
03 Linux与Hadoop操作实验
(一)熟悉常用的Linux操作
请按要求上机实践如下linux基本命令。
cd命令:切换目录
(1)切换到目录 /usr/local

(2)去到目前的上层目录

(3)回到自己的主文件夹

ls命令:查看文件与目录
(4)查看目录/usr下所有的文件

mkdir命令:新建新目录
(5)进入/tmp目录,创建一个名为a的目录,并查看有多少目录
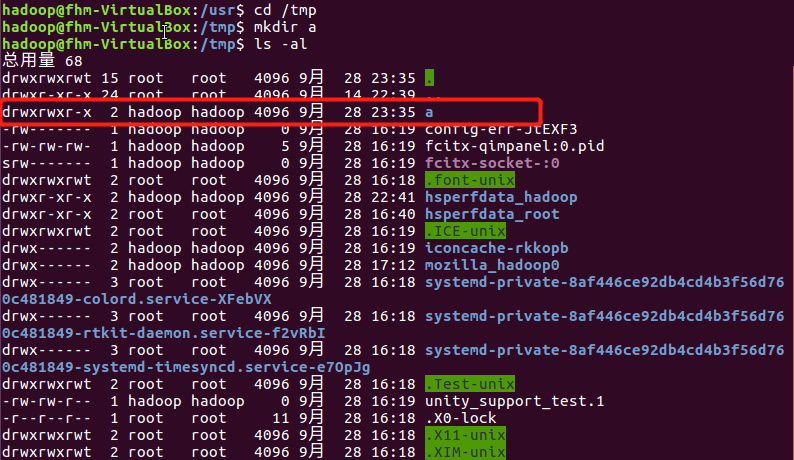
(6)创建目录a1/a2/a3/a4

rmdir命令:删除空的目录
(7)将上例创建的目录a(/tmp下面)删除

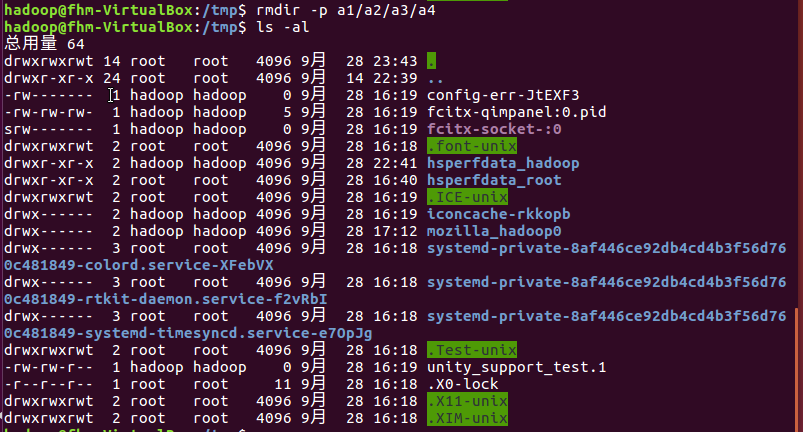
(8)删除目录a1/a2/a3/a4,查看有多少目录存在
cp命令:复制文件或目录
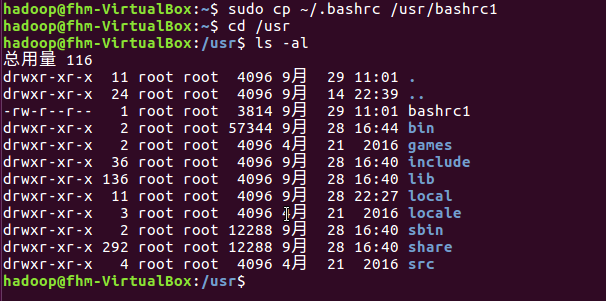
(9)将主文件夹下的.bashrc复制到/usr下,命名为bashrc1
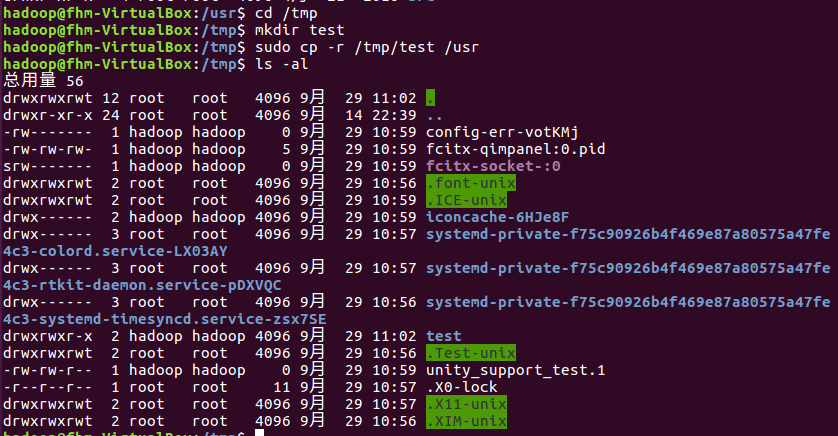
(10)在/tmp下新建目录test,再复制这个目录内容到/usr
mv命令:移动文件与目录,或更名
(11)将上例文件bashrc1移动到目录/usr/test

