



python 模拟登录
Python模拟登录的几种方法
方法一:直接使用已知的cookie访问
特点:
简单,但需要先在浏览器登录
原理:
简单地说,cookie保存在发起请求的客户端中,服务器利用cookie来区分不同的客户端。因为http是一种无状态的连接,当服务器一下子收到好几个请求时,是无法判断出哪些请求是同一个客户端发起的。而“访问登录后才能看到的页面”这一行为,恰恰需要客户端向服务器证明:“我是刚才登录过的那个客户端”。于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态)。
当然,这也意味着,只要得到了别的客户端的cookie,我们就可以假冒成它来和服务器对话。这给我们的程序带来了可乘之机。
我们先用浏览器登录,然后使用开发者工具查看cookie。接着在程序中携带该cookie向网站发送请求,就能让你的程序假扮成刚才登录的那个浏览器,得到只有登录后才能看到的页面。
具体步骤:
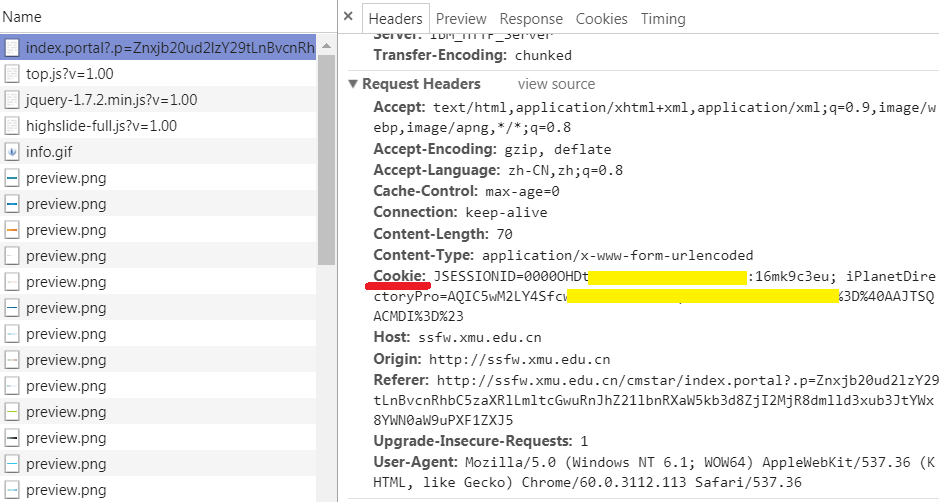
1.用浏览器登录,获取浏览器里的cookie字符串
先使用浏览器登录。再打开开发者工具,转到network选项卡。在左边的Name一栏找到当前的网址,选择右边的Headers选项卡,查看Request Headers,这里包含了该网站颁发给浏览器的cookie。对,就是后面的字符串。把它复制下来,一会儿代码里要用到。
注意,最好是在运行你的程序前再登录。如果太早登录,或是把浏览器关了,很可能复制的那个cookie就过期无效了。
2.写代码
urllib库的版本:

#! /usr/bin/env python
# -*- coding:utf-8 -*-
import sys
import io
from urllib import request
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'csrftoken=Q4RsWBTLQh8TPgRtihyeLmaswKyJsQE6UooebfNJUscCYmotd2CKZSKLTsJYmk88; sessionid=m8p7y6ityqjsrqlotffiyt8xszqm2pfq'
#登录后才能访问的网页
url = 'http://127.0.0.1:8000/account/edit/'
req = request.Request(url)
#设置cookie
req.add_header('cookie', cookie_str)
#设置请求头
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36')
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))
requests库的版本:
方法二:模拟登录后再携带得到的cookie访问
原理:
我们先在程序中向网站发出登录请求,也就是提交包含登录信息的表单(用户名、密码等)。从响应中得到cookie,今后在访问其他页面时也带上这个cookie,就能得到只有登录后才能看到的页面。
具体步骤:
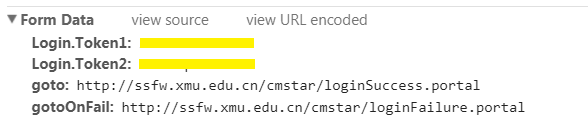
1.找出表单提交到的页面
还是要利用浏览器的开发者工具。转到network选项卡,并勾选Preserve Log(重要!)。在浏览器里登录网站。然后在左边的Name一栏找到表单提交到的页面。怎么找呢?看看右侧,转到Headers选项卡。首先,在General那段,Request Method应当是POST。其次最下方应该要有一段叫做Form Data的,里面可以看到你刚才输入的用户名和密码等。也可以看看左边的Name,如果含有login这个词,有可能就是提交表单的页面(不一定!)。

这里要强调一点,“表单提交到的页面”通常并不是你填写用户名和密码的页面!所以要利用工具来找到它。
2.找出要提交的数据
虽然你在浏览器里登陆时只填了用户名和密码,但表单里包含的数据可不只这些。从Form Data里就可以看到需要提交的所有数据。
3.写代码
urllib库的版本:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import sys
import io
import re
import urllib.request
import http.cookiejar
import requests
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
username = 'bookmarks'
password = 'bookmarks'
csrftoken = None
#登录时表单提交到的地址
login_url = 'http://127.0.0.1:8000/account/login/'
#设置请求头
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4',
