

As a reader --> AdvDiffuser: Natural Adversarial Example Synthesis with Diffusion Models
- 📌论文分类4:
AdvDiffuser is open source and available at https://github.com/lafeat/advdiffuser
https://github.com/ChicForX/advdiff_impl
- 论文名称 AdvDiffuser: Natural Adversarial Example Synthesis with Diffusion Models
- 作者 Chen X, Gao X, Zhao J, et al.
- 期刊名称 Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 4562-4572.
- 简要摘要
过去的对抗样本研究工作通常涉及固定范数扰动预算,无法捕捉人类感知扰动的方式。最近的研究转向了自然无限制对抗例子(unrestricted adversarial examples, UAEs),它打破了lp扰动界限,但仍然在语义上是合理的。目前的方法使用GAN或VAE通过扰动潜在编码来生成UAEs。然而,这会导致高级信息的丢失,从而导致低质量和不自然的UAEs。鉴于此,本文提出了一种利用扩散模型合成自然UAEs的新方法AdvDiffuser。它可以从头开始或有条件地基于参考图像生成UAEs。
为了生成自然的UAEs,对预测图像进行扰动,将其潜在编码引导到特定分类器的对抗样本空间。本文还提出了基于类激活映射的对抗性绘制,以保留图像的突出区域,同时干扰不太重要的区域。在CIFAR-10, CelebA和ImageNet上,证明了它可以以接近100%的成功率击败RobustBench排行榜上最强大的模型。此外,与目前最先进的攻击相比,合成的UAEs不仅更自然,而且更强大。具体来说,与GA攻击相比,使用AdvDiffuser生成的UAEs表现出小6倍的LPIPS扰动,小2~3倍的FID分数和高出0.28的SSIM指标,使它们在感知上更隐蔽。最后,使用AdvDiffuser进行对抗性训练,进一步提高了模型对不可见威胁模型攻击的鲁棒性。
- 关键词 UAE DM
- ✏️论文内容
- 【内容1】
- 💡Introduction & Preliminaries & Related Work
- 基于梯度的无限制对抗性攻击在预定义的扰动范围内扰动原始图像。Geometry-aware attacks几何感知攻击[20]使用代理模型最小化所需的lp预算,并在无限制对抗性攻击的CVPR竞赛中获得第一名[4]。另一方面,perceptual attacks感知攻击[19,51]使用感知距离的界限来优化扰动,如LPIPS[49]和结构相似性[42]。其他方法则考虑图像的重新着色[36,37]。然而,选择代理模型和距离度量需要主观先验知识,来生成看起来现实的对抗性样本。
- 生成对抗网络(GANs)等生成模型具有从数据分布中有效学习和采样的能力[38,50],这就是为什么要使用它们来生成对抗性样本的原因。这些方法搜索潜在空间中的扰动,这些扰动可能导致目标模型在解码后对图像进行错误分类,以便找到对抗性样本。然而,干扰潜在编码会改变生成图像的高级语义,这在人类感知上是显著的[17]。这种扰动会在某些图像属性中引入模糊性,并明显扭曲原始概念,从而经常导致生成语义模糊且质量差的UAEs。这些UAEs在感知上可能与原始样本非常不同。
