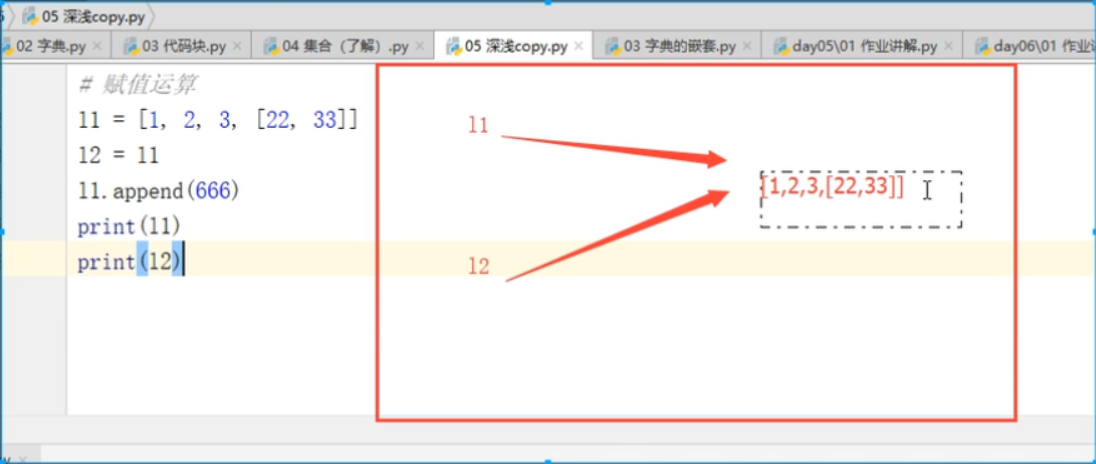
#浅copy
l1 = [1, 2, 3, 4, [2,2,4]]
l2 = l1.copy()
l1.append(666)
print(l1,id(l1))
print(l2,id(l2))#结果一样
浅copy:l1 与 l2对地址不一样,但是里面(每一个元素)指向的地址都是一样的
深copy:两个完全不一样(外壳地址和数据地址也不同)
python对深copy做了一个优化,将不可变数据类型沿用一同个,将可变的数据类型重新创建一份
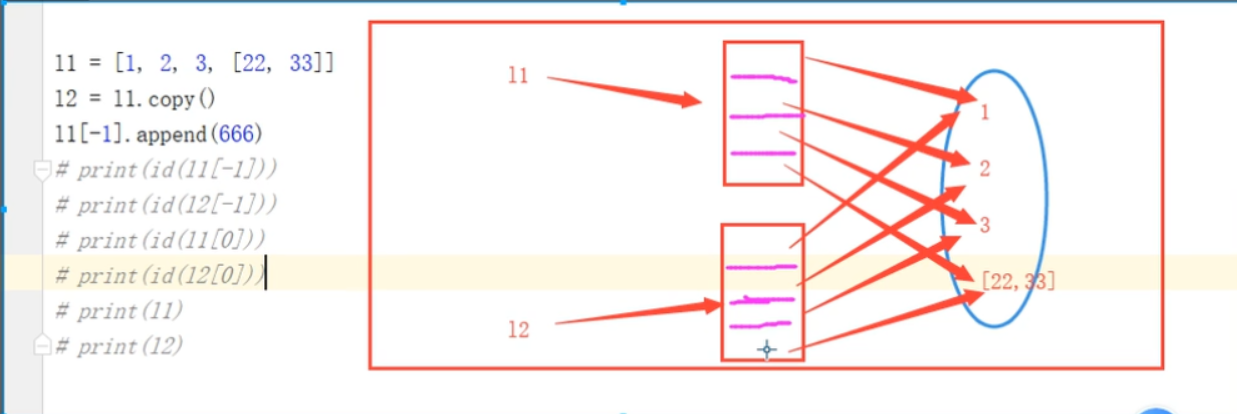
import copy
l1 = [1, 2, 3, [22, 33]]
l2 = copy.deepcopy(l1)
print(id(l1))
print(id(l2))#结果也不一样
l1[-1].append(666)
print(l1)
print(l2)#结果不一样
浅copy:list dict:嵌套的可变的数据类型是同一个
深copy:list dict :嵌套的可变数据类型不是同一个
python笔记2021.11.22可迭代对象、字典列表
三个对可迭代对象操作的函数
for循环:
msg = "sc学习是非常快乐的一件事"
for i in msg:
print(i,end=' ')
enumerate(枚举函数):
# enumerate:枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
l1 = ['你', '我', '它', '他', '她']
# for i,name in enumerate(l1):
# print(i,name)
for i in enumerate(l1):
print(i)
range:范围函数
# range:指定范围,生成指定数字。
l1 = ['你', '我', '它', '他', '她']
for i in range(-1,-3,-1):
print(l1[i])
#range函数详解:range(1,-3,1)返回值是一个None,同理range(0,3,-1)也不行
#第二个符号位要和第三个步长的符号位保持一致,简单来说就是要符合逻辑思路,range函数取数前闭后开区间。
python基本数据类型补充:
字符串:
#captalize, swapcase, title
print(name.capitalize())#首字母大写
print(name.swapce()) #大小写翻转
msg = 'aokang yao kuai le'
print(msg.title()) #每个单词首字母大写
# 内同居中,总长度,空白处填充
ret2 = msg.center(30,"*")
print(ret2)
#寻找字符串中的元素是否存在
# ret6 = msg.find("fjdk",1,6)
# print(ret6) # 返回的找到的元素的索引,如果找不到返回-1
# ret61 = msg.index("fjdk",4,6)
# print(ret61) # 返回的找到的元素的索引,找不到报错。
元组:
python中元组有一个特性,元组中如果只含有一个元素且没有逗号,则该元组不是元组,与改元素数据类型一致,如果有逗号,那么它是元组。
tu = (1)
print(tu,type(tu)) # 1 <class 'int'>
tu1 = ('alex')
print(tu1,type(tu1)) # 'alex' <class 'str'>
tu2 = ([1, 2, 3])
print(tu2,type(tu2)) # [1, 2, 3] <class 'list'>
tu = (1,)
print(tu,type(tu)) # (1,) <class 'tuple'>
tu1 = ('alex',)
print(tu1,type(tu1)) # ('alex',) <class 'tuple'>
tu2 = ([1, 2, 3],)
print(tu2,type(tu2)) # ([1, 2, 3],) <class 'tuple'>
元组也有一些其他的方法:
index:通过元素找索引(可切片),找到第一个元素就返回,找不到该元素即报错。
tu = ('太白', [1, 2, 3, ], 'WuSir', '女神')
print(tu.index('太白')) # 0
count: 获取某元素在列表中出现的次数
tu = ('太白', '太白', 'WuSir', '吴超')
print(tu.count('太白')) # 2
列表的其他操作方法:
count(数)(方法统计某个元素在列表中出现的次数)。
a = ["q","w","q","r","t","y"]
print(a.count("q"))
index(方法用于从列表中找出某个值第一个匹配项的索引位置)
a = ["q","w","r","t","y"]print(a.index("r"))
sort (方法用于在原位置对列表进行排序)。
reverse (方法将列表中的元素反向存放)。
a = [2,1,3,4,5]a.sort()# 他没有返回值,所以只能打印aprint(a)a.reverse()#他也没有返回值,所以只能打印aprint(a)
列表也可以相加与整数相乘
l1 = [1, 2, 3]l2 = [4, 5, 6]# print(l1+l2) # [1, 2, 3, 4, 5, 6]print(l1*3) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
循环列表,改变列表大小的问题
先不着急,说这个问题,先做一道小题:
有列表l1, l1 = [11, 22, 33, 44, 55],请把索引为奇数对应的元素删除(不能一个一个删除,此l1只是举个例子,里面的元素不定)。
有人说这个还不简单么?我循环列表,然后进行判断,只要他的索引为奇数,我就删除。OK,你可以照着这个思路去做。
那么根据题意,这个题最终的结果应该是:l1 = [11, 33, 55],但是你得到的结果却是: l1 = [11, 33, 44] 为什么不对呢???
用这个进行举例:当你循环到22时,你将列表中的22删除了,但是你带来的影响是:33,44,55都会往前进一位,他们的索引由原来的2,3,4变成了1,2,3 所以你在往下进行循环时,就会发现,额........完全不对了。
那这个怎么解决呢?有三种解决方式:
方法一:直接删除
l1 = [11, 22, 33, 44, 55]del l1[1::2]print(l1)
方法二:倒叙删除
l1 = [11, 22, 33, 44, 55]for index in range(len(l1) - 1, -1, -1): if index % 2 == 1: l1.pop(index)print(l1)
方法三:思维置换
l1 = [11, 22, 33, 44, 55]l2 = l1[::2]print(l2)
4.字典的增删改查
#popitem 3.5版本之前,popitem为随机删除,3.6之后为删除最后一个,有返回值dic = {'name':'aokang', 'age':18}ret = dic.popitem()print(ret,dic)#('age', 18) {'name': 'aokang'}#字典的三种创建方式:#方法一:# updatedic = {'name':'aokang', 'age':18}dic.update(sex='男', habbit='玩游戏',age=18)print(dic)#{'name': 'aokang', 'age': 18, 'sex': '男', 'habbit': '玩游戏'}#方法二dic = {'name':'aokang', 'age':18}dic.update([(1, 'a'),(2, 'b'),(3, 'c'),(4, 'd')])print(dic)#{'name': 'aokang', 'age': 18, 1: 'a', 2: 'b', 3: 'c', 4: 'd'}#方法三dic1 = {'name':'aokang', 'age':18}dic2 = {"weight":75}dic1.update(dic2)print(dic1)#{'name': 'aokang', 'age': 18, 'weight': 75}
fromkeys:创建一个字典:字典的所有键来自一个可迭代对象,字典的值使用同一个值。
dic = dict.fromkeys('abcd','奥康')print(dic)#{'a': '奥康', 'b': '奥康', 'c': '奥康', 'd': '奥康'}dic = dict.fromkeys([1, 2, 3],'我')print(dic)#{1: '我', 2: '我', 3: '我'}# 这里有一个坑,就是如果通过fromkeys得到的字典的值为可变的数据类型,那么你的小心了。dic = dict.fromkeys([1, 2, 3], [])dic[1].append(666)print(id(dic[1]),id(dic[2]),id(dic[3])) # 1927145351424 1927145351424 1927145351424print(dic) # {1: [666], 2: [666], 3: [666]}
循环字典,改变字典大小的问题
来,先来研究一个小题,有如下字典:
dic = {'k1':'太白','k2':'barry','k3': '白白', 'age': 18} 请将字典中所有键带k元素的键值对删除。那么拿到这个题,有人说我一个一个删除,这是不行的,因为这个字典只是举个例子,里面的元素不确定,所以你要怎么样?你要遍历所有的键,符合的删除,对吧? 嗯,终于上套了,哦不,上道了,请开始你的表演。
dic = {'k1':'xx','k2':'barry','k3': 'ee', 'age': 18}for i in dic: if 'k' in i: del dic[i]print(dic)#你会发现,报错了。。。。。#错误原因:#RuntimeError: dictionary changed size during iteration#翻译过来是:字典在循环迭代时,改变了大小。#在循环一个字典的过程中,不要改变字典的大小(增,删字典的元素),这样会直接报错。#解决方法:思维置换l1 = []for key in dic:#循环的主体是类似于列表的容器不是一个字典,可通过循环一个列表删除键值对 if 'k' in key:#不可以通过循环一个字典去删除这个字典的键值对 l1.append(key)for i in l1: dic.pop(i)print(dic)#for key in list(dic.keys()): if 'k' in key: dic.pop(key)print(dic)#不加list它是动态获取的
str list 两者转换
# str ---> lists1 = 'alex 太白 武大'print(s1.split()) # ['alex', '太白', '武大']# list ---> str # 前提 list 里面所有的元素必须是字符串类型才可以l1 = ['alex', '太白', '武大']print(' '.join(l1)) # 'alex 太白 武大'
所有数据都可以转化成bool值
转化成bool值为False的数据类型有:'', 0, (), {}, [], set(), None
python笔记2021.11.27文件操作
1.文件的初始
利用python代码操作文件
文件路径:path
打开方式:只读,只写,读写,读写执行
编码方式:utf-8,gbk等
open 是python的内置函数,open底层调用的是操作系统的接口
f1,变量,fh,file_handler:叫做文件句柄。对我文件进行的任何操作都得通过文件句柄+.的方式操作
encoding:可写可不写,不写参数默认编码本:操作系统的默认编码
windows:gbk
linux:utf-8
mac:utf-8
f = open(r"文件路径","encoding" = "utf-8", 'mode' = '执行方式比如r,rb'):文件路径前面+r强制忽略文件路径产生的错误
对文件操作三部曲:第一部:打开文件;第二部:对文件进行操作;第三步:关闭文件句柄f1.close(),如果读完文件后不关闭它就会一直占用内存,所以需要关闭。
2.文件的读
1.f.read()一次性全部读出来!!
f = open('文件路径', encoding='utf-8/gbk', mode='r/rb')
content = f.read()
print(content)
f.close()
2.read(n)按照字符读取
f = open('文件路径', encoding='utf-8/gbk', mode='r/rb')
content = f.read(n)#表示读取前n个字符
print(content)
f.close()
3.f.readline()按行读
f = open('文件路径', encoding='utf-8/gbk', mode='r/rb')
content = f.readline()#会把/n读出来换行
print(content)
f.close()
4.f.readlines():每一行返回一个列表,列表中每一个元素是源文件的每一行。
f = open('文件路径', encoding='utf-8/gbk', mode='r/rb')
l1 = f.read.lines()
print(l1)
f.close()
5.循环读取:一行一行打印(操作大文件使用文件句柄)上面每一个方法打开大文件,内存都会被大文件占用,而循环句柄,打印一行释放一行,不会占用过多内存!!!
