


As a reader --> NetDiffus: Network Traffic Generation by Diffusion Models through Time-Series Imaging
- 📌论文分类Ⅲ:
- 论文名称 NetDiffus: Network Traffic Generation by Diffusion Models through Time-Series Imaging
- 作者 Sivaroopan N, Bandara D, Madarasingha C, et al.
- 期刊名称 arXiv preprint arXiv:2310.04429, 2023.
- 简要摘要
网络数据分析现在几乎是所有网络解决方案的核心。尽管如此,由于现代网络的复杂性、商业敏感性、隐私和监管限制等诸多原因,对网络数据的有限访问一直是一个持久的挑战。这项工作探索如何利用扩散模型(DM)的最新进展来生成合成的网络流量数据。开发了一个端到端框架——NetDiffus,它首先将一维时间序列网络流量转换为二维图像,然后为原始数据合成具有代表性的图像。实验证明,NetDiffus优于基于GAN的最先进的流量生成方法,生成数据的保真度提高了66.4%,下游机器学习任务的保真度提高了18.1%。在七种不同的流量轨迹上评估了NetDiffus,并表明利用合成数据显著改善了流量指纹、异常检测和流量分类的效果。
- 关键词
- ✏️论文内容
为了克服流量数据的现有问题,合成数据生成已成为一种有希望的替代方案。虽然有许多用于数据包生成的技术和工具,如NS3[21]和iPerf[17],以满足给定的模型或分布,但它们无法模拟真实轨迹的复杂性。
基于ML的方法能够从痕迹中学习以克服这一限制[18,20,25,38,40]。其中,基于生成模型的解决方案,如DoppleGanger[20]、NetShare[40]和CTGAN[38],在表示实际网络约束和问题方面表现出了优异的性能。然而,作为许多最先进(SOTA)网络流量生成工具基础的GAN存在模式崩溃、梯度消失和不稳定性,除非超参数选择得当[8]。
这项工作探索了如何利用扩散模型(DM)架构的最新进展来生成合成网络流量。与生成模型(如GAN)相比,DM表现出了出色的性能,特别是与如Dall-E模型的受控图像生成相比[22]。控制生成输出的能力使DM非常适合用于训练ML模型的合成数据生成,因为它允许生成平衡的数据集。这将导致生成更健壮和准确的训练模型。然而,还没有对DM产生网络流量进行研究。据我们所知,这是利用扩散模型生成网络数据的第一次尝试。
- 本文提出NetDiffus,这是一个使用DM利用时间序列成像来实现高保真合成数据的网络流量生成框架。首先,我们将1D网络轨迹转换为一种称为Grammian Angular sum Field (GASF)的特定图像格式[37],以捕获1D网络轨迹的重要特征。GASF图像可以编码诸如数据包大小、包间时间等特征,最重要的是将1D时间序列样本之间的相关性编码到2D空间的图像上,使其成为ML模型的丰富信息源。第二,减少计算量,改进特征学习过程,在GASF图像上应用了一些简单的图像处理技术,如对比度调整和图像大小调整。最后,这些增强的数据用于训练DM,来自训练模型的合成数据用于改进各种下游ML任务。
- 这项工作的目标是生成2D GASF格式的网络流量特征,无论是原始的(例如,数据包大小)还是预处理的(例如,一组数据包下载的字节数[3]),并将其直接用于改进下游ML任务[12,31,36,37]。请注意,与最近的工作不同[20,40],NetDiffus在此阶段不生成元数据。
