


As a reader --> Deep PackGen: A Deep Reinforcement Learning Framework for Adversarial Network Packet Generation
- 📌论文分类Ⅰ:
框架Deep PackGen:采用深度强化学习来生成对抗性数据包,将原始恶意网络数据包作为输入并系统地对其进行扰动,Deep PackGen将其伪装成良性数据包,同时仍保持其功能- 论文名称 Deep PackGen: A Deep Reinforcement Learning Framework for Adversarial Network Packet Generation
- 作者 Hore S, Ghadermazi J, Paudel D, et al.
- 期刊名称 arXiv preprint arXiv:2305.11039, 2023.
- 简要摘要
人工智能(AI)和机器学习(ML)算法的最新进展,加上更快的计算基础设施的可用性,通过ML辅助网络入侵检测系统(NIDS)的开发,增强了网络安全运营中心(防御者)的安全态势。同时,在AI/ML模型的支持下,攻击者逃逸安全的能力也有所提高。因此,防御者需要主动防范利用NIDS检测机制的逃逸攻击。最近的研究发现,基于流和基于包的特征的扰动可以欺骗ML模型,但这些方法都有局限性。对基于流的特征进行扰动很难进行逆向工程,而对基于包的特征进行扰动生成的样本则不可玩。
本文提出了框架Deep PackGen,采用深度强化学习来生成对抗性数据包,旨在克服文献中方法的局限性。通过将原始恶意网络数据包作为输入并系统地对其进行扰动,Deep PackGen将其伪装成良性数据包,同时仍保持其功能。实验使用公开可用的数据,Deep PackGen对各种ML模型和不同攻击类型的平均对抗成功率达到66.4%。调查还显示,超过45%的成功对抗样本是逃逸分类器决策边界的分发包。从本文对攻击者对不同类型的恶意数据包进行特定逃逸扰动的能力的研究中获得的知识可以帮助防御者增强其NIDS的鲁棒性,以应对不断发展的对抗性攻击。
- 关键词 Network Intrusion Detection Systems · Adversarial Attack · Red Team Evaluation of ML/DL models · Deep Reinforcement Learning · DRL Cyber Framework
- ✏️论文内容
- 【1】introduction
- 针对网络入侵防御的规避攻击主要是通过干扰基于网络流的特征来欺骗ML模型。
- 然而,基于流的攻击是不切实际的,因为将这些扰动从流级别反向工程到构建实际数据包是非常复杂和困难的,Rosenberg等[2021a]。此外,不同基于流的特征之间隐藏的相关性进一步加剧了在真实网络通信中重放扰动的计算难度(Han等[2021])。更重要的是,必须进行扰动,以维持通信的功能。
- 然而,基于流的攻击是不切实际的,因为将这些扰动从流级别反向工程到构建实际数据包是非常复杂和困难的,Rosenberg等[2021a]。此外,不同基于流的特征之间隐藏的相关性进一步加剧了在真实网络通信中重放扰动的计算难度(Han等[2021])。更重要的是,必须进行扰动,以维持通信的功能。
- 因此,在数据包级别上制作对抗性攻击对于提高实现规避攻击的实用性是必要的。
- 这些研究利用公开可用的数据集来获得混淆样本,并依赖于使用试错法和其他近似技术进行随机扰动。生成的对抗样本然后针对线性、基于树的和非线性ML模型进行规避测试。这些研究的局限性如下:
- 对样本的干扰主要集中在基于时间的特征上,分类器可以通过使用原始包信息进行训练来免疫这些特征。有些还使用数据包或有效负载注入和数据包破坏生成对抗性样本。然而,包级特征之间存在相关性,直接影响分类器的特征集,这些研究都没有考虑到这一点。这种现象也被称为包突变的副作用Pierazzi等[2020]。
