Word2vec 基本原理
-
词嵌入算法
基于神经网络的表示一般称为词向量、词嵌入(word embedding)或分布式表示(distributed representation)。其核心是上下文的表示以及上下文与目标词之间的关系映射,主要通过神经网络对上下文,以及上下文和目标词之间的关系进行建模。
-
词向量
最常见的方法是用 One-hot。它假设词之间的语义和语法关系是相互独立的。
先创建一个词汇表并把每个词按顺序编号,每个词就是一个很长的向量,向量的维度等于词汇表大小,只有在对应位置上的数字为 1,其他都为 0 。
如: PHP is the best programming language in the world.
I really enjoy the process of programming.
对于这两句话,我们先构造一个词典
\[D=\{'PHP':1,\quad 'is':2,\quad 'the':3,\quad 'best':4,\quad 'programming':5, \quad 'language':6, \quad 'in':7, \quad 'world':8, \quad 'I':9, \quad 'really':10, \quad 'enjoy':11, \quad 'process':12, \quad 'of':13, \quad \} \]上面的词典包含14个单词,然后对每个单词进行 one-hot 编码
PHP : (1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) is : (0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) the : (0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) ... ... ... of : (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1)得到了每个单词的embedding之后,就可以送入到机器学习或者深度学习模型中进行后续处理。
不足:
- 无法捕捉词与词之间得相似度,即仅从两个向量是无法看出两个词汇之间的关系,也称为 “ 语义鸿沟” 问题
- 维度爆炸。随着词典规模的增大,维度变得越来越大,矩阵也变得超稀疏,且会耗费巨大得计算资源。
- 无法保留词序信息
-
word2vec
word2vec 是 Google 在 2013 年发布的一个开源词向量建模工具。
基本思想:通过训练将每个词映射成 K 维实数向量(K 一般为模型中的超参数),通过词之间的距离(欧氏距离等)来判断它们之间的语义相似度。
word2vec 结构图:
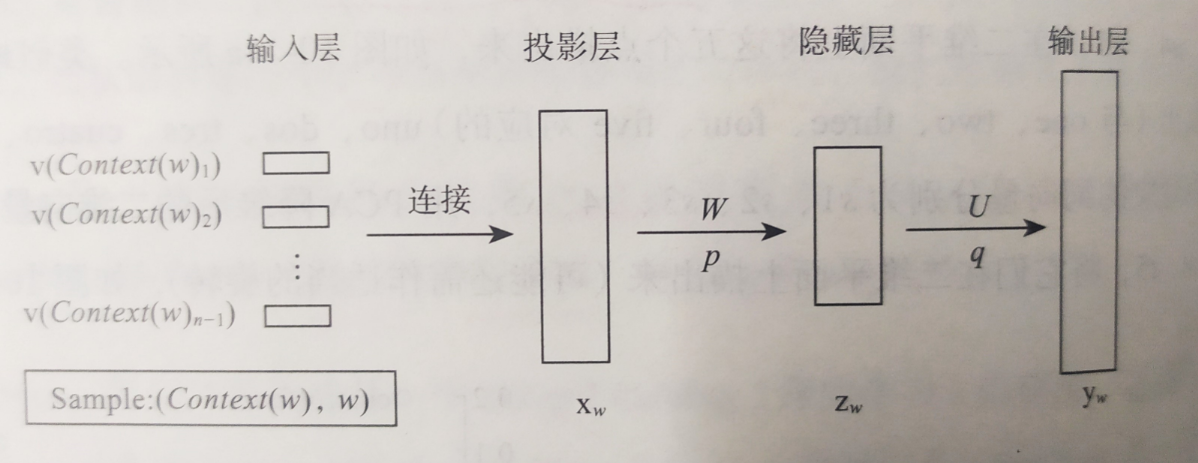
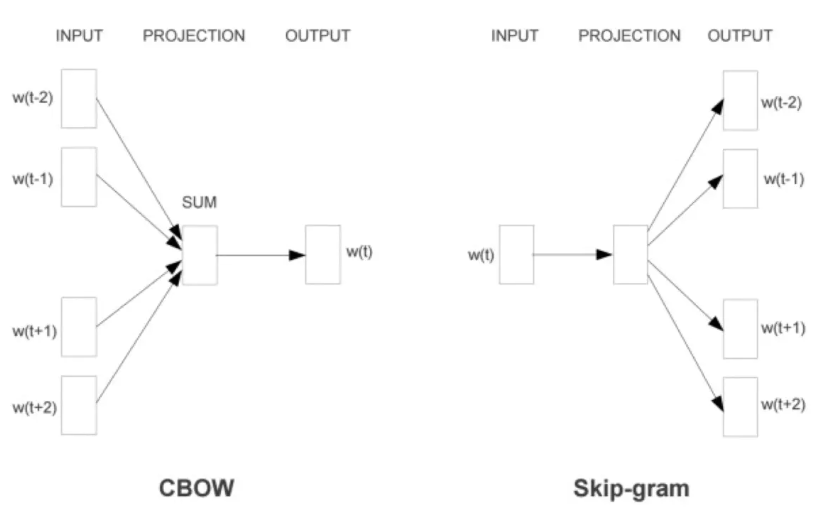
word2vec 采用的模型有两种:CBOW(Continuous Bag-Of-Words) 和 Skip-Gram 两种
两种结构如下:
-
CBOW
通过上下文来预测当前词。包含输入层、投影层、输出层(没有隐藏层)。
- 随机生成一个所有单词的词向量矩阵,每一行对应一个单词向量
- 对于某一个单词(中心词),从矩阵中提取其周边单词的向量
- 求周边单词的词向量的均值向量
- 在该均值上使用 logistic regression 进行训练,softmax 作为激活函数
- 期望回归得到的概率向量可以与真实的概率向量(即中心词 one-hot 编码向量)相匹配
-
Skip-gram
它与 CBOW 相反,通过中心词来预测上下文,输出层是一颗 Huffman 树。
Huffman 树
对于一组节点,按权值从小到大排列,每次选其中最小的两个节点组合成一个新的节点,放入节点集中,再次选择,直到节点选完。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号