- 利用广泛的网络流量数据:视频、网络和物联网,实验结果表明标准DM可以生成比基线更高保真度的数据。例如,与基于SOTA GAN的模型DoppelGanger[20]和NetShare[40]相比,NetDiffus的保真度分别提高了28.0%和85.6%。此外,利用这些合成数据来训练与不同网络相关任务相关的ML模型,例如流量指纹、异常检测和数据有限场景下的分类。即使不与原始数据结合,NetDiffus在这些任务中也可以达到与原始数据几乎相同的精度或提高1-57%的精度。与上述基线相比,NetDiffus合成数据在相应的ML任务中可以提高4.7-32.3%的分类性能。
- 【内容1】
- 💡related work
合成网络流量生成:在数据生成领域已经做了大量的工作[7,13,18,20,40]。
马尔可夫模型和递归神经网络通常用于先前的网络流量生成模型[20,25]。尽管它们提供了泛化性能,但它们在特定领域生成任务中的保真度仍然有限。在最近的工作中,基于生成对抗网络(GAN)的模型已经彻底改变了网络流量合成,提供了强大的功能。GAN中使用的生成器和鉴别器架构可以有效地提取网络轨迹特征,并进一步修改以保持时间属性[13,18,20,38,40]。尽管GAN前景光明,但仍存在模式崩溃、训练不稳定和不灵活等主要问题[8,20]。
成像时间序列数据:将一维数据转换为二维图像在许多著作中得到了广泛的研究[11,27,33,34,37]。
这种转换的一个动机是在下游分析任务中性能的提高,特别是在基于ML的分类中[37]。此外,这种图像表示具有丰富的ML任务信息[34]。文献[37]的作者利用格拉曼矩阵和马尔可夫跃迁场(MTF),将一维数据转换为特定的图像格式,称为格拉曼角和场(GASF)和格拉曼角差场(GADF)。这些数据格式是格拉曼角场(GAF)的导数,通过将时间序列转换为极坐标系并映射一维样本之间的相关性而生成。
DM及其在数据生成中的前景:DM属于基于似然的方法,在训练中具有更大的分布覆盖率、可扩展性和稳定性,是GAN模型中模式崩溃、不稳定性和灵活性较差等问题的解决方案[8,15,26]。在前向传递中,DM逐渐在输入图像中加入高斯噪声,直到其成为纯噪声。然后训练DNN模型对图像进行去噪,恢复原始图像。这个训练好的深度神经网络作为一个生成模型,从纯噪声分布中产生图像。最近的许多工作已经在图像、音频、文本到图像和图像到文本生成等任务中使用了DM,但尚未在各种网络流量类型的网络流量生成中使用[6 - 8,42]。
- 与之前的工作不同,本文演示了如何通过将时间序列分布转换为2D GASF图像来使用DM生成网络流量。这些图像准确地捕获特征分布,包括1D样本点之间的相关性,进一步支持下游ML任务。
- 💡related work
- 【内容2】
- 💡NETDIFFUS实现
- 1.Capturing important feature attributes 重要特征属性捕获
![]()
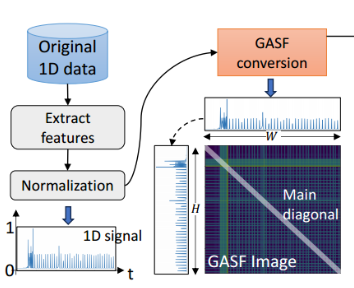
- dnn可以学习输入数据的隐藏特征。然而,识别样本之间的相关性、一维信号或时间序列中的频率相关模式等细微特征需要复杂的模型和严格的训练过程。在模型训练之前手动提取这些特征是非常重要的,因为它可以使模型有效地学习这些特征并提高数据保真度。为了实现这一点,在NetDiffus中,按照[37]中的方法将1D信号转换为2D图像格式GASF。GASF图像将振幅、包间间隙和时间相关性等特征映射到一个二维空间上。
给定网络特征的一维信号(例如,bytes dl(downloaded)),首先将其转换为极坐标,然后创建相应的Grammian矩阵。这里,Grammian矩阵的元素表示极坐标系统中时间序列样本的余弦角之间的内积,这是GAF的基础。通过取内积,矩阵进一步表示一维轨迹中采样点之间的关联图[37]。然后,通过对行和列方向上的所有元素对求和来创建GASF图像,以消除对GAF数据中半径的依赖。附录A进一步解释了GASF转换。图1b为GASF图像样本。宽度(𝑊)和高度(𝐻)等于轨迹长度。图像的主对角线对应于时间序列信号,包含编码的特征幅度、包间间隙等。
