大模型时代的推荐系统Recommender Systems in the Era of Large Language Models (LLMs)
文章地址:https://arxiv.org/abs/2307.02046
笔记中的一些小实验中的模型都是基于GPT-3.5架构的ChatGPT模型。
本文主要讲述了比较具有代表性的方法利用LLM去学习user和item的表示,从预训练、微调和提示三个范式回顾了近期用于增强推荐系统的LLM先进技术,最后讨论了这一新型领域有前景的方向。
INTRODUCTION
这里关于推荐系统的一些基本背景就不再赘述。作者在这里指出了目前推荐系统存在的三个问题:
- 由于数据和模型规模的限制,目前基于DNN(例如CNN)和一些预训练语言模型(例如BERT)无法充分捕获到user和item的文本信息,这表示它们的自然语言理解能力较差,这会导致推荐效果不理想。
- 大多数现有推荐算法都是为自己特定的任务设计的,它们对未见过的推荐任务的泛化能力不足(例如一个专门为评分设计的推荐算法在可解释性任务上表现较差)。
- 目前大多数基于DNN的推荐方法在简单决策上有好的表现(例如评分、top k推荐),但是它们在支持有着包含多步推理的复杂决策面临困难(例如进行旅行推荐时要考虑目的地的旅游景点、然后安排与旅游景点相应的合适行程、并根据用户偏好推荐旅行计划)。
那么LLM能解决上述问题吗?以下是我用chatgpt进行行程的推荐。



看起来效果不错,chatgpt的回答基本上满足了我的需求,目前主流的推荐模型是做不到的,而且这个还是没有经过特定旅游数据调整的大模型。
DEEP REPRESENTATION LEARNING FOR LLM-BASED RECOMMENDER SYSTEMS
这一部分主要讲的就是利用LLM学习推荐系统中user和item的表示,包括基于ID的推荐系统和基于文本信息的推荐系统。
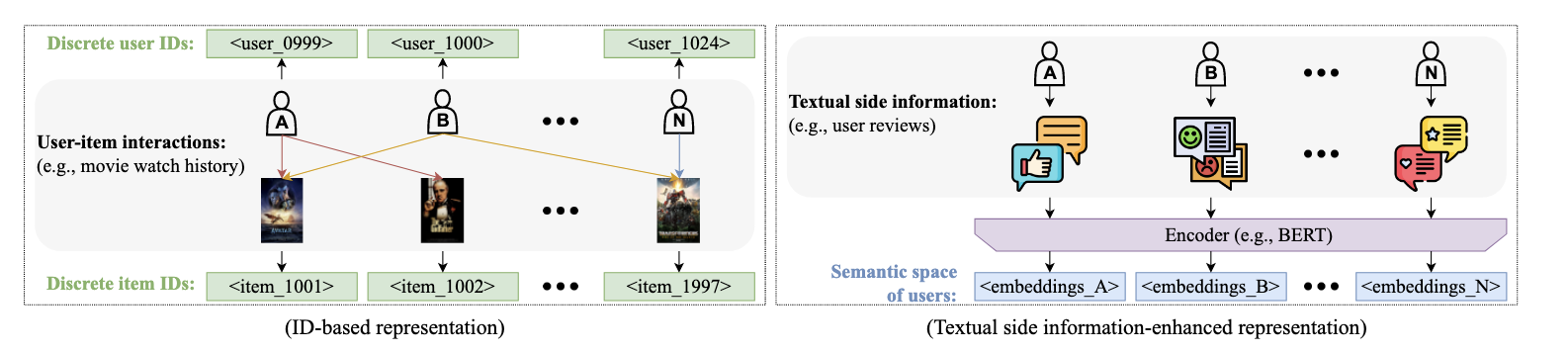
ID-based Recommender Systems
在现代推荐系统中,通常使用离散的ID表示user和item,并通过学习ID embedding来模拟user和item之间的行为。在基于LLM的推荐系统中,通常使用“[prefix]_[ID]”的形式表示user和item。prefix表示类型(item or user),数字ID有助于识别其唯一性。
P5是早期的一种基于LLM方法的统一范式,它通过将user和item映射为索引,将各种推荐数据格式(例如user与item的交互、用户画像、item描述等)转化为自然语言序列。后续很多方法都是基于P5的思想,改进映射方式,将推荐数据转化为语言序列。
