

论文阅读 | MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
引言
自从AlexNet通过赢得ImageNet挑战推广了深度卷积神经网络以来,卷积神经网络在计算机视觉中变得无处不在。为了达到更高的精度,总的趋势是制造更深层和更复杂的网络。然而,在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型是难以被应用的。
本文描述了一种高效的网络体系结构和一组两个超参数,以建立非常小、低延迟的模型,这些模型可以很容易地满足移动和嵌入式视觉应用的设计要求。
Depthwise separable convolution
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,如图1所示。
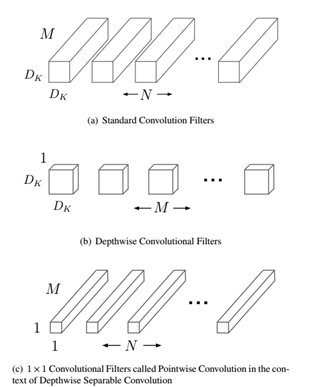
图1 Depthwise separable convolution
1.标准卷积 Standard Convolution
假定输入特征图大小是 \(D_F \times D_F \times M\) ,而输出特征图大小是\(D_F \times D_F \times N\) ,其中 \(D_F\)是特征图的width和height,这是假定两者是相同的,而\(M\)和\(N\)指的是通道数(channels or depth)。这里也假定输入与输出特征图大小(width and height)是一致的。采对于标准的卷积 \(D_K \times D_K\) ,其计算量将是:
2.深度可分离卷积 Depthwise separable convolution
对于depthwise convolution其计算量为: \(D_K \times D_K \times M \times D_F \times D_F\),pointwise convolution计算量是:\(M \times N \times D_F \times D_F\),所以depthwise separable convolution总计算量是:
3.两者之比
比较depthwise separable convolution和标准卷积如下:
4.小结
一张输入图片(假设shape为5×5×3):对于标准卷积,经过shape为3×3×3×4的卷积核后,输出4个 Feature Map;对于深度可分离卷积,Depthwise Convolution 的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,经过运算后生成 3 个 Feature Map,再经过 1×1×4 的 Pointwise Convolution,生成4个 Feature Map。深度可分离卷积通过两步运算来减少运算量。
更加形象的描述请参考:Depthwise卷积与Pointwise卷积
MobileNet 结构
MobileNet结构建立在深度可分离卷积上,第一层是完全卷积。MobileNet架构如表1所示。所有层都加入了batchnorm和ReLU(最终的全连接层没有加),并输入到softmax层进行分类。图2将具有规则卷积、批处理范数和ReLU非线性的层与具有深度卷积、1×1点卷积以及每个卷积层后的batchnorm和ReLU的因子分解层进行对比。最终的平均池会在完全连接层之前将空间分辨率降低到1。将深度卷积和点卷积计算为单独的层,MobileNet有28层。
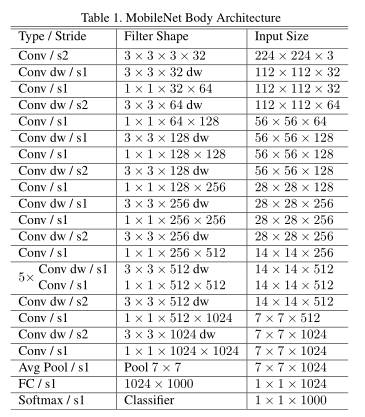
表1 MobileNet 结构

图2 Left: Standard convolutional layer with batchnorm and
ReLU. Right: Depthwise Separable convolutions with Depthwise
and Pointwise layers followed by batchnorm and ReLU.
MobileNet瘦身——超参数:Width Multiplier,Resolution Multiplier
为了构造这些更小且计算成本更低的模型,引入了一个参数α,称为Width Multiplier。α的作用是在每层均匀地细化网络,其取值范围为(0,1],那么输入与输出通道数将变成\(\alpha M\) 和 \(\alpha N\),对于depthwise separable convolution,其计算量变为:
第二个参数resolution multiplier主要是按比例降低特征图的大小,记为\(\rho\),加上resolution multiplier,depthwise separable convolution的计算量为:
resolution multiplier仅仅影响计算量,但是不改变参数量.
参考
1.《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
2.https://zhuanlan.zhihu.com/p/80041030
3.https://zhuanlan.zhihu.com/p/31551004
4.https://zhuanlan.zhihu.com/p/99173115

 浙公网安备 33010602011771号
浙公网安备 33010602011771号