Deep Interest Network for Click-Through Rate Prediction阅读笔记
动机
本文是2018年阿里的一篇文章,提出了比较经典的深度学习推荐系统DIN。当时CTR预估模型大都遵循着Embedding&MLP范式,这种情况下用户表示通常被压缩为一个固定长度的向量,而不管广告是什么,这使得模型很难从用户丰富的历史交互信息中捕获用户不同的兴趣。作者针对上述问题提出了Deep Interest Network(DIN),它通过设计一个局部激活单元来自适应地针对一个特定广告,从用户的历史行为中学习用户兴趣的表示来解决这一问题。
方法
base model
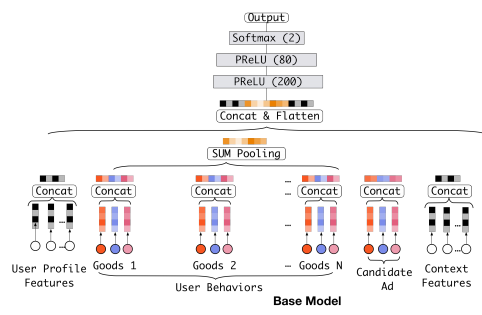
广告CTR预估任务中一般有四类信息,分别是用户配置信息、用户行为信息、广告信息和上下文信息,每部分信息都包含若干种类的特征,我们需要将这些特征从一个稀疏的表示映射为一个稠密的表示,可以通过embedding层实现。对于one-hot编码的特征,可以直接从embedding层获取其表示\(e^i=w^i_j\)。对于multi-hot编码的特征,可以先获取所有的表示,然后再通过一个池化层(通常采用平均或是和)。然后将所有特征的表示连接起来,输入进MLP。损失函数为二分类交叉熵损失函数。

整体结构如下图。
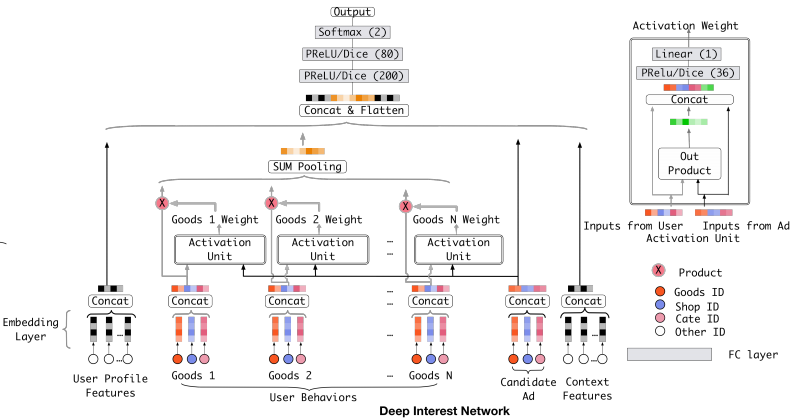
DIN
DIN与base model最大的区别就是在于如何处理用户历史交互行为,base model通常是用平均或者和操作来将这一部分转化为一个固定的向量表示,但是这无法很好地体现出用户的兴趣。DIN通过考虑用户历史行为与广告的相关性,自适应地计算用户的兴趣,用户的兴趣在不同的广告中是不同的。比如说一个用户有过运动鞋、篮球、足球、电脑的交互历史,当前广告是显示器的广告,那么当前广告与用户交互历史中的电脑更相关,用户在此广告中的兴趣会更偏向电脑,而不是运动相关的鞋子、球类。用户兴趣的表示从简单的平均或是求和变为了一个加权计算。
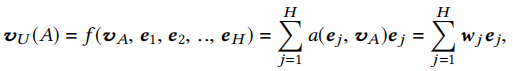
a(·)是一个前馈神经网络,具体结构可看下图右上角,将与用户有交互的物品表示和广告表示做一个哈达玛积,然后再连接起来。之后输入进MLP,最后输出的是一个标量,表示权重。
训练技巧
小批量正则化感知
细粒度的特征会使表示维度增大,在阿里的广告数据集中,商品id的维度可达6亿。而为了避免过拟合,我们需要正则化。但是如果每个batch对所有参数都进行正则化,那么计算量是难以接受的,本文作者提出了一种正则化方法,核心思想是在本轮更新中,只有利用到的参数才进行正则化操作。
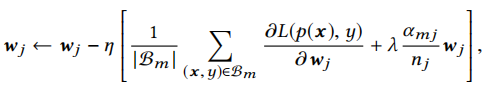
数据自适应的激活函数

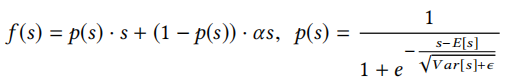
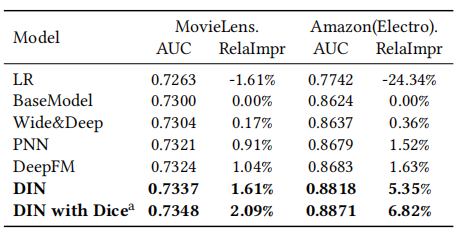
实验结果
本文提出的DIN均超越基准模型效果。
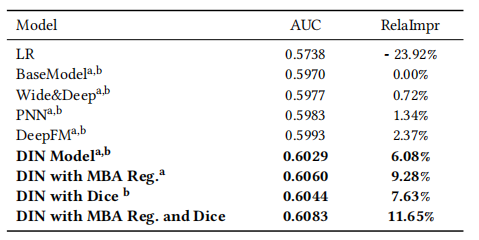
总结
本文提出的DIN核心的地方就是在计算用户兴趣时,考虑到当前广告的内容,通过注意力方法计算出与当前广告内容相似的交互历史物品,并赋予它们较大的权重。这样的做法使得用户在面对不同广告时有不同的兴趣表现,使得模型有更强的表达能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号