



一、实验环境
软件:Prometheus、Grafana、Altermanager
硬件:k8s集群(控制节点、工作节点)
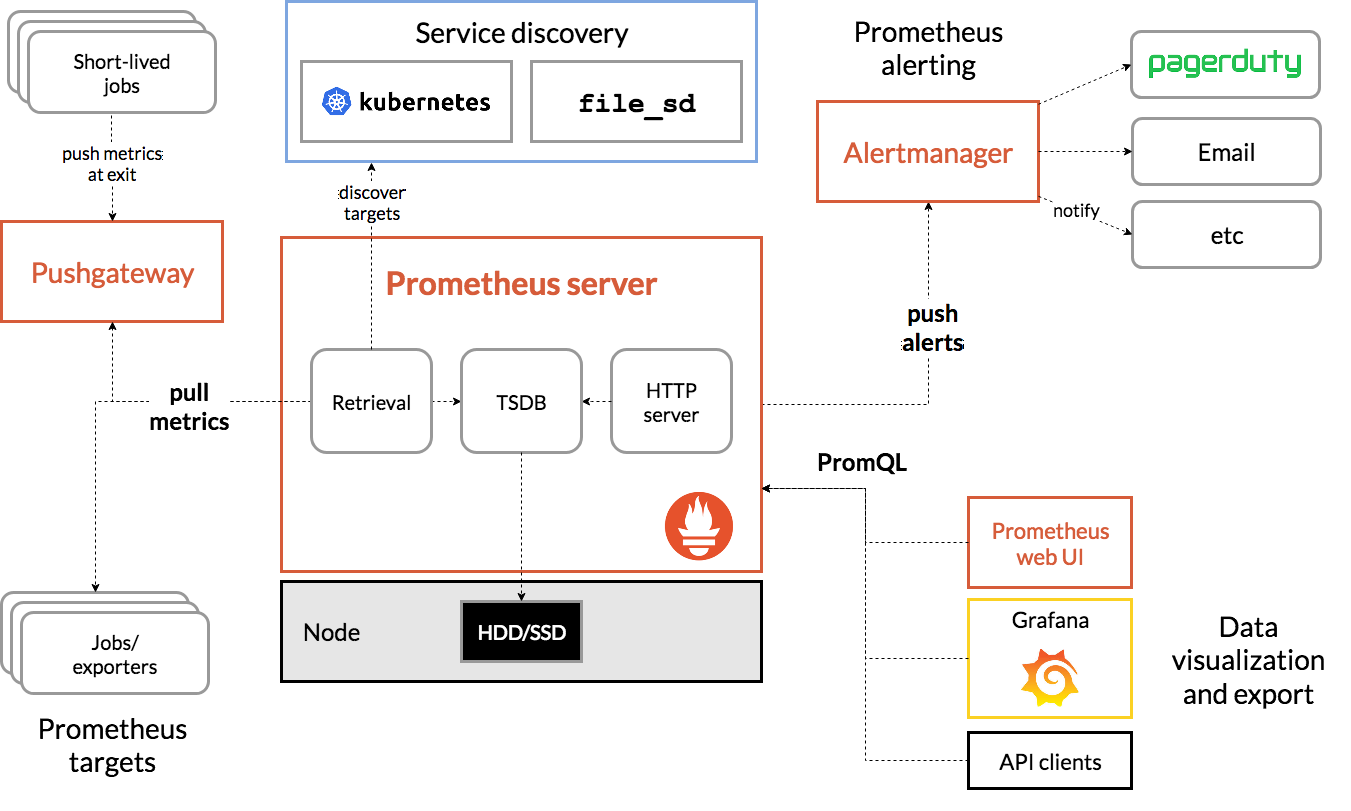
二、Prometheus
2.1. 特点
- 多维度数据模型,每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定;
- 灵活的查询语言(PromQL),可对指标进行加、乘、连接等操作;
- 可直接本地部署,不依赖其他分布式存储;
- 通过基于HTTP的pull方式采集时序数据;
- 可通过中间网关pushgateway的方式把时间序列数据推送到Prometheus server端;
- 高效存储,每采样数据占3.5 bytes左右,300W的时间序列,30s的间隔,保留60天,消耗磁盘大概200G;
2.2. 组件
the main Prometheus server which scrapes and stores time series data
client libraries for instrumenting application code
a push gateway for supporting short-lived jobs
special-purpose exporters for services like HAProxy,StatsD, Graphite, etc.