- 现有的基于数据包的方法的另一个限制是,它们会干扰向前和向后的数据包(即,从主机到目的地的通信,然后目的地再返回到主机)。显然,攻击者只能控制转发的数据包,即那些从主机发送到目的地(服务器)的数据包。
- 对样本的干扰主要集中在基于时间的特征上,分类器可以通过使用原始包信息进行训练来免疫这些特征。有些还使用数据包或有效负载注入和数据包破坏生成对抗性样本。然而,包级特征之间存在相关性,直接影响分类器的特征集,这些研究都没有考虑到这一点。这种现象也被称为包突变的副作用Pierazzi等[2020]。
- 这些研究利用公开可用的数据集来获得混淆样本,并依赖于使用试错法和其他近似技术进行随机扰动。生成的对抗样本然后针对线性、基于树的和非线性ML模型进行规避测试。这些研究的局限性如下:
- 针对网络入侵防御的规避攻击主要是通过干扰基于网络流的特征来欺骗ML模型。
- 【2】contribution
- 本方法使用基于学习的方法,其中人工智能代理被训练对任何给定的恶意数据包进行(接近)最优扰动。代理学习使用深度强化学习(DRL)方法以顺序的方式进行这些扰动。识别网络通信中的转发数据包,并仅修改它们以产生对抗性样本,对使用包级数据训练的分类器评估对抗性样本。
- 目标是对原始数据包进行最小和有效的扰动,以保持通信的功能。这种扰动包括:修改互联网协议(IP)报头、传输控制协议(TCP)报头、TCP选项和段数据中的有效部分。此外,只考虑干扰那些无需任何预处理就可以从原始数据包捕获(PCAP)文件中获得的特征。这使得使用扰动数据包复制攻击变得可行。
- 在本研究中还考虑了包突变的副作用。例如,对IP或TCP报头的任何更改都会分别影响IP和TCP校验和。数值实验部分(#4)提供了对扰动及其副作用的详细描述。
- 还评估从一种环境获得的学习是否可转移到另一种环境,这样做是为了衡量方法在现实环境中的有效性,在现实环境中,攻击者可能不了解ML模型和用于构建NIDS的数据。
- 总之:论文通过开发一种基于学习的方法DRLenabled来解决构建对抗样本的文献空白,该方法具有以下特征:只有转发的数据包受到干扰;为了保持包的功能,考虑了有效的扰动;考虑了扰动的副作用;对抗性样本的有效性在未见分类器上进行了测试;论证了该框架在其他网络环境中的可移植性。这是第一个将受限网络数据包扰动问题作为顺序决策问题并使用DRL方法解决的研究。方法可以生成出分布外(OOD)数据包,这些数据包也可以逃避更复杂的非线性分类器的决策边界。此外,还解释了为什么与其他攻击类型相比,某些攻击类型的数据包更容易被操纵。
- 本方法使用基于学习的方法,其中人工智能代理被训练对任何给定的恶意数据包进行(接近)最优扰动。代理学习使用深度强化学习(DRL)方法以顺序的方式进行这些扰动。识别网络通信中的转发数据包,并仅修改它们以产生对抗性样本,对使用包级数据训练的分类器评估对抗性样本。
- 【3】method
- Deep PackGen框架
-
![]()
- 💡思路:提出的框架名为Deep PackGen,如图1所示,由三个主要部分组成:数据集创建、包分类模型开发和对抗网络包生成。
- Data Set Creation
- 本研究创建了一个包含原始数据包数据的数据集,该数据集具有源自source的单向流。来自单向流的数据包用于训练ML模型并生成对抗样本(网络数据包)。
- 创建过程使用一个工具,该工具从PCAP文件中提取原始数据包数据,选择单向数据包,进行预处理,并将原始数据转换为规范化的数字特征值。这里提供了处理和标记数据的完整程序。
该程序的步骤如下:
1. 在基于python的Scapy Biondi[2010]和dpkt Song and contributor[2009]等解析器的帮助下,解析来自PCAP文件的不同头和段信息。