- dnn可以学习输入数据的隐藏特征。然而,识别样本之间的相关性、一维信号或时间序列中的频率相关模式等细微特征需要复杂的模型和严格的训练过程。在模型训练之前手动提取这些特征是非常重要的,因为它可以使模型有效地学习这些特征并提高数据保真度。为了实现这一点,在NetDiffus中,按照[37]中的方法将1D信号转换为2D图像格式GASF。GASF图像将振幅、包间间隙和时间相关性等特征映射到一个二维空间上。
- 2.Highlighting hidden features 突出显示隐藏特征
![]()
- 二维域中操作时,增强GASF图像的对比度可以进一步突出DM可以有效学习的细微特征变化,并提高保真度。
根据公式对原始GASF图像进行标准伽玛校正,𝐼𝑐= A∗𝐼𝑟^γ,其中𝐼𝑟,𝐼𝑐,A和γ分别是伽玛校正图像,原始图像,常数和伽玛变量。经验地设置了γ = 0.25,A= 1。图1a显示了样本原始图像和伽玛校正图像的直方图分布。注意到,该过程将像素值分离到不同的范围,增加了图像对比度并强调了特征变化。
- 二维域中操作时,增强GASF图像的对比度可以进一步突出DM可以有效学习的细微特征变化,并提高保真度。
- 3.Supporting fast and stable training 支持快速稳定训练
- DM通常需要很高的计算能力和时间。因此,保持GASF图像大小与跟踪长度相似可能会导致更长的训练时间和资源不足。作为一种解决方案,将图像大小调整为固定的较小分辨率,并为DM训练提供低分辨率图像。
将OpenCV.resize()方法与INTER_AREA插值方法结合使用,INTER_AREA插值方法基于面积关系对图像像素进行重新采样,是图像抽取的首选方法[23]。根据经验决定图像大小,而不影响下游ML性能,因为图像大小调整可能会从图像中删除高频信息。此外,将GASF像素范围最大归一化为[0,1],将每个像素除以全局最大值255。这使得DM的训练过程更快、更稳定。实现过程利用Python-numpy中的矢量化操作来加速这些像素级操作。
- DM通常需要很高的计算能力和时间。因此,保持GASF图像大小与跟踪长度相似可能会导致更长的训练时间和资源不足。作为一种解决方案,将图像大小调整为固定的较小分辨率,并为DM训练提供低分辨率图像。
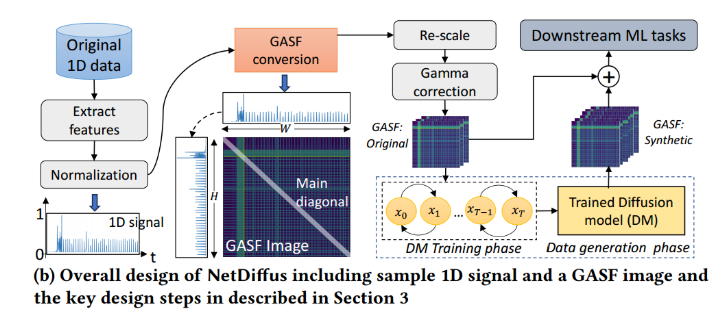
- 4.Overall design of NetDiffus “NetDiffus”的总体设计
![]()
- 从相关数据集的时间序列特征提取和最大归一化开始。然后,将一维信号转换为GASF图像,通过伽马变换和调整图像大小进一步增强GASF图像。最后,使用这些原始GASF图像来训练DM。
除非另有说明,否则从每个数据集中,使用前80%的数据用于合成数据生成,并将剩余的数据作为下游ML任务的测试数据集。将扩散步骤设置为1000,并将标准的U-Net模型设置为5层,用于去噪过程。合成的GASF图像结合原始GASF数据用于改进各种下游ML任务。后续将发布所有的模型细节与组件。
- 观察到一个基本的DM架构足以生成高保真的GASF图像。实验没有从GASF图像中构建相应的1D轨迹进行下游分析,一方面,对于各种基于ML的分析,2D图像是一种合适的格式[12,31,36,37]。另一方面,观察到2D GASF数据与1D数据相比,ML分类性能有所提高。然而,1D轨迹的重建可以通过应用公式轻松完成!
