伪分布式Hadoop+Zookeeper+HBase+Phoenix搭建
本次搭建运行环境在Windows10下的linux子系统进行搭建(linux我使用ubuntu,用其它都可以)
目前先搭建Hadoop+Zookeeper+HBase+Phoenix,后续会慢慢的增加的吧🐒
Hadoop官网:http://hadoop.apache.org/
Zookeeper官网:http://zookeeper.apache.org/
HBase官网:https://hbase.apache.org/
Phoenix官网:https://phoenix.apache.org/
如果懒得看我下面的配置,可以前往这里,我是通过这里进行学习的(官方文档还是很稳的🐒):
Hadoop配置:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation
Zookeeper配置:https://zookeeper.apache.org/doc/current/zookeeperStarted.html
HBase配置:http://hbase.apache.org/book.html#quickstart
Phoenix配置:https://phoenix.apache.org/installation.html
准备工作:
1.前往Microsoft store 安装好看的Windows Terminal(如果想要知道如何加在右键菜单上,去搜一下就有了)
2.前往Microsoft store 安装Ubuntu 20.04LTS(进行一些基础的配置,大概就是配置一下账号密码而已)
3.前往https://mirror.bit.edu.cn/apache下载对应的大数据平台的组件,我这边的配置是根据cdh来的,跟着平台走比较稳:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_62_packaging.html
- https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/
- https://archive.apache.org/dist/zookeeper/zookeeper-3.4.5/
- https://archive.apache.org/dist/hbase/2.1.2/
- https://archive.apache.org/dist/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/
- 如果不想按上面的版本来,这个地址有许多的历史版本可以去下载(https://archive.apache.org/dist/)
4.下载(https://www.netsarang.com/zh/xftp)学习版本(用来传输下载下来的组件,当然你也可以在linux下用wget指令下载,还省去这个麻烦的步骤,也可以直接不需要它)
5.下载(https://code.visualstudio.com),下vscode用来打开文件编辑,我感觉我傻傻的😏,进去后需要用下载这个组件(Remote Development)
上面都准备完成后,开始进入主题
第一步:
先更新一下ubuntusudo apt update
下载jdk1.8,一定要java8,java11容易出问题巨坑
apt-cache search openjdk可以查看所有jdk版本
sudo apt-get install openjdk-8-jdk安装这个
安装成功执行java -version

就是正确的
java的目录在/usr/lib/jvm下
运行Phoenix下的py脚本需要安装python
sudo apt-get install python
在ubuntu安装ssh,用来做连接 sudo apt install openssh-server
生成密钥sudo ssh-keygen -A
编辑sudo vi /etc/ssh/sshd_config
找到 PasswordAuthentication no将其更改为yes,保存退出
vi的操作方式:i编辑,esc后输入:wq!保存离开
启动ssh sudo service ssh --full-restart

第二步:
使用xftp工具连接ubuntu,将我们下载的组件都扔到某个目录下,具体自己定。(建议在linux下进行下载,不用移来移去wget指令)
使用tar -xvf *.tar.gz解压
通过vscode连接linux,打开hadoop的目录

如果没有连接过就选择Add New SSH Host
录入格式请看输入框提示,如:ssh 用户名@linux地址 ssh root@localhost
录入完可以自行选择保存地址,选择保存地址后,右下角估计会弹出一个提示Host added!,点击connect即可,过程中会让你选择连接的系统,并且输入密码
连接成功后,下次再连接,可以通过远程资源管理进行
第三步配置环境变量:
这个时候就得将所有解压出来的指令配置在变量中,方便我们日常使用而不用经常跑到目录下去使用它的指令
打开sudo vi /etc/profile
直接在头部增加我们的环境变量代码
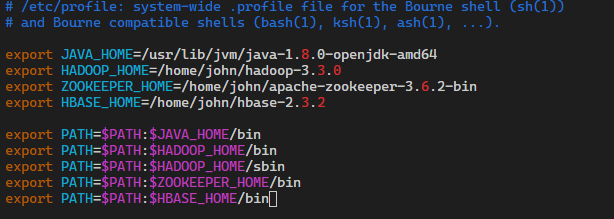
大概这样的格式
vi的操作方式:i编辑,esc后输入:wq!保存离开
执行source /etc/profile
执行完后,可以通过echo $变量名进行验证
第四步Hadoop配置:
回到我们的资源管理器,打开文件夹,选择我们的Hadoop目录
前往hadoop目录下,目前我们这帮新手接触最多的估计就是这几个文件
hadoop-env.sh, core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml
hadoop-env.sh的配置
在开头加上JAVA_HOME的路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
core-site.xml的配置
<configuration>
<!-- hdfs地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml的配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml的配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
yarn-site.xml的配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
设置无密码的ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
配置完成后执行
hdfs namenode -format格式化文件系统
start-dfs.sh启动NameNode、DataNode、SecondaryNameNode
start-yarn.sh启动NodeManager和ResourceManager
想要停止也有对应的stop指令,不过我就懒人了,使用start-all.sh就会调用上面两个指令
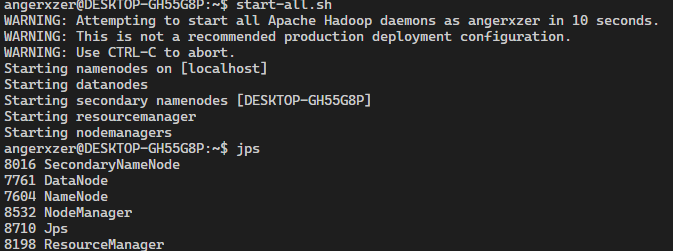
启动成功可以访问(http://localhost:9870)进行查看,上面配置文件的具体解释看官方文档的说明
第五步Zookeeper配置:
Zookeeper的配置就相当简单了,只需要把自带的zoo_sample.cfg模板里面的内容,复制到新创建的zoo.cfg里去即可
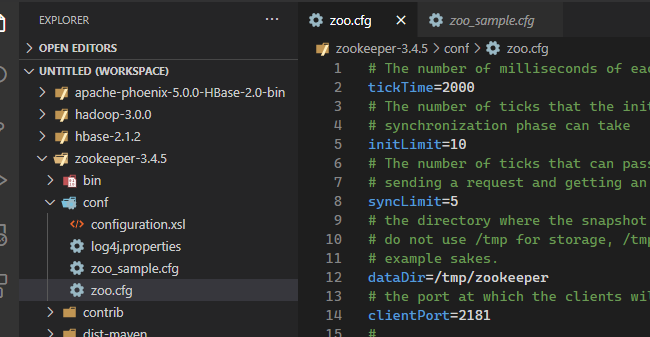
然后通过zkServer.sh start启动我们的zookeeper
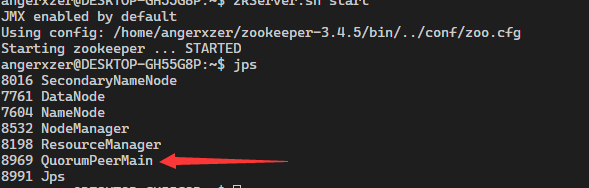
第六步HBase配置:
HBase的主要配置文件hbase-env.sh,hbase-site.xml
还是老样子,在hbase-env.sh开头处加上JAVA_HOME的路径,然后关闭自带的Zookeeper
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export HBASE_MANAGES_ZK=false
export HBASE_PID_DIR=改成自己的路径/hbase-2.1.2/pids
hbase-site.xml的配置(这里采用伪分布式的部署,里面的地址按自己设置的进行配置)
