领域概况
对比学习
SimCLRv2 from Google brain team
Facebook's MoCo
动作分割
早期的工作大都通过滑动窗口来建模外观和动作的变化状态,因此他们主要关注于短期的依赖关系。之后同时捕捉长期和短期的依赖关系称为了动作分割的焦点。——Global2Local
序列模型,序列模型以迭代的方式捕捉长短期的依赖关系。
Vo and Bobick 利用贝叶斯网络来分割由随机上下文无关文法表示的动作。
Tang et al. 使用隐马尔可夫模型建模状态的转换。之后,隐马尔可夫模型可以与上下文无关文法、高斯混合模型和循环神经网络相结合,以建模长期的动作依赖关系。
Cheng et al.利用序列记忆器,从通过视频学习到的视觉词中捕捉长期依赖关系。
然而,在建模长期依赖关系时,这些序列模型不能灵活地并行处理。他们同时也经常遭受信息遗忘问题。
多路结构. 一些研究者利用多路模型建模长期和短期的依赖关系。
Richard and Gall利用动态规划推理由长度模型、语言模型和动作分类器组成的网络。
Singh et al.通过一个二路网络学习短视频块的表示,然后将这些表示传递给双向 LSTM,以捕捉不同块之间的相关性。(采用顺序预测,方法速度慢)
? 提出一个三路结构,包含自我、空间和时序三路架构被引入以学习第一人称视图的特定特性。然后使用多类支持向量机对这些特征进行分类。
Tricornet利用混合时间卷积和循环网络来捕捉局部的运动并且记忆长期的动作依赖关系。
Cou-pledGAN 使用生成网络,利用多模态的数据以更好地建模人类的动作演变。利用多路结构来捕捉长短期的信息的方式增加了计算冗余
时间卷积网络. 最近,时间卷积网络可以(TCN)通过调整感受野在一个统一的结构内建模不同时序长度的依赖关系,同时可以并行地处理长视频
Lea et al.提出编码器-解码器风格的 TCN 用于在动作分割任务中捕捉长距离的时序模式,同时通过扩张卷积增大感受野。他们的方法遵循编码器-解码器架构,在编码器中进行
时域卷积和池化,在解码器中进行上采样和反卷积。(细粒度信息丢失问题)
Lei 和 Todorovic 进一步对编码-解码的TCN改进,通过可形变卷积处理有完整分辨率的残差流,以及有低分辨率的池化流。
Ding 和 Xu 在编码器-解码器 TCN 的基础上增加了横向连接,并提出了一种预测逐帧动作标签的时域卷积特征金字塔状网络。
Mac et al.提出使用可变形卷积和局部一致性约束来学习时空特征。
MS-TCN利用多阶段的扩张TCN以及手工设计的扩张率组合,从不同大小的时序感受野中提取信息。
然而,感受野的调整仍然取决于人工的设计,这可能是不合适的。
补充技术,通过边缘的优化进一步提升视频分割的准确性