(12)将上例test目录重命名为test2

rm命令:移除文件或目录
(13)将上例复制的bashrc1文件删除

(14)将上例的test2目录删除

cat命令:查看文件内容
(15)查看主文件夹下的.bashrc文件内容
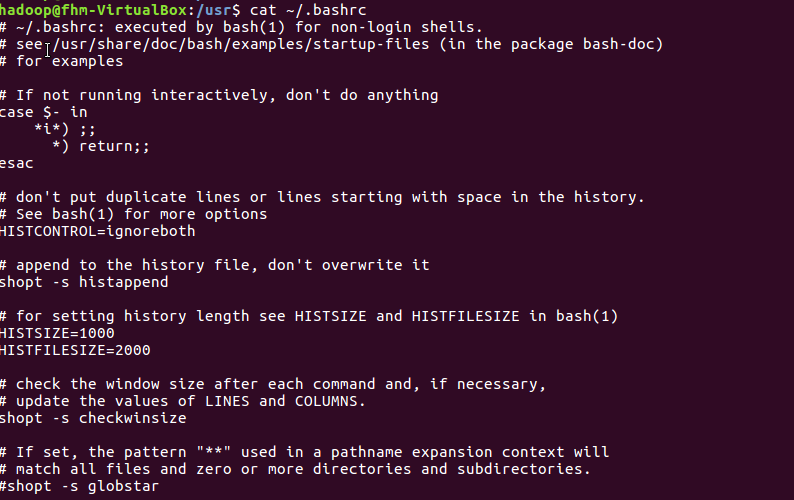
tac命令:反向列示
(16)反向查看主文件夹下.bashrc文件内容

