20172324 2018-2019-1《程序设计与数据结构》实验2报告
20172324 2018-2019-1《程序设计与数据结构》实验2报告
课程:《程序设计与数据结构》
班级: 1723
姓名: 曾程
学号:20172324
实验教师:王志强
实验日期:2018年9月30日
必修/选修: 必修
一、实验内容
链表练习
-
实验一:参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder
- 用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
-
实验二:基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能
-
比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树
-
用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
-
-
实验三:**自己设计并实现一颗决策树
** -
实验四:输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果
- 如果没有用树,则为0分
- 提交测试代码运行截图,要全屏,包含自己的学号信息
-
实验五:完成PP11.3
-
实验六::参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果
二、实验过程及结果
-
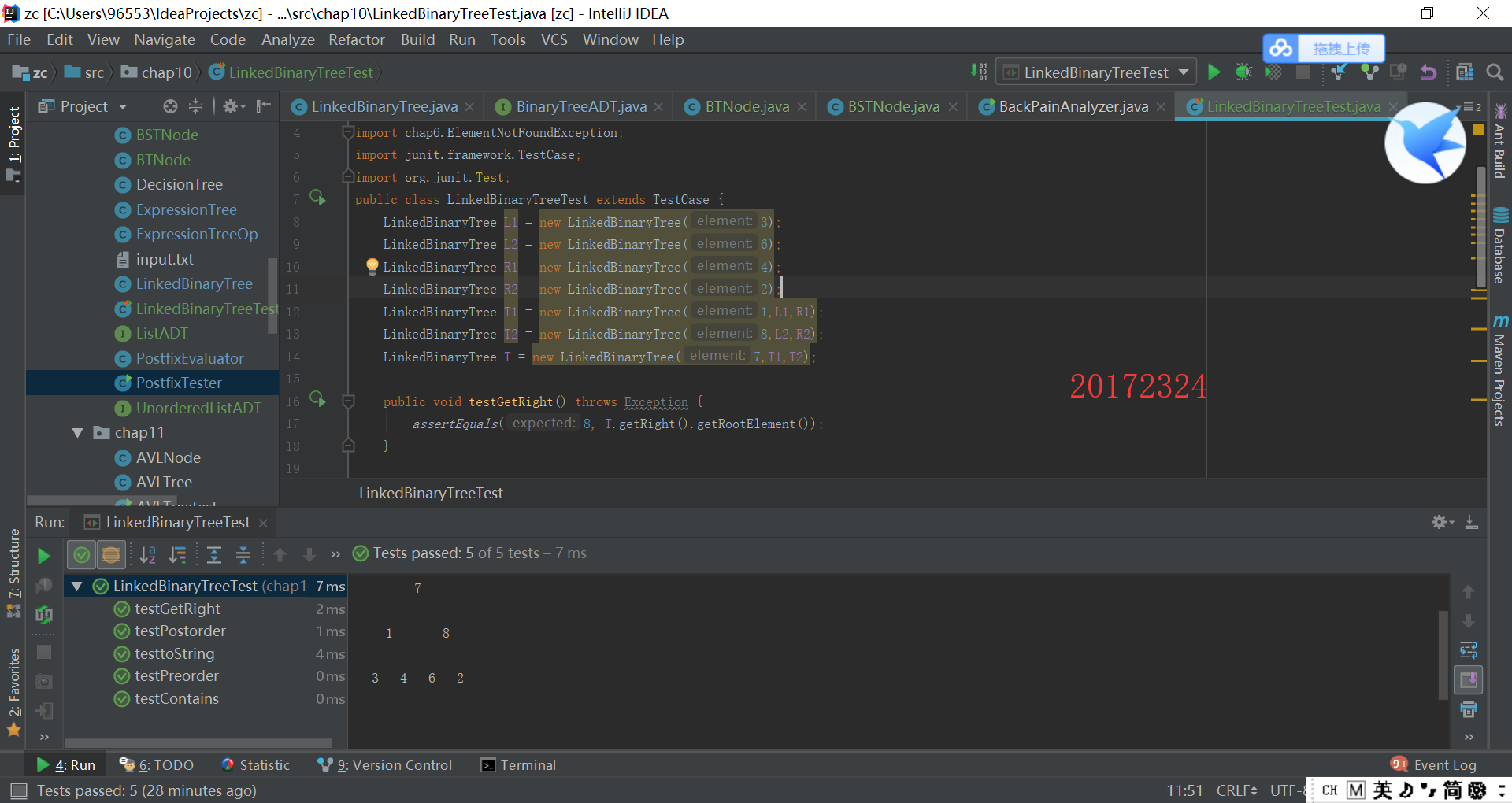
实验1结果截图:
