


As a reader --> AutoDiff: combining Auto-encoder and Diffusion model for tabular data synthesizing
- 📌论文分类2:
结合自动编码器和扩散模型的表格数据合成,code is available at https://github.com/UCLA-Trustworthy-AI-Lab/AutoDiffusion- 论文名称 AutoDiff: combining Auto-encoder and Diffusion model for tabular data synthesizing
- 作者 Suh N, Lin X, Hsieh D Y, et al.
- 期刊名称 NeurIPS 2023 SyntheticData4ML workshop
- 简要摘要
在现代机器学习的许多子领域,包括计算机视觉、语言模型或语音合成,扩散模型已经成为合成数据生成的主要范式。本文利用扩散模型的力量来生成合成表格数据。表格数据的异构特征一直是表格数据合成的主要障碍,采用自编码器架构来解决这一问题。与最先进的表格合成器相比,本文模型生成的合成表与真实数据的统计保真度很好,并且在机器学习实用程序的下游任务中表现良好。在15个公开可用的数据集上进行了实验。值得注意的是,本文模型熟练地捕获了特征之间的相关性,这在表格数据合成中一直是一个长期的挑战。
- 关键词
- ✏️论文内容
- 【内容1】
- 💡introduction
合成表格数据的创建对于研究、测试和分析是非常宝贵的,特别是在实际数据稀缺或敏感的情况下。它为学生和专业人员提供了场景探索、算法测试和实际数据分析体验。此外,合成表格数据可作为评估数据处理和预测模型的基准,确保安全的性能评估。它解决了隐私、数据稀缺和可访问性问题,为学术界和工业界的数据驱动研究提供了新的可能性。
考虑到合成表格数据的重要性,许多研究人员已经投入了巨大的努力来构建具有保真度和实用性保证的表格合成器。CTABGAN[24]及其变体[25,26](例如,CTABGAN, CTABGAN+)因使用生成式对抗网络[8](GANs)生成表格数据而受到欢迎。这些模型采用先进的数据编码器,用高斯混合模型(GMM)对连续变量建模,用one-hot编码对离散变量建模。然而,GMM可能不适用于某些现实世界的连续变量,并且one-hot编码可能会增加离散变量的数据维数,这需要大型神经网络。
随着Dalle -2[20]的兴起,扩散模型[23]表现优异,在图像合成[4]、医学成像[17]等多个领域优于生成对抗网络(GAN)[8]模型。最近,基于扩散的表格合成器,如Stasy[11],通过使用min-max scaling和one-hot编码预处理数据显示出前景,在各种任务中优于基于GAN的方法。然而,基于分数的扩散模型[23]最初并不是为异构特征而设计的。
较新的方法,如使用Doob的h-transform[15]、TabDDPM[13]和CoDi[14]的方法,旨在通过组合不同的扩散模型[23,10]或利用对比学习[22]来共同进化模型,以提高异构数据上的性能,从而解决这一挑战。根据这条研究路线,本文提出了一种结合自编码器和扩散模型的新表格数据合成器,称为AutoDiff。
- 💡contribution
介绍表格数据合成的三个挑战,以及AutoDiff模型解决这些问题的主要思想。为了便于理解AutoDiff模型,通常通过与其他最先进(SOTA)模型的简要比较来强调这些思想。
