


As a reader --> Apollon: A robust defense system against Adversarial Machine Learning attacks in Intrusion Detection Systems
- 📌论文分类Ⅱ:
一种新型防御系统Apollon,使用多种分类器来识别入侵,并使用Multi-Armed Bandits (MAB)与Thompson采样来动态选择每个输入的最佳分类器或分类器集合
1 https://github.com/antonioalfa22/apollon.- 论文名称 Apollon: A robust defense system against Adversarial Machine Learning attacks in Intrusion Detection Systems
- 作者 Antonio Paya, Sergio Arroni, Vicente García-Díaz, Alberto Gómez
- 期刊名称 Computers & Security
- 简要摘要
对抗性机器学习(AML)攻击的兴起对入侵检测系统(IDS)及其检测威胁的能力提出了重大挑战。为了解决这个问题,本文介绍了Apollon,一种可以保护IDS免受AML攻击的新型防御系统。Apollon使用多种分类器来识别入侵,并使用Multi-Armed Bandits (MAB)与Thompson采样来动态选择每个输入的最佳分类器或分类器集合。这种方法使Apollon能够防止攻击者学习IDS行为并生成可以逃逸IDS检测的对抗性样本。在几个最流行和最新的数据集上评估了Apollon,并表明它可以成功地检测攻击,而不会影响其在传统网络流量上的性能。研究结果表明,Apollon是一种强大的防御IDS中AML攻击的防御系统。
- 关键词 Adversarial Machine Learning, Intrusion Detection Systems, Artificial Intelligence, Cybersecurity, Multi-Armed Bandits
- ✏️论文内容
- 【1】研究目标
- Apollon通过阻止攻击者通过学习IDS的行为来生成对抗性流量,从而保护IDS免受攻击者的攻击。Apollon利用各种分类器来检测入侵,并使用带有Thompson采样的Multi-Armed Bandits (MAB)来为每个输入实时选择最佳分类器或分类器组合,使其能够在不影响传统网络流量性能的情况下实现这一目标。通过这种方式,Apollon可以防止攻击者在实际训练时间内学习IDS的行为,为IDS行为增加了一层不确定性,使攻击者更难以检测IDS行为并生成对抗性流量。
- Apollon通过阻止攻击者通过学习IDS的行为来生成对抗性流量,从而保护IDS免受攻击者的攻击。Apollon利用各种分类器来检测入侵,并使用带有Thompson采样的Multi-Armed Bandits (MAB)来为每个输入实时选择最佳分类器或分类器组合,使其能够在不影响传统网络流量性能的情况下实现这一目标。通过这种方式,Apollon可以防止攻击者在实际训练时间内学习IDS的行为,为IDS行为增加了一层不确定性,使攻击者更难以检测IDS行为并生成对抗性流量。
- 【2】研究方法
