DataLoader?直接切片更香!(pytorth GPU加速探讨)
DataLoader?直接切片更香!(pytorth GPU加速探讨)
写文章时作者刚看了两天pytorch,对其底层原理不甚了解。
这不是一篇技术文章,请谨慎参考
仅从实际效果来讲一下遇到的情况
使用pytorch的小伙伴一定不会陌生这样的代码:
train_loader = DataLoader(
dataset=dataset,
batch_size=128,
shuffle=True,
)
for epoch in range(50):
for x, y in train_loader:
x = x.cuda()
y = y.cuda()
...
且不谈在windows下经常出现DataLoader中num_workers参数不为0会报各种错的缺点。
我在心里其实一直都有疑惑,dataloader的效率如何?
尤其是
x = x.cuda()
y = y.cuda()
这两行代码,因为我们的batch有时并不是很大,在循环中需要很多次cuda()的操作
那么这个将数据搬运到GPU上的函数效率如何?
每个epoch为什么重复都要搬到GPU上?
能不能直接一次将数据都搬到GPU上再进行运算?
因为通过DataLoader进行计算时,我们可以清楚地通过任务管理器看到GPU的状况
以MNIST数据集为例,迭代时GPU占用率如下:
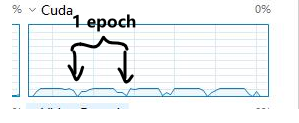
很明显的可以看到CUDA核心并没有占满,而且具有周期性,中间的占用并不连续。
后来在将Dataloader的num_workers=2,使用两个线程进行搬运数据
GPU的占用率如下:
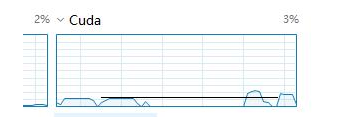
可以看到,双线程明显比单线程的占用率要更大一些,但是仍然很低,周期性无法消除。
后来经过不断增加num_workers数量,发现其最大占用率也不超过40%
那么问题来了,为什么不用最简单的切片?
首先编写一个生成索引的类(模仿DataLoader的格式)
class BatchIndex:
def __init__(self, size, batch_size, shuffle=False, drop_last=True):
if drop_last:
self.index_list = [(x, x + batch_size,) for x in range(size) if
not x % batch_size and x + batch_size <= size]
else:
li = [(x, x + batch_size,) for x in range(size) if not x % batch_size]
x, y = li[-1]
li[-1] = (x, size)
self.index_list = li
self.shuffle = shuffle
self.drop_last = drop_last
if shuffle:
import random as r
r.shuffle(self.index_list)
def __next__(self):
self.pos += 1
if self.pos >= len(self.index_list):
raise StopIteration
return self.index_list[self.pos]
def __iter__(self):
self.pos = -1
return self
def __len__(self):
return len(self.index_list)
该类的 size, batch_size, shuffle=False, drop_last=True等参数相想必不用多说。
该类是一个迭代器,能够产生切片所需的下标。
于是我们的代码就变成了:
# 一次性将所有内容放到GPU上
model.cuda()
x_data = x_data.cuda()
y_data = y_data.cuda()
x_test = x_test.cuda()
y_test = y_test.cuda()
for epoch in range(5):
for a,b in BatchIndex(60000,64,True): # batch_size = 64, shuffle = True
x = x_data[a:b]
y = y_data[a:b]
...
运行程序可以发现GPU占用率如下:
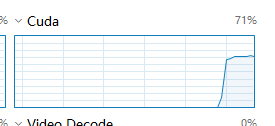
占用率达到了70%,且不再出现周期波动(废话)。
时间缩短了近两三倍左右。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号