XGBoost
一、XGBoost起源
XGBoost的全称是ExtremeGradient Boosting,2014年2月诞生,作者为华盛顿大学研究机器学习的大牛——陈天奇。
他在研究中深深的体会到现有库的计算速度和精度问题,为此而着手搭建完成 xgboost 项目。
XGBoost问世后,因其优良的学习效果以及高效的训练速度而获得广泛的关注,并在各种算法大赛上大放光彩。
二、参数解析
XGBoost的作者把所有的参数分成了三类:
通用参数:宏观函数控制。
Booster参数:控制每一步的booster(tree/regression)。
学习目标参数:控制训练目标的表现
1)通用参数
booster[默认gbtree]
选择每次迭代的模型,有两种选择:
gbtree:基于树的模型
gbliner:线性模型
尽管有两种booster可供选择,tree booster的表现远远胜过linear booster,所以linear booster很少用到
silent[默认0]
当这个参数值为1时,静默模式开启,不会输出任何信息。
一般这个参数就保持默认的0,因为这样能帮我们更好地理解模型。
nthread[默认值为最大可能的线程数]
这个参数用来进行多线程控制,应当输入系统的核数。
如果你希望使用CPU全部的核,那就不要输入这个参数,算法会自动检测它。
2)booster参数
-
1. learning_rate[默认0.3]
典型值为0.01-0.2。
-
2. min_child_weight[默认1]
决定最小叶子节点样本权重和。这个参数用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。
-
3. max_depth[默认6]
这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。需要使用CV函数来进行调优。典型值:3-10
-
4. max_leaf_nodes
树上最大的节点或叶子的数量。可以替代max_depth的作用。因为如果生成的是二叉树,一个深度为n的树最多生成n2个叶子。
-
5. gamma[默认0]
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。
-
6. max_delta_step[默认0]
这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。通常,这个参数不需要设置。但是当各类别的样本十分不平衡时,它对逻辑回归是很有帮助的。
这个参数一般用不到,但是你可以挖掘出来它更多的用处。
-
7. subsample[默认1]
这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。典型值:0.5-1
-
8. colsample_bytree[默认1]
用来控制每棵随机采样的列数的占比(每一列是一个特征)。典型值:0.5-1
-
9. colsample_bylevel[默认1]
用来控制树的每一级的每一次分裂,对列数的采样的占比。
我个人一般不太用这个参数,因为subsample参数和colsample_bytree参数可以起到相同的作用。但是如果感兴趣,可以挖掘这个参数更多的用处。
-
10. lambda[默认1]
权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。
-
11. alpha[默认0]
权重的L1正则化项。(和Lasso regression类似)。可以应用在很高维度的情况下,使得算法的速度更快。
-
12. scale_pos_weight[默认1]
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
3)学习目标参数:这个参数用来控制理想的优化目标和每一步结果的度量方法。
objective(默认reg:linear):这个参数定义需要被最小化的损失函数。最常用的值有:
binary:logistic 二分类的逻辑回归,返回预测的概率(不是类别)。
multi:softmax 使用softmax的多分类器,返回预测的类别(不是概率)。 在这种情况下,你还需要多设一个参数:num_class(类别数目)。
multi:softprob 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。
eval_metric(默认值取决于objective参数的取值)
对于有效数据的度量方法。
对于回归问题,默认值是rmse,对于分类问题,默认值是error。
典型值有:

seed(默认0):随机数的种子
三、Xgboost原理推导
1)基本原理
首先使用训练集训练一棵树,然后使用这棵树预测训练集,得到每个样本的预测值,由于预测值与真值存在偏差,所以真值与预测值相减可以得到“残差”(这里相当于用训练集训练模型,再反过来作用于训练集-不要以为一棵树就能完全学到所有样本的真值,那样会过拟合的)
接下来训练第二棵树,此时不再使用真值,而是使用残差作为标准答案。两棵树训练完成后,可以再次得到每个样本的残差
然后进一步训练第三棵树,以此类推。树的总棵数可以人为指定,也可以监控某些指标(例如验证集上的误差)来停止训练
2)示例
a)预测客户去银行审批贷款的额度,假设客户的额度为1000
使用第一颗树预测,其目标函数为1000。假设模型预测的结果为920,则残差为80
构造第二课树预测,这时其目标函数就要基于第一颗树的预测结果,第二颗树的目标函数为80。假设第二颗树预测的结果为50,则与真实值的残差还剩下30,即会作为第三颗树的目标值
构造第三棵树预测,此时的目标函数为30,假设第三课树又找回来12
依次类推,串行构造,需要把前一颗树的结果当成一个整体。最终结果值为n棵树的结果相加。比如例中,如果只做三颗树预测,最终结果为982
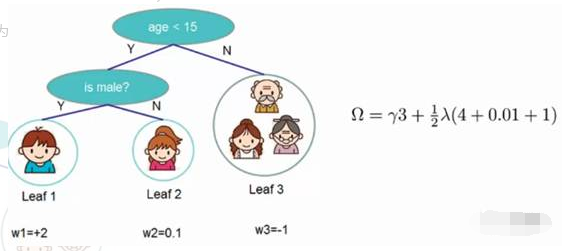
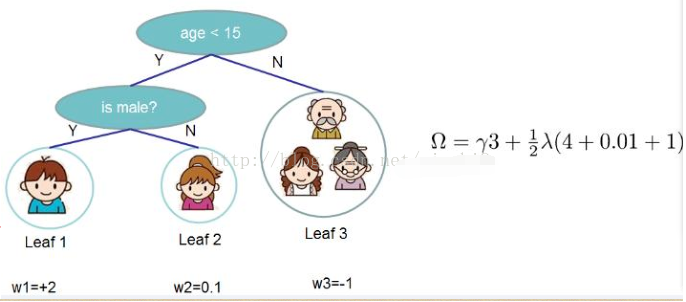
b)用两颗树来预测一个人是否喜欢玩游戏。最下面的一行数2、0.1、-1为得分值

模型的结果为两颗树的值相加。比如男孩爱玩游戏的得分为2.9,老人爱玩游戏的得分为-1.9
3)简单流程
假设我们构造k颗树,则对于样本i来说,输出值就是k颗树的输出值累加:
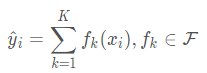

其中K表示总共K个决策树,k表示第k个决策树,F表示决策树的函数空间
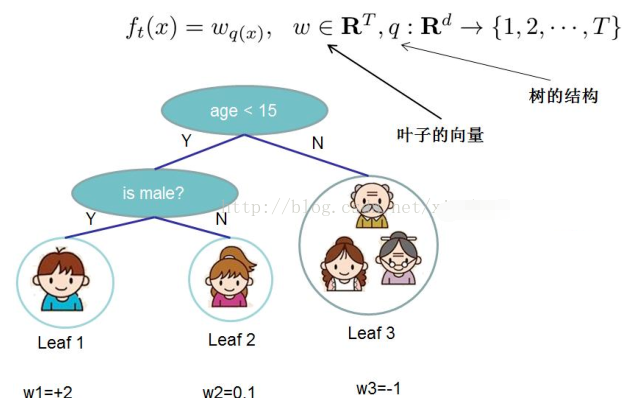
每一个决策树都有独立的树结构q和叶节点权重w
首先,我们想问“树的参数是什么”?我们需要学习的是函数\(f_k\)包含独立的树结构q和叶节点权重w,这比传统的利用梯度法求解的优化问题要难得多
由于同时训练所有的树不容易,我们选用另一策略:将已经学习的树固定,每次向其中添加一棵新的树,在第t颗树后获得的预测值记为: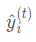 ,因此我们构建流程如下:
,因此我们构建流程如下:

所以整个流程就是每一轮增加一颗什么样的树\(f_t(x_i)\),才能使模型最优
4)推导
我们希望每轮增加的树可以优化目标函数:

这里要注意:Constant是前t-1棵树的惩罚项,前t-1树结构已经确定
前t-1棵树预测值之和+第t棵树预测值与真实值要最接近
惩罚项主要防止树模型过大,由叶子数量和L2正则组成:
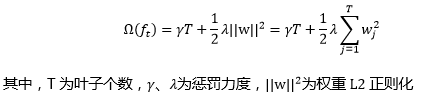
其中惩罚项计算如下:注意-叶子节点权重w(其实就是预测值)
在推导之前,需要读者先了解泰勒公式:
![]()
这里可以这么理解:$x$为原来的模型,红框内的$\Delta x$当作新的树模型,即新增加一个模型
这样我们就可以进行如下泰勒展开
而我们的目标函数是:
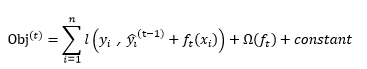
如果用MSE-平方损失作为损失函数,将上式展开(注意:将平方项展开后的常数项已经用新的constant代替):

但是对于其他的损失函数,我们未必能得出如此漂亮的式子,所以,对于一般的损失函数,我们可以采用如下的泰勒展开近似来定义一个近似的目标函数,如下所示:

值得注意的是,损失函数l是给定的,y的真实值是知道的,预测值是根据前t-1颗树知道的,则gi和hi是可算的
这里如果我们的损失函数是平方损失函数,则gi和hi计算如下:
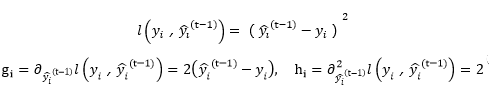
这里有必要再明确一下,gi和hi的含义。gi怎么理解呢?现有t-1棵树是不是?这t-1棵树组成的模型对第i个训练样本有一个预测值\(y_i\)是不是?
这个预测值与第i个样本的真实标签\(yi\)肯定有差距是不是?这个差距可以用上面的损失函数来衡量是不是?现在gi和hi的含义你已经清楚了是不是?
我们来看一个实例,假设我们正在优化第11棵CART树,也就是说前10棵 CART树已经确定了。这10棵树对样本\((x_i,y_i=1)\)的预测值是\(y_i=-1\),假设我们现在是做分类,我们的损失函数是:

我们可以求出这个损失函数在\(y_i=-1\)点的梯度:
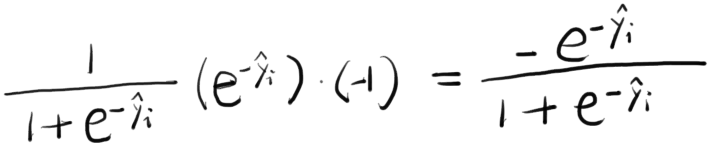
将\(y_i=-1\)带入上式,计算得到-0.2689。这个-0.2689就是g_i。该值是负的,也就是说,如果我们想要减小这10棵树在该样本点上的预测损失,我们应该沿着梯度的反方向去走,也就是要增大
来答一个小问题,在优化第t棵树时,有多少个gi和hi要计算?嗯,没错就是各有N个,N是训练样本的数量。如果有10万样本,在优化第t棵树时,就需要计算出个10万个gi和hi
感觉好像很麻烦是不是?但是你再想一想,这10万个gi之间是不是没有啥关系?是不是可以并行计算呢?聪明的你想必再一次感受到了,为什么xgboost会辣么快!
好,现在我们来审视下这个式子,哪些是常量,哪些是变量。式子最后有一个constant项,聪明如你,肯定猜到了,它就是前t-1棵树的正则化项。l(yi, yi^t-1)也是常数项
剩下的三个变量项分别是第t棵CART树的一次式,二次式,和整棵树的正则化项。再次提醒,这里所谓的树的一次式,二次式,其实都是某个叶子节点的值的一次式,二次式
我们的目标是让这个目标函数最小化,常数项显然没有什么用,我们把它们去掉,就变成了下面这样:
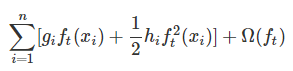
5)重新定义决策树
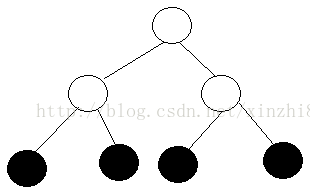
一个xi的样本进入决策树分类是由最终的的叶子权值决定,即黑色实心圆,而中间的空心圆只是决定的 xi 样本落入到哪一个叶子
q(x)表示样本x落入的叶子,即是q是将每个样本分配到相应叶子的函数
Wq(x)表示样本x落入叶子的权值,即W是叶节点上的得分向量
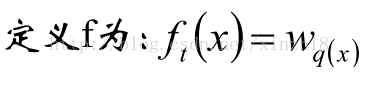
所以一颗决策树的核心是:“树结构”与“叶权值”,如下:

6)正则项定义
决策树的复杂度可参考叶节点数和叶权值(在XGBoost里,如下定义复杂度):
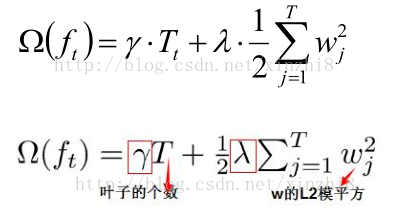
举例:
注意:当然,不止一种方式可以定义复杂度,但实践中上面提到的就能很好得起作用。正则化项在很多树模型包里都没有很好地处理,甚至直接忽略
这是因为,传统树模型只强调提升模型的纯度,而模型复杂度控制采用启发式方法。通过公式定义,我们可以更好得理解学习器训练过程,并起获得较好的实践结果
下面是公式推导里神奇的部分!将树模型重新公式化表示之后,可以将第t棵树的目标值记作:
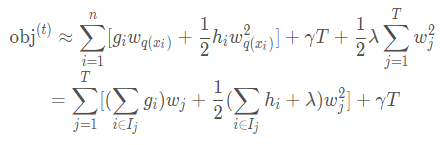
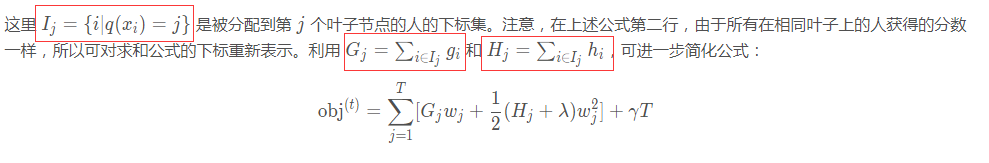
也就是下面的解释: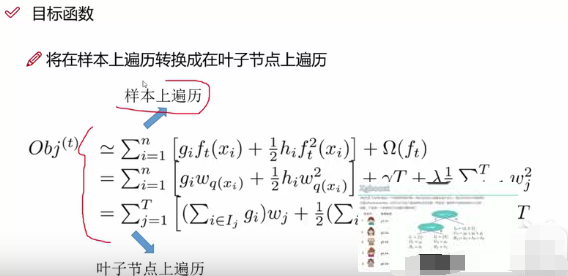

也就是衡量了我们当前树的模型效果的好坏
7)目标函数计算总结:
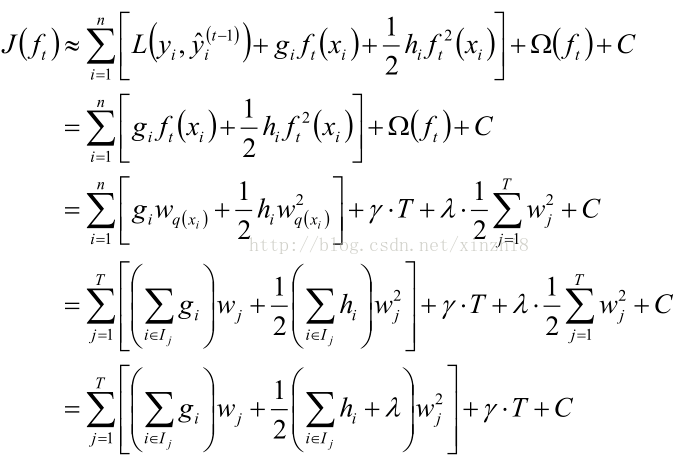
定义如下式子:
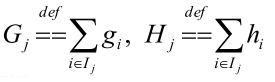
得:
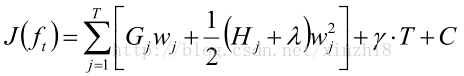
对W求偏导:
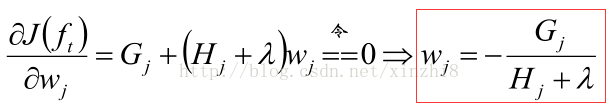
代入目标函数:
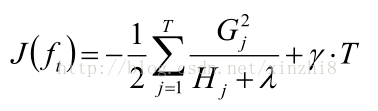
举例:XGBoost公式做的事情