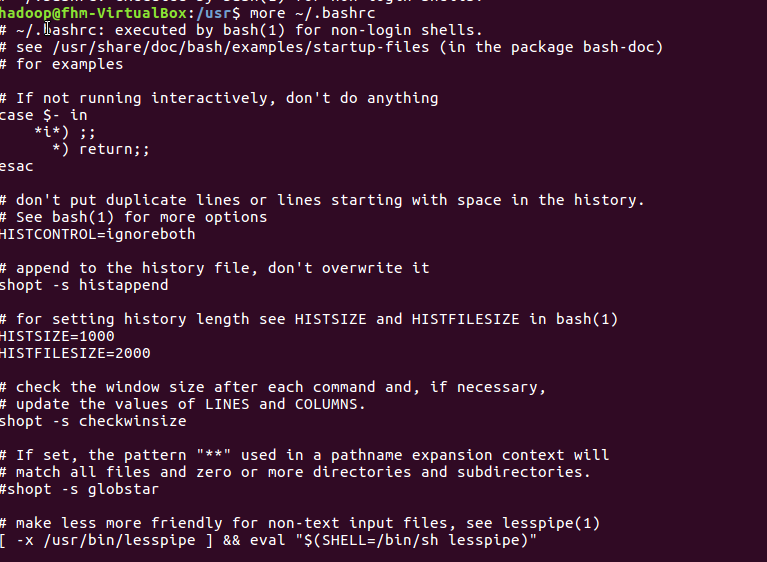
more命令:一页一页翻动查看
(17)翻页查看主文件夹下.bashrc文件内容
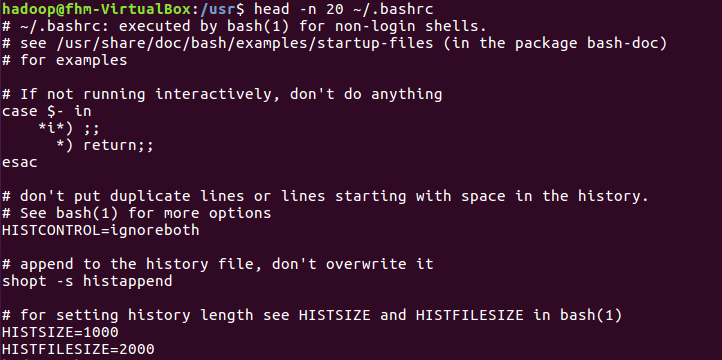
head命令:取出前面几行
(18)查看主文件夹下.bashrc文件内容前20行
(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行
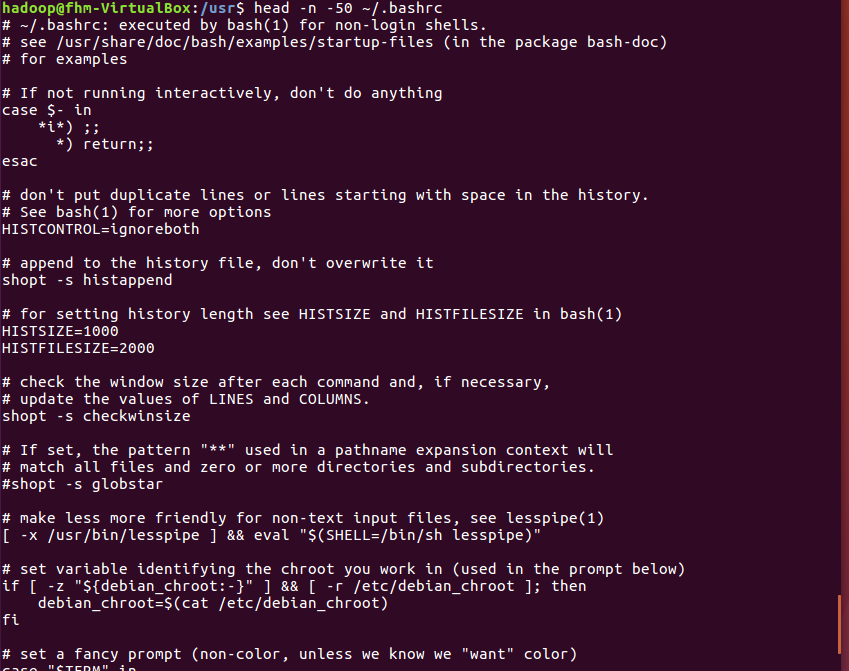
tail命令:取出后面几行