- Multi-Armed Bandits, 多武装强盗MAB:是概率论和机器学习中的经典问题,agent必须在具有不确定回报的竞争选择中分配有限的资源集(Kuleshov and Precup, 2014)。agent面临着一个权衡,是基于当前信息开发具有最高预期回报的选择,还是探索可能在未来产生更高回报的新选择。MAB问题在各个领域有许多实际应用,例如临床试验、自适应路由、金融投资组合设计和在线广告。已经提出了几种算法来解决MAB问题,例如optimistic initialization(Machado等人,2014),upper confidence bound(UCB) (Carpentier等人,2011)和Thompson sampling(Agrawal和Goyal, 2012)。这些算法的不同之处在于它们如何平衡探索和利用,以及它们如何估计每种选择的预期回报。
汤普森抽样是一种贝叶斯方法,它在每个选择的未知奖励分布上保持一个概率分布,并根据这些分布的抽样来选择行动。具体来说,在每个时间步,Thompson从每个分布中抽样一个奖励,选择与最高抽样奖励相关的行动,并根据观察到的奖励更新其对奖励分布的信念。这种方法已被证明在许多应用中是有效的,并且在最小化后悔方面有很强的理论依据。
近年来,由于能够以有原则的方式平衡探索和利用,汤普森采样法越来越受欢迎。通过从概率分布中抽样而不是从奖励分布中抽样,汤普森抽样鼓励对所有选择的探索,同时仍然倾向于具有更高预期奖励的选择。此外,贝叶斯框架允许结合关于奖励分布的先验知识,这在数据有限的情况下特别有用。
MAB问题与强化学习(RL)领域有着复杂的联系。在强化学习中,agent努力获取知识并制定策略,即策略,在与环境的交互过程中最大化其总回报。在过去的几年里,强化学习在各个领域都取得了显著的成功。值得注意的是,它在需求预测领域发现了重要的效用(Ramos等人,2022a,b)。
- 在本文的工作中,使用MAB算法为每个网络流量请求选择最佳分类器(IDS)。这类似于在需求预测中如何使用MAB来选择最优的预测模型,或确定给定预测模型的最佳超参数。通过使用MAB,可以在利用基于当前信息的具有最高预期精度的分类器和探索可能在未来产生更高精度的新分类器之间取得平衡。
![]()
- Apollon由多层组成,提供比传统IDS和以前的工作更好的安全性。提出的系统结合了多个分类器,MAB算法,并请求聚类来提供针对AML攻击的强大防御。
- Apollon的第一层涉及使用多个分类器,而不是传统上在IDS中使用的单个分类器。使用多个分类器背后的概念是增加试图复制IDS模型的潜在攻击者的难度。这是因为他们无法预测哪个特定模型将负责对给定请求进行分类。
- 为了动态地为每个输入选择最优的分类器或分类器集合,Apollon涉及到使用Multi-Armed Bandits (MAB)和Thompson采样。MAB负责根据系统的当前状态为每个请求选择要使用的分类器。
- 最后对请求进行聚类,每个聚类都有一个版本的分类器,只使用该聚类的信息进行训练。攻击者无法以简单的方式预测请求属于哪个聚类,使用聚类给系统增加了另一层不确定性。
- Apollon的第一层涉及使用多个分类器,而不是传统上在IDS中使用的单个分类器。使用多个分类器背后的概念是增加试图复制IDS模型的潜在攻击者的难度。这是因为他们无法预测哪个特定模型将负责对给定请求进行分类。
- 优点
- Apollon不像传统的对抗训练方法需要大量的对抗数据,而是被巧妙地设计成在没有这些数据的情况下有效地工作。这种设计不仅简化了训练过程,而且确保Apollon在不断变化的网络环境中保持弹性和适应性。