f = open('文件路径', encoding='utf-8/gbk', mode='r/rb')
for line in f:
print(line)
f.close()
6.四种模式:
r,rb ,r+,r+b
r:读取文本文件
rb:读取非文本文件(二进制文件)
3.文件的写
w,wb,w+,w+b
1.w
#如果文件存在先清空后写入,不存在就创建
f = open('文件的写', encoding='utf-8',mode='w')
f.write("随便写写")
f.close()
2.wb(操作非文本类文件)
4.文件的追加
a,ab,a+,a+b
f = open('文件的写', encoding='utf-8', mode='a')#a追加
f.write('都是生活的痕迹')
f.close()
5.文件操作的其他模式
r+:+就是表示增加一个功能
f = open('文件的写', encoding='utf-8',mode='r+')#先读后写
content = f.read()
print(content)
f.write('追加追加追加')
6.文件操作的其他功能
1.f.tell()
获取光标的位置,单位字节
2.f.seek()
调整光标的位置
f = open('文件路径', encoding='utf-8/gbk', mode='r/rb')f.seek(n)#将光标移到n字节content = f.read()#从n+1个·字节开始读取字符print(content)f.close()
3.flush :强制刷新
f = open('文件路径', encoding='utf-8', mode='w')f.write('sgsdgds')f.flush()f.close()
7.打开文件的另一种方式
1.语法糖:优点-
1.不用手动关闭文件,过一段时间会自动关闭
2.一个with可以执行多个open(即可以执行多个文件)
with open('文件的写', encoding='utf-8', mode='r') as f1, \ open('文件路径', encoding='utf-8', mode='w') as f2: f2.write('sfegsgegs') print(f1.read())
8.文件操作的改
```修改文件操作的五个步骤:1.以读的模式打开原文件2.以写的模式创建一个新文件3.将原文件的内容读出来修改成新的内容4.将原文件删除5.将新文件重命名成原文件```#低版本import oswith open("文件自述1.bak", encoding='utf-8', mode='r') as f1 ,\ open('文件自述.bak', encoding='utf-8', mode='w') as f2: old_content = f1.read() new_content = old_content.replace('sb', '11') f2.write(new_content)os.remove('文件自述1.bak')os.rename('文件自述.bak','文件自述1.bak')#高版本:for循环读取文章 import oswith open('文件', encoding='utf-8', mode='r') as f1, \ open('文件1', encoding='utf-8', mode='w') as f2: for line in f1: old_content = line new_content = old_content.replace('alex', '11') f2.write(new_content)#文件句柄未关闭可循环写,不会清空覆盖os.remove('文件')os.rename('文件1', '文件')
python笔记2021.11.28函数
1.函数:一个函数封装一个功能
以功能(完成一件事情)为向导,用于登录,注册,len
1.减少了代码的重复性
2.增强了代码的可读性
2.函数的结构和调用
```
结构: def (关键字,定义函数) 函数名(与变量设置相同,具有可描述性。)
函数体:函数中尽量不要出现print
```
3.函数的返回值
return总结:
1.在函数中,终止函数
2.return可以给函数的执行者返回值,或多个
4.函数的参数
函数的传参:让函数封装的这个功能,盘活
形参和实参:函数执行传的参数叫做实参,函数定义传的参数叫做形参
一、实参角度:
1.位置参数:从左至右,一一对应
def max(a,b):
if a > b:
return a
else:
return b
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
print(max(a,b))
2.三元运算符:适用情况只有一个if和else
a = 10
b = 20
c = a if a > b else b#如果a>b则返回a,否则返回b
print(c)
3.关键字参数
def meet(high, age, skill)
pass
meet(age=25, skill='技术好的', high=175)
4.混合参数:位置参数一定要在关键字参数前面
def meet(high, age, skill)
pass
meet(175,age=25, skill='技术好的')
二、形参角度
def split1(l):
if len(l) > 2:
l1 = l[0:2:1]
return l1
else:
return l
l1 = [1, 2, 3]
print(split1(l1))
#三元运算符
def split1(l):
c = l if len(l) < 2 else l[:2]
1.默认值参数:设置的意义经常使用的参数
def meet(age, skill, sex='女')
p
python笔记2021.11.28函数参数(*args)、全局变量
1.形参角度
万能的参数:*args
def eat(*args):
print('我请你吃:%s %s %s %s' %args)
eat('西瓜', '饼干', '果冻', '梨子')#参数可以任意加
#函数定义时*代表集合,它将所有的位置参数聚合成一个元组,赋值给了args
def sums(*args):
s = 0#用于 += 的时候需要初始化
for i in args:
s += i
return s
print(sums(1, 2, 3, 1))#实现功能对输入的任意数字进行求和
*的魔性用法
#函数定义时将所有的关键字参数聚和到一个字典中,将这个字典赋值给了kwargs
def func(**kwargs):
print(kwargs)
print(func(name='alex', age='18', sex='男'))
仅限关键字参数
形参的最终顺序
def func(a, b, *args, sex='男',c, **kwargs):#顺序,仅限关键字参数放在两个万能参数之间
print(a,b)
print(sex)
print(args)
print(c)
print(func(1, 2, 2, 3, c='666'))
#在函数调用时,*和**表示打散(打包和解压)
2.名称空间
1.全局名称空间,局部名称空间
#全局命名空间:相对于当前的py文件
a = 1
b = 2
def func()
#局部命名空间:例如函数内的变量定义--》又称临时命名空间:随着函数调用而开辟,结束而消失
2.加载顺序,取值顺序
#内置名称空间:python源码提供的内置函数:print,input等
#三个空间加载顺寻:内置空间--》全局空间---》局部空间
#取值顺序:就近原则(从局部开始找打就打印局部,没找到再去全局去找,然后再去内置去找)
#从全局开始就从全局开始找,全局没有再去内置去找
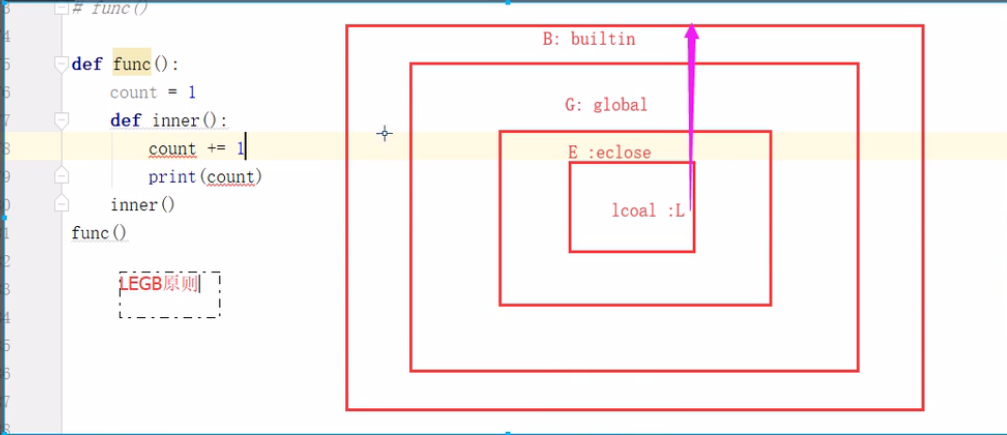
3.作用域
#全局作用域:内置名称空间,全局名称空间
#局部作用域:局部名称空间
#局部作用域可以调用全局变量
data = '周五'
def func():
print(date)
#局部变量在引用前需要赋值
#局部作用域不能改变全局作用域的变量:当python解释器读取到局部作用域时,发现你对一个变量进行修改操作,解释器会认为你已经在局部定义过这个局部变量了,他就从局部找到这个局部变量,找不到就报错了。
def func():
count += 1#需要在局部先定义
returen count
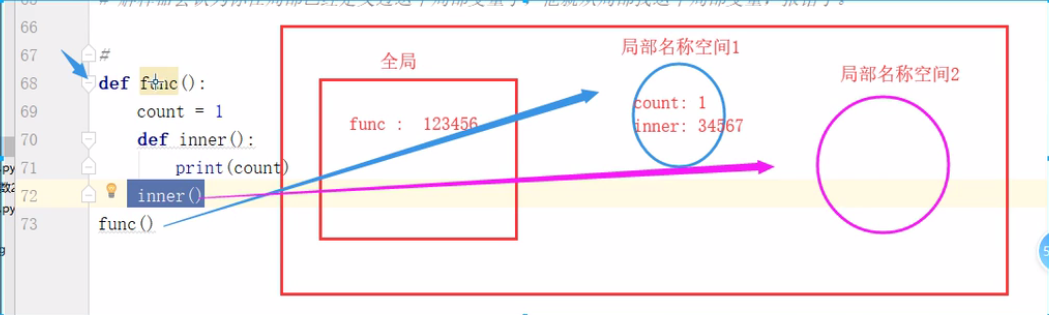
3.函数的嵌套(高阶函数)
def func():
count = 1
def inner():
print(count)
inner()
func()
4.内置函数globals, locals
a = 1
b = 2
def func():#当前作用域(局部
name = 'alex'
age = 18
print(globals())#返回的是字典:字典里面的键值对:全局作用域的所有内容
print(locals())#返回的是字典:字典里面的键值对:当前作用域的所有内容
5.关键字:nonlocal global
登录者自测表未完善
def register(n, s, a, e):
with open('用户名称', encoding='utf-8', mode='a') as f1:
f1.write('{}|{}|{}|{}\n'.format(n, s, a, e))
while 1:
name = input("请输入你的姓名:")
if name.upper() == 'Q': break
sex = input('请输入你的性别:')
if sex.upper() == 'Q': break
age = input('请输入你的年龄:')
if age.upper() == 'Q': break
edu = input('请输入你的学历:')
if edu.upper() == 'Q': break
register(name, sex, age, edu)
python笔记2021.11.29函数和迭代器
0.补充知识点,关于函数传参的%
#易错
count = 1
def func():
print(count)
count = 3
func()#报错:当在局部作用打印变量的时候,解释器会先去局部找,而定义在引用后面所以会报错
1.global nonlocal
# global:在局部作用域声明一个全局变量
name = 'coookie'
def func():
global name
name = 'alex'
print(name)
func()
print(name)#alex name被声明为全局变量,可以修改最初定义的name
#alex
#易错一
def func():
global name
name = 'alex'
print(name)
func()#因为func函数在print后面所以会发生先引用后声明的错误---》nameError
#nonlocal
#1.不能够操作全局变量
#2.局部作用域:内层函数对外层函数的局部变量进行修改
def wrapper():
count = 1
def inner():
nonlocal count
count += 1
print(count)#引用上层变量而不修改
print(count)
inner()
wrapper()#1
#2
2.函数名的运用
#func()
#1.函数名指向的是函数的内存地址,函数名 + ()就可以执行函数
def func():
print('in func')
def func1():
print('in func1')
func1 = func#可以把函数名字看成一个变量
func1()
#函数名可以作为容器类型的元素
def func():
print('in func')
def func1():
print('in func1')
def func2():
print('in func2')
l1 = [func, func1, func2]
for i in l1:
i()#in func in func1 in func2
#函数名可以作为函数的参数
def func():
print('in func')
def func1(x):
x()
print('in func1')
func1(func)#in func in func1
#函数名可以作为函数的一个返回值
def func():
print('in func')
def func1(x):
print('in func1')
return x
ret = func1(func)
ret()#in func1
#in func
3.新特性:格式化输出
#%s format需要占位比较麻烦
name = 'cookie'
age = 18
msg = '我叫%s, 今年%s' %(name, age)
msg1 = '我叫{}, 今年{}'.format(name, age)
#新特性:格式化输出,3.6版本以后
name = 'cookie'
age = 18
msg = f'我叫{name},今年{age}'#f直接输出
#可以加表达式
dic = {'name':'cookie', 'age':18}
msg = f'我叫{dic["name"]},今年{dic["age"]}'#字符串外面用单引号,字典括号里面就用双引号,反之则用单引号
print(msg)
name = 'cookie'
age = 18
msg = f'我叫{name.upper()},今年{age}'#字符串外面用单引号,字典括号里面就用双引号,反之则用单引号
print(msg)
#优点:1.结构更加清晰 2.可以结合表达式和函数使用 3.效率提升了
#注:
# ! , : { } ;这些标点不能出现在{} 这里面。
# print(f'{;12}') # 报错
# 所以使用lambda 表达式会出现一些问题。
# 解决方式:可将lambda嵌套在圆括号里面解决此问题。
x = 5
print(f'{(lambda x: x*2) (x)}') # 10
4.迭代器:
-
可迭代对象
解释:python中一切皆对象
专业角度:内部含有‘__iter__'方法的对象,是可迭代对象
-
判断一个对象是否是可迭代对象
目前学过的可迭代对象:str, list, tuple, set, dict, range, 文件句柄(文件路径)
s1 = 'sefgds' print('__iter__' in dir(s1))#Ture 判断一个对象是不是可迭代对象 -
小结(可迭代对象)
优点:1.存储数据能够直接显示,比较直观
2.拥有方法比较多,操作方便
缺点:1.占用内存比较多
2.不能直接通过for循环,或者循环取值 #迭代器才可以直接取值(for寻欢内部对其进行转化,转化成迭代器)
-
迭代器的定义
- 专业角度:内部含有专业角度:内部含有'__iter__'方法并且含有‘__next__’方法
-
判断一个对象是否是迭代器
判断对象dir()里面是否有专业角度:内部含有'__iter__'方法和含有‘__next__’方法
-
可迭代对象如何转化成迭代器,迭代器的取值
s1 = 'sdgwgew' obj = iter(s1) #s1.__iter__()转化 print(obj) print(next(obj))#print(obj.__next__()) print(next(obj))#print(obj.__next__()) print(next(obj))#print(obj.__next__()) #一个next取一个值,多了会报错 -
while循环模拟for循环机制
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99, 1, 111, 33] ret = iter(l1) while 1: try: print(next(ret)) except StopIteration: break -
小结(迭代器)
优点:1.节省内存:迭代器在内存中相当于只占一个数据的空间:因为每次取值上一条数据都会被释放,加载当前的此条数据
2.惰性机制:一次取一个值,不会多取值
有一个迭代器模式可以很好的解释上面这两条:迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。这就是迭代器模式。
迭代器的缺点:
1.速度慢(时间换空间)
2. 不能直观的查看里面的数据。
3.取值时不走回头路,只能一直向下取值。(每次都会记住取值位置)
l1 = [11,22,33,44,55,66,77,88,99,1,111,33] ret = iter(l1) for i in range(4): print(next(ret)) for i in range(3): print(next(ret)) #前提在同一个进程内 #11 #22 #33 #44 #55 #66 #77 -
可迭代对象与迭代器的对比
可迭代对象:是一个操作方法比较多,比较直观存储数据相对少(几百万数据,8g内存可以承受)的一个数据集
用途:当你侧重于对于数据可以灵活处理,并且内存空间足够,将数据集设置为可迭代对象是明确的选择。
迭代器: 是一个非常节省内存,可以记录取值位置,可以直接通过循环+next方法取值,但是不直观,操作方法比较单一的数据集。
应用:当你的数据量过大,大到足以撑爆你的内存或者你以节省内存为首选因素时,将数据集设置为迭代器是一个不错的选择。(可参考为什么python把文件句柄设置成迭代器)。
python笔记2021.11.30迭代器、生成器、列表推导式、内置函数
1.生成器
什么是生成器?这个概念比较模糊,各种文献都有不同的理解,但是核心基本相同。生成器的本质就是迭代器,在python社区中,大多数时候都把迭代器和生成器是做同一个概念。不是相同么?为什么还要创建生成器?生成器和迭代器也有不同,唯一的不同就是:迭代器都是Python给你提供的已经写好的工具或者通过数据转化得来的,(比如文件句柄,iter([1,2,3])。生成器是需要我们自己用python代码构建的工具。最大的区别也就如此了。
获取生成器的三次方式:
生成器函数
生成器表达式
-
yield
#生产器函数 def func(): print(111) print(222) yield 3 yield 4 ret = func() print(next(ret))#111 222 都是打印出来的,3才是取出来的,一个next对应一个yield #return 和 yield 的区别 # return一般在函数中只设置一个,他的作用是终止函数,并且给函数的执行者返回值。 # yield在生成器函数中可设置多个,他并不会终止函数,next会获取对应yield生成的元素。 #第一种是直接把包子全部做出来,占用内存。 def eat(): lst = [] for i in range(1,10000): lst.append('包子'+str(i)) return lst e = eat() print(e) #吃包子:吃一个生产一个,非常的节省内存,而且还可以保留上次的位置。 def gen_func(): for i in range(1, 5000): yield f'{i}号包子' ret = gen_func() for i in range(1,201): print(next(ret)) -
yield from
def func(): l1 = [1, 2, 3, 4, 5] yield from l1#相当于将l1这个列表变成一个迭代器返回 ret = func() print(next(ret)) print(next(ret)) #1 #2 def func(): l1 = [1, 2, 3, 4, 5] l2 = [6, 7, 8, 9, 10] yield from l1 #等价于yield 1 #yield 2 #yield 3 #yield 4 #yield 5 yield from l2 #等价于yield 6 #yield 7 #yield 8 #yield 9 #yield 10 ret = func() print(next(ret)) print(next(ret)) print(next(ret)) print(next(ret)) print(next(ret)) print(next(ret)) #1 #2 #3 #4 #5 #6
2.生成器表达式、列表推导式
列表推导式:用一行代码去构建一个比较复杂且有规律的的列表
l1 = []
for i in range(1,11):
l1.append(i)
print(l1)
#列表推导式:把上述代码用一行列表来构建
#情况一:循环模式【变量(加工后的变量) for 变量 in iterable】
l1 = [i for i in range(1,11)]
print(l1)
#将10以内所有整数的平方写入列表。
l1 = [i**2 for i in range(1,11)]
print(l1)
#100以内所有的偶数写入列表.
