数据结构
数据结构定义
我们如何把现实中大量而且非常复杂的问题以特定的数据类型(个体)和特定的存储结构(个体的关系)保存到相应的主存储器(内容)中,以及在此基础上为实现某个功能而执行的相应操作,这个相应的操作也叫做算法
数据结构==个体+个体的关系
算法==对存储数据的操作
数据结构的特点
数据结构是软件中最核心的课程
程序=数据的存储+数据的操作+可以而被计算机执行的语言
线性结构
把所有的节点用一根线串起来
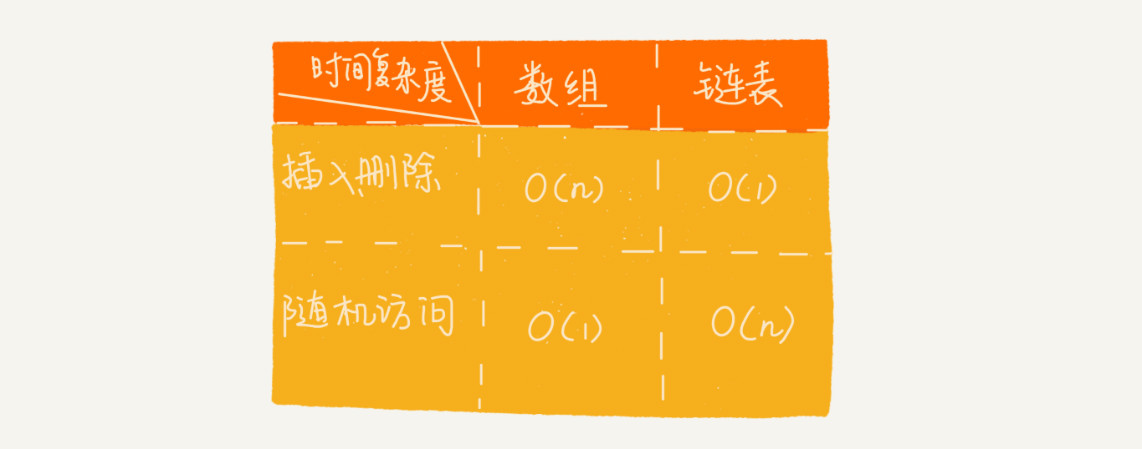
数组和链表的区别
数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个 100MB 大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败。 而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是 100MB 大小的链表,根本不会有问题。

连续存储(数组)
数组,在其python中称为列表,是一种基本的数据结构类型
查询的时间复杂度O(1)
修改删除的时间复杂度O(n)
数组的优点:
- 存取速度快
缺点:
事先需要知道数组的长度
需要大块的连续内存
插入删除非常的慢,效率极低
离散存储(链表)
定义:
- n个节点离散分配
- 彼此通过指针相连
- 每个节点只有一个前驱节点,每个节点只有一个后续节点
- 首节点没有前驱节点,尾节点没有后续节点
优点:
- 空间没有限制,插入删除元素很快
缺点:
- 查询较比慢
链表的节点结构


data为自定义的数据,next为下一个节点的地址
专业术语:
- 首节点:第一个有效节点
- 尾节点:最后一个有效节点
- 头结点:第一个有效节点之前的那个节点,头节点并不存储任何数据,目的是为了方便对链表的操作
- 头指针:指向头节点的指针变量
- 尾指针:指向尾节点的指针变量
链表的分类:
- 单链表
- 双链表,每一个节点有两个指针域
- 循环链表,能通过任何一个节点找到其他所有的节点
- 非循环链表
算法:
- 增加
- 删除
- 修改
- 查找
- 总长度
单链表的算法
class Hero(object): def __init__(self, no=None, name=None, nickname=None, pNext=None): self.no = no self.name = name self.nickname = nickname self.pNext = pNext def add(head, hero): ### 后面添加 # head.pNext = hero cur = head # print(id(cur), id(head)) while cur.pNext != None: if cur.pNext.no > hero.no: break cur = cur.pNext hero.pNext = cur.pNext cur.pNext = hero # print(id(cur), id(head)) def showAll(head): cur = head while cur.pNext != None: cur = cur.pNext print(cur.no, cur.name) def delHero(head, no): cur = head while cur.pNext != None: if cur.pNext.no == no: break cur = cur.pNext ### cur += 1 cur.pNext = cur.pNext.pNext head = Hero() h1 = Hero(1, 'h1', '及时雨') add(head, h1) h2 = Hero(2, 'h2', '玉麒麟') add(head, h2) h4 = Hero(4, 'h3', '智多星') add(head, h4) h3 = Hero(3, 'h4', '智多星') add(head, h3) showAll(head)
数组和链表的性能比较
栈
栈的定义
一种可以实现"先进后出"的存储结构
栈类似于一个箱子,先放进去的书,最后才能取出来,同理,后放进去的书,先取出来

