
mysql随笔
数据库简单操作
登录mysql
- mysql -u root -p
- 输入密码:root
显示数据库列表:show databases;
建库与删库:create databases 库名; drop databases 库名;
使用库、建表、删表:use 库名; create table 表名(字段列表); drop table 表名;
查看表结构:desc 表名;
数据库表的增删查改操作
向所有字段插入
语法:insert into 表名(列1,列2,列3...) values(值1,值2,值3...); 示例:create table stu( id int(10) primary key, name varchar(10), score float ); insert into stu(id,name,score) values (2,"Lili",98.5); insert into stu(id,name,score) values (3,"wangge",95.3);
向指定字段插入
语法:insert into 表名(指定字段集合) values (指定字段值) 示例:alter table stu modify id int auto_increment; insert into stu(name,score) values ("heshao",96.8);
修改数据
语法:update 表名 set 字段1=值,字段2=值...; 示例:update stu set name="java" where 筛选;
删除数据
语法:delete from 表名 【where 筛选】 【order by 筛选】【limit 筛选】 示例:delete from stu where id=1;
查询数据
语法:查询所有字段和部分字段 示例:select * from stu; select name,score from stu; 使用distinct去除重复数据 语法:select distinct 字段名 from 表名; 使用limit指定查询结果的行数 语法:select 字段名 from 表名 limit 数字; 使用order by对结果进行排序 order by 字段名 【ASC|DESC】 select * from stu order by score desc; 使用where进行条件查询
多表联合查询(表连接的方式)
常用术语:
- 冗余:存储两次数据,以便使系统更快速。
- 主键:主键是唯一的,同一张表中不允许出现同样的两个键值。
- 外键:用于连接两张表
表连接的方式
- 内连接
- 外连接
- 自连接
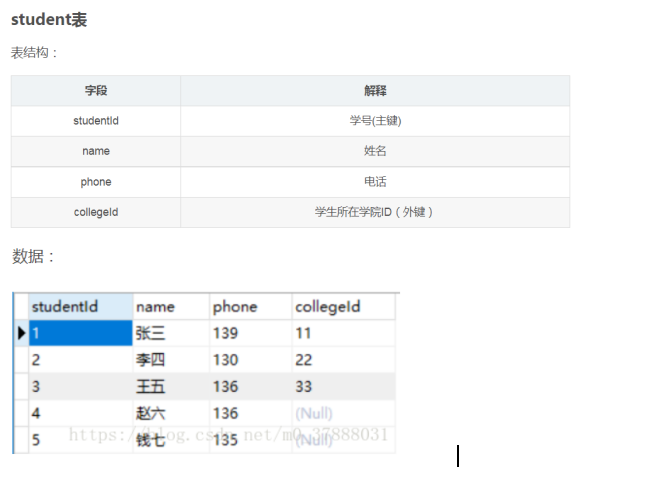
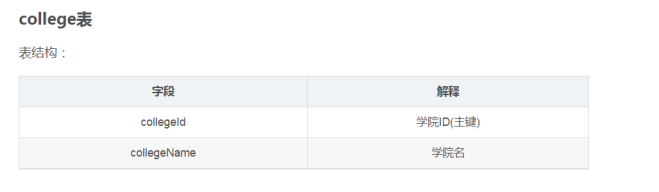
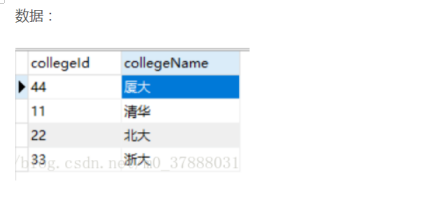
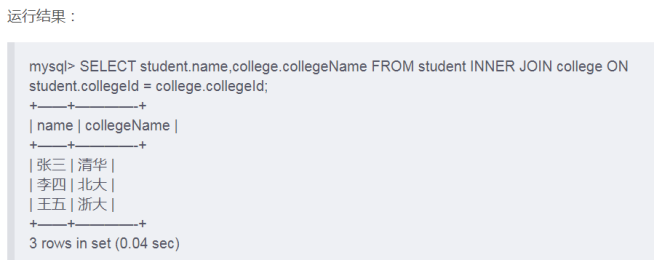
内连接
内连接就是表间的主键和外键相连,只取得键值一致的。语法如下:
select 列名1,列名2...from 表1 inner join 表2 on 表1.外键=表2.主键 where 条件语句;
外连接
与取得双方表中数据的内连接相比,外连接只能取得其中一方存在的数据,外连接又分为左连接和右连接。
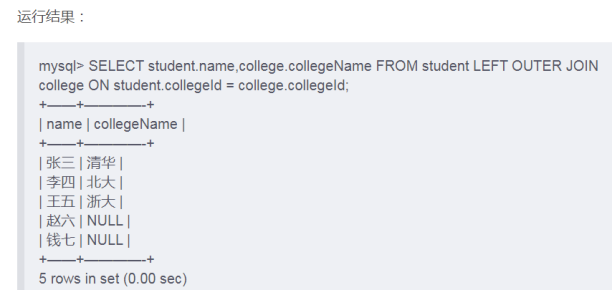
左外连接
当然需要两个表中的键值一致。语法如下:
select 列名1 from 表1 left outer join 表2 on 表1.外键=表2.主键 where 条件语句;
右外连接
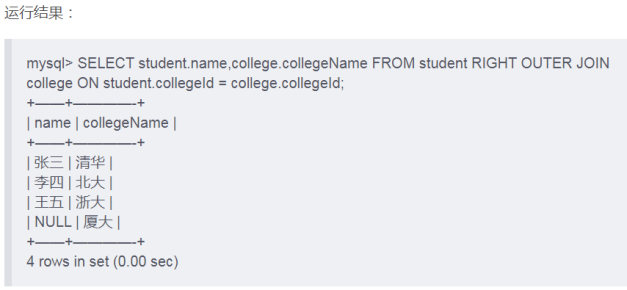
同理,右连接将会以右边作为基准,进行检索。语法如下:
select 列名1 from 表1 right outer join 表2 on 表1.外键=表2.主键 where 条件语句;
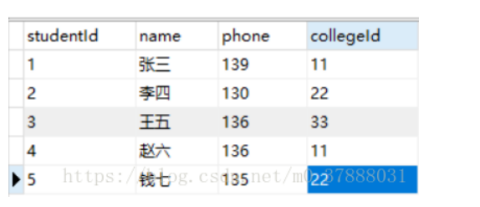
自连接
自己跟自己连接,有意义。