l1 = [ i for i in range(1,101,2)]
print(l1)
#从python1集到python100集写入列表lst
l1 = [ f'python第{i}集' for i in range(1,101)]
print(l1)
#情况二:筛选模式【变量(加工后的变量) for 变量 in iterable if 条件】
#100以内所有的偶数写入列表.
l1 = [ i for i in range(1,101) if i%2==0]
print(l1)
#30以内能被3整除的数
l1 = [ i for i in range(1,31) if i%3==0]
print(l1)
#过滤掉长度小于3的字符串列表,并将剩下的转换成大写字母
l1 = [ 'barry', 'ab', 'wo', 'cookie']
l2 = [str1.upper() for str1 in l1 if len(str1) <= 3]
print(l2)
#情况三:嵌套模式
#找到嵌套列表中名字含有两个‘e’的所有名字(有难度)
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
#思路
l1 = []
for i in names:
for j in i:
if j.count('e')==2:
l1.append(j)
print(l1)
#列表推导式解决方法
l1 = [name for i in names for name in i if name.count('e')==2]#去掉:和append然后变成列表推导式
print(l1)
生成器表达式
#与列表推导式几乎一样
#列表推导式与生成器表达式区别写法上【】换成(),
#本质上一个是iterable(可迭代对象) iterator(迭代器)
obj = (i for i in range(1,11))#方括号变成小括号就是生成器
for i in obj:
print(i)
总结:
列表推导式:
缺点:
1.有毒。列表推导式只能构建比较复杂并且有规律的列表。会让人上瘾
2.超过三层循环才能构建成功的不建议使用
3. 排错不行
优点:
1.一行构建简单
2.装逼哈哈哈哈
#构建一个列表
l1 = [i for i in range(2,11)] + list('GGJIO')
print(l1)
字典推导式
lst1 = ['jay','jj','meet']
lst2 = ['周杰伦','林俊杰','郭宝元']
dic = {lst1[i]:lst2[i] for i in range(len(lst1))}
print(dic)
3.内置函数
了解
#python 提供了68个内置函数
#eval 剥去字符串的外衣,运算里面的代码(非常危险,开发项目的时候容易中毒,不要使用)
s1 = '1+3'
print(eval(s1))#4,sql注入,网络传输的时候绝对不可以用eval
#type:查看类型
#exec:与eval几乎一样,但是是处理代码流的(都有可替代的建议不用)
msg = """
for i in range(1,10)
print(i)
"""
#help(帮助文档)
#callable:检查一个对象是否可以调用--》函数名可以调用
由于我们这没有表格的功能,我把这些内置函数进行分类:
黄色一带而过:all() any() bytes() callable() chr() complex() divmod() eval() exec() format() frozenset() globals() hash() help() id() input() int() iter() locals() next() oct() ord() pow() repr() round()
红色重点讲解:abs() enumerate() filter() map() max() min() open() range() print() len() list() dict() str() float() reversed() set() sorted() sum() tuple() type() zip() dir()
蓝色未来会讲: classmethod() delattr() getattr() hasattr() issubclass() isinstance() object() property() setattr() staticmethod() super()
上面的黄色,红色的内置函数是在这两天讲完的(讲过的就不讲了),蓝色的讲完面向对象会给大家补充,剩余还有一些课上就不讲了,课下练习一下就可以。
python笔记2021.12.01匿名函数(lambda),闭包,内置函数
0.字典前端有关的题目
x = {'name':'alex',
'Values':[{'timestamp':1517991992.94,'Values':110,},
{'timestamp':1517991992.93,'Values':120,},
{'timestamp':1517991992.92,'Values':300,},
{'timestamp':1517991992.91,'Values':200,},
{'timestamp':1517991992.90,'Values':10,},]
}#换成下面这样的前端界面才可以识别,上面这样的字典前端界面无法识别
#将上面数据类型换为:[[1517991992.94, 110], [1517991992.93, 120], [1517991992.92, 300], [1517991992.91, 200], [1517991992.9, 10]]
print([[i['timestamp'], i['Values']] for i in x.get('Values') ])
1.匿名函数(一句话函数)
#lambda(等价于def) 定义形参:返回值
func1 = lambda a,b:a + b
print(func(1,2))
#写匿名函数:接收两个int参数,将较大的数据返回。
func2 = lambda a,b: a if a > b else b
print(fun2(2,5))
#写匿名函数,:接收一个可切片的数据,返回索引为0与2的对应的元素(元组形式)。
func3 = lambda a: (a[0], a[2])
a = (1, 2, 3, 4)
print(func3(a))
2.内置函数(了解)
bin#将十进制转化为二进制字符串返 **
otc#将十进制转化成八进制字符串返回 **
hex#将十进制转化为十六进制字符串返回 **
divmod#计算除数与被除数之间的商数和余数,后面求分页可能会用到 **
print(divmod(10,3))#(3, 1)
round#:保留浮点数的小数位的有效位数
print(round(3.141592653,4))#3.1416
pow#:求x**y次幂。(三个参数为x**y的结果会对z取余)**
print(pow(2,3))#8
print(pow(2,3,3))#二的三次幂对三取余,2
bytes ***
s1 = 'cookie'
#b=s1.encode('utf-8')
b = bytes(s1,encoding='utf-8')
print(b)
ord#:输入字符找该字符编码的位置 **
print(ord('a'))#97
print(ord('中'))#20013 unicode码,超出ascall码的都是Unicode码
chr#:输入位置数字找出其对应的字符 **(例子:用于随机验证码)
print(chr(97))#a
repr#:返回一个对象的string形式(原形毕露)
s1 = 'cookie'
print(repr(s1))#看字符串原型态,'cookie'
all#:判断可迭代对象全是真才为真
l1 = [1,2,'f','']
print(all(l1))#False
3.内置函数(重要)
print#源码def print(self, *args, sep=' ', end='\n', file=None):
# known special case of print
"""
#ist() 将一个可迭代对象转换成列表
#tuple() 将一个可迭代对象转换成元组
#dict() 通过相应的方式创建字典。
#abs() 返回绝对值
i = -5
print(abs(i)) # 5
sum()#: 求和
print(sum([1,2,3]))
print(sum((1,2,3),100))
min() 求最小值max() 最大值与最小值用法相同。
ret = min([1,2,-5,],key=abs) # 按照绝对值的大小,返回此序列最小值
print(ret)
# 加key是可以加函数名,min自动会获取传入函数中的参数的每个元素,然后通过你设定的返回值比较大小,返回最小的传入的那个参数。
print(min(1,2,-5,6,-3,key=lambda x:abs(x))) # 可以设置很多参数比较大小
dic = {'a':3,'b':2,'c':1}
print(min(dic,key=lambda x:dic[x]))
# x为dic的key,lambda的返回值(即dic的值进行比较)返回最小的值对应的键
l2 = [('cookie',18), ('aokang',20), ('xiaoli',21)]
print(min(l2,key=lambda x:x[1]))#数字是每个数组的第二个对象所以按下标1来比较
reversed() 将一个序列翻转, 返回翻转序列的迭代器 reversed 示例:
l = reversed('你好') # l 获取到的是一个生成器
print(list(l))
ret = reversed([1, 4, 3, 7, 9])
print(list(ret)) # [9, 7, 3, 4, 1]
zip() 拉链方法。函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,
然后返回由这些元祖组成的内容,如果各个迭代器的元素个数不一致,则按照长度最短的返回,
lst1 = [1,2,3]
lst2 = ['a','b','c','d']
lst3 = (11,12,13,14,15)
for i in zip(lst1,lst2,lst3):
print(i)
#(1, 'a', 11)
#(2, 'b', 12)
#(3, 'c', 13)
sorted排序函数
和lambda组合使用
lst = ['天龙八部','西游记','红楼梦','三国演义']
print(sorted(lst,key=lambda s:len(s)))
结果:
['西游记', '红楼梦', '天龙八部', '三国演义']
lst = [{'id':1,'name':'alex','age':18},
{'id':2,'name':'wusir','age':17},
{'id':3,'name':'taibai','age':16},]
# 按照年龄对学生信息进行排序
print(sorted(lst,key=lambda e:e['age'],reverse=Ture)) #默认从低到高,当reverse=False的时候从大到小输出
结果:
[{'id': 3, 'name': 'taibai', 'age': 16}, {'id': 2, 'name': 'wusir', 'age': 17}, {'id': 1, 'name': 'alex', 'age'
filter筛选过滤
语法: filter(function,iterable)
function: 用来筛选的函数,在filter中会自动的把iterable中的元素传递给function,然后根据function返回的True或者False来判断是否保留此项数据
iterable:可迭代对象
lst = [{'id':1,'name':'alex','age':18},
{'id':1,'name':'wusir','age':17},
{'id':1,'name':'taibai','age':16},]
ls = filter(lambda e:e['age'] > 16,lst)
print(list(ls))
#map 列表推导式的循环模式,返回的是迭代器,与列表推导式速度一样只是返回对象不一样
l1 = [1, 4, 9, 16, 25]
print([i**2 for i in range(1,6)])
ret = map(lambda x:x**2, l1)
print(list(ret))
#reduce
from functools import reduce
def func(x,y):
return x * 10 + y
l = reduce(func, [1,2,3,4])
print(l)
4.闭包
#1.闭包只能存在嵌套函数中
#封闭的东西:保证数据的安全
#2.闭包的定义:内存函数对外层函数的非全局变量的引用(或使用),就会形成闭包
#被引用的非全局变量也称作自由变量,这个自由变量会与内层函数产生一个绑定关系,自由变量不会在内存中消失
# 例如:整个历史中的某个商品的平均收盘价。什么叫平局收盘价呢?就是从这个商品一出现开始,每天记录当天价格,然后计算他的平均值:平均值要考虑直至目前为止所有的价格。
# 比如大众推出了一款新车:小白轿车。
# 第一天价格为:100000元,平均收盘价:100000元
# 第二天价格为:110000元,平均收盘价:(100000 + 110000)/2 元
# 第三天价格为:120000元,平均收盘价:(100000 + 110000 + 120000)/3 元
def make_averager():
l1 = []
def averager(new_value):
l1.append(new_value)
total = sum(l1)
return total/len(l1)
return averager
avg = make_averager()#这条函数等于averager:通过函数的嵌套理解
print(avg(110000))
print(avg(100000))
#二、如何判断一个嵌套函数是不是闭包
#判断条件
#1.闭包只能存在嵌套函数中
#2.内层函数对外层函数非全局变量的引用(使用),就会形成闭包
# 例一:
def wrapper():
a = 1
def inner():
print(a)
return inner
ret = wrapper()#是
# 例二:
a = 2
def wrapper():
def inner():
print(a)
return inner
ret = wrapper()#不是
# 例三:
def wrapper(a,b):
def inner():
print(a)
print(b)
return inner
a = 2
b = 3
ret = wrapper(a,b)#是,传值传进去也会在局部开辟空间
#如何用代码判断闭包?---也就是判断有无自由变量
print(ret.__code__.co_freevars)#
l1存在的原因就是闭包现象,自由变量

python笔记2021.12.07装饰器,开放封闭原则
题目:求解+理解
#求结果
def num():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in num()])
1.装饰器
#装饰器:装饰,举例:对房子进行装修,增加了许多功能,可以洗澡,看电视
#开放封闭原则
#开放:对代码的拓展开放的,例如加新地图
#封闭:对源码的修改式封闭的;例如:走路,跑步基本功能不会改变
#装饰器:1.完全遵循开放封闭原则---装饰器就是一个函数
#装饰器:2.在不改变原函数的代码以及调用方式的前提下,为其增加新的功能。
#版本一:写一下代码测试index函数的执行效率
def index():
time.sleep(3)
print('欢迎登录博客园首页!')
import time
# print(time.time())#格林威治时间
def timmer(f): #f = index function index123
def inner(): # inner function inner123
start_time = time.time()
f()#index() function index123
end_time = time.time()
print(end_time - start_time) # 模拟网络延迟和代码运行效率
return inner
index = timmer(index)#inner function inner123
index()#inner()
#标准版本:语法糖版本
import time
# print(time.time())#格林威治时间
def timmer(f):#装饰器必须放在这些函数最前面
def inner():
start_time = time.time()
f()
end_time = time.time()
print(end_time - start_time) # 模拟网络延迟和代码运行效率
return inner
@timmer #index = timmer(index),语法糖
def index():
time.sleep(3)
print('欢迎登录博客园首页!')
index()#inner
def dariy():
time.sleep(3)#模拟的网络延迟或者代码效率
print('欢迎登录日记页面!')
dariy()#没有加@itmmer所以没有执行装饰器
#版本三:关于return的部分
import time
# print(time.time())#格林威治时间
def timmer(f):
def inner():
start_time = time.time()
r = f()
end_time = time.time()
print(end_time - start_time) # 模拟网络延迟和代码运行效率
return r
return inner
@timmer #index = timmer(index),语法糖
def index():
time.sleep(0.6)
print('欢迎登录博客园首页!')
return 999
ret = index()
print(ret)
@timmer#要加函数头部前面
def dariy():
time.sleep(0.6)#模拟的网络延迟或者代码效率
print('欢迎登录日记页面!')
return 666
ret = dariy()
print(ret)
#加上装饰器不应该改变原函数的返回值,所以666,应该返回给我下面的ret.
