


python 小知识点
浅析python 中__name__ = '__main__' 的作用
很多新手刚开始学习python的时候经常会看到python 中__name__ = \'__main__\' 这样的代码,可能很多新手一开始学习的时候都比较疑惑,python 中__name__ = '__main__' 的作用,到底干嘛的?
有句话经典的概括了这段代码的意义:
“Make a script both importable and executable”
意思就是说让你写的脚本模块既可以导入到别的模块中用,另外该模块自己也可执行。
这句话,可能一开始听的还不是很懂。下面举例说明:
先写一个模块:
|
1
2
3
4
5
|
#module.pydef main(): print "we are in %s"%__name__if __name__ == '__main__': main() |
这个函数定义了一个main函数,我们执行一下该py文件发现结果是打印出”we are in __main__“,说明我们的if语句中的内容被执行了,调用了main():
但是如果我们从另我一个模块导入该模块,并调用一次main()函数会是怎样的结果呢?
|
1
2
3
|
#anothermodle.pyfrom module import mainmain() |
其执行的结果是:we are in module
但是没有显示”we are in __main__“,也就是说模块__name__ = '__main__' 下面的函数没有执行。
这样既可以让“模块”文件运行,也可以被其他模块引入,而且不会执行函数2次。这才是关键。
总结一下:
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!
Python 变量、地址、id、is与==
一、简介
本篇主要介绍Python作为一种动态语言的动态特点、Python的变量保存、以及id()函数和is()函数和==操作符之间爱恨纠缠的关系。
二、动态语言
首先所谓的动态语言、静态语言,其实就是针对变量的类型而言的。
静态语言比较常见的如Java和C#,你在定义变量的时候就得说好了它是啥类型如:int num;
动态语言就不必,为啥不必呢,因为无所谓啊。动态语言的变量可以随时改变类型哦,比如:
a=1#此时a是一个整数类型
a=0.1#变成了浮点数类型
a="Hello"#又变成了字符串类型
OK,那么好像看起来,动态语言更灵活,更牛逼一点。是的,是更灵活,但是既然要到运行的时候才能确定怎么存储、使用这些变量,肯定会在某些方面(比如性能)上有弱点吧,金无赤足,各有所长嘛。
三、Python变量的保存
那么看似牛X的Python变量是如何可以切换类型的呢,其实真正牛的不是Python变量,而是Python语言的解释执行器。
举个例子如下,解释器可以这么运作。首先在内存中地址为XXXX的地方存了一个变量1,然后运行到a=1时,发现整数1要赋值给变量a,所以解释器就知道了啊哈变量a是整型,然后a其实保存的是地址XXXX。
然后运行到a=0.1,解释执行器在内存中地址为YYYY的地方存了0.1,然后知道了啊哈a是浮点类型,然后a保存的地址变为了YYYY。
a=1
a=0.1既然解释器每次在保存变量值(指向地址)时,都要识别值得类型并关联到变量,所以效率肯定会低一点吧。(如果解释执行器是这么运作的话,Python可是有不止一种解释执行器,所以也得看开发解释执行器的人的设计啦)。
四、id() is() 与 ==
id()函数非常好理解,就是求变量地址,例子如下,注意同样是值1,可能对应的地址是不同的,因为在内存为1分配地址时分配了不同地址。
a=1
print(id(a))#输出3543160
了解了id(),那么is()和==的区别就好理解了。==就是看值相等不,相等就返回True。而is()就是看id相等不,相等就返回True。
举个例子:
a=1
b=1.0
a==b#True,值就是相等哦
a is b#False,地址肯定不一样
c=1
a is c#True,这个应该看解释器了,如果解释器为常量1分配一样的地址就相等了,也有可能解释器特殊喜欢分配不同地址。

如图,为什么有的相同,有的不同,原因是什么,有没有阈值
Python 解释器对于数字有个小数字缓存池:-5~256, 原因是:地址数据最少是32位的,现在都是64位了,如果单独为一个小整数创建一个对象,10个地方用到这个小整数,那么就会在内存中创建10个存储的内存地址的空间,地址占用的数据长度比数据本身还大这样非常不划算。而有这个缓存池,python解释器内部就会共享这个小整数对象,不去开内存空间。从而减少内存的使用率,降低浪费。)
字符串也有内存池,给了2k空间,python内部有算法,按照内部权重排列,如果级别高了就把你放入内存。列表、字典都有。
楼上说的比较清楚了,python会提前分配一些常用的值来提高效率,具体可以看《Python 源码剖析》
Python中值相同的不同变量在内存中的地址相同吗?
a=333
b=333
id(a)-->41374624L
id(b)-->41374600L
我用的是2.7版本的,结果不一致。但是我看视频上说这个地址值应该相等!!