子查询
通常我们在查询的SQL中嵌套查询,称为子查询。子查询通常会使复杂的查询变得简单,但是相关的子查询要对基础表的每一条数据都进行子查询的动作,所以当表单中数据过大时,一定要慎重选择。
语法如下:
SELECT 列名1 ...FROM 表名 WHERE 列名 比较运算符 (SELECT 命令);

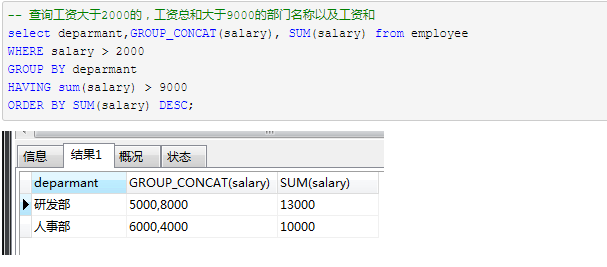
SQL分组查询GroupBy + Having
- group by + having 用来分组查询后指定一些条件来输出查询结果
- having 和 where 一样,但 having 只能用于 group by
having 和 where 的区别:
- having 是在分组后对数据进行过滤,where 是在分组前对数据进行过滤
- having后面可以使用分组函数(统计函数),where后面不可以使用分组函数
- where 是对分组前记录的条件,如果某行记录没有满足where字句的条件,那么这行记录不会参加分组;而 having是对分组后数据的约束

一.索引的作用
在创建索引时,需要考虑哪些列会用于 SQL 查询,然后为这些列创建一个或多个索引。事实上,索引也是一种表,保存着主键或索引字段,以及一个能将每个记录指向实际表的指针。数据库用户是看不到索引的,它们只是用来加速查询的。数据库搜索引擎使用索引来快速定位记录。
INSERT 与 UPDATE 语句在拥有索引的表中执行会花费更多的时间,而SELECT 语句却会执行得更快。这是因为,在进行插入或更新时,数据库也需要插入或更新索引值。
索引的类型:
- UNIQUE(唯一索引):索引列中的值必须是唯一的,但是允许为空值
- INDEX(普通索引):MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
- PRIMARY(主键索引):是一种特殊的唯一索引,不允许有空值
- 组合索引:一个的索引包含多个列
- fulltext index(全文索引)
创建索引
(1)使用ALTER TABLE语句创建索性(应用于表创建完毕之后再添加。)
ALTER TABLE 表名 ADD 索引类型 (unique,primary key,fulltext,index)[索引名](字段名)