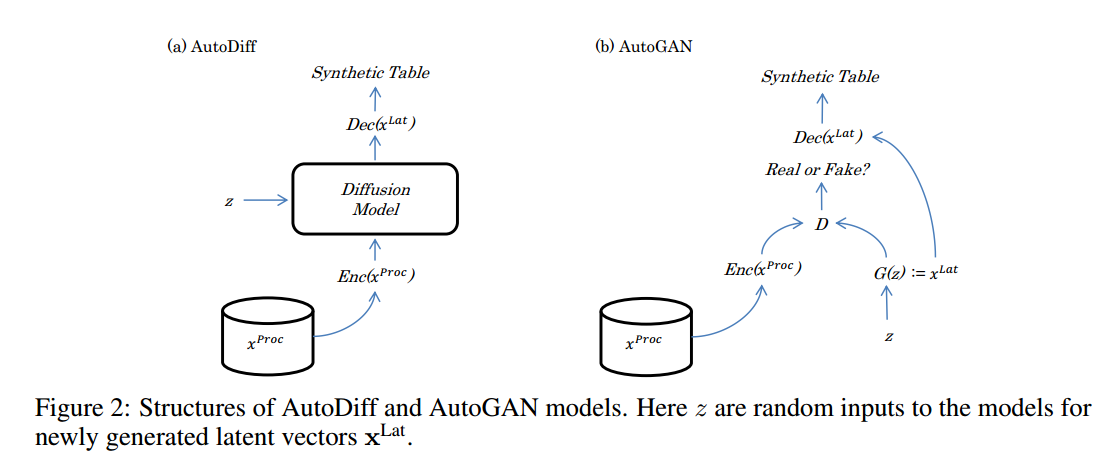
①异构特征是构建表格合成器时最具挑战性的问题,因为现实世界中的表格经常具有数字、离散甚至混合类型的特性。本文通过结合自动编码器和基于分数的扩散模型[23]的想法来解决这一挑战。自编码器是一种神经网络结构,它学习将输入数据编码为潜在表示,并将其重建回原始输入。利用自编码器的能力来学习潜在空间中原始异构特征的“连续表示”。然后,将学习到的表征输入到扩散模型中生成新的潜在表征。经过训练的解码器将新生成的表示转换回原始异构特征的形式。这种思想很好地利用了两种模型的优点,自编码器可以处理异构特征,而扩散模型在学习连续空间上的分布方面表现出了很好的性能。
②混合类型特征是在许多现实世界的表格数据中常见的一种特征,它既有数值成分,也有离散成分。这些特征特别难以捕捉,因为大多数生成模型只关注在数值或离散域上的学习分布。因此,简单地将分别为数值变量和离散变量设计的两种不同的模型结合起来是不清楚的。本文通过创建一个虚拟变量来编码混合类型特征中重复值的频率来解决这个问题。【这个虚拟变量被附加到预处理表中,作为自动编码器的输入,这样自动编码器的潜在表示就包含了关于虚拟变量的信息。通过预训练的解码器对扩散模型生成的新的潜在表征进行解码。解码器的输出既具有混合型特征,又具有相应的虚拟特征。将这两个特征的信息组合在一起作为最终输出。】[25]中引入的混合型编码器与本文的不同之处是,它们直接通过GMM中的one-hot编码和参数对行进行编码。
③特征的相关性是在构建表格合成器时需要捕获的重要统计对象。然而,由于表格数据的异构性,捕获这些相关性比捕获纯数值或离散特征之间的相关性要求更高。AutoDiff通过其扩散模型学习连续空间中潜在表征的联合分布的构造自然地规避了这一挑战。只要AutoDiff中的自动编码器提供了表中行的良好潜在表示,就应该期望AutoDiff能够很好地捕获特征之间的相关性。将本文的想法与基于SOTA扩散的方法TabDDPM进行对比来强调这一贡献,TabDDPM中每个分类变量被认为是独立的(即,它们对每个分类变量使用单独的前向扩散过程),并且分类变量和数值变量也被建模为独立的,因为它们分别对数值变量和离散变量使用两种不同类型的扩散模型。基于GAN的方法(即CTGAN, CTABGAN+)也提出类似的论点,因为它们分别使用GMM来处理数值特征。我们将这些模型与我们的模型在不同的真实世界数据集上进行比较实验,其结果如第3节的表1所示。
④数值比较:对AutoDiff与CTGAN[24]、TVAE[24]、CTABGAN+[26]、Stasy[11]、TabDDPM[13]等模型(具有公开代码)在15个真实数据集上的不同指标进行了数值比较。除了上述模型外,还引入了AutoGAN模型,它是MedGAN的自定义适配[3]。这个包含是专门为比较扩散模型和GAN模型在相同自编码器下的性能而定制的。具体来说,生成表的质量通过(1)统计保真度,(2)下游任务中的机器学习效用,以及(3)通过[25]中最近记录距离(DCR)的隐私保证来衡量。
- 为了展示本文想法的性能,在图1中展示了6个不同模型中混合类型变量的生成数据与实际数据的比较图。
![]()
- 为了展示本文想法的性能,在图1中展示了6个不同模型中混合类型变量的生成数据与实际数据的比较图。
- 💡introduction
- 【内容2】
- 💡method
详细描述模型中的每个组件:介绍输入和合成表格数据的预处理和后处理步骤;给出自编码器和扩散模型的构造
- Pre- and post-processing steps.