Textual Side Information-enhanced Recommender Systems
基于ID的方法存在局限性,因为user和item的ID是离散的,不能够提供足够的语义信息捕获user和item的表是进行推荐。因此,user和item的相关性计算非常有挑战性,尤其是交互非常稀疏时。为了解决上述问题,一种具有前景的替代方案是利用user和item的文本信息。因此,一些研究人员利用语言模型(例如BERT、GPT等)对user和item文本信息进行编码,对相似的user或item分组。text-based collaborative filtering (TCF) 通过提示GPT-3等LLM,探索了基于文本的协同过滤,证明了文本侧信息增强推荐系统的潜力。只靠语言模型进行编码可能会过度强调文本特征,后续有研究人员提出了通过引入知识图谱、用户行为等方式缓解该问题。
PRE-TRAINING & FINE-TUNING LLMS FOR RECOMMENDER SYSTEMS
本章主要讲述了应用于推荐系统 LLM 的特定预训练任务,以及在下游推荐任务中提高性能的微调策略。
Pre-training Paradigm for Recommender Systems
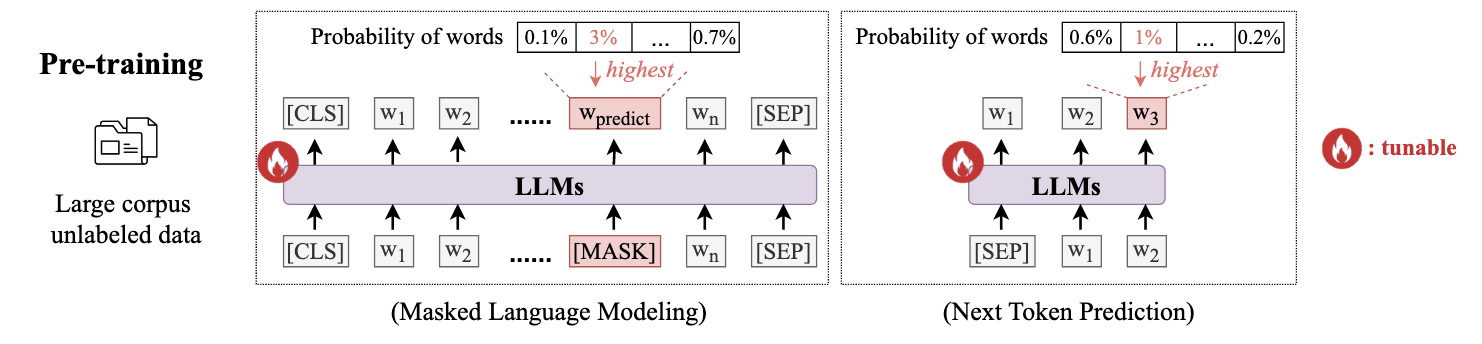
NLP领域的LLM的预训练通常有两种:1.仅编码器或编码器-解码器的Transformer结构,它随机屏蔽token或span,并要求LLM预测被掩盖的token或span。2.仅解码器的Transformer结构,通过给定的上下文预测下一个token。
在推荐系统的预训练中,PTUM提出了两种相似的预训练方法:1.mask行为序列中的一个用户行为,并基于序列中的其它行为对mask的行为进行预测。2.通过已有的历史行为预测next k个行为。
Fine-tuning Paradigm for Recommender Systems

LLM的微调主要分为两种,全模型微调和参数高效微调。
-
Full-model Fine-tuning
需要调整整个模型的参数,例如RecLLM微调LaMDA用于YouTube视频的会话推荐、GIRL利用有监督微调策略指导找工作。 -
Parameter-efficient Fine-tuning
LLM参数量巨大,进行全量参数微调需要耗费大量计算资源。PEFT微调一小部分模型权重或一些额外的可训练权重,同时固定 LLM 中的大部分参数以实现与全模型微调相当的性能。例如引入额外可训练额外的参数作为适配器、LoRA。