(20)查看主文件夹下.bashrc文件内容最后20行
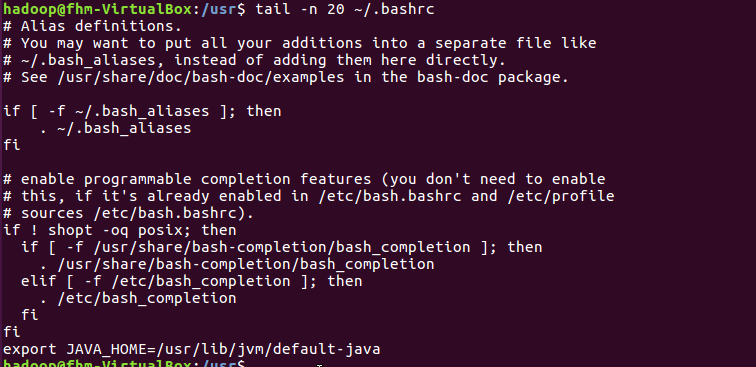
(21)查看主文件夹下.bashrc文件内容,只列出50行以后的数据
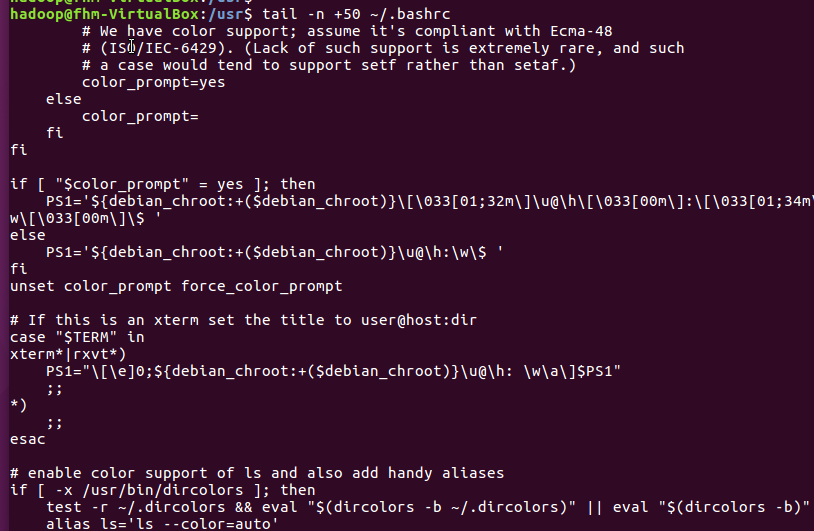
chown命令:修改文件所有者权限
(22)将hello文件所有者改为root帐号,并查看属性
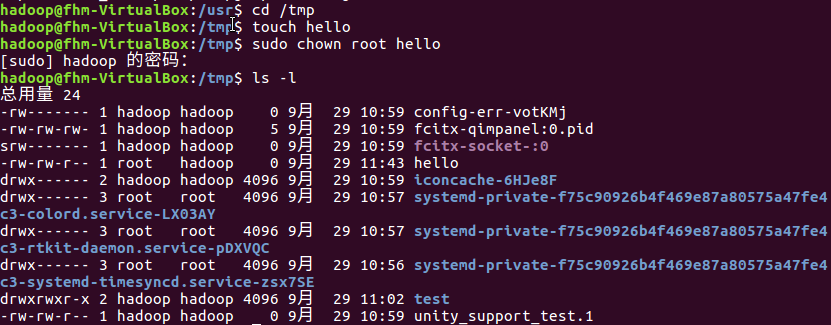
Vim/gedit/文本编辑器:新建文件
(23)在主文件夹下创建文本文件my.txt,输入文本保存退出。