- 对真实的表格数据进行预处理,使机器学习模型能够正确地从数据中提取所需的信息,这是至关重要的。将异构特征分为三类:(1)数值特征,(2)离散特征,(3)混合特征。
1. 数值特征:如果x的项是实值连续的,则将x归类为数值特征。此外,如果条目是超过25个不同值的整数,例如,“成人收入数据集中的年龄”,则x被归类为数值特征(25是用户指定的阈值)。使用scikit-learn库[19]中的最小-最大标量或高斯分位数变换来预处理数值特征。此后,将x进程编号表示为已处理的列。
2. 离散特征:如果x的条目具有字符串数据类型,则将x归类为离散特征,例如“性别”。此外,小于25个不同整数的x被归类为离散特征。对于预处理,简单地将x的项映射为大于等于0的整数,并进一步将数据类型分为两部分:二值和多分类,表示为x_Bin和x_Cat。
3. 混合类型特征:假设x被归类为数值特征,如果x中的某些值重复超过整个数据点的h个百分比,则将x视为混合类型特征(h是用户指定的参数,本文将其设置为1)。编码混合类型变量的想法是创建另一个离散特征变量y,它编码x中条目的标签。将重复次数少于h %的条目标记为0。对于重复次数超过h%的条目,按照重复频率的顺序用从1到K的整数标记它们。这里,K是重复次数超过整个数据点的h%的条目的总数。
4. 后处理步骤:AutoDiff模型生成合成数据集后,必须将其恢复到原始格式。对于数值特征,这是通过逆变换实现的,例如反转最小-最大缩放或使用逆法向变换。
离散特征中的整数标签被映射回其原始分类值或字符串值。对于混合型特征,将y^syn表示为第3项生成的虚拟变量y的AutoDiff模型中新合成的列。将x^syn和y^syn的信息合并,如果y^syn中对应的标签为0,则x^syn中的条目保持原样。如果y^syn中的标签是大于0的整数值,那么x^syn中的相应条目将被替换为用于编码y的重复值。
- 对真实的表格数据进行预处理,使机器学习模型能够正确地从数据中提取所需的信息,这是至关重要的。将异构特征分为三类:(1)数值特征,(2)离散特征,(3)混合特征。
- Auto-encoder.
- 预处理后的输入数据x被送入自动编码器,即AE, AE学习输入数据的潜在表示。AE的网络结构简单地由具有ReLU激活函数的多层感知器块组成。
- 预处理后的输入数据x被送入自动编码器,即AE, AE学习输入数据的潜在表示。AE的网络结构简单地由具有ReLU激活函数的多层感知器块组成。
- Stasy- & Tab-AutoDiff.
- 基于分数的扩散模型[23]被用于生成新的x^Lat的潜在表征。。在这项工作中,使用方差保存(VP)-SDE进行数据扰动,并使用Euler-Maruyama方法[23]对实验进行抽样。本文设计了两种类型的AutoDiff模型:Stasy-AutoDiff和Tab-AutoDiff,分别采用了与Stasy[11]相同的时间依赖评分网络和TabDDPM[13]);min-max scaler 和 高斯分位数变换用于预处理数值变量。采用相同的分数网络的原因是为了便于比较Stasy-AutoDiff (resp. Tab-AutoDiff,和Stasy(resp. TabDDPM)之间的性能。(本工作采用无微调步骤的Stasy näive形式)。AutoDiff的整体流程如图2所示。
![]()
- 基于分数的扩散模型[23]被用于生成新的x^Lat的潜在表征。。在这项工作中,使用方差保存(VP)-SDE进行数据扰动,并使用Euler-Maruyama方法[23]对实验进行抽样。本文设计了两种类型的AutoDiff模型:Stasy-AutoDiff和Tab-AutoDiff,分别采用了与Stasy[11]相同的时间依赖评分网络和TabDDPM[13]);min-max scaler 和 高斯分位数变换用于预处理数值变量。采用相同的分数网络的原因是为了便于比较Stasy-AutoDiff (resp. Tab-AutoDiff,和Stasy(resp. TabDDPM)之间的性能。(本工作采用无微调步骤的Stasy näive形式)。AutoDiff的整体流程如图2所示。
- Med-AutoDiff & AutoGAN.
