如何优雅的维护 K8S Worker 节点
前言
正常维护工作节点的流程
当我们要进行 K8S 节点维护时往往需要执行 kubectl drain, 等待节点上的 Pod 被驱逐后再进行维护动作。
命令行如下:
kubectl drain NODE
待节点排空后再进行维护操作, 内核升级等。
存在问题吗?
drain 命令有一个问题, 他不会考虑资源所定义的 UpdateStrategy, 而直接强制驱逐或删除 Pod, 这样就会导致 Deployment 或 StatefulSet 资源的 Pod 达不到所设置的策略数.
思考一个案例
- 有一个 Deployment 资源, 它使用了如下配置
副本数为 3, 采用了滚动更新, 并且先启动完成一个 Pod 后再进行旧 Pod 的删除(最大不可用为0,最小可用为2).replicas: 2 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 0 type: RollingUpdate - 当下集群有 2 个 worker 节点
意味着, 其中一个节点被调度了 2 个 Pod, 其中一个节点被调度了 1 个 Pod.
假设 node1 运行着 pod1 和 pod3, node2 运行着 pod2. - 这时候 drain node1, 会出现 Deployment 只有一个 Pod 可用
更糟糕的情况
Deployment 的 Pod 全部运行在需要维护的节点上, 这时候执行 drain 那将是一个灾难, 这个 Deployment 在新的Pod启动之前它无法在对外提供服务了, 恢复的时间取决于新 Pod 的启动速度。
kubectl-safe-drain 项目
GitHub: https://github.com/majian159/kubectl-safe-drain
一个 kubectl 插件, 用于更为安全的排空节点。
对于 Deployment 和 StatefulSet 资源会根据其配置的更新策略先将Pod调度到其它可用节点。
逻辑和原理
- 先将需要排空的节点标记为不可调度 (kubectl cordon)
- 在找到该节点上的 Deployment 和 StatefulSet 资源
- 修改 Deployment 和 StatefulSet 的 PodTemplate, 让K8S根据对应的更新策略重新部署Pod, 这时候需要排空的节点不可被调度, 从而达到先将排空节点中的Pod安全重建到其它节点的逻辑。
目前支持安全迁移的资源
- Deployment
- StatefulSet
效果
首先我们有一个 Deployment 配置如下
spec:
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
操作前有两个可用 Pod
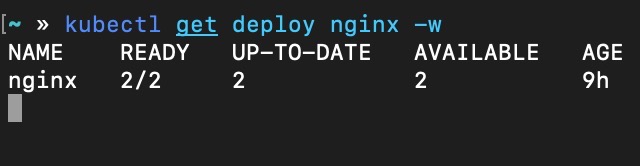

执行 safe-drain 后
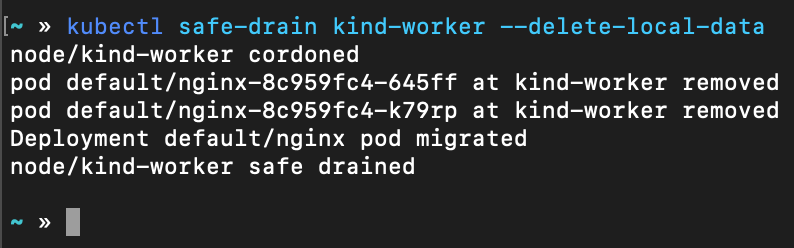
查看 Deployment 变化过程