这个跟java完全不一样啊。。。
希望有懂Python的帮忙解惑
整数id相等是因为Python内部对较小的整数做了缓存,印象里应该是-128~127,不太确定。但超出范围的整数就没有缓存了,因此大的数值id不相等是正常的。
Python中函数的参数传递与可变长参数
1.Python中也有像C++一样的默认缺省函数
1 def foo(text,num=0):
2 print text,num
3
4 foo("asd") #asd 0
5 foo("def",100) #def 100
定义有默认参数的函数时,这些默认值参数位置必须都在非默认值参数后面。
调用时提供默认值参数值时,使用提供的值,否则使用默认值。
2.Python可以根据参数名传参数
1 def foo(ip,port):
2 print "%s:%d" % (ip,port)
3
4 foo("192.168.1.0",3306) #192.168.1.0:3306
5 foo(port=8080,ip="127.0.0.1") #127.0.0.1:8080
第4行,没有指定参数名,按照顺序传参数。
第5行,指定参数名,可以按照参数名称传参数。
3.可变长度参数

1 #coding:utf-8 #设置python文件的编码为utf-8,这样就可以写入中文注释
2 def foo(arg1,*tupleArg,**dictArg):
3 print "arg1=",arg1 #formal_args
4 print "tupleArg=",tupleArg #()
5 print "dictArg=",dictArg #[]
6 foo("formal_args")
上面函数中的参数,tupleArg前面“*”表示这个参数是一个元组参数,从程序的输出可以看出,默认值为();dicrtArg前面有“**”表示这个字典参数(键值对参数)。可以把tupleArg、dictArg看成两个默认参数。多余的非关键字参数,函数调用时被放在元组参数tupleArg中;多余的关键字参数,函数调用时被放字典参数dictArg中。
下面是可变长参数的一些用法:
1 #coding:utf-8 #设置python文件的编码为utf-8,这样就可以写入中文注释
2 def foo(arg1,arg2="OK",*tupleArg,**dictArg):
3 print "arg1=",arg1
4 print "arg2=",arg2
5 for i,element in enumerate(tupleArg):
6 print "tupleArg %d-->%s" % (i,str(element))
7 for key in dictArg:
8 print "dictArg %s-->%s" %(key,dictArg[key])
9
10 myList=["my1","my2"]
11 myDict={"name":"Tom","age":22}
12 foo("formal_args",arg2="argSecond",a=1)
13 print "*"*40
14 foo(123,myList,myDict)
15 print "*"*40
16 foo(123,rt=123,*myList,**myDict)
输出为:

从上面的程序可以看出:
(1)如代码第16行。
参数中如果使用“*”元组参数或者“**”字典参数,这两种参数应该放在参数列表最后。并且“*”元组参数位于“**”字典参数之前。
关键字参数rt=123,因为函数foo(arg1,arg2="OK",*tupleArg,**dictArg)中没有rt参数,所以最后也归到字典参数中。
(2)如代码第14行。
元组对象前面如果不带“*”、字典对象如果前面不带“**”,则作为普通的对象传递参数。
多余的普通参数,在foo(123,myList,myDict)中,123赋给参数arg1,myList赋给参数arg2,多余的参数myDict默认为元组赋给myList。
>>> foo(123,456,*myList,**myDict)
arg1= 123
arg2= 456
tupleArg 0-->my1
tupleArg 1-->my2
dictArg age-->22
dictArg name-->Tom
>>> foo(123,456,*('xx','yy'),**myDict)
arg1= 123
arg2= 456
tupleArg 0-->xx
tupleArg 1-->yy
dictArg age-->22
dictArg name-->Tom
foo(123,rt=123,*myList,**myDict) 等同于:
foo(123,rt=123,"my1","my2","name"="Tom","age"=22)
123为第一个参数arg1,"my1"作为第二个参数赋给arg2
单星号形式(*args)用来传递非命名键可变参数列表。双星号形式(**kwargs)用来传递键值可变参数列表。
下面的例子,传递了一个固定位置参数和两个变长参数。
|
1
2
3
4
5
6
|
def test_var_args(farg, *args): print "formal arg:", farg for arg in args: print "another arg:", argtest_var_args(1, "two", 3) |
结果如下:
|
1
2
3
|
formal arg: 1another arg: twoanother arg: 3 |
这个例子用来展示键值对形式的可变参数列表,一个固定参数和两个键值参数。
|
1
2
3
4
5
6
|
def test_var_kwargs(farg, **kwargs): print "formal arg:", farg for key in kwargs: print "another keyword arg: %s: %s" % (key, kwargs[key])test_var_kwargs(farg=1, myarg2="two", myarg3=3) |
执行结果:
|
1
2
3
|
formal arg: 1another keyword arg: myarg2: twoanother keyword arg: myarg3: 3 |
调用函数时,使用 *args and **kwargs
这种语法不仅仅是在函数定义的时候可以使用,调用函数的时候也可以使用
|
1
2
3
4
5
6
7
|
def test_var_args_call(arg1, arg2, arg3): print "arg1:", arg1 print "arg2:", arg2 print "arg3:", arg3args = ("two", 3)test_var_args_call(1, *args) |
执行结果如下:
|
1
2
3
|
arg1: 1arg2: twoarg3: 3 |
键值对方式:
|
1
2
3
4
5
6
7
|
def test_var_args_call(arg1, arg2, arg3): print "arg1:", arg1 print "arg2:", arg2 print "arg3:", arg3kwargs = {"arg3": 3, "arg2": "two"}test_var_args_call(1, **kwargs) |
结果如下:
|
1
2
3
|
arg1: 1arg2: twoarg3: 3 |
python 引用和拷贝
一、python中的变量与对象、可变对象和不可变对象:
a = 3 #创建 int对象 3,创建变量a, 变量a指向对象3