an alertmanager to handle alerts
various support tools
2.3. Zabbix和Prometheus:
| Zabbix | Prometheus |
|---|---|
| 后端用C,界面用PHP,定制化难度很高 | 后端用GO,前端Grafana,JSON编辑即可解决,定制化难度较低 |
| 集群规模上线10000个 | 支持更大的集群规模,速度也更快 |
| 适合监控物理机环境 | 适合云环境监控,对OpenStack、Kubernetes有更好的集成 |
| 监控数据存储在关系型数据库,如MySQL,很难从现有数据库中扩展维度 | 监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合 |
| 安装简单,zabbix-server一个软件包包括所有服务端功能 | 安装相对复杂,监控、告警和界面都分属不同组件 |
| 图形化界面成熟 | 界面相对较弱,很多配置需要修改配置文件 |
三、安装
3.1. node-export
curl http://192.168.56.129:9100/metrics
[root@anyu967master1 ~]# kubectl create ns monitor-sa
[root@anyu967master1 ~]# docker pull prom/node-exporter
[root@anyu967master1 prometheus]# kubectl get pods -n monitor-sa -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-fswvs 1/1 Running 0 57s 192.168.56.130 anyu967node1 <none> <none>
node-exporter-z4gtq 1/1 Running 0 56s 192.168.56.129 anyu967master1 <none> <none>
# 在命名空间monitor-sa下创建sa账号monitor
[root@anyu967master1 prometheus]# kubectl create serviceaccount monitor -n monitor-sa
serviceaccount/monitor created
# 在命名空间monitor-sa创建clusterrolebinding名字是monitor-clusterrolebinding
[root@anyu967master1 prometheus]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