- LinkedBinaryTree中有给出getLeft的方法,所以根据所给的getLeft补写出getRight方法
- 书上说:contains方法留作程序设计项目,它可以使用find方法判定目标元素是否存在于树中
- LinkedBinaryTree要补写preorder,postorder,LinkedBinaryTree中给出了inorder的方法,根据inorder写出preorder和postorder
-
实验2结果截图:
- 前序是:根左右的顺序,中序是左根右的顺序。首先找root,前序的第一个是root;观察前序,除根之外的必在左右子树;观察中序,root左侧的为左子树,右侧的为右子树;在左子树和右子 树中根据前序再判断谁是根;同样道理,以此类推

- 前序是:根左右的顺序,中序是左根右的顺序。首先找root,前序的第一个是root;观察前序,除根之外的必在左右子树;观察中序,root左侧的为左子树,右侧的为右子树;在左子树和右子 树中根据前序再判断谁是根;同样道理,以此类推
-
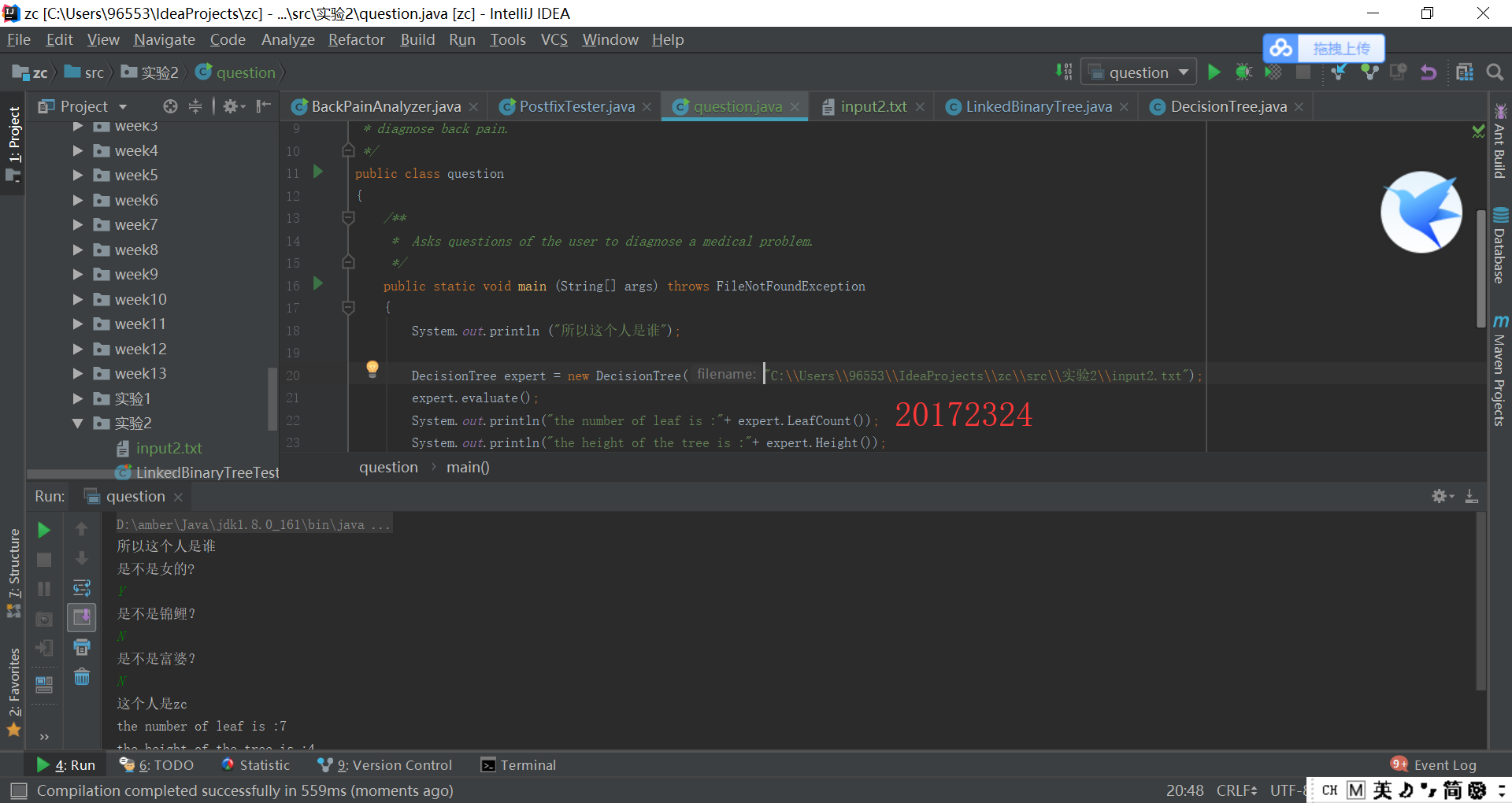
实验3结果截图:
-
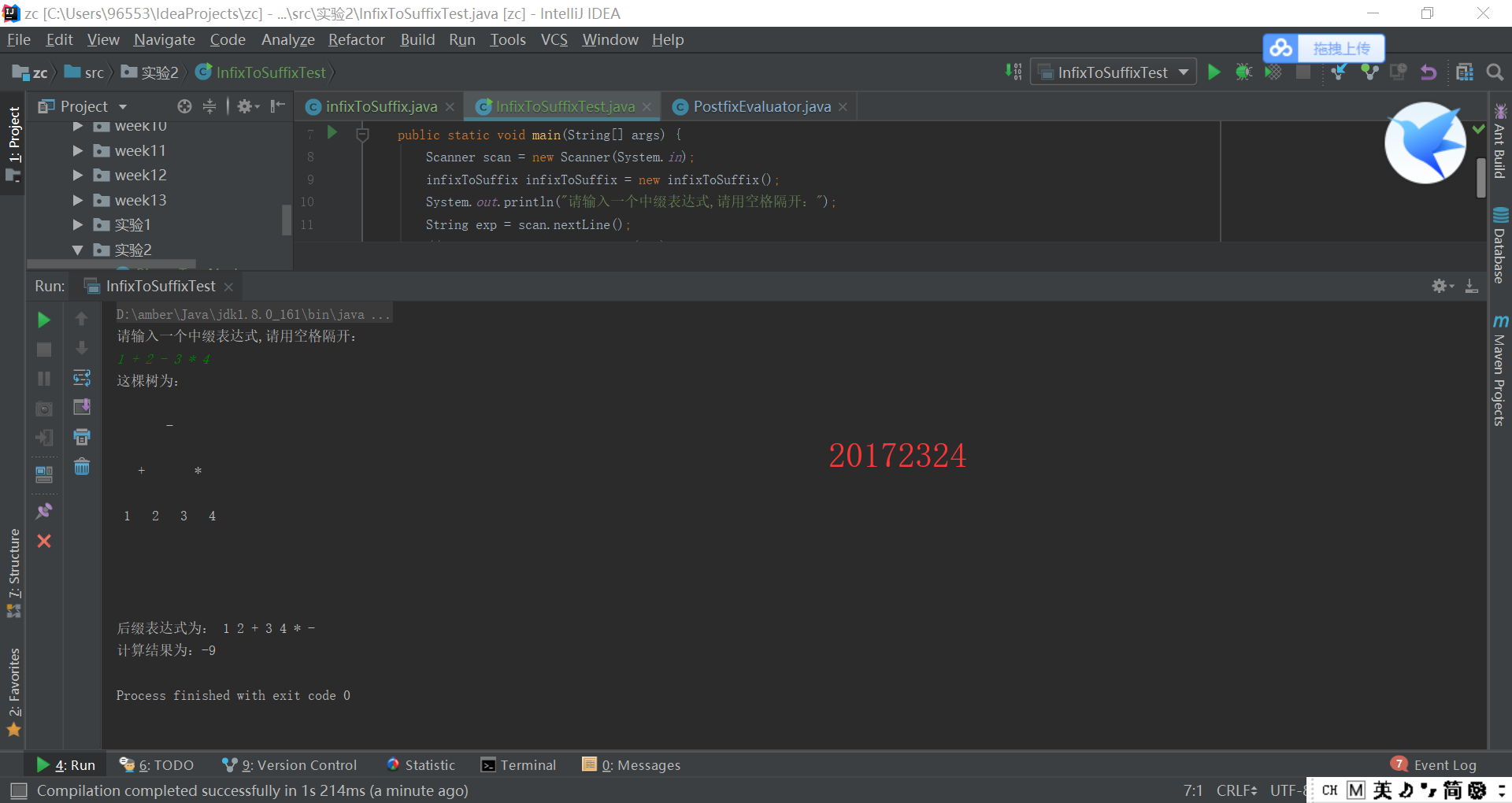
实验4结果截图:
-
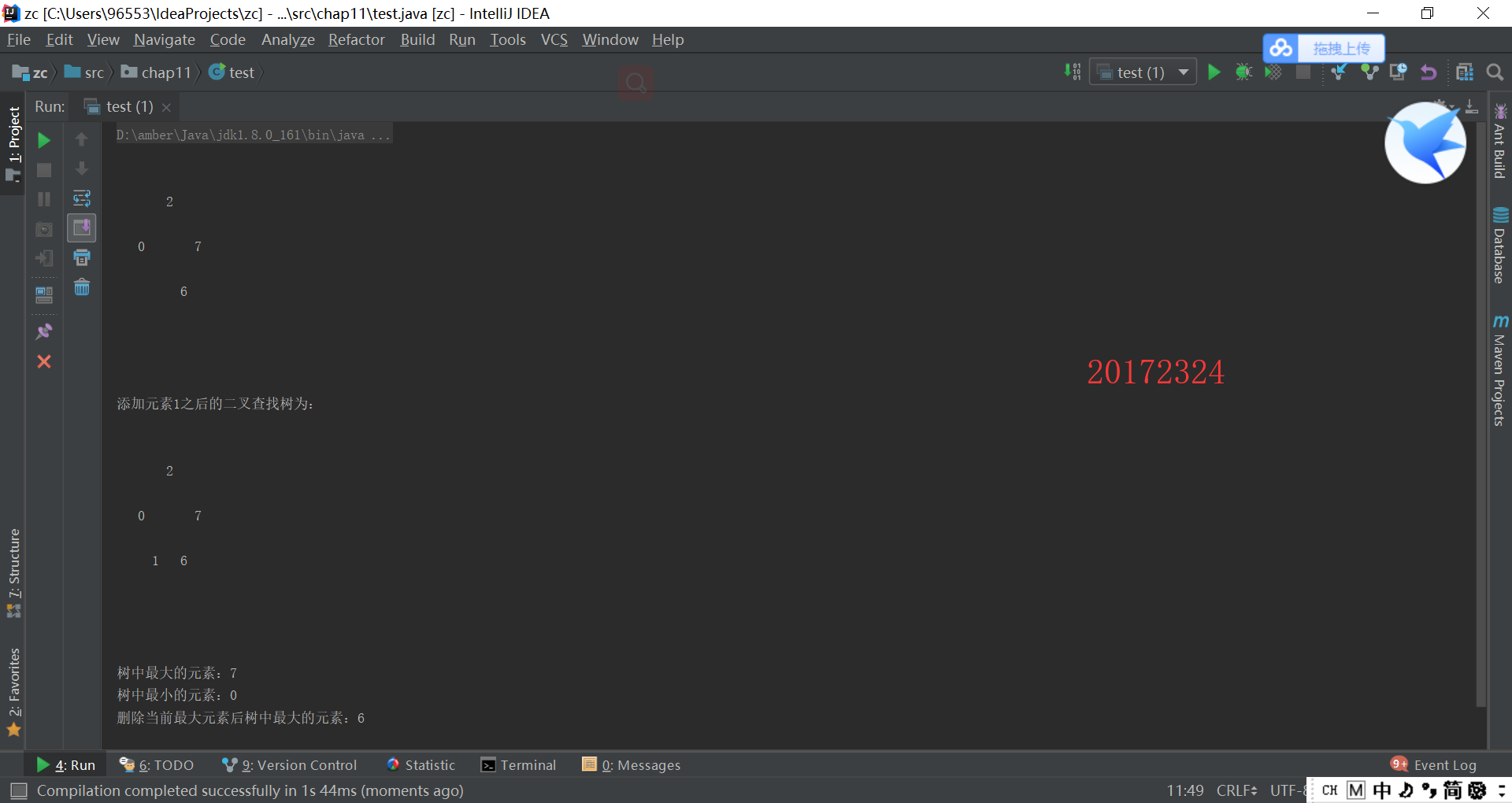
实验5结果截图:
二叉搜索树是一种特殊的二叉树,即:节点的左子节点的值都小于这个节点的值,节点的右子节点的值都大于等于这个节点的值
比根节点要小的数会放在当前根节点的左子结点,因此要实现findMin()只要获取该树的最左边的结点即是最小值
比根节点要大的数会放在当前根节点的右子结点,因此要实现findMax()只要获取该树的最右边的结点即是最大值
- 实验6分析:
最后一个实验是对Java中的红黑树(TreeMap,HashMap)进行源码分析,首先要了解红黑树是什么,第七周博客中有提到过。
TreeMap类
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
- TreeMap(K,V) K - 此映射维护的键的类型 V - 映射值的类型
- TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
- TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
- TreeMap 实现了Cloneable接口,意味着它能被克隆。
- TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
- TreeMap() 使用键的自然顺序构造一个新的、空的树映射。
- TreeMap(Comparator<? super K> comparator) 构造一个新的、空的树映射,该映射根据给定比较器进行排序。
- TreeMap(Map<? extends K,? extends V> m) 构造一个与给定映射具有相同映射关系的新的树映射,该映射根据其键的自然顺序 进行排序。
- TreeMap(SortedMap<K,? extends V> m) 构造一个与指定有序映射具有相同映射关系和相同排序顺序的新的树映射。
firstEntry()和getFirstEntry()方法:
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
firstEntry() 和 getFirstEntry() 都是用于获取第一个节点。firstEntry() 是对外接口;getFirstEntry() 是内部接口。而且,firstEntry() 是通过 getFirstEntry() 来实现的。
那么为什么不直接调用getFirstEntry() ,而调用 firstEntry() 呢?这么做的目的是:防止用户修改返回的Entry。getFirstEntry()返回的Entry是可以被修改的,但是经过firstEntry()返回的Entry不能被修改,只可以读取Entry的key值和value值。
HashMap类
初始容量与加载因子是影响HashMap的两个重要因素:
public HashMap(int initialCapacity, float loadFactor)
初始容量默认值:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
加载因子默认值:
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
- HashMap<K,V> K - 此映射所维护的键的类型 V- 所映射值的类型
- HashMap() 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity, float loadFactor) 构造一个带指定初始容量和加载因子的空 HashMap。
- HashMap(Map<? extends K,? extends V> m) 构造一个映射关系与指定 Map 相同的新 HashMap。
如果在map中包含对应的特定的键值则返回true,否则返回false。