- 通过消除对抗性数据的需求,Apollon为入侵检测提供了更实用和可扩展的解决方案。此外,Apollon不会改变基础模型。相反,它改进了应用程序,以达到最高效率。这与已建立的防御机制相协调,允许无缝集成并增强其适应性。
- 通过为每个请求类型选择最合适的分类器,Apollon在非AML网络流量场景中保持了传统IDS的性能标准。此外,它还能防止攻击者使用AML技术轻松理解分类器的行为。这个健壮的框架确保了在Apollon增强现有模型的整体性能的同时,它也加强了对AML攻击的防御。
- Apollon不像传统的对抗训练方法需要大量的对抗数据,而是被巧妙地设计成在没有这些数据的情况下有效地工作。这种设计不仅简化了训练过程,而且确保Apollon在不断变化的网络环境中保持弹性和适应性。
- Multi-Armed Bandits, 多武装强盗MAB:是概率论和机器学习中的经典问题,agent必须在具有不确定回报的竞争选择中分配有限的资源集(Kuleshov and Precup, 2014)。agent面临着一个权衡,是基于当前信息开发具有最高预期回报的选择,还是探索可能在未来产生更高回报的新选择。MAB问题在各个领域有许多实际应用,例如临床试验、自适应路由、金融投资组合设计和在线广告。已经提出了几种算法来解决MAB问题,例如optimistic initialization(Machado等人,2014),upper confidence bound(UCB) (Carpentier等人,2011)和Thompson sampling(Agrawal和Goyal, 2012)。这些算法的不同之处在于它们如何平衡探索和利用,以及它们如何估计每种选择的预期回报。
- 【3】具体实现
- Listing 1显示了一个带有两个集群和三个分类器的Apollon训练过程样本的输出。训练数据首先在两个聚类之间进行划分,为每个聚类训练分类器,最后分配奖励。
![]()
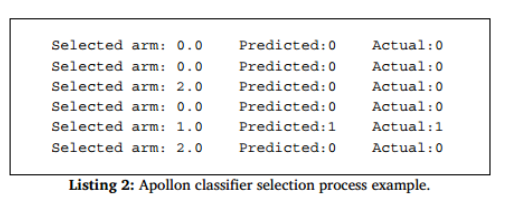
- Listing 2显示了每个请求、预测值和实际值的分类器的选择过程样本。
![]()
- ①Apollon的第一层涉及使用多个分类器,而不是传统IDS中通常使用的单个分类器。使用多个分类器的想法是使攻击者更难以复制IDS模型,因为他无法预测哪个模型将对请求进行分类。
通过使用更多的不同分类器,系统通过引入更大的不确定性变得更有弹性,更好的分类器意味着Apollon系统的更好表现。在Apollon中,可以使用任何类型的分类器。这些分类器可以是基于深度学习或机器学习的最常见的分类器,也可以是基于网络流量请求预测技术的分类器,或者是基于规则系统的更经典的分类器。
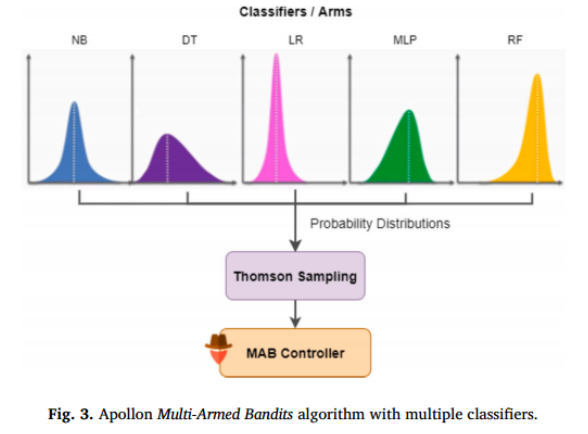
- ②Apollon防御系统的第二层涉及使用MAB算法为每个网络流量请求选择适当的分类器或分类器集。MAB负责选择最佳分类器或分类器集合来评估请求是良性的还是恶意的。这种方法避免了为每个分类器手动调整阈值或权重的需要。MAB算法通过选择具有最高概率提供正确分类的分类器来工作。
![]()
在Apollon中,使用Thomson Sampling,这是一种解决MAB问题的流行算法。汤姆森采样平衡了对可用分类器的探索和利用,确保系统选择最优分类器或一组分类器,同时仍然对新的和未知类型的流量做出响应。Apollon中的MAB算法被设计为考虑到系统中使用的不同类型的分类器。例如,如果随机森林分类器的正确概率很高,但朴素贝叶斯和逻辑回归分类器的概率较低,则MAB算法将为该特定请求选择随机森林分类器。这样,MAB算法保证了系统为每个请求选择最优的分类器集合,提高了分类的整体精度。