<configuration>
<!-- 部署在Hadoop下的文件系统中 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<!-- 解决list_namespace java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper的错误 -->
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<!-- 开启分布式运行 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 配置在外置的Zookeeper下 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<!-- 配置在外置的Zookeeper的端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>改成自己的路径</value>
</property>
<!-- 使用我们电脑的文件系统,作为数据存储,解决Failed to become active master异常 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
然后我们就可以执行start-hbase.sh开启我们的HBase了
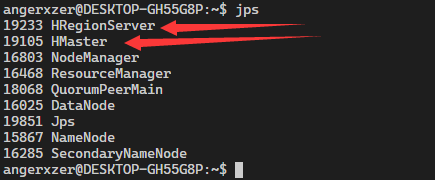
可以通过(http://localhost:16010)进行查看
第七步Phoenix配置:
将我们的目录下的
phoenix-5.0.0-HBase-2.0-server.jar
phoenix-core-5.0.0-HBase-2.0.jar
放到HBase的lib目录下
修改HBase下的hbase-site.xml,增加两个属性
<!-- 二级索引支持 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<!-- Phoenix 开启 schema 与 namespace 的对应关系 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
然后将HBase的hbase-site.xml文件里的内容,直接copy到Phoenix下的hbase-site.xml下
然后通过Phoenix bin目录下的sqlline.py zookeeper地址运行起来
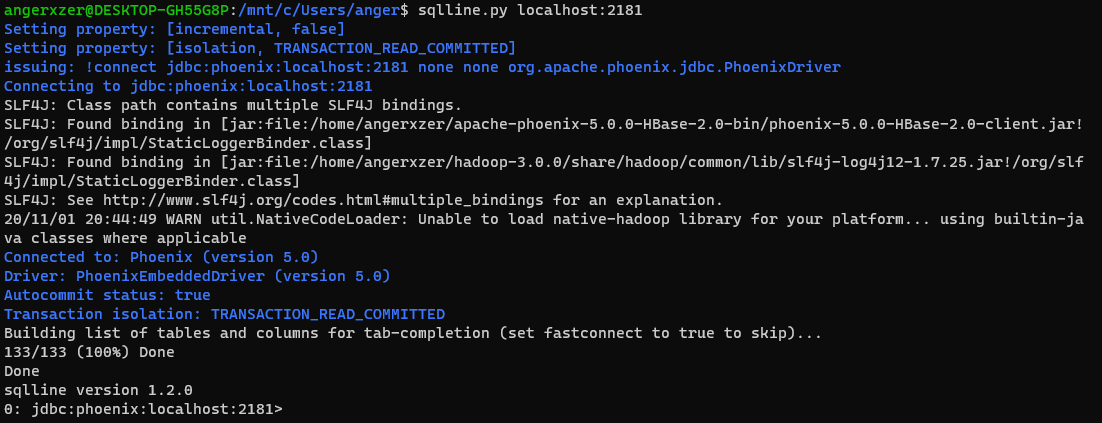
至此我们的初步搭建已算完成
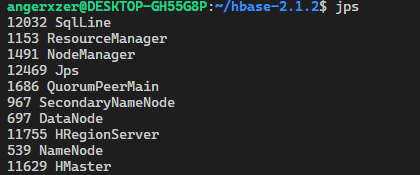
第八步Phoenix的使用:
!table查看所有的表,这里强烈建议一切按大写命名规则,Phoenix的巨坑

如果创建表出现这个错误:Error: ERROR 722 (43M05): Schema does not exist schemaName=test (state=43M05,code=722)
就需要手动创建命名空间create Schema "*";
导入的文档地址:https://phoenix.apache.org/bulk_dataload.html
csv导入psql.py -t tableName zookeeper地址 data.csv
二级索引的文档地址:http://phoenix.apache.org/secondary_indexing.html
建立异步二级索引(踩坑了,这个版本建立不了异步索引,因为commons-cli版本为1.2的🙈)
CREATE INDEX ASYNC_INDEX ON "namespace"."tableName" ("列簇名"."列名") ASYNC
hbase org.apache.phoenix.mapreduce.index.IndexTool --schema namespace --data-table table --index-table INDEX --output-path ASYNC_IDX_HFILES
建立索引
CREATE INDEX indexName ON tableName (ColumnName);
删除索引