PROMPTING LLMS FOR RECOMMENDER SYSTEMS
除了上述的预训练和微调,提示是帮助LLM适应下游任务的最新范式,它是可应用于llm输入的文本模板,例如“和_之间的关系是”。目前主要有以下三种提示技术:提示、提示调优、指令调优。
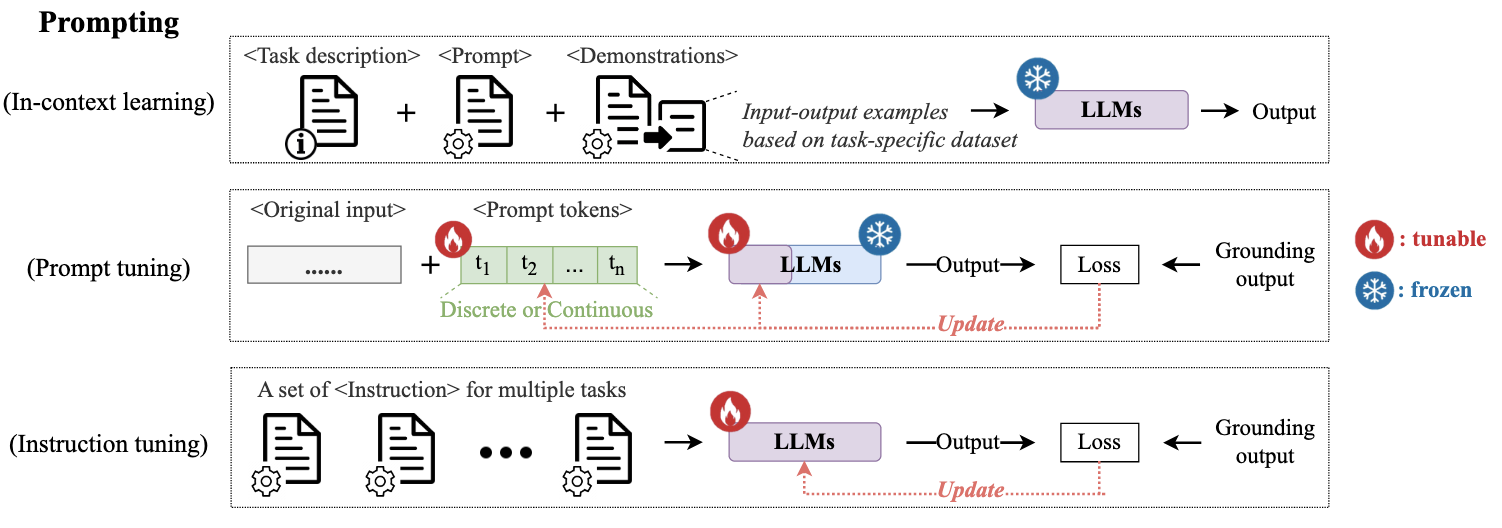
Prompting
核心思想是保持LLM冻结(参数不更新),通过特定的提示使LLM适应下游任务。
-
Conventional Prompting
一种方法是提示工程,模拟在预训练期间遇到的语言模型的文本来生成提示,例如将推荐中的评论摘要任务转化为文本摘要,输入“写一个简短的句子总结___”。另一种方法是few-shot提示,提供少量输入输出示例。由于语言生成任务和下游推荐任务存在巨大差距,传统的提示方法作用有限。 -
In-Context Learning (ICL)
ICL的关键之处在于激发LLM上下文学习能力,从推理阶段的上下文中学习未见过或新的下游任务。通常有两种设置,一种是zero-shot,另一种是few-shot。
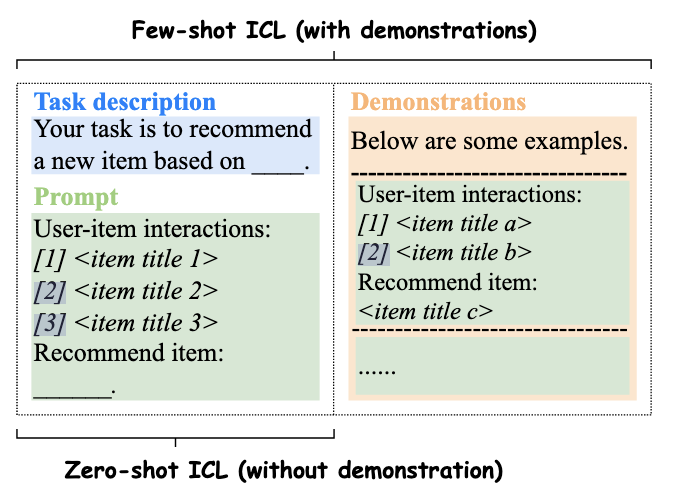
zero-shot情况下的推荐。

第一眼看上去似乎推荐结果很正常,但是实际上有不少问题,这五部作品中,第一部作品书名应该是《沉默的巡游》,第二部作品应该不存在(我没找到对应的作品),第三部似乎没什么问题,第四部作品作者是弗雷德里克·巴克曼,第五部作者是马塞尔·普鲁斯特。后面会再次提到这个问题,LLM会创作出一些不存在的事物。 -
Chain-of-Thought (CoT) Prompting
LLM在推理任务繁重的任务中性能有限,在一些多步问题中LLM往往缺少一个或几个中间步骤,导致推理逻辑破裂,推理结果错误。CoT通过向推理步骤中加入注释,这使 LLM 能够分解复杂的决策过程,并通过逐步推理生成最终结果。考虑zero-shot和few-shot场景:1.zero-shot CoT。在zero-shot场景下,通过插入类似“逐步思考”和“因此,答案是”这样的文字去提示LLM。2.few-shot CoT。特定任务的推理步骤是为 ICL 中的每个演示手动设计的,其中原始输入-输出示例被增强为输入-CoT-输出方式。此外,CoT 还能增强 ICL 演示中的任务描述,根据特定任务知识添加可解释的推理步骤描述。
适当的CoT推理步骤的设计高度依赖于特定推荐任务的上下文和目标,论文中的一个栗子。
[CoT Prompting] 基于用户购买历史,让我们逐步思考。首先,请推断用户的高层购物意图。其次,哪些项目通常与购买的项目一起购买。最后,请根据购物意图选择最相关的项目,并将它们推荐给用户。