- MAB算法根据不同分类器以前的性能不断更新其概率,使系统能够适应流量模式随时间的变化,并确保系统始终更新最新的攻击类型。MAB算法对后验分布进行采样,并为每个分类器生成一个值,然后选择值最高的分类器。
然而,在存在平局的情况下,表明多个分类器具有同等高的最佳概率,则采用集成方法,特别是Bootstrap Aggregating,通常称为Bagging (Lee et al, 2020),来组合这些选定模型的输出。这种方法确保即使有多个“最佳”分类器,决策过程保持稳健和有效。选择Bagging作为集成方法源于其与目标相一致的固有属性。Bagging的工作原理是通过训练集的自举样本生成多个版本的预测器,然后汇总它们的预测。这个过程本质上减少了方差,使得整体对单个分类器的特性不那么敏感。在基于MAB的系统中,分类器之间的联系表明了密切匹配的性能,Bagging提供了一种自然的方法来利用这些分类器的集体力量,而不会引入不当的偏见。
- 通过使用Multi-Armed Bandits算法,Apollon可以为每个网络流量请求动态选择最佳分类器或分类器集,使系统对新类型的攻击响应更快。
Thomson Sampling的使用保证了系统在探索和利用之间的平衡,提高了分类的整体攻击检测率。选择MAB算法优于传统集成算法的主要原因是其动态适应性。在防御IDS中的AML攻击的背景下,威胁形势不断发展。MAB提供了随时间调整的灵活性,允许根据历史性能探索和利用不同的分类器。这种动态选择机制确保系统即使在对手调整策略时也保持健壮。传统的集成方法虽然功能强大,但在更静态的模型组合上运行,并且在响应不断变化的对抗策略时可能不那么敏捷。
- ③Apollon防御系统的最后一层包括基于网络流量请求的特征,对其进行聚类,然后为每个聚类训练每个分类器的单独版本。在Apollon中,使用K-Means算法根据网络流量请求的特征对其进行聚类,确保具有相似特征的请求被分组在一起。这些特征与分类器用来评估请求的特征相同,从而确保聚类基于分类器用来做出决策的相同信息。
虽然这似乎增加了计算复杂性,而没有直接提高传统的性能指标,如准确性或检测率,但它在增加系统对对抗性攻击的鲁棒性方面起着至关重要的作用。这一层丰富了系统的整体多样性,确保了在不同数据簇上训练的多个模型的存在。当攻击者试图通过黑/灰盒攻击复制系统行为时,这种增加的变化会使攻击者的任务复杂化。它本质上增加了系统的不可预测性,形成了Apollon对此类尝试的强大防御的关键部分。
K-Means是一种流行的聚类算法,用于许多机器学习应用程序。K-Means算法的工作原理是随机选择𝑘点作为初始质心,然后迭代更新质心直到聚类收敛。
- 每个聚类都有每个分类器的专用版本,专门针对该聚类中的流量请求进行训练。这种针对不同流量模式的特定调优显著提高了系统的复杂性,并增强了其对对抗性学习的防御能力。
- 当一个新的网络流量请求到达Apollon时,它会根据其特征被分类到适当的聚类中。然后,Multi-Armed Bandits算法为该集群选择最优分类器集,在特定集群中考虑每个分类器的性能。然后,选定的分类器或分类器集合评估请求,以确定它是良性的还是恶意的。
- 在Apollon中使用聚类,再加上每个聚类上每个分类器的单独训练,允许Multi-Armed Bandit算法根据接收到的请求类型为每个分类器生成多个概率分布。这种策略的混合增加了潜在攻击者识别响应分类器的挑战,从而降低了系统模仿成功的概率。
