
高性能计算-CUDA-mma PTX 指令行为分析
1. 介绍:
- PTX 指令集中 WMMA 矩阵计算从共享内存加载数据到 fragment 片段使用的封装API是 load__matrix_sync,其底层 PTX指令与mma 一致,并且 fragment 布局一致。本文介绍底层 ldamatrix、stmatrix 指令的行为,并且用代码进行验证。
2. 测试代码
- 测试目标:
- 对fp16数据类型的 16*16 矩阵使用 ldmatrix 指令保存到线程寄存器再使用 stmatrix 指令保存到共享内存,查看矩阵数据布局变化,及每个线程寄存区的数值。
- 使用 trans 参数,查看矩阵数据的布局变化。
/*
测试目标:
1. 对fp16数据类型的 16*16 矩阵使用 ldmatrix 指令保存到线程寄存器再使用 stmatrix 指令保存到共享内存,查看矩阵数据布局变化,及每个线程寄存区的数值。
2. 使用 trans 参数,查看矩阵数据的布局变化。*/
#include <iostream>
#include <cuda_runtime.h>
#include "common/tester.h"
#include "common/common.h"
#include <stdio.h>
#include <cuda_fp16.h>
using namespace nvcuda;
__device__ __forceinline__ void ld_st_128bit(void *dst, void *src)
{
*reinterpret_cast<float4 *>(dst) = *reinterpret_cast<float4 *>(src);
}
#define REG(val) (*reinterpret_cast<uint32_t*>(&(val)))
#define HALF2(val) (*reinterpret_cast<half2*>(&(val)))
//ptx
__device__ __forceinline__ void ldmatrix_sync(half *dst,half *src)
{
asm volatile(
"ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];"
: "=r"(REG(dst[0])),
"=r"(REG(dst[2])),
"=r"(REG(dst[4])),
"=r"(REG(dst[6]))
: "l"(__cvta_generic_to_shared(src)));
}
__device__ __forceinline__ void ldmatrix_trans_sync(half *dst, void *src)
{
//LD.trans trans frament 块内 N格式,寄存器按列存储读取
asm volatile(
"ldmatrix.sync.aligned.x4.m8n8.shared.trans.b16 {%0, %1, %2, %3}, [%4];"
: "=r"(REG(dst[0])),
"=r"(REG(dst[2])),
"=r"(REG(dst[4])),
"=r"(REG(dst[6]))
: "l"(__cvta_generic_to_shared(src)));
}
__device__ __forceinline__ void stmatrix_sync_x2(half *dst, half *src)
{
//sm_100 later
asm volatile(
"stmatrix.sync.aligned.m8n8.x2.shared.b16 [%0], {%1, %2};"
: // 无输出操作数,它从C/C++代码的角度看,是消耗了输入操作数(即寄存器%1和%2中的数据),整个操作过程并没有产生一个可供C/C++代码使用的“返回值”或“输出变量”,因此被声明为“无输出操作数”
: "l"(__cvta_generic_to_shared(dst)),
"r"(REG(src[0])),
"r"(REG(src[2]))
: "memory" //“memory”字段属于clobber列表的一部分,它告知编译器该汇编指令可能会修改内存内容,使用"memory"可以确保编译器不会缓存内存中的旧值,从而保证后续操作能读取到最新的数据
);
}
__device__ __forceinline__ void stmatrix_sync_x4(half *dst, half *src)
{
//sm_100 later
asm volatile(
"stmatrix.sync.aligned.m8n8.x4.shared.b16 [%0], {%1, %2, %3, %4};"
: // 无输出操作数,它从C/C++代码的角度看,是消耗了输入操作数(即寄存器%1和%2中的数据),整个操作过程并没有产生一个可供C/C++代码使用的“返回值”或“输出变量”,因此被声明为“无输出操作数”
: "l"(__cvta_generic_to_shared(dst)),
"r"(REG(src[0])),
"r"(REG(src[2])),
"r"(REG(src[4])),
"r"(REG(src[6]))
: "memory" //“memory”字段属于clobber列表的一部分,它告知编译器该汇编指令可能会修改内存内容,使用"memory"可以确保编译器不会缓存内存中的旧值,从而保证后续操作能读取到最新的数据
);
}
__device__ __forceinline__ void stmatrix_trans_sync_x4(half *dst, half *src)
{