- 为了解决这些问题,本文提出了AdvDiffuser,一种基于扩散模型的新型生成式无限制对抗性攻击[13]。扩散模型的灵感来自于非平衡热力学,它定义了一个对图像加噪进行扩散步骤的马尔可夫过程,然后学习反向扩散过程,从有噪声的图像中生成数据样本。这使得经过训练的扩散模型能够以高保真度和多样性对数据分布进行采样。
- 具体地,利用并修改了预训练扩散模型的反向去噪过程,并注入了能够成功攻击防御模型的小的对抗性扰动。扩散模型是用去噪目标训练的,因此,它们可以有效地去除明显的对抗性噪声,同时保留攻击能力,产生自然的UAEs。为了获得更逼真的结果,本文引入了对抗性修复,它利用了基于梯度的类激活映射(GradCAM)的掩码[35]。它根据物体的显著性调整每个像素的去噪强度,确保包含重要物体的区域经历较小的修改。由于AdvDiffuser在像素级扰动图像,与基于GAN的方法产生的扰动相比,它产生的感知扰动要小得多。因此,与基于梯度或GAN的方法合成的UAEs相比,本文方法产生的最终UAEs更自然,更难以察觉。除了图像条件攻击之外,AdvDiffuser提供了另一个优于其他无限制对抗性攻击的优势,因为它能够生成无限数量的合成但自然的对抗性示例。这可以潜在地为未来的防御技术提供更全面的健壮性训练和评估。
- contribution
- 第一个用扩散模型研究自然对抗样本合成的工作。除了它的图像条件攻击能力,它也是第一个可以生成无限数量的合成但自然的对抗样本的。
- 提出对抗性图像处理,以引入基于CAM的样本条件,在保留参考图像语义的同时产生多样化和高质量的输出。
- AdvDiffuser可以成功地欺骗RobustBench[6]中排名靠前的鲁棒模型,成功率很高(接近100%)。生成的样本与原始分布非常相似。与目前最先进的无限制对抗性攻击相比,本文的扰动更有效,更不易察觉,具有更好的LPIPS, FID和SSIM距离指标。
- 第一个用扩散模型研究自然对抗样本合成的工作。除了它的图像条件攻击能力,它也是第一个可以生成无限数量的合成但自然的对抗样本的。
- Unrestricted Adversarial Examples
- 由于lp-范数距离不足以准确捕捉人类如何感知扰动,近年来人们对无限制对抗示例(UAEs)的兴趣激增。UAEs是满足如下条件的分布的图像:人类可以正确分类,但被分类器错误分类。
第一类方法利用规定的图像变换,看起来很自然地搜索UAEs。Xiao等[44]使用空间扭曲变换生成对抗性示例。Ali等[37]通过切换到LAB色彩空间,在保持亮度分量不变的情况下,对AB通道进行了对抗性样本的优化,改变了不同区域的扰动范围。
许多论文已经提出了训练生成模型来生成对抗性攻击的想法[1,43,15]。然而,这种方法通常受到攻击成功率有限的影响。[46,38,15,50]中提出了一种替代方法,该方法利用在自然图像上预训练的生成模型,通过干扰潜在表示来产生对抗性样本。这种技术可能会产生视觉质量较低的UAEs,它可能不会较好地匹配原始数据分布。
基于梯度的非受限攻击[19,20]使用传统的lp范数以外的距离度量搜索UAEs。这种方法导致了更强的对抗性扰动,但难以被人类感知。Laidlaw等[19]使用LPIPS[49]执行投影梯度下降(PGD) [23], LPIPS采用深度特征作为感知度量。几何感知攻击[20]进一步使用验证模型来寻找lp攻击的最小摄动界限。然而,选择代理模型和距离度量需要主观先验知识来生成看起来现实的对抗性示例。