- MedGAN[3]在某种意义上与AutoDiff具有非常相似的结构,它们使用了将自编码器和GAN模型相结合的思想。该模型仅适用于具有离散变量的数据集。值得注意的是,他们使用MSE作为分类变量,而不是本文中的CE损失。在此设置之后,修改了损失(3),并将训练好的模型称为Med-AutoDiff。
- 此外,还设计了适用于异构特征的AutoGAN模型。利用了上文提到的自编码器,并在MedGAN[3]中引入的GAN模型中使用了相同的生成器和鉴别器。具体来说,对鉴别器使用了小批量平均,对生成器使用了批量归一化和跳跃式连接。AutoGAN和MedGAN最显著的区别在于discriminator的参数:在AutoGAN中,discriminator区分真实和虚假的潜在向量;而在MedGAN中,它区分真实和虚假的解码潜在向量,并在训练discriminator的同时对解码器进行微调。选择在解码器中固定参数,以便与Med-AutoDiff进行公平的比较。还要注意,在AutoGAN中使用了相同的自编码器Med-AutoDiff损失。
- MedGAN[3]在某种意义上与AutoDiff具有非常相似的结构,它们使用了将自编码器和GAN模型相结合的思想。该模型仅适用于具有离散变量的数据集。值得注意的是,他们使用MSE作为分类变量,而不是本文中的CE损失。在此设置之后,修改了损失(3),并将训练好的模型称为Med-AutoDiff。
- 💡method
- 【内容3】
- 💡experiment
- 数据集:收集了15个不同的真实数据集,对AutoDiff模型进行了定量对比实验。这些数据集通常用于测试最近的表格数据合成器的性能。在所有6个模型中,为15个数据集中的每一个生成10个合成表。
- 结果比较
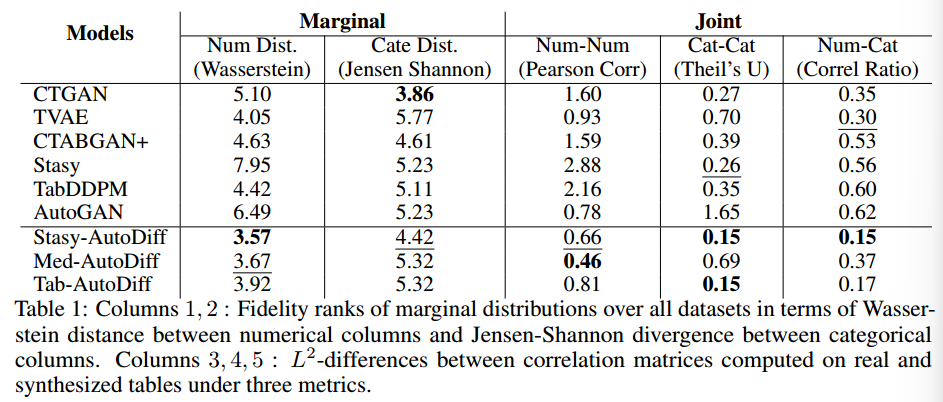
- 合成表的保真度:是指生成的表保留原始数据集的统计属性的程度。受[25,13]的启发,使用一系列指标评估真实(R)和合成(S)表之间的边缘和联合特征分布的相似性。具体来说,对于数值特征,使用Wasserstein距离(WD)来量化R和s之间的差异;对于分类特征,使用Jensen-Shannon散度(JS)来衡量它们分布中的相似性。
- 此外,根据特征类型使用各种方法评估联合分布质量。这包括使用数值-数值特征关系的Pearson相关系数,用于评估分类-分类特征之间依赖性的Theil 's U统计量,以及分类-数值特征关联的相关比率。
- 表1中的前两列记录了在进行评估的所有150个数据集中,应用于R和S之间列的各自不相似性度量的模型的平均排名。表1中的后三列记录了每个模型的150个合成表中R和S之间计算的相关矩阵的平均l2距离。
![]()
- 结果表明,对于所有5个指标,三个AutoDiff模型要么显示最好的结果(粗体),要么显示第二好的结果(下划线)。与CTGAN相比,AutoDiff对数值特征的恢复相当好,但对分类特征的恢复表现相对较差。在WD度量上的良好表现是由于自编码器的复杂设计,特别是混合类型的特征,以及扩散模型学习连续变量的能力的结合。将结果与Stasy和TabDDPM进行比较,甚至可以看出自编码器的作用。回想一下,Stasy和TabDDPM中使用了Stasy- Autodiff和Tab-AutoDiff完全相同的扩散模型。