a = "test" #创建string对象,变量a指向对象"test"
对象:可变对象和不可变对象,不可变对象包括int,float,long,str,tuple等,可变对象包括list,set,dict等。
需要注意的是:这里说的不可变指的是对象值的不可变。
(1)、对于不可变类型的对象,如果要更改变量,则会创建一个新值,把变量绑定到新的对象上,而旧值如果没有被引用就等待垃圾回收。
(2)、可变类型数据对对象操作的时候,不需要再在其他地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的内存地址会保持不变,但区域会变长或者变短。
举例说明:
# 重新赋值之后,变量a的内存地址已经变了
# 'hello'是str类型,不可变,所以赋值操作重新创建了str 对象 'world'对象,然后将变量a指向了它
# list重新赋值之后,变量lst的内存地址并未改变
# [1, 2, 3]是可变的,append操作只是改变了其value,变量lst指向没有变
二、变量无类型,对象有类型
总结来说:在Python中,类型是属于对象的,而不是变量, 变量和对象是分离的,对象是内存中储存数据的实体,变量则是指向对象的指针。
三、python引用
python一般内部赋值变量的话,都是传个引用变量,和C语言的传地址的概念差不多,
比如:
a = [1,2,3] 表示变量a保存了这个列表的地址
python里可以用id()来查询下 a在内存的地址是:675375852
b = a
那b的内容是什么,地址又是什么呢?用print 输出下b的内容也是[1,2,3]
然后我们查看下b的地址看下能否验证我们的结论
print id(b)
果然b的地址也是:675375852
这样会带来一个问题,因为变量a,和变量b都是保存了同一个列表的地址。如果我改变a指向的列表的值的话,那b指向的列表的值也同时改变
比如: a[1] = 6
print a
输出的内容是[1,6,3]
print b
b指向的列表的内容也是[1,6,3]
如果我们只想修改a列表里面的内容。而不想修改b的内容,那就要用到python的拷贝了
a=[1,2,3]
b=a[:] ###拷贝了一份a的内容给b
a[1]=6
print a
输出a的内容是[1,6,3]
而b的内容不是[1,6,3]
而是[1,2,3]
四、函数值传递
先看一个例子:
- def func_int(a):
- a += 4
- def func_list(lst):
- lst[0] = 4
- t = 0
- func_int(t)
- print t
- # output: 0
- t_list = [1, 2, 3]
- func_list(t_list)
- print t_list
- # output: [4, 2, 3]
主要是因为可变对象和不可变对象的原因:对于可变对象,对象的操作不会重建对象,而对于不可变对象,每一次操作就重建新的对象。
在函数参数传递的时候,Python其实就是把参数里传入的变量对应的对象的引用依次赋值给对应的函数内部变量。参照上面的例子来说明更容易理解,func_int中的局部变量"a"其实是全部变量"t"所指向对象的另一个引用,由于整数对象是不可变的,所以当func_int对变量"a"进行修改的时候,实际上是将局部变量"a"指向到了整数对象"1"。所以很明显,func_list修改的是一个可变的对象,局部变量"a"和全局变量"t_list"指向的还是同一个对象。
五、浅拷贝 & 深拷贝
接下来的问题是:如果我们一定要复制一个可变对象的副本怎么办?简单的赋值已经证明是不可行的,所以Python提供了copy模块,专门用于复制可变对象。
copy中有两个方法:copy()和deepcopy(),前一个是浅拷贝,后一个是深拷贝。
浅拷贝仅仅复制了第一个传给它的对象,下面的不管了;而深拷贝则将所有能复制的对象都复制了。
下面是一个例子:
- import copy
- a = [[1, 2, 3], [4, 5, 6]]
- b = a
- c = copy.copy(a)
- d = copy.deepcopy(a)
- a.append(15)
- a[1][2] = 10
- print a
- print b
- print c
- print d
输出结果:
六、作用域
在Python程序中创建、改变或查找变量名时,都是在一个保存变量名的地方进行中,那个地方我们称之为命名空间。作用域这个术语也称之为命名空间。
变量名引用分为三个作用域进行查找:首先是本地,然后是函数内(如果有的话),之后是全局,最后是内置。在默认情况下,变量名赋值会创建或者改变本地变量。全局声明将会给映射到模块文件内部的作用域的变量名赋值。Python 的变量名解析机制也称为 LEGB 法则,具体如下:
当在函数中使用未确定的变量名时,Python搜索4个作用域:本地作用域(L),之后是上一层嵌套结构中 def 或 lambda 的本地作用域(E),之后是全局作用域(G),最后是内置作用域(B)。按这个查找原则,在第一处找到的地方停止。如果没有找到,Python 会报错的。
参考博文: https://my.oschina.net/leejun2005/blog/145911
详解Python中的__new__、__init__、__call__三个特殊方法
__new__: 对象的创建,是一个静态方法,第一个参数是cls。(想想也是,不可能是self,对象还没创建,哪来的self)
__init__ : 对象的初始化, 是一个实例方法,第一个参数是self。
__call__ : 对象可call,注意不是类,是对象。
先有创建,才有初始化。即先__new__,而后__init__。
上面说的不好理解,看例子。
1.对于__new__
|
1
2
3
4
5
6
7
8
|
class Bar(object): pass class Foo(object): def __new__(cls, *args, **kwargs): return Bar() print Foo() |
可以看到,输出来是一个Bar对象。
__new__方法在类定义中不是必须写的,如果没定义,默认会调用object.__new__去创建一个对象。如果定义了,就是override,可以custom创建对象的行为。
聪明的读者可能想到,既然__new__可以custom对象的创建,那我在这里做一下手脚,每次创建对象都返回同一个,那不就是单例模式了吗?没错,就是这样。可以观摩《飘逸的python - 单例模式乱弹》
定义单例模式时,因为自定义的__new__重载了父类的__new__,所以要自己显式调用父类的__new__,即object.__new__(cls, *args, **kwargs),或者用super()。,不然就不是extend原来的实例了,而是替换原来的实例。
2.对于__init__
使用Python写过面向对象的代码的同学,可能对 __init__ 方法已经非常熟悉了,__init__ 方法通常用在初始化一个类实例的时候。例如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# -*- coding: utf-8 -*-class Person(object): """Silly Person""" def __init__(self, name, age): self.name = name self.age = age def __str__(self): return '<Person: %s(%s)>' % (self.name, self.age)if __name__ == '__main__': piglei = Person('piglei', 24) print piglei |
