第二次作业:卷积神经网络Part3
第二次作业:卷积神经网络Part3
一、代码练习
1.HybridSN
模型的网络结构为如下图所示:
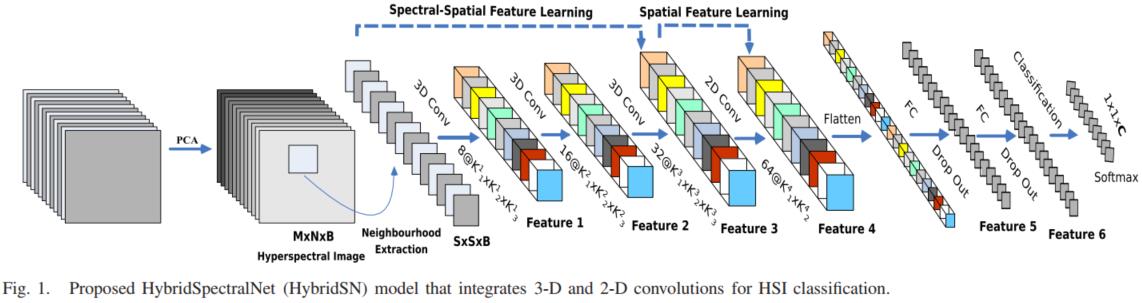
-
三维卷积:
conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19) -
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
-
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
-
接下来是一个 flatten 操作,变为 18496 维的向量,
-
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
-
最后输出为 16 个节点,是最终的分类类别数。
HybridSN 类的代码:
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
# conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
self.conv1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU()
)
# conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
self.conv2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU()
)
# conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
self.conv3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
# conv4: (576, 19, 19), 64个 3x3 的卷积 ==> (64, 17, 17)
self.conv4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.fc1 = nn.Linear(18496, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, class_num)
self.dropout = nn.Dropout(p=0.4)
def forward(self, x):
# 进行三维卷积
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
# 进行二维卷积,把前面 32*18 reshape 一下,得到 (576, 19, 19)
out = self.conv4(out.reshape(out.shape[0], -1, 19, 19)) # out.shape[0]--Batchsize; out.shape[1]--channel;
# 接下来是一个 flatten 操作,变为 18496 维的向量
out = out.reshape(out.shape[0], -1)
# 接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout
out = self.fc1(out)
out = self.dropout(out)
out = self.fc2(out)
out = self.dropout(out)
# 最后输出为 16 个节点,是最终的分类类别数
out = self.fc3(out)
return out
# 随机输入,测试网络结构是否通
x = torch.randn(1, 1, 30, 25, 25)
net = HybridSN()
y = net(x)
print(y.shape)
print(y)
经过训练后,精确度为 96.78%
2.SENet
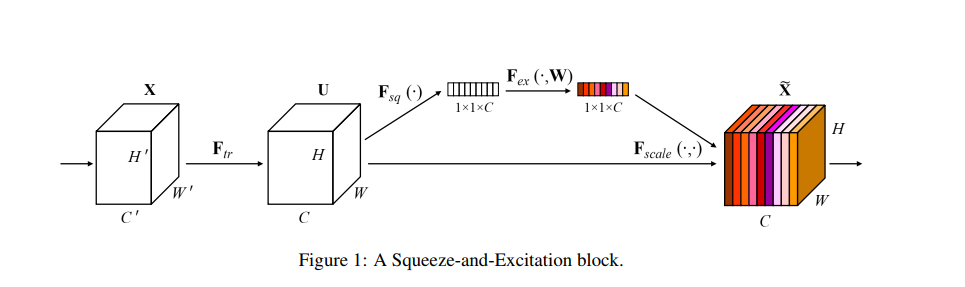
上图是 SENet 的 Block 单元,图中的 \(F_{tr}\) 是传统的卷积结构, X 和 U 是 \(F_{tr}\) 的输入和输出,这些都是以往结构中已存在的。SENet 增加的部分是U后的结构:对 U 先做一个 Global Average Pooling(图中的\(F_{sq}(.)\),即 Squeeze 过程),输出的 1x1xC 数据再经过两级全连接(图中的\(F_{ex}(.)\),即Excitation),最后用sigmoid 限制到 [0,1] 的范围,把这个值作为 scale 乘到 U 的 C 个通道上, 作为下一级的输入数据。
总的来说,Squeeze-and-Excitation:
· Squeeze: 通过全局平均池化来生成信道统计信息
· Excitation: FC--限制模型复杂度
