

sqlserver 优化
1.优化not in
a、in 和 exists
in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询,一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in.
select * from A where id in(select id from B) --> in 使用外表(A表)的索引
select * from A where exists(select id from B where id=A.id) --> exists 使用内表(A表)的索引
select * from A where id in(1,2,3) = select * from A where id=1 or id=2 or id=3
b、not in 和 not exists
如果not in的子查询中返回的任意一条记录含有空值,则查询将不返回任何记录。如果子查询字段有非空限制,这时可以使用not in
select * from A where id not in(select id from B) --> not in 对内外表都进行全表扫描,没有用到索引
select * from A where not exists(select id from B where id=A.id) --> not exists使用内表的索引
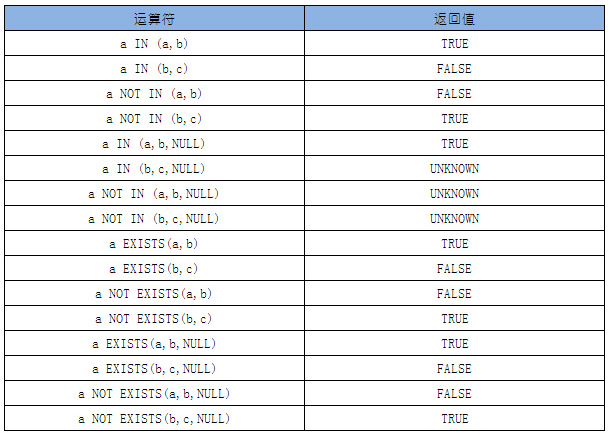
in遇到包含NULL的情况,就会返回UNKNOWN。not in永远不会返回TRUE,而是返回NOT TRUE或NOT UNKNOWN。exists只返回TRUE或FALSE
not in 优化例子:
-- 1.使用"not in": exculdeAccounts有4000个值 :1,2,...,4000, 非常耗时 SELECT s.account_id FROM dbo.statement_detail s WHERE s.statement_id = :stmtId AND s.account_id not in(:exculdeAccounts) -- 2.使用"not exists": 将exculdeAccounts转化为表连接,提高了效率 DECLARE @X XML; SET @X = convert(XML, '<root><a>' + replace('1,2,3,4,5,6', ',', '</a><a>') + '</a></root>'); WITH exculde_accounts AS ( SELECT T.c.value('.', 'BIGINT') AS account_id FROM @X.nodes('/root/a') T(c) ) SELECT s.account_id FROM dbo.statement_detail s WHERE s.statement_id = :stmtId AND NOT EXISTS ( SELECT 1 FROM exculde_accounts e WHERE e.account_id = s.account_id )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号