//sm_100 later
//trans frament 块内 N格式,寄存器按列存储读取
asm volatile(
"stmatrix.sync.aligned.m8n8.x4.shared.trans.b16 [%0], {%1, %2, %3, %4};"
: // 无输出操作数,它从C/C++代码的角度看,是消耗了输入操作数(即寄存器%1和%2中的数据),整个操作过程并没有产生一个可供C/C++代码使用的“返回值”或“输出变量”,因此被声明为“无输出操作数”
: "l"(__cvta_generic_to_shared(dst)),
"r"(REG(src[0])),
"r"(REG(src[2])),
"r"(REG(src[4])),
"r"(REG(src[6]))
: "memory" //“memory”字段属于clobber列表的一部分,它告知编译器该汇编指令可能会修改内存内容,使用"memory"可以确保编译器不会缓存内存中的旧值,从而保证后续操作能读取到最新的数据
);
}
#define KEEP // 共享内存与寄存器矩阵布局保持一致
// #define NO_USE_ROW //加载数据不使用 rol col
//AOut: A矩阵转存结果;TOut: 保存每个线程寄存器数据
__global__ void ldkernel(half *A,half *B,half *AOut,half *BOut,half *TAOut,half *TBOut)
{
__shared__ half sA[16*16];
__shared__ half sAOut[16*16]; //保存转存结果
__shared__ half sB[16*16];
__shared__ half sBOut[16*16]; //保存转存结果
uint32_t tid = threadIdx.x;
//共享内存存储原始数据的数组,数据布局不变
ld_st_128bit(&sA[tid*8], A+tid*8);
ld_st_128bit(&sB[tid*8], B+tid*8);
__syncthreads();
//根据每个线程从全局内存转移的原始数据,作为 fragment 排布中对应线程号传入地址中的数据,来组织矩阵
uint32_t RA[4];
uint32_t RB[4];
//每个线程传入规定布局首地址,数据分发给其他线程的寄存器
uint32_t keep_row = tid%16; //保持矩阵布局不变的ld/st坐标
uint32_t keep_col = tid/16; //保持矩阵布局不变的ld/st坐标
uint32_t change_row = (tid*8)/16; //改变矩阵布局的ld/st坐标
uint32_t change_col = tid%2; //改变矩阵布局的ld/st坐标
#ifdef KEEP //寄存器矩阵与共享内存矩阵数据排布保持不变
ldmatrix_sync((half*)RA,sA + keep_row*16 + keep_col*8);
// lmatrix trans参数的作用:fragment 内按列读取,外N 内N格式
ldmatrix_trans_sync((half*)RB,sB + keep_row*16 + keep_col*8);
#else //重新组织共享内存矩阵排布:按对应线程号数据重新组织矩阵
#ifdef NO_USE_ROW
ldmatrix_sync((half*)RA,sA + tid*8);
ldmatrix_trans_sync((half*)RB,sB + tid*8);
#else
ldmatrix_sync((half*)RA,sA + change_row*16 + change_col*8);
// lmatrix trans参数的作用:fragment 内按列读取,外N 内N格式
ldmatrix_trans_sync((half*)RB,sB + change_row*16 + change_col*8);
#endif
#endif
#if 0
if(tid==0)
printf("thread 0,REG[0](%3.f,%3.f)\n",__half2float(*((half*)&RA[0])),__half2float(*((half*)&RA[0]+1)));
#endif
//线程内的元素连续保存到 TAOut
*(float*)(&TAOut[tid*8]) = *(float*)(&RA[0]);
*(float*)(&TAOut[tid*8+2]) = *(float*)(&RA[1]);
*(float*)(&TAOut[tid*8+4]) = *(float*)(&RA[2]);
*(float*)(&TAOut[tid*8+6]) = *(float*)(&RA[3]);
//线程内的元素连续保存到 TBOut
*(float*)(&TBOut[tid*8]) = *(float*)(&RB[0]);
*(float*)(&TBOut[tid*8+2]) = *(float*)(&RB[1]);
*(float*)(&TBOut[tid*8+4]) = *(float*)(&RB[2]);
*(float*)(&TBOut[tid*8+6]) = *(float*)(&RB[3]);
//转存A矩阵到 AOut
stmatrix_sync_x4(sAOut + keep_row*16 + keep_col*8,(half*)RA);
stmatrix_trans_sync_x4(sBOut + keep_row*16 + keep_col*8,(half*)RB);
