
BUAA OO 第一单元总结
BUAA OO 第一单元总结
- 第一次作业
第一次作业要求化简一个一元(变量只能为\(x\))的表达式,其中可以出现空白符和连续的正负号,至少需要去掉所有括号。为了得到性能分,还需要进行合并同类项的操作。
· 程序架构
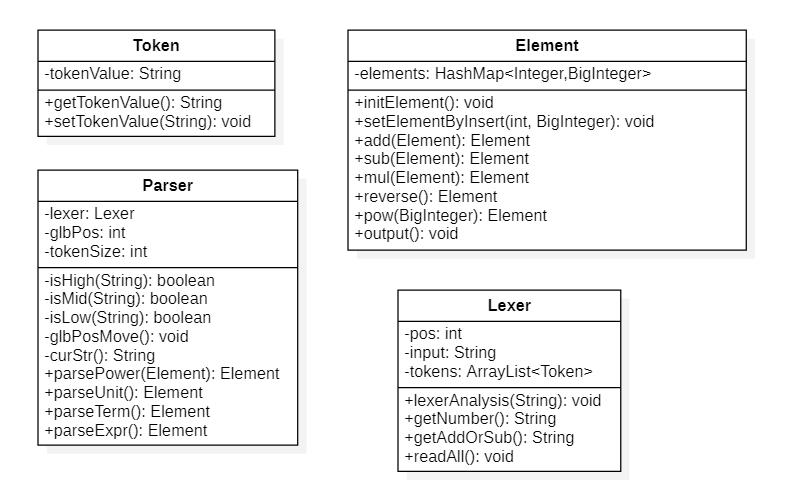
(一些类的get和set方法没有明确标出)
第一次作业采用了递归下降的处理方法,各个类的作用如下:
-
Element:使用
HashMap<Integer,BigInteger>存储各个元素的信息,其中Key表示次数,Value表示系数。由于第一次作业不包含任何其他特殊函数,所以无论是因子、项还是表达式都可以用Element来存储,结构比较统一,方便运算和化简。为方便叙述,给出因子、项和表达式的定义:
- 因子:(+/-)变量的幂 + 常数的幂 + 括号表达式的幂(其中幂次为1可以省略幂指数)
- 项:因子的乘积
- 表达式:项的加和
-
Token:存储表达式基本单元的类,如操作符、括号、操作数和变量。
-
Lexer:对输入表达式进行词法分析的类,将字符串分割为若干token并存入
ArrayList<Token>,并且在读入过程中进行初步化简:- 将连续的一串加减号划归为一个加/减号。
- 对于操作数直接用字符串存储,在后续处理过程中可以直接使用转换为整数。
-
Parser:递归下降逐个解析
ArrayList<Tokens>的元素。glbPos表示token的位置,isHigh() isMid() isLow()方法判断此时的token是否代表运算符并判断优先级。递归下降的入口是parseExpr(),之后进入parseTerm()和parseUnit(),再从parseUnit()调用parseExpr()实现递归下降。由于结构统一,因此每个parse方法的返回类型都是Element。
· 基于度量的结构分析
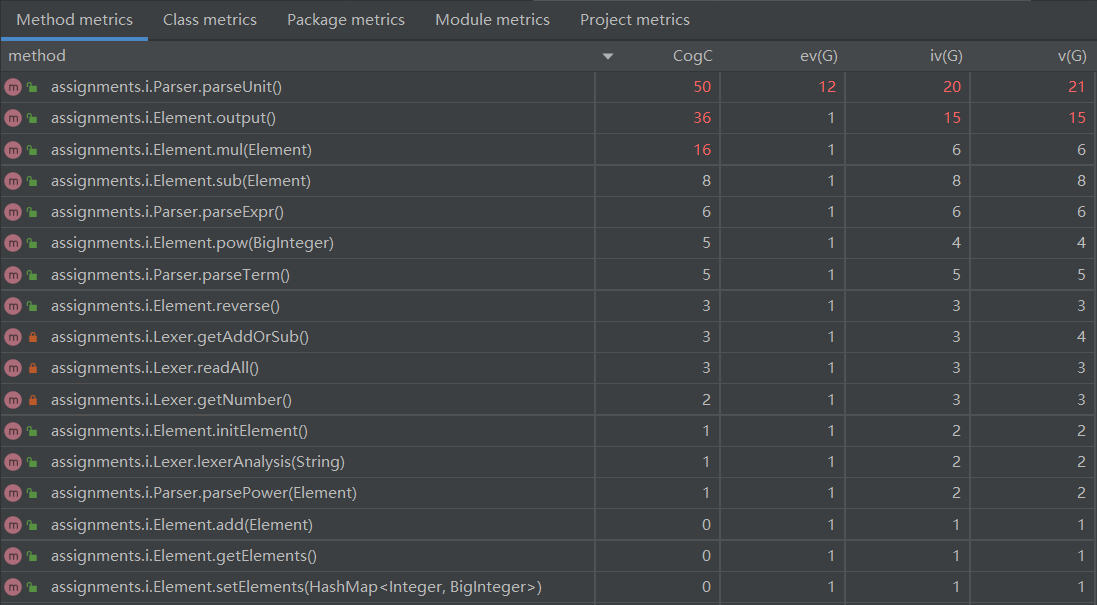
根据CogC指标排序,可以发现认知复杂度较高的方法为parseUnit()和output()。
parseUnit()方法复杂度较高的原因是因子的定义比较多,需要判断类型和是否有乘方,导致其中出现很多判断分支;output()的原因类似,也是出现了很多分支来判断如何输出字符串。
