Pandas遍历行列的方法
 使用pandas读取数据为DataFrame后,遍历行列的方法
使用pandas读取数据为DataFrame后,遍历行列的方法
〇、数据
0.1 原数据如下
假设我们有以下数据(dorm.csv)
XH,XM,XB,XY
202257694105,秦始皇,男,机电工程学院
202264102743,商鞅,男,机电工程学院
202287626690,王安石,男,机电工程学院
202248753397,吕不韦,男,管理学院
202296533475,朱元璋,男,管理学院
202200542807,曹操,男,管理学院
202289055551,赵匡胤,女,管理学院
202217071922,赢政,女,管理学院
202204415323,刘邦,女,管理学院
202296448632,诸葛亮,女,管理学院
202215757718,李世民,女,管理学院
202229631163,孔融 ,男,国际教育学院
202220646023,李白,男,国际教育学院
202269847696,杜甫,男,国际教育学院
202220640437, 白居易,男,国际教育学院
202211178434,刘禹锡,男,国际教育学院
202263751024,李商隐,男,国际教育学院
202289662584,杜牧,男,机电工程学院
202273777190,李贺,男,机电工程学院
202279761033,张九龄,男,机电工程学院
0.2 读取代码如下
import pandas as pd
name_dict = {
'XH': '学号',
'XM': '姓名',
'XB': '性别',
'XY': '学院名称',
}
dorm = pd.read_csv(
'part.csv', # 要读取的文件
sep=',', # 使用的分隔符
header=0, # 标题行索引,0是第一行
usecols=name_dict.keys(), # 想要读取的列
dtype='string', # 按此类型进行读取和处理
)
dorm.columns = name_dict.values() # 更改字段名
print(dorm)
读取结果如下:

一、遍历行
# 使用iterrows方法
for index, row in dorm.iterrows():
"""Iterate over DataFrame rows as (index, Series) pairs."""
print(row['姓名'], row['性别'], row['学号'])
# 使用itertuples方法
for row in dorm.itertuples():
"""Iterate over DataFrame rows as namedtuples."""
print(row.姓名, row.性别, row.学号)
遍历效果图如下:

二、遍历列
# 可摘选指定列进行遍历
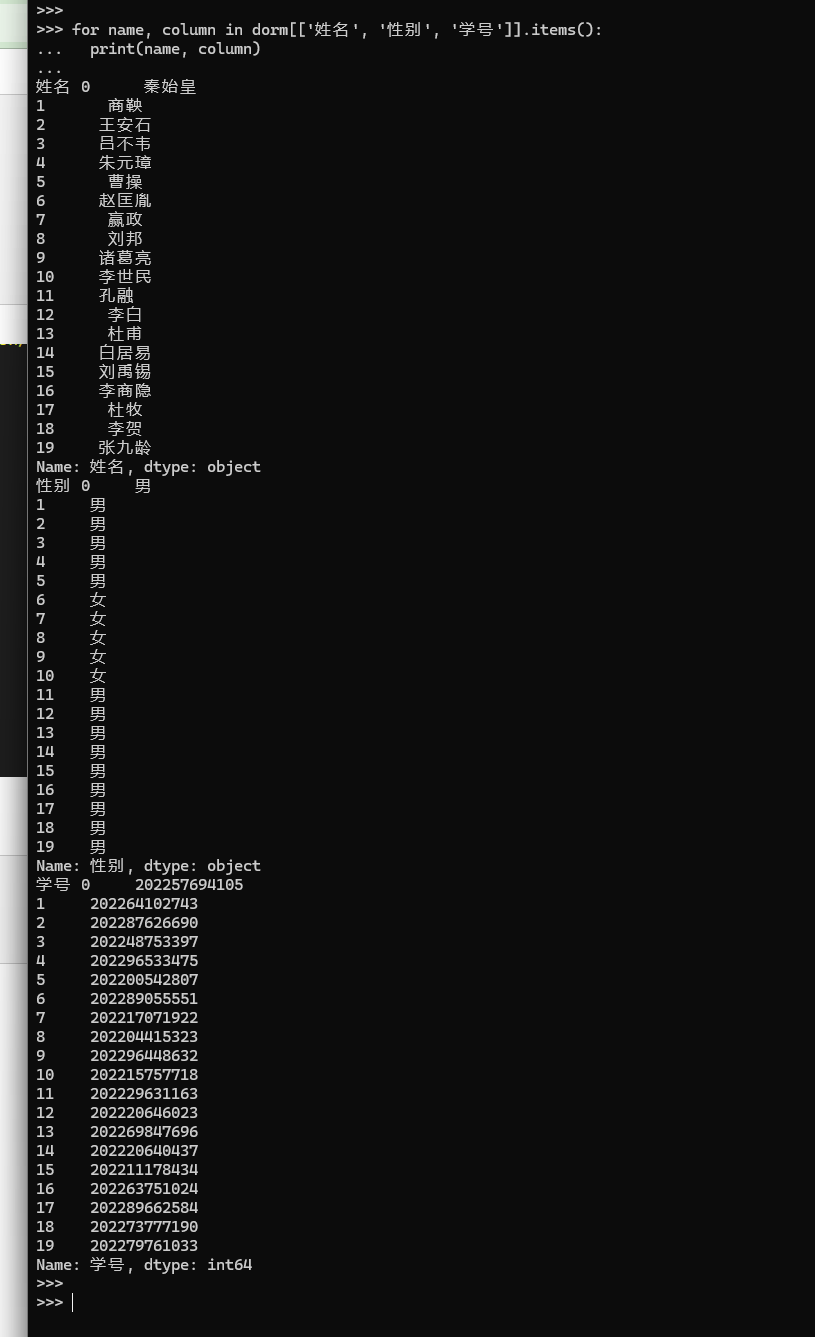
for name, column in dorm[['姓名', '性别', '学号']].items():
"""Iterate over (column name, Series) pairs."""
print(name, column)
有了计划记得推动,不要原地踏步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号