Personalized Adaptive Meta Learning for Cold-start User Preference Prediction阅读笔记
动机
本文是2021年AAAI上的一篇论文。MAML是解决推荐系统冷启动问题的常用方法,由于在现实生活中用户的分布不是均匀的(不同的用户有不同的配置文件,我们定义主要用户为具有与其他大量用户相似信息的用户,其余用户为次要用户),MAML方法倾向于适应主要用户而忽略次要用户。为了解决上述这一过拟合问题,本文提出了PAML模型。
方法
本文最主要的特点就是提出了具有自适应学习率的元学习来解决推荐系统中的冷启动问题。
Adaptive Learning Rate
为了同时考虑主要用户和次要用户,我们提出了一种自适应学习率方法,为不同的用户设计不同的梯度步骤
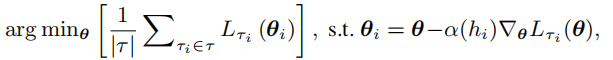
我们需要获取用户分布、网络参数和用户学习率之间的关系,因此我们需要一个方法,根据用户的特征来自适应的获取学习率。在此基础上,我们提出了PAML,它可以直接通过梯度下降训练模型
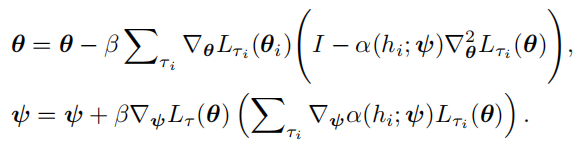
其中\(\theta和\psi\)分别是模型和学习率网络的参数。
下面是PAML的两种实例。
Approximated Tree-based PAML
如果直接使用全连接网络很难为每个用户都生成合适的学习率,因为网络不能记住这么大量用户的信息。为了解决这一问题,我们考虑到相似的用户具有相似的学习率,基于该想法,我们引入了基于相似度的方法寻找有相似兴趣的用户。
用户的学习率由以下公式计算得出
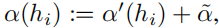
其中
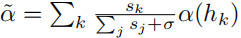
k是与当前用户最相似的k个用户,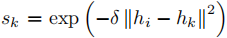 。
。
\(\alpha^{'}(h_i)\)是一个神经网络将用户的embedding投影为一个实值。
为了快速找到K个相近的邻居,我们利用kdtree作为存储用户嵌入的基本结构。我们首先使用几个用户的embedding和他们的学习率来初始化树,之后根据查询用户的embedding在树中找到近似的邻居,之后将该用户添加到树中,并删除最不频繁使用的用户,这样可将每个用户的搜索时间复杂度由O(n)降为O(logn)。
Regularizer-based PAML
对于现实世界涉及到数百万用户的应用程序时,即便是线性复杂度的方法存储用户embedding也是无法接受的。因此我们设计了一个辅助函数帮助模型记住它所看到过的用户
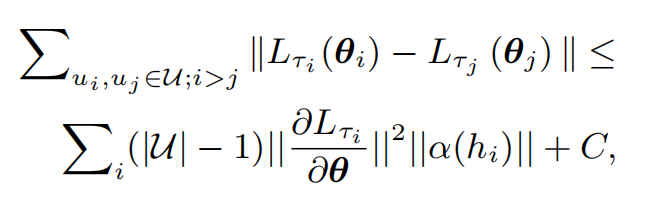
上述公式中小于等于号左边的是原始损失,该式子计算量很大,因此我们简化它,只计算它的上界,就是小于等于号右边的公式。
令
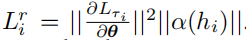
最终的损失为
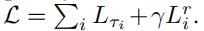
PAML两种实例的流程为

实验结果
本文提出的方法在大部分情况下是最优的。

总结
本文主要的贡献是提出了一种自适应学习率的MAML方法来解决推荐系统中冷启动问题,同时还引入了KD树快速找到相似用户,使用一种正则化减少内存使用,并保持模型的记忆能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号