这样便是__init__最普通的用法了。但__init__其实不是实例化一个类的时候第一个被调用 的方法。当使用 Persion(name, age) 这样的表达式来实例化一个类时,最先被调用的方法 其实是 __new__ 方法。
3.对于__call__
对象通过提供__call__(slef, [,*args [,**kwargs]])方法可以模拟函数的行为,如果一个对象x提供了该方法,就可以像函数一样使用它,也就是说x(arg1, arg2...) 等同于调用x.__call__(self, arg1, arg2) 。模拟函数的对象可以用于创建防函数(functor) 或代理(proxy).
|
1
2
3
4
5
6
|
class Foo(object): def __call__(self): pass f = Foo()#类Foo可call f()#对象f可call |
总结,在Python中,类的行为就是这样,__new__、__init__、__call__等方法不是必须写的,会默认调用,如果自己定义了,就是override,可以custom。既然override了,通常也会显式调用进行补偿以达到extend的目的。
这也是为什么会出现"明明定义def _init__(self, *args, **kwargs),对象怎么不进行初始化"这种看起来诡异的行为。(注,这里_init__少写了个下划线,因为__init__不是必须写的,所以这里不会报错,而是当做一个新的方法_init__)
Python 中的单例模式
单例模式
单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息。如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪费内存资源,尤其是在配置文件内容很多的情况下。事实上,类似 AppConfig 这样的类,我们希望在程序运行期间只存在一个实例对象。
在 Python 中,我们可以用多种方法来实现单例模式:
- 使用模块
- 使用
__new__ - 使用装饰器(decorator)
- 使用元类(metaclass)
使用模块
其实,Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入时,就会直接加载 .pyc 文件,而不会再次执行模块代码。因此,我们只需把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。如果我们真的想要一个单例类,可以考虑这样做:
|
1
2
3
4
5
6
|
# mysingleton.py
class My_Singleton(object):
def foo(self):
pass
my_singleton = My_Singleton()
|
将上面的代码保存在文件 mysingleton.py 中,然后这样使用:
|
1
2
3
|
from mysingleton import my_singleton
my_singleton.foo()
|
使用 __new__
为了使类只能出现一个实例,我们可以使用 __new__ 来控制实例的创建过程,代码如下:
|
1
2
3
4
5
6
7
8
9
|
class Singleton(object):
_instance = None
def __new__(cls, *args, **kw):
if not cls._instance:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kw)
return cls._instance
class MyClass(Singleton):
a = 1
|
在上面的代码中,我们将类的实例和一个类变量 _instance 关联起来,如果 cls._instance 为 None 则创建实例,否则直接返回 cls._instance。
执行情况如下:
|
1
2
3
4
5
6
7
8
|
>>> one = MyClass()
>>> two = MyClass()
>>> one == two
True
>>> one is two
True
>>> id(one), id(two)
(4303862608, 4303862608)
|
使用装饰器
我们知道,装饰器(decorator)可以动态地修改一个类或函数的功能。这里,我们也可以使用装饰器来装饰某个类,使其只能生成一个实例,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from functools import wraps
def singleton(cls):
instances = {}
@wraps(cls)
def getinstance(*args, **kw):
if cls not in instances:
instances[cls] = cls(*args, **kw)
return instances[cls]
return getinstance
@singleton
class MyClass(object):
a = 1
|
在上面,我们定义了一个装饰器 singleton,它返回了一个内部函数 getinstance,该函数会判断某个类是否在字典 instances 中,如果不存在,则会将 cls 作为 key,cls(*args, **kw) 作为 value 存到 instances 中,否则,直接返回 instances[cls]。
使用 metaclass
元类(metaclass)可以控制类的创建过程,它主要做三件事:
- 拦截类的创建
- 修改类的定义
- 返回修改后的类
使用元类实现单例模式的代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
class Singleton(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
return cls._instances[cls]
# Python2
class MyClass(object):
__metaclass__ = Singleton
# Python3
# class MyClass(metaclass=Singleton):
# pass
|
小结
- Python 的模块是天然的单例模式,这在大部分情况下应该是够用的,当然,我们也可以使用装饰器、元类等方法
本文由 funhacks 发表于个人博客,采用 Creative Commons BY-NC-ND 4.0(自由转载-保持署名-非商用-禁止演绎)协议发布。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题为: Python 中的单例模式
本文链接为: https://funhacks.net/2017/01/…
range, xrange, yield(生成器), 协程
1. range, built-in 函数, 传递一个参数时,这个参数赋值给stop,两个参数时,第一个赋值给start,第二个赋值给stop, 返回一个list
def range(start=None, stop=None, step=None): # known special case of range
"""
range(stop) -> list of integers