// stmatrix_sync_x4(sBOut + keep_row*16 + keep_col*8,(half*)RB);
ld_st_128bit(AOut+ 8*tid,sAOut+ 8*tid);
ld_st_128bit(BOut+ 8*tid,sBOut+ 8*tid);
}
void initArr(half *A,uint32_t N)
{
for(int i=0;i<N;i++)
A[i] = __float2half((float)i);
}
void printMatrix(char* str,half *addr,uint32_t M,uint32_t N)
{
printf("%s",str);
for(int i=0;i<M;i++)
{
for(int j=0;j<N;j++)
printf("%3.f ",__half2float(addr[i*16+j]));
printf("\n");
}
}
void printThreadRegister(char *str,half *addr,uint32_t len)
{
printf("%s",str);
for(int i=0;i<32;i++)
{
printf("thread %2d,",i);
for(int j=0;j<4;j++)
{
printf(" reg[%d]:(%3.0f,%3.f)",j,__half2float(addr[i*8+j*2]),__half2float(addr[i*8+j*2+1]));
printf(";");
}
printf("\n");
}
}
int main()
{
half A[16*16]={0};
half AOut[16*16]={0}; //保存gpu 转存输出的A矩阵
half TAOut[16*16]={0}; //保存每个线程的寄存器数据
half B[16*16]={0};
half BOut[16*16]={0}; //保存gpu 转存输出的B矩阵
half TBOut[16*16]={0}; //保存每个线程的寄存器数据
initArr(A,16*16);
initArr(B,16*16);
printMatrix("原始数组A数据:\n",A,16,16);
printMatrix("原始数组B数据:\n",B,16,16);
half *DA = NULL;
half *DAOut = NULL;
half *DTAOut = NULL; //保存线程中A矩阵寄存器数据
half *DB = NULL;
half *DBOut = NULL;
half *DTBOut = NULL; //保存线程中B矩阵寄存器数据
cudaMalloc((void**)&DA,16*16*sizeof(half));
cudaMalloc((void**)&DAOut,16*16*sizeof(half));
cudaMalloc((void**)&DTAOut,16*16*sizeof(half));
cudaMalloc((void**)&DB,16*16*sizeof(half));
cudaMalloc((void**)&DBOut,16*16*sizeof(half));
cudaMalloc((void**)&DTBOut,16*16*sizeof(half));
cudaMemcpy(DA,A,16*16*sizeof(half),cudaMemcpyHostToDevice);
cudaMemcpy(DB,B,16*16*sizeof(half),cudaMemcpyHostToDevice);
ldkernel<<<1,32>>>(DA,DB,DAOut,DBOut,DTAOut,DTBOut);
cudaMemcpy(AOut,DAOut,16*16*sizeof(half),cudaMemcpyDeviceToHost);
cudaMemcpy(TAOut,DTAOut,16*16*sizeof(half),cudaMemcpyDeviceToHost);
cudaMemcpy(BOut,DBOut,16*16*sizeof(half),cudaMemcpyDeviceToHost);
cudaMemcpy(TBOut,DTBOut,16*16*sizeof(half),cudaMemcpyDeviceToHost);
//按寄存器矩阵的主序,打印寄存器矩阵
printf("按寄存器矩阵的主序,打印寄存器矩阵\n");
#ifdef KEEP
printf("共享内存矩阵与寄存器矩阵排布一致:\n");
#else
printf("重新组织寄存器矩阵: 按照寄存器矩阵线程号对应的线程号搬运到共享内存数据重新排布矩阵\n");
#endif
printMatrix("A_Out:\n",AOut,16,16);
printMatrix("B_Out:\n",BOut,16,16);
//遍历每个线程的4个寄存区,8个 half 数据
printThreadRegister("遍历线程的A矩阵寄存器数据:\n",TAOut,16*16);
printThreadRegister("遍历线程的B矩阵寄存器数据:\n",TBOut,16*16);
cudaFree(DA);
cudaFree(DB);
cudaFree(DAOut);
cudaFree(DBOut);
cudaFree(DTAOut);
cudaFree(DTBOut);
return 0;
}
3. 测试结果
原始数组A数据:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127