#'Cookie': 'csrftoken={}'.format(csrftoken),
}
# 获取token
sss = requests.Session()
r = sss.get(login_url, headers=headers)
reg = r"<input type='hidden' name='csrfmiddlewaretoken' value='(.*)' />"
pattern = re.compile(reg)
result = pattern.findall(r.content.decode('utf-8'))
token = result[0]
print(sss.cookies.get_dict())
csrftoken = sss.cookies.get_dict()['csrftoken']
headers['Cookie'] = r'csrftoken={}'.format(csrftoken)
print(headers)
#登录时需要POST的数据
data = {'username': username,
'password': password,
'csrfmiddlewaretoken': token,
}
post_data = urllib.parse.urlencode(data).encode('utf-8')
#构造登录请求
req = urllib.request.Request(login_url, data = post_data, headers = headers)
# resp = urllib.request.urlopen(req)
# print(resp.read().decode('utf-8'))
#构造cookie
cookie = http.cookiejar.CookieJar()
#由cookie构造opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
#发送登录请求,此后这个opener就携带了cookie,以证明自己登录过
resp = opener.open(req)
#登录后才能访问的网页
url = 'http://127.0.0.1:8000/account/edit/'
# 注意,下面这句传了headers参数的请求是不行的,因为headers参数的cookie中不包含sessionid,
# 而且这个参数优先级看起来比opener中的cookie要高,所以请求会因为没有sessionid而无法有效识别为已登录用户
# req = urllib.request.Request(url, headers=headers)
#构造访问请求
req = urllib.request.Request(url)
resp = opener.open(req)
print(resp.read().decode('utf-8'))
requests库的版本:
方法三:模拟登录后用session保持登录状态
原理:
session是会话的意思。和cookie的相似之处在于,它也可以让服务器“认得”客户端。简单理解就是,把每一个客户端和服务器的互动当作一个“会话”。既然在同一个“会话”里,服务器自然就能知道这个客户端是否登录过。
具体步骤:
1.找出表单提交到的页面
2.找出要提交的数据
这两步和方法二的前两步是一样的
3.写代码
requests库的版本
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
import requests
username = 'bookmarks'
password = 'bookmarks'
#登录时表单提交到的地址
#注意: 这里的url一定要正确,不然会导致登录后,session中没有sessionid,无法访问登录后才能访问的页面,比如这里写成 'http://127.0.0.1:8000/account/',
#也可以登录(会跳转到'http://127.0.0.1:8000/account/login/'),但sss.cookies.get_dict():{'csrftoken': 'bagQl1Vg6yPhcUbmT6pdeyssZuk4EdsDqWUdkL93ceNuhYSrCse9JyKxdFn3gOxb'}
#如果是正确的url,则sss.cookies.get_dict():{'csrftoken': 'YA54duVvR4ujQTbbn4HPcwwFaowZF6QTTl0UY3xw7aoZHSmZCtylz4neoMNL1Xop', 'sessionid': 'jrn2u3bfpao4e0biwlmvbms96lzsqzep'}
#带有sessionid,具体原因,我目前未知
login_url = 'http://127.0.0.1:8000/account/login/'
#设置请求头