(2) 使用CREATE INDEX语句对表增加索引(CREATE INDEX可用于对表增加普通索引或UNIQUE索引,可用于建表时创建索引。)

为了进一步榨取mysql的效率,就可以考虑建立组合索引,即将LOGIN_NAME,CITY,AGE建到一个索引里:
ALTER TABLE USER_DEMO ADD INDEX name_city_age (LOGIN_NAME(16),CITY,AGE);
(3) 删除索引( 删除索引可以使用ALTER TABLE或DROP INDEX语句来实现。)

(4)查看表的创建;
show create table book;

(5) 用explain关键字,来查看索引是否正在被使用,并且输出其使用的索引信息
explain select * from book where author="nana";

二.视图
1、什么是视图
视图就是通过查询得到的一张虚拟表,然后保存下来,下次直接使用即可
2、为什么要用视图
如果要频繁的使用一张虚拟表,可以不用重复查询

就像查询表数据一样,使用视图。
强调:
1、在硬盘中,视图只有表结构,没有表数据文件
2、视图通常是用于查询,尽量不要修改视图中的数据
三.存储过程
-
1、什么是存储过程
- 存储过程包含了一系列可执行的sql语句,存储过程中存放于mysql中,通过调用它的名字可以执行其内部的一堆sql。
- 存储过程跟编程时的函数没有什么区别,只是运用的地方不同而已,存储过程运用在数据库系统中,通过sql调用,创建一个存储过程就相当于创建了一个sql函数,可以传入参数(当然肯定也能没有参数)实现某种特定的功能。这其中有一点小差异那就是:编程时函数传入的参数都是输入参数(特意强调输入参数是为了和存储过程的参数作区分),函数执行完后会有一个返回值;而存储过程中申明时既要指定输入参数,也要指定输出参数(前提是有必要用到)。
不带参数的存储过程
#指定界定符(因为;是mysql默认的语句结束符,而存储过程中需要一组语句同时执行,所以需重新指定界定符号) DELIMITER ;; #创建存储过程 CREATE PROCEDURE my_test() #存储过程体 BEGIN #申明变量 DECLARE test_name VARCHAR(100); #给变量赋值 SET test_name= 'my_test'; #执行插入操作 INSERT INTO `test_pro`(`test_name`) VALUES(test_name); END;; #恢复mysql默认界定符 DELIMITER;
调用存储过程时采用 call 存储过程名称 的语法,执行 call my_test();
带输入参数的存储过程
MySQL 支持 in (传递给存储过程),out (从存储过程传出) 和 inout (对存储过程传入和传出) 类型的参数。
存储过程的代码位于 begin 和 end 语句内,它们是一系列 select 语句,用来检索值,然后保存到相应的变量 (通过 into 关键字)
-- 根据姓名查询学生信息,返回学生的城市
delimiter ;;
create procedure select_students_by_name(
in _name varchar(255),
out _city varchar(255), -- 输出参数
inout _age int(11)
)
begin
select city from students where name = _name and age = _age into _city;
end ;;
delimiter ;执行存储过程:
set @_age = 20; set @_name = 'jack'; call select_students_by_name(@_name, @_city, @_age); select @_city as city, @_age as age;
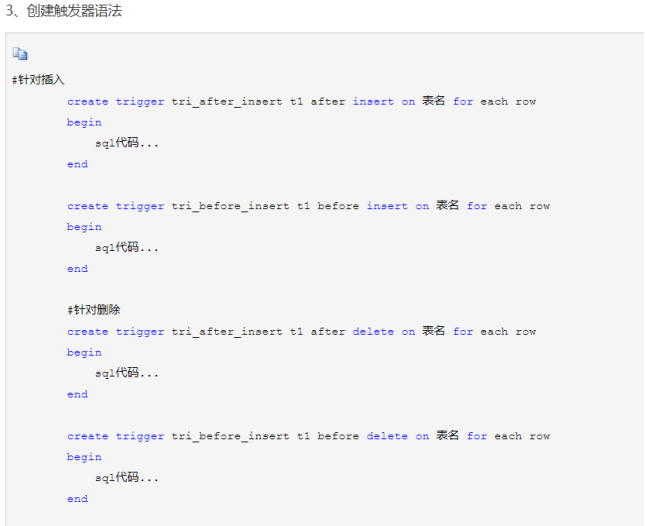
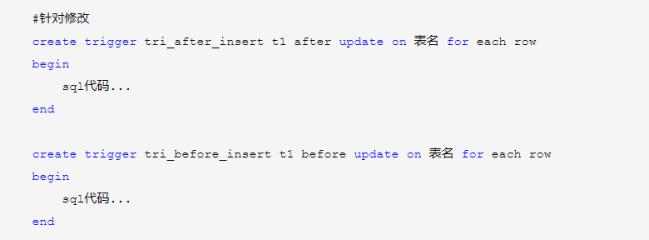
四.触发器
触发器尽量少的使用,因为不管如何,它还是很消耗资源,如果使用的话要谨慎的使用,确定它是非常高效的:触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。
五.事务
1、什么是事务
开启一个事务可以包含一些sql语句,这些语句要么同时成功,
要么一个都别想成功,这个特性称为事务的原子性
2、事务的作用
用于设计转账接口的时候使用