128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143
144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175
176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191
192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207
208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223
224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239
240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255
原始数组B数据:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127
128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143
144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175
176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191
192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207
208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223
224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239
240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255
按寄存器矩阵的主序,打印寄存器矩阵
共享内存矩阵与寄存器矩阵排布一致:
A_Out:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127
128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143
144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175
176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191
192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207
208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223
224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239
240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255
B_Out:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127
128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143
144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175
176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191
192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207
208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223
224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239
240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255
遍历线程的A矩阵寄存器数据:
thread 0, reg[0]:( 0, 1); reg[1]:(128,129); reg[2]:( 8, 9); reg[3]:(136,137);
thread 1, reg[0]:( 2, 3); reg[1]:(130,131); reg[2]:( 10, 11); reg[3]:(138,139);
thread 2, reg[0]:( 4, 5); reg[1]:(132,133); reg[2]:( 12, 13); reg[3]:(140,141);
thread 3, reg[0]:( 6, 7); reg[1]:(134,135); reg[2]:( 14, 15); reg[3]:(142,143);
thread 4, reg[0]:( 16, 17); reg[1]:(144,145); reg[2]:( 24, 25); reg[3]:(152,153);
thread 5, reg[0]:( 18, 19); reg[1]:(146,147); reg[2]:( 26, 27); reg[3]:(154,155);