#但是下面的这个ret实际接收的是inner函数的返回值,而666返回给的是装饰器里面的f()也就是r,我们现在要解决的问题是将r给inner返回值
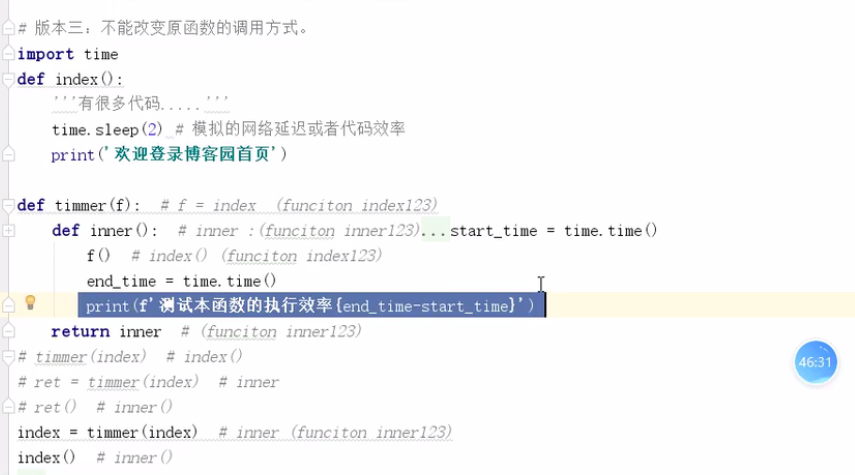
#版本四:被装饰函数带参数,最标准的装饰器
import time
# print(time.time())#格林威治时间
def timmer(f):
def inner(*args,**kwargs):
#函数的定义时:*表示聚合
start_time = time.time()
r = f(*args,**kwargs)#kwargs接收除常规参数列表职位的键值参数字典
#函数的执行时 *表示打散
end_time = time.time()
print(end_time - start_time) # 模拟网络延迟和代码运行效率
return r
return inner
# @timmer #index = timmer(index),语法糖
def index(name):
time.sleep(0.6)
print(f'欢迎{name}登录博客园首页!')
return 999
index('cookie')
@timmer#要加函数头部前面
def dariy(name,age):
time.sleep(0.6)#模拟的网络延迟或者代码效率
print(f'欢迎{name}{age}岁登录日记页面!')
return 666
dariy('cookie',18)
#标准版装饰器模板
def wrapper(f);
def inner(*args,**kwargs)
'''添加额外功能:执行被装饰函数之前的操作数''
ret = f(*args,**kwargs)
''''添加额外功能:执行被装饰之后的操作'''''
return ret
return inner
2.装饰器的应用:登录认证(写一个装饰器认证)
python笔记2021.12.08自定义模块,加密模块加密登录,模块的多种导入
python语言中,模块哦分为三类:
- 第一类:内置模块,也叫做标准库。此类模块就是python解释器给你提供的,比如我们之前见过的time模块,os模块。标准库的模块非常多(200多个,每个模块又有很多功能)
- 第二类:第三方模块,第三方库。一些python大神写的非常好用的模块,必须通过pip install 指令安装的模块,比如BeautfulSoup, Django,等等。大概有6000多个
- 第三类:自定义模块。我们自己在项目中定义的一些模块。
一、编写好的一个python文件可以有两种用途:
脚本:一个文件就是整个程序,用来被执行(比如你之前写的模拟博客园登录那个作业等)
模块:文件中存放着一堆功能,用来被导入使用
(1)自定义模块:我们先定义一个模块,定义一个模块其实很简单就是写一个文件,里面写一些代码(变量,函数)即可。此文件的名字为cookie.py,文件内容如下:
模块中出现for循环,if语句、函数定义等它们统称为模块的成员
print('from the cookie.py')
name = 'cookie1'
def read1():
print('cookie模块:',name)
def read2():
print('cookie模块')
read1()
def change():
global name
name = 'array'
(2)自定义模块被其他模块导入的时候,其中的可执行语句会立即执行
(3)python中提供一种检测方法来检测程序是开发阶段还是 使用阶段
(4)__name__:脚本方式运行时,固定的字符串:pritn(__name__) 输出__main__
(5)以导入方式运行时,__name__就是文件名
#作用:用来控制.py文件在不同的应用场景下执行不同的逻辑(或者是在模块文件中测试代码)
if __name__ == '__main__'#说明这是在开发阶段,在被导入的文件中
'''函数语句'''
二、系统导入模块的路径
-
内存中:如果之前成功导入过一个模块 ,直接使用已经存在的模块
-
内置路径中:安装路径下:lib
-
sys.path:是一个路径的列表
-
如果以上三个都找不到就报错
-
动态修改sys.path:os.path.dirname():获取某个路径的父路径。通常用于获取当前模块的相对路径
#添加要导入文件的路径到sys.path中,如果因为路径问题文件无法导入 import sys #sys.path.append(r'导入模块文件路径') #print(__file__)#当前文件的绝对路径 #使用相对路径找到导入文件夹的位置 #使用os模块获取一个路径的父路径 import os print(os.path.dirname(__file__) + '/导入模块文件路径')
三、导入模块的多种方式
import xxx :导入一个模块的所有成员
from xxx import xxx:从某个模块中导入某个成员
from xxx import x,y,z:从某个模块中导入多个成员
from xxx import *:导入一个模块的所有成员,默认全部导入'__aLL__'是一个列别(仅作用于本导入方式),用于控制被导入的成员在模块中写入,__all__ =['函数名',] ,
#import xxx和from xxx import *的区别
#第一种需要使用文件名当前缀,不会产生命名冲突
#第二个可以直接使用成员名,可能会产生命名冲突
#怎么解决命名冲突
#使用别名解决冲突:alias
from xxx import xx as a
#相对导入同项目下的模块
#从当前目录路径开始
from 相对路径 import xxx
相对路径:linux文件路径一样

四、random模块
#此模块提供了随机数的方法
import random
random.random():获取[0.0,1.0]范围内的浮点数
random.randint(a,b):[a,b]获取范围内的整数
random.uniform():获取[a,b)范围内的浮点数
random.shuffle(x):把参数指定的数据中的元素打乱,参数必须是一个可变数据类型
random.sample(x,k):从x中随机抽取k个数据,组成一个列表返回
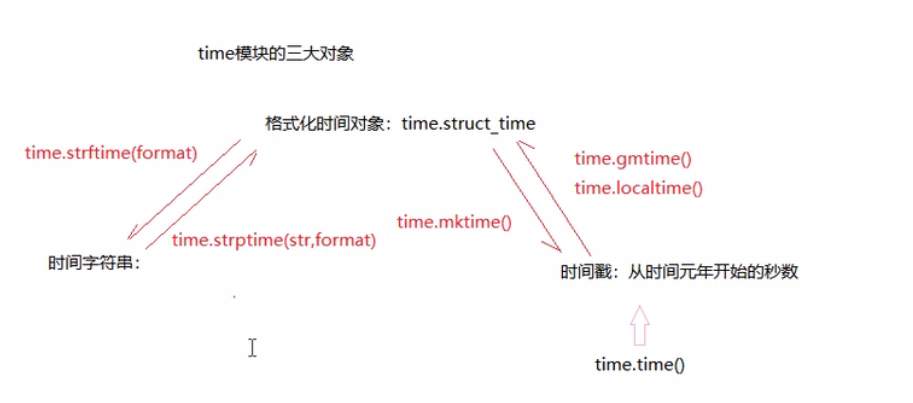
五、time模块
#这个模块封装了获取时间和字符串时间
import time
print(time.time())#获取时间戳:从时间元年(1970.01.01.00:00:00)到现在经过的秒速
#获取格式化时间对象:是九个字段组成的
print(time.gmtime)#格林尼治时间
#打印当地时间
print(time.localtime())
#时间对象转换成时间戳
t1 = time.localtime() #时间对象
t2 = time.mktime(t1) #获取对应的时间戳
#格式化时间对象和字符串之间的转换
s = time.strftime('%Y %m %d %H: %M: %S')
print(s)#2021 12 09 20: 30: 01
#把时间字符串转换成时间对象
time_obj= time.strptime('%Y %m %d','2019 09 01')
print(time_obj)
#time.struct_time(tm_year=2019, tm_mon=9, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=244, tm_isdst=-1)指定的有时间,没指的使用默认值
#暂停当前的线程,随眠xxx秒
#time.sleep(xxx)
for i in range(5):
print(time.strftime('%Y %m %d %H :%M :%S'))
time.sleep(1)
六、datetime模块
import datetime
#date类
d = datetime.date(2021,10,10)
#获取date对象的各个属性:获取年月日
print(d.year)
print(d.month)
print(d.day)
t = datetime.time(10, 48, 59)
##获取time对象的各个属性:获取时分秒
print(t.hour)
print(t.minute)
print(t.second)
#datetime中的类,主要用于数学计算的
dt = datetime.datetime(2020,11,2,11,11,11)
print(dt)#2020-11-02 11:11:11
#时间变化量
td = datetime.timedelta(days=1)
d = datetime.date(2020,1,1)
res = d - td
print(res)#2019-12-31
#时间变化量会产生进位
t = datetime.datetime(2020,10,10,10,59,59)
s = datetime.timedelta(seconds=1)
# d = datetime.date(2020,1,1)
res = t + s
print(res)#2020-10-10 11:00:00
#练习:计算某一年的二月份有多少天
#普通算法:根据年份计算是否是闰年
#用datetime模块
#首先创建出指定年份的3月1号,然后让它往前走一天
year = int(input('输入年份:'))
#创建指定年份的date对象
d = datetime.date(year,3,1)
td = datetime.timedelta(days=1)
res = d - td
print(res)
#和时间段进行运算的结果 类型是什么
d = datetime.date(2019,3,1)
td = datetime.timedelta(days=1)
res = d - td
print(type(res))#结果类型和第一个操作数类型保持一致
七、os模块 sys模块
#和文件操作相关,重命名,和删除
import os
os.remove('a.txt')#删除文件
os.rename('a.txt','b.txt')#重命名文件
os.removedirs('空文件名')#只能删除空文件夹
import shutil#此模块可以删除有内容的文件夹
shutil.rmtree('文件名')
#和路径相关的操作,被封装到另外一个子模块:os.path
os.path.dirname(r'路径')#不判断路径是否存在,取文件上级路径
os.path.basename(r'文件路径')#取文件名
os.path.split(r'文件路径')#分离文件名和路径
print(os.path.join('d:\\','sss','dddd'))#拼接文件路径
#如果是/开头的路径,默认就是在当前盘符下(当前文件路径下)
res = os.path.abspath(r'/a/b/c')
print(res)#G:\a\b\c
#如果不是/开头的路径,默认就是在当前文件路径下
res = os.path.abspath(r'/a/b/c')
print(res)#G:\python代码\pythonProject\leecode\a\b\c
print(os.path.isdir('文件名'))#判断文件是否存在
print(os.path.isfile('文件名'))#判断是不是文件
#sys模块和python解释器相关
#获取命令行方式运行的脚本后面的参数
import sys
print('脚本名: ',sys.argv[0]) #脚本名
print(sys.argv[0]) #第一个参数
#解释器去寻找模块的路径
#sys.path
#返回已经加载的模块
print(sys.modules)
八、json模块
#javaScript Object Notation:已经成为一种简单的数据交换格式#json:将数据转换成字符串,用于存储或网络传输,通常一次性写,一次性读import jsons = json.dumps([1,2,3])#把指定的对象转换成json格式的字符串print(s)print(type(s))s = json.dumps((1,2,3))#元组序列化后,变成列表print(s)#[1,2,3]import jsonres = json.dumps({'name':'cookie','age':10,})print(res)#{"name": "cookie", "age": 10}print(type(res))#<class 'str'>#将json结果写到文件中with open('a.txt', encoding='utf-8',mode='at') as f1: json.dump([1,2,3],f1) #反序列化:元组会变成列表res = json.dumps([1,2,3])#dumps序列化到内存中,dump序列化到文件中lst = json.loads(res)#反序列化print(type(lst))#从文件中反序列化with opne('a.txt',mode='r,encoding='utf-8') as f1: json.load() # 使用文件的write方法实现多次写json序列化数据with open('json.txt', mode='at', encoding='utf-8') as f: f.write(json.dumps([1, 2, 3]) + '\n') f.write(json.dumps([4, 6, 5]) + '\n')# 一行一行反序列化with open('json.txt', mode='rt', encoding='utf-8') as f: json.loads(f.readline().strip()), json.loads(f.readline().strip())
