Pytorch笔记
相关配置
- CUDA:12.2
- cuDNN:12.X
- python:3.11
- pytorch:对应CUDA12.1
torch相关配置函数
torch.cuda.is_available() //cuda是否可用
torch.cuda.device_count() //查看GPU数量
torch.cuda.get_device_name() //查看DEVICE(GPU)名
torch.cuda.current_device() //检查目前使用GPU的序号
torch.cuda.set_device() //指定使用的卡
参考
学习框架
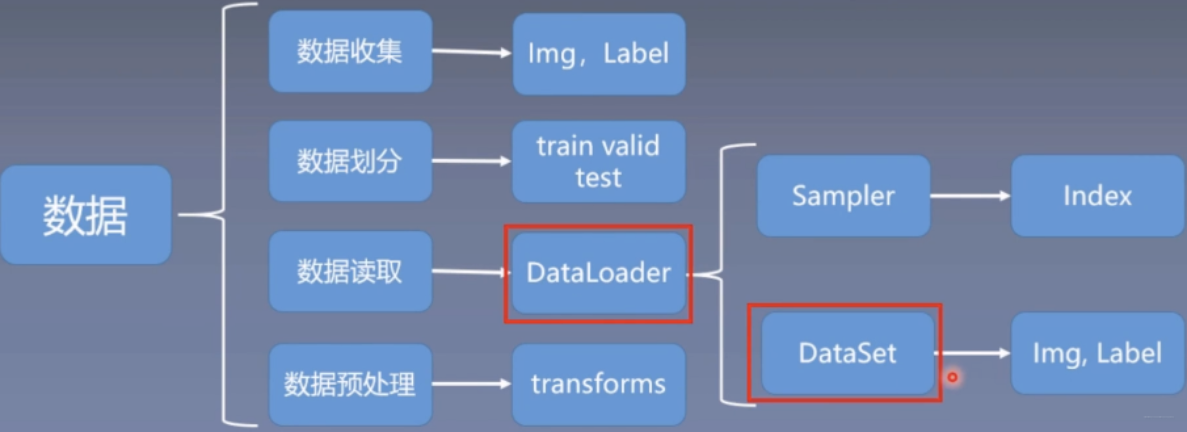
五大模块:数据+模型+损失函数+优化器+迭代训练
数据模块:数据收集、数据划分、数据读取、数据预处理
数据读取
- Dataset:负责可被pytorch使用的数据集的创建
- Dataloader:向模型中传递数据

DataLoader的使用
载入相关类
from torch.utils.data import DataLoader
了解DataLoader函数
DataLoader(
dataset,
batch_size=1,
shuffle=False,
num_workers=0,
drop_last
)
"""
dataset:是数据集
batch_size:是指一次迭代中使用的训练样本数。通常我们将数据分成训练集和测试集,并且我们可能有不同的批量大小。
shuffle:是传递给 DataLoader 类的另一个参数。该参数采用布尔值(真/假)。如果 shuffle 设置为 True,则所有样本都被打乱并分批加载。否则,它们会被一个接一个地发送,而不会进行任何洗牌。
num_workers:允许多处理来增加同时运行的进程数
drop_last:数据集大小不被batch size整除时,是否将最后的batch丢弃
"""
Dataset自定义数据集
Dataset本质是一个抽象类,不能实例化,所以在使用Dataset的时候,需要定义自己的数据集类,也是Dataset的子类,来继承Dataset类的属性和方法
- Dataset可以作为DataLoader的参数传入DataLoader,实现基于张量的数据预处理
- Dataset主要有两种类型,分别是
Map-style datasets和Iterable-style datasets
Map-style datasets:实现了__getitem__()和__len__()方法,它代表数据的索引到真正数据样本的映射
读取的数据并非直接把所有数据读取出来,而是读取的数据的索引或者键值 这种类型是使用最多的类型,采用这种访问数据的方式可以大大节约训练时需要的内存数量,提高模型的训练效率
Iterable-style datasets:实现了__iter__()方法,与上述类型不同之处在于,他会将真实的数据全部载入,然后在整个数据集上进行迭代 这种读取数据的方式比较适合处理流数据
比如将车牌数据集作为自定义数据
目录结构:
D:
│
└───Program Files
│
└───DeepLearning
│
└───Pytorch
│
├───MyDatasets.py
└───data
│
├───train_data
└───train_label
# Writer:TuTTTTT
# 编写Time:2023/11/21 17:09
#自定义车牌数据集,并实现getitem/len方法
from torch.utils.data import Dataset
import os
from PIL import Image
class LicenseData(Dataset):
# 初始化init:建立训练数据的路径
def __init__(self,root_dir,train_dir):
self.rootpath=root_dir
self.trainpath=train_dir
self.datapath=os.path.join(self.rootpath,self.trainpath)
self.files=os.listdir(self.datapath)
# 利用getitem获取图像元数据,方便显示图片
def __getitem__(self, id):
file_name=self.files[id] # 获取特定文件名
path=os.path.join(self.datapath,file_name) # 跟路径拼接
img=Image.open(path)
return img
# 统计数据长度
def __len__(self):
return len(self.files)
#调用测试