步骤:首先在主文件夹下创建文本文件my.txt.,打开文件后,输入i/a进入编辑状态。
输入文本,然后按esc键退出编辑模式,返回命令模式。最后按:wq和回车键,退出并保存文本内容。
结果如下图:
tar命令:压缩命令
(24)将my.txt打包成test.tar.gz

(25)解压缩到~/tmp目录

(二)熟悉使用MySQL shell操作
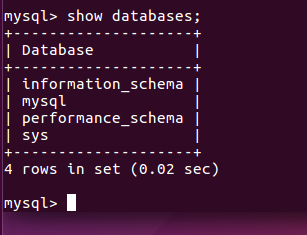
(26)显示库:show databases;
(27)进入到库:use 库名;

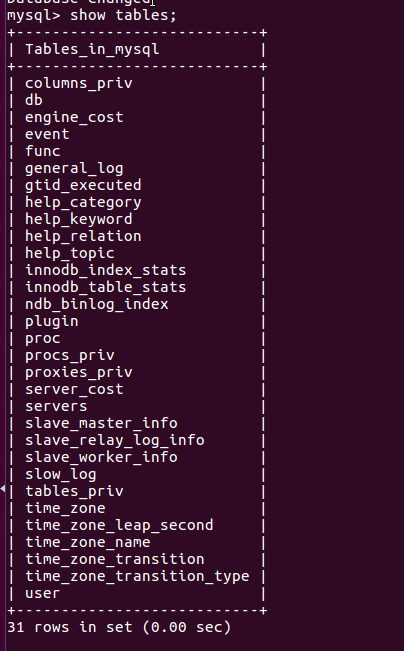
(28)展示库里表格:show tables;
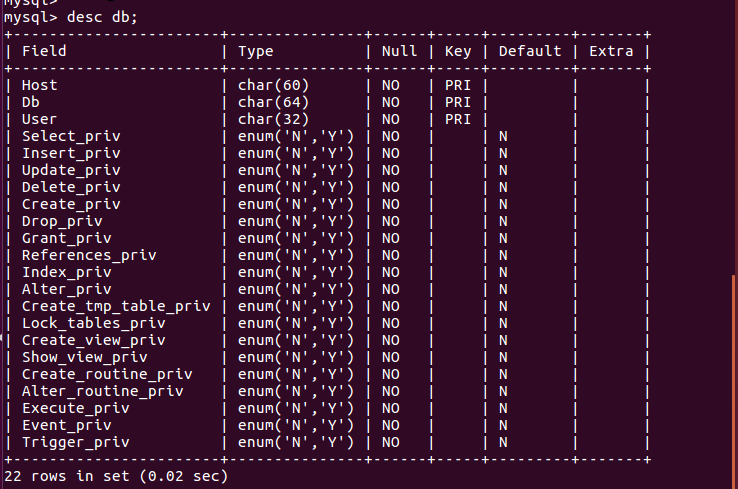
(29)显示某一个表格属性:desc 表格名;
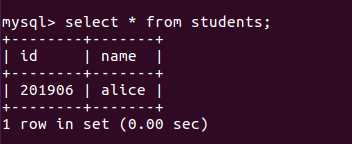
(30)显示某一个表格内的具体内容:select *form 表格名;

(31)创建一个表格:create table if not exists 表格名(名);