方法有些类似于contains方法,在功能上contains检测是否有对应关联的键,containsValue检测是否有对应的值,内部使用V(泛型)定义一个值,而Node<K,V>实现了Map.Entry<K,V>这个接口,每个key-value都放在了Node<K,V>这个对象中,采用 Node<K,V>[] tab 数组的方式来保存key-value对,之后判断tab数组是否为空,size是transient声明的实例变量,确保其大于0后,遍历存放key-value的tab数组,每对键值又定义了e来保存并遍历,直到e对应的下一个值为空,将e对应的某值赋给v,最后判断是否和指定值地址相同,或者判断是否键值不为空并且字符完全相同,至少一者成立才能返回true,比之前链表中contains方法的开销、时间复杂度更大。
三、实验过程中遇到的问题和解决过程
-
问题一:实验四的思考过程
-
问题一解决方案:根据上学期学习的后缀表达式的特点,我们可以知道,只要是运算符的就都是根结点。我们这里需要使用一个栈来保存字符。遍历后缀表达式,每当遇到是非运算符的字符,就将它入栈,当遇到是运算符,就将栈中前两个结点出栈,和运算符组成一棵子树,然后入栈。遍历完成后,栈中剩下的唯一的一个结点就是该后缀表达式的二叉树的根结点。但是做着做着发现好像和书上提供的代码是一样的,Java实验肯定不会只是书上的代码,然后仔细分析了题目发现和书上不一样的地方在书上是直接输入后缀表达式,实验要求的是利用树将中缀转后缀之后再用后缀表达式计算。大概想法就变成了将表达式的每一个元素进行拿出,按照数字、加减运算符、乘除运算符分成三种情况,用两个栈或者链表进行保存加减和构成树的结点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号