栈的分类
静态栈:静态栈的核心是数组,类似于一个连续内存的数组,我们只能操作其栈顶元素
动态栈:动态栈的核心是链表

栈的算法
栈的算法主要是压栈和出栈两种操作的算法
理解思路:
- 栈操作的是一个个节点
- 栈本身也是一种存储的数据结构
- 栈有初始化,压栈,出栈,判空,遍历,清空等主要方法
栈的应用
函数的调用
浏览器的前进和后退
表达式求值
内存分配
树
树的定义
我们可以简单的认为:
- 树有且仅有一个根节点
- 有若干个互不相交的子树,这些子树本身也是一颗树
通俗的定义:
- 树就是由节点和边组成的
- 每一个节点只能有一个父节点,但可以有多个子节点,但有一个节点例外,该节点没有父节点,此节点就称为根节点
树的专业术语
节点
父节点
子节点
子孙
堂兄弟
兄弟
深度:从根节点到最底层节点的层数被称为深度,根节点是第一层
叶子节点:没有子节点的节点
度:子节点的个数
树的分类
一般树:任意一个节点的子节点的个数不受限制
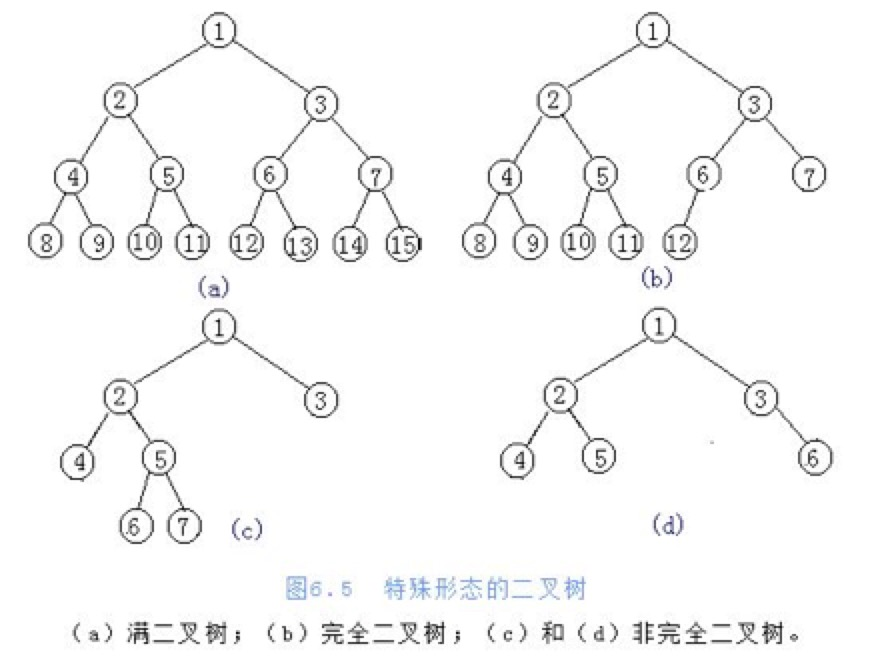
二叉树:
- 定义:任意一个节点的子节点的个数最多是两个,且子节点的位置不可更改
满二叉树:
- 定义:在不增加层数的前提下,无法再多添加一个节点的二叉树
完全二叉树:
- 定义:只是删除了满二叉树最底层最右边连续的若干个节点
一般二叉树
森林:n个互不相交的数的集合
树的操作
把一个非线性的结构数据转换成一个线性结构的数据存储起来
一般树的存储
- 双亲表示法:求父节点方便
- 孩子表示法:求子节点方便
- 双亲孩子表示法:求父节点和子节点都很方便
- 二叉树表示法
- 即把一般树转换成二叉树,按照二叉树的方式进行存储
- 具体的转化办法:
- 设法保证任意一个节点的左指针指向它的第一个孩子
- 设法保证任意一个节点的右指针指向它的下一个兄弟
- 只要能满足上述的条件就能够转化成功
二叉树的操作
连续存储(完全二叉树,数组方式进行存储)
- 优点:查找某个节点的父节点和子节点非常的快
- 缺点:耗用内存空间过大
- 转化的方法:先序,中序,后序
链式存储(链表存储)
- data区域,左孩子区域,右孩子区域
森林的操作
- 把所有的数转化成二叉树,方法同一般树的转化
二叉树具体的操作
1.二叉树的先序遍历(先访问根节点)
先访问根节点
再先序遍历左子树
再先序遍历右子树
2.二叉树的中序遍历(中间访问根节点)
先中序遍历左子树
再访问根节点
再中序遍历右子树
3.二叉树的后序遍历(最后访问根节点)
先中序遍历左子树
再中序遍历右子树
再访问根节点
4.已知先序和中序,求出后序
#### 例一 先序:ABCDEFGH 中序:BDCEAFHG 求后序? 后序:DECBHGFA #### 例二 先序:ABDGHCEFI 中序:GDHBAECIF 求后序? 后序:GHDBEIFCA
5.已知中序和后序,求出先序
中序:BDCEAFHG
后序:DECBHGFA
求先序?
先序:ABCDEFGH
树的应用
树是数据库中数据组织的一种重要形式
操作系统子父进程的关系本身就是一颗树
面向对象语言中类的继承关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号