· bug分析
本次作业的bug出现在形式化定义上。一开始我把因子定义为变量的幂 + 常数 + 表达式的幂,可以注意到这里缺少了常数的幂,于是输入x*2**2获得的结果就为4*x**2,因为程序把x*2parse成了一个整体,于是在强测中出现了bug。在parseUnit()方法中添加一个判断即可解决。
- 第二次作业
第二次作业在第一次作业的基础上增加了三角函数(括号内只能是非负整数和\(x\)的非负整数幂)、自定义函数和求和函数,依然要求去除不必要的括号并展开所有自定义函数和求和函数。本次作业的函数不能嵌套。
· 程序架构
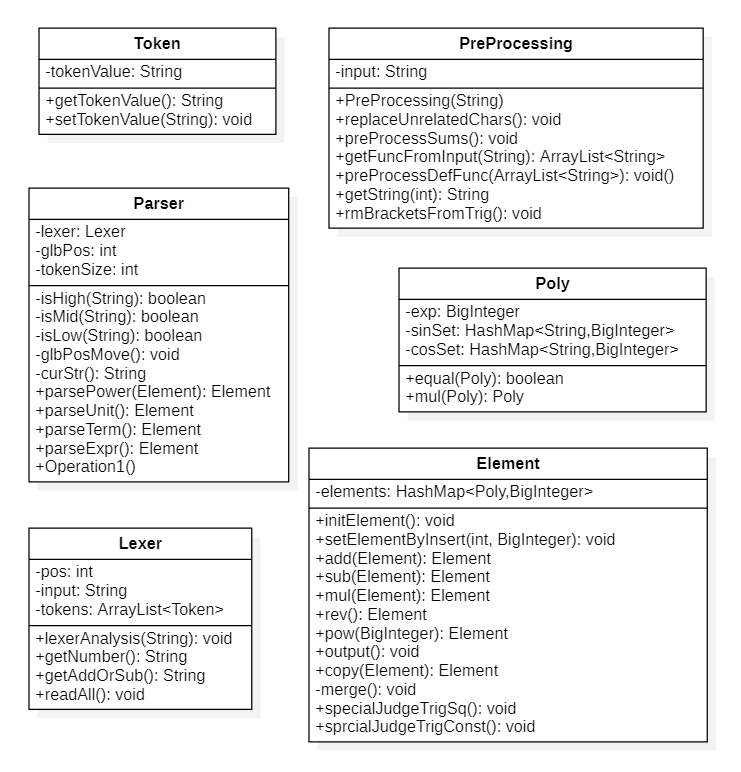
(一些类的get和set方法没有明确标出)
第二次作业仍然保持了递归下降的处理思路,因为找到了可以统一存储表达式各个部分的数据结构,感觉并没有重构的必要。(其实是偷懒)
-
Poly:这里我将项定义为:
\[a*(x^b*\prod_{i=0}^{\infin}\ sin^{s_i}(S_i)*\prod_{j=0}^{\infin}\ cos^{c_i}(C_j)) \]而Poly则存储了最外层括号里面的内容,\(b\)对应
exp,sinSet和cosSet分别对应两个累乘。HashMap<String,BigInteger>中的String记录的是\(S_i\),因为本次作业三角函数中只能是\(x^p\ (p\ge0)\)或者\(t\ (t\ge0,t\in \mathbb{Z})\),因此格式是完全确定且唯一的,可以用字符串存储。而且因子和项都可以用这种形式处理,这使得计算方面更加简便。 -
Element:
HashMap<Poly,BigInteger>表示了Poly和系数\(a\)的对应关系集合,即许多项的和。其中包含了两个化简的方法,分别是特殊处理\(sin(0)/cos(0)\)和处理三角函数*方和。
-
PreProcessing:这个类用来处理自定义函数和求和函数,并且把第一次作业中出现的一些化简步骤整合了进来。下面简要说明如何处理两种函数。
-
自定义函数:
- 读入自定义函数的定义,根据等号划分为左右两部分,分别为
defL和defR,使用正则匹配的捕获组来捕获defL的函数名以及变量(按顺序)。注意在此之前需要得到此函数变量的数量,然后使用特定的Pattern来匹配(我定义了一个Pattern数组,用来存放不同变量数量的defL正则表达式)。 - 当在输入中找到自定义函数(记为