- 从相关数据集的时间序列特征提取和最大归一化开始。然后,将一维信号转换为GASF图像,通过伽马变换和调整图像大小进一步增强GASF图像。最后,使用这些原始GASF图像来训练DM。
- 💡NETDIFFUS实现
- 【内容3】
- 💡evalution & results
- dataset:收集了两个主要数据集(D1)和(D3),并选择了一个公开可用的数据集(D2)来解决网络中存在的各种情况。
D1流媒体视频:从YouTube (YT), Stan和Netflix上选择视频,各20个,时长为3分钟,并对每个视频进行多次流,产生100条痕迹。在流式传输时,被动捕获网络数据包,将其分成不重叠的0.25 s的bin,提取每个bin中的Total bytes dl特征。分帧可以突出网络轨迹中不同的视频特定特征(例如,质量交换),并提高下游ML任务的性能。预期的ML任务是将给定的痕迹指纹归类到来自给定平台的20个视频之一中。
D2访问网页:从[32]中选择了公开可用的网页冲浪数据集,该数据集有20个网站。提取的特征包括数据包方向(即uplink(+1)和downlink(-1)数据包),包间间隙。每个轨迹有5000个固定数量的样本。轨迹超过5000个样本,它被截断,否则填充0到5000个样本。每个流量轨迹被归类为20个类(即网站)中的一个,作为网站指纹任务。
D3物联网智能家居设备产生的流量:通过被动监控两种智能家居辅助设备Google home[14]和Amazon alexa[1]的网络流量来收集该数据集。用户为每个设备提供10个不同的命令,设备与云服务器通信以执行相关活动。通过重复每个命令,收集了1000条轨迹,并且每个轨迹保持在300数据包长度,遵循D2中相同的轨迹截断和0填充方法。捕获的特征包括数据包大小、方向和包间间隙。ML任务是将每个轨迹分类为一个活动。- 选择的数据集包含广泛的特征,例如从原始数据包大小到汇总的总字节dl值,这些数据集可以用于广泛的ML任务。这进一步验证了NetDiffus对不同网络相关特征生成的鲁棒性,以及基于GASF的合成数据对下游任务的有效性。
- 如何利用数据进行机器学习训练,有三种主要场景:I) original:只使用原始数据;ii) synth:只使用合成数据;iii) ori+synth:将原始数据与合成数据结合。
除非另有说明,否则将来自每个数据集的每个类的数据(即网络流量轨迹)分为80%-20%的训练测试分割,用于训练和测试数据生成中的DM和下游任务中的ML模型。
- 选择的数据集包含广泛的特征,例如从原始数据包大小到汇总的总字节dl值,这些数据集可以用于广泛的ML任务。这进一步验证了NetDiffus对不同网络相关特征生成的鲁棒性,以及基于GASF的合成数据对下游任务的有效性。
- benchmark models:DoppelGanger(DG)[20], NetShare[40]. DG和NetShare的表现优于许多其他基于机器学习和统计方法[4,10,39,41],因此,将其他GAN方法和基于机器学习的方法排除在比较之外。由于两个模型合成的为1D数据,在比较之前需要将模型的1D合成轨迹转换为GASF图像。
DoppelGanger (DG)[20]:一种基于GAN的方法,它可以生成元数据和轨迹的流量特征,同时找到它们之间的相关性。本文使用他们的一个数据集,维基百科网络流量(WW)来训练NetDiffus,首先,将DG与NetDiffus进行比较,同时保留其原始属性,其次,展示NetDiffus对不同数据集的鲁棒性。
NetShare[40]:基于SOTA GAN的包/流报头生成方法,与表格格式相比,将其作为时间序列数据。虽然考虑的基本模型是DG,但作者声称,通过提出的包/流数据EPOCHS合并机制,生成的可扩展性得到了提高,合成数据的保真度得到了提高。使用D3-Google和D3-Alexa数据集训练Netshare,因为这些数据集与Netshare中的数据包级数据生成是兼容的。
- analysis:
- ①data fidelity 数据保真度
![]()