Relu
FC--重新激活
Sigmoid--限制输出范围为 [0,1]
引入 SENet 的 HybridSN:
class SELayer(nn.Module):
def __init__(self, channel, r=16):
super(SELayer, self).__init__()
# Squeeze
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# Excitation
self.fc1 = nn.Linear(channel,round(channel/r))
self.relu = nn.ReLU()
self.fc2 = nn.Linear(round(channel/r),channel)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
out = self.avg_pool(x)
out = out.view(out.shape[0], out.shape[1])
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
out = out.view(out.shape[0], out.shape[1], 1, 1)
return x * out
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.SELayer = SELayer(64, 16)
self.fc1 = nn.Linear(18496, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, class_num)
self.dropout = nn.Dropout(p=0.4)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out.reshape(out.shape[0], -1, 19, 19))
out = self.SELayer(out) # 二维卷积后面添加SENet
out = out.reshape(out.shape[0], -1)
out = self.fc1(out)
out = self.dropout(out)
out = self.fc2(out)
out = self.dropout(out)
out = self.fc3(out)
return out
经过训练后,精确度为97.85%,比没有 SENet 的网络有所提高。因为通过 SENet 控制 scale 的大小,把重要的特征增强,不重要的特征减弱。
二、视频学习
1.《语义分割中的自注意力机制和低秩重建》-李夏
- 语义分割:对每一个像素都同时地产生一个 Label
![]()
- 传统的完全由卷积层组成的网络结构,感受野获得的有用信息是有限的。
- Nonlocal Network:为了推测某一位置上的物品信息,需要建立此位置像素和其他像素之间的关系
![]()
- A^2-Nets: 认为一张图是由若干个关键内容组合成的,首先发现这些组合因子,然后再将这些组合因子映射回来。
![]()
- A^2-Nets 与 Nonlocal Network 的区别:相当于矩阵的结合律,但是计算量会减小很多。
![]()
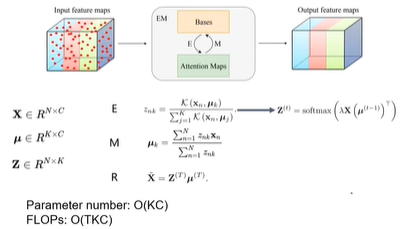
- EM Attention Networks
![]()


2.《 图像语义分割前沿进展》-程明明
在计算机视觉发展过程中,在对图像的理解方面,一直在追求对多尺度信息的理解。如果我们能够做到更好的多尺度的感受,我们就可以更好的理解图像,对图像进行分割。卷积神经网络有三个非常重要的层,分别是:卷积、激活、池化,我们分别从卷积和池化两个角度出发,来改进网络,从而获得更好的多尺度信息。
-
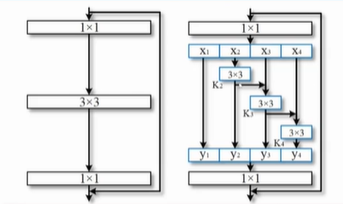
Res2Net
富尺度空间的深度神经网络通用架构
![]()
左图为经典的ResNet的结构,右图在此基础上将输入分为多组进行分组卷积,可以更好地提取不同尺度信息,同时可以与其它结构相兼容(如SENet)。 -
Strip Pooling(带状池化)
在进行语义分割的过程中,我们既需要细节信息,同时又需要捕捉全局的信息。
捕捉全局信息的方法,如:Non-local modules,Self-Attention,需要计算一个很大的affinity matrix; Dilated convolution,Pyramid/globlal pooling,很难获得各向异性的信息。
采用 Strip pooling 可以在一个方向上获得全局的信息,同时在另一个方向上获得细节信息。
采用横向和纵向的条状池化可以获得各向异性的信息。
![]()
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号