input)的时候进行第二次正则匹配&捕获(注意要找对函数名),按顺序获得需要代入的表达式,这样input和defL中参变量和实际表达式就以捕获组的序号进行了一一对应,方便处理如\(f(y,x)=y-x\)等参变量不按顺序出现的自定义函数。 - 读取
defR,将参变量替换为对应需要代入的表达式即可(记得在每个代入的表达式外套一层括号来表示这是一个整体,防止替换回去之后产生错误),这里需要注意的一点是如果先进行了\(y\)或者\(z\)的替换而参变量中有\(x\),那么在将\(y\)替换为含\(x\)的表达式之后可能会重复替换\(x\)(比如\(f(y,x)=y-x\),input为\(f(x,x+1)\),那么替换过程就是\(y-x\rightarrow x-x\rightarrow (x+1)-(x+1)\rightarrow 0\),这显然是不正确的)。这里我的解决方法是:在替换的时候都把\(x\)替换为不相关的字符\(w\),最后再统一replaceAll("w","x")即可。
在处理自定义函数的时候,助教一再强调不要暴力字符串替换,而是先对表达式进行建模,再代入原式,奈何我没有想到很好的建模方法,于是只是使用了暴力替换。不过如果用表达式树处理的话建模会方便很多,可以先对各个表达式建一棵树,代入的时候替换掉上面的节点再插入原来的表达式树即可。
- 读入自定义函数的定义,根据等号划分为左右两部分,分别为
-
求和函数:也是使用了字符串替换的方法,通过循环 + StringBuilder构建需要替换的字符串。这里有三个需要注意的点:
- \(sin\)中也包含字母i,替换的时候要小心。可以先把三角函数名提前换为s&c来解决。
- 如果求和上限小于下限,则本项应为0。
- 求和上下限最好定义为
BigInteger类型防止溢出。
-
-
Lexer&Parser&Token:和第一次作业基本相同。
· 基于度量的结构分析
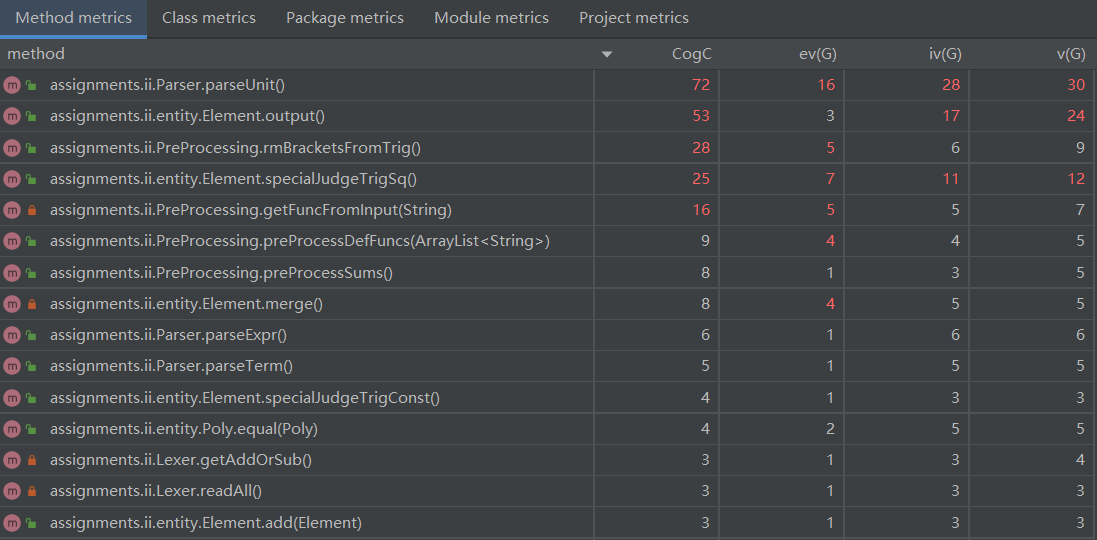
根据CogC指标排序发现,认知复杂度较高的方法前两位仍然是parseUnit()和output(),这是更复杂的因子定义和更复杂的输出逻辑造成的。此外一些化简方法的复杂度也较高。