Prompt Tuning
提示调优作为一种附加技术,它为LLM添加新的提示标记,并根据特定任务的数据集优化提示。一般来说,与针对特定任务手动设计提示符相比,提示调优所需的特定任务知识和人力较少,而且只涉及可调整提示和LLM输入层的最小参数更新。LLM的提示调优策略可分为两种。
-
Hard Prompt Tuning
Hard Prompt Tuning指生成和更新离散的提示文本模板(如自然语言),用于提示LLM完成特定的下游任务。尽管为下游推荐任务生成或改进自然语言提示既有效又方便,但Hard Prompt Tuning调整不可避免地面临着离散优化的挑战,需要在广阔的词汇空间中费力地试错,以找到适合特定推荐任务的提示。 -
Soft Prompt Tuning
Soft Prompt Tuning采用连续向量作为提示(例如文本向量),并根据任务特定的数据集优化提示,例如使用梯度方法根据推荐损失更新提示。与Hard Prompt Tuning相比,Soft Prompt Tuning更适合在连续空间上进行调整,但需要付出可解释性的代价。
Instruction Tuning
指令调优具有提示、预训练、微调范式的特征,指令调优的关键在于训练LLM将提示作为任务指令,而不是解决具体的下游任务。具体可以分为两个阶段:
-
Instruction (Prompt) Generation Stage:指令调优引入了自然语言中基于指令的提示格式,它由面向任务的输入(即基于任务特定数据集的任务描述)和所需的目标(即基于任务特定数据集的相应输出)对组成。
-
Model Tuning Stage :对LLM进行微调。
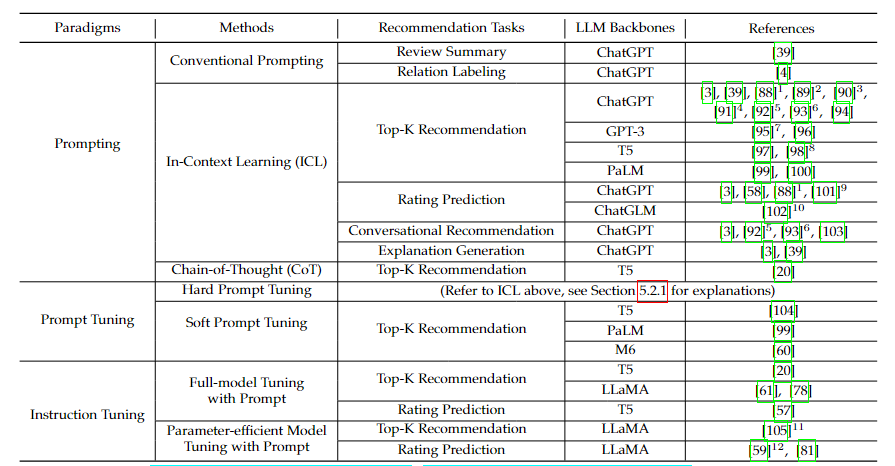
FUTURE DIRECTIONS
LLM在推荐系统中的应用仍处于早期探索阶段,存在许多机遇与挑战,本章主要讲了一些潜在的发展方向。
-
Hallucination Mitigation:
减少幻觉。LLM会生成一些合理但实际不存在的事物,例如上面我在用chatgpt进行书籍推荐时,它生成的一些推荐会出现书籍不存在或者书籍与作者不匹配的情况,但是如果你不了解这些书和作者,很难发现有什么问题。为了缓解这个问题,可以尝试使用事实知识图谱作为补充信息。 -
Trustworthy Large Language Models for Recommender Systems
基于LLM的推荐系统的可信问题,主要包括四个方面:
1.安全与鲁棒。微小的扰动可能影响推荐系统的性能,存在恶意人员操纵特定产品的市场。