2. 通过6元组信息(source IP address, destination IP address, source port, destination port, protocol, and epoch time)对报文数据进行标记,识别良性和恶意报文。对于恶意数据包,每个样本被分配原始攻击类别标签(网站上描述获得)。
3. 使用源IP地址提取单向报文,即只提取标识源发送的报文,不包括目的的响应,将把这些单向数据包称为转发数据包。
4. 删除在训练基于ML的分类器时可能增加偏差的标题信息。这包括从IP头中删除ETH头信息,从IP头中删除源和目的IP地址信息,从TCP头中删除源和目的端口信息。图2显示了一个TCP/IPv4模型,其中红色下划线表示该信息的位置,红色字体中的数字表示将从每一层删除的字节数。
5. 将所有报文的feature-length设置为N。在前一步中删除信息后,剩余的每个字节将成为该数据集中的一个特征。字节数将根据数据包的类型而变化。因此,为了保持数据的标准结构,对Theile等人的特征空间进行了补零填充[2020]。
6. 将每个数据包中的原始信息从0-255之间的十六进制数转换为十进制数,并将其规范化为0-1之间,以提高机器计算效率。
- TCP/IP模型,每层包含的字节信息
-
![]()
- 本研究创建了一个包含原始数据包数据的数据集,该数据集具有源自source的单向流。来自单向流的数据包用于训练ML模型并生成对抗样本(网络数据包)。
- Packet Classification Model Development
- 攻击者可能不完全了解防御方的模型,因此需要一个替代防御者ML-NIDS来生成和评估对抗样本的代理。本文提出了一个集成模型作为防御者模型的代理,来训练对抗代理。集成模型由多个分类器(ML模型)组成,使分类器在识别恶意数据包方面具有鲁棒性。这里使用本文生成的训练数据集开发各种线性、基于树的和非线性ML模型,并使用测试数据集对它们进行评估。
- 攻击者可能不完全了解防御方的模型,因此需要一个替代防御者ML-NIDS来生成和评估对抗样本的代理。本文提出了一个集成模型作为防御者模型的代理,来训练对抗代理。集成模型由多个分类器(ML模型)组成,使分类器在识别恶意数据包方面具有鲁棒性。这里使用本文生成的训练数据集开发各种线性、基于树的和非线性ML模型,并使用测试数据集对它们进行评估。
- Adversarial Sample Generation
- Problem Definition:目标是开发一种方法来生成恶意网络数据包,可以欺骗防御者基于ML的NIDS。为了实现这一点,原始的恶意数据包被干扰,伪装成良性流量。在这个问题中,扰动受到保持数据包的恶意和功能的要求约束。
- Problem Formulation:通过对网络数据包进行扰动来生成对抗性样本可以作为一个顺序决策问题。攻击者从原始的恶意网络数据包开始,进行顺序扰动。在每次迭代中,对数据包进行修改,并将该扰动样本通过数据包分类模型检查其是否成功规避其分类决策边界。迭代过程继续进行,直到获得成功的对抗样本或达到最大迭代次数。目标是学习(接近)最优的扰动集:给定一个原始的恶意网络数据包,以生成一个对抗样本。这种顺序决策问题可以被表述为马尔可夫决策过程(MDP)。
- State:st,是时刻t可用信息的表示。状态空间由从该框架的第一个组件创建的数据集中获得的网络数据包的规范化字节值和防御者模型给出的分类标签(0表示良性,1表示恶意)组成。每个包包含N个特征,这使得状态空间为N + 1维。
- Action:at,表示在时刻t作用于网络数据包的扰动(s), δ ∈∆。动作选择的数量被限制为|∆|,并且这些选择是离散的。
- Reward:rt,是衡量在特定状态下采取行动的有效性。奖励信号可以帮助攻击量化在特定状态下采取行动的效果。本文设计了一个新的奖励函数来指导攻击者学习一个最优的策略来进行扰动,给定原始的恶意网络数据包。奖励函数定义如下:
![]()
- 其中,k是被扰动网络样本成功逃避的集合中分类器的数量。这个函数产生积极和消极的奖励。当受扰动的样本避开了集成模型中的一个或多个分类器,可以获得积极的奖励,奖励值与它能够通过被错误分类为良性样本而欺骗的分类器的数量成正比;每次扰动样本未能逃避集成模型中的任何分类器时,都会产生一个小的负奖励。
- State:st,是时刻t可用信息的表示。状态空间由从该框架的第一个组件创建的数据集中获得的网络数据包的规范化字节值和防御者模型给出的分类标签(0表示良性,1表示恶意)组成。每个包包含N个特征,这使得状态空间为N + 1维。
- DRL-based Solution Approach:网络数据包扰动问题具有较大的状态空间和动作空间。为了克服使用传统RL方法计算和存储所有状态-动作对的动作值(Q值)的问题,使用深度神经网络架构来估计这些值。攻击者以DRL代理的形式,使用在框架的第一个组件中创建的数据集中的恶意样本进行训练。值得注意的是,在训练和测试阶段,DRL代理对机器学习模型的架构、参数值或损失函数没有可见性。
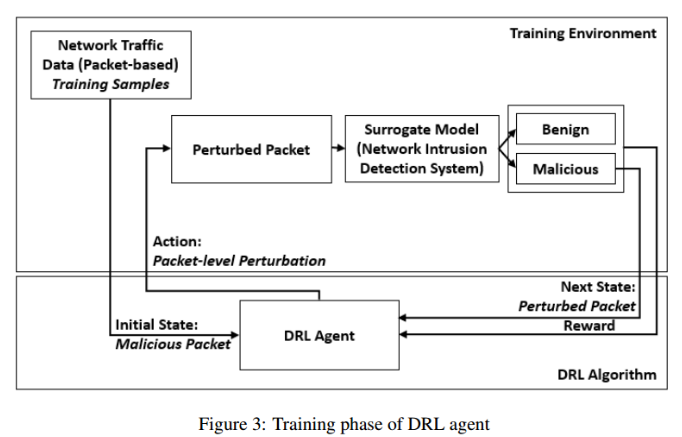
- DRL Training Phase:包括DRL代理和训练环境之间的交互。
-
![]()
- 对于每种攻击类型,DRL代理获得随机选取的数据样本,并规定扰动动作。环境允许实现这些动作,导致系统状态的一步转换,生成一个扰动样本。奖励是根据受干扰包逃逸分类器集合的能力来计算的。这个过程一直持续到达到停止条件,即对抗样本成功地被误分类为良性流量或达到最大时间步数。
- DRL代理与训练环境交互,并通过遵循一组称为策略的规则来学习生成对抗性数据包。代理的决策基于一系列状态、动作和奖励,这些都是由训练环境决定的。DRL代理将根据生成的数据包逃避ML代理模型的能力获得奖励。使用double Q-Learning (DDQN)的DRL来训练agent。
DDQN是一种单架构深度Q网络,适用于具有离散动作空间的问题。DDQN与传统深度Q学习的显著区别在于,DDQN通过使用额外的网络来解耦动作选择和评估过程。这有助于减少传统Q学习中出现的高估错误。
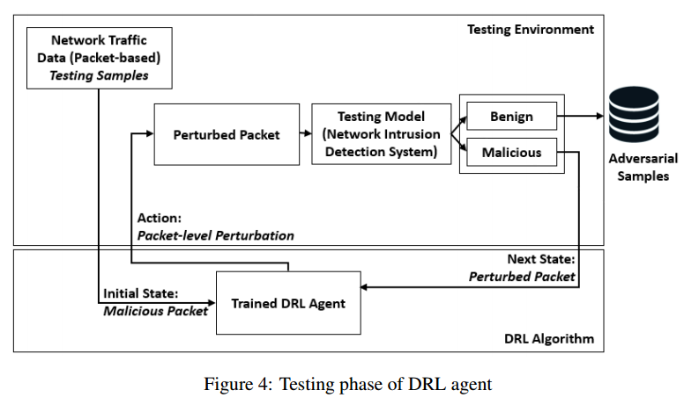
- DRL Testing Phase:针对不同的ML模型对训练好的DRL代理进行测试。
-
![]()
- 代理的神经网络架构使用训练阶段结束时获得的学习权值(θ)。在此阶段,DRL代理在没有任何奖励信号的情况下运行,其行为基于其学习策略。在此期间,从训练阶段未看到的测试样本生成对抗性样本。这允许评估代理在各种分类器上的性能,包括那些在DRL训练环境中未使用的分类器。使用对抗性成功率(ASR)度量来衡量每个代理的性能。([扰动后误分类的样本总数 - 扰动前误分类的样本总数] / 扰动前ML模型正确分类为恶意的样本总数)
- DRL Training Phase:包括DRL代理和训练环境之间的交互。
- Problem Definition:目标是开发一种方法来生成恶意网络数据包,可以欺骗防御者基于ML的NIDS。为了实现这一点,原始的恶意数据包被干扰,伪装成良性流量。在这个问题中,扰动受到保持数据包的恶意和功能的要求约束。
- Data Set Creation
- Deep PackGen框架
- 【4】experiment
- 数据集
- CICIDS-2017、CICIDS-2018
- CICIDS-2017、CICIDS-2018
- 指标
- 数据处理
- 只考虑转发数据集中的数据包,因为攻击者控制(生成和操纵)来自其soure的数据包。从每个数据包中提取有效载荷字节,并将每个字节表示为该数据集中的一个特征。将十六进制数转换为十进制数,并将每个特征值归一化为0-1的范围,其中最小和最大特征值分别为0和255。总共有1525个功能。