· bug分析
本次作业在强测和互测中都没有出现bug,不过强测中一些点的性能分不高,这是因为我用原始的字符串来存储三角函数的内容,处理\(sin(0)/cos(0)\)的化简时只考虑到字符串内容为“0”而忽视了\(sin(-0)\)、\(cos(+0)\)等,造成没有化简完全的情况。
- 第三次作业
第三次作业在第二次作业的基础上允许了自定义函数的嵌套(求和函数内不允许出现自定义函数),同时三角函数内可以为表达式。
· 程序架构
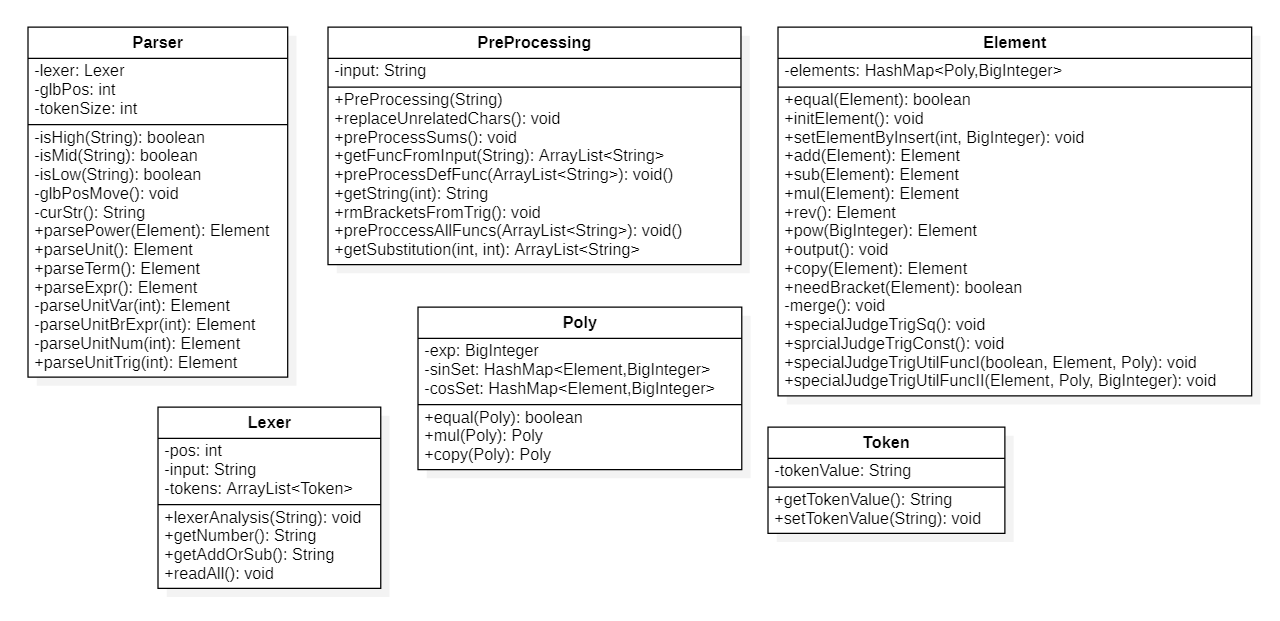
(一些类的get和set方法没有明确标出)
第三次作业在第二次作业的基础上只需要改动很少就可以,所以保持了原来的架构。其中最核心的改动是将Poly中存储三角函数的结构改为HashMap<Element,BigInteger>,并(差不多)重写了Poly和Element的equals()方法。
但是如果想要化简结果,则需要耗费很多时间来完善代码和测试。我花了大概两天时间才基本完成大概化简方法,其中有无数次测试\(\rightarrow\)发现bug\(\rightarrow\)修改代码\(\rightarrow\)测试的循环😭。最核心的是三角函数*方和的化简,大致的逻辑为:
- 遍历Element的
HashMap,看是否同时有两个不同的项,其中一个\(sin\)的次数大于等于2,另一个\(cos\)的次数大于等于2,并且其中包含的内容相同(这里需要重写equals()方法,我自己另外写了一个equal()来替代,这是不明智的做法)。其中内容相同的第一要素是三角函数中Element的HashMap的大小相同,所以需要在每次运算之后进行一次同类项合并。 - 判断这两项在分别将第一步找出来的\(sin\)和\(cos\)次数减去2之后,剩下的部分是否相同,如果相同,则把\(cos\)那项的系数减过去,而它自己丢掉一个\(cos^2\)。比如\(x*sin^3(x+1)+2*cos^2(x+1)*x*sin(x+1)\)化简为\(-x*sin^3(x+1)+x*sin(x+1)\),本质上就是作了\(cos^2P=1-sin^2P\)的替换,虽然不是每个表达式都能完全化简,不过在相当一部分测试样例中都是奏效的。