8)找出最优的树结构
有了评判树的结构好坏的标准,我们就可以先求最佳的树结构,这个定出来后,最佳的叶子结点的值实际上在上面已经求出来了
问题是:树的结构近乎无限多,一个一个去测算它们的好坏程度,然后再取最好的显然是不现实的。所以,我们仍然需要采取一点策略,这就是逐步学习出最佳的树结构
这与我们将K棵树的模型分解成一棵一棵树来学习是一个道理,只不过从一棵一棵树变成了一层一层节点而已。如果此时你还是有点蒙,没关系,下面我们就来看一下具体的学习过程
我们以上文提到过的判断一个人是否喜欢计算机游戏为例子。最简单的树结构就是一个节点的树。我们可以算出这棵单节点的树的好坏程度obj*。假设我们现在想按照年龄将这棵单节点树进行分叉,我们需要知道:
1、按照年龄分是否有效,也就是是否减少了obj的值
2、如果可分,那么以哪个年龄值来分
为了回答上面两个问题,我们可以将这一家五口人按照年龄做个排序。如下图所示:
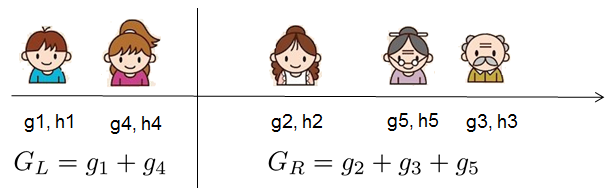
按照这个图从左至右扫描,我们就可以找出所有的切分点。对每一个确定的切分点,我们衡量切分好坏的标准如下:
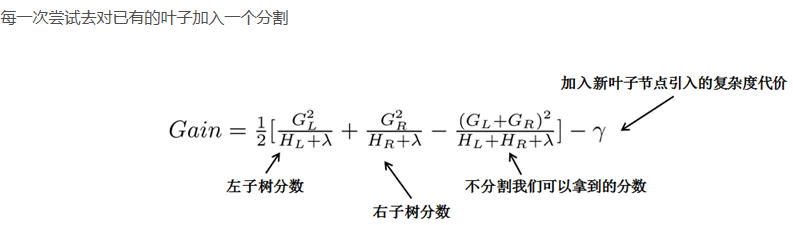
这个Gain实际上就是单节点的obj*减去切分后的两个节点的树obj*,Gain如果是正的,并且值越大,表示切分后obj*越小于单节点的obj*,就越值得切分
同时,我们还可以观察到,Gain的左半部分如果小于右侧的γ,则Gain就是负的,表明切分后obj反而变大了。γ在这里实际上是一个临界值,它的值越大,表示我们对切分后obj下降幅度要求越严
这个值也是可以在xgboost中设定的。 扫描结束后,我们就可以确定是否切分,如果切分,对切分出来的两个节点,递归地调用这个切分过程,我们就能获得一个相对较好的树结构
注意:xgboost的切分操作和普通的决策树切分过程是不一样的。普通的决策树在切分的时候并不考虑树的复杂度,而依赖后续的剪枝操作来控制。xgboost在切分的时候就已经考虑了树的复杂度,就是那个γ参数。所以,它不需要进行单独的剪枝操作
四、感谢
Xgboost基本原理好理解,但是推导过程比较复杂抽象,自己也花了几天的时间去看博客和文章,这里感谢下面的博客,正是你们的抽象变具体,才让我加深了对Xgboost的理解,真诚的感谢!
1.https://blog.csdn.net/xinzhi8/article/details/73466554
2.https://blog.csdn.net/PbGc396Dwxjb77F2je/article/details/78786959
3.https://blog.csdn.net/cymy001/article/details/79037785
4.https://www.cnblogs.com/kuangsyx/p/9043168.html
视频参考:https://www.bilibili.com/video/BV1KE411M7Pi?p=1(讲的不错哦)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号