range(start, stop[, step]) -> list of integers
Return a list containing an arithmetic progression of integers.
range(i, j) returns [i, i+1, i+2, ..., j-1]; start (!) defaults to 0.
When step is given, it specifies the increment (or decrement).
For example, range(4) returns [0, 1, 2, 3]. The end point is omitted!
These are exactly the valid indices for a list of 4 elements.
"""
pass
>>> type(range(2))
<type 'list'>
>>> range(2)
[0, 1]
2. xrange, 是一个built-in class,
>>> help(xrange)
Help on class xrange in module __builtin__:
class xrange(object)
| xrange(stop) -> xrange object
| xrange(start, stop[, step]) -> xrange object
|
| Like range(), but instead of returning a list, returns an object that
| generates the numbers in the range on demand. For looping, this is
| slightly faster than range() and more memory efficient.
|
| Methods defined here:
|
| __getattribute__(...)
| x.__getattribute__('name') <==> x.name
|
| __getitem__(...)
| x.__getitem__(y) <==> x[y]
|
| __iter__(...)
| x.__iter__() <==> iter(x)
|
| __len__(...)
| x.__len__() <==> len(x)
|
| __reduce__(...)
|
| __repr__(...)
| x.__repr__() <==> repr(x)
|
| __reversed__(...)
| Returns a reverse iterator.
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __new__ = <built-in method __new__ of type object>
| T.__new__(S, ...) -> a new object with type S, a subtype of T
>>>
>>>
class xrange(object):
"""
xrange(stop) -> xrange object
xrange(start, stop[, step]) -> xrange object
Like range(), but instead of returning a list, returns an object that
generates the numbers in the range on demand. For looping, this is
slightly faster than range() and more memory efficient.
"""
def __getattribute__(self, name): # real signature unknown; restored from __doc__
""" x.__getattribute__('name') <==> x.name """
pass
def __getitem__(self, y): # real signature unknown; restored from __doc__
""" x.__getitem__(y) <==> x[y] """
pass
def __init__(self, stop): # real signature unknown; restored from __doc__
pass
def __iter__(self): # real signature unknown; restored from __doc__
""" x.__iter__() <==> iter(x) """
pass
def __len__(self): # real signature unknown; restored from __doc__
""" x.__len__() <==> len(x) """
pass
@staticmethod # known case of __new__
def __new__(S, *more): # real signature unknown; restored from __doc__
""" T.__new__(S, ...) -> a new object with type S, a subtype of T """
pass
def __reduce__(self, *args, **kwargs): # real signature unknown
pass
def __repr__(self): # real signature unknown; restored from __doc__
""" x.__repr__() <==> repr(x) """
pass
def __reversed__(self, *args, **kwargs): # real signature unknown
""" Returns a reverse iterator. """
pass
>>> type(xrange(2))
<type 'xrange'>
>>> xrange(2)
xrange(2)
3. yield, 生成器
在Python中,这种一边循环一边计算的机制,称为生成器(Generator)
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> l = [x*2 for x in xrange(10)]
>>> l
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
>>> type([x*2 for x in xrange(10)])
<type 'list'>
>>> g=(x*2 for x in xrange(10))
>>> g
<generator object <genexpr> at 0x00000000026D4828>
>>> type(g)
<type 'generator'>
>>> g.next()
0
>>> g.next()
2
>>>
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
>>> def odd():
... print 'setp 1'
... yield 1 #相当于return 1
... print 'step 2'
... yield 3
... print 'step 3'
... yield 5
...