这里一个重要的点是深拷贝/浅拷贝的区别,比如第二步去掉\(cos^2\)只需浅拷贝,直接修改this的Poly就可以,但是第一步中判断”包含的内容相同“时,不能真的分别去掉\(sin^2\)和\(cos^2\),而是需要复制一份独立的副本(不是引用同一个地址的数据,而是两块独立的内存空间,其中的内容相同),为此可以直接写一个copy()方法来复制,也可以用序列化方法来实现深拷贝(具体实现原理可以上网搜索)。
附序列化实现深拷贝的代码:
public class SerialCloneable implements Cloneable,Serializable
{
public Object clone()
{
try
{
//save the object to a byte array
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bout);
out.writeObject(this);
out.close();
//read a clone of the object from the byte array
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream in = new ObjectInputStream(bin);
Object result = in.readObject();
in.close();
return result;
}
catch(Exception e)
{
return null;
}
}
}
· 基于度量的结构分析
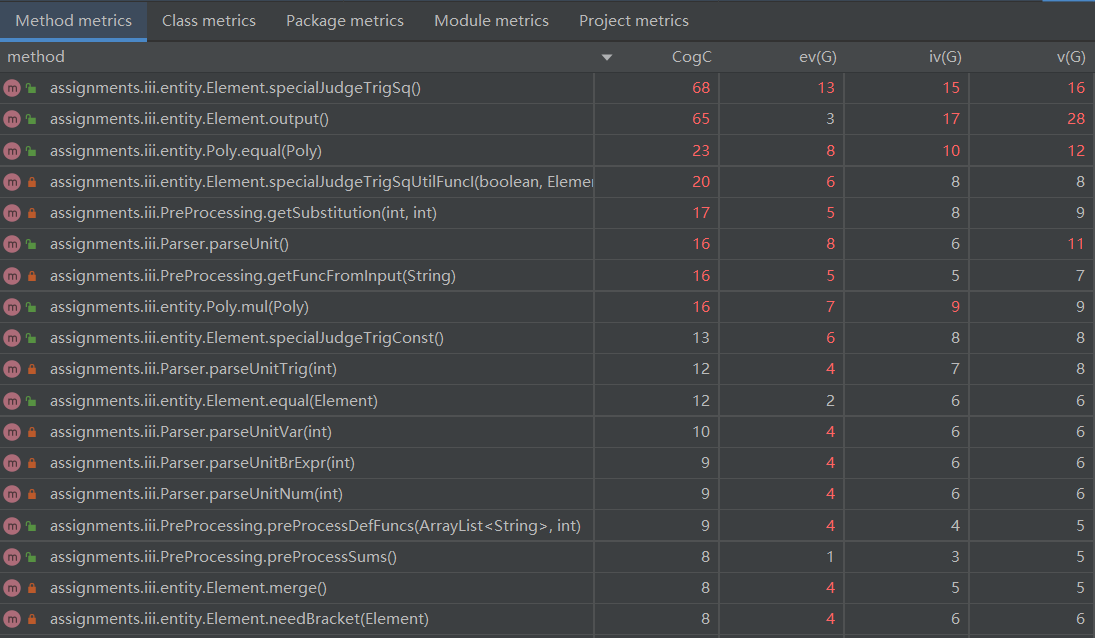
根据分析数据可知,认知复杂度较高的方法主要是化简和输出。本次作业中parseUnit()方法被拆分了,所以复杂度有所降低。
· bug分析
本次作业出现了一些bug,分析如下:
- 由于自定义函数允许嵌套,使用正则表达式捕获组处理输入的表达式会出现错误:
- 正则表达式不能进行括号的匹配,可能会在嵌套的函数中间进行截断,导致程序结果错误甚至报错。
- 解决方法:自行实现自定义函数内部表达式的括号匹配,等价于自己重新写了一个”更加智能“的捕获组。
- 三角函数输出格式错误:
output()调用的needBracket()方法逻辑有误,一些情况下会少输出一对三角函数内的括号,比如应该输出\(sin((5*cos(x)))\)而只输出了\(sin(5*cos(x))\)。- 解决方法:调整