DROP INDEX indexName ON tableName;
第九步通过JAVA访问Phoenix API(后续大概思路也是通过JAVA提供接口便于其他语言访问了):
我们前面无论配置的多么繁琐,最主要的目的还是存储我们的数据,查询我们的数据
Phoenix操作HBase有两种办法:
1、一种是通过Phoenix core和Phoenix client两个jar包来访问(Thick Driver),但是我一直失败,没成功过,也没找出原因,就放弃了这种做法
2、通过Phoenix的QueryServer暴露出来的API进行操作(Thin Driver),这个是文档地址:http://phoenix.apache.org/server.html
这次我们主要采用第二种方法,首先需要修改HBase和Phoenix下的hbase-site.xml,增加几个属性
<property>
<name>phoenix.queryserver.http.port</name>
<value>8765</value>
</property>
<property>
<name>phoenix.queryserver.metafactory.class</name>
<value>org.apache.phoenix.queryserver.server.PhoenixMetaFactoryImpl</value>
</property>
<property>
<name>phoenix.queryserver.serialization</name>
<value>PROTOBUF</value>
</property>
配置完成后,通过queryserver.py [start|stop]启动,启动成功如下
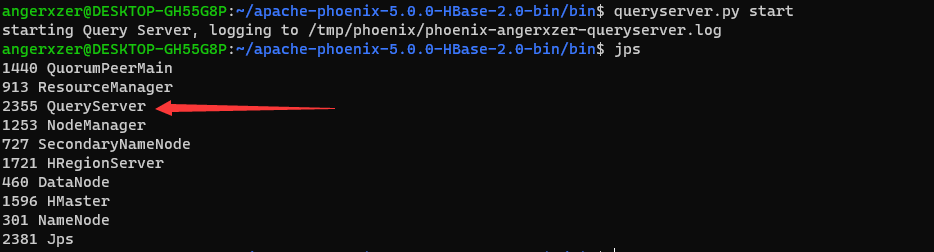
接下来会用到的工具有:IDEA,Maven,至于这两个的使用我还不太熟悉,你们就去找其他博客学习学习🙈
当然,使用Maven记得配置一下国内镜像源,下载包的速度会比较快,然后IDEA需要配置一下编码,有乱码的情况会出现
使用IDEA新建Maven Project(这是一个控制台项目,我不是主要搞java的怎么方便怎么来),这里我就不打勾了
在main=>java下新建Program类,增加main方法作为我们的程序入口
配置Maven项目的启动
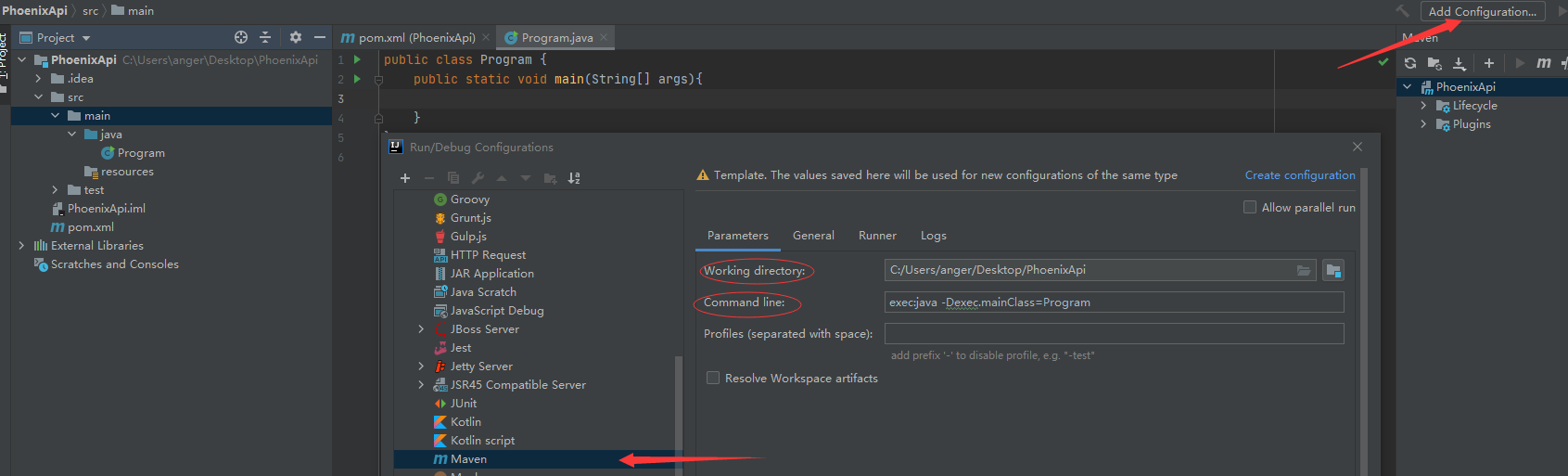
可以尝试Run,能否正常运行
接下来就是配置pom.xml文件,通过maven下载我们需要用到的包
<dependencies>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.6</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.13.0</version>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20200518</version>
</dependency>
</dependencies>
下载我们的Maven包,下载完成后会出现Dependencies这个文件夹
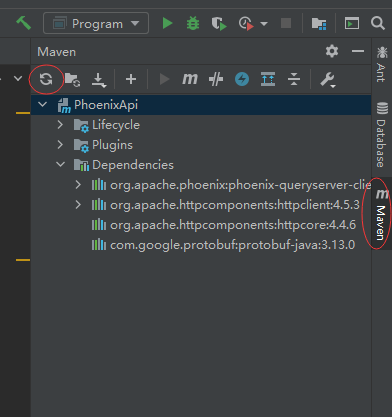
连接的代码如下(能到这里跑通代码已经不容易了下😭,如果加上了kerberos验证这里估计会有个天大的巨坑):
public class Program {
public static void main(String[] args){
try{
Class.forName("org.apache.phoenix.queryserver.client.Driver");
Connection conn = DriverManager.getConnection("jdbc:phoenix:thin:url=http://localhost:8765;serialization=PROTOBUF");
print("连接成功!");
}catch (Exception ex){
print(ex.getMessage());
}
}
public static void print(String msg){
System.out.println(msg);
}
}