thread 6, reg[0]:( 20, 21); reg[1]:(148,149); reg[2]:( 28, 29); reg[3]:(156,157);
thread 7, reg[0]:( 22, 23); reg[1]:(150,151); reg[2]:( 30, 31); reg[3]:(158,159);
thread 8, reg[0]:( 32, 33); reg[1]:(160,161); reg[2]:( 40, 41); reg[3]:(168,169);
thread 9, reg[0]:( 34, 35); reg[1]:(162,163); reg[2]:( 42, 43); reg[3]:(170,171);
thread 10, reg[0]:( 36, 37); reg[1]:(164,165); reg[2]:( 44, 45); reg[3]:(172,173);
thread 11, reg[0]:( 38, 39); reg[1]:(166,167); reg[2]:( 46, 47); reg[3]:(174,175);
thread 12, reg[0]:( 48, 49); reg[1]:(176,177); reg[2]:( 56, 57); reg[3]:(184,185);
thread 13, reg[0]:( 50, 51); reg[1]:(178,179); reg[2]:( 58, 59); reg[3]:(186,187);
thread 14, reg[0]:( 52, 53); reg[1]:(180,181); reg[2]:( 60, 61); reg[3]:(188,189);
thread 15, reg[0]:( 54, 55); reg[1]:(182,183); reg[2]:( 62, 63); reg[3]:(190,191);
thread 16, reg[0]:( 64, 65); reg[1]:(192,193); reg[2]:( 72, 73); reg[3]:(200,201);
thread 17, reg[0]:( 66, 67); reg[1]:(194,195); reg[2]:( 74, 75); reg[3]:(202,203);
thread 18, reg[0]:( 68, 69); reg[1]:(196,197); reg[2]:( 76, 77); reg[3]:(204,205);
thread 19, reg[0]:( 70, 71); reg[1]:(198,199); reg[2]:( 78, 79); reg[3]:(206,207);
thread 20, reg[0]:( 80, 81); reg[1]:(208,209); reg[2]:( 88, 89); reg[3]:(216,217);
thread 21, reg[0]:( 82, 83); reg[1]:(210,211); reg[2]:( 90, 91); reg[3]:(218,219);
thread 22, reg[0]:( 84, 85); reg[1]:(212,213); reg[2]:( 92, 93); reg[3]:(220,221);
thread 23, reg[0]:( 86, 87); reg[1]:(214,215); reg[2]:( 94, 95); reg[3]:(222,223);
thread 24, reg[0]:( 96, 97); reg[1]:(224,225); reg[2]:(104,105); reg[3]:(232,233);
thread 25, reg[0]:( 98, 99); reg[1]:(226,227); reg[2]:(106,107); reg[3]:(234,235);
thread 26, reg[0]:(100,101); reg[1]:(228,229); reg[2]:(108,109); reg[3]:(236,237);
thread 27, reg[0]:(102,103); reg[1]:(230,231); reg[2]:(110,111); reg[3]:(238,239);
thread 28, reg[0]:(112,113); reg[1]:(240,241); reg[2]:(120,121); reg[3]:(248,249);
thread 29, reg[0]:(114,115); reg[1]:(242,243); reg[2]:(122,123); reg[3]:(250,251);
thread 30, reg[0]:(116,117); reg[1]:(244,245); reg[2]:(124,125); reg[3]:(252,253);
thread 31, reg[0]:(118,119); reg[1]:(246,247); reg[2]:(126,127); reg[3]:(254,255);
遍历线程的B矩阵寄存器数据:
thread 0, reg[0]:( 0, 16); reg[1]:(128,144); reg[2]:( 8, 24); reg[3]:(136,152);
thread 1, reg[0]:( 32, 48); reg[1]:(160,176); reg[2]:( 40, 56); reg[3]:(168,184);
thread 2, reg[0]:( 64, 80); reg[1]:(192,208); reg[2]:( 72, 88); reg[3]:(200,216);
thread 3, reg[0]:( 96,112); reg[1]:(224,240); reg[2]:(104,120); reg[3]:(232,248);