needBracket()内部的逻辑。
- hack策略
下载其他同学的代码更多是为了学习架构(毕竟也没有自动评测机 + 没有发现细枝末节的bug),因此在第一单元的互测中我并没有查看很多同学的代码,更多还是提交边缘数据和测试中出现bug的数据。
- 架构设计评价
三次作业的架构给我最大的印象就是:居然没有使用接口和继承。
其实第一单元作业并没有给我一种逐渐摸索架构的感觉,因为从第一次作业使用HashMap处理各种元素之后,第二次作业我的第一个思路就是:如何填充HashMap来继续保持结构的统一性。于是后来增加的Poly类就不能算是架构很大的调整,无非是细枝末节的完善以迎合新的需求,最后的第三次作业也可以说完全继承了第一次作业的架构。
可能是因为找到了一个统一的数据结构来存储因子、项和表达式,我没有再对项目进行细化处理。所有的计算都包含在Element和Poly类中;所有的表达式整体化简都在PreProcessing类中;所有的词法语法分析都包含在Lexer和Parser类中,相互之间的依赖关系比较浅,一个类处理完后交给另一个类。总体来说类之间的耦合程度很低,每个类基本上在各司其职,内聚程度比较高。
但是我认为这种架构的可扩展性不够,并且没有很好遵守”对新增开放、对修改关闭“的编程原则。可以发现从第一次到第三次作业的过程中,Element类在不断膨胀,虽然后两次中添加了Poly来”分担“处理表达式的职能,但是仍然不是一个很好的解决方案。如果后续还有第四次甚至第五次迭代,这个架构有两种结果:要么膨胀到复杂度极高的状态,要么只能推倒重构。如果想要提高可扩展性,可以将Element和Parser拆开,增加其他的表达式元素类并使用接口。
- 心得体会
面向对象第一单元到这里就告一段落了,在本学期开始之前,我对OO的设想是:无非只是学一门新语言而已,但是这一单元带给我的绝不止熟悉Java的语法那么简单。面向对象不只是一种编程思想,还是一种理解世界的抽象化思维,它更加贴*人们*常认识事物的方式,并且便于迭代开发(这一单元使用面向过程恐怕最多可以通过第一次作业)。无论是对未来的程序设计还是对认识世界的思维方式,面向对象思想都大有可用之处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号