root_dir=os.getcwd() #->DeepLearning
train_dir='Pytorch\\data\\train_data'
license=LicenseData(root_dir,train_dir)
img=license[0]
img.show()
Tensorboard包
Tensorboard安装|打开
安装
pip|conda
打开
tensorboard --logdir=~ //logdir是事件文件所在文件夹名的父级目录,
注1:默认使用6006端口,若要使用别的端口则附加:--port=~
注2:logdir要注意路径的问题
界面图:

- SummaryWriter 类提供了一个高级 API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。 该类异步更新文件内容。 这允许训练程序调用方法以直接从训练循环将数据添加到文件中,而不会减慢训练速度。
- add_scalar():添加标量
- add_tensor():添加张量
- add_image():添加图片
- close():关闭
SummaryWriter
#导包
from torch.utils.tensorboard import SummaryWriter
SummaryWriter源码
class SummaryWriter:
def __init__(
self,
log_dir=None,
comment="",
purge_step=None,
max_queue=10,
flush_secs=120,
filename_suffix="",
):
log_dir (str): 保存目录位置。默认为 runs/**CURRENT_DATETIME_HOSTNAME**,每次运行后会更改。使用分层文件夹结构,以便轻松比较不同运行之间的差异。例如,对于每个新实验,传入 'runs/exp1'、'runs/exp2' 等,以便在它们之间进行比较。
comment (str): 附加到默认 log_dir 后缀的注释 log_dir。如果指定了 log_dir,则此参数不起作用。
purge_step (int): 当在步骤 :math:T+X 处记录崩溃并在步骤 :math:T 处重新启动时,任何全局步骤大于或等于 :math:T 的事件将被清除并从 TensorBoard 中隐藏。请注意,崩溃和恢复的实验应该具有相同的 log_dir。
max_queue (int): 在强制刷新到磁盘之前,挂起的事件和摘要的队列大小。默认为十个项目。
flush_secs (int): 挂起的事件和摘要刷新到磁盘的频率,以秒为单位。默认为每两分钟一次。
filename_suffix (str): 添加到 log_dir 目录中所有事件文件的后缀。有关文件名构造的详细信息,请参阅 tensorboard.summary.writer.event_file_writer.EventFileWriter。
from torch.utils.tensorboard import SummaryWriter
# 创建具有自动生成的文件夹名称的摘要写入器。
writer = SummaryWriter()
# 文件夹位置:runs/May04_22-14-54_s-MacBook-Pro.local/
# 使用指定的文件夹名称创建摘要写入器。
writer = SummaryWriter("my_experiment")
# 文件夹位置:my_experiment
# 创建带有附加注释的摘要写入器。
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# 文件夹位置:runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
add_scalar()
def add_scalar(
self,
tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False,
):
参数:
tag (str): 数据标识符
scalar_value (float or string/blobname): 要保存的值
global_step (int): 要记录的全局步骤值
walltime (float): 可选,用事件的秒数覆盖默认的 walltime(time.time())。
new_style (boolean): 是否使用新样式(tensor 字段)或旧样式(simple_value 字段)。新样式可能导致更快的数据加载
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
add_image()