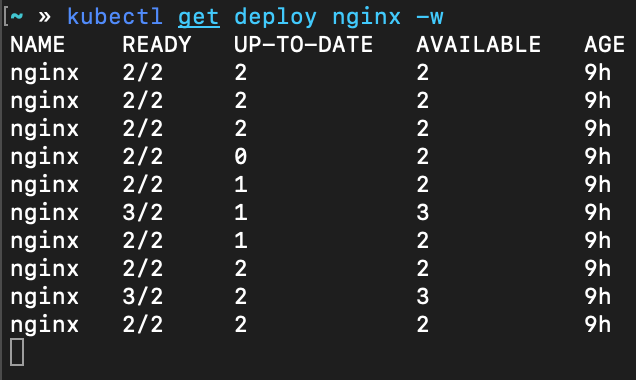
查看 Pod 变化过程
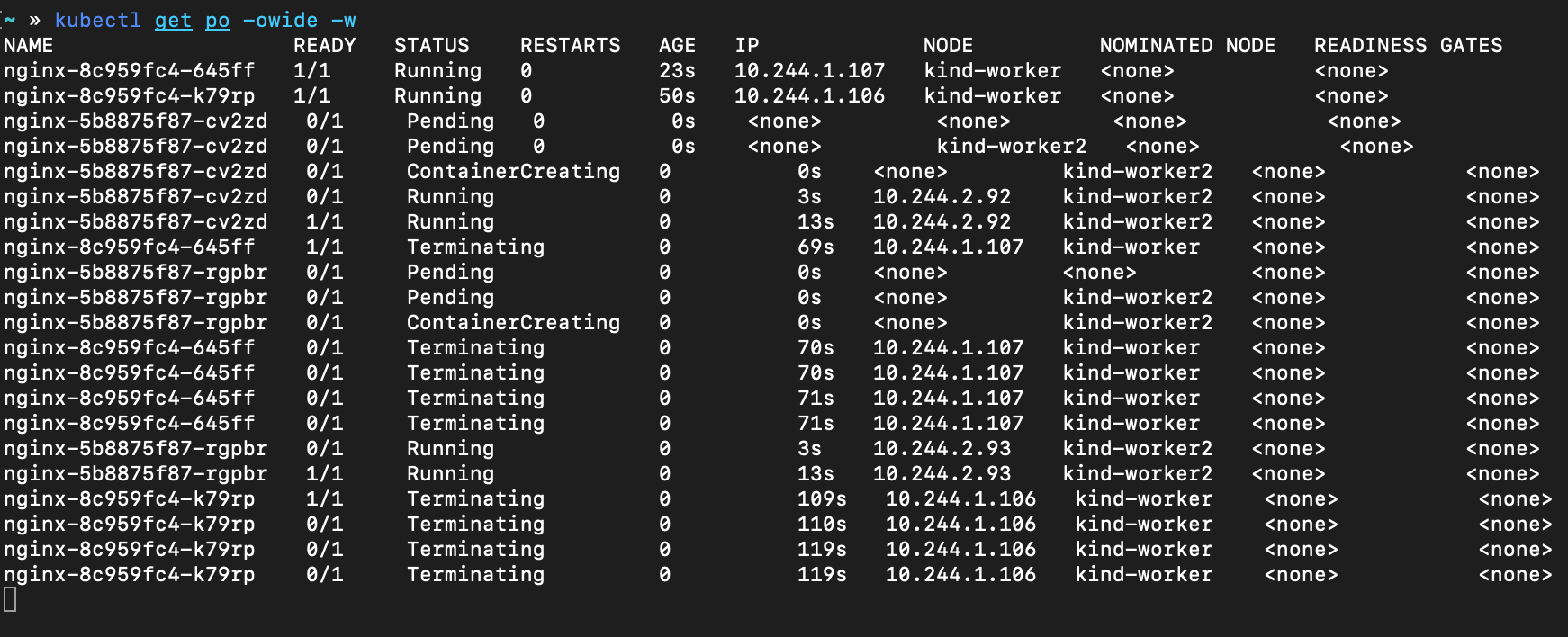
流程简述
从 Deployment watch 的信息中可见最小 Ready 数没有小于 2, 从 Pod watch 的信息中可见 kind-worker2 上承载了 2 个准备就绪的 nginx Pod, 也就是说 nginx 从 kind-worker 安全的移动到了 kind-worker2 节点上。
与 PDB (Pod Disruption Budget) 有什么区别?
PDB 只会保障 Pod 不被驱逐, 而不会帮助它在其它可用节点上重建。
使用了 PDB 后能防止服务不可用的尴尬情况,但它还是需要人工手动迁移 Pod。
理想的情况是搭配 PDB 使用, 防止严苛情况下服务不可用的问题。
安装
二进制文件
Linux
curl -sLo sdrain.tgz https://github.com/majian159/kubectl-safe-drain/releases/download/v0.0.1-preview1/kubectl-safe-drain_0.0.1-preview1_linux_amd64.tar.gz \
&& tar xf sdrain.tgz \
&& rm -f sdrain.tgz \
&& mv kubectl-safe-drain /usr/local/bin/kubectl-safe_drain
macOS
curl -sLo sdrain.tgz https://github.com/majian159/kubectl-safe-drain/releases/download/v0.0.1-preview1/kubectl-safe-drain_0.0.1-preview1_darwin_amd64.tar.gz \
&& tar xf sdrain.tgz \
&& rm -f sdrain.tgz \
&& mv kubectl-safe-drain /usr/local/bin/kubectl-safe_drain
Windows
基于 Krew
curl -O https://raw.githubusercontent.com/majian159/kubectl-safe-drain/master/krew.yaml \
&& kubectl krew install --manifest=krew.yaml \
&& rm -f krew.yaml
使用
kubectl safe-drain NODE
# safe-drain并没有调用 drain命令, 而是利用了 SchedulingDisabled 机制
# 所以如有需要可以继续使用 drain 命令来确保节点被驱逐
kubectl drain NODE
TODO
- 考虑节点亲和力和节点选择器的情况
- 输出更为友好的提示信息
写在最后
该项目部分代码源于 kubectl 项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号