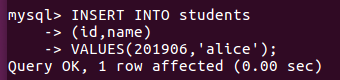
(32)向某一个表格中插入具体内容:insert into 表格名(名)values(value);
插入记录包含自己的学号姓名。
(33)显示表的内容。
(三)熟悉Hadoop及其操作
34.对比操作三个文件系统:分别用命令行与窗口方式查看windows,Linux和Hadoop文件系统的用户主目录。
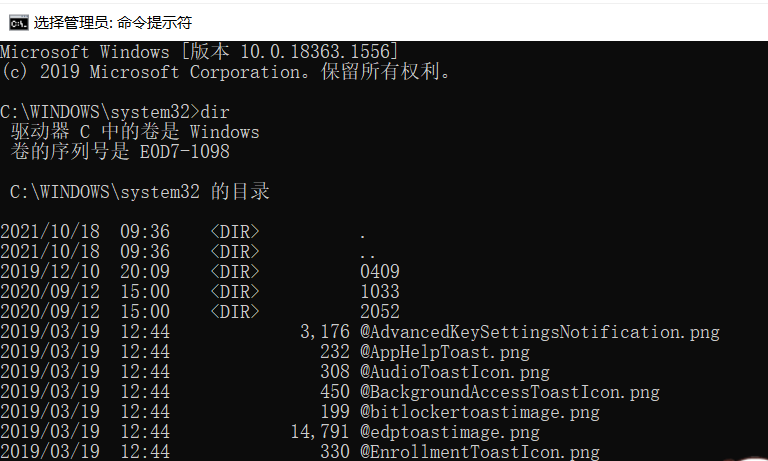
(1)windows文件系统的用户主目录
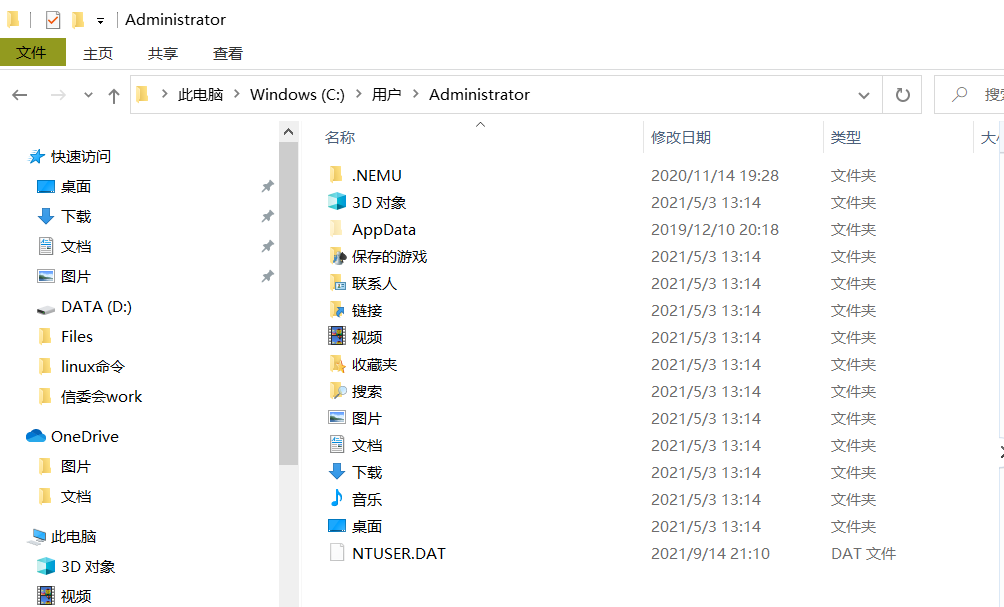
(2)Linux文件系统的用户主目录