- 由于lp-范数距离不足以准确捕捉人类如何感知扰动,近年来人们对无限制对抗示例(UAEs)的兴趣激增。UAEs是满足如下条件的分布的图像:人类可以正确分类,但被分类器错误分类。
- Diffusion Models
- Ho等人[13]首次证明扩散模型可以生成比GAN质量和多样性更高的图像。
在此基础上,改进的DDPM[24]学习方差调度,提高样本质量和采样效率。Dhariwal等[7]用分类器引导进一步增强,生成类条件样本。这种方法利用分类器的softmax交叉熵损失梯度来指导图像合成。受此启发,Liu等[21]将其扩展到基于图像和文本的引导,Choi等[5]使用参考图像作为引导,进一步实现了图像翻译、编辑和绘图应用。Ho等人[14]提出训练条件扩散模型,消除了使用分类器的需要。
扩散模型在各个领域都有许多应用。例如,Dall-E[28]和stable diffusion[30]通过用户指定的文本提示,生成专业的艺术绘画。DiffPure[25]使用扩散模型来净化对抗性样本,使下游视觉模型更加鲁棒。此外,还有许多将扩散模型应用于自然语言处理、信号处理和时间序列数据建模的技术。
- Ho等人[13]首次证明扩散模型可以生成比GAN质量和多样性更高的图像。
- 💡Introduction & Preliminaries & Related Work
- 【内容2】
- 💡Method
- 图1提供了AdvDiffuser算法的高级概述。
![]()
- 该算法首先计算被攻击图像的Grad-CAM[35],利用防御模型和ground-truth标签形成显著目标的掩码。然后,迭代使用预训练的扩散模型,对潜在图像x_(t-1)进行去噪。
- 随后,对图像进行l2-bounded PGD攻击。在此之后,AdvDiffuser使用预先计算的掩码在产生的攻击图像和带噪的原始图像之间进行插值。通过重复t步去噪过程,它形成了一个添加对抗性扰动的过程,同时从注入的噪声中去除非自然成分。因此,本方法可以生成语义上接近原始的对抗性样本,但包含具有更多细节多样性的基于形状的对抗性扰动。
- 该算法首先计算被攻击图像的Grad-CAM[35],利用防御模型和ground-truth标签形成显著目标的掩码。然后,迭代使用预训练的扩散模型,对潜在图像x_(t-1)进行去噪。
- Adversarial Guidance
- 引入对抗性引导,使用扩散模型生成自然对抗性样本。这涉及到迭代解决以下优化问题:
![]()
- 在每一步中,该过程首先去噪先前扰动的潜在变量x_(t-1),然后引入欺骗防御分类器f的对抗性扰动。因此,它形成一个鞍点解,试图用扩散模型最小化负对数似然,同时增加防御分类器f的对抗性损失,其中y = argmax f(x)是预测标签。
- 为了优化(5),采用投影梯度下降(PGD)[23]攻击,通过迭代i ∈ [0: I-1],找到参考图像z_0的近似解z_I:
![]()
- P表示z在l2-distance 的ε-ball中的投影。进一步,使用标准化的softmax交叉熵(SCE)损失[47]作为最大目标函数L,而不是传统的SCE损失,因为它被证明比替代的损失更有效地产生成功的攻击。令z_I = PGD(z_0, f, , I)来求解上述过程,其中z_0 = x_(t-1), x_t = z_I , ε = ε_t,分别求解(6)