Li et al.利用迭代的训练过程,进行动作清单优化以及软边界分配。
Wang et al. 利用语义边界信息来优化预测结果。
其他的研究者关注于弱监督下的动作分割 或无监督下的分割。
这些工作仍然依赖于高效的 TCN 来建模动作依赖关系,是对我们所提出的方法补充。
实例分割
1.自顶向下,遵循“先检测后分割”策略,首先检测边界框,然后在每个bbox中分割实例掩码。比如Mask R-CNN
2.自底向上,对每个像素点嵌入一个向量,将不同实例的像素点拉开,相同实例的像素点拉进。然后使用聚合后处理方法,将实例区分开来。
基于实例的位置和大小——SOLO
目标检测
参考
综述
目标检测算法近20年发展路线图:
近20年来目标检测领域的技术路线主要可分为两个阶段,即以传统检测方法为主的第一阶段,以及基于深度学习的第二阶段。为了完整阐述目标检测技术路线的演变过程,下面将按照这两个阶段以及第二阶段中的分类情况顺序介绍相关算法的特点。需要注意的是,在本节中出现的mAP(mean Average Precision),即平均精度,均为mAP50。
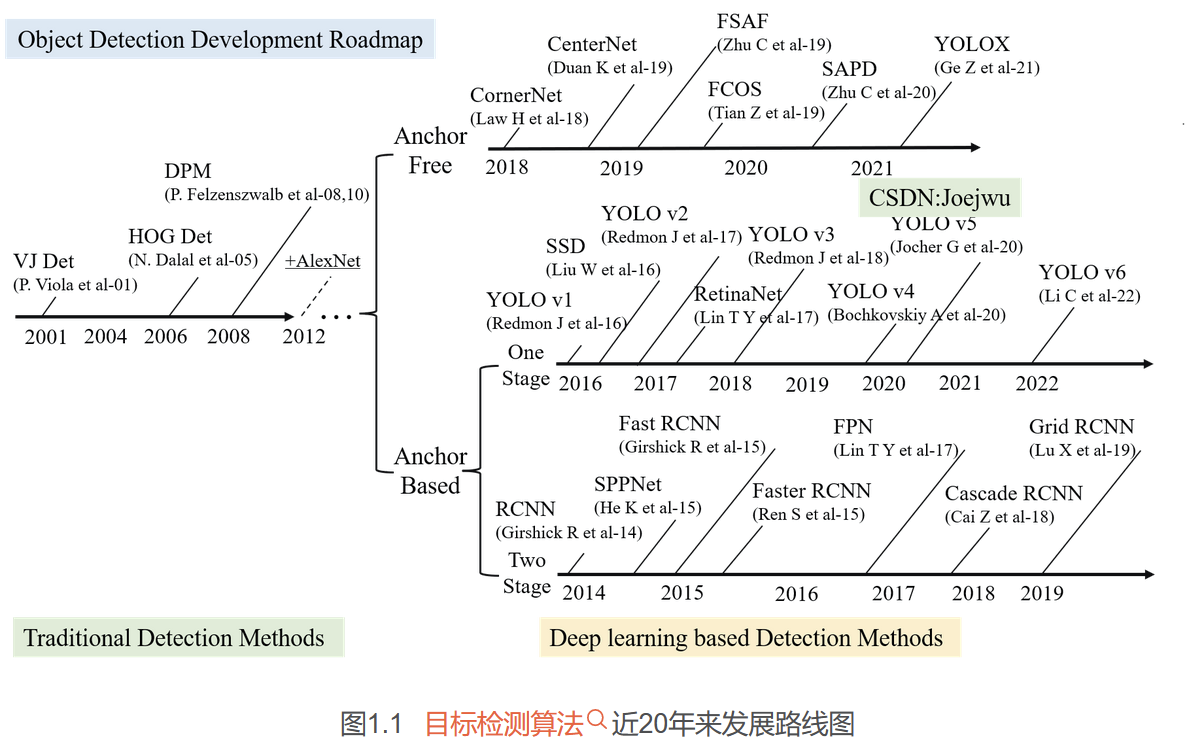
1.传统目标检测算法
传统目标检测算法中无法像现在主流的基于CNN的检测模型那样直接提取有效特征,而主要是通过手工提取的方式,概括其检测流程主要即先选取候选区域,或者称为ROI(Region Of Interest),随后对可能包含目标的区域提取特征,最后即对提取的特征进行分类。
- Viola P等人提出的Viola Jones(VJ Detector)检测器中通过对滑动窗口的检测来判断是否存在目标,并通过积分图、AdaBoost分类器以及级联结构三大优化措施来降低计算量以加速检测。
- Dalal N等人提出的HOG检测器基于本地像素块提取特征直方图,并且在待检测目标受光照或变形等影响下仍能获得较好的检测效果。
- Felzenszwalb P F等人提出的DPM检测器可作为HOG检测器的一种延申,其在HOG检测器的基础上叠加边框回归等技术,在VOC目标检测挑战赛上获得过冠军,成为当时目标检测领域的SOTA(State Of The Art)。
尽管这些传统检测算法在当时已取得了不错的结果,但是相较于当前基于深度学习的检测算法,这些传统算法在精度、计算量以及检测速度等方面均要远远落后。
2.基于深度学习的Anchor-based两阶段目标检测算法
上述基于手工提取特征的传统目标检测算法发展较为缓慢,直到AlexNet出现后,其引发了卷积神经网络在计算机视觉领域的变革,基于CNN的目标检测算法逐渐成为了当前该领域内的主流。其中,又细分出了两条技术路线,即Anchor based方案与Anchor free方案,此处的Anchor即锚框,即分为基于锚框的检测方案与无固定锚框的检测方案。在Anchor based方案中,还包括单阶段与两阶段检测算法,此处将先介绍目前两阶段检测算法的相关研究现状。