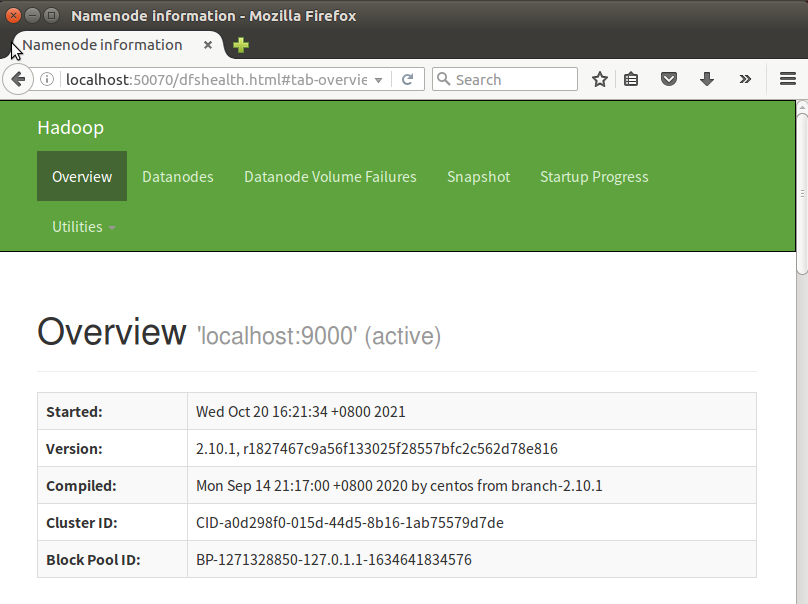
(3)Hadoop文件系统的用户主目录

35.一个操作案例:
(1)启动hdfs

(2)查看与创建hadoop用户目录。

(3)在用户目录下创建与查看input目录

(4)将hadoop的配置文件上传到hdfs上的input目录下。

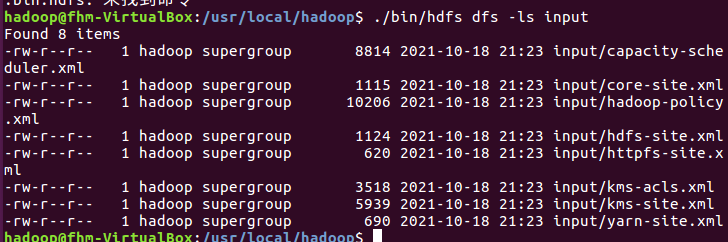
(5)运行MapReduce示例作业,输出结果放在output目录下。


(6)查看output目录下的文件

(7)将输出结果文件下载到本地

(8)查看下载的本地文件
(9)停止hdfs

36.设置Hadoop环境变量,在本地用户主目录下启动hdfs,查看hdfs用户主目录,停止hdfs。
Hadoop运行程序时,输出目录不能存在,否则会提示错误。因此若要再次执行,需要执行如下命令删除output文件夹。

配置环境变量,hdfs命令不用带路径
(1)打开配置文件:


(2)让配置文件生效,在本地用户主目录下启动hdfs:
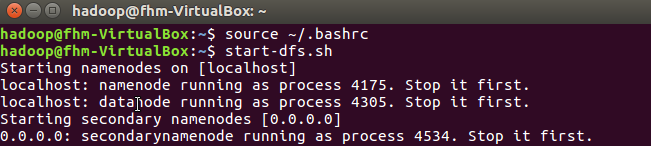
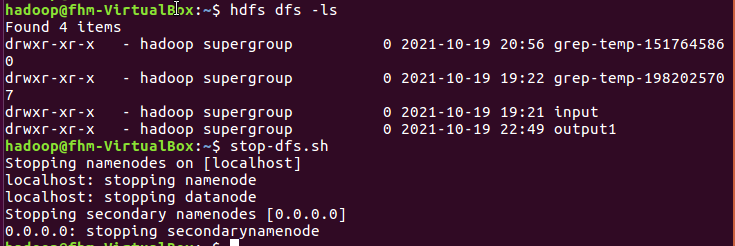
(3)hdfs启停与dfs命令不用带路径:
其实在安装hadoop时遇到很多问题,但最终找到办法解决了。下列列举我安装过程中遇到的问题:
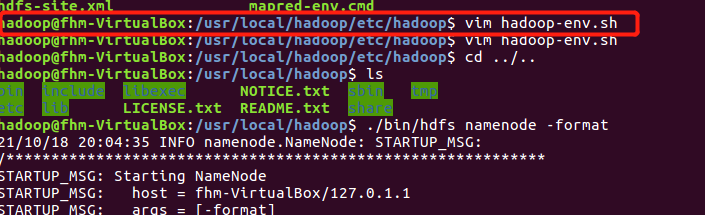
(1)Hadoop在执行start-dfs.sh命令出现Error:JAVA_HOME is not set and could not be found
解决办法:
在/usr/local/hadoop/etc/hadoop里的hadoop-env.sh文件里把java路径设置成之前在/.bashrc文件里的JAVA_HOME环境变量。

(2)Hadoop在执行start-dfs.sh命令需要输入密码,原因是没有配置ssh无密码登录。
解决办法:
参考博文步骤4、配置无密码登录。
https://www.cnblogs.com/amnotgcs/p/12694407.html
(3)Hadoop运行MapReduce示例作业,显示“无法分配内存”的问题,原因是虚拟机内部内存不够。
解决办法:
参考博文把虚拟机内部交换空间增大就可以使用了。
https://www.cnblogs.com/zhshan/p/13824614.html
注意切换到超级用户 (sudo su) 设置交换空间的内存,并且不能够设置太大,否则不能够设置。
设置交换空间的内存大小可以参考博文。
https://segmentfault.com/a/1190000022620410


(4)另外执行过多NameNode的格式化,也会造成运行MapReduce作业会出现java拒绝连接的问题。
查看jsp,发现DataNode不能够启动。
解决办法:

执行完以上的语句后,并再一次执行NameNode的格式化和开启NameNode和DataNode守护进程就可以运行成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号