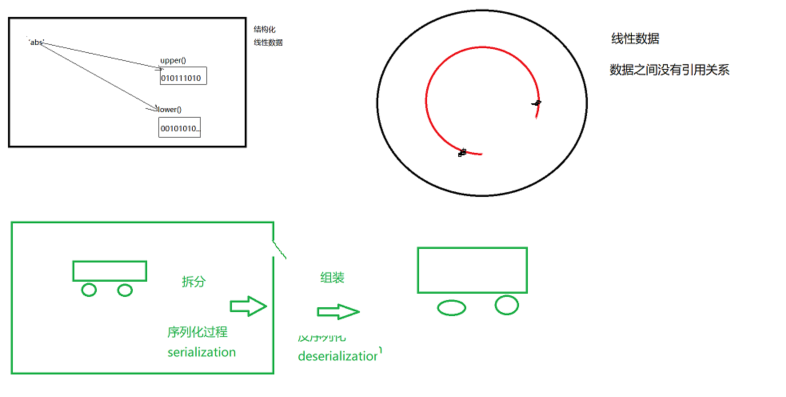
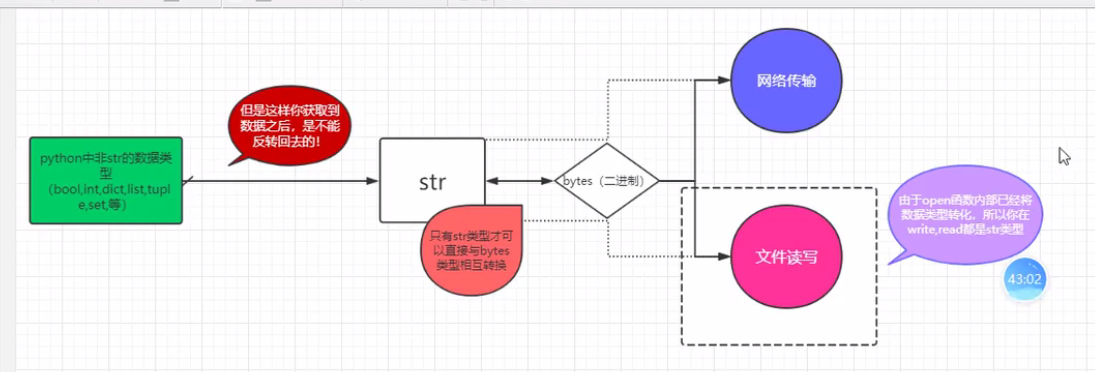
序列化:将内存中的数据,转换成字节串,用以保存在文件或通过网络传输,称为序列化过程
反序列化:从文件,网络中获取的数据,转换成内存中原来的数据类型,称为反序列化过程
九、pickle模块
#所有的数据类型都可以通过此模块进行序列化import picklebys = pickle.dumps(set('abs'))res = pickle.loads(bys)print(type(res))#<class 'set'> #多次pickle数据写到同一个文件中with open('b.txt',mode='rb') as f1: for i in range(n): res = pickle.load(f1) print(res)#多次反序列化 #pickle常用场景:和json一样,一次性写入,一次性读取#区别:只能用于python,json可以跨语言#可以多次读写
十、hashlib模块
#封装一些用于加密的类#加密的目的:用于判断和验证,而不是解密#特点:把一个大的数据,切分成不同的块,分别对不同的块进行加密,再汇总的结果,和直接对整体数据加密的结果是一致的#单向加密,不可逆#原始数据的一点差异将导致雪崩式变化 #md5加密算法 ```给数据加密的三大步骤: 1.获取一个加密对象 2.使用加密的对象的update进行加密 3.通过hexdigest或digest方法获取加密结果
import hashlib
获取一个加密对象
m = hashlib.md5()
m.update('afs'.encode('utf-8'))
通过hexdigest获取加密结果
res = m.hexdigest()
print(res)
sha系列加密算法:sha224(32),sha256(64)
s = hashilb.sha224()
十一、collect模块```python#容器类namedtuple():命名元组defaultdict():默认值字典Counter():计数器 from collections import namedtuple#namedtupleRectangle = namedtuple('Rectangle_class',['length','width'])r = Rectangle(10,5)#通过属性访问元组的元素print(r.length)print(r.width)#通过索引访问元组的元素print(r[0])print(r[1])#10#defaultldict()from collections import defaultdict,Counterd = defaultdict(int, name='Andy', age=10)print(d['age'])#计数打印出现次数前三的c = Counter('asdfsdhfsdahfksadhfksadhfashdfkbscgrwefv')print(c.most_common(3))
十二、加密登录注册列题
import hashlib#注册和登录def get_md5(username,passwd): m = hashlib.md5() m.update(username.encode('utf-8')) m.update(passwd.encode('utf-8')) return m.hexdigest()def register(username, password): res = get_md5(username,password) with open('user.txt',mode='a+',encoding='utf-8') as f1: f1.write(res)def login(username,passwd):#获取当前登录信息 res = get_md5(username, passwd) #读取文件与其中数据进行对比 with open('user.txt',mode='rt',encoding='utf-8') as f2: for line in f2: line.strip() if res == line.strip(): return 1 else: return 0while True: op = int(input("1.注册 2.登录 q.退出\n")) if op == 1: username = input('请输入的用户名:') password = input('请输入你的用户密码:') register(username,password) elif op == 2: username = input('请输入的用户名:') password = input('请输入你的用户密码:') res = login(username,password) if res: print('登录成功!') else: print("请先注册账户!") username = input('请输入的用户名:') password = input('请输入你的用户密码:') register(username, password) elif op == 'q': print('退出!') break
python笔记2021.12.11自定义模块,hashlib等
1.自定义模块
2.模块是什么?:就是一个py文件
抖音:20万行代码放在不同的文件中
为什么不能放一个文件?
-
代码太多,读取代码耗时太长。
-
代码不容易维护
-
所以将py文件拆分成100或多个文件,每个文件相识功能的函数提取出来。
3.为什么要有模块
-
拿来主义,提高开发效率
-
便于管理和维护
4.模块的分类
- 内置模块。python解释器自带的模块越(200多个)
- 第三方模块,一些大牛写的,需要pip install 例如:Diango,request,flask
- 自定义模块,自己写的py文件
5.import的使用
-
第一次导入模块执行三件事
-
第一次引用模块,会将这个模块里面的所有代码加载到内存中,只要你的程序没有结束,接下来不论你再应用多少次,它每次都会先去内存中找,所有只有第一次引用会执行 一便
第一次导入模块执行三件事情:- 在内存中创建一个以模块名命名的名称空间
- 执行此名称空间所有的可执行代码(将模块文件中所有的变量与值的对应关系加载到这个名称空间)
- 通过文件名+.的方式引用模块里面的函数
-
-
被导入模块有独立的名称空间
-
为模块起别名
-
简单,便捷
-
有利于代码的简化
-
起别名,统一接口,归元化思想
import mysql as my1
-
-
导入多个模块:一个一个导入
6.import ... from ...
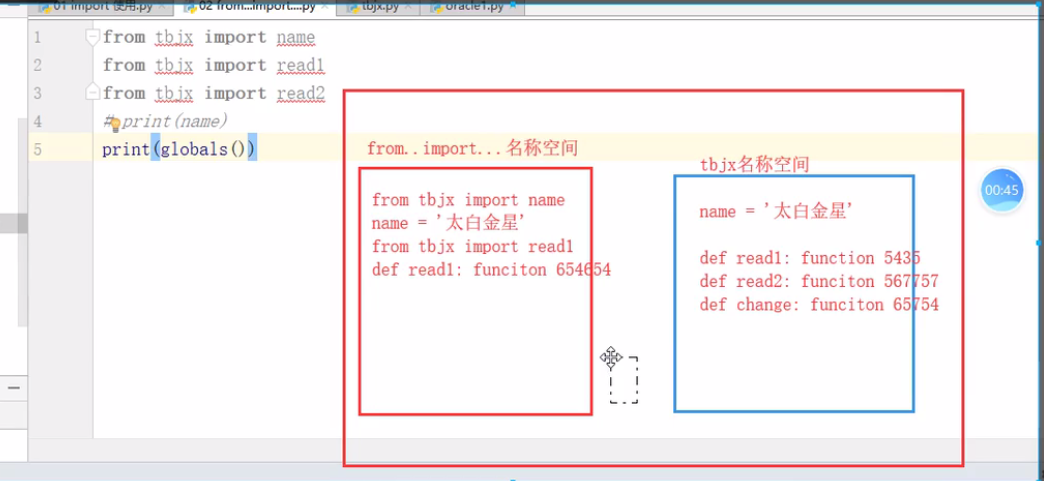
from xxx import xxx#获取模块中单个函数或类,相当于从文件模块拷贝一份到当前文件
-
import ... from ... 与import 的区别
-
import ... from ...容易与本地文件产生命名冲突
name = 'cookie' from xxx import name#文件中有name变量的赋值 print(name)#打印的name是导入文件中的,因为文件导入复制一份的时候name便指向了xxx里的name name = 'oldboy' from tbjx import name, read1, read2 print(name) ''' 执行结果: 太白金星 ''' ---------------------------------------- from tbjx import name, read1, read2 name = 'oldboy' print(name) #执行结果:oldboy
-
-
from ... import *
- 从 ... 中导入所有
-
循环导入的问题
-
py文件的两种功能
- py文件的两个功能:
- 当作脚本的时候
__name__ == __main__ - 当做模块被引用的时候
__name__ == 文件名 - 作为模块需要调试的时候,加上
if __name__ == 'main' - 2.作为项目的启动文件需要用
- 当作脚本的时候
- py文件的两个功能:
-
模块的搜索路径
-
1.先从内存中去找
-
2.会从内置的模块中去找
-
3.从sys.path中去找
-
import sys sys.path.append(r'文件路径')#当上面三个都找不到的时候,手动添加路径到sys.path
-
-
-
json和pickle模块
-
序列化模块:将一种是数据结构转化成特殊的序列
-
为什么存在序列化?
数据存储在文件中,str(bytes类型)形式存储,比如字典
数据通过网络传输,str不能还原回去
特殊的字符串:序列化
-
-
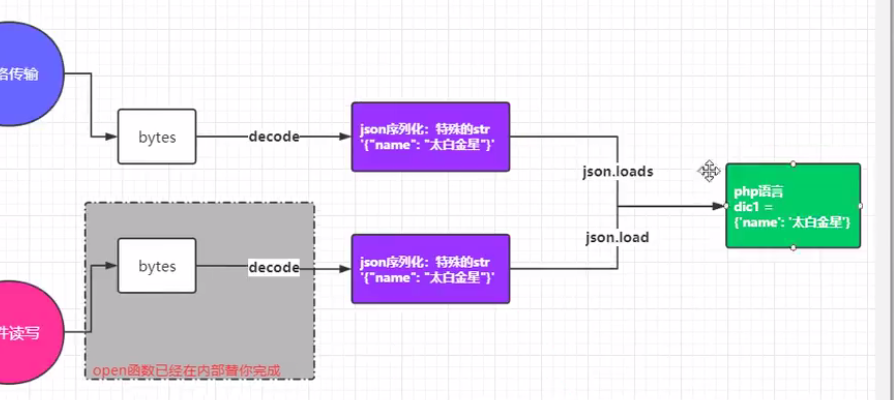
json模块:(重点)
- 1.不同语言都遵循的一种数据转化格式,即不同语言都使用的特殊字符串。(比如Python的一个列表[1,2,3]利用json转成特殊字符串,然后在编码成bytes发送给php的开发者,php的开发者就可以解码成特殊的字符串,然后再反解成原字数据
- 2.json序列化只支持Python数据结构:dict,list,tuple,int ,float,Ture, False, None
#两对四种方法:dumps,loads import json dic = { 'usernaem':'cookie', 'passwd':123, 'status':True } st = json.dumps(dic) print(st, type(st))#主要用于网络传输,也可以用于文件读写 #dunm 与 load 也能写入文件,只能写入一个数据结构 #一次写入文件多个
-
pickle模块只能在python中使用,适用于python所有的数据类型
#dumps 和 loads在此模块中只能用于网络传输 #dump 和 load 只能用于文件读写
-
hashlib模块
-
用法:
- 1.将bytes类型字节转化成固定长度的16进制数字祖成的字符串
- 2.不同的bytes利用相同的算法(MD5)转化成的结果一定不同
- 3.相同的bytes利用相同的算法(MD5)转化成的结果一定相同
- 4.hashlib算法不可逆(MD5被王晓云破解了)
MD5
import hashlib s1 = 'ashdfiowhsifohwhefwh' md = hashlib.md5() md.update(s1.encode('utf-8')) print(md.hexdigest())#0d31588927d42a1a5637bfcb7c56d51f #加盐 s1 = 'ashdfiowhsifohwhefwh' md = hashlib.md5('奥康'.encode('utf-8 '))#静态的盐,加盐 md.update(s1.encode('utf-8')) print(md.hexdigest()) #动态的盐 s2 = 'sdfsgwer' md1 = hashlib.md5('cookie'[::2].encode('utf-8')) md1.update(s1.encode('utf-8')) print(md1.hexdigest())sha系列
#随着sha系列数字越高加密越复杂:金融类,安全类用这个 #文件校验 import hashlib s1 = '123456' ret = hashlib.sha256() ret.update(s1.encode('utf-8')) print(ret.hexdigest()) #low版校验 def file_md5(path): ret = hashlib.md5() with open(path, mode='rb') as f1: b1 = f1.read() print(b1) ret.update(b1) return ret.hexdigest() result = file_md5('a.txt') print(result) #高版校验:1024字节读取 def height_md5(path): ret = hashlib.md5() with open(path,mode='rt',encoding='utf-8') as f2: while True: lines = '' line = f2.read(1024) lines += line time.sleep(0.01) if not line: break ret.update(lines.encode('utf-8')) return ret.hexdigest() result = height_md5('a.txt') print(result) -
python笔记2021.12.12软件的开发规范
软件的开发规范
1.为什么要有软件开发规范?
-
qpp 软件不可能全部写在一个文件中,不容易查找,不规范
代码越多,便需将代码分文件
-
一. 软件的开发规范
什么是开发规范?为什么要有开发规范呢?