- 相关性度量:三个AutoDiff模型显示了表1中所示的三个度量的最佳性能。因为AutoDiff中的扩散模型旨在捕获x^Lat的联合分布,而其他模型则针对不同的数据类型使用不同的模型。Stasy在捕捉分类变量之间的相关性方面表现得很好,而TVAE擅长捕捉Num-Cat相关性。总体而言,AutoDiff在所有5个指标的保真度测量中都优于AutoGAN模型。
- 表1中的前两列记录了在进行评估的所有150个数据集中,应用于R和S之间列的各自不相似性度量的模型的平均排名。表1中的后三列记录了每个模型的150个合成表中R和S之间计算的相关矩阵的平均l2距离。
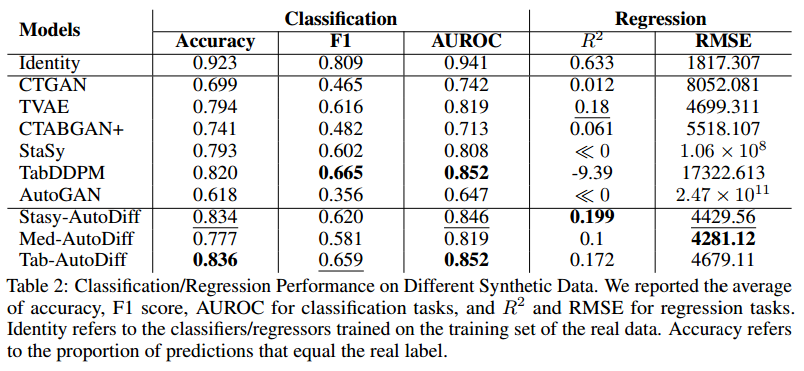
- 评估AutoDiff在保留合成数据的机器学习效用方面的功效,遵循了合成训练和真实测试(TSTR)[7]管道。
- 对于每个真实数据集,以80%/20%的比例将其分成训练/测试集。然后拟合两个预测模型,一个在真实数据的训练集上,另一个在相应的合成表上。最后在实际数据的测试集上对两种模型的性能进行了测试。对于分类任务,使用Naïve贝叶斯,k近邻,决策树,随机森林,XGBoost, LightGBM和CatBoost。对于回归任务,使用线性回归,套索回归,决策树,随机森林。
![]()
- 表2显示了所有数据集的平均总体性能指标,报告了在各种合成器生成的合成表上训练的分类器和回归器的性能。值得注意的是,AutoDiff始终优于GAN和基于自动编码器的方法,如CTGAN、CTABGAN+、AutoGAN和TVAE。与其他基于扩散的方法相比,AutoDiff表现出优越的性能;它明显优于原始的Stasy方法,后者不使用基于自动编码器的编码。虽然AutoDiff对基于ddpm的模型(TabDDPM)的改进在分类任务中是相当的,但对于回归任务来说,它的改进更为明显,这可以从显著较高的R2值和较低的RMSE分数中得到证明。有趣的是,当在所有三个指标上比较Stasy- Autodiffs和Tab-Autodiffs时,注意到TabDDPM的高斯分位数变换和分数网络结构的使用提高了分类任务的性能。
- 对于每个真实数据集,以80%/20%的比例将其分成训练/测试集。然后拟合两个预测模型,一个在真实数据的训练集上,另一个在相应的合成表上。最后在实际数据的测试集上对两种模型的性能进行了测试。对于分类任务,使用Naïve贝叶斯,k近邻,决策树,随机森林,XGBoost, LightGBM和CatBoost。对于回归任务,使用线性回归,套索回归,决策树,随机森林。
- 隐私是合成表格数据生成中的一个重要问题,本文简单地通过[25]中到最近记录的距离(DCR)来测量它。对于每个合成样本,DCR计算到真实记录的最小l2距离,Mean DCR计算所有合成样本的这些距离的平均值。