- 最终,令ε_t = σβ_t,σ∈[0, 1 ]调整对抗性引导的强度。这意味着(6)注入的对抗性扰动总是小于扩散模型使用的噪声尺度,并且减小w.r.t.方差表以保证合成样本的自然性。
- 引入对抗性引导,使用扩散模型生成自然对抗性样本。这涉及到迭代解决以下优化问题:
- Adversarial Inpainting
- 对抗性修复:允许基于参考图像创建自然的对抗性样本。该过程确保生成的图像与参考图像非常相似,同时还处理背景纹理、形状或对象等方面,这些方面可能被防御分类器视为包含不相关的特征。目标是生成能够成功欺骗防御分类器的图像,同时最好保留原始图像中的显著目标。
- 该过程首先使用梯度加权类激活映射(gradient - weighted class activation mapping, Grad-CAM)识别ground-truth标签y的参考图像x0中的显著区域[35]。Grad-CAM基于防御分类器f,帮助定位y对应对象的类特定区域,然后将定位进一步归一化为[0,1],成为显著对象的掩码:
![]()
- 受inpainting技术的启发[22],在每个去噪步骤t中,有评估如下:
![]()
- x_(t-1)可以在xt上使用(4)进行采样。
- 对抗性修复:允许基于参考图像创建自然的对抗性样本。该过程确保生成的图像与参考图像非常相似,同时还处理背景纹理、形状或对象等方面,这些方面可能被防御分类器视为包含不相关的特征。目标是生成能够成功欺骗防御分类器的图像,同时最好保留原始图像中的显著目标。
- The AdvDiffuser Algorithm
- 算法1中提供了AdvDiffuser的完整算法概述。
![]()
- 该算法接受一个扩散模型ε_θ、一个受攻击的分类器f、一个可选的参考图像x、一个ground-truth标签y、一个对抗导引标度σ、一个对抗迭代I和一个噪声表β_(1:T)作为输入。如果指定了参考图像,则计算显著目标掩码m。对于每个扩散步骤t,算法使用条件扩散器对目标y迭代去噪潜在变量x_t。之后,它注入一个小的对抗性扰动,并使用PGD攻击构造z_I。然后,它通过使用掩码m在带噪图像xobj_(t-1)和z_I之间的插值来保留显著目标。最终,在完成所有步骤后,它产生自然的对抗示例x_0。
- 算法1中提供了AdvDiffuser的完整算法概述。
- 💡Method
- 【内容2】
- 💡Experimental Results
在引入扰动的隐蔽性和合成样本的真实性方面,对现有的sota进行了比较。最后,对其功能组件和超参数进行了消融实验和敏感性分析。- 实验设置:数据集 --> ImageNet、CIFAR-10、CeleBA 模型 --> 预训练条件DDPM模型 白盒环境
- 比较方法
- Synthetic Adversarial Examples from Scratch
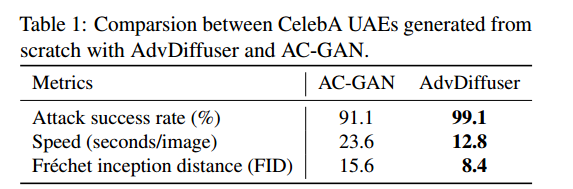
- 首先比较AdvDiffuser和AC-GAN[38]各自从零开始生成对抗性示例的能力。
- 使用了与[38]中对抗性训练相同的鲁棒性分类器。它具有97.3%的自然准确率,在l∞ = 8/255的PGD攻击下精度为76.5%的鲁棒性。如表1所示,AdvDiffuser在成功率、FID评分[12]和样本生成速度方面都优于AC-GAN。