thread 4, reg[0]:( 1, 17); reg[1]:(129,145); reg[2]:( 9, 25); reg[3]:(137,153);
thread 5, reg[0]:( 33, 49); reg[1]:(161,177); reg[2]:( 41, 57); reg[3]:(169,185);
thread 6, reg[0]:( 65, 81); reg[1]:(193,209); reg[2]:( 73, 89); reg[3]:(201,217);
thread 7, reg[0]:( 97,113); reg[1]:(225,241); reg[2]:(105,121); reg[3]:(233,249);
thread 8, reg[0]:( 2, 18); reg[1]:(130,146); reg[2]:( 10, 26); reg[3]:(138,154);
thread 9, reg[0]:( 34, 50); reg[1]:(162,178); reg[2]:( 42, 58); reg[3]:(170,186);
thread 10, reg[0]:( 66, 82); reg[1]:(194,210); reg[2]:( 74, 90); reg[3]:(202,218);
thread 11, reg[0]:( 98,114); reg[1]:(226,242); reg[2]:(106,122); reg[3]:(234,250);
thread 12, reg[0]:( 3, 19); reg[1]:(131,147); reg[2]:( 11, 27); reg[3]:(139,155);
thread 13, reg[0]:( 35, 51); reg[1]:(163,179); reg[2]:( 43, 59); reg[3]:(171,187);
thread 14, reg[0]:( 67, 83); reg[1]:(195,211); reg[2]:( 75, 91); reg[3]:(203,219);
thread 15, reg[0]:( 99,115); reg[1]:(227,243); reg[2]:(107,123); reg[3]:(235,251);
thread 16, reg[0]:( 4, 20); reg[1]:(132,148); reg[2]:( 12, 28); reg[3]:(140,156);
thread 17, reg[0]:( 36, 52); reg[1]:(164,180); reg[2]:( 44, 60); reg[3]:(172,188);
thread 18, reg[0]:( 68, 84); reg[1]:(196,212); reg[2]:( 76, 92); reg[3]:(204,220);
thread 19, reg[0]:(100,116); reg[1]:(228,244); reg[2]:(108,124); reg[3]:(236,252);
thread 20, reg[0]:( 5, 21); reg[1]:(133,149); reg[2]:( 13, 29); reg[3]:(141,157);
thread 21, reg[0]:( 37, 53); reg[1]:(165,181); reg[2]:( 45, 61); reg[3]:(173,189);
thread 22, reg[0]:( 69, 85); reg[1]:(197,213); reg[2]:( 77, 93); reg[3]:(205,221);
thread 23, reg[0]:(101,117); reg[1]:(229,245); reg[2]:(109,125); reg[3]:(237,253);
thread 24, reg[0]:( 6, 22); reg[1]:(134,150); reg[2]:( 14, 30); reg[3]:(142,158);
thread 25, reg[0]:( 38, 54); reg[1]:(166,182); reg[2]:( 46, 62); reg[3]:(174,190);
thread 26, reg[0]:( 70, 86); reg[1]:(198,214); reg[2]:( 78, 94); reg[3]:(206,222);
thread 27, reg[0]:(102,118); reg[1]:(230,246); reg[2]:(110,126); reg[3]:(238,254);
thread 28, reg[0]:( 7, 23); reg[1]:(135,151); reg[2]:( 15, 31); reg[3]:(143,159);
thread 29, reg[0]:( 39, 55); reg[1]:(167,183); reg[2]:( 47, 63); reg[3]:(175,191);
thread 30, reg[0]:( 71, 87); reg[1]:(199,215); reg[2]:( 79, 95); reg[3]:(207,223);
thread 31, reg[0]:(103,119); reg[1]:(231,247); reg[2]:(111,127); reg[3]:(239,255);
4. mma 指令分析
- 本测试用例用一个 warp大小的block ,对 fp16(16 * 16)的矩阵数据转移通路为:global -> sharedMemory -> register -> global。