- 一、事务的基本要素(ACID)
- 1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
- 2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
- 3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
- 4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
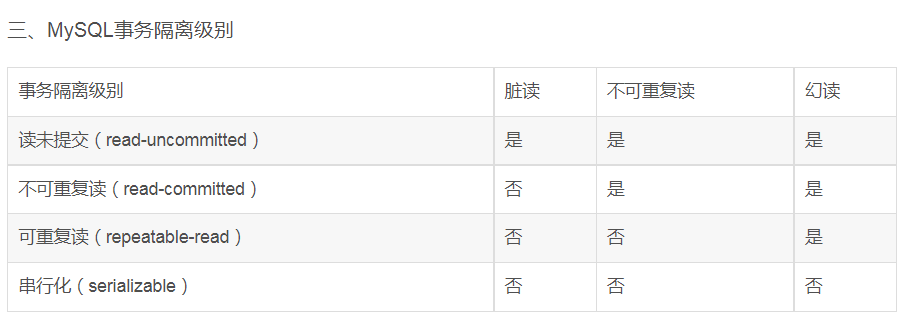
- 二、事务的并发问题
- 1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
- 2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
- 3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
- 小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
![]()
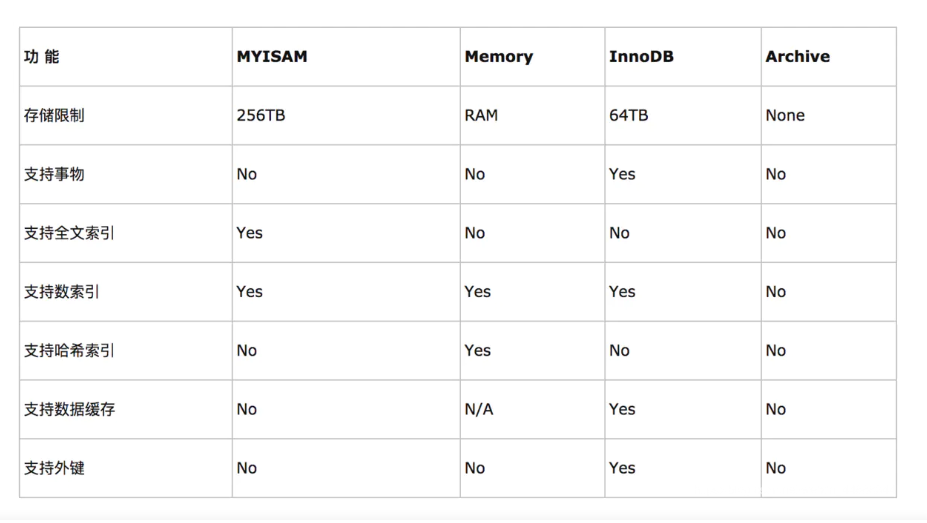
MySql四种搜索引擎的区别(数据库引擎是用于 存储、处理和保护数据的核心服务)
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号