- 使用度量FID (Frechet Inception Distance)[5]来评估合成轨迹的保真度(较低的FID分数意味着原始图像和合成图像具有接近的分布)。虽然没有对GASF转换后1D域的NetDiffus保真度进行评估,但2D GASF格式的高保真度也表明了1D域的高保真度。
- 使用度量FID (Frechet Inception Distance)[5]来评估合成轨迹的保真度(较低的FID分数意味着原始图像和合成图像具有接近的分布)。虽然没有对GASF转换后1D域的NetDiffus保真度进行评估,但2D GASF格式的高保真度也表明了1D域的高保真度。
- ②Performance in downstream ML models 下游ML模型中的性能表现
![]()
- 在所有ML模型中,NetDiffus的准确率都超过了DG,平均为4.67%。对于D3-Google和D3-Alexa数据集,NetDiffus的平均性能分别优于Netshare 32.3%和17.3%。这些结果表明NetDiffus可以优于许多SOTA数据生成模型。
- 进一步表明NetDiffus合成数据也可以用于评估不同的下游ML算法。在使用合成数据来调整负载平衡、集群调度等模型时,这一点非常重要[20]。要实现这一目标,合成数据的一个关键特性是,在不同算法下,合成数据应具有与原始数据相似的精度趋势。【对这一部分的解释保持怀疑?】
除了图3b-底部的D3-Alexa-MLP评估外,NetDiffus合成数据在所有其他情况下都遵循与其原始数据相似的精度模式。例如,在图3a中,CNN、XGBoost和MLP在原始数据和NetDiffus数据上都显示出更高的分类精度,而在NB上两个数据集都显示出较低的分类精度。
- 在所有ML模型中,NetDiffus的准确率都超过了DG,平均为4.67%。对于D3-Google和D3-Alexa数据集,NetDiffus的平均性能分别优于Netshare 32.3%和17.3%。这些结果表明NetDiffus可以优于许多SOTA数据生成模型。
- ③Improved ML performance in use-cases 改进用例中的ML性能
- ML在网络流量监控中得到了广泛的应用,但由于训练数据的不足,其性能有限。
- 第一个用例分析了NetDiffus合成数据如何优化流量指纹任务。
![]()
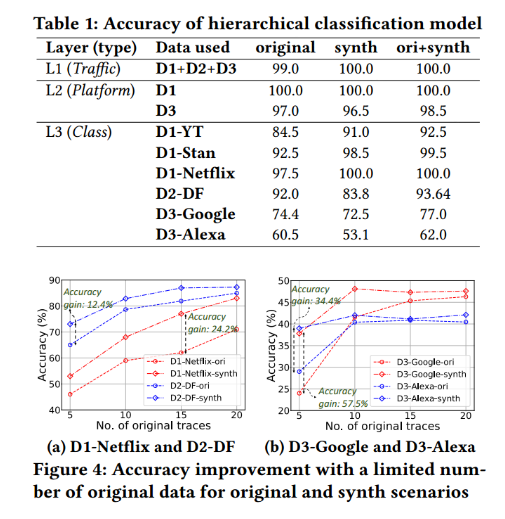
利用三种分类类型下的分层ML分类器:L1:流量类型(例如,视频,网络或物联网),L2:平台类型(例如,YT, Stan)和L3:个人类(例如,个人视频,网站)。
table1 报告了分类准确率。观察到在原始和合成数据场景中,L1和L2都提供了95%以上的准确性。与L1和L2相比,L3是一项具有挑战性的任务,因为类的数量更多,并且类之间的轨迹相似。在D1视频指纹任务中,由于合成数据的高保真度,可以看到合成场景中D2和D3的准确率比原始数据平均下降了5.83%,但参考最近的文献[20,40]并考虑到任务的难度,认为这样的准确率水平仍然是可以接受的。而通过将原始数据与合成数据相结合,实现了比原始场景提高1-8%的精度。
有限数量的原始轨迹是一个具有挑战性的场景,它阻碍了上述ML性能。为了看到NetDiffus对提高下游ML精度的支持,改变了NetDiffus数据生成的原始轨迹数量,并添加了生成的合成轨迹来训练ML模型。从图4可以看出,在原始轨迹数量有限的情况下,NetDiffus合成轨迹可以超过原始数据的精度。在图4a中,D2-DF synth与原始场景相比,精度提高了12.4%,在图4b中,D3-Google synth与原始场景相比,精度提高了57.5%。这与表1中synth场景中较低的性能形成对比,并突出了NetDiffus在数据有限的用例中的优势。
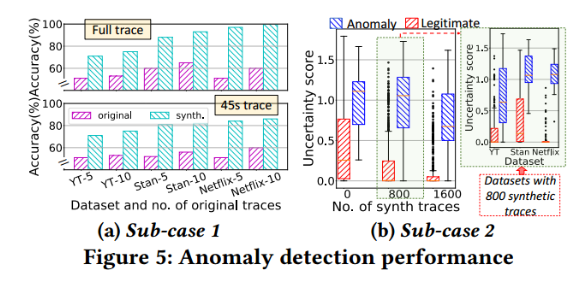
- 第二个用例分析异常检测,通常难以收集足够的恶意数据来训练模型。
![]()
在L3分类任务中扩展D1视频指纹,同时在训练ML模型时模拟真实世界的异常检测,创建类不平衡环境。假设随机选择的两个类具有有限数量的轨迹是异常的,而另一个包含所有可用训练轨迹的五个类是合法的。