>>> o=odd()
>>> type(o)
<type 'generator'>
>>> o.next()
setp 1
1
>>> o.next()
step 2
3
>>> o.next()
step 3
5
>>> o.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
同样的,把函数改成generator后,我们基本上从来不会用next()来调用它,而是直接使用for循环来迭代:
>>> for i in odd():
... print i
...
setp 1
1
step 2
3
step 3
5
例子:
著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
普通函数:
>>> def fib(max):
... n, a, b=0, 0, 1
... while n<max:
... print b
... x=a
... a=b
... b+=x
... n+=1
...
>>> fib(6)
1
1
2
3
5
8
注意:
x=a & a=b & b+=x 这三行可以直接写成 a,b=b,a+b, 这里就不需要中间变量x了(因为执行的时候,先计算=号右边的,所以那个时候a,b都是原始值)
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print b
a, b = b, a + b
n = n + 1
生成器函数(包含yield):
def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1
>>> fib(3)
<generator object fib at 0x0000000001DE4240>
>>> for i in fib(6):
... print i
...
1
1
2
3
5
8
>>>
如何把嵌套的python list转成一个一维的python list?
比如:
普通函数:
def flat(tree):
res = []
for i in tree:
if isinstance(i, list):
res.extend(flat(i))
else:
res.append(i)
return res
print [x for x in flat([[1, 2, 3], [5, 2, 8], [7, 8, 9]])]
[1, 2, 3, 5, 2, 8, 7, 8, 9]
print [x for x in flat([4, [1, 2, 3], [5, 2, 8], [7, 8, 9], [2, [3, 1]]])]
[4, 1, 2, 3, 5, 2, 8, 7, 8, 9, 2, 3, 1]
生成器函数:
def expand_list(nested_list):
for item in nested_list:
if isinstance(item, (list, tuple)):
for sub_item in expand_list(item):
yield sub_item
else:
yield item
print [x for x in expand_list([[1, 2, 3], [5, 2, 8], [7, 8, 9]])]
or
print list(expand_list([[1, 2, 3], [5, 2, 8], [7, 8, 9]]))
4. 协程 & yield
https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0013868328689835ecd883d910145dfa8227b539725e5ed000
协程,又称微线程,纤程。英文名Coroutine。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持还非常有限,用在generator中的yield可以一定程度上实现协程。虽然支持不完全,但已经可以发挥相当大的威力了。
来看例子:
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
import time
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
time.sleep(1)
r = '200 OK'
def produce(c):
c.next() # 必须先执行(也可以换成c.send(None)),不然调用c.send(n)会报错 'TypeError: can't send non-None value to a just-started generator'
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n) #c.send(n)会返回到上次c生成器yield 返回的地方,并继续执行,和c.next()相比,可以设置yield r的值,这样相当于可以穿一个参数过去,比如可以写成c.send(2*n),consumer 里面的n就会是2n了
print('[PRODUCER] Consumer return: %s' % r)
c.close()
if __name__=='__main__':
c = consumer()
produce(c)
执行结果:
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator(生成器),把一个consumer传入produce后:
-
首先调用c.next()启动生成器;
-
然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
-
consumer通过yield拿到消息,处理,又通过yield把结果传回;
-
produce拿到consumer处理的结果,继续生产下一条消息;
-
produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用Donald Knuth的一句话总结协程的特点:
“子程序就是协程的一种特例。”
about 生成器函数(本质是一个class?) built-in 函数 send & close:
class __generator(object):
'''A mock class representing the generator function type.'''
def __init__(self):
self.gi_code = None
self.gi_frame = None
self.gi_running = 0
def __iter__(self):
'''Defined to support iteration over container.'''
pass
def next(self):
'''Return the next item from the container.'''
pass
def close(self):
'''Raises new GeneratorExit exception inside the generator to terminate the iteration.'''
pass
def send(self, value):
'''Resumes the generator and "sends" a value that becomes the result of the current yield-expression.'''
pass
def throw(self, type, value=None, traceback=None):
'''Used to raise an exception inside the generator.'''