4.1 ldmatrix:从共享内存加载矩阵A到寄存器
asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];" \
: "=r"(R0), "=r"(R1), "=r"(R2), "=r"(R3) \
: "r"(addr))
-
m8n8:fragment 大小为 8 * 8;
-
x4:共有4个 fragment;一个warp负责对4个 frament 进行mma 计算,一个 fragment一次mma计算,共进行四次 mma 计算;
-
对于一个 8 * 8 的 fragment,8个线程提供8个 fragment 行的首地址;对于 2* 2 的fragment,线程提供地址的布局为 "N" 格式:
thread(0-7) thread(16-23) thread(8-15) thread(24-31)
-
每个线程有4个向量寄存器,每个寄存器有 2个fp16数据;
-
4个 fragment 的A矩阵整体布局如下:
- 左上角 fragment_0 存储warp所有线程的 REGISTER[0],左下角 fragment_1 存储所有线程的 REGISTER[1],右上角 fragment_2 存储所有线程的 REGISTER[2],右上角 fragment_3 存储所有线程的 REGISTER[3];

- 一个 fragment 行有8个 fp16,由 4个线程的4个寄存器分别持有;
- ldmatrix 传入的寄存器地址提供了 fragment 行的首地址,数据分发给4线程的4个寄存器;比如线程0,传入了线程0的 REGISTER[0] 地址,传入的共享内存数据 0-7,分别分发给了线程0-3 的 REGISTER[0],如下图:

- 线程0的四个向量寄存器保存数据为 0, 1, 128, 129, 8, 9, 136,137,详细布局如下图:

4.1.1 带 trans 参数的 ldmatrix,加载矩阵B到寄存器
asm volatile(
"ldmatrix.sync.aligned.x4.m8n8.shared.trans.b16 {%0, %1, %2, %3}, [%4];"
: "=r"(REG(dst[0])),
"=r"(REG(dst[2])),
"=r"(REG(dst[4])),
"=r"(REG(dst[6]))
: "l"(__cvta_generic_to_shared(src)));
-
trans:frament 块内 N格式,寄存器按列存储读取,内N外N的格式读写。不改变原矩阵的数据排布,只改变寄存器的读写方向。
-
以16 * 8有2个 fragment 的矩阵为例,整体布局如下:
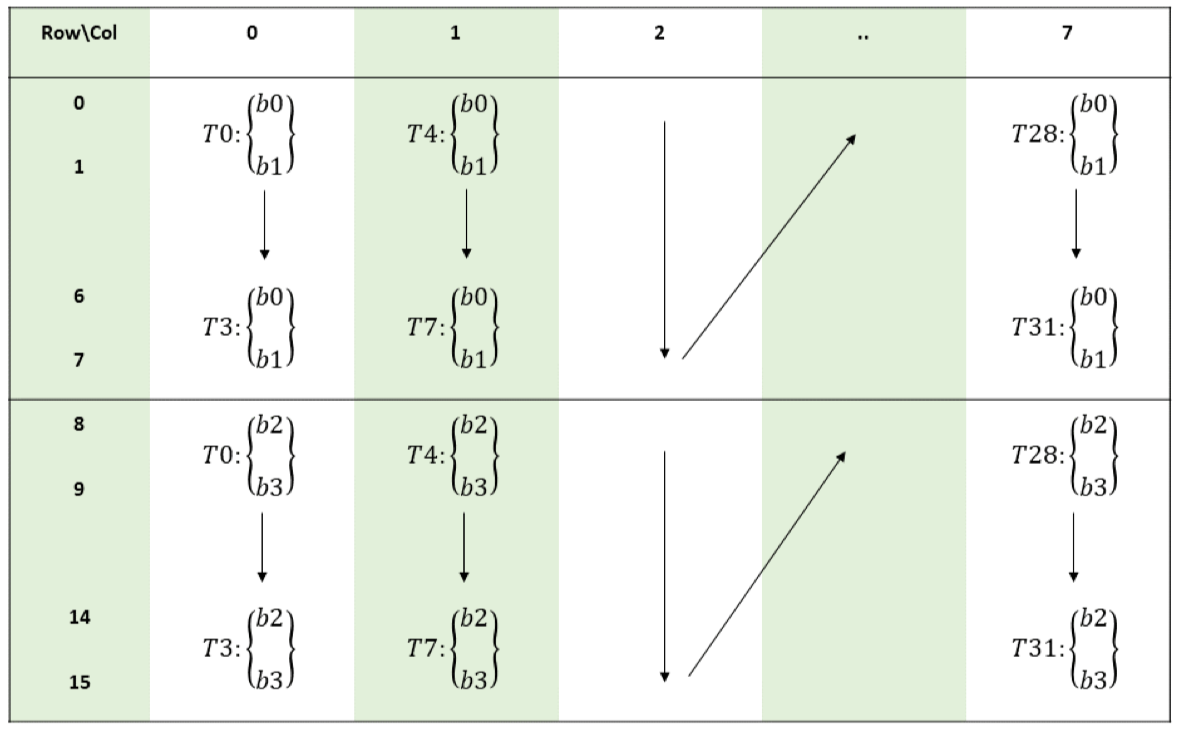
- 以本测试用力B矩阵为例,0号线程读取数据为
0, 16, 128, 144, 8, 24, 136, 152,详细布局如下图:

4.1.2 寄存器与共享内存矩阵不一致的方式加载数据
- 需要改变线程读取数据的位置,以下提供一种算法:
uint32_t change_row = (tid*8)/16; //改变矩阵布局的ld/st坐标
uint32_t change_col = tid%2; //改变矩阵布局的ld/st坐标
- 线程0的四个向量寄存器保存数据为
0, 1, 64, 65, 128, 129, 192, 193, 详细布局如下图:

4.2 stmatrix: 保存寄存数据到共享内存
asm volatile(
"stmatrix.sync.aligned.m8n8.x4.shared.b16 [%0], {%1, %2, %3, %4};"
: // 无输出操作数,它从C/C++代码的角度看,是消耗了输入操作数(即寄存器%1和%2中的数据),整个操作过程并没有产生一个可供C/C++代码使用的“返回值”或“输出变量”,因此被声明为“无输出操作数”
: "l"(__cvta_generic_to_shared(dst)),
"r"(REG(src[0])),
"r"(REG(src[2])),
"r"(REG(src[4])),
"r"(REG(src[6]))
: "memory" //“memory”字段属于clobber列表的一部分,它告知编译器该汇编指令可能会修改内存内容,使用"memory"可以确保编译器不会缓存内存中的旧值,从而保证后续操作能读取到最新的数据
);
- 给 PTX 指令提供数据地址的线程排布与 ldmatrix 一致。
- 如果 ldmatrix 时使用 trans,stmatrix 时也是用 trans,该矩阵数据排布不变。
4.2 mma:矩阵乘累加计算
asm volatile("mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 {%0, %1}, {%2, %3, %4, %5}, {%6, %7}, {%8, %9};" \
: "=r"(RD0), "=r"(RD1) : "r"(RA0), "r"(RA1), "r"(RA2), "r"(RA3), "r"(RB0), "r"(RB1), "r"(RC0), "r"(RC1))
-
m16n8k16:A(16 * 16) B(16 * 16) 两个矩阵相乘,查手册 fp16 使用size m16n8k16 ,切分数据进行2次 mma 计算;
-
.row:矩阵A按行存储;
-
.col:矩阵B按列存储;
-
决定了ld/st 的PTX指令API。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号