- 两阶段目标检测算法即先从待检测图像中选择候选区域,然后再从候选区域中检测并生成目标边框。
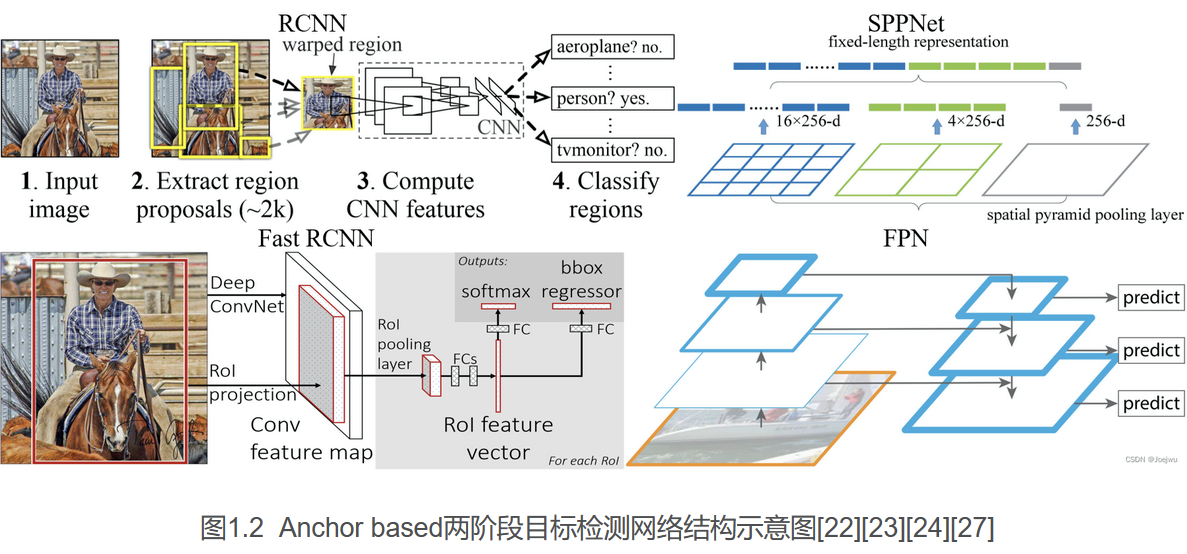
- 最早的基于CNN的两阶段目标检测算法是Girshick R等人提出的RCNN[22],该检测器通过选择搜索从候选框中选择可能包含物体的目标框,然后将这些目标框全部缩放到固定尺寸,随后作为CNN模型的输入来提取特征,最终将提取的特征传输给SVM(Support Vector Machine)分类器,用来判断是否存在目标以及进一步的分类。RCNN最终在PASCAL VOC 2007数据集上实现了58.5%的平均精度,相较于传统检测器中DPM 33.7%的最高平均精度,实现了极大的提升。
- 随后,在2015年,He K等人提出了SPPNet[23],该检测器中采用了一种空间金字塔池化层,其使得模型中全连接层的输入都是固定尺寸的特征图,进而可避免重复计算,最终在PASCAL VOC 2007数据集上实现了59.2%的mAP。
- Girshick R等人基于RCNN以及SPPNet,提出了Fast RCNN[24],在VOC 2007数据集上实现了70.0%的mAP,但该检测器中仍采用了RCNN中的选择搜索算法,而该算法的使用将导致整个检测过程速度较慢。为此,Ren S等人在此基础上提出了Faster RCNN[25],该检测器中舍弃了选择搜索算法,而创新性地提出了通过区域候选网络生成候选框,可大幅提升检测速度,最终在VOC 2007数据集上实现了73.2%的mAP,MS COCO数据集[26]上实现了42.7%的mAP。
- Lin T Y等人在Faster RCNN的基础上,提出了FPN(Feature Pyramid Network)技术[27],其具有横向连接的自上而下的结构,极大地促进了检测精度的提升,并最终在COCO数据集上实现了59.1%的mAP。
- Cai Z等人提出的Cascade RCNN[28]同样是在Faster RCNN的基础上,通过堆叠多个级联模块,进而可采用不同IOU(Intersection Over Union)阈值进行训练,最终也在COCO数据集上实现了SOTA效果。
- Lu X等人提出的Grid RCNN[29]中则是将Faster RCNN中的位置回归替换为关键点检测,并实现了SOTA。
如图1.2中,即展示了部分上述两阶段检测器中的典型结构。
3. 基于深度学习的Anchor based单阶段目标检测算法
- 不同于两阶段检测器中需要先获得候选区域再进行检测,单阶段目标检测算法中可直接产生检测结果,即类别概率与边界框坐标,仅需一个阶段即可完成检测。