- 只考虑转发数据集中的数据包,因为攻击者控制(生成和操纵)来自其soure的数据包。从每个数据包中提取有效载荷字节,并将每个字节表示为该数据集中的一个特征。将十六进制数转换为十进制数,并将每个特征值归一化为0-1的范围,其中最小和最大特征值分别为0和255。总共有1525个功能。
- 分类模型创建
- 为了有效地训练DRL代理来欺骗分类器的决策边界,在DRL代理的训练环境中使用了专门用于各自攻击类型的ML代理模型。例如,如果DRL代理在干扰端口扫描攻击的数据包上进行训练,那么ML代理模型将使用从相同攻击的网络流数据中提取的转发数据包进行训练。
- 为了有效地训练DRL代理来欺骗分类器的决策边界,在DRL代理的训练环境中使用了专门用于各自攻击类型的ML代理模型。例如,如果DRL代理在干扰端口扫描攻击的数据包上进行训练,那么ML代理模型将使用从相同攻击的网络流数据中提取的转发数据包进行训练。
- 对抗DRL代理训练
- DRL代理的状态空间由从网络数据包中提取的1525个特征及其分类标签组成,这些特征是与不同TCP/IP头和段信息相关的字节的规范化值。
- 本研究中的重点是找到(接近)最优的扰动集,这些扰动集可以应用于给定的恶意网络数据包,以生成成功的对抗性样本,同时保持通信功能。为保证方法有效,基于领域知识选择了一组有效的扰动(∆)。
1.将fragmentation bytes从do not fragment修改为do fragment。这种扰动可以应用于未分片的数据包。do fragment命令的十六进制值为40。这种扰动直接影响字节数7和8,并间接影响IP报头的字节数9、11和12,其中字节9表示生存时间(TTL)值,字节11和12表示IP校验和值。IP校验和可以通过添加IP报头中只跳过校验和字节[1994]的所有元素来计算。校验和值随着fragmentation bytes字节值的变化而变化。由于分片化,TTL值也被调整(Stevens and Hirsch[1994])。
2.将fragmentation bytes从do not fragment修改为more fragment。这种扰动可以应用于分片/不分片的数据包。more fragment命令的十六进制值为20。这种扰动直接影响到字节数7和8,间接影响到IP报头的字节数9、11和12。
3.增加或减少(+/- 1)TTL字节值。对这个字节的任何有效扰动都会导致最终TTL值在1-255之间。这种扰动直接影响到字节数9,并间接影响到IP报头的11和12字节。
4.增加或减少(+/- 1)window size bytes。对这些字节的任何有效扰动将导致最终窗口大小值在1-65535之间。这直接影响到TCP报头的第15和16字节,并间接影响到TCP报头的第17和18字节,这两个字节代表TCP校验和,类似于IP校验和Cerf和Kahn[1974]。
4.增加或减少maximum segment size(MSS)值。这种扰动只能应用于SYN和SYN- ACK数据包。对于已经具有MSS选项的数据包,只增加/减少该值。MSS取值范围为0 ~ 65535。TCP选项没有特定的顺序,MSS选项的长度为2或4字节。这种扰动也间接影响到TCP报头的字节数17和18。
5.增加或减少window scale值。这种扰动只能应用于SYN和SYN- ACK数据包。对于默认情况下没有window scale的数据包,将窗口缩放添加到SYN或SYN- ACK数据包中;而对于已经具有window scale选项的数据包,只增加/减少该值。window scale值限制在0-14之间。window scale选项的长度为1或2字节。这种扰动也间接影响到TCP报头的字节数17和18。