你现在包括之前写的一些程序,所谓的'项目',都是在一个py文件下完成的,代码量撑死也就几百行,你认为没问题,挺好。但是真正的后端开发的项目,系统等,少则几万行代码,多则十几万,几十万行代码,你全都放在一个py文件中行么?当然你可以说,只要能实现功能即可。咱们举个例子,如果你的衣物只有三四件,那么你随便堆在橱柜里,没问题,咋都能找到,也不显得特别乱,但是如果你的衣物,有三四十件的时候,你在都堆在橱柜里,可想而知,你找你穿过三天的袜子,最终从你的大衣口袋里翻出来了,这是什么感觉和心情......
软件开发,规范你的项目目录结构,代码规范,遵循PEP8规范等等,让你更加清晰滴,合理滴开发。
那么接下来我们以博客园系统的作业举例,将我们之前在一个py文件中的所有代码,整合成规范的开发。
首先我们看一下,这个是我们之前的目录结构(简化版):

py文件的具体代码如下:
 View Code
View Code此时我们是将所有的代码都写到了一个py文件中,如果代码量多且都在一个py文件中,那么对于代码结构不清晰,不规范,运行起来效率也会非常低。所以我们接下来一步一步的修改:
- 程序配置.
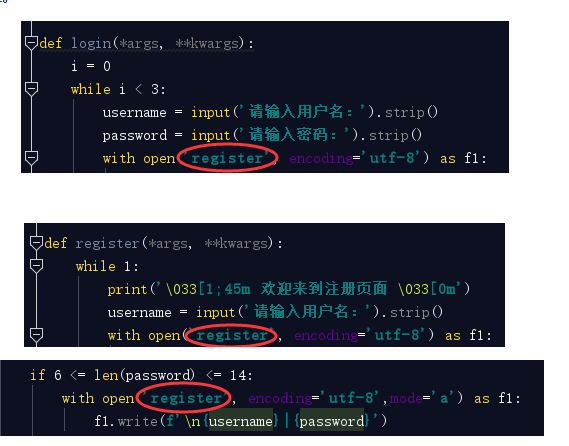
你项目中所有的有关文件的操作出现几处,都是直接写的register相对路径,如果说这个register注册表路径改变了,或者你改变了register注册表的名称,那么相应的这几处都需要一一更改,这样其实你就是把代码写死了,那么怎么解决? 我要统一相同的路径,也就是统一相同的变量,在文件的最上面写一个变量指向register注册表的路径,代码中如果需要这个路径时,直接引用即可。
- 划分文件。
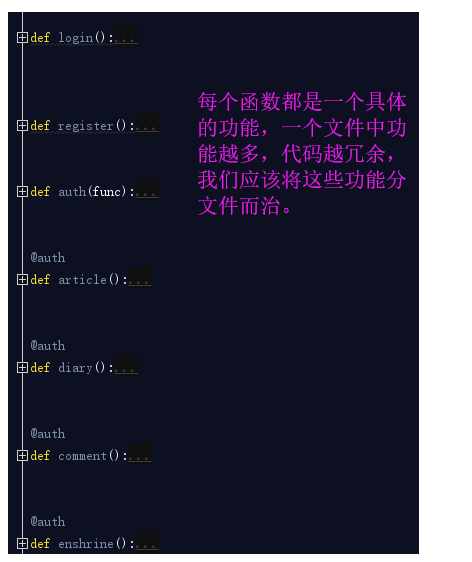
一个项目的函数不能只是这些,我们只是举个例子,这个小作业函数都已经这么多了,那么要是一个具体的实际的项目,函数会非常多,所以我们应该将这些函数进行分类,然后分文件而治。在这里我划分了以下几个文件:
settings.py: 配置文件,就是放置一些项目中需要的静态参数,比如文件路径,数据库配置,软件的默认设置等等
类似于我们作业中的这个:

common.py:公共组件文件,这里面放置一些我们常用的公共组件函数,并不是我们核心逻辑的函数,而更像是服务于整个程序中的公用的插件,程序中需要即调用。比如我们程序中的装饰器auth,有些函数是需要这个装饰器认证的,但是有一些是不需要这个装饰器认证的,它既是何处需要何处调用即可。比如还有密码加密功能,序列化功能,日志功能等这些功能都可以放在这里。
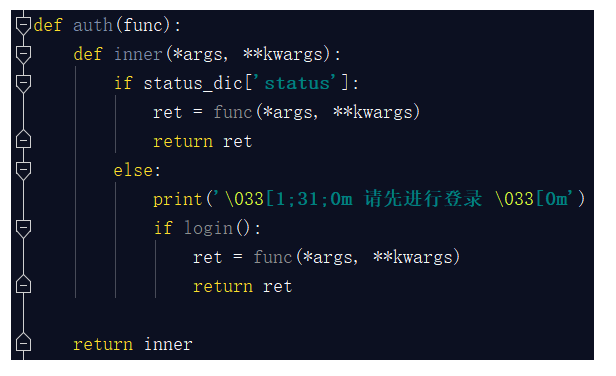
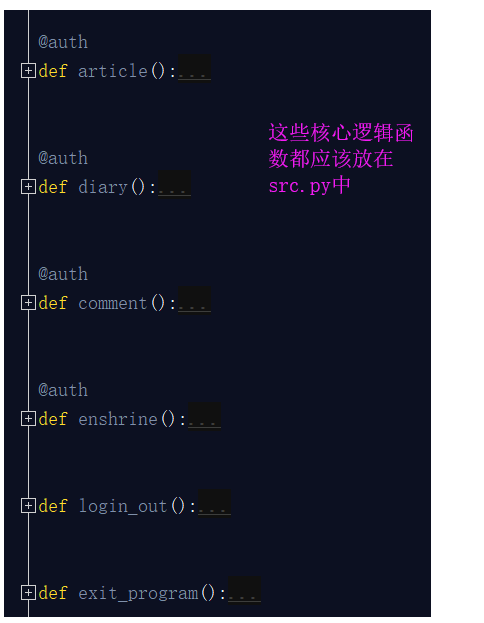
src.py:这个文件主要存放的就是核心逻辑功能,你看你需要进行选择的这些核心功能函数,都应该放在这个文件中。
start.py:项目启动文件。你的项目需要有专门的文件启动,而不是在你的核心逻辑部分进行启动的,有人对这个可能不太理解,我为什么还要设置一个单独的启动文件呢?你看你生活中使用的所有电器基本都一个单独的启动按钮,汽车,热水器,电视,等等等等,那么为什么他们会单独设置一个启动按钮,而不是在一堆线路板或者内部随便找一个地方开启呢? 目的就是放在显眼的位置,方便开启。你想想你的项目这么多py文件,如果src文件也有很多,那么到底哪个文件启动整个项目,你还得一个一个去寻找,太麻烦了,这样我把它单独拿出来,就是方便开启整个项目。
那么我们写的项目开启整个项目的代码就是下面这段:
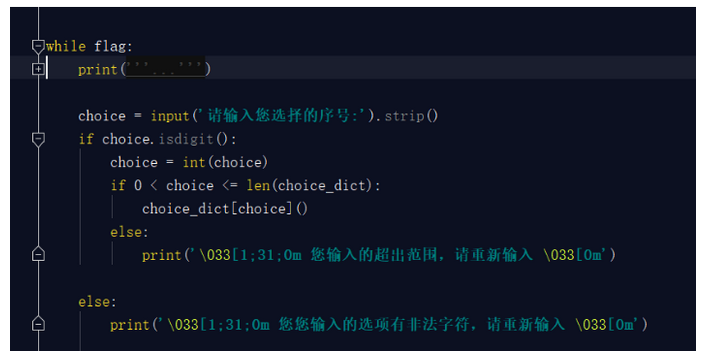
你把这些放置到一个文件中也可以,但是没有必要,我们只需要一个命令或者一个开启指令就行,就好比我们开启电视只需要让人很快的找到那个按钮即可,对于按钮后面的一些复杂的线路板,我们并不关心,所以我们要将上面这个段代码整合成一个函数,开启项目的''按钮''就是此函数的执行即可。
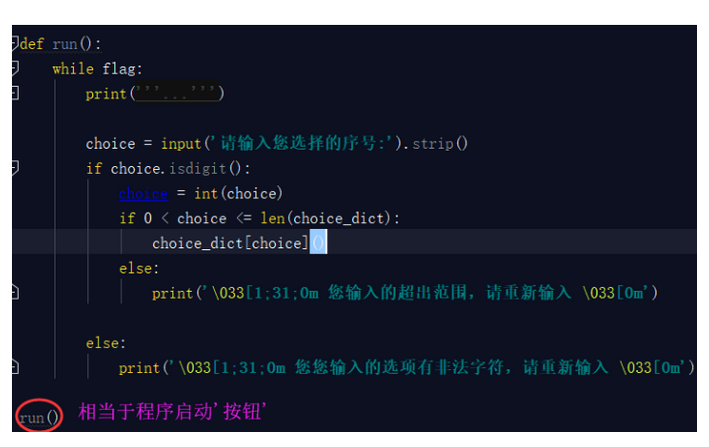
这个按钮要放到启动文件start.py里面。
除了以上这几个py文件之外还有几个文件,也是非常重要的:
类似于register文件:这个文件文件名不固定,register只是我们项目中用到的注册表,但是这种文件就是存储数据的文件,类似于文本数据库,那么我们一些项目中的数据有的是从数据库中获取的,有些数据就是这种文本数据库中获取的,总之,你的项目中有时会遇到将一些数据存储在文件中,与程序交互的情况,所以我们要单独设置这样的文件。
log文件:log文件顾名思义就是存储log日志的文件。日志我们一会就会讲到,日志主要是供开发人员使用。比如你项目中出现一些bug问题,比如开发人员对服务器做的一些操作都会记录到日志中,以便开发者浏览,查询。
至此,我们将这个作业原来的两个文件,合理的划分成了6个文件,但是还是有问题的,如果我们的项目很大,你的每一个部分相应的你一个文件存不下的,比如你的src主逻辑文件,函数很多,你是不是得分成:src1.py src2.py?
你的文本数据库register这个只是一个注册表,如果你还有个人信息表,记录表呢? 如果是这样,你的整个项目也是非常凌乱的:
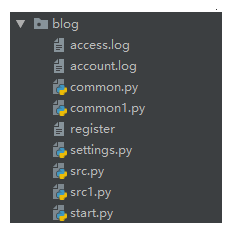
3. 划分具体目录
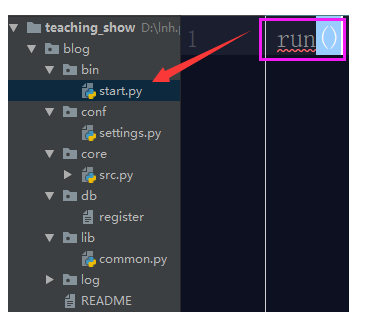
上面看着就非常乱了,那么如何整改呢? 其实非常简单,原来你就是30件衣服放在一个衣柜里,那么你就得分类装,放外套的地方,放内衣的地方,放佩饰的地方等等,但是突然你的衣服编程300件了,那一个衣柜放不下,我就整多个柜子,分别放置不同的衣物。所以我们这可以整多个文件夹,分别管理不同的物品,那么标准版本的目录结构就来了:
为什么要设计项目目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
- 一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
- 另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
- 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
- 可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。

上面那个图片就是较好的目录结构。
二. 按照项目目录结构,规范博客园系统
接下来,我就带领大家把具体的代码写入对应的文件中,并且将此项目启动起来,一定要跟着我的步骤一步一步去执行:
- 配置start.py文件
我们首先要配置启动文件,启动文件很简答就是将项目的启动执行放置start.py文件中,运行start.py文件可以成功启动项目即可。 那么项目的启动就是这个指令run() 我们把这个run()放置此文件中不就行了?
这样你能执行这个项目么?肯定是不可以呀,你的starts.py根本就找不到run这个变量,肯定是会报错的。
NameError: name 'run' is not defined 本文件肯定是找不到run这个变量也就是函数名的,不过这个难不倒我们,我们刚学了模块, 另个一文件的内容我们可以引用过来。但是你发现import run 或者 from src import run 都是报错的。为什么呢? 骚年,遇到报错不要慌!我们说过你的模块之所以可以引用,那是因为你的模块肯定在这个三个地方:内存,内置,sys.path里面,那么core在内存中肯定是没有的,也不是内置,而且sys.path也不可能有,因为sys.path只会将你当前的目录(bin)加载到内存,所以你刚才那么引用肯定是有问题的,那么如何解决?内存,内置你是左右不了的,你只能将core的路径添加到sys.path中,这样就可以了。
import sys sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\core') from src import run run()这样虽然解决了,但是你不觉得有问题么?你现在从这个start文件需要引用src文件,那么你需要手动的将src的工作目录添加到sys.path中,那么有没有可能你会引用到其他的文件?比如你的项目中可能需要引用conf,lib等其他py文件,那么在每次引用之前,或者是开启项目时,全部把他们添加到sys.path中么?