![]()
- 图2显示了随机抽样的带有各自方法的UAEs。对比进一步表明,AdvDiffuser可以生成具有内聚性的人脸图像,而AC-GAN可能无法生成具有真实人脸特征的图像。
![]()
- 进一步提供了为ImageNet模型从头合成对抗性样本的示例,如图3所示。
![]()
- 首先比较AdvDiffuser和AC-GAN[38]各自从零开始生成对抗性示例的能力。
- Unrestricted Adversarial Examples
对于依赖图像的UAEs合成,将AdvDiffuser与当前的SOTA,几何感知(GA)攻击[20]进行比较,后者是2021年CVPR竞赛的第1名获胜者[4]。它包含并自然包含两个子攻击,即使用PGD攻击的GA-PGD[23]和使用特征空间攻击(FSA)的GA-FSA[46]。对于黑盒可转移性,GA算法攻击使用验证模型来确定最优摄动预算。在白盒攻击的情况下,这样的验证模型是不必要的,使用相同的扰动预算增量。- CIFAR-10:如图4所示,本文攻击方法可以生成与原始图像相似但具有不同特征的对抗样本。表2提供了各自模型上的攻击成功率。附录D中进一步比较了DiffPure下的攻击方法,DiffPure是一种利用扩散模型来净化对抗性扰动的防御机制。
![]()
![]()
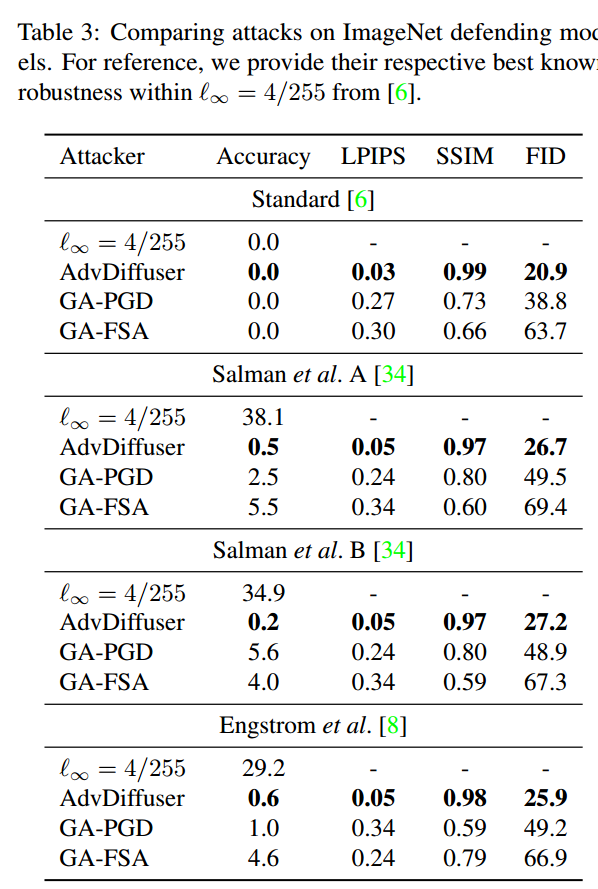
- ImageNet:GA攻击变体通常对防御有效。然而,如图5所示,它们在一定程度上改变了图像的整体颜色,造成了显著的颜色偏移。另一方面,GA-PGD产生的扰动在低信息区域(例如背景天空)很容易被注意到。相比之下,本文的UAEs更加现实。AdvDiffuser不仅比两种GA变体具有更高的成功率,而且更难以识别,具有更高的SSIM,更低的LPIPS和FID评分,如表3所示。
![]()
![]()
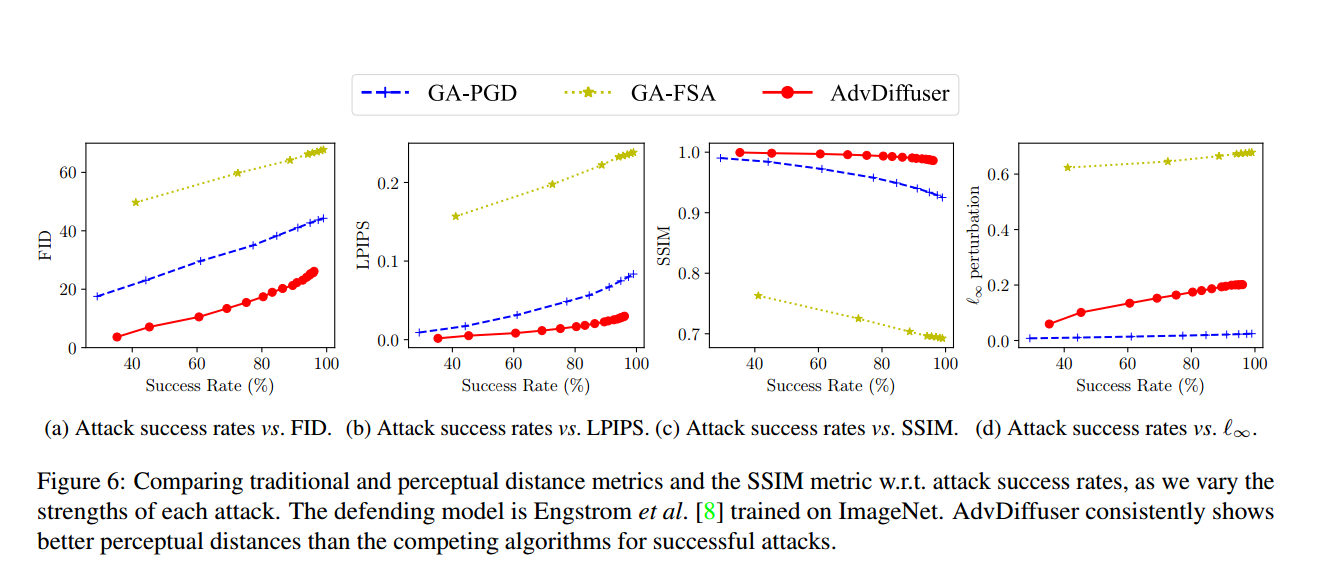
- 图6描述了FID、平均l∞、LPIPS和SSIM距离指标w.r.t.攻击成功率,因为我们改变了每次攻击的强度。该图显示,AdvDiffuser的表现一直优于竞争对手,因为除了l∞距离指标外,它对所有指标都产生了微小的变化。排除l∞距离,因为这不是本文优化的目标,图5显示l∞有界攻击产生明显的伪影。此外,它与所考虑的感知指标无关。
![]()
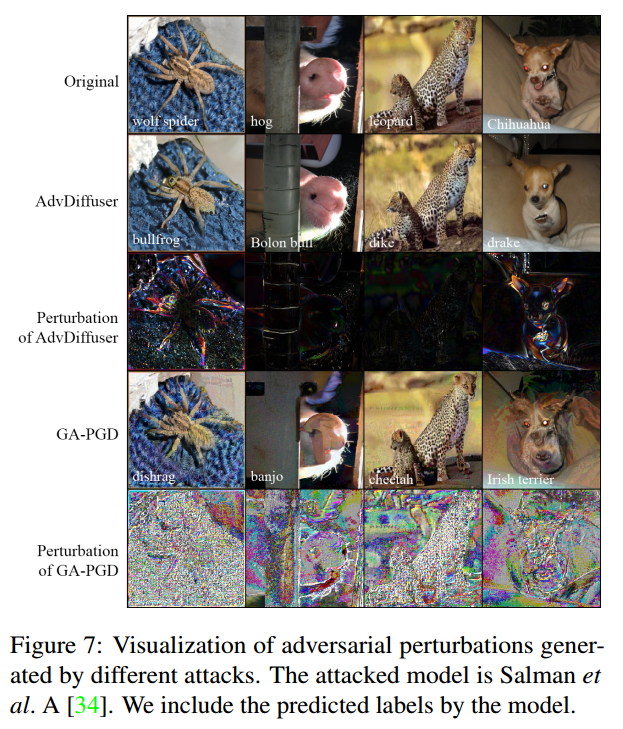
- 在图7中放大并显示了由各自攻击所增加的扰动。研究结果表明,扰动与“形状特定”的变化是一致的,与自然图像分布一致。还证明,即使在明显的扰动下,本文的UAEs也可以保持图像的原始语义内容。这一观察结果验证了将反向去噪过程和对抗引导结合起来产生的扰动更接近于干净图像分布的观点。相反,观察到GA-PGD产生的UAEs具有高频噪声,具有可见的“纹理”偏差,因此可能看起来不太自然。
![]()
- CIFAR-10:如图4所示,本文攻击方法可以生成与原始图像相似但具有不同特征的对抗样本。表2提供了各自模型上的攻击成功率。附录D中进一步比较了DiffPure下的攻击方法,DiffPure是一种利用扩散模型来净化对抗性扰动的防御机制。
- Robustness against Unseen Threat Models