clusterrolebinding.rbac.authorization.k8s.io/monitor-clusterrolebinding created
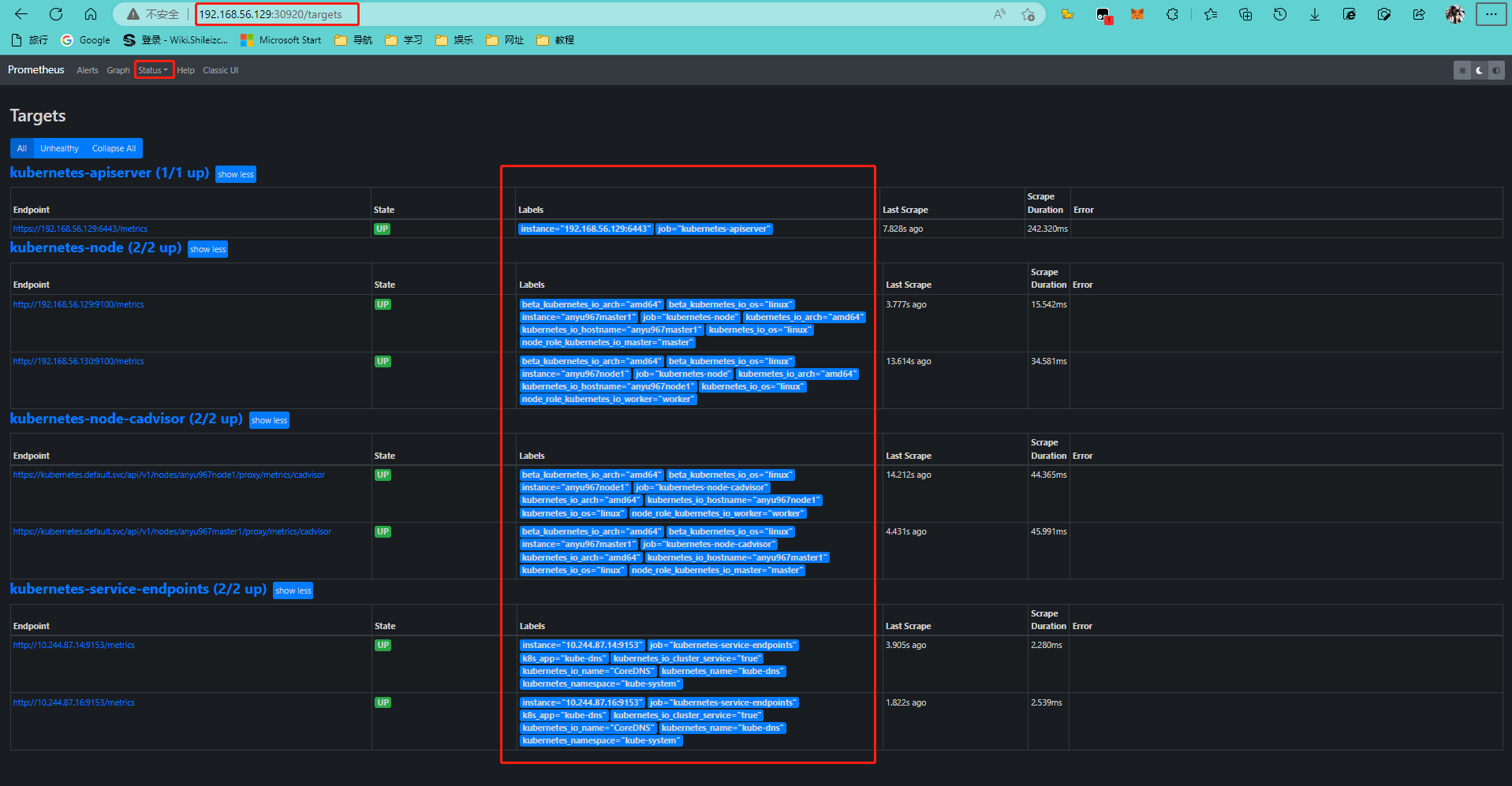
3.2. 安装Prometheus
Dashboards-k8s
# 创建configmap 存储卷,存放配置信息
[root@anyu967master1 prometheus]# kubectl apply -f prometheus-cfg.yaml
configmap/prometheus-config created
[root@anyu967master1 prometheus]# kubectl get configmap -n monitor-sa
NAME DATA AGE
kube-root-ca.crt 1 6h34m
prometheus-config 1 87s
[root@anyu967master1 prometheus]# kubectl describe configmap prometheus-config -n monitor-sa
Name: prometheus-config
Namespace: monitor-sa
Labels: app=prometheus
Annotations: <none>
[root@anyu967master1 prometheus]# kubectl apply -f prometheus-svc.yaml
service/prometheus created
[root@anyu967master1 prometheus]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.106.162.34 <none> 9090:30920/TCP 10s # http://192.168.56.130:30920
[root@anyu967master1 prometheus]# kubectl get pods -n monitor-sa -o wide -l app=prometheus
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-server-65586786cc-gksmn 1/1 Running 0 16m 10.244.87.25 anyu967node1 <none> <none>
# 热加载 curl -X POST http://10.244.87.25:9090/-/reload
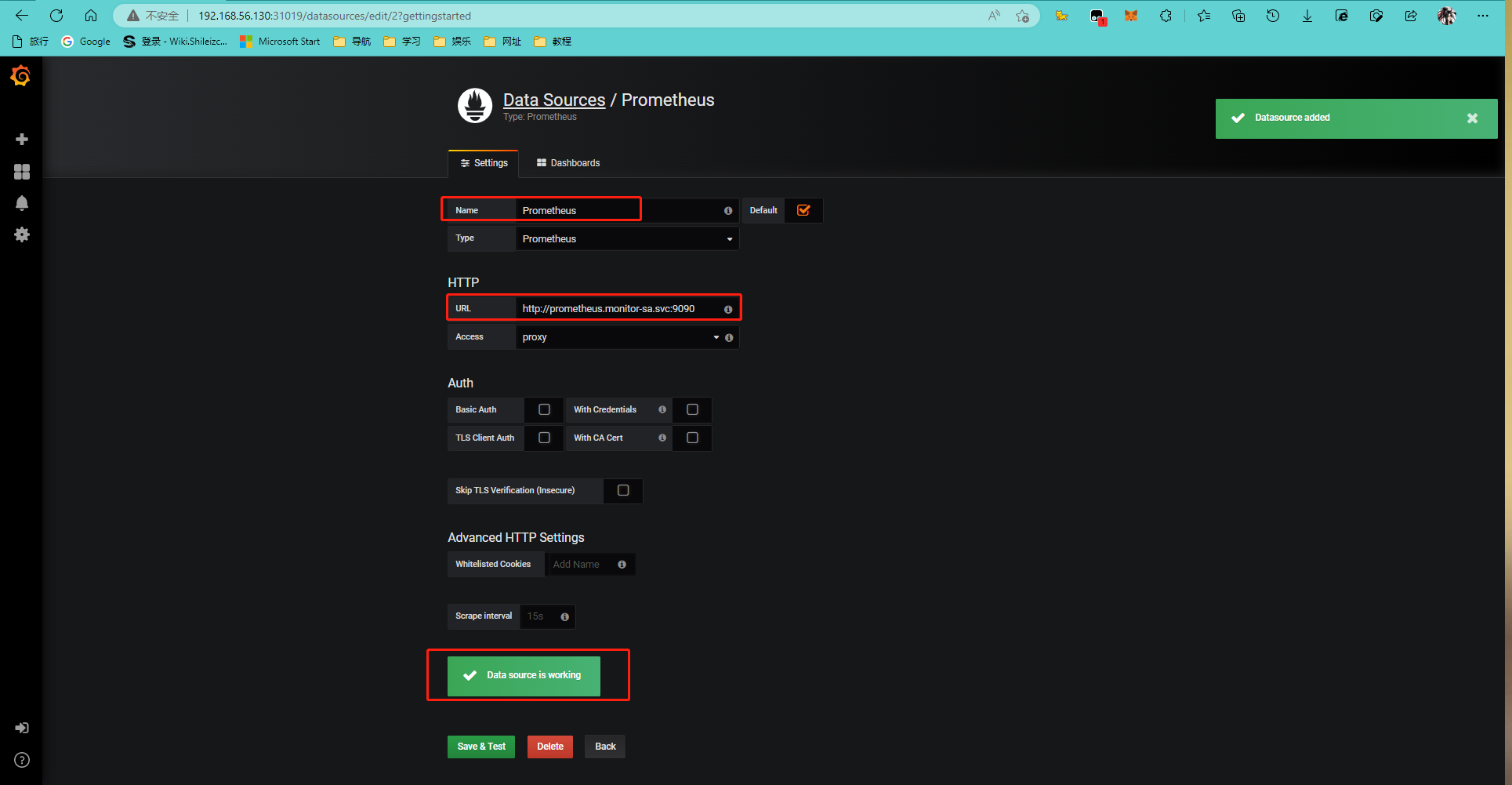
3.3. 安装Grafana
[root@anyu967master1 prometheus]# kubectl apply -f grafana.yaml