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\core') sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\conf') sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\db') sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\lib')这样是不是太麻烦了? 我们应该怎么做?我们应该把项目的工作路径添加到sys.path中,用一个例子说明:你想找张三,李四,王五,赵六等人,这些人全部都在一栋楼比如在汇德商厦,那么我就告诉你汇德商厦的位置:北京昌平区沙河镇汇德商厦。 你到了汇德商厦你在找具体这些人就可以了。所以我们只要将这个blog项目的工作目录添加到sys.path中,这样无论这个项目中的任意一个文件引用项目中哪个文件,就都可以找到了。所以:
import sys sys.path.append(r'D:\lnh.python\py project\teaching_show\blog') from core.src import run run()上面还是差一点点,你这样写你的blog的路径就写死了,你的项目不可能只在你的电脑上,项目是共同开发的,你的项目肯定会出现在别人电脑上,那么你的路径就是问题了,在你的电脑上你的blog项目的路径是上面所写的,如果移植到别人电脑上,他的路径不可能与你的路径相同, 这样就会报错了,所以我们这个路径要动态获取,不能写死,所以这样就解决了:[
 ](javascript:void(0)😉
](javascript:void(0)😉import sys import os # sys.path.append(r'D:\lnh.python\py project\teaching_show\blog') print(os.path.dirname(__file__)) # 获取本文件的绝对路径 # D:/lnh.python/py project/teaching_show/blog/bin print(os.path.dirname(os.path.dirname(__file__))) # 获取父级目录也就是blog的绝对路径 # D:/lnh.python/py project/teaching_show/blog BATH_DIR = os.path.dirname(os.path.dirname(__file__)) sys.path.append(BATH_DIR) from core.src import run run()[
](javascript:void(0)😉那么还差一个小问题,这个starts文件可以当做脚本文件进行直接启动,如果是作为模块,被别人引用的话,按照这么写,也是可以启动整个程序的,这样合理么?这样是不合理的,作为启动文件,是不可以被别人引用启动的,所以我们此时要想到
__name__了:[
](javascript:void(0)😉import sys import os # sys.path.append(r'D:\lnh.python\py project\teaching_show\blog') # print(os.path.dirname(__file__)) # 获取本文件的绝对路径 # D:/lnh.python/py project/teaching_show/blog/bin # print(os.path.dirname(os.path.dirname(__file__))) # 获取父级目录也就是blog的绝对路径 # D:/lnh.python/py project/teaching_show/blog BATH_DIR = os.path.dirname(os.path.dirname(__file__)) sys.path.append(BATH_DIR) from core.src import run if __name__ == '__main__': run()[
](javascript:void(0)😉这样,我们的starts启动文件就已经配置成功了。以后只要我们通过starts文件启动整个程序,它会先将整个项目的工作目录添加到sys.path中,然后在启动程序,这样我整个项目里面的任何的py文件想引用项目中的其他py文件,都是你可以的了。
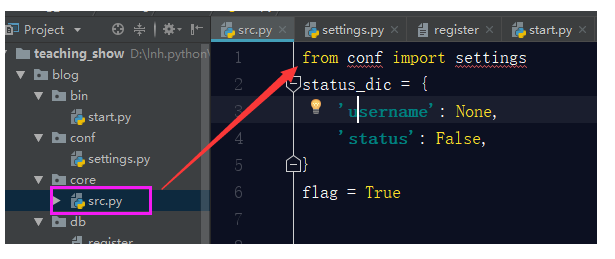
- 配置settings.py文件。
接下来,我们就会将我们项目中的静态路径,数据库的连接设置等等文件放置在settings文件中。
我们看一下,你的主逻辑src中有这样几个变量:
[
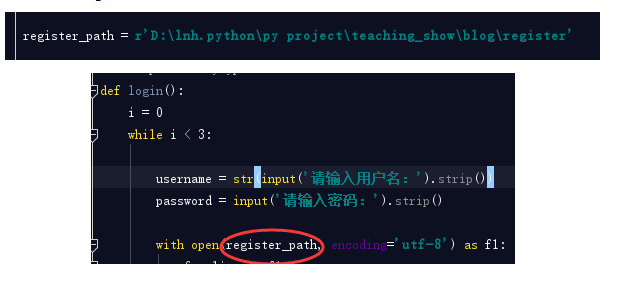
](javascript:void(0)😉status_dic = { 'username': None, 'status': False, } flag = True register_path = r'D:\lnh.python\py project\teaching_show\blog\register'[
](javascript:void(0)😉我们是不是应该把这几个变量都放置在settings文件中呢?不是!setttings文件叫做配置文件,其实也叫做配置静态文件,什么叫静态? 静态就是一般不会轻易改变的,但是对于上面的代码status_dic ,flag这两个变量,由于在使用这个系统时会时长变化,所以不建议将这个两个变量放置在settings配置文件中,只需要将register_path放置进去就可以。
register_path = r'D:\lnh.python\py project\teaching_show\blog\register'拼接路径


但是你将这个变量放置在settings.py之后,你的程序启动起来是有问题,为什么?
with open(register_path, encoding='utf-8') as f1: NameError: name 'register_path' is not defined因为主逻辑src中找不到register_path这个路径了,所以会报错,那么我们解决方式就是在src主逻辑中引用settings.py文件中的register_path就可以了。
这里引发一个问题:为什么你这样写就可以直接引用settings文件呢?我们在starts文件中已经说了,刚已启动blog文件时,我们手动将blog的路径添加到sys.path中了,这就意味着,我在整个项目中的任何py文件,都可以引用到blog项目目录下面的任何目录:bin,conf,core,db,lib,log这几个,所以,刚才我们引用settings文件才是可以的。
- 配置common.py文件
接下来,我们要配置我们的公共组件文件,在我们这个项目中,装饰器就是公共组件的工具,我们要把装饰器这个工具配置到common.py文件中。先把装饰器代码剪切到common.py文件中。这样直接粘过来,是有各种问题的:

所以我们要在common.py文件中引入src文件的这两个变量。
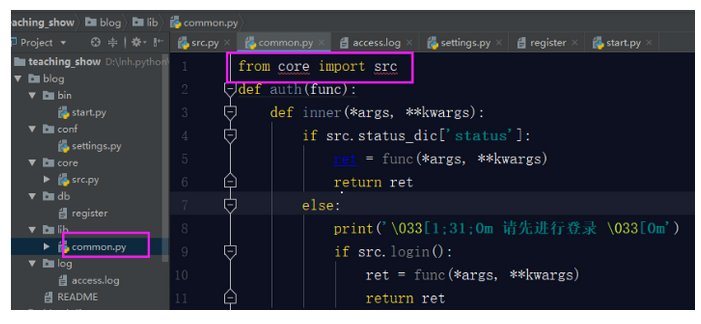
可是你的src文件中使用了auth装饰器,此时你的auth装饰器已经移动位置了,所以你要在src文件中引用auth装饰器,这样才可以使用上。
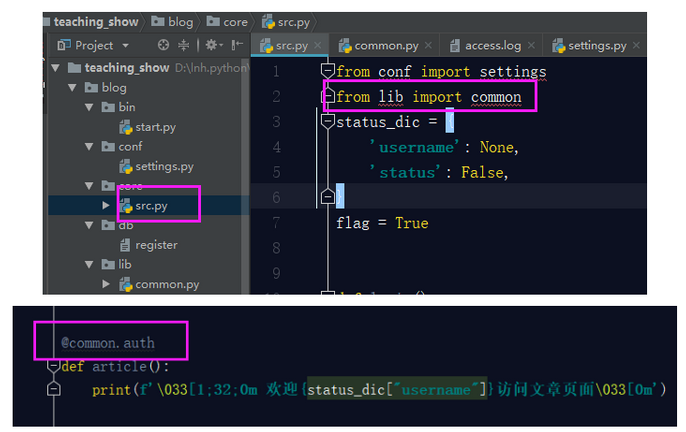
OK,这样你就算是将你之前写的模拟博客园登录的作业按照规范化目录结构合理的完善完成了,最后还有一个关于README文档的书写。
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个
README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
python笔记2021.12.12正则相关笔记
0.正则的用处
-
1.检测一个输入的字符串是否合法
- 用户输入一个内容时,我们提前做检测,能够减轻服务器压力和提高效率
-
2.从一个大的文件中找到需要的文本 (爬虫和日志分析)
1.初始元字符
- [xxx],一个括号表示一个字符位置
- [0-9] 匹配数字0-9
- [a-zA-Z0-9] 匹配0-9和26个大小写字母
2.正则表达式快捷方式元字符
-
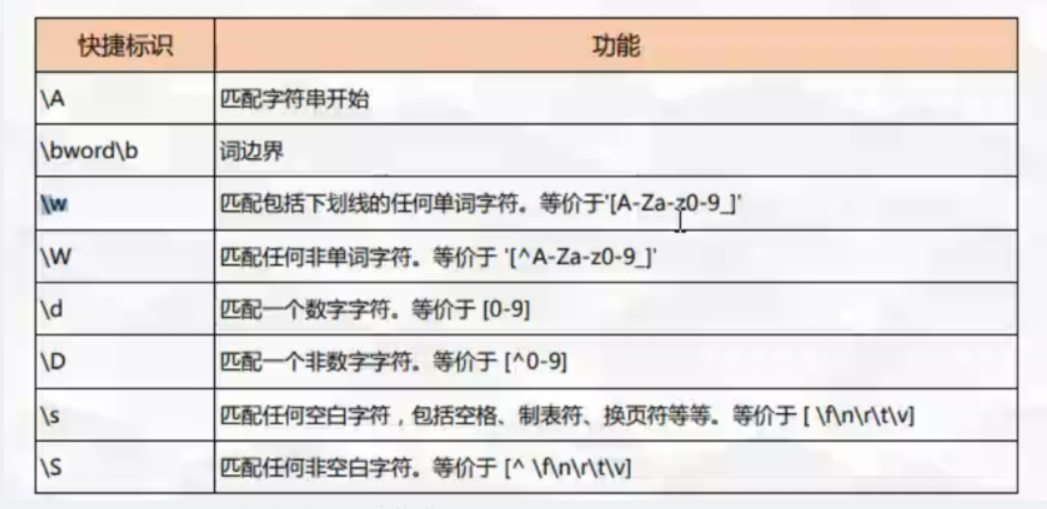
\A
import re ret = re.search(r"\Aworld","world world") print(ret.group())#world -
\b-->#\b 词边界#前后都是边界#是字符不属于词
ret = re.findall(r"\bwould","would 123would would123 wouldabc would#")#查找以would开头的 print(ret)#['would', 'would', 'would', 'would'] -
\B -->#\B 不是词边界B,不是以什么什么结尾的或开始的
ret = re.findall(r"\Bwould\B","1would1 123would would123 wouldabc would#") print(ret) -
\d --> 匹配任意数字
ret = re.findall(r"\d","1would1 123would would123 wouldabc would#") print(ret)#['1', '1', '1', '2', '3', '1', '2', '3'] -
\D -->匹配非数字
ret = re.findall(r"\D","1woul") print(ret)#['w', 'o', 'u', 'l'] -
\w --> 匹配任意一个字符
ret = re.findall(r"\w","1woul") print(ret)#['1', 'w', 'o', 'u', 'l'] -
\W -->不匹配字符字母
-
ret = re.findall(r"\W","1woul@d kk p;m") print(ret)#['@', ' ', ' ', ';'] -
\t -->tab
-
\n -->回车
-
\s -->匹配空格,tab,和回车:匹配空字符--字符前面有空格
ret = re.findall(r"\swould", " 1 would1 123would would 123 wouldabc would#") print(ret)#[' would', ' would', ' would', ' would'] -
\S -->匹配非空字符
ret = re.findall(r"\Swould", " 1would1 12 3 would would 123 wouldabc would#")print(ret)#['1would']
-
区间取反
[^\d] -->匹配所有的非数字
ret = re.findall("[^A-Za-z0-9_]","hseuifghwg56w6#%&" "g_")print(ret)#['#', '%', '&'] -
当放[1]$时,表示以什么开头,以什么结尾
ret = re.findall("^\w*$","hseuifghwg56w")print(ret)#['hseuifghwg56w'] -
.占位符 表示除换行符外的任意一个字符
-
ret = re.findall("p.thon","Python python pgthon p thon pthon p\nthon")print(ret)#['python', 'pgthon', 'p thon']
3.通配符
- ?--> 匹配0到一次
ret = re.findall("py?","py p pyt pytthon")print(ret)#['py', 'p', 'py', 'py']
-
+ -->匹配一次或多次
ret = re.findall("py+","py p pyt pyyytthon")print(ret)#['py', 'py', 'pyyy'] -
{n,m} -->匹配n到m次
ret = re.findall("py{2,4}","py pyy pyyyyyy")print(ret)#['pyy', 'pyyyy']
4.贪婪匹配和非贪婪匹配
-
贪婪匹配
基于:贪心算法
和回溯算法:从后往前找
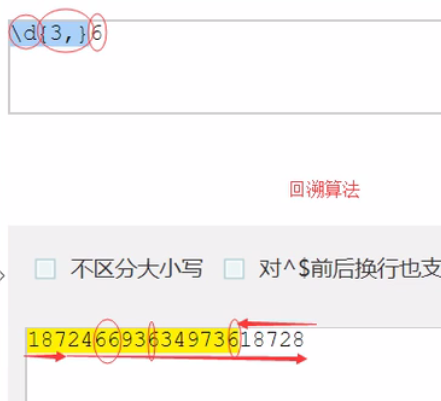
ret = re.findall("py{2,4}","py pyy pyyyyyy")print(ret)#匹配允许范围内最多的ret = re.findall("\d{3}6","176646678214134843649832489")print(ret)#['1766', '8436']ret = re.findall("\d{3,}6","176646678214134843649832489")print(ret)#匹配3次以上#['1766466782141348436'] -
非贪婪匹配又称惰性机制
非贪婪匹配--在通配符后面加个?
ret = re.findall("py{2,4}?","pyyy p pyyt pyyyy")print(ret)#['pyy', 'pyy', 'pyy']ret = re.findall("\d??y","15y p pyyt pyyyy")print(ret)#['5y', 'y', 'y', 'y', 'y', 'y', 'y']#.*?x:表示匹配任意字符 任意多次数 但是一旦遇到x就停下来#.*x:表示匹配任意字符 任意多次数 遇到最后一个x就停下来
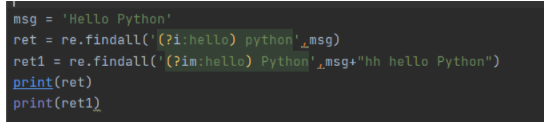
5.内联标记


6.findall 和 search
-
1.findall:返回值是一个列表,从头到位找到所有的符合条件的返回,优先显示分组中的
ret = re.findall(r"\bwould","would 123would would123 wouldabc would#")print(ret)#['would', 'would', 'would', 'would'] -
search:返回值是一个对象,使用.group()方法打印结果,返回找到的第一个值
- 变量.group()的结果和变量.group(0)的结果一致
- 变量.group(n)的形式来指定获取第n个分组中匹配到的内容
ret = re.search("\d??y","15y p pyyt pyyyy")print(ret.group())#5y -
为什么search中不需要分组优先,而在findall中需要?