i)子案例1:合法类和异常类均可获得真实数据。在这种情况下,简单地计算异常轨迹分类的精度。为了模拟较短的持续时间并进一步推广异常行为,将轨迹长度从180秒(完整轨迹)限制为前45秒。
ii)子案例2:基础真值标签仅对合法类可用。在测试阶段,采用深度集成方法,基于分类结果的熵来衡量分类的不确定性[29]。对于正常轨迹和异常轨迹,预期的不确定性分别较低和较高。
与仅使用原始数据相比,添加合成轨迹分别提供54.6(±18.3)%和48.5(±9.0)%的平均增益;合成轨迹减少了合法样本预测的不确定性(例如,1600个合成轨迹的平均不确定性为0.75),然而,异常样本的不确定性仍然很高。这个较高的不确定性分数是决定给定轨迹是否为异常的指示[29]。
- 第三个用例分析了NetDiffus对近实时分类的支持,表示只提取部分网络轨迹而不等待整个轨迹的场景。
![]()
假设可以识别出网络轨迹的起始点。对应的GASF图像是通过从代表有限数据的1D轨迹的底部和右侧方向裁剪初始GASF图像来生成的。使用L3分类,为不同的轨迹长度(D1的轨迹长度、D2和D3的数据包百分比)训练了不同的分类器。
图6(a)显示,D1数据在只有45s数据的情况下,在ori+synth场景下可以达到92%以上的精度,比原始精度提高了5.7%。
在图6(b)和图6(c)的D2和D3数据中,虽然synth精度低于原始场景,但ori+synth精度始终优于原始场景。
另一方面,synth精度在original和ori+synth中都遵循相同的增长趋势,最终与original的精度差距减小,如D2。
根据经验,GASF转换需要毫秒范围内的时间(即大约10毫秒),而不会影响整个推理过程。
- ML在网络流量监控中得到了广泛的应用,但由于训练数据的不足,其性能有限。
- ④Comparison with 1D DM 与1D DM的比较
- 结果表明,NetDiffus中的二维DM比其一维DM性能更好。
- 结果表明,NetDiffus中的二维DM比其一维DM性能更好。
- ①data fidelity 数据保真度
- 💡evalution & results
- 本文提出NetDiffus,这是一个使用DM利用时间序列成像来实现高保真合成数据的网络流量生成框架。首先,我们将1D网络轨迹转换为一种称为Grammian Angular sum Field (GASF)的特定图像格式[37],以捕获1D网络轨迹的重要特征。GASF图像可以编码诸如数据包大小、包间时间等特征,最重要的是将1D时间序列样本之间的相关性编码到2D空间的图像上,使其成为ML模型的丰富信息源。第二,减少计算量,改进特征学习过程,在GASF图像上应用了一些简单的图像处理技术,如对比度调整和图像大小调整。最后,这些增强的数据用于训练DM,来自训练模型的合成数据用于改进各种下游ML任务。
- 总结
- 提出NetDiffus,一个基于扩散模型(DM)的网络流量生成工具。它将时间序列网络流量数据转换为称为Grammian Angular Summation Field (GASF)的特定图像格式。在解决与合成网络流量生成相关的多个挑战以实现更高的数据保真度的同时,还展示了GASF格式的合成数据在各种下游ML任务中的有效性,以提高其分类性能。此外,NetDiffus的性能超过了基于SOTA GAN的方法和1D DM。
- 提出NetDiffus,一个基于扩散模型(DM)的网络流量生成工具。它将时间序列网络流量数据转换为称为Grammian Angular Summation Field (GASF)的特定图像格式。在解决与合成网络流量生成相关的多个挑战以实现更高的数据保真度的同时,还展示了GASF格式的合成数据在各种下游ML任务中的有效性,以提高其分类性能。此外,NetDiffus的性能超过了基于SOTA GAN的方法和1D DM。
- 论文名称 NetDiffus: Network Traffic Generation by Diffusion Models through Time-Series Imaging




To see I can not see,
to know I do not know.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号