deployment.apps/monitoring-grafana created
service/monitoring-grafana created
[root@anyu967master1 prometheus]# kubectl get pods -n kube-system -o wide -l k8s-app=grafana
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
monitoring-grafana-d47cdf886-jc48x 1/1 Running 0 93s 10.244.87.27 anyu967node1 <none> <none>
[root@anyu967master1 prometheus]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 24d
metrics-server ClusterIP 10.100.133.133 <none> 443/TCP 18d
monitoring-grafana NodePort 10.104.250.21 <none> 80:31019/TCP 4m12s # http://192.168.56.130:31019/?orgId=1
3.4. 安装 kube-state-metrics组件
kube-state-metrics通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,可以使用Prometheus来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等;调度了多少个replicas,现在可用的有几个,多少个Pod是running/stopped/terminated状态,Pod重启了多少次,有多少job在运行中;
# kubectl config use-context kubernetes-admin@kuberneters 切换当前上下文
# kubectl create sa kube-state-metrics
# kubectl create CLusterRolebinding kube-state-metrics --clusterrole=kube-state-metrics --serviceaccount=kube-system:kube-state-metrics
[root@anyu967master1 prometheus]# kubectl apply -f kube-state-metrics-rabc.yaml
serviceaccount/kube-state-metrics unchanged
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics unchanged