- 最早出现的单阶段检测器是由Redmon J等人提出的YOLO v1[30],其创新性地提出将图像划分为多个网格(Grid Cell),然后对每一个网格均预测边界框与类别概率;作为单阶段检测器的开山之作,YOLO v1虽然在精度上略低于同时期的两阶段检测器,但其检测速度却远远高于后者,因此在问世后,即引发了大量的关注,因为在实际落地场景中所追求的就是极高的检测速度。随后两年中,YOLO v1原团队相继提出了YOLO v2[31]与YOLO v3[32],其中YOLO v2在v1的基础上将骨干网络替换为DarkNet19,实现了更高的检测精度与速度,YOLO v3则是进一步地将骨干网络替换为DarkNet53,并借鉴FPN中的思想采用三条分支去检测不同尺度的目标,其在COCO数据集上达到了57.9%的mAP。在这之间,Liu W等人提出了SSD检测器[33],采用了Multi-reference和Multi-resolution技术,在COCO数据集上实现了46.5%的mAP;Lin T Y等人则是提出了RetinaNet[34],其将原本的交叉熵损失函数替换为根据Loss值来调节权值的Focal Loss,同样借鉴FPN中的思想,最终在COCO数据集上实现59.1%的mAP。
- YOLO v3之后的几个版本的YOLO模型,均为该领域其他团队提出。Bochkovskiy A等人提出YOLO v4[16],该模型具备较大的工程实践价值,因为在该检测器中集成了同时期目标检测领域中众多的Tricks,最终在COCO数据集上实现了65.7%的mAP。Glenn Jocher等人提出了YOLO v5[35],该模型在YOLO v3的基础上,同样集成了大量的Tricks,其最新版本在COCO数据集上实现了68.9%的mAP,不仅在精度上超越了YOLO v4,该检测器在速度上同样高于后者的实现;而在与两阶段检测器的比较中,此时单阶段检测器的精度已从略低发展为远远超越,同时还继续保持着检测速度上的优势。鉴于此,本研究中选择了YOLO v5模型作为后续压缩实验的主要目标。最近的YOLO v6[36]由Li C等人于2022年提出,该检测器在YOLO v5的基础上参考RepVGG[37]中的思想,对原检测器中的骨干网络以及Neck部分进行了优化设计,最终在COCO数据集上实现了70.0%的mAP。
4. 基于深度学习的Anchor Free目标检测算法