pass
可迭代(Iterable), 迭代器(Iterator), 生成器(generator)
可迭代 包括( iterable, iterator, generator )
1. iterable:
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list / tuple / dict / set / str /等;
一类是generator,包括生成器和带yield的generator function。
一类是Iterator, 比如一个实现了__iter__和__next__方法的类
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
|
1
2
3
4
5
6
7
8
9
10
11
|
<code class="hljs python">>>> from collections import Iterable>>> isinstance([], Iterable)True>>> isinstance({}, Iterable)True>>> isinstance('abc', Iterable)True>>> isinstance((x for x in range(10)), Iterable)True>>> isinstance(100, Iterable)False</code> |
2. 迭代器
迭代器 包括( iterator, generator )
生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
|
1
2
3
4
5
6
7
8
9
|
<code class="hljs python">>>> from collections import Iterator>>> isinstance((x for x in range(10)),Iterator)True>>> isinstance([],Iterator)False>>> isinstance({},Iterator)False>>> isinstance('abc',Iterator)False</code> |
可以通过built-in函数iter来把list转为iterator:
>>> li = [1,2,3]
>>> from collections import Iterable, Iterator
>>> isinstance(li, Iterable)
True
>>> isinstance(li, Iterator)
False
>>> li.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'next'
>>> it = iter(li)
>>> isinstance(li, Iterator)
False
>>> isinstance(it, Iterator)
True
>>> it.next()
1
>>> it.next()
2
>>> it.next()
3
>>> it.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
>>> def gg():
... print 'step1'
... yield 1
... print 'step2'
... yield 2
...
>>> isinstance(gg(), Iterator)
True
>>> isinstance(gg(), Iterable)
True
3. 生成器
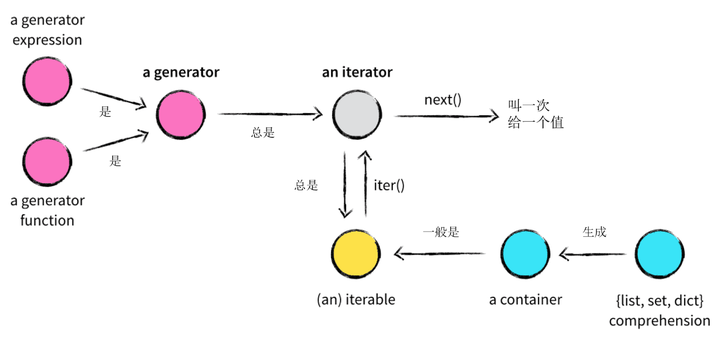
简单来说,generator是iterator的一种,不过它更简洁,不用写带有__iter__() 和 __next__() 的类, 比如:
等差数列
一般的iterator:
from itertools import islice
class seq:
def __init__(self):
self.gap = 2
self.curr = 1
def __iter__(self):
return self
def __next__(self):
value = self.curr
self.curr += self.gap
return value
f = seq()
list(islice(f, 0, 10))
Out: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
以上, 我们构建了一个等差数列, 差为2. 其中, f既是iterable(因为iter方法), 也是iterator(因为有next方法).
对于iterator, next方法做的两件事是:
- 更新iterator的状态,到下次调用;
- 返回当前调用结果, eg: return value.
generator iterator
def seq():
gap, curr = 2, 1
while True:
yield curr
curr = curr + gap
f = seq()
list(islice(f, 0, 10))
Out: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
以上, 我们看到了让它如此优雅的原因 yield. 凡是函数中包含yield语句的就是生成器函数
另外一种generator是 generator expression:squares_list = (x * x for x in range(3))
squares_list
<generator object <genexpr> at 0x10435eaf0>
next(squares_list)
Out: 0
list(squares_list)
Out: [1, 4]
https://zhuanlan.zhihu.com/p/21395221
谈起Generator, 与之相关的的概念有
- {list, set, tuple, dict} comprehension and container
- iterable
- iterator
- generator fuction and iterator
- generator expression
接下来, 我们分别来看看这些概念:
{list, set, tuple, dict} comprehension and container
Container是存储元素的数据结构, 一般存储在内存中. 在Python中,常见的container包括但不限于:
- list, deque, …
- set, …
- tuple, namedtuple, …
- dict, defaultdict, Counter, …
简单举例:
assert 1 in [1, 2, 3] # list
assert 1 in {1, 2, 3} # set
assert 1 in (1, 2, 3) # tuple
d = {1: 'foo', 2: 'bar', 3: 'qux'}
assert 1 in d # dict
特别的, String也是container. 我们可以查询一个substring是否在string里, 如:
s = 'foobar'
assert 'foo' in s
assert 'x' not in s # string 包含所有的 substrings. 需要注意的是string并不存储这些substrings, 只是可以如此查询
iterable
一般说来,大部分的containers是iterable.而iterable不限于containers,还包括像文件.