[root@anyu967master1 prometheus]# kubectl apply -f kube-state-metrics-deploy.yaml
deployment.apps/kube-state-metrics created
[root@anyu967master1 prometheus]# kubectl get pods -n kube-system -o wide -l app=kube-state-metrics
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-state-metrics-6989c984d6-gmjlk 1/1 Running 0 57s 10.244.87.32 anyu967node1 <none> <none>
[root@anyu967master1 prometheus]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 25d
kube-state-metrics ClusterIP 10.107.111.194 <none> 8080/TCP 23s
metrics-server ClusterIP 10.100.133.133 <none> 443/TCP 19d
monitoring-grafana NodePort 10.104.250.21 <none> 80:31019/TCP 25h
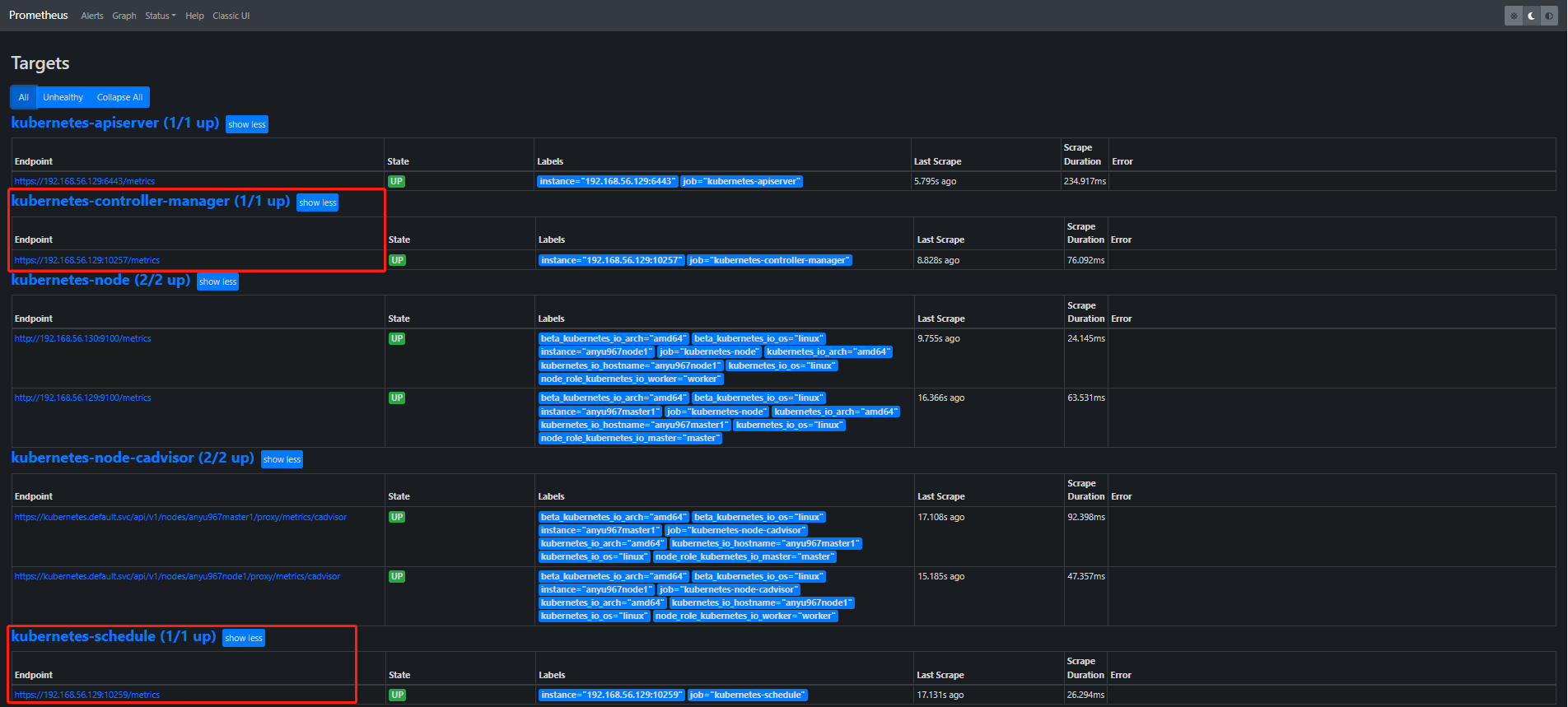
3.5. AlertManager
Kubernetes监控手册07-监控controller-manager
kube-prometheus监控 controller-manager && scheduler 组件
PROMETHEUS监控KUBE-CONTROLLER-MANAGER和KUBE-SCHEDULER
Kubernetes监控手册09-监控ETCD
Prometheus 入门到实战
告警处理流程:
1、Prometheus Server监控目标主机上暴露的HTTP接口(假设接口A),通过Promethes配置的
'scrape_interval'定义的时间间隔,定期采集目标主机上监控数据;
2、当接口A不可用的时候,Server端会持续的尝试从接口中取数据,直到'scrape_timeout'时间后停止尝试,这时候把接口的状态变为D0WN;
3、Prometheus同时根据配置的'evaluation_interval'的时间间隔,定期(默认lmin)的对AlertRule进行评估:当到达评估周期的时候,发现接口A为DOWN,即UP=0为真,激活Alert,进入'PENDING'状态,并记录当前active的时间
