DropoutNet: Addressing Cold Start in Recommender Systems阅读笔记
动机
本文是2017年nips上的一篇论文。在当时对于冷启动问题,大部分工作是针对cold item的,或是将偏好和内容都结合在目标函数中使其非常复杂。本文作者提出了DropoutNet,这个方法利用深度学习中dropout的思想,且只有一个目标函数,简单有效。
方法
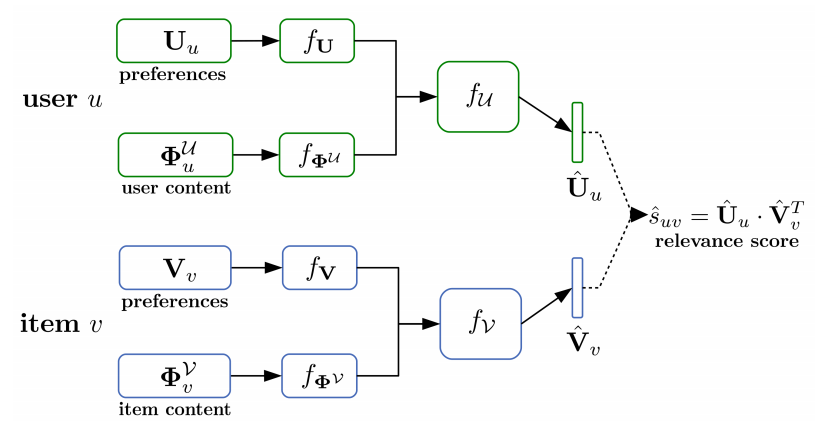
模型的框架见下图。输入分为四个部分,分别是用户偏好、用户内容(例如年龄、职业等信息)、物品偏好、物品内容。
目标函数为
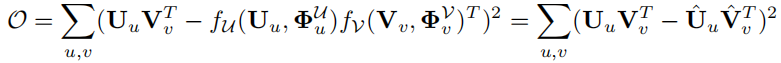
在冷启动场景下,对于新的user和item,我们并没有它们的偏好信息,那么训练目标就变为如下

在训练好模型后,可以用模型进行推理。老用户或物品的偏好是通过WMF等模型预训练获得的,如果有新用户或物品加入,重新再训练一遍模型过于费时,这里用一个近似的方法得到新用户的表示
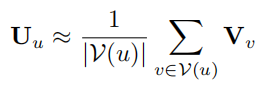
取这个用户交互物品的偏好表示的均值。新物品的偏好表示可以用类似的方法获得。
训练过程如下

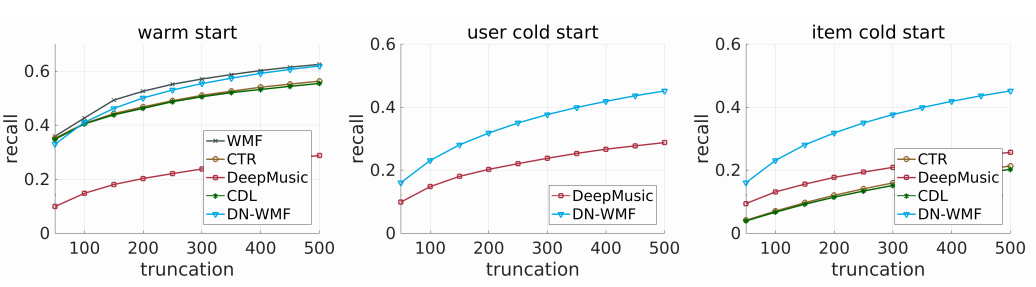
实验结果
本文提出的方法在warm情况下与当时sota模型效果相当,在cold情况下取得最佳效果。
RecSys 2017 Challenge数据集

CiteULike数据集
总结
本文虽然距现在已经有很长一段时间,但是有很多借鉴的地方,我觉得本文经典的地方在于目标函数和训练方式,模型的结构倒是很常见。首先本文的目标函数是评分之间的差异,一个评分是只由物品和用户的偏好计算得出,另一个是用物品的偏好和内容及用户的偏好和内容得出。之前看到的论文的大多数做法是通过训练一个输入为属性输出为表示的模型去学习冷启动物品和用户的表示,目标函数是用户(物品)的表示和模型通过用户(物品)属性学习得出的表示的差异。本文的目标函数在偏好缺失的情况下鼓励模型只使用内容信息,而偏好与内容信息都存在的情况下鼓励模型忽略内容信息。但是因为在训练过程中,采样的数据是随机进行缺失或平均处理的,因此模型平衡了这两种极端情况,这也就是该模型既能在warm状态下效果基本不下降,在cold情况下效果更好的原因。整体来说本文简单易懂,方法很巧妙,与当前大部分解决冷启动问题的方法都不同。
这里还有一个疑问,如果将目标函数中的红框部分换成真实评分,效果会不会更好。因为考虑到预训练模型效果不一定非常好,之后跑一下代码解决这个疑问。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号