- 从本质上讲,低DCR表明合成样本记住了真实表中的一些数据点,违反了一些隐私限制。相反,高DCR值表示合成器产生了一些新的数据点,这些数据点在实数表中无法观察到。但请注意,一些随机噪声可能具有高DCR值。因此,DCR应同时考虑保真度和实用性。表3给出了9个模型的Mean-DCR (MDCR)的平均排名。
![]()
- 排名越高,说明模型的MDCR值越低。采用排名的原因是由于每个数据集的MDCR有很大的可变性。由于精心设计的自编码器经常过拟合输入数据,并结合扩散模型的记忆问题[2],这一结果是意料之中的。观察到的总体排名MDCR类似于表1中数值变量的保真度,并且强烈推测TabDPPM在MDCR测量中相对于AutoDiff的良好性能归因于它没有捕获特征之间的相关结构,但对单个特征显示出良好的保真度。
- 从本质上讲,低DCR表明合成样本记住了真实表中的一些数据点,违反了一些隐私限制。相反,高DCR值表示合成器产生了一些新的数据点,这些数据点在实数表中无法观察到。但请注意,一些随机噪声可能具有高DCR值。因此,DCR应同时考虑保真度和实用性。表3给出了9个模型的Mean-DCR (MDCR)的平均排名。
- 合成表的保真度:是指生成的表保留原始数据集的统计属性的程度。受[25,13]的启发,使用一系列指标评估真实(R)和合成(S)表之间的边缘和联合特征分布的相似性。具体来说,对于数值特征,使用Wasserstein距离(WD)来量化R和s之间的差异;对于分类特征,使用Jensen-Shannon散度(JS)来衡量它们分布中的相似性。
- 💡experiment
- 【内容1】
- 未来工作
- 通过良好的统计保真度和合成表格数据的实用性来确保隐私保障是应该解决的最基本的问题之一。在严格的差分隐私(DP)框架下[6],进一步扩展满足DP约束的AutoDiff模型的现有形式是未来工作最有希望的方向[5,16]。
- 通过良好的统计保真度和合成表格数据的实用性来确保隐私保障是应该解决的最基本的问题之一。在严格的差分隐私(DP)框架下[6],进一步扩展满足DP约束的AutoDiff模型的现有形式是未来工作最有希望的方向[5,16]。
- 附录
- Real Tabular-data List
- Score-based diffusion model
- Correlation Plots of Abalone
这部分提供了Stasy-AutoDiff和TabDDPM合成表的鲍鱼数据集的相关图。图3和图4顶部的热图显示了真实数据集和合成数据集的相关性图的差异。
- DCR values for each dataset
这部分为每个数据集提供了10个合成数据集的平均值-DCR值。最小的(加粗),排在倒数第二的(下划线),这意味着合成数据集接近真实。
- Real Tabular-data List
- 论文名称 AutoDiff: combining Auto-encoder and Diffusion model for tabular data synthesizing


To see I can not see,
to know I do not know.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号