4、当下一个alert rule的评估周期到来的时候,发现UP=0继续为真,然后判断警报Active的时间是否己经超出rule里的'for'持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则alert的状态变为'FIRING',同时调用Alertmanager接口,发送相关报警数据;
5、AlertManager收到报警数据后,会将警报信息进行分组,然后根据alertmanager配置的'group_wait'时间先进行等待,等wait时间过后再发送报警信息;
6、属于同一个Alert Group的警报,在等待的过程中可能进入新的alert,如果之前的报警已经成功发出,那么间隔'group_interval'的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个group的报警信息会汇总在一个邮件里进行发送;
[root@anyu967master1 prometheus]# kubectl apply -f alertmanager-cm.yaml
configmap/alertmanager created
[root@anyu967master1 prometheus]# kubectl get configmap -n monitor-sa
NAME DATA AGE
alertmanager 1 64s
kube-root-ca.crt 1 2d2h
prometheus-config 1 43h
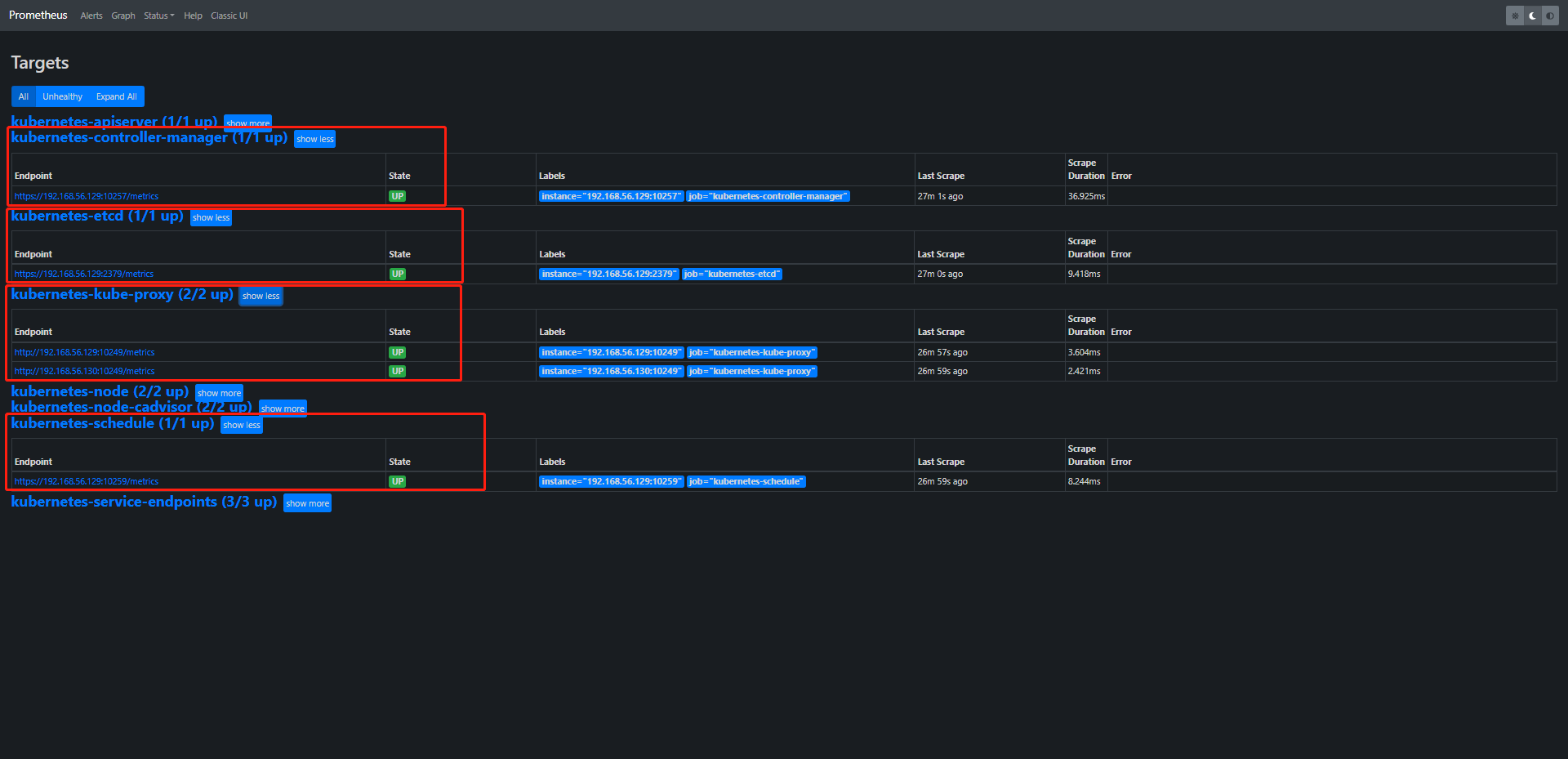
# 解决无法采集controller-manager数据,因为是 http://192.168.56.129:10257/metrics
[root@anyu967master1 prometheus]# kubectl get ep -n kube-system kube-controller-manager -o yaml
apiVersion: v1
kind: Endpoints
metadata:
creationTimestamp: "2022-12-10T17:10:23Z"
labels:
k8s-app: kube-controller-manager
service.kubernetes.io/headless: ""
name: kube-controller-manager
namespace: kube-system
resourceVersion: "343633"
uid: 9f07cc5b-435d-42fd-8ca5-b2d94c616e13
subsets:
- addresses:
- ip: 192.168.56.129
nodeName: anyu967master1
targetRef:
kind: Pod