ret = re.findall('<\w+>(\w+)<\w+>','<h1>safeawergwarg<h1>')print(ret)#['safeawergwarg']ret = re.search('<(\w+)>(\w+)<\w+>','<h1>safeawergwarg<h1>')print(ret.group())#<h1>safeawergwarg<h1> 在括号内标记?:(?:取消分组优先,不会打印出来)print(ret.group(1))#h1 ---有几个小括号分几组print(ret.group(2))#safeawergwarg

对正则进行定义可以匹配类型

7.正则断言
- 零宽正向先行断言(?=pattren)
- 零宽负向先行断言(?!pattren)
- 零宽正向后行断言(?<=pattren)
- 零宽正向后行断言(?=!pattren)
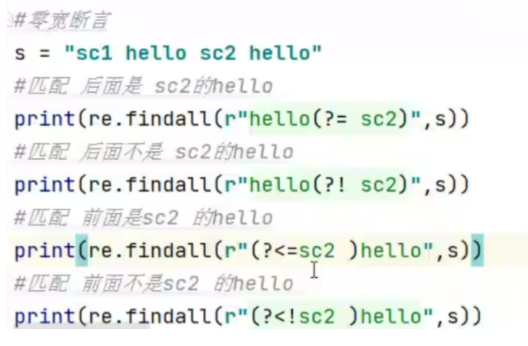
8.re模块中的方法
-
split:分割
ret = re.split('\d+', 'cookie254za22iyi')print(ret))#['cookie', 'za', 'iyi']把\d+当分割符ret = re.split('\d(\d)\d', 'cookie254za22iyi')print(ret)#['cookie', '5', 'za22iyi'],通过优先级保留数字 -
sub:替换
ret = re.sub('\d+','s', 'cookie254za22iyi')print(ret)#cookieszasiyi -
subn:以元组形式返回替换和替换次数
ret = re.subn('\d+','s', 'cookie254za22iyi')print(ret) -
match:匹配
ret = re.match('\d+', '555cookie254za22iyi')print(ret.group())#555ret = re.match('\d+', 'cookie254za22iyi')print(ret)#Noneret = re.search('^\d+', '555cookie254za22iyi')print(ret.group())#555,match等价于此表达式
-
compile:节省了多次解析同一个正则表达式的时间
ret = re.compile('\d+')ret1 = ret.search('cookie123')ret2 = ret.findall('cookie456')print(ret1.group())#123 print(ret2)#['456'] -
finditer:迭代获取,节省空间
ret = re.compile('\d+')#两个一起节省空间和时间(只用一次不能缩节省时间)res = ret.finditer('sdf54gfhjksdfwgfwef5ef5we4dfghjfghjk')for i in res: print(i.group(),end=' ')#54 5 5 4
8.re模块的拾遗
-
分组命名(?P<组名>正则)
-
分组命名的引用
(?P(name)) xx(?P=name)
exp = '<abc>asdfhuihewfuih(s)sjd</abc>ghjfkjksh</abd>'ret = re.search(r'<(?P<tag>\w+)>(.*?)</(?P=tag)>',exp)#非贪婪匹配print(ret.group(2))#asdfhuihewfuih(s)sjd -
\1的使用:引用第一个分组的内容,因为加了r所以要使用转义符
exp = '<abc>asdfhuihewfuih(s)sjd</abc>ghjfkjksh</abd>'ret = re.search(r'<(\w+)>.*?<(/\1)>',exp)#非贪婪匹配print(ret)#<re.Match object; span=(0, 31), match='<abc>asdfhuihewfuih(s)sjd</abc>'> -
有时候我们匹配的内容有些不是我们想要的,那么我们就要先把这些内容匹配出来然后把不想要的东西从结果中去掉
9.爬虫的例子9.爬虫的例子:还未添加反爬措施,无法访问以后有时间再完善
import requests
import re
import json
User_Agent= 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0'
def getPage(url):
response = requests.get(url,User_Agent)
return response.text
def parsePage(s):
print(s)
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S)
ret = com.finditer(s)
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
}
def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
f = open("move_info7", "a", encoding="utf-8")
for obj in ret:
print(obj)
data = json.dumps(obj, ensure_ascii=False)
f.write(data + "\n")
if __name__ == '__main__':
count = 0
for i in range(10):
main(count)
count += 25
python笔记2021.12.14,递归函数
1.递归函数
-
官网规定递归最大的深度1000层:从调用开始到结束也算,print显示998,但是实际走过了1000次
-
为什么要限制最大递归次数?
- 每调用一次函数就会开辟一个临时空间,不断的递归调用就会不断的开辟,内存就会越来越大
-
递归:
-
1.递归要尽量控制次数,如果需要迭代很多层才能解决问题,就使用递归
-
2.递归的最大深度可以更改
import sys sys.setrecursionlimit(10000)#但是做了最大限制无法达到很大的值 -
递归函数是怎么停下来的
#一个递归函数想要结束必须在函数内写一个return并且这个条件是可以达到的 count = 0 def func(): global count print(count) count += 1 if count == 3: return func() print('456') func()#1 2 return一层一层返回所以打印两个456 456 #并不是函数中有return,return的结果就一定能够在调用外层函数接收到 def func(1): 1 += 1 if 1 == 3: return 3 func(2) func(1) print() def func(2): 2 += 1 if 3 == 3: return 3#但是返回的是给func(2)所有外部接受不到 func(2) #解决方法在每层最后return返回 def func(count): count += 1 print(count) if count == 4: return 4 ret = func(count) return ret func(1)#2 3 4
-
-
2.题目

#1.阶乘
#2. os模块查看文件夹下面所有文件,使用迭代实现
import os
def show_file(path):
name_lst = os.listdir(path)
for name in name_lst:
abs_path = os.path.join(path,name)
if os.path.isfile(abs_path):
print(abs_path)
elif os.path.isdir(abs_path):
show_file(abs_path)
show_file("G:\python代码\pythonProject\leecode")
#3.用os模块计算文件夹下面所有文件大小
import os
def show_file(path):
size = 0
name_lst = os.listdir(path)
for name in name_lst:
abs_path = os.path.join(path,name)
if os.path.isfile(abs_path):
size += os.path.getsize(abs_path)
elif os.path.isdir(abs_path):
show_file(abs_path)
print(path,size)
show_file("G:\python代码\pythonProject\leecode")
#G:\python代码\pythonProject\leecode\11 97
#G:\python代码\pythonProject\leecode 694188
import os
def show_file(path):
size = 0
name_lst = os.listdir(path)
for name in name_lst:
abs_path = os.path.join(path,name)
if os.path.isfile(abs_path):
size += os.path.getsize(abs_path)
elif os.path.isdir(abs_path):
ret = show_file(abs_path)
size += ret
return size
ret = show_file("G:\python代码\pythonProject\leecode")
print(ret)#694713
#4.斐波拉契数列
#方法一:非常慢:递归次数很高,并且调用了两层类似于树
def fib(n):
if n == 1 or n == 2:
return 1
else:
return fib(n-1)+fib(n-2)
ret = fib(6)
print(ret)
#方法二:没有递归100次所以很快
def fib(n):
a = 1
b = 1
while n > 2:
a, b = b, a + b
n -= 1#不执行此操作便不会跳出循环
return b
ret = fib(3)
print(ret)
#方法三 :递归牺牲空间换时间
def fib(n, a = 1, b = 1):
if n == 1 or n == 2:
return b
else:
a, b = b, a + b
return fib(n-1, a, b)
ret = fib(100)
print(ret)
#方法四:yield用的时候就生成一个空间,节省空间
def fib(n):
a = 1
yield a
b = 1
yield b
while n > 2:
a, b = b, a + b
yield b
n -= 1
for i in fib(10):
print(i)
#方法五:优化
def fib(n):
if n == 1:
yield 1
else:
yield from(1,1)#作为一个迭代器返回
a,b = 1, 1
while n > 2:
a, b = b, a + b
yield b
n -= 1
for i in fib(2):
print(i)
#5.三级菜单也可能是n级
menu = {
'北京': {
'海淀': {
'五道口': {
'soho': {},
'网易': {},
'google': {}
},
'中关村': {
'爱奇艺': {},
'汽车之家': {},
'youku': {},
},
'上地': {
'百度': {},
},
},
'昌平': {
'沙河': {
'老男孩': {},
'北航': {},
},
'天通苑': {},
'回龙观': {},
},
'朝阳': {},
'东城': {},
},
'上海': {
'闵行': {
"人民广场": {
'炸鸡店': {}
}
},
'闸北': {
'火车战': {
'携程': {}
}
},
'浦东': {},
},
'山东': {},
}
def threeLM(dic):
while True:
for k in dic:print(k)
key = input('input>>').strip()
if key.lower() == 'b' or key.lower() == 'q':
return key
elif key in dic.keys() and:
ret = threeLM(dic[key])#递归实现
if ret.lower() == 'q':
return 'q'
threeLM(menu)
#堆栈计算方法
l = [menu]
while l:
for key in l[-1]:print(key)
k = input('input>>').strip() # 北京
if k in l[-1].keys() and l[-1][k]:l.append(l[-1][k])
elif k == 'b':l.pop()
elif k == 'q':break
#方法三
def threeLM(dic):
flag = True
while flag:
for k in dic:print(k)
key = input('input>>').strip()
if dic.get(key):
dic1 = dic[key]
ret = threeLM(dic1)#递归函数返回值赋值给ret
flag = ret#b时返回Ture给上级函数,上级while循环再循环一次
if not flag:return False
elif key.lower() == 'b' :#返回上一级菜单
return True
elif key.lower() == 'q':
return False
threeLM(menu)
python笔记2021.12.14,shutil模块,logging模块
1.shutil模块:和文件目录相关的,不用使用迭代
import shutil
#拷贝文件
# shutil.copy2('原文件', '现文件')
shutil.copy2(r'G:\python代码\pythonProject\leecode\a.txt',
r'G:\python代码\pythonProject\leecode\b.txt')
#拷贝目录
# shutil.copytree("原目录", "新目录", ignore=shutil.ignore_patterns("*.pyc"))
shutil.copytree('G:\python代码\pythonProject\leecode',
'G:\python代码\pythonProject\cv',
ignore=shutil.ignore_patterns("b.txt"))#将不需要拷贝的文化写入这个里面(‘*.py’)
#删除目录
shutil.rmtree('G:\python代码\pythonProject\cv',ignore_errors=True)
# 移动文件
shutil.move(r'G:\python代码\pythonProject\leecode\test.txt',
r'G:\python代码\pythonProject\leecode\abs.txt',
copy_function=shutil)
#获取磁盘使用空间
total, used, free = shutil.disk_usage(".")
print("当前磁盘共: %iGB, 已使用: %iGB, 剩余: %iGB"%(total / 1073741824, used / 1073741824, free / 1073741824))
total, used, free = shutil.disk_usage(".")
print(f"当前磁盘共: {total / 1073741824}GB, 已使用: {used / 1073741824}GB, 剩余: {free / 1073741824}GB")
# 压缩文件
# shutil.make_archive('压缩文件夹的名字', 'zip','待压缩的文件夹路径')
shutil.make_archive('leecode', 'zip','G:\python代码\pythonProject\leecode\coode')
# 解压文件
# shutil.unpack_archive('zip文件的路径.zip','解压到目的文件夹路径')
shutil.unpack_archive('leecode.zip')#解压的文件需为非空文件
2.logging模块
-
为什么要写log?
- 1.为了排错
- 2.log用来做数据分析
#做数据分析的内容大部分写入数据库中 #输出的内容是有等级的:从上到下越来越严重:默认处理warring级别以上的所有信息 import logging logging.debug('debug message') #调试 logging.info('info message') #信息 logging.warning('warning message') #警告 logging.error('error message') #错误 logging.critical('critical message') #批判性的 #处理错误信息 import logging def cal_mul(exp): exp = 4 * 6 logging.debug('4 * 6 = 24') def cal_div(): pass def cal_add(): pass def cal_sub(exp): exp = 3 - 24 def cal_inner_bracket(exp2): ret = cal_mul(4*6) exp2 = 3 - 24 ret = cal_sub(3 - 24) logging.debug('3-4*6 = -21') return 21 def main(exp): exp=(1+2*(3-4))/5 ret = cal_inner_bracket('3-4*6') return ret logging.basicConfig(level=logging.DEBUG) ret = main('(1+2*(3-4))/5') print(ret) #1.无论你希望日志里打印哪些内容,都得你自己写,没有自动生成日志这种事情 #2.日志的格式,通过logging.basicConfig来写logging模块默认行为 # logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: # # filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 # filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 # format:指定handler使用的日志显示格式。 # datefmt:指定日期时间格式。 # level:设置rootlogger(后边会讲解具体概念)的日志级别 # stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 # # format参数中可能用到的格式化串: # %(name)s Logger的名字 # %(levelno)s 数字形式的日志级别 # %(levelname)s 文本形式的日志级别 # %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 # %(filename)s 调用日志输出函数的模块的文件名 # %(module)s 调用日志输出函数的模块名 # %(funcName)s 调用日志输出函数的函数名 # %(lineno)d 调用日志输出函数的语句所在的代码行 # %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 # %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 # %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 # %(thread)d 线程ID。可能没有 # %(threadName)s 线程名。可能没有 # %(process)d 进程ID。可能没有 # %(message)s用户输出的消息
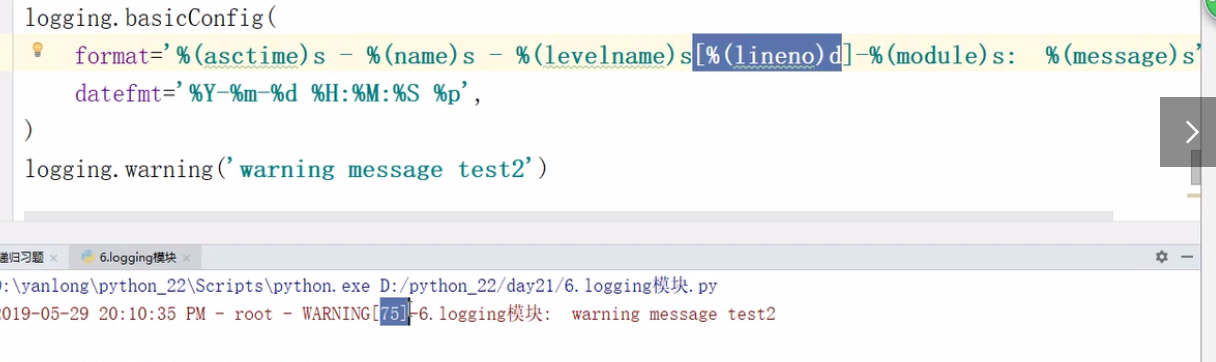
- 日志的级别,日志格式,输出位置:
import logging
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('你好')
-
日志切割
import time import logging from logging import handlers sh = logging.StreamHandler() rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5) fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8') logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[fh,sh,rh], level=logging.ERROR ) for i in range(1,100000): time.sleep(1) logging.error('KeyboardInterrupt error %s'%str(i))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号