2.非歧视和公平。经过大量数据集训练的 LLM 常常会无意中学习并延续人类数据中的偏见和刻板印象,这些偏见和刻板印象随后会在推荐结果中显露出来。
3.可解释性。由于隐私和安全考虑,某些公司和组织选择不开源其先进的LLM。因此,推荐系统的LLM可以被视为“黑匣子”,用户试图理解为什么产生特定输出或推荐的过程变得复杂。
4.隐私性。一方面,用于推荐系统的LLM的高度依赖于从社交媒体和书籍等各种来源收集的大量数据。数据中包含的用户敏感信息(如电子邮件和性别)很可能被用于训练现代 LLM,以提高预测性能和提供个性化体验,从而导致用户隐私信息泄露的风险。另一方面,这些系统通常会处理敏感的用户数据,包括个人偏好、在线行为和其他可识别信息。 -
Vertical Domain-Specific LLMs for Recommender Systems
为推荐系统量身定制的LLM可以节省专业人员大量时间,并且获取更好的推荐效果。 -
Users&Items Indexing
LLM理解长文本能力不佳,因为很难有效地捕获长文本中的user-item交互信息。而这些交互信息中包含了大量协同知识,对理解和预测用户偏好做出了巨大贡献。 -
Fine-tuning Efficiency
微调可以使得预训练好的LLM应用于特定领域。然而,微调的计算成本可能很高,特别是对于推荐系统中非常大的模型和大型数据集。因此,提高微调的效率是一个关键挑战。 -
Data Augmentation
推荐系统是数据驱动的,其基础是通过用户在数字平台上的互动或通过招募注释者来收集用户行为数据。然而,这些方法似乎都是资源密集型的,可能无法长期持续,输入数据的质量和多样性直接影响模型的性能和多功能性。为了克服以真实数据为中心的研究的不足,可以尝试使用LLM进行数据增强(例如对用户进行多样化提示)提升推荐效果。
SUMMARY
总的来说,将LLM应用在推荐系统中是一个很有前景的方向,但是目前还有许多问题,比较重要的就是上面的幻觉现象还有一个其他论文中提到的推理延迟。大模型创造力很强,但是它也会经常创造一些不存在的事物,如果将不存在的事物推荐给用户,那用户满意度肯定是直线下降的,包括我之前尝试用它找某个方面的论文,它给出的论文标题和作者都有模有样的,但是这些论文实际不存在。相对于目前的推荐系统,大模型推理耗费的时间更久,这就可能造成用户等了一段时间,但是推理还没结束,导致用户满意度下降。大模型相对于传统模型优点也很多,推荐结果的解释性更强,它通常在给出推荐结果的同时,会附带对推荐的item描述以及为什么推荐。它可以理解我们所说的内容,进行多次推荐,每次根据我们输入的内容,修改推荐的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号