name: kube-controller-manager-anyu967master1
namespace: kube-system
uid: 9c212344-11a8-4aec-9920-d043a67fa076
ports:
- name: https-metrics
port: 10257
protocol: TCP
[root@anyu967master1 prometheus]# kubectl edit configmap kube-proxy -n kube-system
kind: KubeProxyConfiguration
metricsBindAddress: "0.0.0.0:10249"
[root@anyu967master1 prometheus]# kubectl get pods -n kube-system |grep kube-proxy |awk '{print $1}' |xargs kubectl delete pods -n kube-system
pod "kube-proxy-pntbq" deleted
pod "kube-proxy-z9562" deleted
[root@anyu967master1 prometheus]# netstat -anlp |grep :10249
tcp6 0 0 :::10249 :::* LISTEN 81735/kube-proxy
[root@anyu967master1 prometheus]# curl -s --cacert /etc/kubernetes/pki/etcd/ca.crt --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://localhost:2379/metrics | head -n 6
[root@anyu967master1 prometheus]# kubectl describe pod etcd-anyu967master1 -n kube-system
[root@anyu967master1 prometheus]# kubectl get pod etcd-anyu967master1 -n kube-system -o yaml
[root@anyu967master1 prometheus]# kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
secret/etcd-certs created
本文来自博客园,作者:anyu967,转载请注明原文链接:https://www.cnblogs.com/anyu967/articles/17343345.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号