Anchor based检测器相较于传统检测器已经在速度、精度上均取得了极大的优势,但由于其基于Anchor进行预测的基本属性,使这一类检测器仍存在不少缺点。例如基于Anchor的检测器往往对其数量、大小以及长宽比等都极为敏感,这些超参的设置不同,最终训练得到的同一结构的模型精度可能存在较大差距。所以这也导致对于不同的任务,不同的数据集,往往都需要通过K-Means聚类方法重新生成一组新的Anchor。此外,无论是在训练过程中还是在仅进行前向推理时,最终都需要计算所有Anchor与Ground Truth(真实框)之间的IOU,而这显然会增加计算量与内存占用等开销。
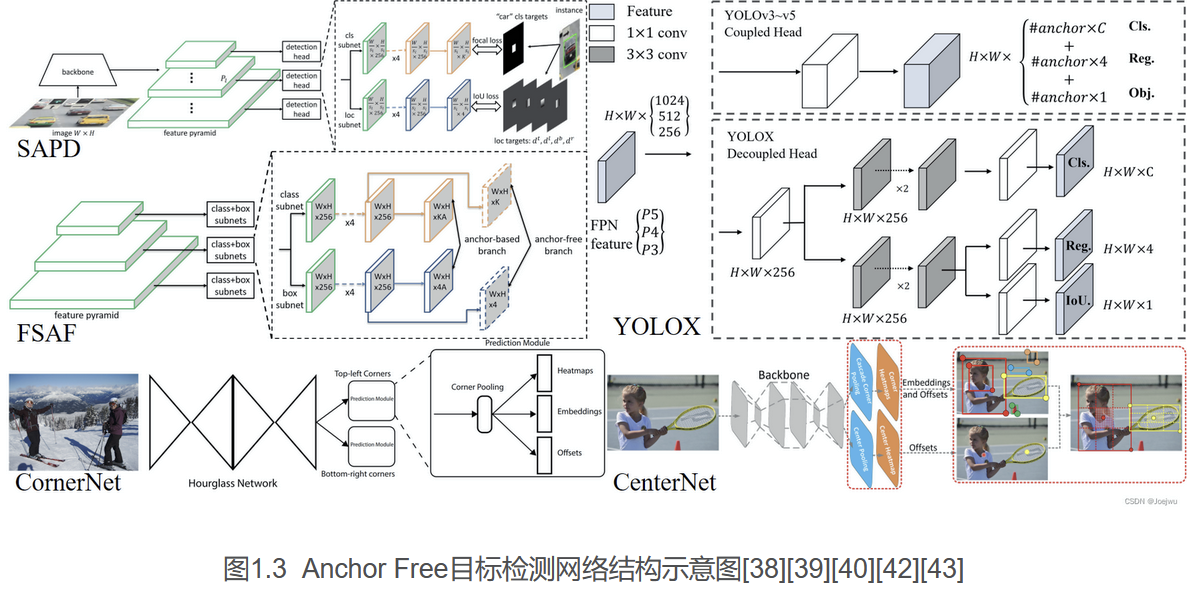
- 鉴于此,Law H等人提出了Anchor Free检测器CornerNet[38],该检测器中将原本对目标边界框的预测替换为对目标关键点的预测,即通过目标左上角和右下角的坐标来确定目标位置,而无需Anchor作为先验框,其最终在COCO数据集上实现了57.8%的mAP。
- Duan K等人随后提出了CenterNet检测器[39],其不在预测左上角与右下角关键点,而是直接检测目标的中心点坐标,最终在COCO数据集上实现了64.5%的mAP。
- Zhu C等人提出的FSAF检测器[40]中提出了一种新的结构FSAF,将其用于特征金字塔网络中Anchor Free分支的训练,最终在COCO数据集上实现了65.2%的mAP。
- 同一时期,Tian Z等人提出的FCOS检测器[41],是一种逐像素的检测算法,除了可作为单阶段检测器外,FCOS还可以作为两阶段检测器中的区域推荐网络,最终在COCO数据集上实现了64.1%的mAP。
- Zhu C等人在2020年提出的SAPD检测器[42]则是在CornerNet以及FSAF的基础上,提出了软加权锚点与软选择金字塔层级两个策略,最终在COCO数据集上实现了67.4%的mAP。
- Ge Z等人提出的YOLOX检测器[43],则是综合了YOLO系列检测器的优势,但有别于该系列检测器均为Anchor based检测器,YOLOX实现了Anchor Free,同时提出了双检测头输出的策略,即一个检测头输出类别,另一个则输出边界框信息,最终在COCO数据集上实现了68.0%的mAP。
如图1.3中,即展示了部分上述Anchor Free检测器中的典型结构。
————————————————————————————————————————
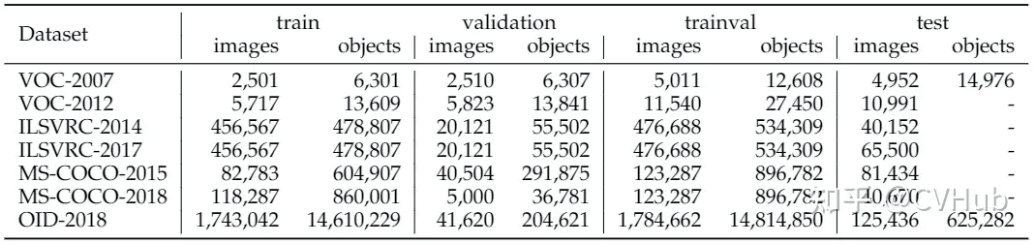
数据集
Pascal VOC21,ILSVRC22,MS-COCO23,和Open Images(QID)24数据集是目标检测使用最多的四大公共数据集。
样例图片及其标签:
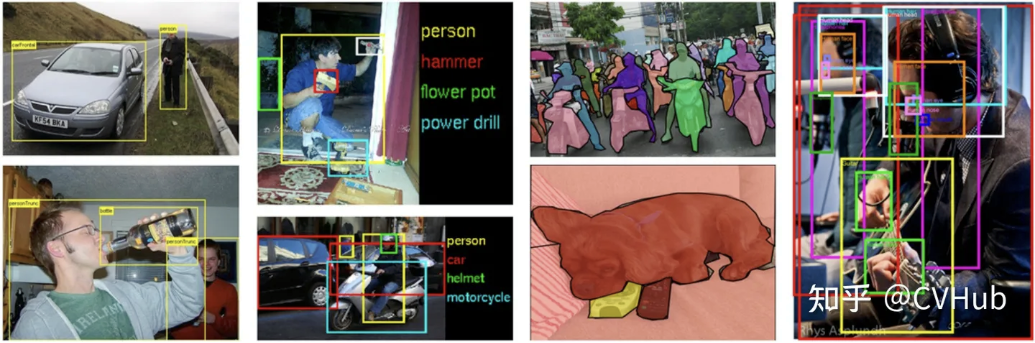
四大检测数据集的数据统计结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号