6.添加段信息。对于这种扰动,从数据集中的良性流量中选择了最常见的TCP有效负载信息。每次选择此操作时,上述TCP有效载荷的一部分作为dead bytes顺序添加到恶意数据包的TCP有效载荷信息的末尾。这种扰动影响TCP段中的字节值,并间接影响TCP报头的字节数17和18。
- 一些实验环境介绍
- DRL代理的状态空间由从网络数据包中提取的1525个特征及其分类标签组成,这些特征是与不同TCP/IP头和段信息相关的字节的规范化值。
- 结果
- Deep PackGen框架成功地在所有分类器训练的网络环境中产生了平均ASR为66.4%的对抗性数据包。简单的模型更容易让DRL代理通过对抗样本生成来逃避决策边界。DDoS和端口扫描代理对所有类型的模型都表现得最好,而渗透代理生成的扰动数据包在欺骗非线性分类器方面的成功率较低。
- 在不同的网络环境下,经过训练的DRL代理在各种基于树的模型和非线性模型上的平均ASR为39.8%。
- 为什么某些攻击类型的数据包比其他攻击类型的数据包更容易受到干扰?数据包特征值与良性类相似的攻击类型更容易受到成功的扰动,从而可以逃避分类器。
(i)从CICIDS-2017数据集中每种攻击类型的网络数据包中计算前500个归一化特征的均值和标准差值。然后将这些值与从良性包中获得的值进行比较,以确定特征值的相似性(或不相似性)。
(ii)使用SHapley加性解释(SHAP) Lundberg和Lee[2017]来识别确定分类边界的重要特征,以便准确检测测试模型中的每种攻击类型。
- 学习的(接近)最优行为及其与分类器决策边界的相关性?在两个测试环境中,最成功的攻击者DDoS代理也产生了最高百分比的分布外(OOD)样本。平均而言,DRL代理在所有测试模型中生成的成功对抗性样本中,超过45%是OOD。
对成功扰动的对抗样本进行统计分析,以确定它们与原始样本的概率差异。对此,进行了Kolmogorov-Smirnov检验(K-S检验)来量化这种差异。双样本K-S检验比较受扰动的对抗样本和原始恶意样本的经验累积分布函数(eCDFs),以确定前者是否与后者来自相同的分布。它给出了两个eCDFs之间的最大距离,也称为K-S统计量(D) Gretton等[2012]。如果D的计算值大于指定显著性水平的临界值,则拒绝原假设,表明样本不是来自同一分布。
- Deep PackGen框架成功地在所有分类器训练的网络环境中产生了平均ASR为66.4%的对抗性数据包。简单的模型更容易让DRL代理通过对抗样本生成来逃避决策边界。DDoS和端口扫描代理对所有类型的模型都表现得最好,而渗透代理生成的扰动数据包在欺骗非线性分类器方面的成功率较低。
- 数据集
- 【1】introduction
- 结论
- 1. 与SVM和DNN等非线性分类器相比,DRL代理在逃避DT和RF等基于树的包分类模型方面具有更高的成功率。
- 2. DRL代理生成对抗样本的成功率直接关系到控制分类器决策边界的关键特征,以及这些特征是否可以在不破坏数据包通信功能的情况下改变。
- 3. 具有与良性流量相似的特征值的攻击,如DDoS和端口扫描,更容易受到对抗性代理的成功干扰。
- 4. DRL代理学习的策略可以转移到新的网络环境中。
- 5. 分类器的决策边界越复杂,逃避所需的扰动幅度就越大,从而导致样本偏离分布。
- 1. 与SVM和DNN等非线性分类器相比,DRL代理在逃避DT和RF等基于树的包分类模型方面具有更高的成功率。
- 参考文献
- 论文名称 Deep PackGen: A Deep Reinforcement Learning Framework for Adversarial Network Packet Generation


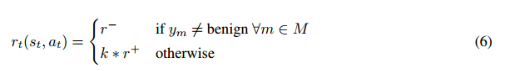
To see I can not see,
to know I do not know.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号