def add_image(
self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"
):
向摘要中添加图像数据。
注意,这需要 pillow 包。
参数:
tag (str): 数据标识符
img_tensor (torch.Tensor, numpy.ndarray, 或 string/blobname): 图像数据
global_step (int): 要记录的全局步骤值
walltime (float): 可选,用事件的秒数覆盖默认的 walltime(time.time())。
dataformats (str): 形如 CHW、HWC、HW、WH 等的图像数据格式规范。
形状:
img_tensor: 默认为 :math:(3, H, W)。可以使用 torchvision.utils.make_grid() 将一批张量转换为 3xHxW 格式,或者调用 add_images 让我们来完成这项工作。形状为 :math:(1, H, W)、:math:(H, W)、:math:(H, W, 3) 的张量也是合适的,只要传递了相应的 dataformats 参数,如 CHW、HWC、HW。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC = np.zeros((100, 100, 3))
img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
writer = SummaryWriter()
writer.add_image('my_image', img, 0)
# 如果您有非默认的尺寸设置,请设置 dataformats 参数。
writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC')
writer.close()
注:PIL下Image读取图片是PIL.JpegImage格式;opencv读取图片是ndarray格式;
且,opencv读取的图片颜色改变了,PIL的不改变
数据预处理
- torchvision:计算机视觉工具包
- torchvision.transforms:常用的图像预处理方法, 比如标准化,中心化,旋转,翻转等操作
- torchvision.datasets:常用的数据集的dataset实现, MNIST, CIFAR-10, ImageNet等
- torchvision.models:常用的模型预训练, AlexNet, VGG, ResNet, GoogLeNet等。
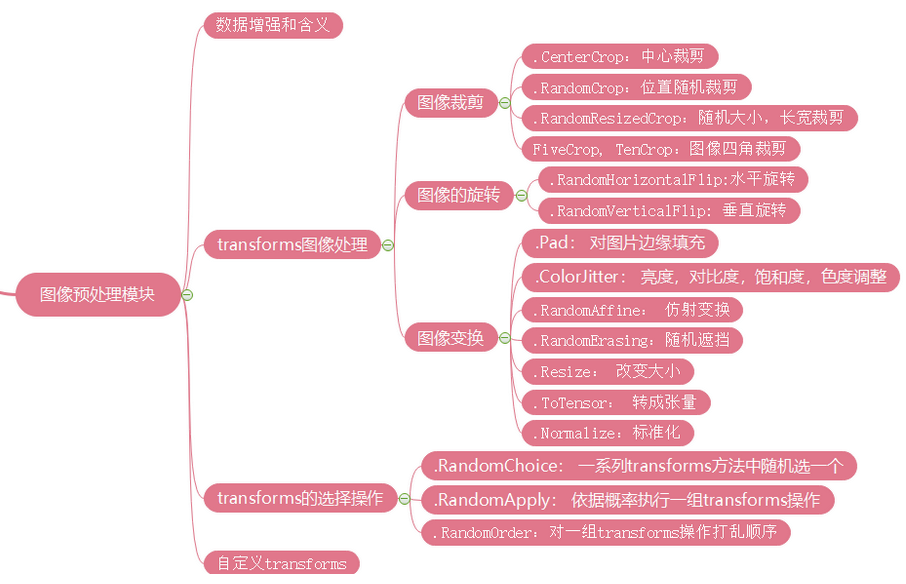
transforms
数据中心化,数据标准化,缩放,裁剪,旋转,翻转,填充,噪声添加,灰度变换,线性变换,仿射变换,亮度、饱和度及对比度变换。
# 导包
from torchvision import transforms
图像处理
1.数据增强
数据增强又称为数据增广, 数据扩增,是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力.
数据增强策略原则: 让训练集与测试集更接近。
- 空间位置上: 可以选择平移
- 色彩上: 灰度图,色彩抖动
- 形状: 仿射变换
- 上下文场景: 遮挡,填充
2.图像裁剪
1. transforms.CenterCrop(size): 图像中心裁剪图片, size是所需裁剪的图片尺寸,如果比原始图像大了, 会默认填充0。
2. transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant): 从图片中位置随机裁剪出尺寸为size的图片, size是尺寸大小,padding设置填充大小(当为a, 上下左右均填充a个像素, 当为(a,b), 上下填充b个,左右填充a个,当为(a,b,c,d), 左,上,右,下分别填充a,b,c,d个), pad_if_need: 若图像小于设定的size, 则填充。 padding_mode表示填充模型, 有4种,constant像素值由fill设定, edge像素值由图像边缘像素设定,reflect镜像填充, symmetric也是镜像填充, 这俩镜像是怎么做的看官方文档吧。镜像操作就类似于复制图片的一部分进行填充。
RandomCrop 是一种常用的数据增强方法,用于随机裁剪输入的图像或张量
# 语法:
torchvision.transforms.RandomCrop(size, padding=0, pad_if_needed=False, fill=0, padding_mode='constant')