- ①Apollon的第一层涉及使用多个分类器,而不是传统IDS中通常使用的单个分类器。使用多个分类器的想法是使攻击者更难以复制IDS模型,因为他无法预测哪个模型将对请求进行分类。
- Listing 1显示了一个带有两个集群和三个分类器的Apollon训练过程样本的输出。训练数据首先在两个聚类之间进行划分,为每个聚类训练分类器,最后分配奖励。
- 【4】实验和结果
- 数据集:CIC-IDS-2017, CSE-CIC-IDS-2018, and CIC-DDoS-2019
- 攻击:
- • Zeroth-order optimization attack (ZOO) (Chen et al., 2017)
- • HopSkipJump attack (HSJA) (Chen et al., 2020)
- • W-GAN based attacks (Lin et al., 2022)
- • Zeroth-order optimization attack (ZOO) (Chen et al., 2017)
- ①Traditional network traffic and attacks
![]()
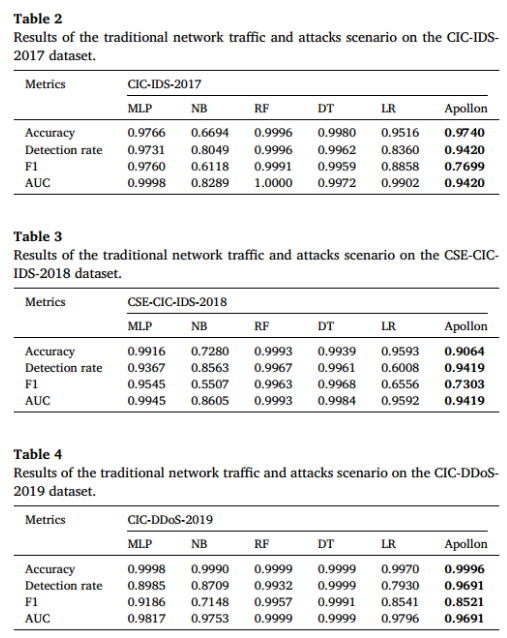
- 本文解决方案显示出较高的检测率和准确率分数,与选择用于比较的分类器相当。
- 在所有数据集中,Apollon并没有获得最好或最差的分数。这是因为Apollon内部从相同的分类器中进行选择。因此,Apollon可以达到的最高分被限制为最佳分类器的最大值,虽然它永远不会表现得像最差的分类器那样差,因为它有其他更好的选择。
- 研究结果表明,即使集成了新的安全机制,Apollon仍然可以在传统的网络流量分类环境中提供较高的准确率和检测率分数。因此,Apollon能够保留IDS的基本功能。
- 本文解决方案显示出较高的检测率和准确率分数,与选择用于比较的分类器相当。
- ②Adversarial Machine Learning attacks
![]()
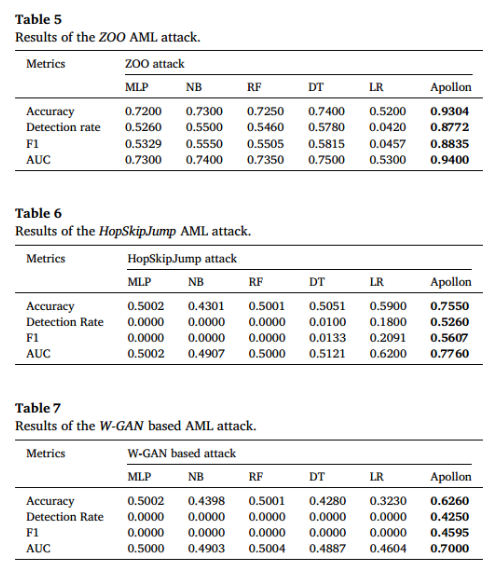
- 三种类型的AML攻击的MAB选择与之前在相同数据集上进行的场景中观察到的情况非常相似。这种一致性可以归因于这样一个事实,即Apollon在每次实验开始时都使用相同的模型初始分布。因此,不同类型攻击之间的选择模式非常相似,相同的模型被选择的频率高于其他模型。
- Apollon在AML攻击中的准确性和检出率的提高可归因于在其模型选择过程中包含不确定性成分。这使得仅根据其响应来训练模型变得困难。实验结果表明,与单独使用的其他分类器相比,本文解决方案具有更强的鲁棒性。
- 虽然解决方案有效地降低了攻击的有效性,但它并没有完全消除攻击。这意味着在增强解决方案的健壮性以进一步增强其对此类攻击的抵抗力方面仍有改进的空间。
- 特别是,如果要用更多的时间来生成攻击,例如通过增加迭代或epoch的数量,那么针对解决方案的这些攻击的有效性很可能会增加虽然制作一个坚不可摧的防御几乎是不可能的,但本解决方案旨在显著增加潜在攻击者成功执行攻击所需的时间和资源。在现实场景中,时间和计算成本的增加会使攻击变得不可行或在经济上不可行,从而起到威慑作用并增加额外的安全层。
- 三种类型的AML攻击的MAB选择与之前在相同数据集上进行的场景中观察到的情况非常相似。这种一致性可以归因于这样一个事实,即Apollon在每次实验开始时都使用相同的模型初始分布。因此,不同类型攻击之间的选择模式非常相似,相同的模型被选择的频率高于其他模型。