- Rebuffi等人[29]证明扩散模型作为一种数据增强技术可以改善对抗性训练。受他们发现的启发,本文探索了AdvDiffuser动态生成对抗性样本的潜力,用于模型执行对抗性训练。然而,与现有的考虑lp鲁棒性的对抗训练技术不同,本文没有使用对威胁模型的明确假设来训练模型。本文试图使用各种威胁模型来评估不同方法的有效性。这包括常规的l1和l2攻击,JPEG损坏[16]、ReColorAdv[18]、拉格朗日感知攻击(LPA)[19]和空间变换对抗性攻击(StAdv)[44]。在表4中对CIFAR-10进行了一系列实验。请注意,使用传统的l2边界训练的模型对于不可见的威胁模型的攻击并不健壮。与之形成鲜明对比的是,本文所有的防御都获得了针对所有威胁模型的一定程度的鲁棒性。
![]()
- Rebuffi等人[29]证明扩散模型作为一种数据增强技术可以改善对抗性训练。受他们发现的启发,本文探索了AdvDiffuser动态生成对抗性样本的潜力,用于模型执行对抗性训练。然而,与现有的考虑lp鲁棒性的对抗训练技术不同,本文没有使用对威胁模型的明确假设来训练模型。本文试图使用各种威胁模型来评估不同方法的有效性。这包括常规的l1和l2攻击,JPEG损坏[16]、ReColorAdv[18]、拉格朗日感知攻击(LPA)[19]和空间变换对抗性攻击(StAdv)[44]。在表4中对CIFAR-10进行了一系列实验。请注意,使用传统的l2边界训练的模型对于不可见的威胁模型的攻击并不健壮。与之形成鲜明对比的是,本文所有的防御都获得了针对所有威胁模型的一定程度的鲁棒性。
- 实验设置:数据集 --> ImageNet、CIFAR-10、CeleBA 模型 --> 预训练条件DDPM模型 白盒环境
- 💡Experimental Results
- 【内容1】
- Conclusion
- 利用扩散模型,本文引入了一种新的技术,AdvDiffuser,用于合成无限数量的自然对抗样本。在去噪过程中,通过对抗性引导来控制潜在变量,从而实现对噪声的抑制,使扩散模型生成自然而强大的对抗样本。
- 实验结果表明,现有的鲁棒模型无法抵御这些攻击。此外,本文的UAES优于之前的工作,更自然,更不易被发现。样本表现出更小的感知距离,但成功率更高。与lp对抗训练相比,使用AdvDiffuser进行对抗训练表明,模型可以获得对训练过程中未见的威胁模型的鲁棒性。
- 利用扩散模型,本文引入了一种新的技术,AdvDiffuser,用于合成无限数量的自然对抗样本。在去噪过程中,通过对抗性引导来控制潜在变量,从而实现对噪声的抑制,使扩散模型生成自然而强大的对抗样本。
- 附录
- 附录A提供了详细的实验配置。
- 附录B通过灵敏度和消融分析,检查了AdvDiffuser中引入的超参数和组件。
- 附录D给出了DiffPure[25]防御的结果,它使用扩散模型从图像中去除对抗性扰动。
- 附录E中为ImageNet提供了额外的UAEs。
- 附录A提供了详细的实验配置。
- 论文名称 AdvDiffuser: Natural Adversarial Example Synthesis with Diffusion Models


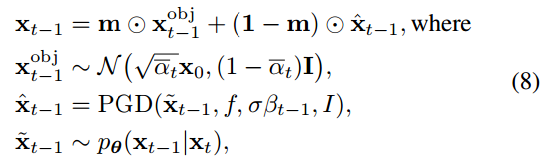







To see I can not see,
to know I do not know.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号