# size (int or tuple): 要裁剪的输出图像的大小。如果是 int,输出将是一个正方形的。
# padding (int or sequence, optional): 可选的填充数值,默认为 0。如果指定了此参数,则在进行裁剪之前在图像周围进行填充。
# pad_if_needed (bool, optional): 如果为 True,则在需要时进行填充,以使输入大小等于所需的大小。
# fill (int or tuple, optional): 填充值,默认为 0。如果指定了填充,将用指定的值填充填充区域。
# padding_mode (str, optional): 填充模式,默认为 'constant'。可选值有 'constant', 'edge', 'reflect', 'symmetric',用于指定填充的方式。
# 示例
transform = transforms.Compose([
transforms.RandomCrop(128),
# 其他变换操作...
])
注意事项:
-
输入类型: RandomCrop 方法通常用于图像数据,但也可以用于其他类型的数据,如张量。
-
随机性: 正如其名,RandomCrop 是一个随机操作,每次应用时都会随机选择裁剪位置。这有助于模型更好地适应不同的输入变化,提高模型的泛化能力。
-
填充: 如果设置了填充 (padding 参数不为默认值),则会在进行裁剪之前在图像周围进行填充。这对于处理边缘情况或要求输出图像大小一致的情况很有用。
-
填充模式: 如果使用了填充,可以通过 padding_mode 参数选择不同的填充方式,例如 'constant', 'edge', 'reflect', 'symmetric'。
-
性能考虑: 随机裁剪是一种计算密集型操作,尤其是在大规模数据集上。在训练过程中,需要权衡数据增强的效果和计算开销。
-
应用顺序: RandomCrop 通常作为数据预处理管道中的一部分,与其他变换操作一起使用。在 transforms.Compose 中按顺序组织变换。
3. transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(3/4, 4/3), interpolation): 随机大小,长宽比裁剪图片。 scale表示随机裁剪面积比例,ratio随机长宽比, interpolation表示插值方法。
4. FiveCrop, TenCrop: 在图像的上下左右及中心裁剪出尺寸为size的5张图片,后者还在这5张图片的基础上再水平或者垂直镜像得到10张图片,具体使用这里就不整理了。
3.图像的翻转和旋转
-
RandomHorizontalFlip(p=0.5), RandomVerticalFlip(p=0.5): 依概率水平或者垂直翻转图片, p表示翻转概率
-
RandomRotation(degrees, resample=False, expand=False, center=None):随机旋转图片, degrees表示旋转角度 , resample表示重采样方法, expand表示是否扩大图片,以保持原图信息。
4.图像变换
-
transforms.Pad(padding, fill=0, padding_mode='constant'): 对图片边缘进行填充
-
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0):调整亮度、对比度、饱和度和色相, 这个是比较实用的方法, brightness是亮度调节因子, contrast对比度参数, saturation饱和度参数, hue是色相因子。
-
transfor.RandomGrayscale(num_output_channels, p=0.1): 依概率将图片转换为灰度图, 第一个参数是通道数, 只能1或3, p是概率值,转换为灰度图像的概率
-
transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0): 对图像进行仿射变换, 反射变换是二维的线性变换, 由五中基本原子变换构成,分别是旋转,平移,缩放,错切和翻转。 degrees表示旋转角度, translate表示平移区间设置,scale表示缩放比例,fill_color填充颜色设置, shear表示错切
-
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False): 这个也比较实用, 对图像进行随机遮挡, p概率值,scale遮挡区域的面积, ratio遮挡区域长宽比。 随机遮挡有利于模型识别被遮挡的图片。value遮挡像素。 这个是对张量进行操作,所以需要先转成张量才能做
-
transforms.Lambda(lambd): 用户自定义的lambda方法, lambd是一个匿名函数。lambda [arg1 [, arg2…argn]]: expression
-
transforms.Resize(size)方法改变图像大小
没限制图像类型
size(序列或 int): 希望的输出大小。如果 size 是一个序列,如(h,w),输出大小将与之匹配。如果尺寸是一个 int、图像的较小边缘将与此数字匹配。 也就是说,如果高度大于宽度,那么图像将被重新缩放为(size * height / width, size)。
- transforms.ToTensor()方法是用于将 PIL 图像或 ndarray 转换为张量,并相应地缩放值。
- 对于 PIL 图像,它将其转换为形状为 (C x H x W)、值范围为 [0.0, 1.0] 的 torch.FloatTensor。支持的 PIL 图像模式有 (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)。
- 对于 numpy.ndarray,如果其数据类型为 np.uint8,也会被转换为形状为 (C x H x W)、值范围为 [0.0, 1.0] 的 torch.FloatTensor。
from torchvision.transforms import ToTensor
from PIL import Image
# 创建一个 PIL 图像
image = Image.open("example.jpg")
# 创建 ToTensor 转换类
to_tensor = ToTensor()
# 使用 ToTensor 转换类将 PIL 图像转换为张量
tensor_image = to_tensor(image)
print("PIL Image:")
print(image)
print("\nTensor Image:")
print(tensor_image)
- transforms.Normalize()方法是将数据进行标准化
!!注:normalize接收tensor类型
参数:
mean(均值):一个包含每个通道均值的序列。
std(标准差):一个包含每个通道标准差的序列。
inplace(原地操作,可选):一个布尔值,指示是否进行原地操作。
标准化计算方式:
import torch