# headers = {
# 'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36',
# # 'Connection': 'keep-alive',
# }
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4'
}
# 获取token
sss = requests.Session()
r = sss.get(login_url, headers=headers)
reg = r"<input type='hidden' name='csrfmiddlewaretoken' value='(.*)' />"
pattern = re.compile(reg)
result = pattern.findall(r.content.decode('utf-8'))
token = result[0]
# postdata
data = {'username': username,
'password': password,
'csrfmiddlewaretoken': token,
}
# 登录
r = sss.post(login_url, headers=headers, data=data)
print(sss)
print(sss.cookies.get_dict())
url = 'http://127.0.0.1:8000/account/edit/'
r = sss.get(url)
print(r.content.decode('utf-8'))
方法四:使用无头浏览器访问
特点:
功能强大,几乎可以对付任何网页,但会导致代码效率低
原理:
如果能在程序里调用一个浏览器来访问网站,那么像登录这样的操作就轻而易举了。在Python中可以使用Selenium库来调用浏览器,写在代码里的操作(打开网页、点击……)会变成浏览器忠实地执行。这个被控制的浏览器可以是Firefox,Chrome等,也可以用无头(没有界面)浏览器。
具体步骤:
1.安装selenium
2.在源代码中找到登录时的输入文本框、按钮这些元素
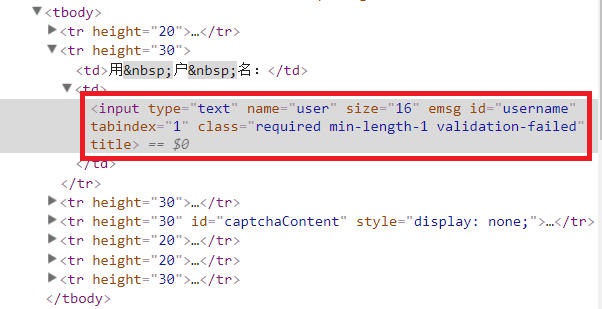
因为要在无头浏览器中进行操作,所以就要先找到输入框,才能输入信息。找到登录按钮,才能点击它。
在浏览器中打开填写用户名密码的页面,将光标移动到输入用户名的文本框,右键,选择“审查元素”,就可以在右边的网页源代码中看到文本框是哪个元素。同理,可以在源代码中找到输入密码的文本框、登录按钮。
3.考虑如何在程序中找到上述元素
Selenium库提供了find_element(s)_by_xxx的方法来找到网页中的输入框、按钮等元素。其中xxx可以是id、name、tag_name(标签名)、class_name(class),也可以是xpath(xpath表达式)等等。当然还是要具体分析网页源代码。
4.写代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') #改变标准输出的默认编码
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
# driver = webdriver.Chrome()
#登录页面
url = r'http://127.0.0.1:8000/account/login/'
driver.get(url)
# 等待一定时间,让js脚本加载完毕
driver.implicitly_wait(3)
#输入用户名
# username = driver.find_element_by_xpath("//*[@id='id_username']")
username = driver.find_element_by_name("username")
username.send_keys('bookmarks')
#输入密码
# password = driver.find_element_by_xpath("//*[@id='id_password']")
password = driver.find_element_by_name("password")
password.send_keys('bookmarks')
#点击“登录”按钮
login_button = driver.find_element_by_xpath("//*[@id='content']/div[1]/form/p[3]/input")
# login_button = driver.find_element_by_xpath("//form[input/@type='submit']")
login_button.submit()
#网页截图
driver.save_screenshot('picture1.png')
#打印网页源代码
print(driver.page_source.encode('utf-8').decode())
driver.quit()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号