iterable是实现了__iter__()方法的对象.该方法返回的是的一个iterator对象.其中,iterator的目的是返回所有元素.来看例子:
from collections import Iterable, Iterator
x = [1, 2, 3]
y = iter(x)
z = iter(x)
next(y)
Out: 1
next(y)
Out: 2
next(z)
Out: 1
next(z)
Out: 2
type(x)
Out: list
isinstance(x, Iterable)
Out: True
type(y)
Out: list_iterator
isinstance(y, Iterable)
Out: True
可以看出, x是list, 也是iterable. y和z都是x的返回值, 也就是iterators, 互相独立. iterators通过___next___()这个方法返回元素,每执行一次, 返回一个元素. 值得注意的是,y作为iterable的实例, 它也是iterator. iterable是一个比iterator更大的概念.
import dis
x = [1, 2, 3]
dis.dis('for _ in x: pass')
1 0 SETUP_LOOP 14 (to 17)
3 LOAD_NAME 0 (x)
6 GET_ITER
>> 7 FOR_ITER 6 (to 16)
10 STORE_NAME 1 (_)
13 JUMP_ABSOLUTE 7
>> 16 POP_BLOCK
>> 17 LOAD_CONST 0 (None)
20 RETURN_VALUE
更深入的, 我们可以明显看出在for循环中, Python每次都是调用FOR_ITER这个指令实现了读取下一个next()的功能, 也就是说, for循环中,首先利用GET_ITER得到x的返回值, 一个iterator. 再通过FOR_ITER得到其中的元素. 如此实现了循环的功能.
iterator
那么什么是iterator? 就像之前我们提到的, iterator可以通过调用__next___()生成下一个值. 我们也可以说有__next___()这个方法的都可以是iterator. 这与它如何生成值无关. 我们具体看一个例子:
from itertools import islice
class seq:
def __init__(self):
self.gap = 2
self.curr = 1
def __iter__(self):
return self
def __next__(self):
value = self.curr
self.curr += self.gap
return value
f = seq()
list(islice(f, 0, 10))
Out: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
以上, 我们构建了一个等差数列, 差为2. 其中, f既是iterable(因为iter方法), 也是iterator(因为有next方法).
对于iterator, next方法做的两件事是:
- 更新iterator的状态,到下次调用;
- 返回当前调用结果, eg: return value.
generator function and iterator
Ok. 终于到了本文的正题 generator. 首先下定义, generator是返回generator iterator的function(函数). 具体来说, 它可以让你更优雅的实现iterator, 而不用写带有__iter__() 和 __next__() 的类. 继续以上面那个等差数列为例, 我们看看generator如何的优雅的完成它:
def seq():
gap, curr = 2, 1
while True:
yield curr
curr = curr + gap
f = seq()
list(islice(f, 0, 10))
Out: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
以上, 我们看到了让它如此优雅的原因 yield.
让我们看看这段code是如何运行的,
首先, seq是一个Python程序, 它返回的是iterator. 当 f = seq() 被调用, generator 会准备好返回. 但这时没有执行任何代码.
接下来, 这个generator实例在islice()中被使用. 仍然没有执行代码. 然后, list()开始建立list. 为了得到list的元素, list()开始调用islice()的next()方法抓取元素, 也就是要在 f 函数中取元素.
记住每次只生成一个元素. 这是代码开始运行到 gap, curr = 2, 1 初始化变量. 接着进入始终为真的循环, 到了yield语句. 它做两件事: 1.暂停, 并更新状态到下一次yield, 2. 返回当前结果, 也就是curr值, 1. 这个值接着被传到了islice(), 最后加到list中. list现在是 [1].
list()继续要下一个值. 暂停的 f 函数继续运行下一个语句curr + gap. curr 现在是2. 继续进入下一个while循环, 遇到 yield. 同样的, yield做两件事: 1.暂停下来调整状态; 2. 返回值2. 值返回到list, list 等于 [1, 2].
如此循环直到list取完10个元素. 特别的, 在第11次去值, islice()会有exception: StopIteration. 告诉list已经取值结束.
generator expression
generator expression是Python的另一种generator. 相信大家都用过list expression, 比如生成一列数的平方:
numbers = [1, 2, 3, 4, 5, 6]
[x ** 2 for x in numbers]
[1, 4, 9, 16, 25, 36]
generator expression很类似, 比如
squares_list = (x * x for x in numbers)
squares_list
<generator object <genexpr> at 0x10435eaf0>
next(squares_list)
Out: 1
list(squares_list)
Out: [4, 9, 16, 25, 36]
以上, 不再累述.
Summary
下图说明了各个概念之间的关系,
注: 图片部分引用自 http://nvie.com/posts/iterators-vs-generators/
最后,谈谈为什么要使用generators. 它能帮你实现更优雅的代码, 减少中间变量和不必要的数据结构,从而代码量, 节省内存空间和运算性能.
针对一个循环代码,
def something():
result = []
for ... in ...:
result.append(x)
return result
你可以做这样的转换
def iter_something():
for ... in ...:
yield x


 浙公网安备 33010602011771号
浙公网安备 33010602011771号