from torchvision.transforms import Normalize
# 创建一个张量图像(示例数据)
image_tensor = torch.rand(3, 256, 256) # 3通道,256x256的图像
# 定义均值和标准差
mean_values = [0.5, 0.5, 0.5]
std_values = [0.5, 0.5, 0.5]
# 创建 Normalize 模块
normalize = Normalize(mean=mean_values, std=std_values)
# 使用 Normalize 模块对图像进行归一化
normalized_image = normalize(image_tensor)
# 打印原始图像和归一化后的图像
print("Original Image Tensor:")
print(image_tensor)
print("\nNormalized Image Tensor:")
print(normalized_image)
其他方法
1、ToPILImage
class ToPILImage:
"""Convert a tensor or an ndarray to PIL Image
This transform does not support torchscript.
Converts a torch.*Tensor of shape C x H x W or a numpy ndarray of shape
H x W x C to a PIL Image while adjusting the value range depending on the ``mode``.
Args:
mode (`PIL.Image mode`_): color space and pixel depth of input data (optional).
If ``mode`` is ``None`` (default) there are some assumptions made about the input data:
- If the input has 4 channels, the ``mode`` is assumed to be ``RGBA``.
- If the input has 3 channels, the ``mode`` is assumed to be ``RGB``.
- If the input has 2 channels, the ``mode`` is assumed to be ``LA``.
- If the input has 1 channel, the ``mode`` is determined by the data type (i.e ``int``, ``float``, ``short``).
.. _PIL.Image mode: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#concept-modes
"""
2、
选择操作
-
transforms.RandomChoice([transforms1, transforms2, transforms3]): 从一系列transforms方法中随机选一个
-
transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5): 依据概率执行一组transforms操作
-
transforms.RandomOrder([transforms1, transforms2, transforms3]): 对一组transforms操作打乱顺序
自定义transforms
transforms原机制
class Compose(object):
def __init__(self, transforms):
if not torch.jit.is_scripting() and not torch.jit.is_tracing():
_log_api_usage_once(self)
self.transforms = transforms
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
自定义transfomrs
class Yourtransfomrs(object):
def __init__(self,...):
...
def __call__(self,img):
...
return img
transforms操作的组合使用
class Compose:
"""Composes several transforms together. This transform does not support torchscript.
Please, see the note below.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])
"""
注:Compose的参数列表里是操作的实例
小结
配置SummaryWriter并添加事件
1、导入SummaryWriter包
2、创建SummaryWriter实例
3、通过实例添加事件
4、关闭SummaryWriter实例
eg.
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
trans_1=transforms.ToTensor()
img_tensor=trans_1(img)
writer.add_image("img_tensor2",img_tensor)
writer.close()
待整理:
torch.randint 是一个用于生成随机整数张量的函数。以下是该函数的基本用法:
torch.randint(low, high, size, dtype=None, generator=None, layout=torch.strided, device=None, requires_grad=False)
- low:生成的整数张量中可能的最小值。
- high:生成的整数张量中可能的最大值,不包括该值。
- size:生成张量的形状。
- dtype:生成张量的数据类型,默认为 torch.int64。
- generator:生成器对象,用于控制生成的随机数。如果不提供,将使用默认的全局生成器。
- layout:张量的布局,默认为 torch.strided。
- device:生成张量的设备,默认为 None,表示使用默认设备。
- requires_grad:是否需要梯度,默认为 False。
示例:
import torch
# 生成形状为 (2, 3)、取值范围在 [0, 10) 之间的整数张量
random_int_tensor = torch.randint(0, 10, (2, 3))
print(random_int_tensor)
注意:需要注意的是,torch.randint 生成的整数张量的范围是左闭右开的,即包含 low 而不包含 high。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号