- 数据集:CIC-IDS-2017, CSE-CIC-IDS-2018, and CIC-DDoS-2019
- 【5】局限性
- 增加模型训练时间:Apollon的一个显著限制是在模型训练阶段所需的计算时间增加。尽管Apollon在预测阶段的计算效率很高(它只是从预定义的分布中采样以选择合适的模型),但训练阶段的计算强度更大。这是因为Apollon需要为池中的每个模型生成这些分布,这可能是一个耗时的过程。这种限制在快速模型训练和部署至关重要的场景中尤其相关。
- 模型池多样性:第二个限制与模型池的多样性有关。Apollon的有效性与它所拥有的模型的多样性和质量有着内在的联系。在模型类型、体系结构或训练数据方面缺乏多样性的池,可能无法充分利用Multi-Armed Bandits机制的潜力。这可能导致性能不佳,并可能降低Apollon对各种对抗性攻击的整体稳健性。
- 这些限制为未来的研究和开发提供了途径,以进一步提高Apollon的现实适用性和有效性。
- 增加模型训练时间:Apollon的一个显著限制是在模型训练阶段所需的计算时间增加。尽管Apollon在预测阶段的计算效率很高(它只是从预定义的分布中采样以选择合适的模型),但训练阶段的计算强度更大。这是因为Apollon需要为池中的每个模型生成这些分布,这可能是一个耗时的过程。这种限制在快速模型训练和部署至关重要的场景中尤其相关。
- 【1】研究目标
- 总结
- 本文提出了Apollon,一种针对入侵检测系统的对抗性机器学习攻击的新型鲁棒防御系统。Apollon利用Multi-Armed Bandits模型为汤普森采样的每个输入实时选择最适合的分类器,为IDS行为增加了一层不确定性,这使得攻击者更难以复制IDS并产生对敌流量。
- 在几个数据集上的实验评估表明,Apollon可以成功地检测攻击,而不会影响其在正常网络流量数据上的性能,并且可以防止攻击者在实际训练时间内学习IDS行为。这些结果表明,Apollon是IDS中针对AML攻击的有效防御系统,有助于提高关键系统的安全性。
- Apollon并没有完全消除AML攻击的风险;相反,它通过显著增加攻击者生成对抗性流量所需的时间和精力来减轻威胁。通过这样做,Apollon增加了攻击者必须驾驭的复杂性层,从而起到威慑作用。这种增加的时间和精力通常会转化为攻击者更高的计算和财务成本,使攻击变得不那么吸引人,甚至在经济上不可行。虽然这并不能使系统完全不受“AML”攻击的影响,但它确实提高了成功攻击的标准,为实际应用程序提供了额外的安全性和弹性层。
- 本文提出了Apollon,一种针对入侵检测系统的对抗性机器学习攻击的新型鲁棒防御系统。Apollon利用Multi-Armed Bandits模型为汤普森采样的每个输入实时选择最适合的分类器,为IDS行为增加了一层不确定性,这使得攻击者更难以复制IDS并产生对敌流量。
- 论文名称 Apollon: A robust defense system against Adversarial Machine Learning attacks in Intrusion Detection Systems


To see I can not see,
to know I do not know.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号